One API is an open-source API gateway that provides a unified interface for various AI models, allowing users to manage and utilize multiple AI services through a single platform. It supports token management, quota management, and usage statistics, making it easier for developers to integrate and manage different AI models in their applications.
With one-api, you can aggregate various AI APIs and request in ChatCompletion, Response, or Claude Messages API formats as needed.
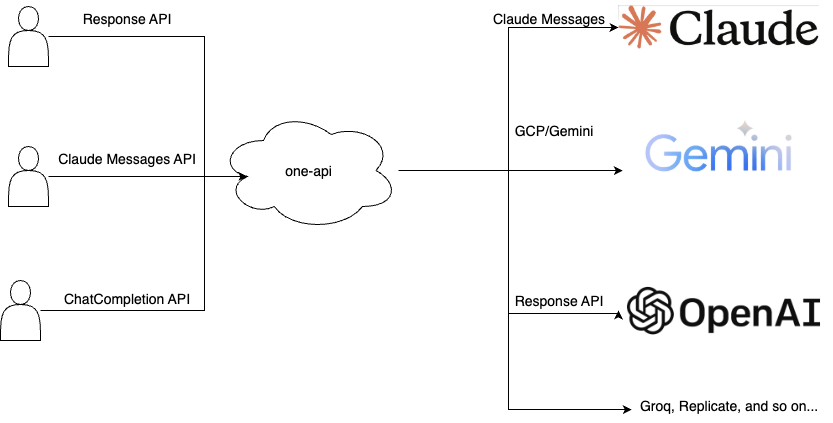
The original author of one-api has not been active for a long time, resulting in a backlog of PRs that cannot be updated. Therefore, I forked the code and merged some PRs that I consider important. I also welcome everyone to submit PRs, and I will respond and handle them actively and quickly.
Fully compatible with the upstream version, can be used directly by replacing the container image, docker images:
ppcelery/one-api:latestppcelery/one-api:arm64-latest
Also welcome to register and use my deployed one-api gateway, which supports various mainstream models. For usage instructions, please refer to https://wiki.laisky.com/projects/gpt/pay/cn/#page_gpt_pay_cn.
- One API
- Turtorial
- Contributors
- New Features
- Universal Features
- OpenAI Features
- (Merged) Support gpt-vision
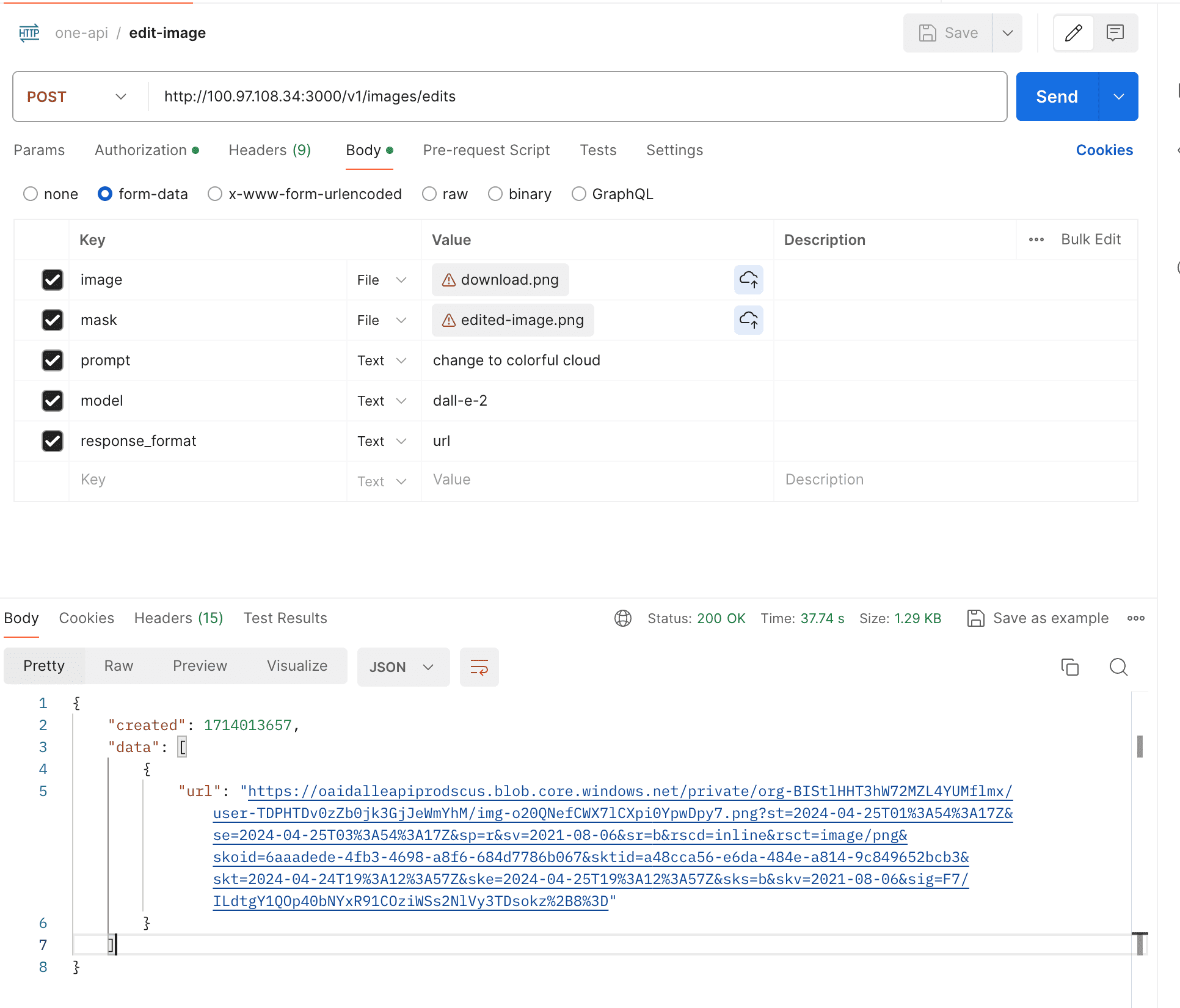
- Support openai images edits
- Support OpenAI o1/o1-mini/o1-preview
- Support gpt-4o-audio
- Support OpenAI web search models
- Support gpt-image-1's image generation & edits
- Support o3-mini
- Support o3 & o4-mini & gpt-4.1
- Support o3-pro & reasoning content
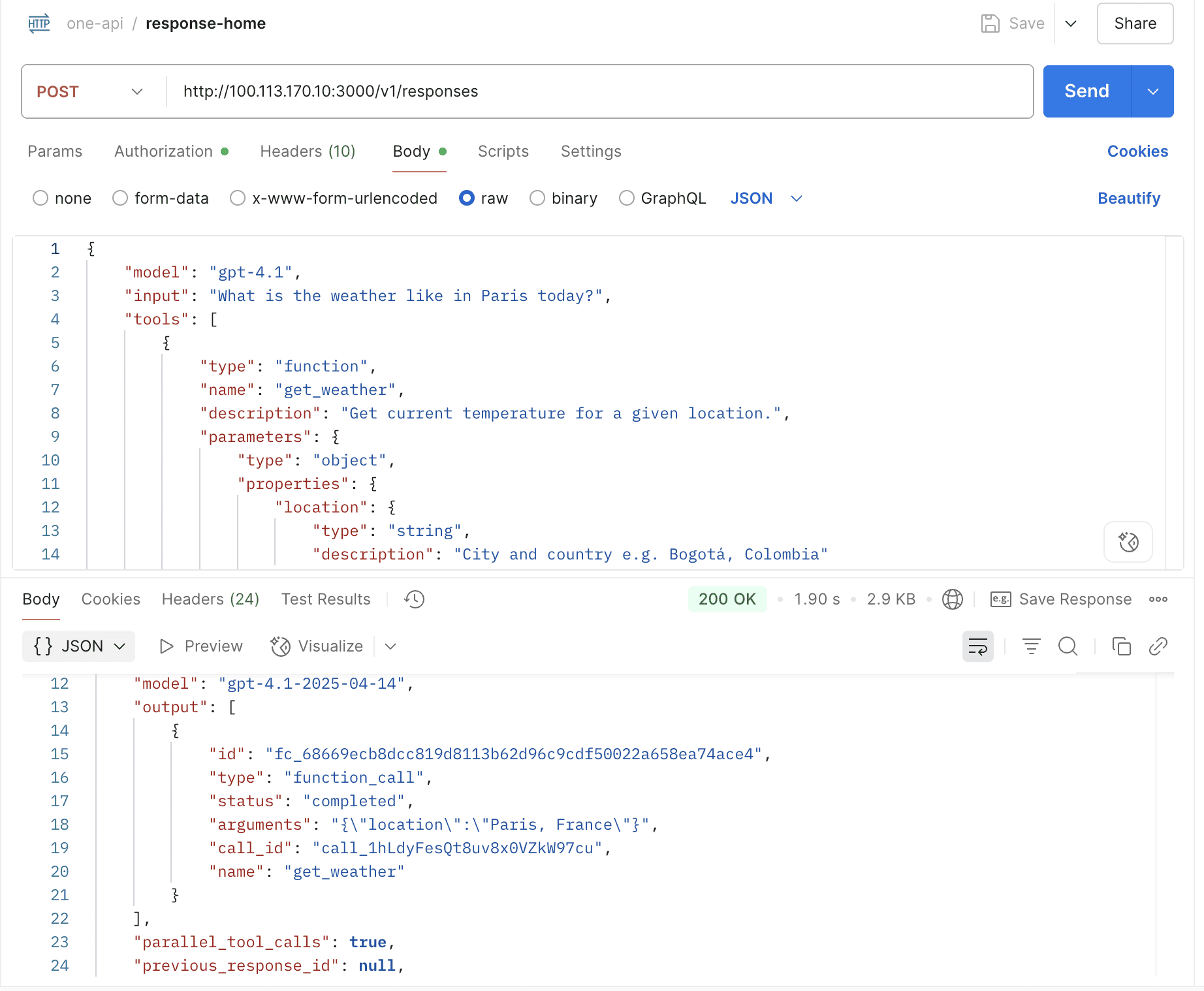
- Support OpenAI Response API
- Anthropic (Claude) Features
- Google (Gemini & Vertex) Features
- Support gemini-2.0-flash-exp
- Support gemini-2.0-flash
- Support gemini-2.0-flash-thinking-exp-01-21
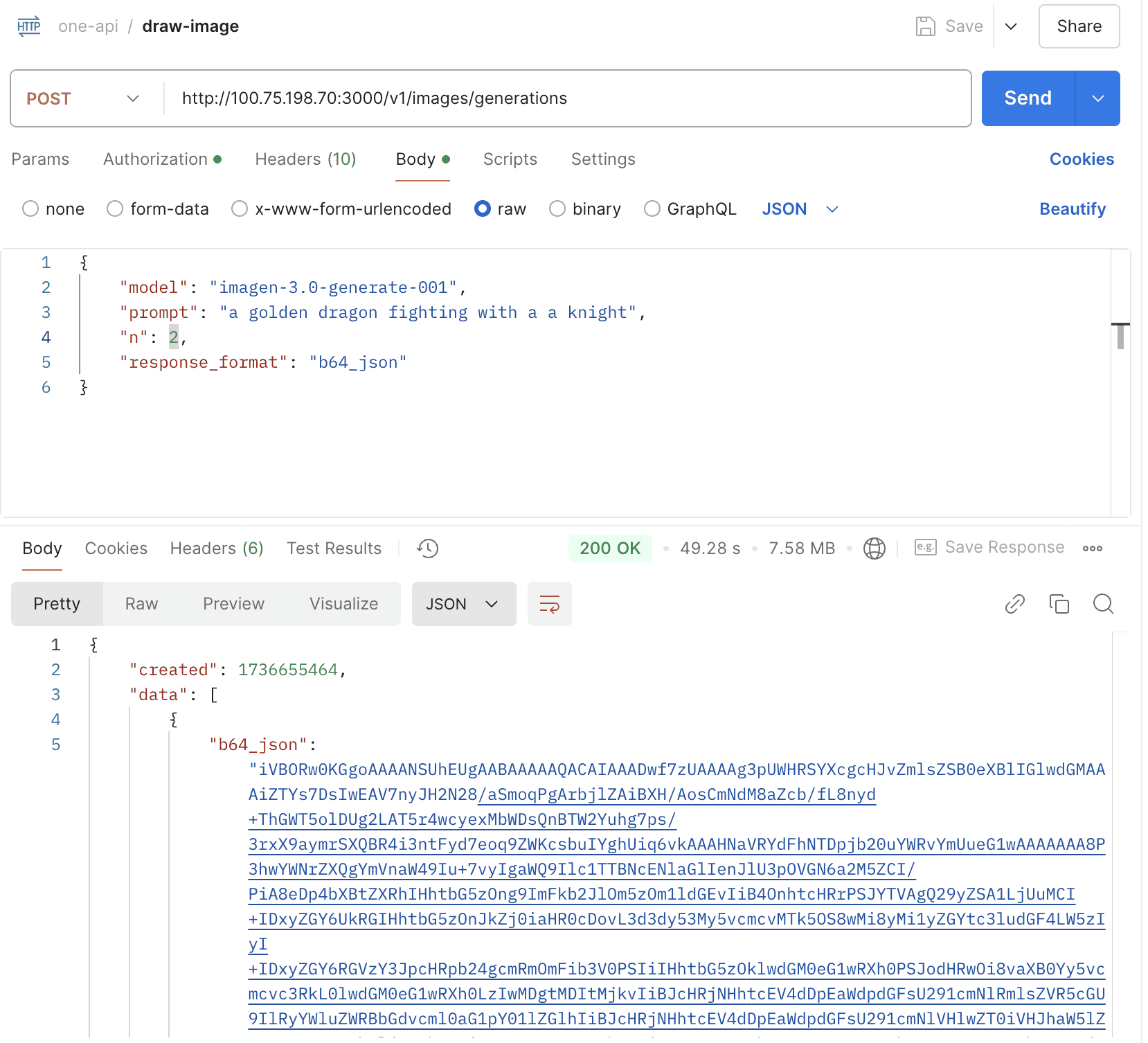
- Support Vertex Imagen3
- Support gemini multimodal output #2197
- Support gemini-2.5-pro
- Support GCP Vertex gloabl region and gemini-2.5-pro-preview-06-05
- Support gemini-2.5-flash-image-preview & imagen-4 series
- AWS Features
- Replicate Features
- DeepSeek Features
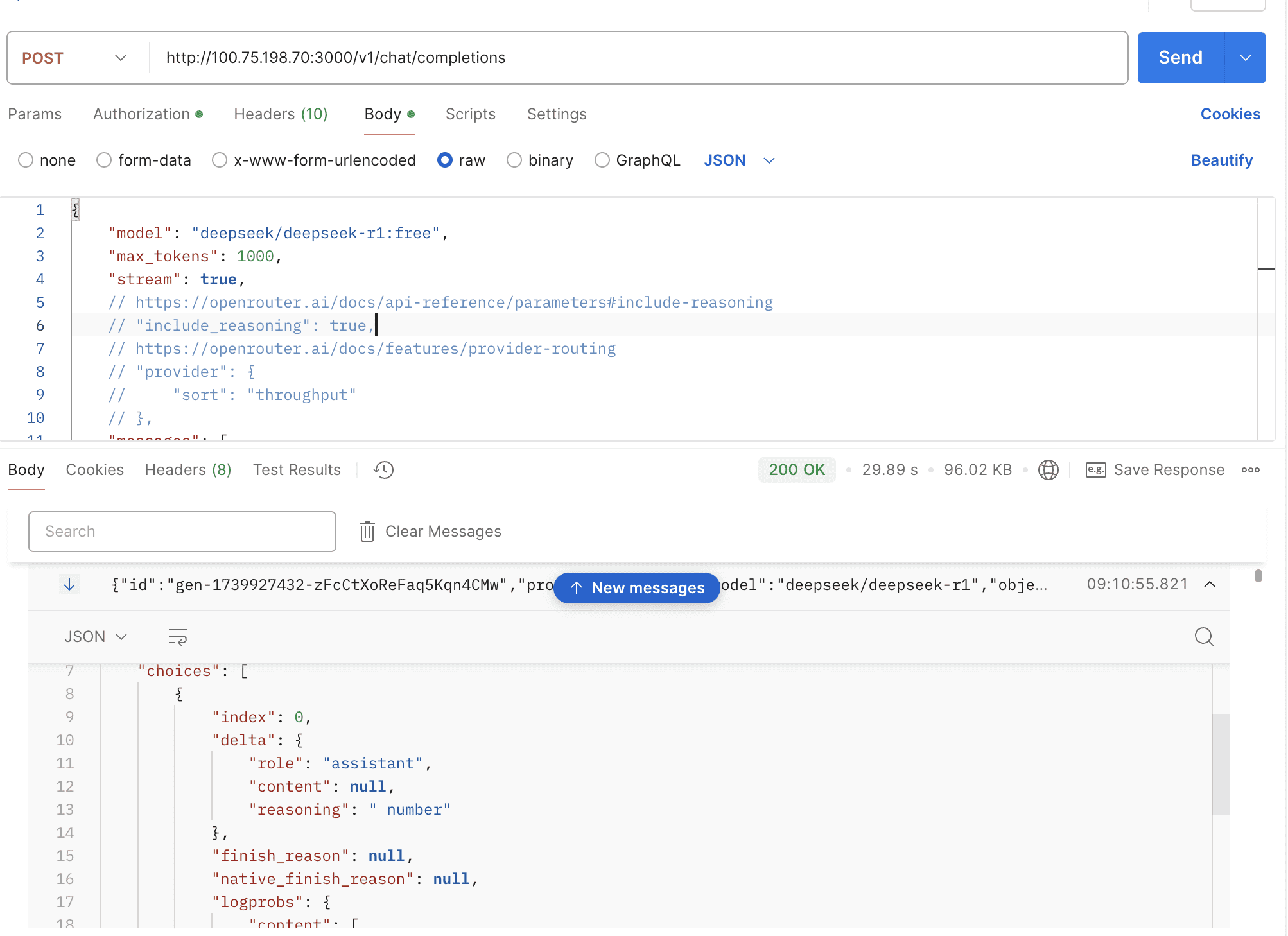
- OpenRouter Features
- Coze Features
