O crescimento massivo de dados, destacado nas últimas décadas, e a aplicação de métodos bibliométricos, estatísticos e computacionais expuseram a capacidade de se gerar análises métricas e deduções topológicas em redes de dados. Esses estudos permitem-nos compreender não apenas padrões em fluxos de redes, mas, também, como medidas de centralidade podem extrair relações e comportamentos de entidades em um sistema.
Os grafos compreendem uma classe de representação estrutural dos dados e das relações que definem as propriedades desses conjuntos de abstração. Com o crescimento acentuado na produção de dados, sobretudo, após a criação das redes sociais e sistemas computacionais complexos, como as redes neurais, evidencia-se a importância da implementação dessas notações que permitem analisar, com maior precisão, o fluxo e conformação de distintos agrupamentos de dados.
Em 2017, visando analisar a formação de redes sociais entre docentes da área de Administração Pública de diferentes instituições, através de periódicos publicados pela CAPES, os pesquisadores da Universidade Federal de Alagoas (UFAL), Donizetti Calheiros, João Ataíde e Claudio Zancan, propuseram a aplicação de técnicas de análise de redes e observaram, conseguinte, que, dentre todas as instituições avaliadas, a partir da centralidade de produção científica do campo de atuação enfatizado, a Fundação Getúlio Vargas (FGV) detinha a maior relevância, ou seja, uma quantidade maior de conexões comparada às outras instituições estudadas.
Em confluência à pesquisa anterior, os pesquisadores Guilherme Bez, Rafael Faraco e Maria Angeloni pulicaram, em 2010, um artigo acerca das metodologias e descrições que constituem a análise de redes na contemporaneidade e, como ensaio dos conceitos propostos, realizaram o levantamento de centralidade de registros de e-mails institucionais, verificando a formação de comunidades em torno de atores por quantidade de relações (grau).
Segundo a pesquisadora Regina Marteleto, da Universidade Federal do Rio de Janeiro (UFRJ), embora hubs, vértices com grandes quantidades de relações, apresentam-se como elos importantes dentro de uma rede, o fluxo circular de informações nesses meios pode influenciar indiretamente qualquer ator, até mesmos aqueles com menor grau de relevância. Para reduzir esse impacto, Marteleto propõe a utilização de métodos de classificação composicional e estudo de centralidade de subgrupos.
Para o pesquisador Peter Marsden, em Internaltional Encyclopedia of Social Measurement, “as medidas de centralidade da rede são índices amplamente aplicados para descrever as posições de entidades individuais dentro das redes”. Outrossim, para exemplificar essa aplicação de relação entre as entidades, Marsden descreve que, se considerarmos cada relação do conjunto como uma posição em uma matriz de adjacências, podemos, então, obter uma rede e buscar compreender padrões e a formação de comunidades nesses grupos de dados.
Em 2017, buscando compreender o comportamento dos usuários do Waze em diferentes contextos de alerta, o pesquisador Victor Neto, da Universidade Federal do Rio de Janeiro, observou, através de bases de dados oferecidas pelo aplicativo, que havia uma distribuição não uniforme em relação à interação dos usuários em diferentes situações, assim, demonstrando uma mudança comportamental dessas entidades em diferentes estados.
Neste contexto, será apresentado um algoritmo, responsável pela amostragem dos atores que compõem uma deteminada base de dados, através de grafos, e a análise de distribuição e relação das entidades estudadas. Para tal, o algoritmo coletará, de uma base de dados simulados de usuários do Facebook, diferentes relações, visando transformá-las em um grafo não-planar e definir medidas de centralidade para avaliar a formação de diferentes subconjuntos e a conexidade dos nós dentro da rede.

Fig. 1 Representação da base de dados por grafo
Para verificar os intervalos de vértices por cardinalidade de grau, ou seja, buscar atores com maior quantidade de relações na rede, implementei um algoritmo de busca em largura, que nos permite visitar e classificar cada nó do grafo, e um algoritmo de ordenação O(n²), responsável por permutar, em ordem decrescente, a posição de cada entidade de acordo com o grau.
