本文介绍了如何使用AML Workbench,利用预训练的深度学习模型(Keras H5 model)在Azure上部署基于Docker/Kubernets集群的RESTful API服务,包括API封装,Docker Image生成,环境配置和部署。
请确保能满足如下条件并安装相应软件:
- Azure 订阅
- 熟悉Azure、Linxu等基本操作
- 熟悉Python
- 需要安装AML Workbench(Windows 10),熟悉操作
- Visual Studio Code
在Azure中创建一台数据科学虚拟机DSVM,DSVM预先安装了用于数据科学的Python各类包和环境,此外Docker也预先配置完成。使用DSVM可以帮助我们迅速进入开发,免去配置环境这一步骤。
首先需要创建 Azure 机器学习服务帐户,请详细参阅,并按照说明执行对应操作。
打开AML Workbench,创建一个空的项目。AML Workbench将会为我们创建一些必须的文件。默认创建的文件目录如下:
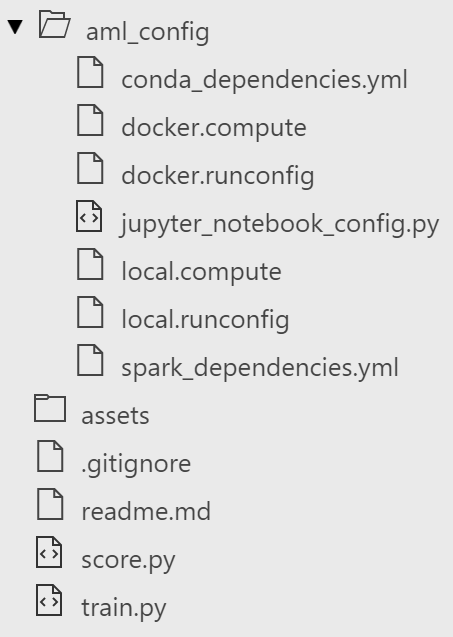
这里我们关注score.py文件,train.py可以用于训练自己的模型,这里使用预训练模型所以不需要此文件。
首先我们编辑score.py 文件。
Score.py文件中定义了run函数,run函数将会使用模型对输入进行预测,并输出结果。
准备好预先训练好的模型文件,对于keras框架,为.h5文件。这里使用myresnet.h5。如果模型文件大于25MB,需要在项目目录下新建outputs文件夹,将模型文件复制到此文件夹下。这是因为AML Workbench不支持大于25MB的项目目录。
转到score.py文件的init()函数,将代码更改为:
def init():
global model
model = load_model('outputs/myresnet.h5')方法之前需要导入相应包中的载入模型方法:
from keras.models import load_model下面编写测试函数,测试函数中使用测试图片,然后将图片转成Base64编码的字符串作为参数(注:AML Workbench生成的API只能接受JSON作为http请求的body,所以不能直接向api传送二进制图片数据)放到了pandas的DataFrame中传给run进行预测。
此外,这里还生成了一个service_schema的JSON文件,这个文件描述了API接口接受的JSON输入格式,并提供了一个输入样例(样例就是下面测试代码所用的输入)。
样例输入代码:
if __name__ == '__main__':
import pandas
base64ImgString = image_to_base64('elephant.jpg')
# Call init() and run() function
#print(base64ImgString)
init()
df = pandas.DataFrame(data=[[base64ImgString]], columns=['image base64 string'])
inputs = {"input_df": SampleDefinition(DataTypes.PANDAS, df)}
resultString = run(df)
print("resultString = " + str(resultString))
# Genereate the schema
generate_schema(run_func=run, inputs=inputs, filepath='service_schema.json')
print("Schema generated.")service_schema文件内容:
{"input": {"input_df": {"internal": "gANjYXp1cmVtbC5hcGkuc2NoZW1hLnBhbmRhc1V0aWwKUGFuZGFzU2NoZW1hCnEAKYFxAX1xAihYDAAAAGNvbHVtbl90eXBlc3EDXXEEY251bXB5CmR0eXBlCnEFWAIAAABPOHEGSwBLAYdxB1JxCChLA1gBAAAAfHEJTk5OSv////9K/////0s/dHEKYmFYCgAAAHNjaGVtYV9tYXBxC31xDFgTAAAAaW1hZ2UgYmFzZTY0IHN0cmluZ3ENaAhzWAwAAABjb2x1bW5fbmFtZXNxDl1xD2gNYVgFAAAAc2hhcGVxEEsBSwGGcRF1Yi4=", "type": 3, "swagger": {"example": [{"image base64 string": "b'略去冗长的base64字符串'"}], "type": "array", "items": {"type": "object", "properties": {"image base64 string": {"type": "object"}}}}}}}样例输入代码中run方法为API将会实际使用的预测方法,代码执行了从编码图片的Base64字符串到图片文件的转换,转换完成后调用模型进行预测,并将模型预测结果置信度最高的前三项包装成JSON字符串返回给调用者。
def run:
import json
# Predict using appropriate functions
# prediction = model.predict(input_df)
base64ImgString = input_df['image base64 string'][0]
#print(base64ImgString)
pil_img = base64_to_image(base64ImgString)
#print("pil_img.size: " + str(pil_img.size))
pil_img.save(imgPath, "JPEG")
print("Save pil_img to: " + imgPath)
img = image.load_img(imgPath, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
result=decode_predictions(preds, top=3)[0]
resultdict={}
if len(result)>0:
resultdict[result[0][1]]=float(result[0][2])
if len(result)>1:
resultdict[result[1][1]]=float(result[1][2])
if len(result)>2:
resultdict[result[2][1]]=float(result[2][2])
else:
resultdict['null']='0'
