In this work, we propose the first Central Asia Food Scenes Dataset that contains 21,306 images with 69,856 instances across 239 food classes. To make sure that the dataset contains various food items, we took as a benchmark the ontology of Global Individual Food Tool developed by Food and Agriculture Organization (FAO) together with the World Health Organization (WHO) [1]. The dataset contains food items across 18 coarse classes: 🍅 Vegetables • 🥖 Baked goods • 🍲 Cooked dishes • 🍎 Fruits • 🌿 Herbs • 🍖 Meat dishes • 🍰 Desserts • 🥗 Salads • 🥫 Sauces • 🥤 Drinks • 🧀 Dairy • 🍔 Fast food • 🍜 Soups • 🍟 Sides • 🥜 Nuts • 🥒 Pickled & fermented • 🥚 Egg products • 🌾 Cereals
The images come from:
- 🤖 15,939 web-scraped images (i.e., Google, YouTube, Yandex)
- 📸 2,324 everyday-life photos
- 🎥 3,043 video frames (1 fps)
The dataset has been checked and cleaned for duplicates using the Python Hash Image library. Furthermore, we have also filtered out images less than 30 kB in size and replaced them by performing additional iterative data scraping and duplicate check to make sure the high quality of the dataset.
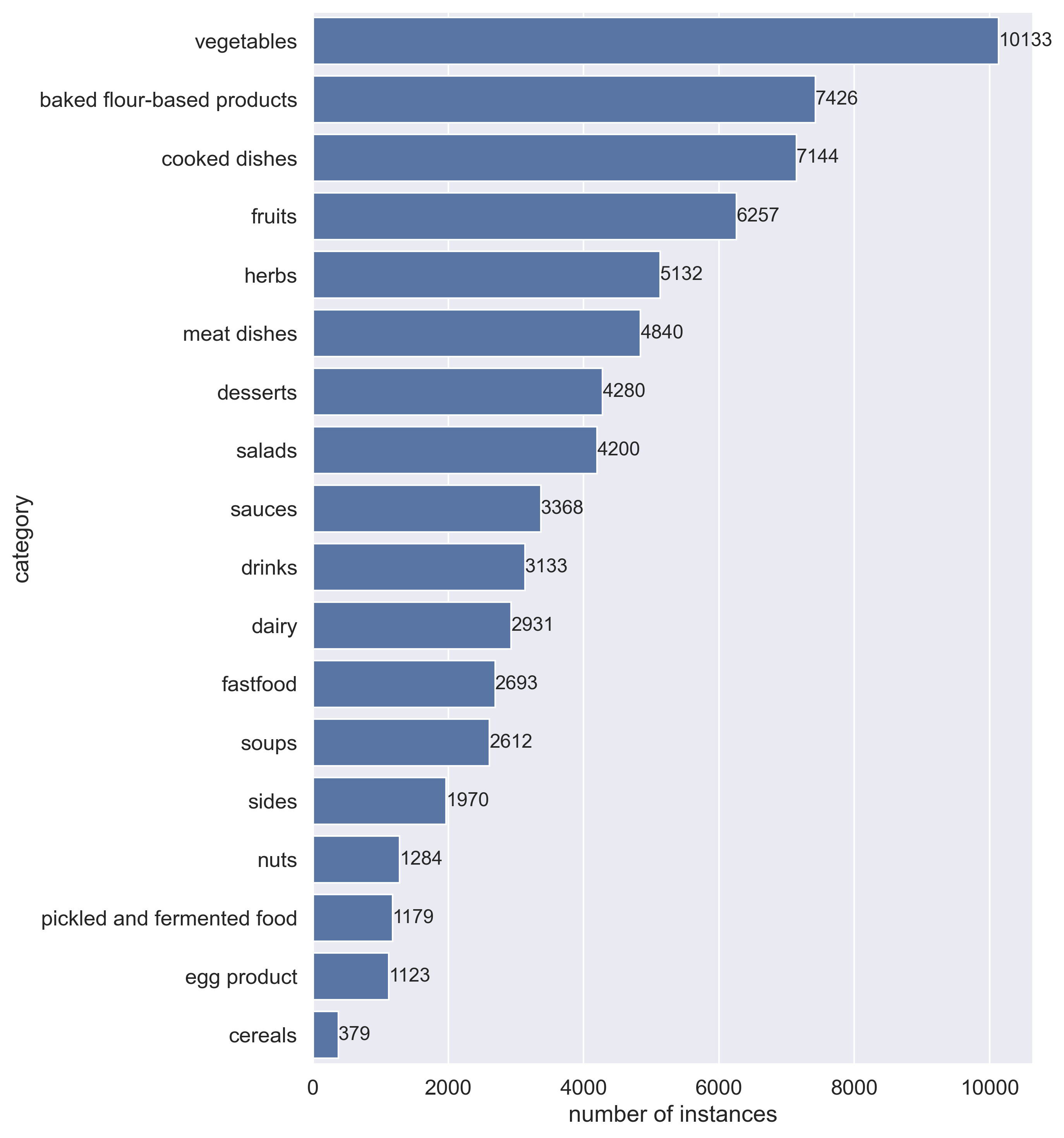
The dataset is unbalaced. The statistics across high-level 18 classes is shown on Figure below.