- XAI / Grok Features
- Black Forest Labs Features
- Bug fix
Run one-api using docker-compose:
oneapi:
image: ppcelery/one-api:latest
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
environment:
# (optional) SESSION_SECRET set a fixed session secret so that user sessions won't be invalidated after server restart
SESSION_SECRET: xxxxxxx
# (optional) If you access one-api using a non-HTTPS address, you need to set DISABLE_COOKIE_SECURE to true
DISABLE_COOKIE_SECURE: "true"
# (optional) DEBUG enable debug mode
DEBUG: "true"
# (optional) DEBUG_SQL display SQL logs
DEBUG_SQL: "true"
# (optional) REDIS_CONN_STRING set REDIS cache connection
REDIS_CONN_STRING: redis://100.122.41.16:6379/1
# (optional) SQL_DSN set SQL database connection,
# default is sqlite3, support mysql, postgresql, sqlite3
SQL_DSN: "postgres://laisky:xxxxxxx@1.2.3.4/oneapi"
# (optional) ENFORCE_INCLUDE_USAGE require upstream API responses to include usage field
ENFORCE_INCLUDE_USAGE: "true"
# (optional) MAX_ITEMS_PER_PAGE maximum items per page, default is 10
MAX_ITEMS_PER_PAGE: 10
# (optional) GLOBAL_API_RATE_LIMIT maximum API requests per IP within three minutes, default is 1000
GLOBAL_API_RATE_LIMIT: 1000
# (optional) GLOBAL_WEB_RATE_LIMIT maximum web page requests per IP within three minutes, default is 1000
GLOBAL_WEB_RATE_LIMIT: 1000
# (optional) /v1 API ratelimit for each token
GLOBAL_RELAY_RATE_LIMIT: 1000
# (optional) Whether to ratelimit for channel, 0 is unlimited, 1 is to enable the ratelimit
GLOBAL_CHANNEL_RATE_LIMIT: 1
# (optional) FRONTEND_BASE_URL redirect page requests to specified address, server-side setting only
FRONTEND_BASE_URL: https://oneapi.laisky.com
# (optional) OPENROUTER_PROVIDER_SORT set sorting method for OpenRouter Providers, default is throughput
OPENROUTER_PROVIDER_SORT: throughput
# (optional) CHANNEL_SUSPEND_SECONDS_FOR_429 set the duration for channel suspension when receiving 429 error, default is 60 seconds
CHANNEL_SUSPEND_SECONDS_FOR_429: 60
# (optional) DEFAULT_MAX_TOKEN set the default maximum number of tokens for requests, default is 2048
DEFAULT_MAX_TOKEN: 2048
# (optional) MAX_INLINE_IMAGE_SIZE_MB set the maximum allowed image size (in MB) for inlining images as base64, default is 30