return json.dumps(resultdict)下面给出完整score.py文件作为参考。
# This script generates the scoring and schema files
# necessary to operationalize your model
from azureml.api.schema.dataTypes import DataTypes
from azureml.api.schema.sampleDefinition import SampleDefinition
from azureml.api.realtime.services import generate_schema
from azureml.assets import get_local_path
#from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
from keras.models import load_model
import base64
from PIL import Image
from io import BytesIO
import re
# Prepare the web service definition by authoring
# init() and run() functions. Test the functions
# before deploying the web service.
imgPath = "uploadedImg.jpg"
model = None
def base64_to_image(base64_str, image_path=None):
#base64_data = re.sub('^data:image/.+;base64,', '', base64_str)
byte_data = base64.b64decode(base64_str)
image_data = BytesIO(byte_data)
img = Image.open(image_data)
if image_path:
img.save(image_path)
return img
def image_to_base64(image_path):
img = Image.open(image_path)
output_buffer = BytesIO()
img.save(output_buffer, format='JPEG')
byte_data = output_buffer.getvalue()
base64_str = base64.b64encode(byte_data)
return base64_str
def init():
# Get the path to the model asset
# local_path = get_local_path('mymodel.model.link')
# Load model using appropriate library and function
global model
# model = model_load_function(local_path)
model = load_model('myresnet.h5')
#model = ResNet50(weights='imagenet')
def run(input_df):
import json
# Predict using appropriate functions
# prediction = model.predict(input_df)
base64ImgString = input_df['image base64 string'][0]
#print(base64ImgString)
pil_img = base64_to_image(base64ImgString)
#print("pil_img.size: " + str(pil_img.size))
pil_img.save(imgPath, "JPEG")
print("Save pil_img to: " + imgPath)
img = image.load_img(imgPath, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
result=decode_predictions(preds, top=3)[0]
resultdict={}
if len(result)>0:
resultdict[result[0][1]]=float(result[0][2])
if len(result)>1:
resultdict[result[1][1]]=float(result[1][2])
if len(result)>2:
resultdict[result[2][1]]=float(result[2][2])
else:
resultdict['null']='0'
return json.dumps(resultdict)
# Implement test code to run in IDE or Azure ML Workbench
if __name__ == '__main__':
# Import the logger only for Workbench runs
from azureml.logging import get_azureml_logger
import pandas
logger = get_azureml_logger(
base64ImgString = image_to_base64('elephant.jpg') #random 5x5 pixels image