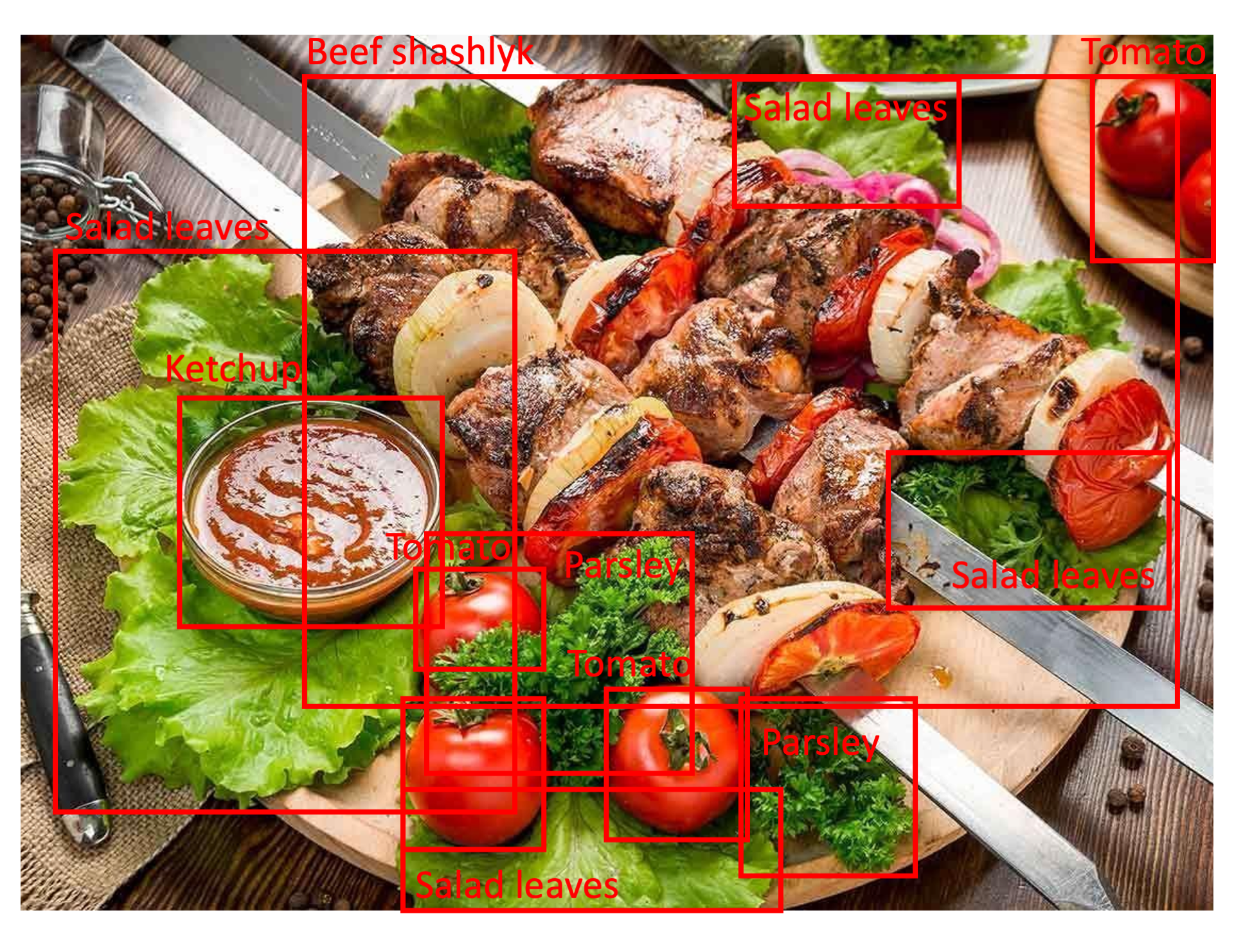
Sample Food scenes annotated images are shown below. Figures illustrate annotated food scenes samples based on our annotation rules that we have followed to create the dataset: the liquid objects such as beverages and soups are annotated together with the dish itself (see upper image), solid food items are annotated without the plate, in case one class is located on top of another class the annotations are made as shown on lower image; in case one class is obscured by another class and the rest of the background class is not visible we highlight only the visible part (see `Salad leaves' class annotation on the lower image).

