
🧪 Your AI teammate that tests, debugs, and fixes LLM agents – production-ready with confidence.

📚 View Full Documentation - Complete guides, examples, and API reference
We're building an AI development teammate that autonomously tests, improves, and evolves your LLM applications. Given input/output pairs, it generates test cases, fixes failures, and iterates until your agent is battle-ready.
Goal: Transform from a testing tool into your AI development partner.
Here is our current progress toward our vision of becoming a true AI development teammate for LLM applications. See our current limitations for details.
We welcome contributions and feature requests! If you have specific scenarios or use cases you'd like to see supported, please:
- Open an Issue: Share your requirements or use cases
- Join Discussions: Help prioritize features that matter to the community
- Contribute Code: Help us build the AI teammate of the future
Your feedback helps us prioritize development and ensures Kaizen Agent becomes the teammate you need for building world-class LLM applications.
🌟 If you find this project helpful, please consider giving it a star — it really helps us!

{kind=link}
💬 Questions? Need help? Join our Discord community to ask questions, share your experiences, and get support from other developers using Kaizen Agent!
Kaizen Agent acts as your AI development partner that continuously evolves and improves your AI agents and LLM applications. Here's how it works at a high level:
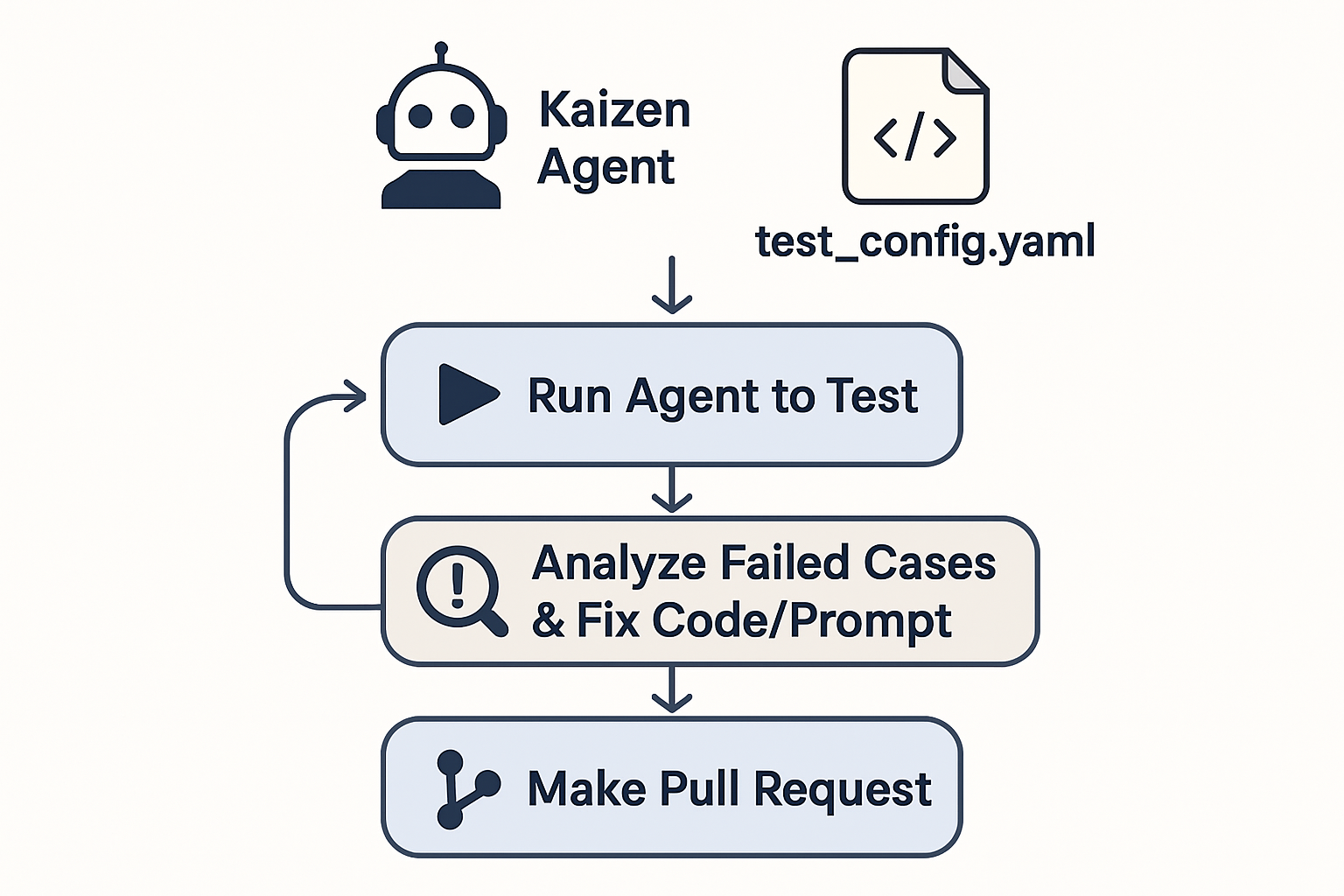
Kaizen Agent is most valuable during the development phase of your AI agents, right after you've written the initial code but before deployment.
Traditional AI development is reactive — you build, test manually, find issues, and fix them. Kaizen Agent flips this to proactive improvement:
- 🎯 Define your vision with input/output pairs that represent ideal behavior
- 🔄 Let Kaizen iterate through thousands of test scenarios automatically
- 📈 Watch your agent evolve as Kaizen suggests and implements improvements
- 🚀 Deploy with confidence knowing your agent has been battle-tested
The result? Your AI applications improve continuously, catching edge cases you never thought of and optimizing performance beyond what manual testing could achieve.
- 🚀 Rapid Prototyping: Get from idea to working agent in minutes, then let Kaizen refine it