# Call init() and run() function
init()
df = pandas.DataFrame(data=[[base64ImgString]], columns=['image base64 string'])
inputs = {"input_df": SampleDefinition(DataTypes.PANDAS, df)}
resultString = run(df)
print("resultString = " + str(resultString))
# Genereate the schema
generate_schema(run_func=run, inputs=inputs, filepath='service_schema.json')
print("Schema generated.")
logger.log("Result",resultString)conda_dependencies.yml文件中需要配置Docker需要的Conda环境,这里只需要加入项目实际用到的包即可。
对于此文件的详细编写方法,请参阅 manage-environments 。
name: project_environment
dependencies:
# The python interpreter version.
# Currently Azure ML Workbench only supports 3.5.2.
- python=3.5.2
- keras=2.1.5
# Required for Jupyter Notebooks.
- ipykernel=4.6.1
- pip:
# Required packages for AzureML execution, history, and data preparation.
- --index-url https://azuremldownloads.azureedge.net/python-repository/preview
- --extra-index-url https://pypi.python.org/simple
- azureml-requirements
- pillow
- pandas
# The API for Azure Machine Learning Model Management Service.
# Details: https://github.com/Azure/Machine-Learning-Operationalization
- azure-ml-api-sdk==0.1.0a10
如果安装了AML Workbench的计算机安装了Dockers环境可以在本地计算机中执行下面的命令,如果要在DSVM中部署一个Docker镜像,需要在DSVM中执行相应命令。命令需要Azure Cli环境,AML Workbench和DSVM已经预先安装了该环境。
