-
😣受不了动漫剧集的命名与Emby自动刮削格式不兼容?
-
🥰本项目可以将大部分下载的剧集(包括动漫、电影、番剧等)转为Emby所需要的文件结构!
-
🚀支持剪切、复制、硬链接(默认)三种移动/重命名方式!
-
✨并且你可以通过简单的配置,让qBittorrent每次下载结束之后自动执行转换!
-
🤖AI识别功能:支持OpenAI和Google Gemini双引擎,智能分析动漫文件映射关系,解决BD分集与TMDB数据不一致的问题!
-
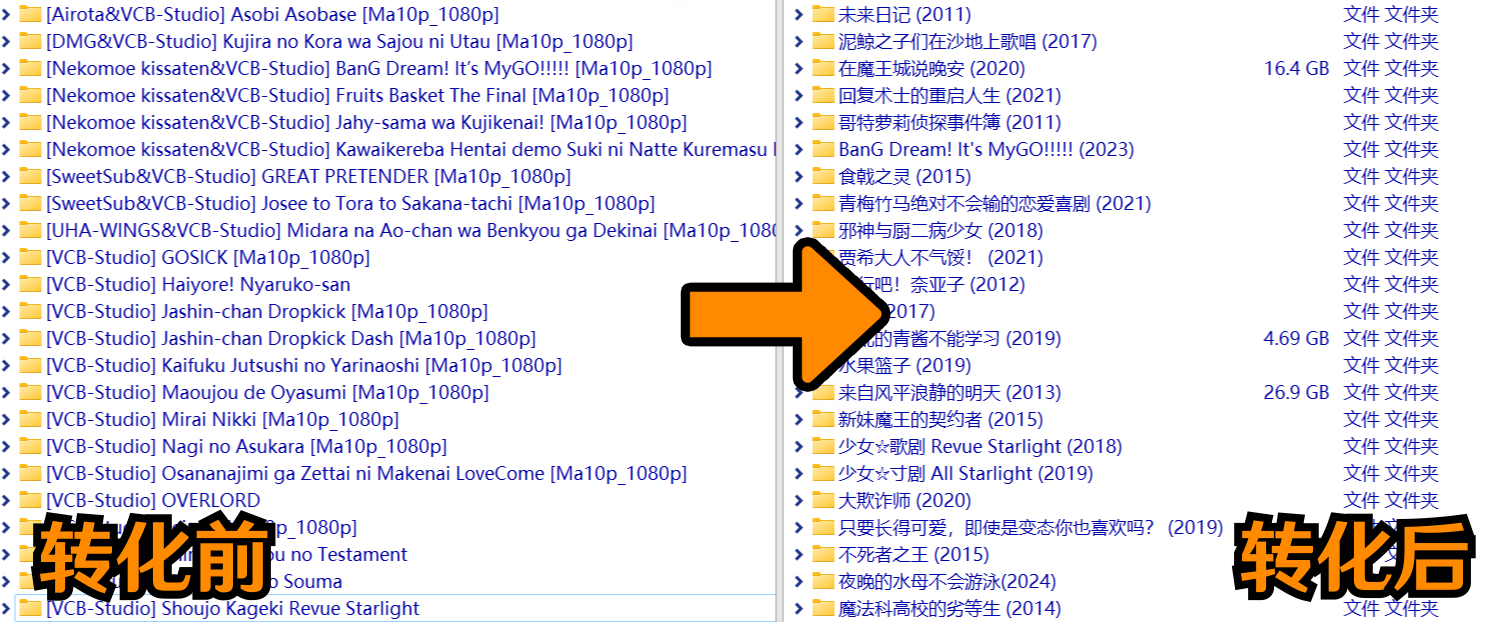
🥳支持复杂的目录结构!以VCB-Studio的Re:从零开始的异世界生活剧集合集为例:
├─[VCB-Studio] Re Zero kara Hajimeru Isekai Seikatsu
│ ├─[VCB-Studio] Re Zero kara Hajimeru Isekai Seikatsu 2nd Season [Ma10p_1080p]