- 🔄 Iterative Enhancement: Continuously improve existing agents with new test cases
- 📊 Performance Optimization: Discover and fix bottlenecks automatically
- 🛡️ Production Readiness: Ensure your agent handles real-world scenarios reliably
- 🎯 Feature Expansion: Add new capabilities while maintaining existing quality
- AI Agents & LLM Applications - Any system that processes natural language or makes decisions
- Customer Support Bots - Ensure consistent, helpful responses across all scenarios
- Content Generation Tools - Maintain quality and style consistency
- Data Analysis Agents - Validate accuracy and edge case handling
- Workflow Automation - Test complex decision trees and business logic
- Production environments - Kaizen is for development/improvement, not live systems
- Simple, stable applications - If your agent is already performing perfectly, you might not need continuous improvement
- Non-AI applications - Kaizen is specifically designed for AI agents and LLM applications
Requirements:
- Python 3.8+ (Python 3.9+ recommended for best performance)
# Create a test directory for your specific agent
mkdir my-email-agent-test
cd my-email-agent-test
# Create a virtual environment (recommended)
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install Kaizen Agent from PyPI
pip install kaizen-agent
# Create .env file with your Google API key
cat > .env << EOF
GOOGLE_API_KEY=your_api_key_here
EOF
# Or set it directly in your shell
export GOOGLE_API_KEY="your_api_key_here"Create my_agent.py:
import google.generativeai as genai
import os
class EmailAgent:
def __init__(self):
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
self.model = genai.GenerativeModel('gemini-2.5-flash-preview-05-20')
# Simple prompt that Kaizen can improve significantly
self.system_prompt = "Improve this email draft."
def improve_email(self, email_draft):
full_prompt = f"{self.system_prompt}\n\nEmail draft:\n{email_draft}\n\nImproved version:"
response = self.model.generate_content(full_prompt)
return response.textCreate my_agent.ts:
import { google } from '@ai-sdk/google';
import { Agent } from '@mastra/core/agent';
export const emailFixAgent = new Agent({
name: 'Email Fix Agent',
instructions: `You are an email assistant. Improve this email draft.`,
model: google('gemini-2.5-flash-preview-05-20'),
});🎯 No Test Code Required!