步骤1.在命令行中登录Azure, 在AML Workbench中打开命令行,输入如下命令。根据提示,打开相应网页,输入生成的密钥即可登录。登录后将输出订阅信息。
az login
步骤2.注册环境提供程序。依次执行如下命令,可依据输出提示查看进度,设置完成需要约1-3分钟世界。
az provider register -n Microsoft.MachineLearningCompute
az provider register -n Microsoft.ContainerRegistry
az provider register -n Microsoft.ContainerService
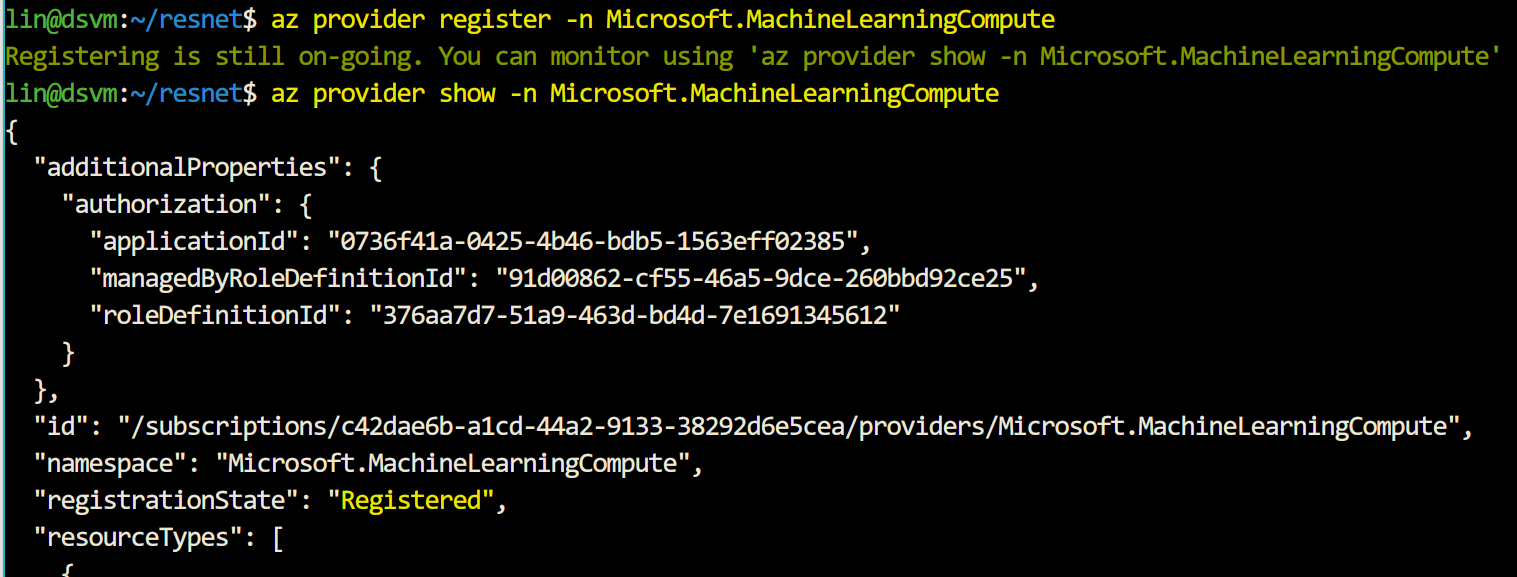
上图显示了执行第一行命令并查询进度的结果,当registrationState字段显示为Registered后可执行后续操作。后两条命令类似。
步骤3.设置本地环境。此步骤需要本地计算机安装Dockers,命令完成将花费约5分钟时间,可依据输出提示查看命令进度。
az ml env setup -l [Azure Region, e.g. eastus2] -n [your environment name] [-g [existing resource group]]
查看进度命令:
az ml env show -n <deployment environment name> -g <existing resource group name>
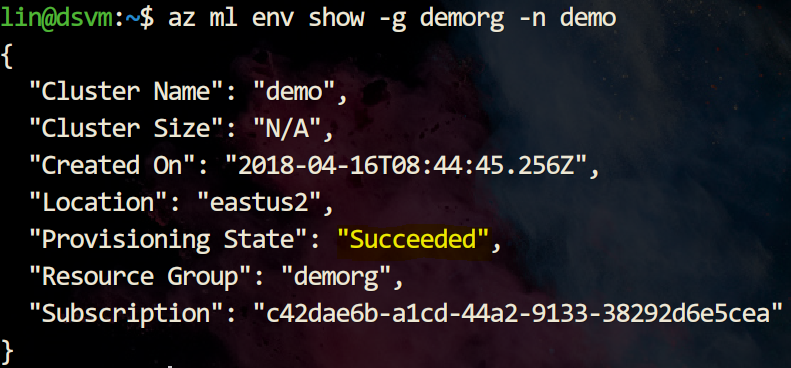
在此命令中,请确保“Provisioning State”的值为“Succeeded”后即可执行后续步骤
本地环境安装命令在订阅中创建以下资源:
- 资源组(如果未提供,或者如果提供的名称不存在)
- 存储帐户
- Azure 容器注册表 (ACR)
- Application Insights 帐户
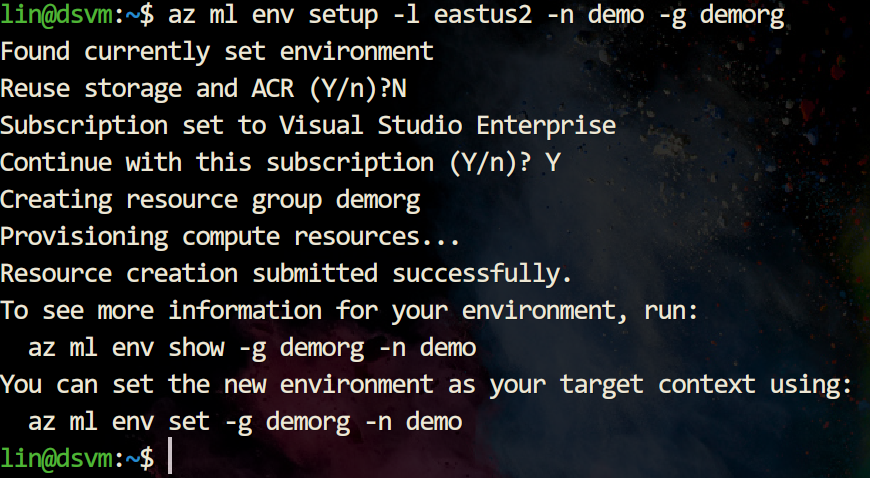
下图显示正在创建中:
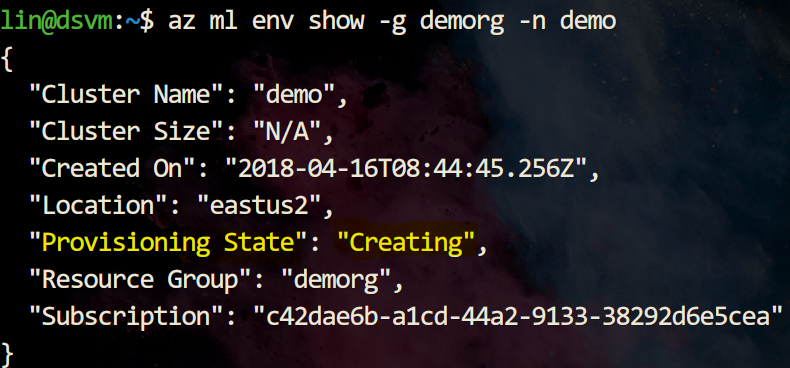
下图显示创建成功:
步骤4.创建模型管理帐户,随后设置模型管理帐户。
az ml account modelmanagement create --location <e.g. eastus2> -n <new model management account name> -g <existing resource group name> --sku-name S1
az ml account modelmanagement set -n <youracctname> -g <yourresourcegroupname>
