I implement all 7 of the distributed file system modules. Each module is implemented as a RESTful service.
I provide a Python library which can be imported into any Python file and used with a similar API to the native Python I/O library.
Additionally I develop a sample GUI which can be used to interact with the distributed file service.
Below are links to the details of the 7 features I implement:
- Distributed Transparent File Access
- Security Service
- Directory Service
- Replication
- Caching
- Transactions
- Lock Service
Each service is implemented as a separate module exposing a RESTful API.
I use Python with the Flask library to implement each component and its lightwight API.
A Python library is provided which can be used to interact with the file system. All operations provided by the library are transparent with respect to the underlying implementation. The user only uses the standard operations open, close, read, write, start_transaction, commit_transation, cancel_transaction but the client under the hood authenticates with the security service, calls the directory service which communicates with the replication service, if requrired calls the lock service and/or the transaction service and finally calls the file server with a copy of the desired file.
Additionally I provide a GUI applicaton with all the same operations but allowing the user to interact with the file system in a more convinient way.
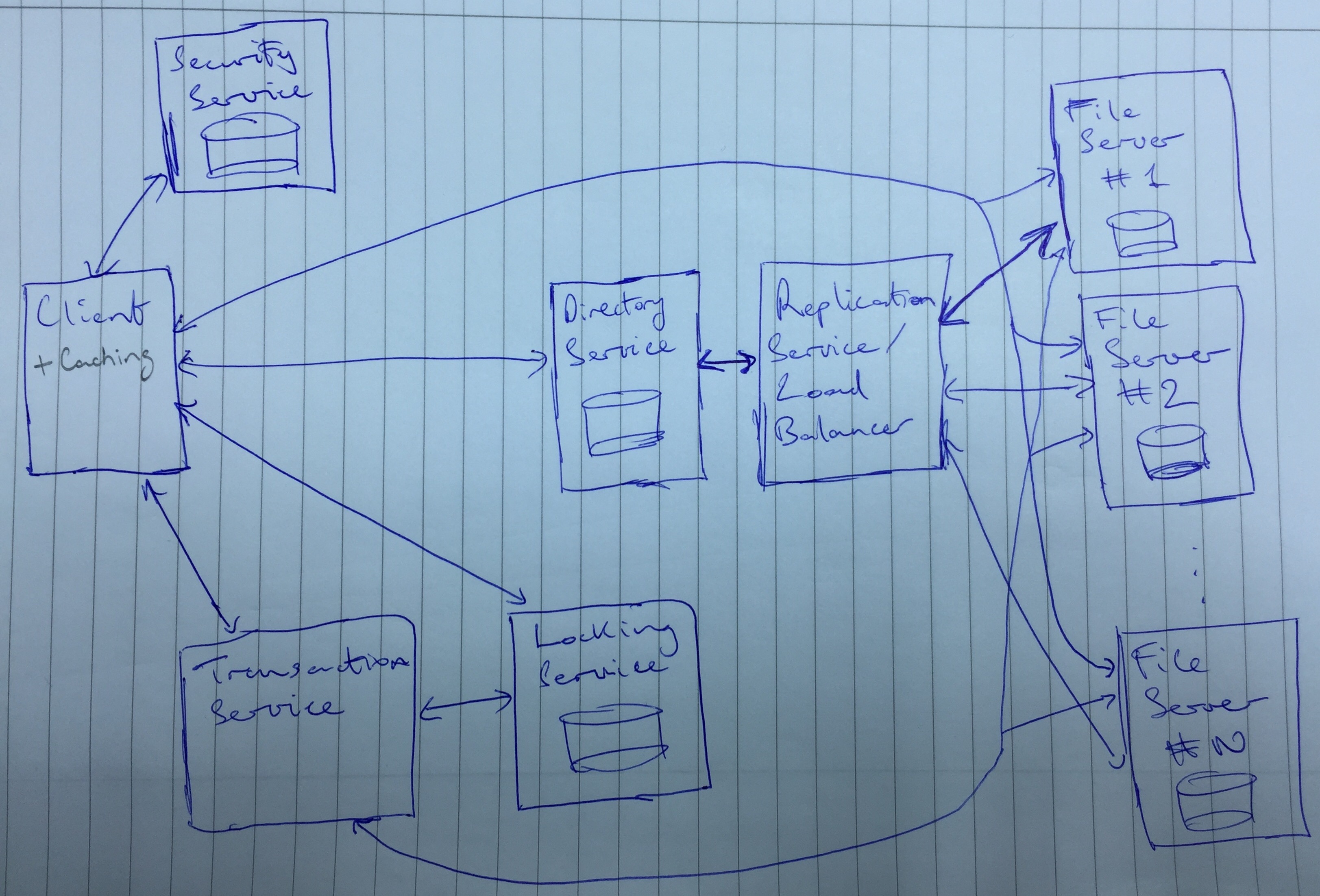
There are two ways to interact with the distributed file system, via a Python library which can be imported into any Python program and exposes an API similar to the Python I/O library. The other is via a GUI.