Kaizen Agent uses YAML configuration to define your agent's ideal behavior. This is a new, more intuitive way to specify what your AI should do:
- ❌ Traditional approach: Write test files with
unittest,pytest, orjest - ✅ Kaizen approach: Define your vision in YAML - describe the ideal behavior!
Create kaizen.yaml:
name: Email Improvement Agent Test
file_path: my_agent.py
description: This agent improves email drafts by making them more professional, clear, and well-structured. It transforms casual or poorly written emails into polished, business-appropriate communications.
agent:
module: my_agent
class: EmailAgent
method: improve_email
evaluation:
evaluation_targets:
- name: quality
source: return
criteria: "The email should be professional, polite, and well-structured with proper salutations and closings"
weight: 0.5
- name: format
source: return
criteria: "The response should contain only the improved email content without any explanatory text, markdown formatting, or additional commentary. It should be a clean, standalone email draft ready for use."
weight: 0.5
files_to_fix:
- my_agent.py
steps:
- name: Professional Email Improvement
input:
input: "hey boss, i need time off next week. thanks"
- name: Edge Case - Empty Email
input:
input: ""
- name: Edge Case - Very Informal Email
input:
input: "yo dude, can't make it to the meeting tomorrow. got stuff to do. sorry!"Create kaizen.yaml:
name: Email Improvement Agent Test
file_path: src/mastra/agents/email-agent.ts
language: typescript
description: This agent improves email drafts by making them more professional, clear, and well-structured. It transforms casual or poorly written emails into polished, business-appropriate communications.
agent:
module: email-agent # Just the file name without extension
evaluation:
evaluation_targets:
- name: quality
source: return
criteria: "The email should be professional, polite, and well-structured with proper salutations and closings"
weight: 0.5
- name: format
source: return
criteria: "The response should contain only the improved email content without any explanatory text, markdown formatting, or additional commentary. It should be a clean, standalone email draft ready for use."
weight: 0.5
files_to_fix:
- src/mastra/agents/email-agent.ts
settings:
timeout: 180
steps:
- name: Professional Email Improvement
input:
input: "hey boss, i need time off next week. thanks"
- name: Edge Case - Very Informal Email
input:
input: "yo dude, can't make it to the meeting tomorrow. got stuff to do. sorry!"# Start the continuous improvement process
kaizen test-all --config kaizen.yaml --auto-fix --save-logsThis will:
- Test your email improvement agent with realistic scenarios
- Automatically enhance the simple prompt to handle different email types
- Save detailed logs to
test-logs/so you can see the evolution of your agent
To enable Kaizen to automatically create pull requests with improvements, you need to set up GitHub access:
- Go to GitHub Settings > Developer settings > Personal access tokens
- Click "Generate new token (classic)"
- Give it a descriptive name (e.g., "Kaizen AutoFix")
- Set an expiration date
- Important: Select these scopes:
- ✅
repo(Full control of private repositories)
- ✅
Create a .env file in your project root:
# Create .env file
cat > .env << EOF
GOOGLE_API_KEY=your_google_api_key_here
GITHUB_TOKEN=ghp_your_github_token_here
EOF# Test GitHub access
kaizen test-github-access --repo your-username/your-repo-name
# Start continuous improvement with automated PRs
kaizen test-all --config kaizen.yaml --auto-fix --create-prKaizen Agent uses YAML configuration files to define your agent's ideal behavior and improvement goals. This approach eliminates the need for traditional test files while providing powerful continuous improvement capabilities.
Here's a complete example that demonstrates how to define your agent's ideal behavior:
name: Text Analysis Agent Test Suite
agent_type: dynamic_region
file_path: agents/text_analyzer.py
description: |
Test suite for the TextAnalyzer agent that processes and analyzes text content.