│ ├─[VCB-Studio] Re Zero kara Hajimeru Isekai Seikatsu Hyouketsu no Kizuna [Ma10p_1080p]
│ ├─[VCB-Studio] Re Zero kara Hajimeru Isekai Seikatsu Memory Snow [Ma10p_1080p]
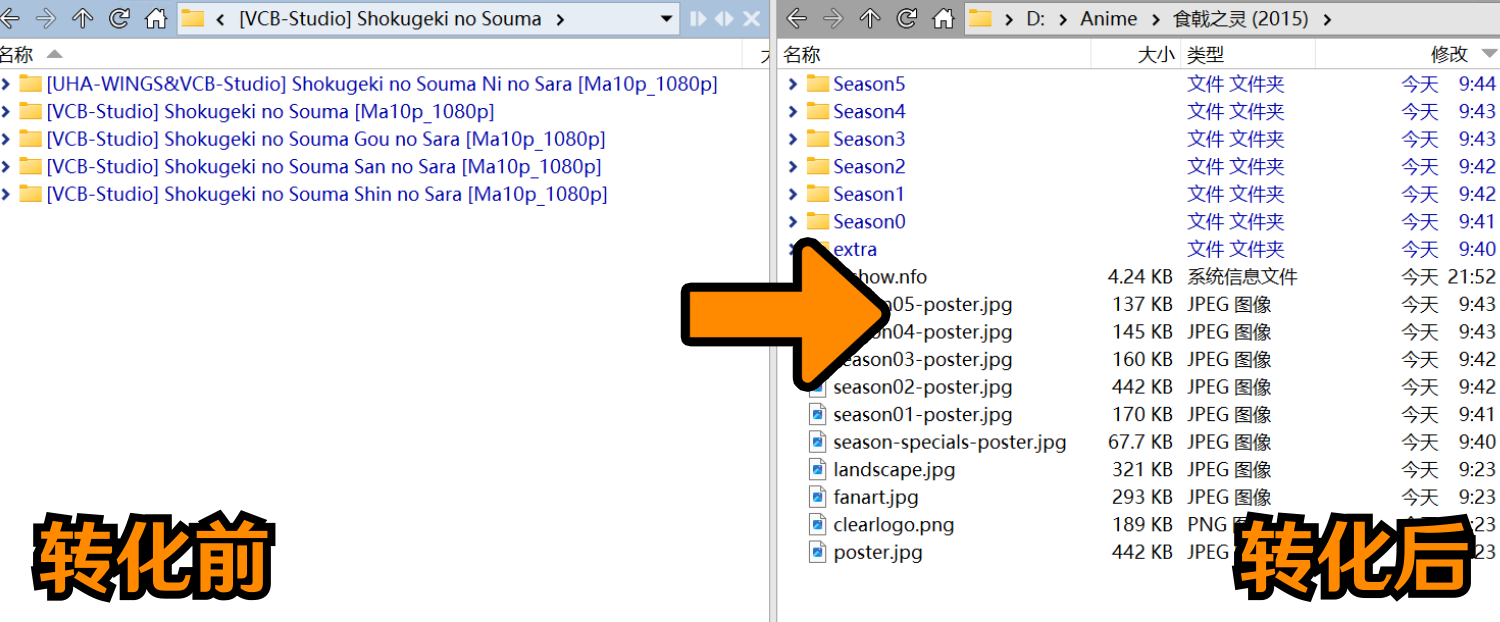
│ ├─[VCB-Studio] Re Zero kara Hajimeru Isekai Seikatsu [Ma10p_1080p]可以看到大的集合里面同时包括以下子文件夹内容:第一季、第二季、电影冰结之绊、电影雪之回忆,而你只需要运行该程序,即可自动分门别类,电影/番剧会被格式化后分别的、正确的复制/硬链接到你指定的文件夹!