| Fold | Train | Valid | Test |
|---|---|---|---|
| images | 17,046 | 2,084 | 2,176 |
| instances | 55,422 | 7,062 | 7,381 |
You can get the data in two ways:
-
Hugging Face Hub
Browse or fetch individual files from our HF repo:
🔗 Central Asian Food Scenes Dataset -
Direct download
Grab the full dataset archive here:
▶️ Download ZIP
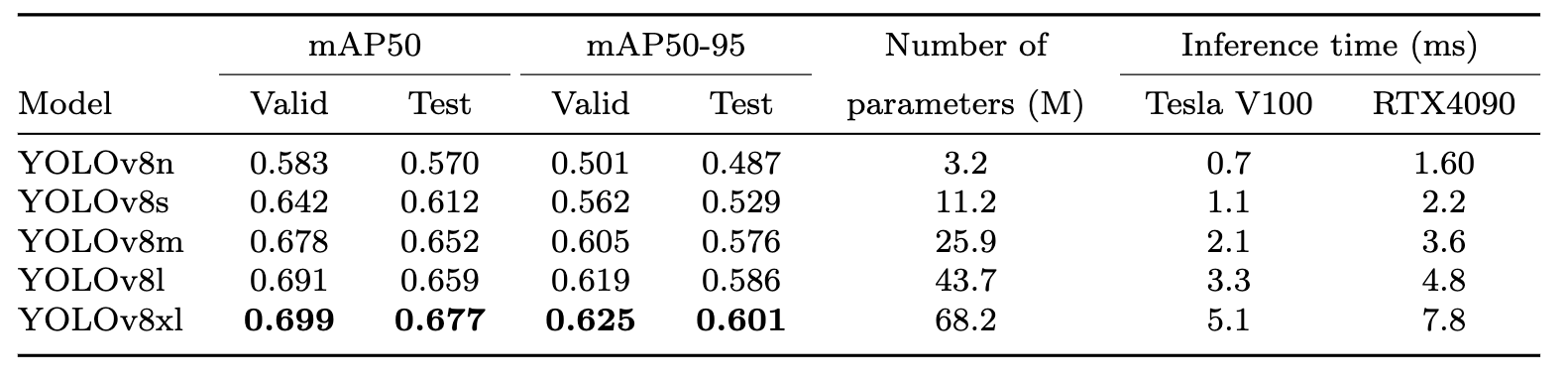
Training results of different versions of the YOLOv8 model on the Central Asian Food Scenes Dataset, model sizes, and inference times.
Pre-trained weights of the YOLOv8 model can be downloaded using these links:
- YOLOv8n: https://issai.nu.edu.kz/wp-content/themes/issai-new/data/models/CAFSD/yolov8n.pt
- YOLOv8s: https://issai.nu.edu.kz/wp-content/themes/issai-new/data/models/CAFSD/yolov8s.pt
- YOLOv8m: https://issai.nu.edu.kz/wp-content/themes/issai-new/data/models/CAFSD/yolov8m.pt
- YOLOv8l: https://issai.nu.edu.kz/wp-content/themes/issai-new/data/models/CAFSD/yolov8l.pt
- YOLOv8x: https://issai.nu.edu.kz/wp-content/themes/issai-new/data/models/CAFSD/yolov8x.pt
[1] European Commission: Impact assessment on measures addressing food waste to complete swd (2014) 207 regarding the review of EU waste management target (2014). Accessed 5-22-2024.
In case of using our dataset and/or pre-trained models, please cite our work:
@article{Karabay2025,
author = {Karabay, Aknur and Varol, Huseyin Atakan and Chan, Mei Yen},
title = {Improved food image recognition by leveraging deep learning and data-driven methods with an application to Central Asian Food Scene},
journal = {Scientific Reports},
volume = {15},
number = {1},
pages = {14043},
year = {2025},
doi = {10.1038/s41598-025-95770-9},
url = {https://doi.org/10.1038/s41598-025-95770-9},
issn = {2045-2322}
}