Starting the servers
In separate terminal windows run the following commands, which will setup 3 replicated file servers (with 2 copies of each file in the file system) and the other servers in the distributed file system:
python distributed_file_system/api.py --port_num=5001 --host=127.0.0.1 --replication_service_addr=http://127.0.0.1:5006
python distributed_file_system/api.py --port_num=5002 --host=127.0.0.1 --replication_service_addr=http://127.0.0.1:5006
python distributed_file_system/api.py --port_num=5003 --host=127.0.0.1 --replication_service_addr=http://127.0.0.1:5006
python lock_service/api.py --port_num=5004 --host=127.0.0.1
python security_service/api.py --port_num=5005 --host=127.0.0.1
python replication/api.py --port_num=5006 --host=127.0.0.1 --num_copies_per_file=2 --file_server_addrs http://127.0.0.1:5001 http://127.0.0.1:5002 http://127.0.0.1:5003
python transactions/api.py --port_num=5007 --host=127.0.0.1 --lock_service_ip=http://127.0.0.1:5004 --file_server_addrs http://127.0.0.1:5001 http://127.0.0.1:5002 http://127.0.0.1:5003
python directory_service/api.py --port_num=5008 --host=127.0.0.1 --replication_service_addr=http://127.0.0.1:5006
This will also automatically setup three users with user_ids 1, 2, 3 and passwords test1, test2 and test3.
Setup the client
from client import Client
client = Client(username, password, directory_service_addr, locking_service_addr, security_service_addr, transaction_service_addr)
Open and write a file
fname = 'path/to/file.txt'
client.open(fname, 'w')
res = client.write(fname, 'write this to the file')
client.close(fname)
Open and read a file
fname = 'path/to/file.txt'
client.open(fname, 'r')
res = client.read(fname)
client.close(fname)
Start and commit a transaction
fname_1 = 'path/to/file1.txt'
fname_2 = 'path/to/file2.txt'
client.start_transaction()
client.open(fname, 'w')
res = client.write(fname_1, 'write this to file 1')
client.close(fname)
client.open(fname, 'w')
res = client.write(fname_1, 'write this to file 2')
client.close(fname)
client.commit_transaction()
Cancelling a transaction
fname_1 = 'path/to/file1.txt'
fname_2 = 'path/to/file2.txt'
client.start_transaction()
client.open(fname, 'w')
res = client.write(fname_1, 'write this to file 1')
client.close(fname)
client.open(fname, 'w')
res = client.write(fname_1, 'write this to file 2')
client.close(fname)
client.cancel_transaction()
In addition to the Python library a simple GUI is provided to interact with the file server. The GUI is built with Tkinter and in fact just calls the provided Python library/client so is in itself a test of the ability to import the library into a Python project and use it to interact with the file server.
To start the GUI go to the root of the project and run:
python gui.py \
--directory_service_addr=http://127.0.0.1:5008 \
--locking_service_addr=http://127.0.0.1:5004 \
--security_service_addr=http://127.0.0.1:5005 \
--transaction_service_addr=http://127.0.0.1:5007 \
--user_id=1 \
--password=test1
Open and write a file
Open and read a file
Start and commit a transaction
Cancelling a transaction
I implement a AFS style distributed file system. In particular I implement AFS v1.
The file server offers fetch and store operations as well as polling operations for the file state. The file server is also exposes operations to the transaction service to correctly handle transactions. None of these operations are directly expose to the user via either the Python client library or the GUI application and are called under the hood as a result of the open, close, read, write, etc. operations that are exposed to the client.
The server exposes these operations via a RESTful API that the client communicates with. The client is a Python library that can be imported into another Python program and provides transparent access to the distributed file system. A user of this library would see little difference to using the standard Python I/O library.
When a file is opened the client stores it locally on the user's machine and subsequent read and write operations are made to that local file. When the file is closed, any changes are pushed to the server.
I implement a flat file system, so the mechanisms specified in AFS v2 for reducing server load via caching directory traversals are unnecessary.