🧠 智能分析能力
- 自动识别字幕组的分季与TMDB官方分季的差异
- 智能处理OVA、特典等特殊内容的归类
- 根据视频时长判断内容类型(正片/特典/PV等)
- 提供置信度评估,低置信度结果会单独记录
🔧 灵活配置选项
- AI提供商选择:OpenAI / Google Gemini
- OpenAI配置:支持兼容API、多种输出格式、自定义模型
- Gemini配置:原生API支持、高效结构化输出
- 智能阈值:可调节置信度阈值
- 功能开关:支持启用/禁用AI功能
- 进入TMDB官网申请
- 复制你的API 密钥,后续会用到
- OpenAI API:申请OpenAI API密钥,或使用兼容的国内API服务
- 推荐模型:deepseek-reasoner(性价比高,效果好)
- 支持多种输出格式,兼容性强
- Google Gemini API:申请Google AI Studio API密钥
- 推荐模型:gemini-2.5-flash(速度快,效果优秀)
- 原生结构化输出,解析更准确
- 如不配置AI功能,程序将使用传统规则进行识别
Important
WEB版本提高了易用性、和识别准确率, 但要求必须本机内存在git和python环境!
-
确保存在Python环境(版本需要
>=3.9), Git环境。 -
命令行执行
git clone https://github.com/KimigaiiWuyi/Bangumi_Auto_Rename.git -b webcd Bangumi_Auto_Renamepip install -r requirements.txt
-
启动
python -m src.start
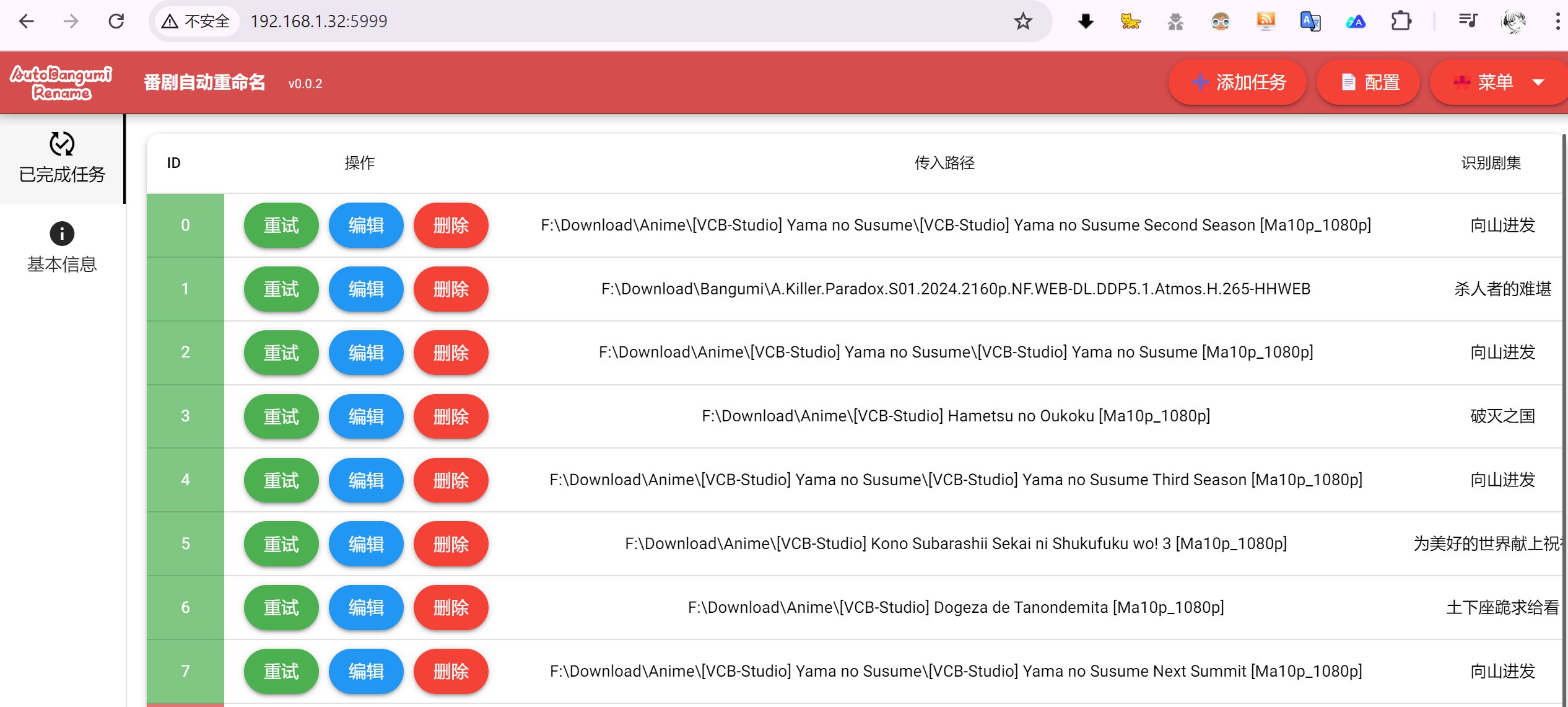
- 打开网页之后(默认端口5999,即地址为
http://127.0.0.1:5999) - 先点击右上角配置按钮,配置以下内容:
- 基础配置:TMDB API密钥和各个整理路径
- AI配置(可选):选择AI提供商、配置API密钥、选择模型等
