{kind=link}
{kind=link}
{kind=link}
Scrapy + redis + MySQL爬去douban图书8w条数据 模块:
- Scrapy
- redis
- MySQL
- pandas
- sqlalchemy
- MySQLdb
- CSV
- 1.spider获取数据用ItemLoader提取保存至item
- 2.pipeline处理返回的item存储到redis
- 3.process_items.py提取redis的数据进行数据清洗保存到 ./Data/*.csv文件
代理池:https://github.com/jhao104/proxy_pool !
获取代理接口的代理IP
为process_items.py提供数据清洗函数
- checkBookInfo(infos)
- isPrice(info)
- isPublishing(info)
入库函数
- to_mysql(mysql_engine,DATA_FILE_PATH,NEW_DATA_FILE_PATH)
----------------------------------------------更新----------------------------------------------
但是更新后有一下问题:
- 1.爬取速度变慢
- 2.较多数据会重复
- 3.某些数据字段错乱
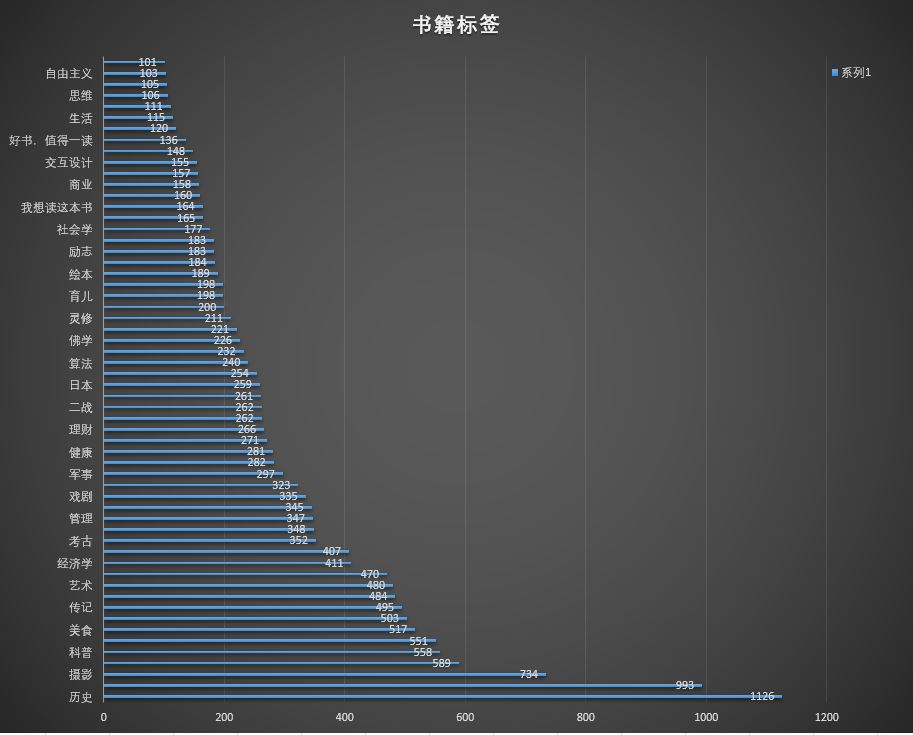
爬取目标:book.douban.com/tag/ 里面的144个标签,每个标签最多50页,每页最多20本书籍
但是经过调整后比原来爬取的少,只有36000条有效数据(根据ISBN 每本书籍都不一样)
预期目标应该有 110000本书籍
----------------------------------------------数据展示-------------------------------------------
爬取的数据使用csv文件保存方便分析和清洗
虽然数据量比较少,但是对于刚刚学习数据分析,数据清洗应该足够
数据清洗:使用pandas进行简单的数据清洗:
- 1.去除重复项
- 2.替换异常值和极端值
- 3.转换数据类型:Date,Price等字段
import os
import pandas
import numpy
books_filename = os.path.join('Data','douban-books.csv')
books_data = pandas.read_csv(books_filename,skiprows=[0,],names =['ISBN','Bookname','Author','Price',
'Comments','Rating','Tag','Original',
'Translator','Publishing','Date','Pages','Series'
])
# 去除重复项
dp_data = books_data.drop_duplicates(['ISBN'])
# 替换异常值和极端值
dp_data = dp_data.replace({'Date':'unknow'},'2017-01-01')
dp_data['Date'] = pandas.to_datetime(dp_data['Date'],errors='coerce')
dp_data['Price'] = pandas.to_numeric(dp_data['Price'],errors='coerce',downcast='float')
dp_data['Date'] = dp_data['Date'].fillna(numpy.datetime64('2017-01-01'))
# 重新写入新的文件,去除不必要字段
cleaned_file = os.path.join('Data','douban-books_cleaned.csv')
dp_data.to_csv(path_or_buf=cleaned_file,index=False,float_format='%.3f',sep='\\',columns=
['ISBN','Bookname','Author','Price',
'Comments','Rating','Tag',
'Translator','Publishing','Date'])
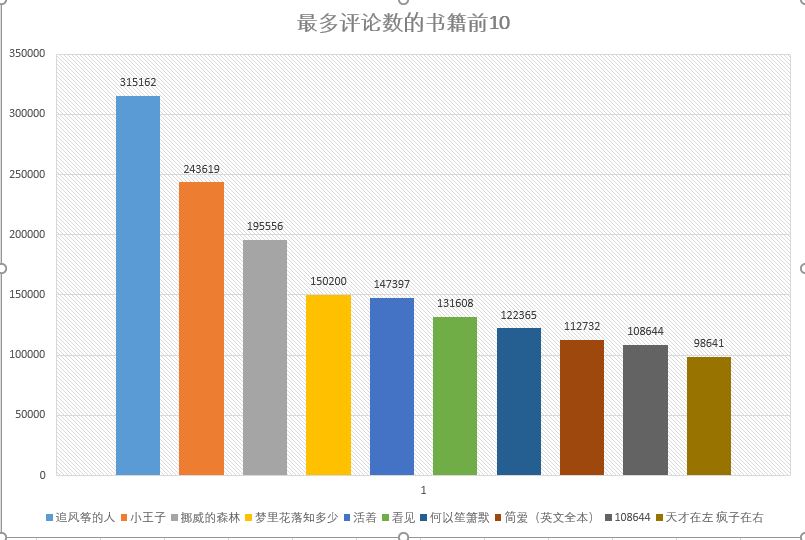
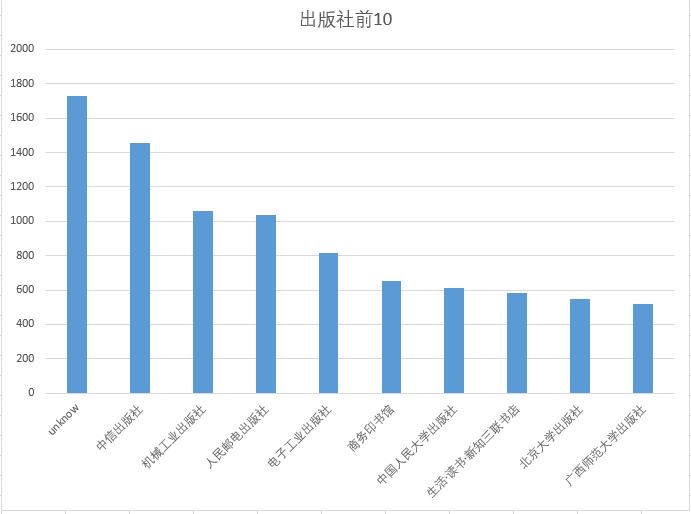
数据分析,使用excel进行简单数据分析