The client side API is:
open(file_name, mode)
close(file_name)
read(file_name)
write(file_name, bytes)
start_transaction()
commit_transaction()
cancel_transaction()
The server side API (not exposed to the user) is:
GET: fetch(file_id, mode)
POST: store(file_id, bytes, transaction_id)
GET: poll(file_id, user_id)
PUT: commit_transaction(transaction_id)
PUT: cancel_transaction(transaction_id)
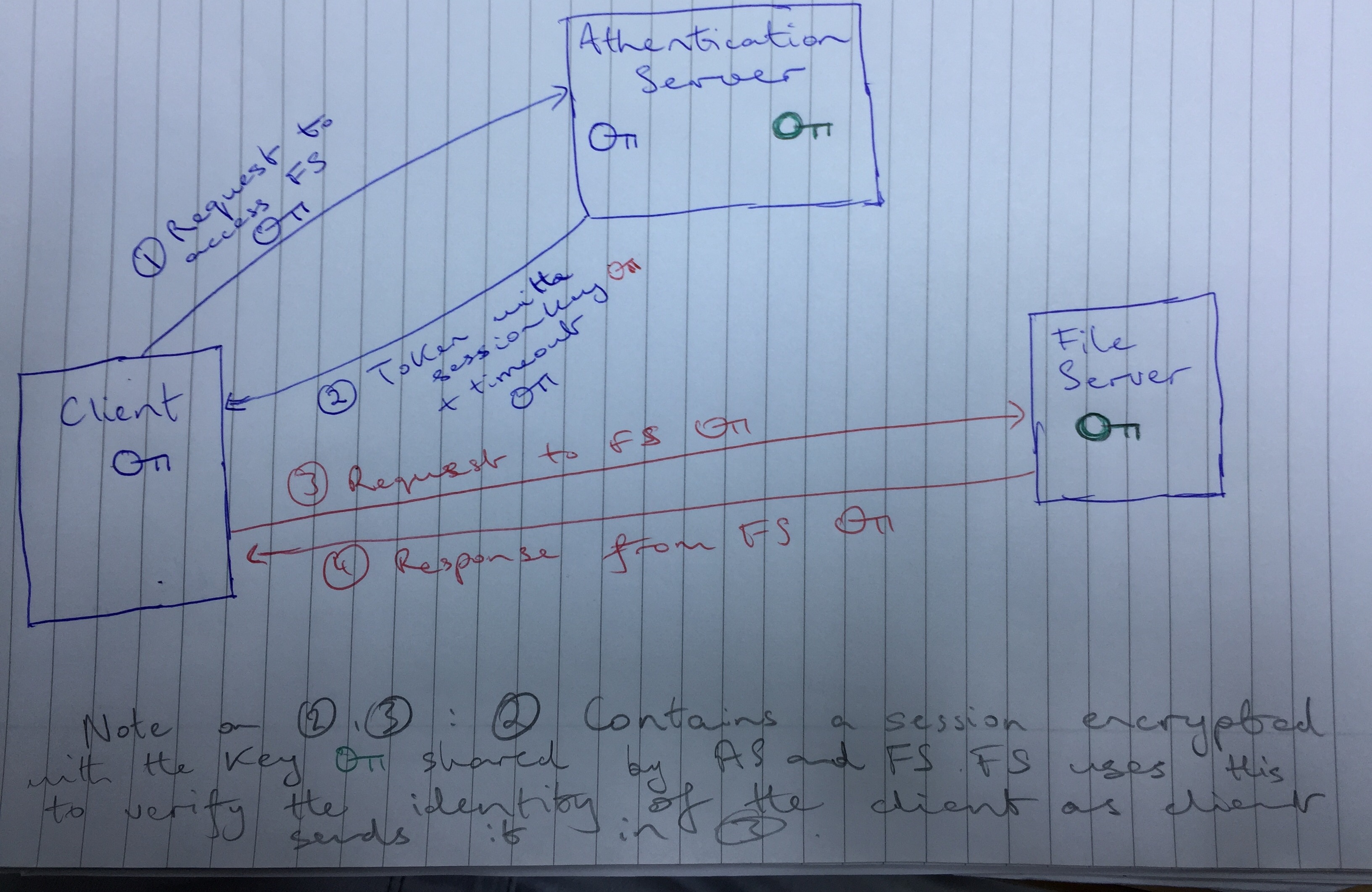
I implement a 3 key authentication protocol as described in the provided documentation.
In particular the client transparaently calls the athentication server (AS) with a request to access a particular service e.g. file server, lock service, etc. This request is encrypted with the client's key (password) which is shared with the AS. The message also contains the user's username unencrypted.
The AS searches it's database for the user's key and decrypts the sent message with this key. If this step passes, it must have been the user who has sent the message as this is a secret key known only to the user and the AS.
The AS sends back a token composed of a session key, a session key encrypted with a key known only to the AS and the service the client wishes to communicate with and a timeout for the session key.