MAX_INLINE_IMAGE_SIZE_MB: 30
# (optional) LOG_PUSH_API set the API address for pushing error logs to telegram.
# More information about log push can be found at: https://github.com/Laisky/laisky-blog-graphql/tree/master/internal/web/telegram
LOG_PUSH_API: "https://gq.laisky.com/query/"
LOG_PUSH_TYPE: "oneapi"
LOG_PUSH_TOKEN: "xxxxxxx"
volumes:
- /var/lib/oneapi:/data
ports:
- 3000:3000The initial default account and password are root / 123456.
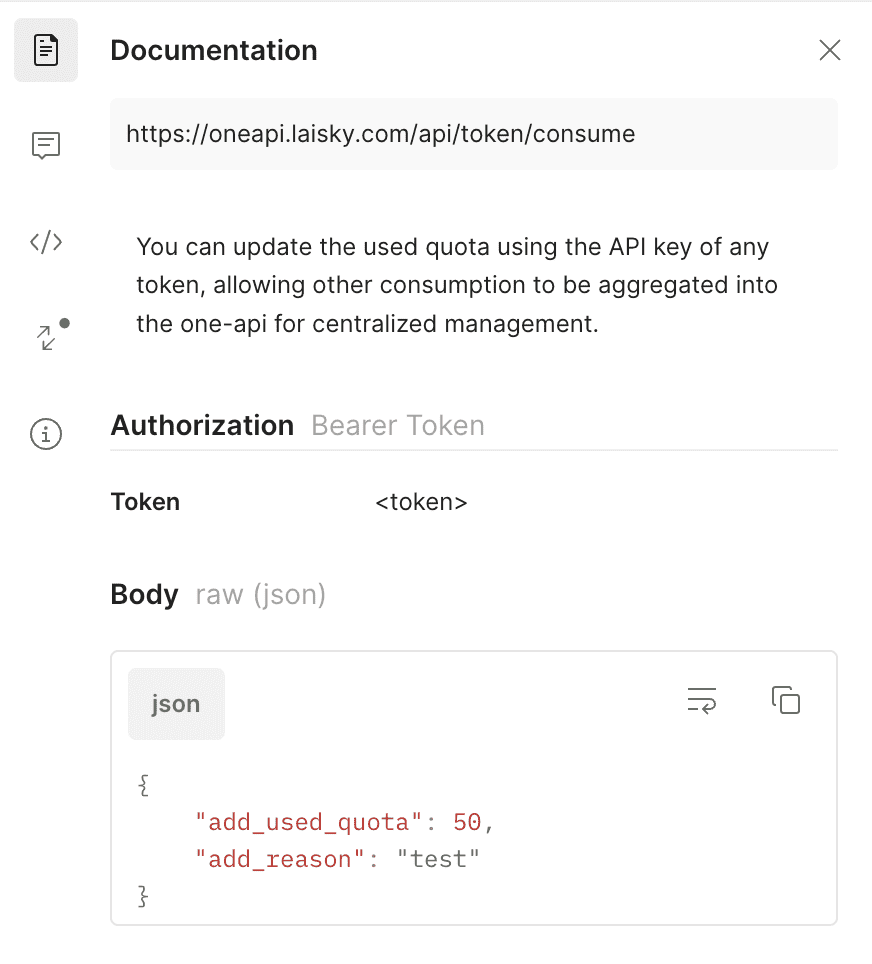
You can update the used quota using the API key of any token, allowing other consumption to be aggregated into the one-api for centralized management.
Each chat completion request will include a X-Oneapi-Request-Id in the returned headers. You can use this request id to request GET /api/cost/request/:request_id to get the cost of this request.
The returned structure is:
type UserRequestCost struct {
Id int `json:"id"`
CreatedTime int64 `json:"created_time" gorm:"bigint"`
UserID int `json:"user_id"`
RequestID string `json:"request_id"`
Quota int64 `json:"quota"`
CostUSD float64 `json:"cost_usd" gorm:"-"`
}
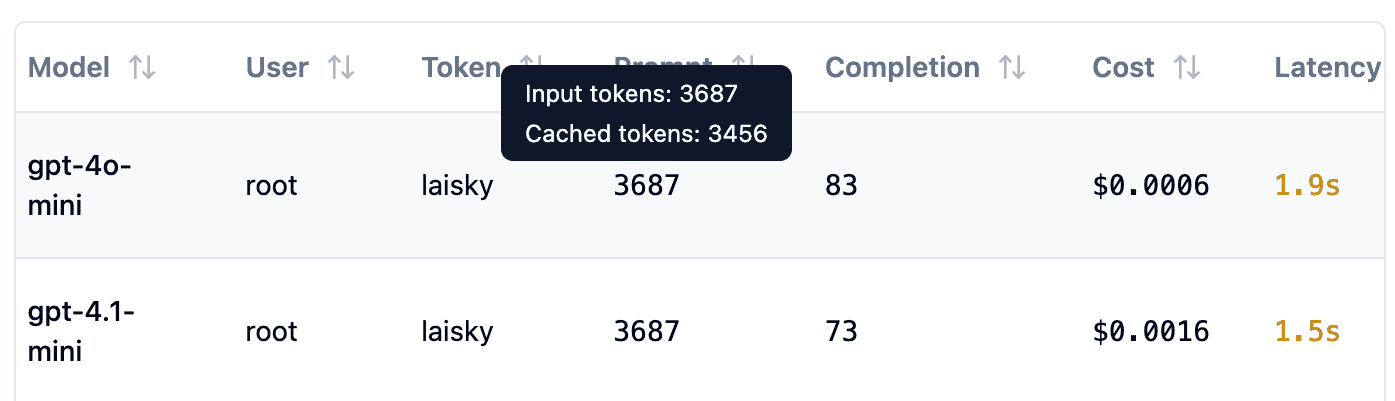
Now supports cached input, which can significantly reduce the cost.