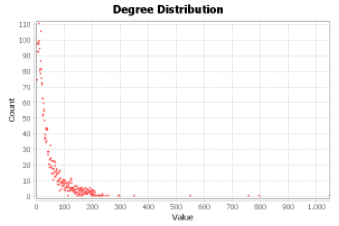
Fig. 2 Gráfico de distribuição de grau por intervalo de vértice
Para o cálculo do closeness, considerei um algoritmo de busca em largura, incumbido de percorrer o grafo, e o somatório dos caminhos de menor peso em relação a cada vértice do grafo através do algoritmo de Dijkstra, alocando-os em uma estrutura. Após esse procedimento, apliquei, novamente, o algoritmo de ordenação com a medida de closeness como parâmetro para verificar quais são os vértices mais próximos do centro de distribuição média e que, portanto, estão mais próximos de todos os outros nós.
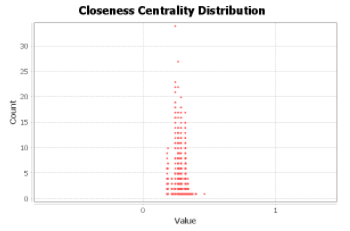
Fig. 3 Gráfico de distribuição de grau por intervalo de vértice
O conjunto de dados escolhido para a implementação do algoritmo foi definido através dos tipos dados coletados para realização da análise de rede proposta. Os dados que iremos estudar foram fornecidos pela Stanford Network Analysis Project e alterados para manter a privacidade dos atores que constituem a base de dados.
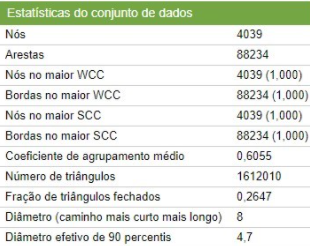
Tab. 1 Tabela de descrição quantitativa da base de dados
Durante a implementação do algoritmo foram utilizados o compilador GNU GCC, interface de desevolvimento CodeBlocks, versão 20.03, o software de visualização de grafos Gephi, versão 0.9.2, a linguagem de programação C/C++ e a biblioteca graphics.
[1] Universidade Federal de Alagoas (UFAL), Donizetti Calheiros Marques Barbosa Neto1 João Antônio da Rocha Ataíde1 Claudio Zancan, “ANÁLISE DE REDES SOCIAIS NA PRODUÇÃO CIENTÍFICA DE PROGRAMAS DE PÓS-GRADUAÇÃO EM ADMINISTRAÇÃO PÚBLICA NO BRASIL”, 25/05/2017
[2] Guilherme Siqueira Bez, Rafael Ávila Faraco, Maria Terezinha Angeloni, “Aplicação da Técnica de Análise de Redes Sociais em uma Instituição de Ensino Superior”, 30/11/2010
[3] Universidade Federal do Rio de Janeiro, Regina Maria Marteleto, “Análise de redes sociais – aplicação nos estudos de transferência da informação”, 04/2001
[4] Universidade Federal do Rio de Janeiro, Victor Ribeiro Neto, “ANÁLISE DE COMPORTAMENTO DO USUÁRIO EM REDES SOCIAIS VEICULARES”, 06/2017
[5] Neil J. Smelser e Paul B. Batles, “International Encyclopedia of the Social & Behavioral Sciences”, publicado pela Elsevier, 2001
[6] University of Maryland, Jennifer J. Preece, “Analyzing the Social Web” 09/2013
Obs: O projeto submetido neste repositório compreende uma das atribuições requisitadas para o cumprimento da eletiva Algoritmos e Estruturas de Dados II, prevista pela Universidade Federal de São Paulo como parte das competências instrínsecas ao curso de Bacharelado em Ciência da Computação.