- 点击添加任务即可使用
注意: 🚨 AI识别为实验性功能,请勿在移动模式中启用!!
-
在配置页面的"AI识别配置"部分:
- 启用AI识别:开启/关闭AI功能
- AI提供商选择:选择OpenAI或Google Gemini
- 置信度阈值:设置结果采用的最低置信度要求
-
OpenAI配置(选择OpenAI提供商时):
- API密钥:填入你的OpenAI兼容API密钥
- API地址:默认为OpenAI官方URL,可改为其他兼容服务(一般以/v1结尾)
- 模型选择:推荐使用Deepseek-R1(deepseek-reasoner)
- 输出格式:选择Function Calling、JSON Object、Structured Output或Text
- API测试:一键测试当前API支持的功能特性
-
Google Gemini配置(选择Gemini提供商时):
- API密钥:填入你的Google AI Studio API密钥
- API地址:默认为AI Studio Gemini URL,可改为Vertex或其它兼容服务
- 模型选择:推荐使用gemini-2.5-flash
- 原生结构化输出:默认启用,无需额外配置
- 智能映射:自动分析本地文件与TMDB数据的对应关系
- 特殊处理:识别OVA、特典、剧场版等特殊内容
- 时长分析:根据视频时长匹配元数据
- 置信度评估:提供分析结果的可信度评分
- 格式适配:支持多种输出格式,确保最佳兼容性
- AI功能需要网络连接和API调用费用
- 不同AI提供商的费用和速度有所差异
- 低置信度结果会在日志中特别标记
- 可以在编辑任务时选择是否使用AI识别
- 如果AI分析失败,会自动回退到传统规则识别
- 建议先使用API测试功能验证配置是否正确
⚠注意:箭头处的命令需要根据上面命令行自己写一下,照抄无效!(下面有提供示例)
- 打开软件,工具 -> 设置 -> 弹出窗口中找到下载 -> 往下滚动 -> Torrent完成时运行
- 根据自己的配置,写入命令,应用保存即可
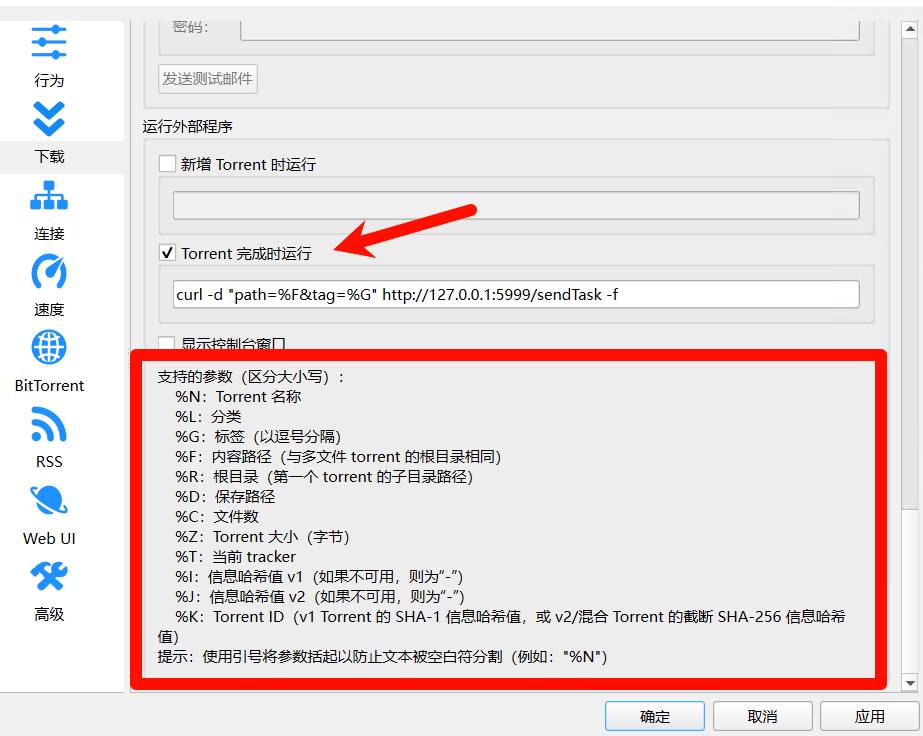