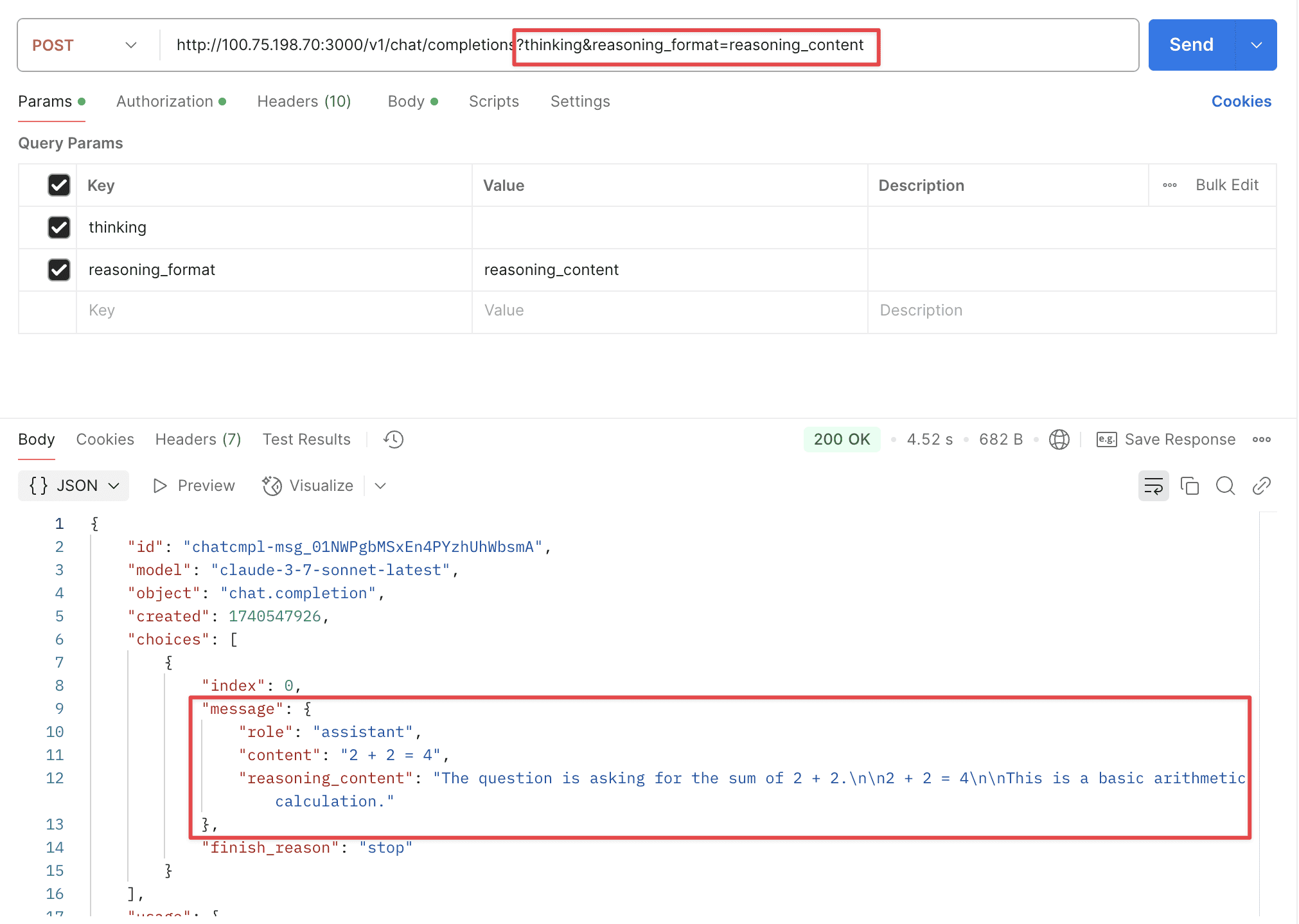
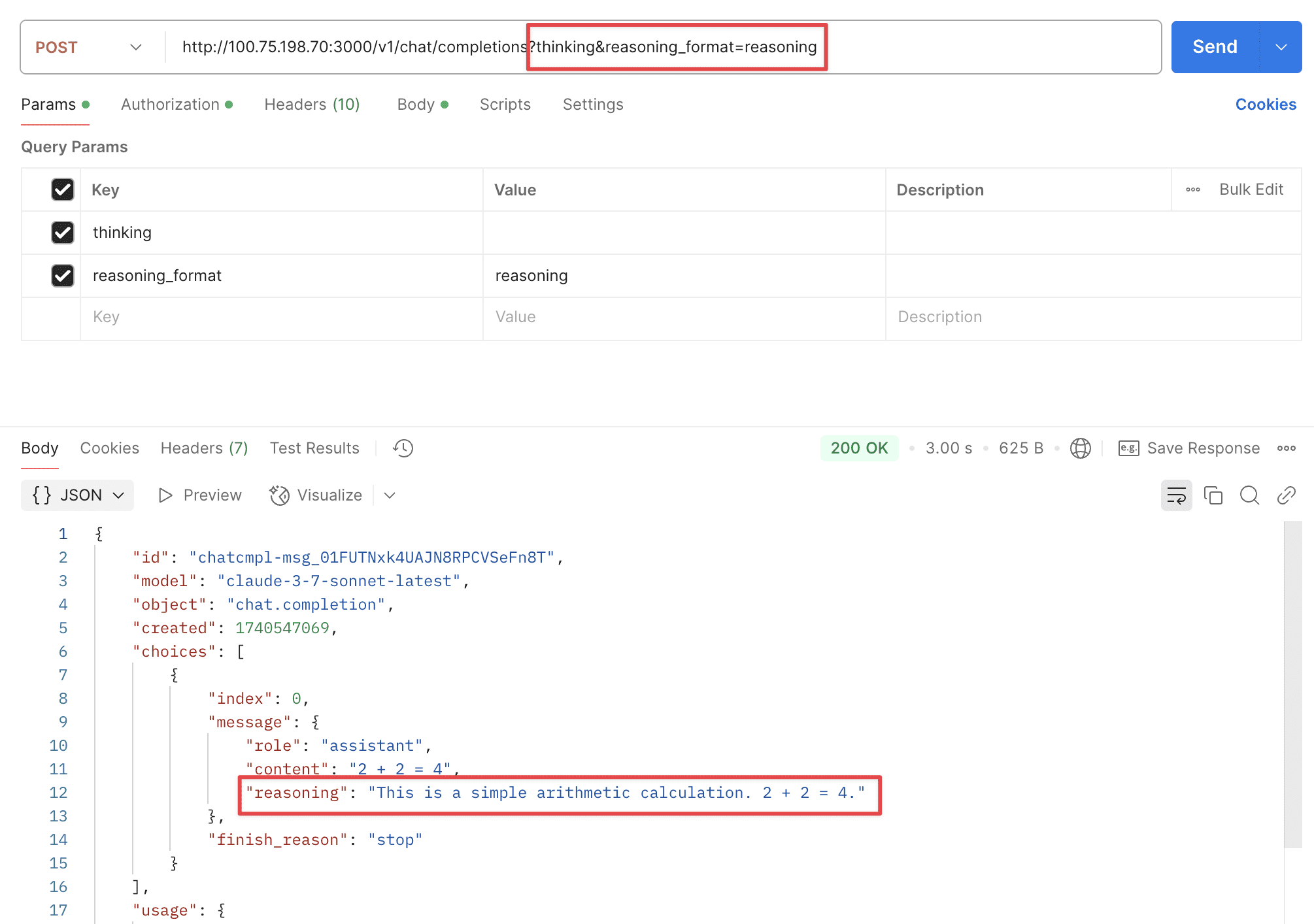
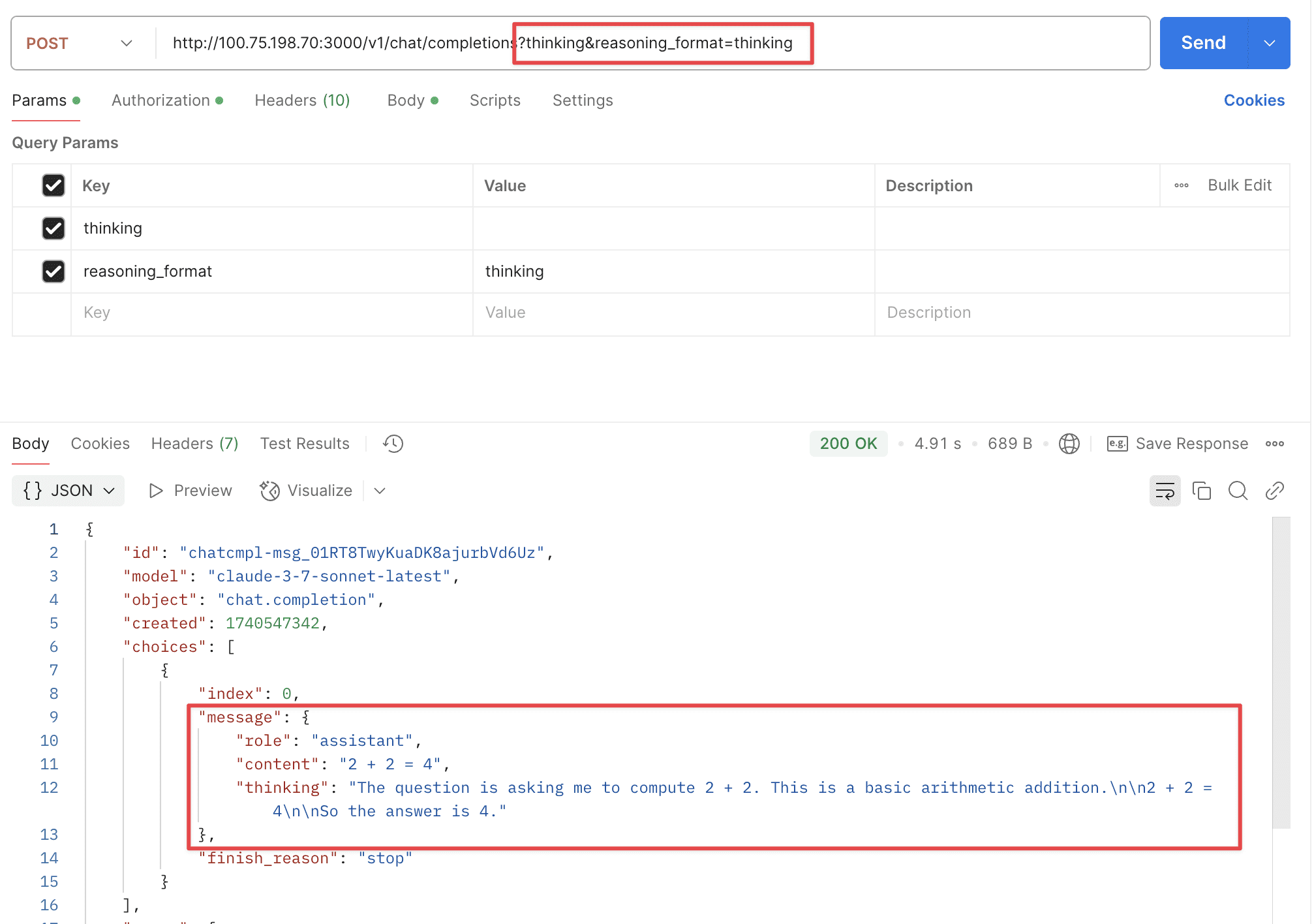
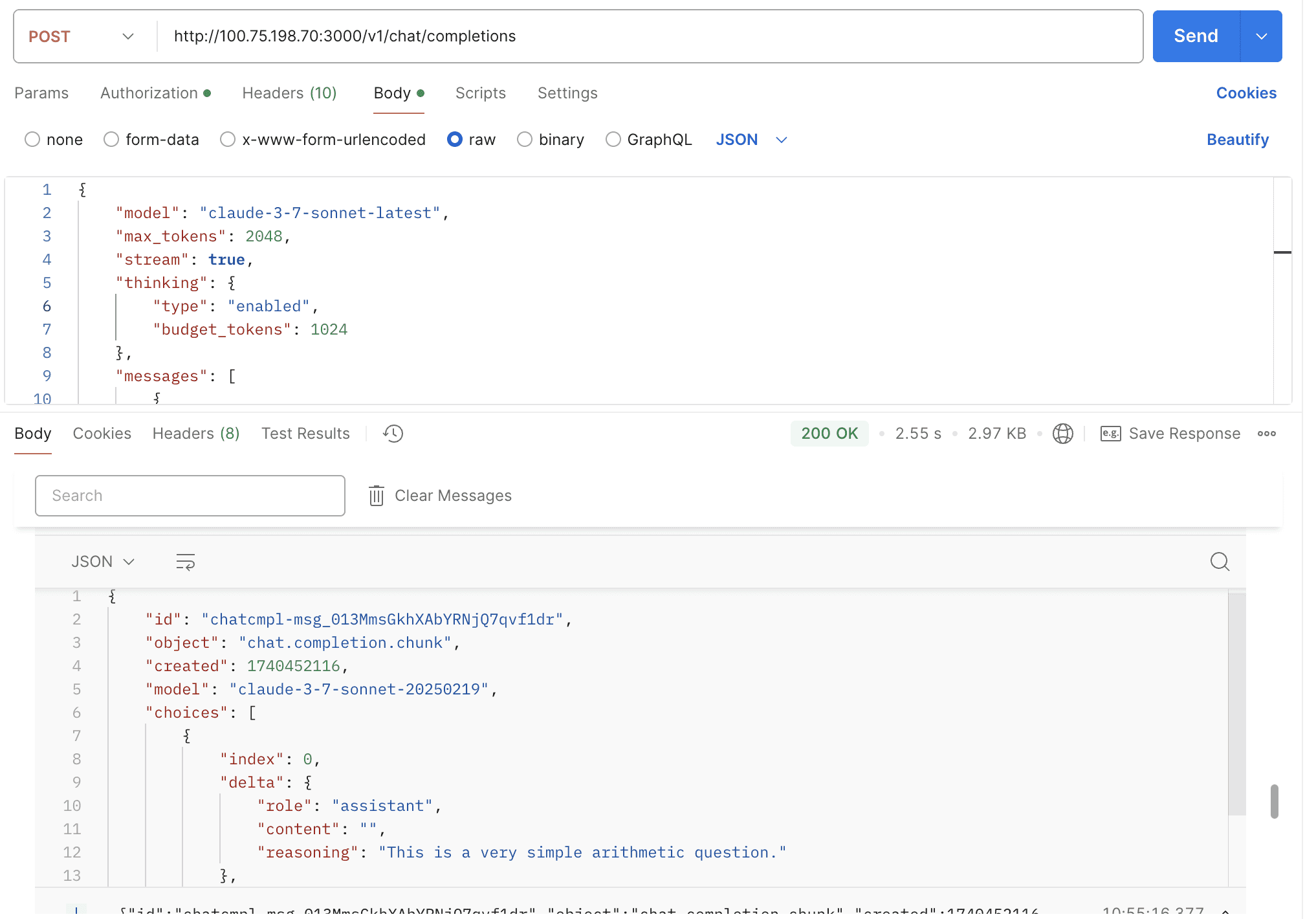
Supports two URL parameters: thinking and reasoning_format.
thinking: Whether to enable thinking mode, disabled