This agent performs sentiment analysis, extracts key information, and provides
structured analysis results. Tests cover various input types, edge cases, and
expected output formats to ensure reliable performance.
agent:
module: agents.text_analyzer
class: TextAnalyzer
method: analyze_text
evaluation:
evaluation_targets:
- name: sentiment_score
source: variable
criteria: "The sentiment_score must be a float between -1.0 and 1.0. Negative values indicate negative sentiment, positive values indicate positive sentiment. The score should accurately reflect the emotional tone of the input text."
description: "Evaluates the accuracy of sentiment analysis output"
weight: 0.4
- name: key_phrases
source: variable
criteria: "The key_phrases should be a list of strings containing the most important phrases from the input text"
description: "Checks if key phrase extraction is working correctly"
weight: 0.3
- name: analysis_quality
source: return
criteria: "The response should be well-structured, professional, and contain actionable insights"
description: "Evaluates the overall quality and usefulness of the analysis"
weight: 0.3
max_retries: 3
files_to_fix:
- agents/text_analyzer.py
- agents/prompts.py
referenced_files:
- agents/prompts.py
- utils/text_utils.py
steps:
- name: Positive Review Analysis
description: "Analyze a positive customer review"
input:
file_path: agents/text_analyzer.py
method: analyze_text
input:
- name: text_content
type: string
value: "This product exceeded my expectations! The quality is outstanding and the customer service was excellent. I would definitely recommend it to others."
expected_output:
sentiment_score: 0.8
key_phrases: ["exceeded expectations", "outstanding quality", "excellent customer service"]
- name: Negative Feedback Analysis
description: "Analyze negative customer feedback"
input:
file_path: agents/text_analyzer.py
method: analyze_text
input:
- name: text_content
type: string
value: "I'm very disappointed with this purchase. The product arrived damaged and the support team was unhelpful."
expected_output:
sentiment_score: -0.7
key_phrases: ["disappointed", "damaged product", "unhelpful support"]
- name: Neutral Text Analysis
description: "Analyze neutral or mixed sentiment text"
input:
file_path: agents/text_analyzer.py
method: analyze_text
input:
- name: text_content
type: string
value: "The product has both good and bad aspects. The design is nice but the price is high."
expected_output:
sentiment_score: 0.0
key_phrases: ["good aspects", "bad aspects", "nice design", "high price"]
- name: Object Input Analysis
description: "Analyze text using a structured user review object"
input:
file_path: agents/text_analyzer.py
method: analyze_review
input:
- name: user_review
type: object
class_path: agents.review_processor.UserReview
args:
text: "This product exceeded my expectations! The quality is outstanding."
rating: 5
category: "electronics"
helpful_votes: 12
verified_purchase: true
- name: analysis_settings
type: dict
value:
include_sentiment: true
extract_keywords: true
detect_emotions: false
expected_output:
sentiment_score: 0.9
key_phrases: ["exceeded expectations", "outstanding quality", "excellent customer service"]
review_quality: "high"
- name: Empty Input Handling
description: "Test how the agent handles empty or minimal input"
input:
file_path: agents/text_analyzer.py
method: analyze_text
input:
- name: text_content
type: string
value: ""
expected_output:
sentiment_score: 0.0
key_phrases: []name: A descriptive name for your agent's improvement journeyagent_type: Type of agent (e.g.,dynamic_regionfor code-based agents)file_path: Path to the main agent file being improveddescription: Detailed description of what the agent does and how it should evolve
agent:
module: agents.text_analyzer # Python module path
class: TextAnalyzer # Class name to instantiate
method: analyze_text # Method to call during testingThe evaluation section defines how Kaizen's LLM evaluates your agent's performance. Each evaluation_target specifies what to check and how to score it.