The user decrypts this message using their key and uses the session key to encrypt all future communication (up to the session key timeout) with this session key. The user includes in all communication with the service unenrypted (with the user key) the session key which has been encrypted with the key known only to the AS and the service.
When the service receives a message from the client, it decrypts the session key that has been encrypted with it's secret key and uses the decrypted session key to decrypt the rest of the message. Any resposes to the client are encrypted with the session key.
All messages on the network are encrypted with secret keys that cannot be derived from the communication, thus communication on the network is secure.
Rivest Cipher 4 is used for fast encryption, although any other cipher could be substituted into this system.
Each service has a different secret key that it shares with the AS.
The security service API (not exposed to the user) is:
GET: get_session_token(user_id, server_name)
POST: create_user(user_id, password, access_level, admin_password)
I use a flat file system - in effect offering a single directory. This is similar to other popular distributed file systems such as Amazon Cloud Storage and Google Cloud Storage.
The client calls the directory with the desired file name and the directory service respondes with the file's id and the server on which the file is stored.
Under the hood the directory service in fact calls the replication service which implements a round robin load balancing protocol and returns the server on which a copy of the file is stored.
The directory service API (not exposed to the user) is:
GET: map_file_name(file_name)
Files are replicated across different file server nodes with consistency maintained by broadcasting writes to nodes with replicas of the written file.
The implemented replication service enables both load balancing and data parallelisation. The administrator chooses both how many file servers there are in the distributed system and how many replicas of each file there are.
The administrator can increase the traffic capacity of the distributed file system by increasing the number of replicas for each file in the distributed file system and increasing the number of file servers in the system.
The administrator can enable the space capacity of the system to grow by increasing the number of file servers in the system while holding the number of replicas of each file constant.
The replication service implements a variant of a round robin load balancing strategy. If a user has not requested a file recently then the next server in the round robin order with a copy of the file is chosen. If the user has requested a file recently they are sent back to the server they previously requested it from.
The replication service exposes an API which is called by the directory service to map file ids to server addresses and by the file server to get all other file servers with a copy of the file so that they can broadcast any modifications.
The replication service API (not exposed to the user) is:
GET: get_next_server_with_copy(file_id)
GET: get_all_servers_with_copies(file_id)
As per the AFS specification, clients cache files locally. On each client side open operation, the client polls the file server. If the local copy of the file is stale then the client makes a fetch call to the file server to get the updated file. If the locally cached copy is still fresh then all operations on the file are made to the locally cached version of the file.
Once this file is closed any modifications to the file are pushed to the file server via a store operation. The file server then maintains consistency with file servers with replicated copies by broadcasting the modification only to these servers.
NB: the caching directory contains only a very simple library which can be used by the client. Caching is primarily implemented as part of the client/file server, so the majority of the caching code exists there.
A simple transaction service enables the user to batch queries into atomic units.
The client exposes a standard transactions API which allows the user to start, commit and cancel transactions.
If the user starts a transaction and later commits it, then the series of operations take effect as if they were not part of a transaction.
If the user cancels a transaction then all operations are rolled back and have no effect.
This service is implemented via shadowing. Files on the file server have a shadow copy to which all operations in a transaction are made.
If the transaction is later committed the shadow file is copied into the master file.
If the transaction is later cancelled then the shadow file is made NULL.
Through the locking service I ensure that mutliple writes on a file id cannot be made.
The transaction service API (not exposed to the user) is:
POST: start_transaction()
POST: commit_transaction(transaction_id)
POST: cancel_transaction(transaction_id)
A read-many, write-one style locking service is provided.
A client locks a file whenever they open a file in write mode. The client calls a RESTful lock service in order to lock/unlock a particular file id.
In order to ensure the lock service scales to a large distributed system we maintain a database containing the lock status of each file id. Thus I don't maintain locks for each file in memory, allowing the number of locks to scale to the limits of the database (disk space) rather than memory.
The lock service locks the database (using a reentrant lock from the Python threading library). It then applies the lock/unlock operation to the database for that file id.
In order to enable parallel handling of lock/unlock requests, I maintain a thread pool in memory. Each file id is hashed to an integer and this integer is used to find that file's reentrant lock.
if pool_size = number of threads in thread pool and num_files = number of file ids in the distributed system
Then the memory requirements of the lock service is O(pool_size) and the disk space requirements are O(num_files). But we can service up to pool_size parallel lock/unlock requests. So we choose how much parallisation of the lock service is desirable while maintaining constant disk space requirements.
The lock service API (not exposed to the user) is:
POST: lock(file_id)
POST: unlock(file_id)