by default.reasoning_format: Specifies the format of the returned reasoning.reasoning_content: DeepSeek official API format, returned in thereasoning_contentfield.reasoning: OpenRouter format, returned in thereasoningfield.thinking: Claude format, returned in thethinkingfield.
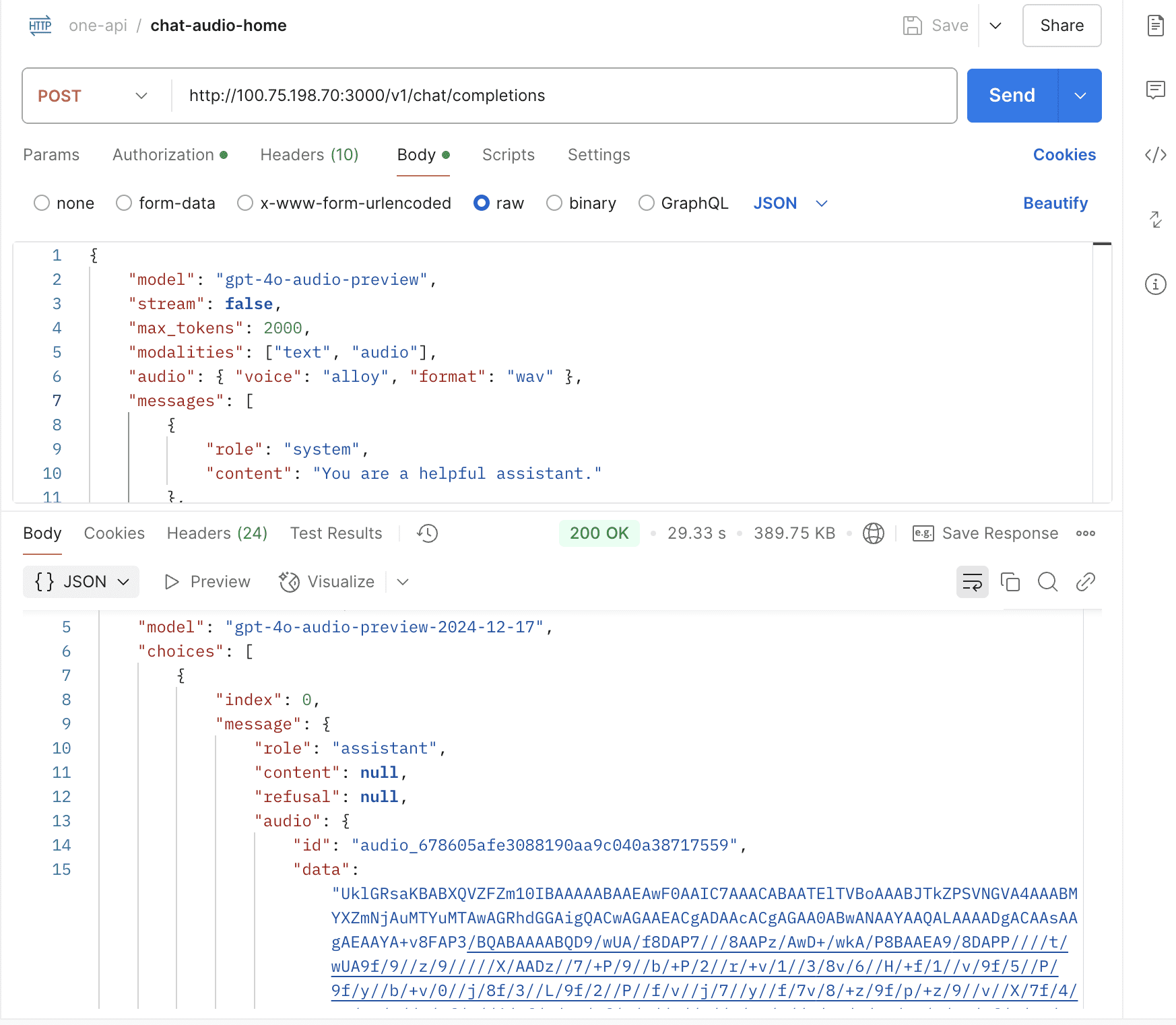

support gpt-4o-search-preview & gpt-4o-mini-search-preview


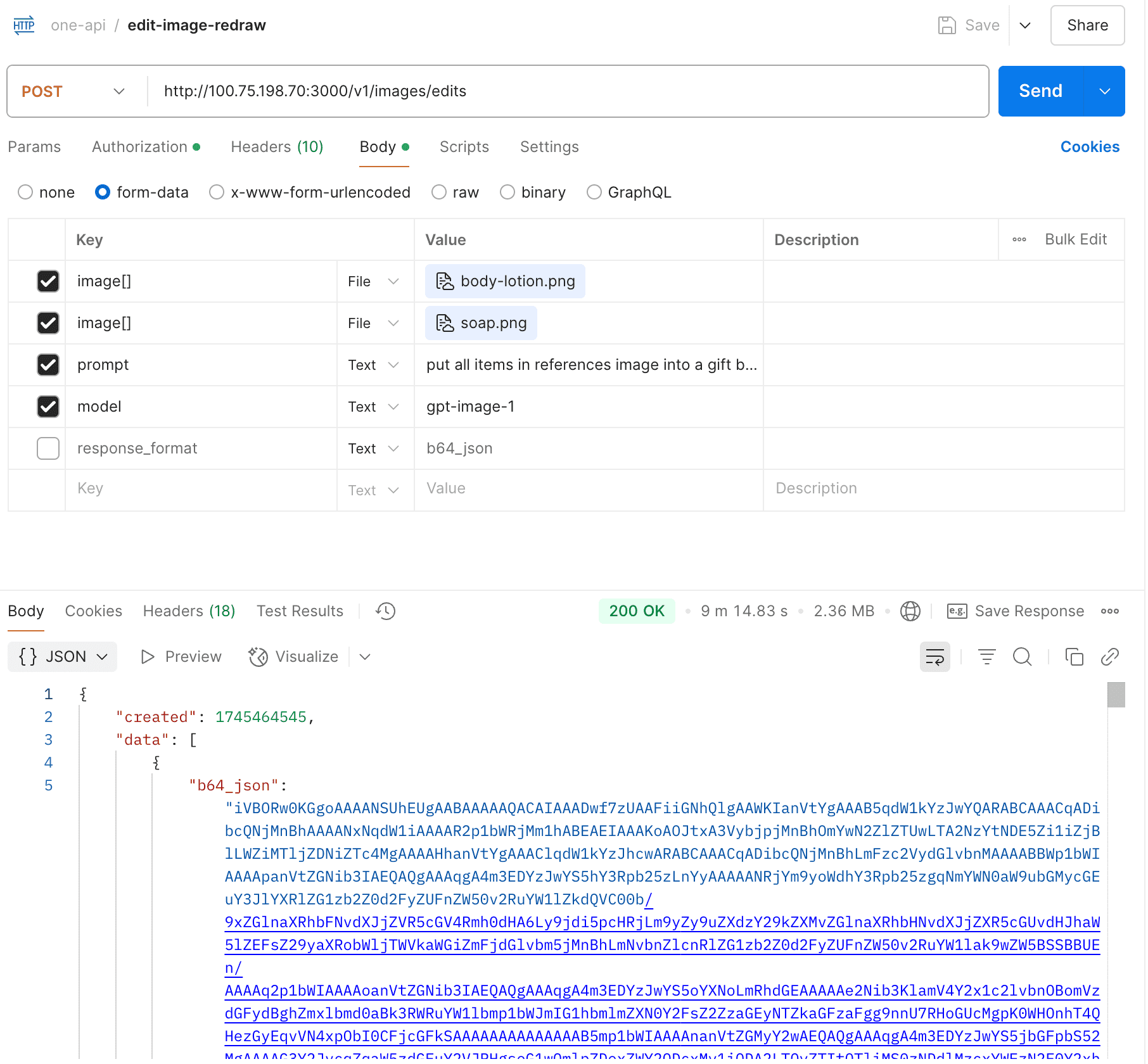
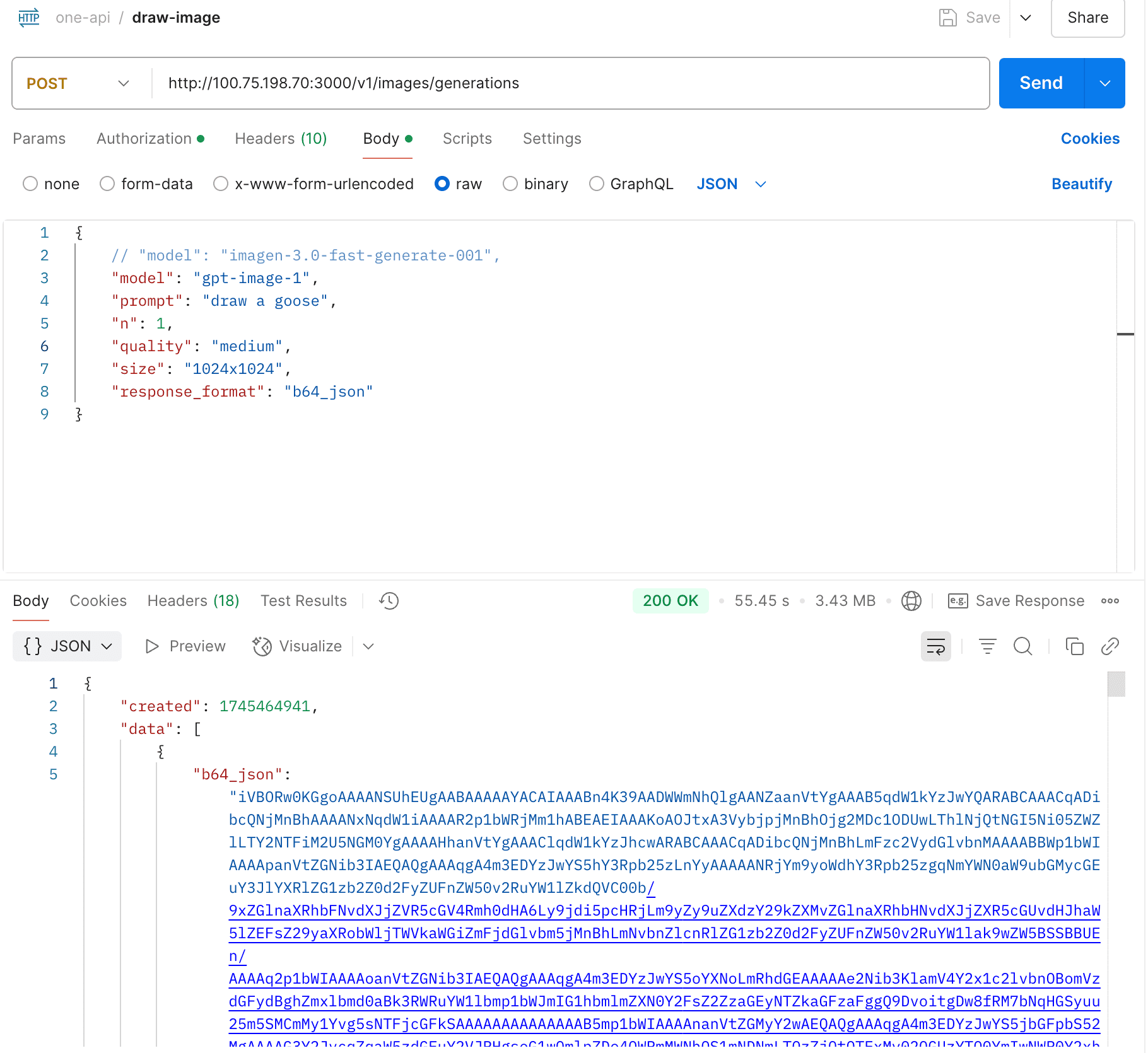
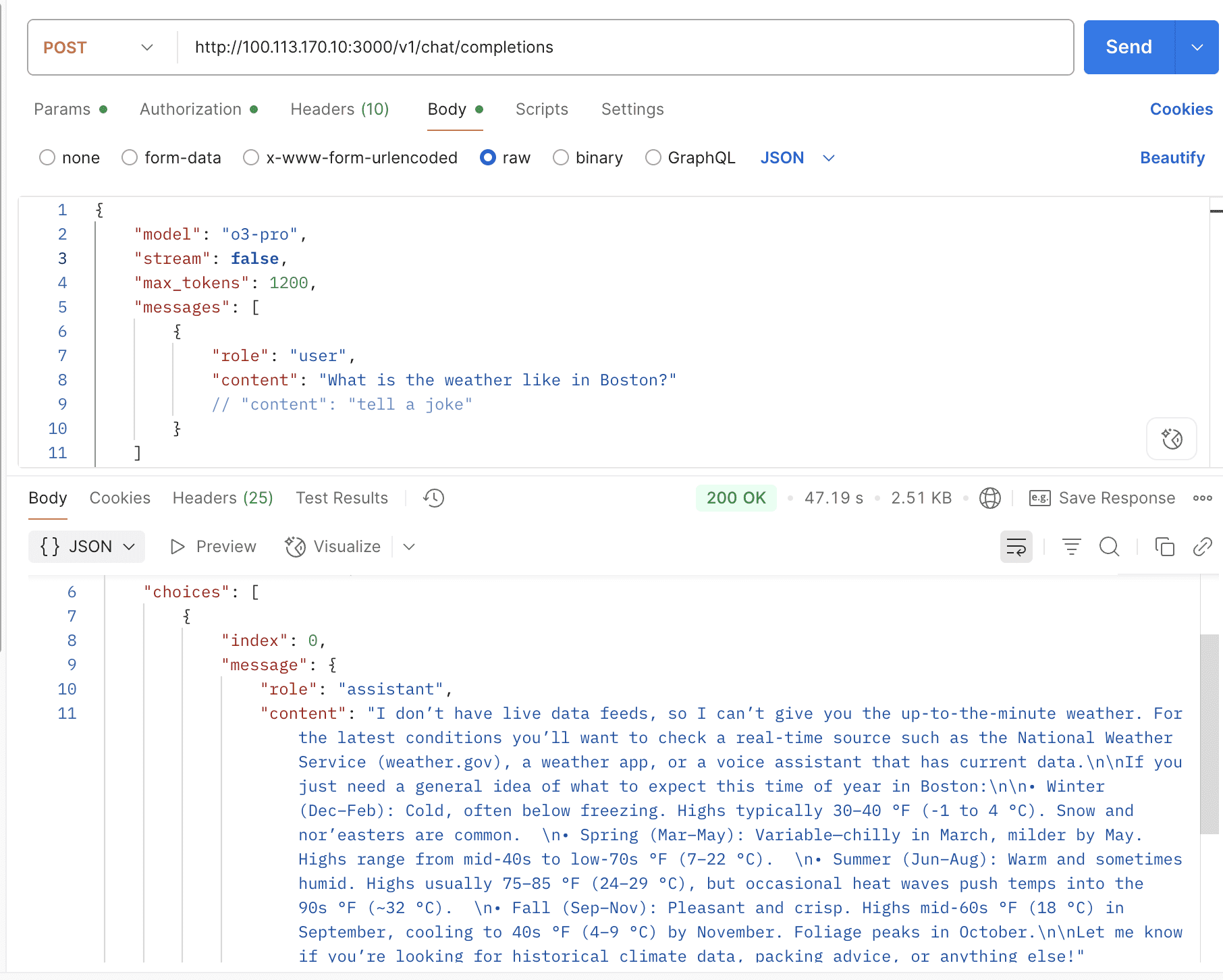
Partially supported, still in development.