evaluation:
evaluation_targets:
- name: sentiment_score # Name of the output to evaluate
source: variable # Source: 'variable' (from agent output) or 'return' (from method return)
criteria: "Description of what constitutes a good result"
description: "Additional context about this evaluation target"
weight: 0.4 # Relative importance (0.0 to 1.0)Key Components:
name: Must match a field in your agent's output or return valuesource:variable: Extract from agent's output variables/attributesreturn: Use the method's return value
criteria: Most important - Instructions for the LLM evaluatordescription: Additional context to help the LLM understand the evaluationweight: Relative importance (0.0 to 1.0, total should equal 1.0)
Writing Effective Criteria:
✅ Good Examples:
- name: sentiment_score
source: variable
criteria: "The sentiment_score must be a float between -1.0 and 1.0. Negative values indicate negative sentiment, positive values indicate positive sentiment. The score should accurately reflect the emotional tone of the input text."
weight: 0.4
- name: response_quality
source: return
criteria: "The response should be professional, well-structured, and contain actionable insights. It must be free of grammatical errors and provide specific, relevant information that addresses the user's query directly."
weight: 0.6❌ Poor Examples:
- name: result
source: return
criteria: "Should be good" # Too vague
weight: 1.0
- name: accuracy
source: variable
criteria: "Check if it's correct" # Not specific enough
weight: 1.0Tips for Better LLM Evaluation:
- Be Specific: Include exact requirements, ranges, or formats
- Provide Context: Explain what "good" means in your domain
- Include Examples: Reference expected patterns or behaviors
- Consider Edge Cases: Mention how to handle unusual inputs
- Use Clear Language: Avoid ambiguous terms that LLMs might misinterpret
max_retries: Number of retry attempts if an improvement attempt failsfiles_to_fix: Files that Kaizen can modify to enhance performancereferenced_files: Additional files for context (not modified)
Each step defines a scenario for improvement with:
name: Descriptive name for the scenariodescription: What this scenario is checkinginput:file_path: Path to the agent filemethod: Method to callinput: List of parameters with name, type, and value
Kaizen supports multiple input types for test parameters:
String Input:
- name: text_content
type: string
value: "Your text here"Dictionary Input:
- name: config
type: dict
value:
key1: "value1"
key2: "value2"Object Input:
- name: user_review
type: object
class_path: agents.review_processor.UserReview
args:
text: "This product exceeded my expectations! The quality is outstanding."
rating: 5
category: "electronics"
helpful_votes: 12
verified_purchase: trueThe class_path specifies the Python class to instantiate, and args provides the constructor arguments.
expected_output: Expected results for evaluation
For quick improvement, you can use this minimal template:
name: My Agent Improvement
file_path: my_agent.py
description: "Improve my AI agent"
agent:
module: my_agent
class: MyAgent
method: process
evaluation:
evaluation_targets:
- name: result
source: return
criteria: "The response should be accurate and helpful"
weight: 1.0
files_to_fix:
- my_agent.py
steps:
- name: Basic Scenario
input:
file_path: my_agent.py
method: process
input:
- name: user_input
type: string
value: "Hello, how are you?"
expected_output:
result: "I'm doing well, thank you!"# Start continuous improvement
kaizen test-all --config kaizen.yaml
# With automatic enhancements
kaizen test-all --config kaizen.yaml --auto-fix
# Create PR with improvements
kaizen test-all --config kaizen.yaml --auto-fix --create-pr
# Save detailed logs
kaizen test-all --config kaizen.yaml --save-logs
# Environment setup
kaizen setup check-env
kaizen setup create-env-example
# GitHub access testing
kaizen test-github-access --repo owner/repo-name
kaizen diagnose-github-access --repo owner/repo-name- Minimum: Python 3.8+
- Recommended: Python 3.9+ for best performance
google-generativeai>=0.3.2(for LLM operations)python-dotenv>=0.19.0(for environment variables)click>=8.0.0(for CLI)pyyaml>=6.0.0(for YAML configuration)PyGithub>=2.6.1(for GitHub integration)