- 这里的命令相比于上面的命令行,需要做一些小的调整,首先一点是
path=的输入,一定要用"%F"替换(上图可能是%D,那是错误的,不要关心图上的命令),这样就是每次种子实际下载的路径了 - 一个是
tag=的输入,可以用"$G"替换,代表着创建种子时候的标签,这里如果下载的是动漫剧集,需要带上anime的标签,如果是电影,带上movie的标签,方便自动整理到对应路径,如果无任何标签,是否是电影会自动判断,是否是动漫则默认为否,如果不需要处理,可以传入no_process的标签 - 填入示例如下
curl --data-urlencode "path=%F" --data-urlencode "tag=%G" "http://127.0.0.1:5999/sendTask" -f- 进入文件夹内,
cd Bangumi_Auto_Rename - 执行
git pull
-
该程序依靠TMDB API(因为Emby也是一样的,可以保证精准度),因此对网络环境有一定要求!
-
AI功能需要额外的API调用费用,但可以显著提高动漫识别准确率
- OpenAI API:官方按token计费,部分提供商有免费的Deepseek R1额度
- Google Gemini API:有免费额度,gemini-2.5-flash速度快
- 该功能仍在开发中,欢迎各位提供测试用例
-
该程序更加适用于动画剧集的重命名,对于电影、剧集,本身Emby的刮削足够精准了。
-
识别率并不是100%,如果有识别错误的,带上截图,提Issues!
-
该程序使用情况覆盖了很多,但是像是非常复杂的情况,例如物语系列这种重量级剧集(加上TMDB对于物语系列的剧集分类,非常的复杂),请不要使用本程序
-
如果已经使用了本程序刮削错误的情况,因为默认是硬链接模式,所以直接删除目标文件夹的对应文件即可,不会影响到源文件!
-
有任何使用上的问题或者建议都可以提Issues,尽力解答!
-
如果本插件对你有帮助,不要忘了点个Star~
-
本项目仅供学习使用,请勿用于商业用途