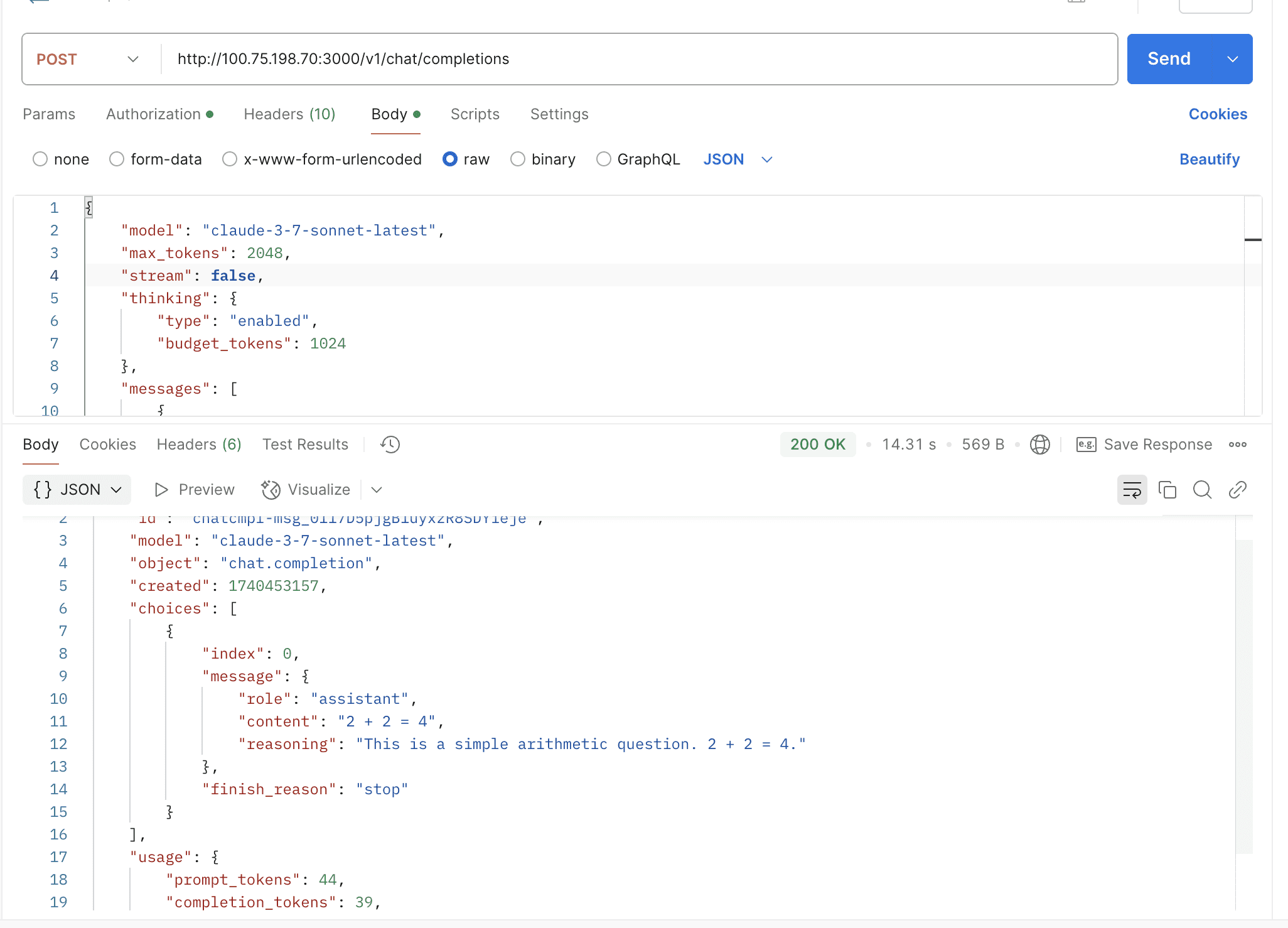
By default, the thinking mode is not enabled. You need to manually pass the thinking field in the request body to enable it.
export ANTHROPIC_MODEL="openai/gpt-oss-120b"
export ANTHROPIC_BASE_URL="https://oneapi.laisky.com/"
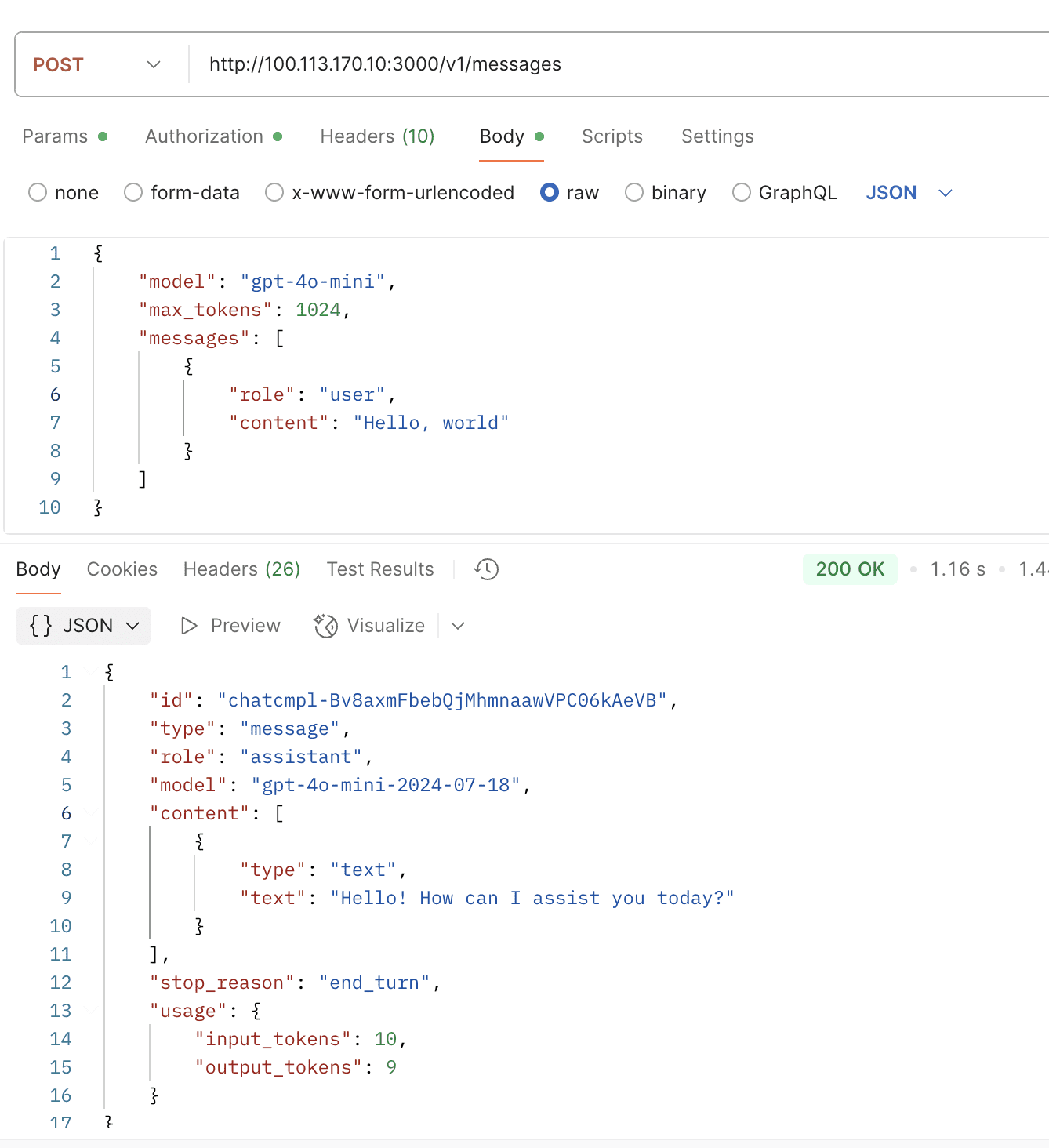
export ANTHROPIC_AUTH_TOKEN="sk-xxxxxxx"You can use any model you like for Claude Code, even if the model doesn’t natively support the Claude Messages API.