步骤5.设置成功完成以后,使用以下命令设置要使用的环境,所用参数参照步骤3中的命令。
az ml env set -n [environment name] -g [resource group]
步骤6.创建实时 Web 服务。
准备好前文提到的score.py,预训练的模型文件myresnet.h5以及service_schema.json和conda_dependenies.yml。其中服务名称,也是新的 Docker 映像名称,必须全部小写,否则会出错。此步骤需要几分钟时间创建Docker镜像。
az ml service create realtime -f score.py --model-file outputs\myresnet.h5 -s service_schema.json -n demo -r python --collect-model-data true -c aml_config\conda_dependencies.yml
请注意,如果是在DSVM中创建,请将所需文件上传的DSVM中,在上述命令中修改文件路径即可。
此命令生成稍后可用的 Web 服务 ID。
可将以下开关与 az ml service create realtime 命令结合使用:
-f:评分脚本文件名。--model-file:模型文件。 在此示例中,它是myresnet.h5文件。
-s:服务架构。 这是在前面的步骤中生成的,方法是在本地运行score.py脚本。-n:应用名称,必须全部采用小写形式。-r:模型的运行时。 在此示例中,它是 Python 模型。 有效的运行时为python和spark-py。--collect-model-data true:此开关启用数据收集功能。-c:在其中指定了其他包的 conda 依赖项文件的路径。
运行该命令时,模型和评分文件会上传到在设置环境过程中创建的存储帐户。 部署过程会生成包含模型、架构和评分文件的 Docker 映像,然后将其推送到 Azure 容器注册表:
<ACR_name>.azureacr.io/<imagename>:<version>
此命令会在本地将该映像提取到计算机,然后启动基于该映像的 Docker 容器。 如果环境是以群集模式配置的,则 Docker 容器会改为部署到 Azure 云服务 Kubernetes 群集中。
在部署过程中,会在本地计算机上创建 Web 服务的 HTTP REST 终结点。 几分钟后,该命令会完成并返回成功消息。 Web 服务已准备好运行!
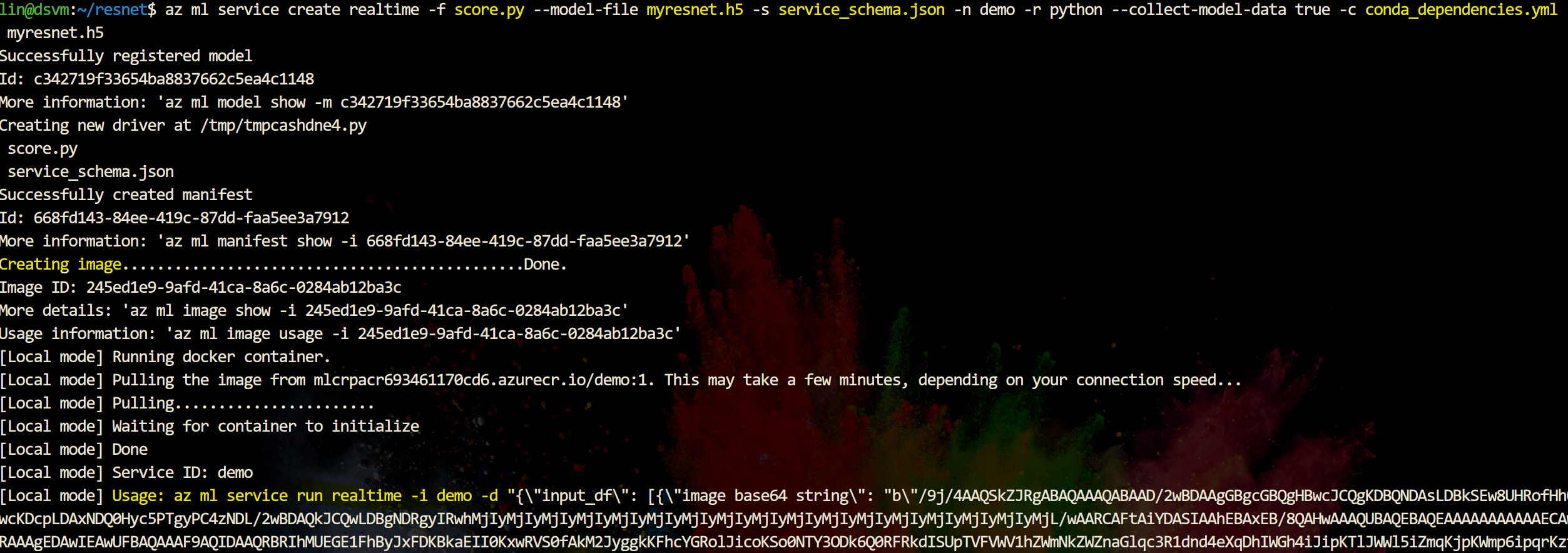
请注意此命令执行完成后的输出,上图创建成功以后会有一个用法提示,由于Base64字符串太长,请在控制台输出中仔细查看。
使用如下命令查看服务运行详情:
az ml service usage realtime -i demo

输出中包含了HTTP REST终结点,请记下此URL路径和端口,如果是在DSVM中创建Docker,请在Azure中开启此虚拟机的对应输入端口,否则将不能在外部访问。
若要查看正在运行的 Docker 容器,请使用 docker ps 命令。
docker ps

步骤7.测试API。
为方便测试,可以使用postman 发送POST请求。HTTP请求头中Content-Type为application/json。
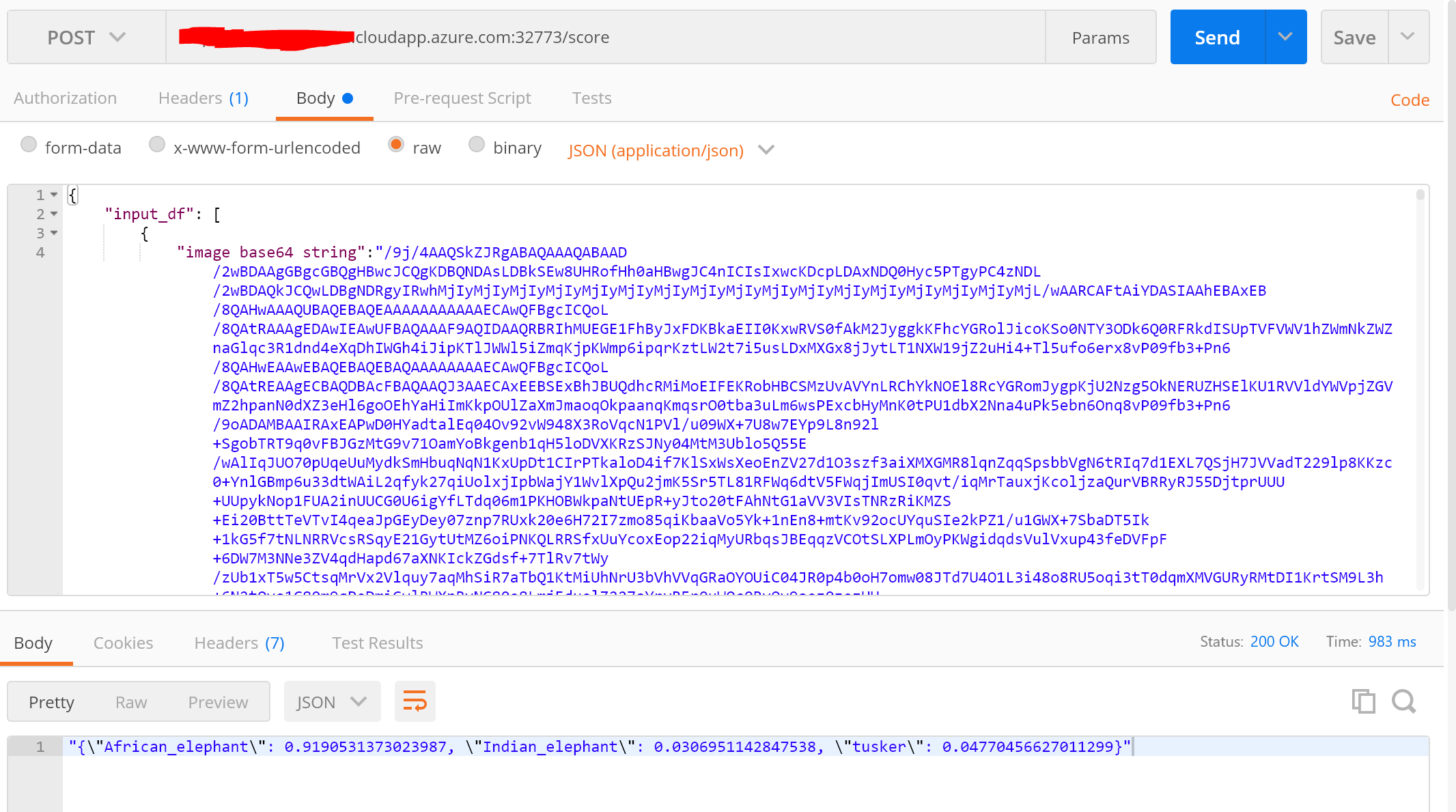
请求body如下:
{
"input_df": [
{
"image base64 string":"略去冗长的base64字符串"
}
]
}
测试结果如下:
至此,在Docker中创建API的任务完成,下面将使用集群发布API。
如果不再需要服务请在Azure中删除对应资源。
为了使API能够在应对大量请求能有良好性能,可以在集群中部署API。所需文件和第一部分完全相同,请先参阅第一部分内容。
步骤1.在命令行中登录Azure, 在AML Workbench中打开命令行,输入如下命令。根据提示,打开相应网页,输入生成的密钥即可登录。登录后将输出订阅信息。
az login
步骤2.注册环境提供程序。依次执行如下命令,可依据输出提示查看进度,设置完成需要约1-3分钟世界。
az provider register -n Microsoft.MachineLearningCompute
az provider register -n Microsoft.ContainerRegistry
步骤3.创建集群,此步骤可能耗费10-20分钟时间,have a cup of coffee。
az ml env setup --cluster -l southeastasia -n democluster -g democlusterrg
群集环境设置命令在订阅中创建以下资源:
- 资源组(如果未提供,或者如果提供的名称不存在)
- 存储帐户
- 一个 Azure 容器注册表 (ACR)
- Azure 容器服务 (ACS) 群集上的 Kubernetes 部署
- Application Insights 帐户
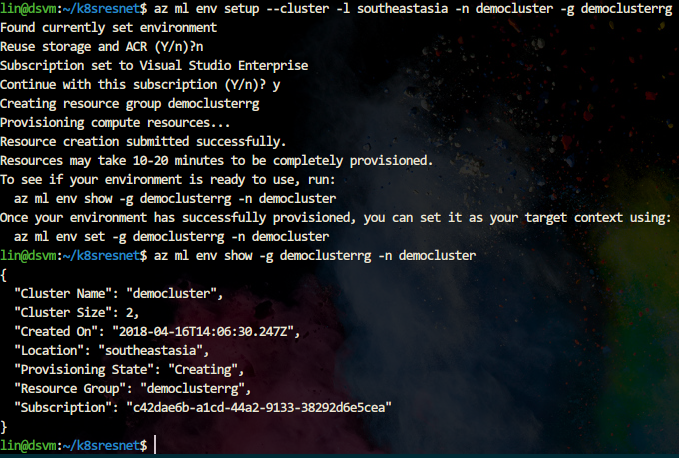
要检查当前正在进行的群集调配的状态,请使用以下命令:
az ml env show -n [environment name] -g [resource group]
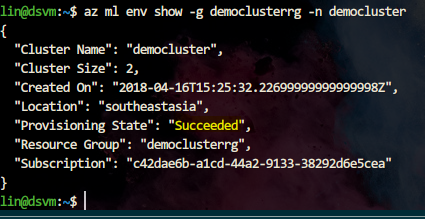
创建成功后进行下一步操作。
步骤4.创建模型管理帐户,随后设置模型管理帐户。