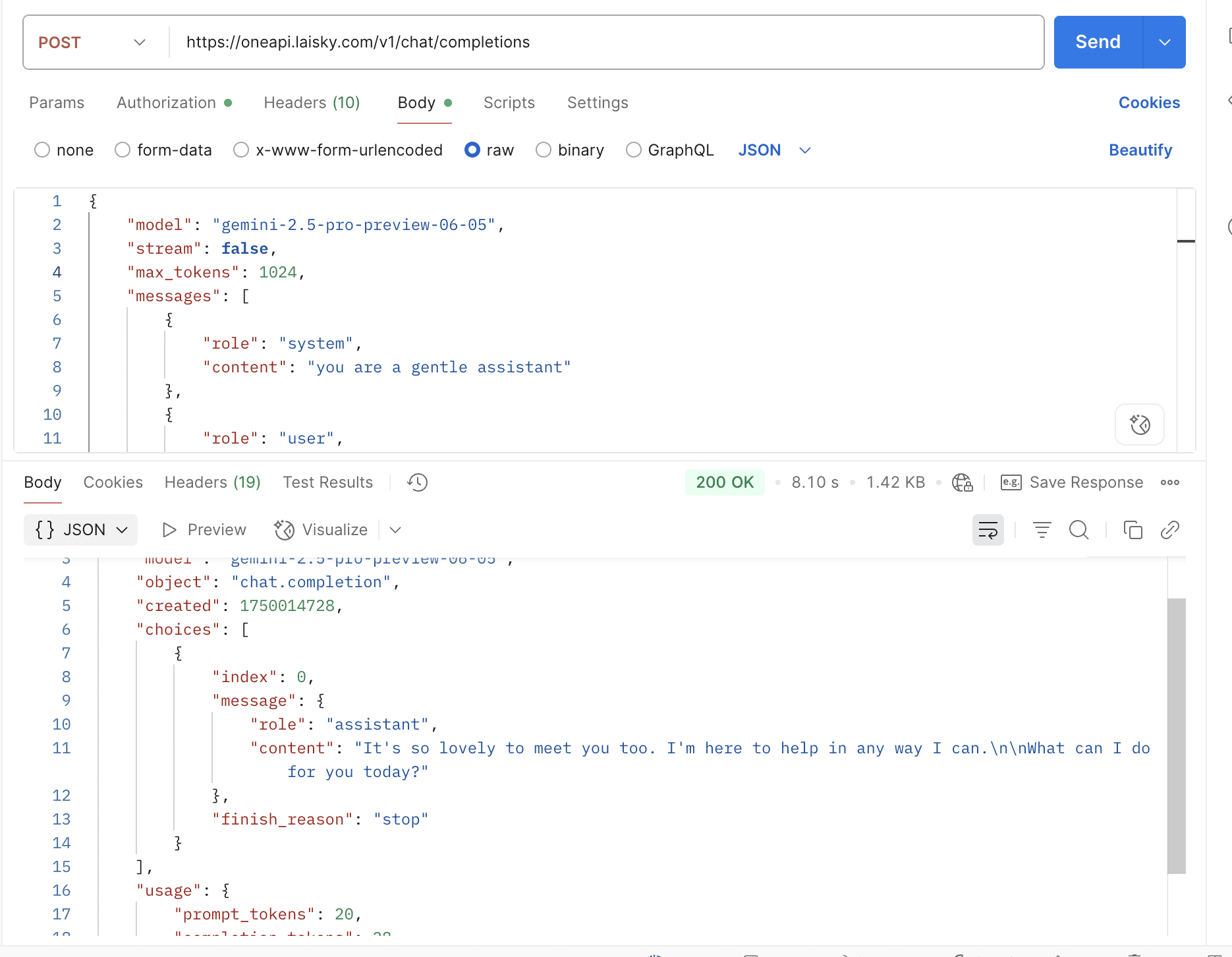
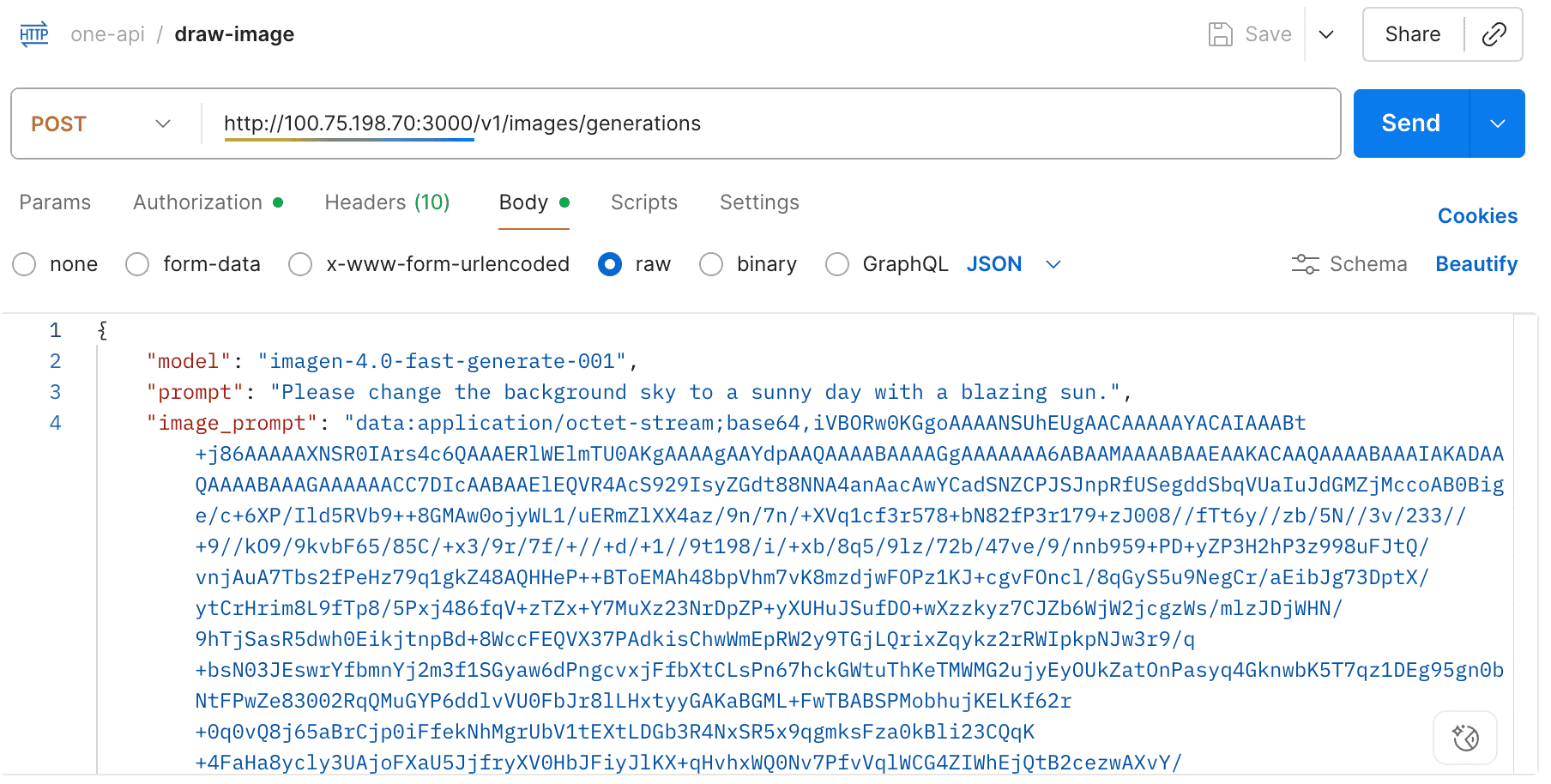

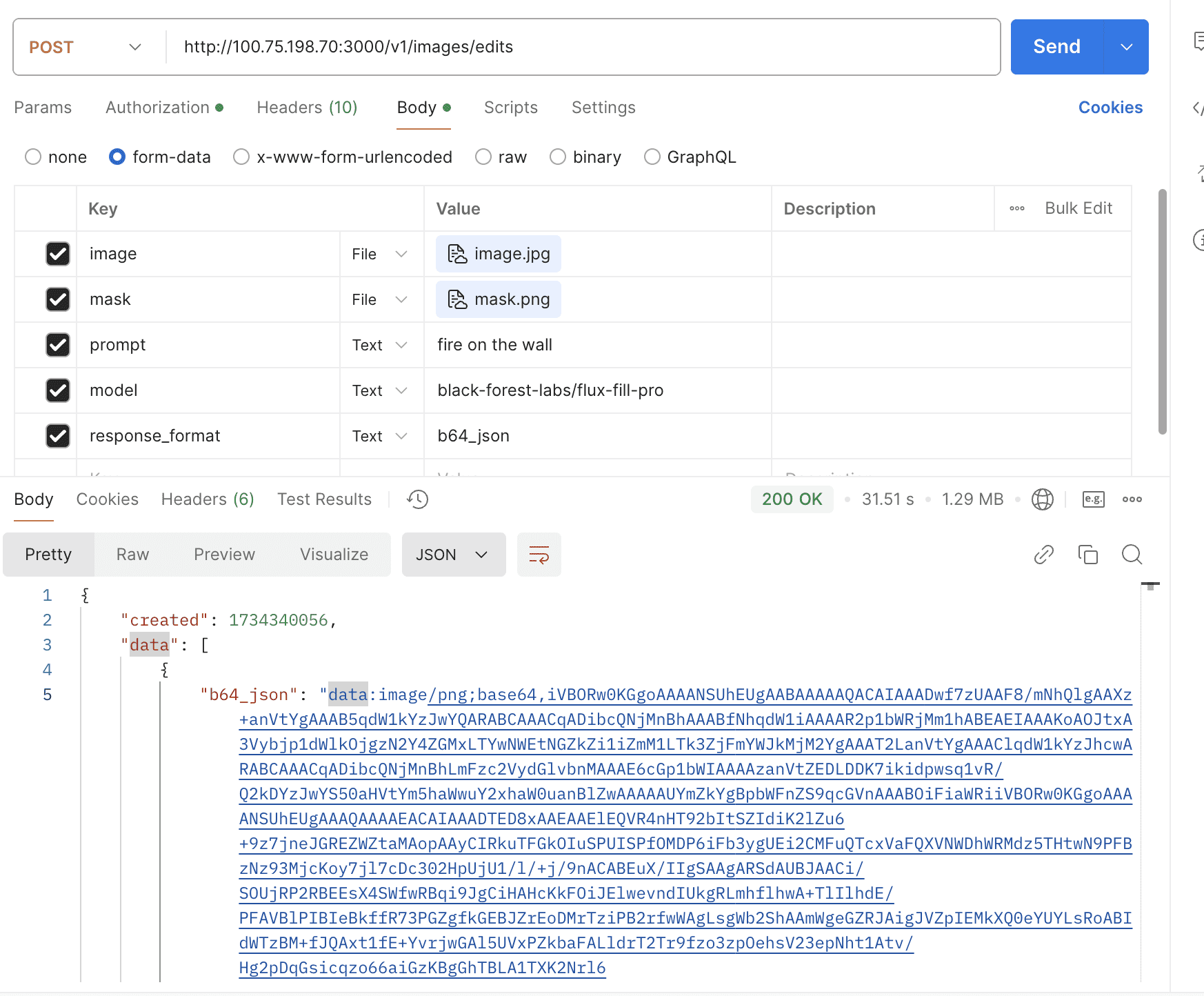

By default, the thinking mode is automatically enabled for the deepseek-r1 model, and the response is returned in the open-router format.

- BUGFIX: Several issues when updating tokens #1933
- feat(audio): count whisper-1 quota by audio duration #2022
- fix: Fix issue where high-quota users using low-quota tokens aren't pre-charged, causing large token deficits under high concurrency #25
- fix: channel test false negative #2065
- fix: resolve "bufio.Scanner: token too long" error by increasing buffer size #2128
- feat: Enhance VolcEngine channel support with bot model #2131
- fix: models API returns models in deactivated channels #2150
- fix: Automatically close channel when connection fails
- fix: update EmailDomainWhitelist submission logic #33
- fix: send ByAll
- fix: oidc token endpoint request body #2106 #36