az ml account modelmanagement create --location <e.g. eastus2> -n <new model management account name> -g <existing resource group name> --sku-name S1
az ml account modelmanagement set -n <youracctname> -g <yourresourcegroupname>
步骤5.设置成功完成以后,使用以下命令设置要使用的环境,所用参数参照步骤3中的命令。
az ml env set -g democlusterrg -n democluster
步骤6.创建实时 Web 服务。
az ml service create realtime -f score.py --model-file myresnet.h5 -s service_schema.json -n democluster -r python -c conda_dependencies.yml
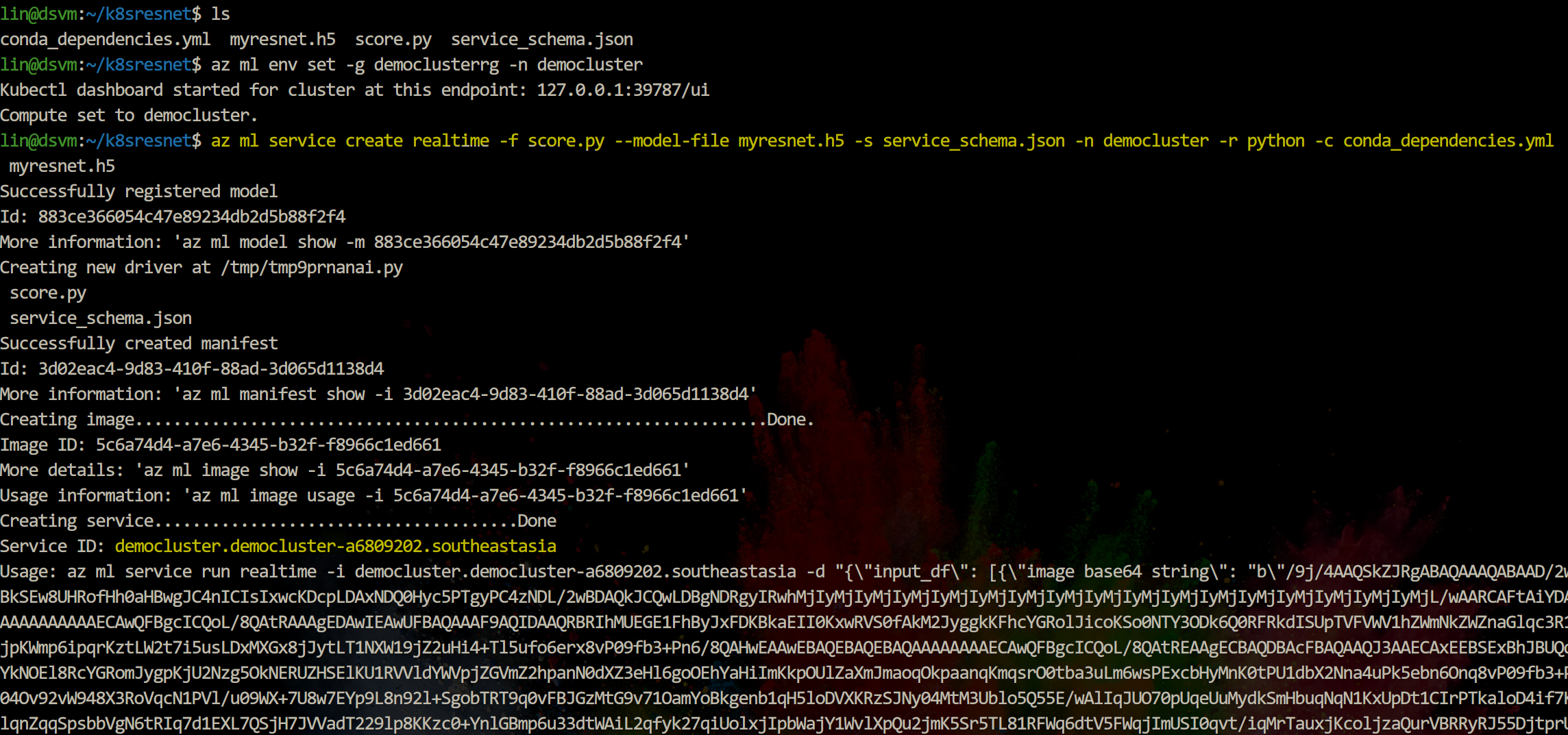
上一条命令输出的最后提示了一条命令来查看服务运行情况,执行这条命令。
az ml service usage realtime -i democluster.democluster-a6809202.southeastasia

上一条命令将输出一个API调用的实例,请注意命令靠前部分的输出,为了保护API,访问将需要一个service key,如何获取service key,将在输出中提示。因为输出中包含了一个输入例子,Base64字符串将会很长,请在命令行中仔细查看。
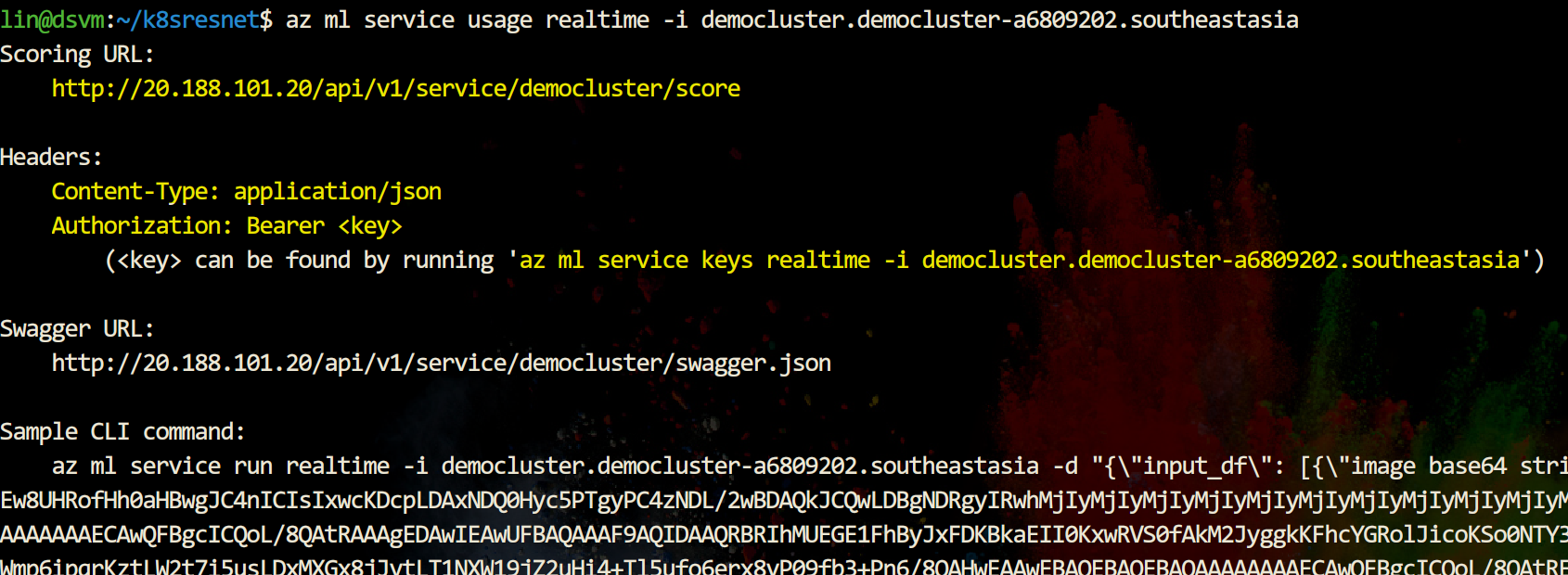
此处使用这条命令获取service key
az ml service keys realtime -i democluster.democluster-a6809202.southeastasia

请记录输出的两个Key,使用时取其任意一个即可。
步骤7.测试API
为方便测试,可以使用postman 发送POST请求。HTTP请求头中Content-Type为application/json。上一步获取的service key需要设置在HTTP请求头的Authorization字段中。
请求body同第一部分。
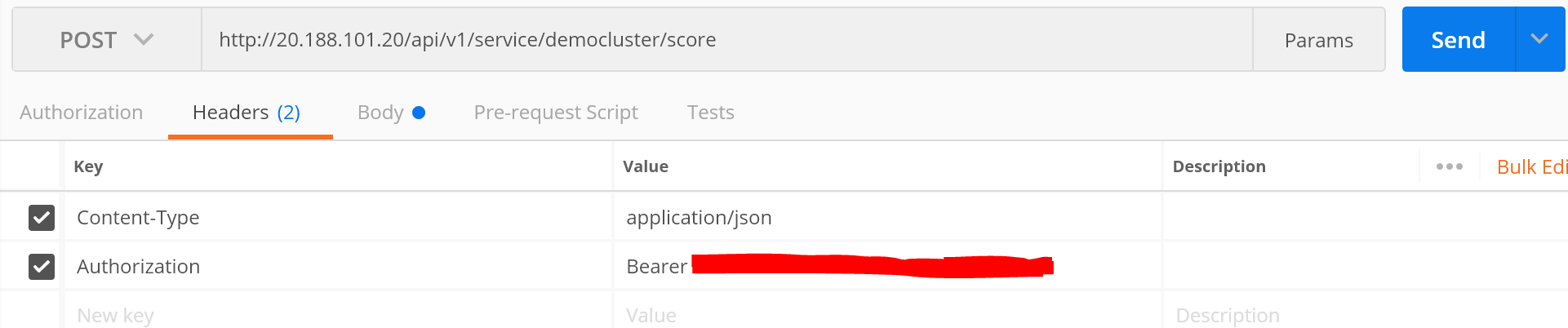
请注意上图中Authorization字段值的设置需要设置为'**Bearer **'+Key。
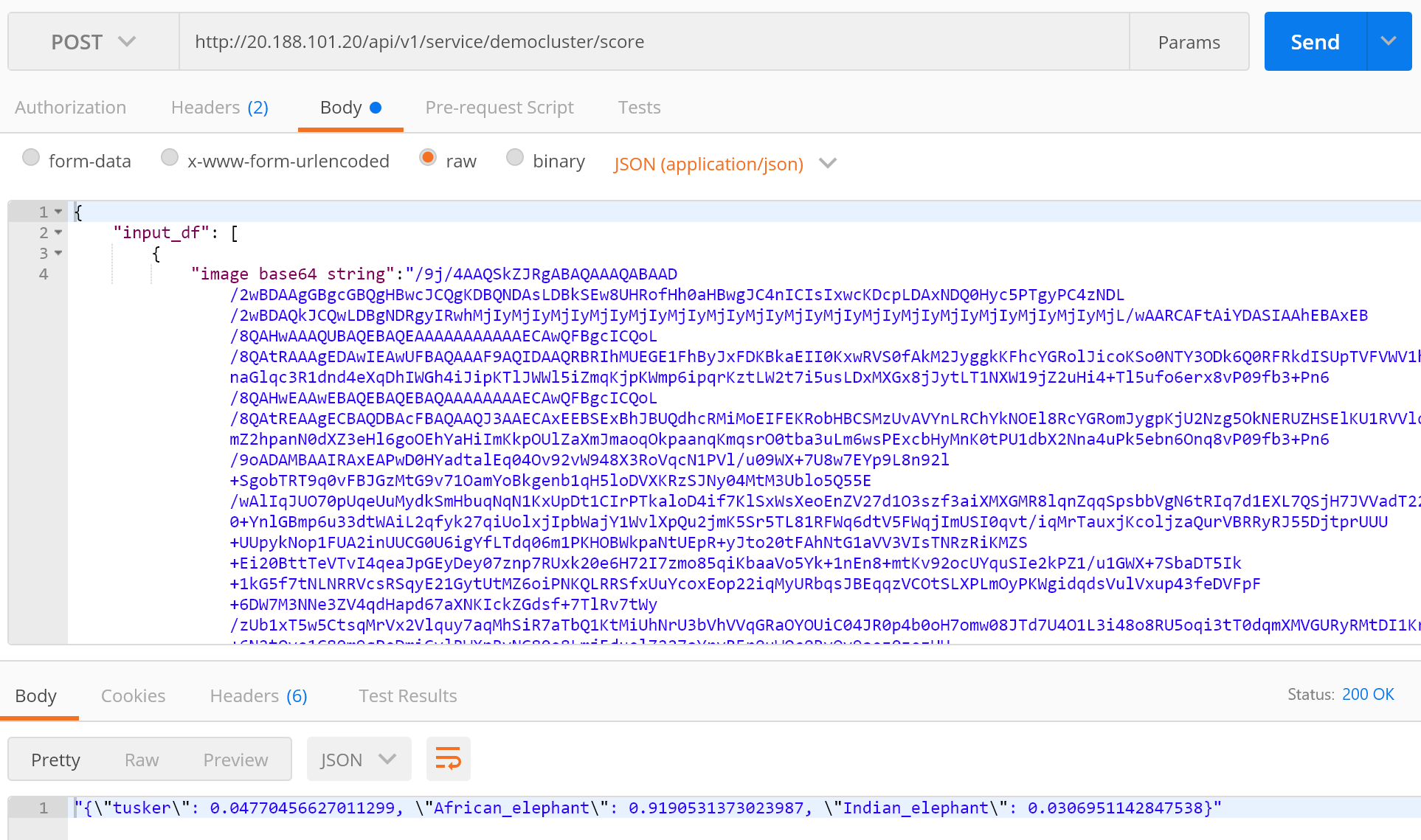
上图显示请求成功调用。
打开Azure门户,可以看到所创建的集群资源,如果不再需要请删除对应服务。
至此,在集群中创建API的任务完成,感谢阅读。