This is the code repo of paper "Stochastic resource optimization over heterogeneous graph neural networks for failure-predictive maintenance scheduling" published in the 32nd International Conference on Automated Planning and Scheduling (ICAPS) 2022.
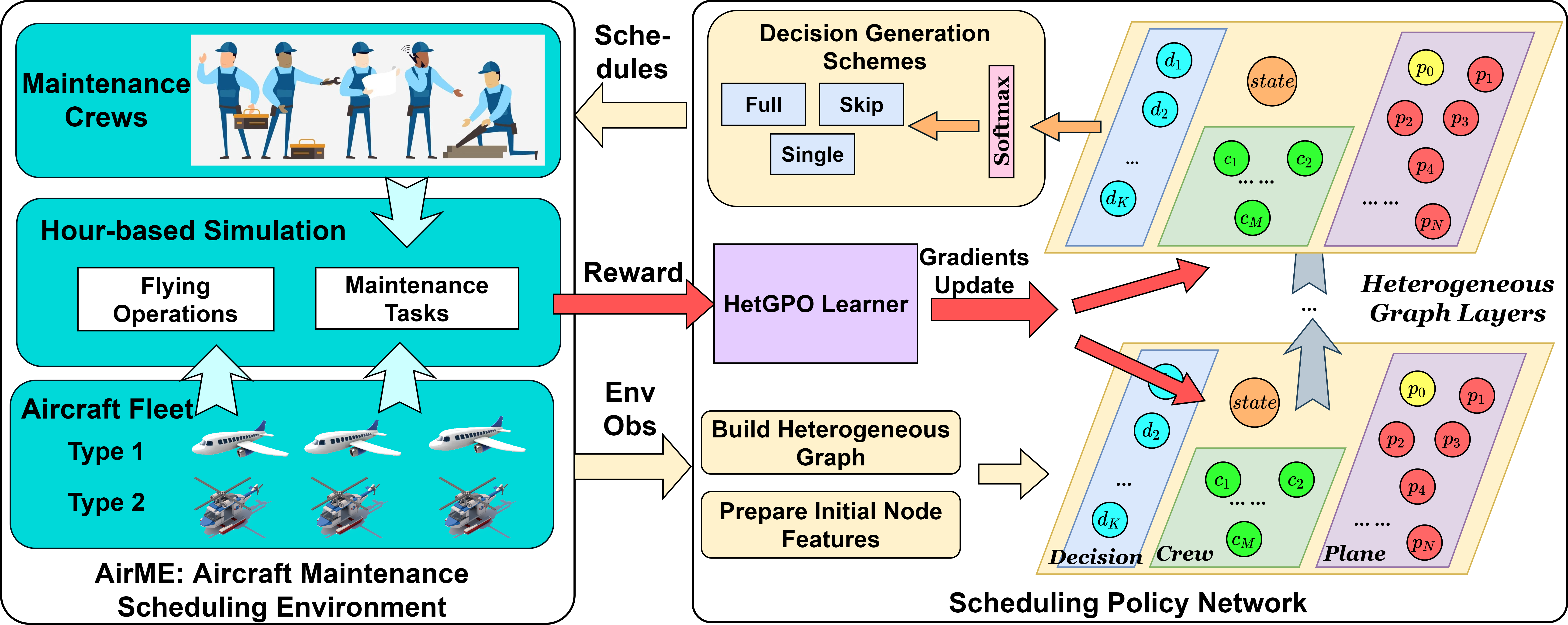
AirME Implementation
RepairEnv utils.py
HetGPO Implementation
Heterogeneous graph layer \graph\hetgatv2.py
Policy network hetnet.py
Scheduler & Learner gposcheduler.py
Training code train_gpo.py
Ablation studies train_value.py
RL baselines: DeepRM & Decima
basenet.py & basescheduler.py & train_base.py
Data generattion
datagen.py
Heuristic Implementation & Model-based Scheduler
heuristics.py
Evaluation Code
\benchmark
base_eval.py
count_results.py
eval_multi.py
gpo_eval.py
M2.py
periodic_eval.py
plot_train.py
Python 3.7.10
cudatoolkit 11.1.74
dgl-cuda11.1 0.6.1
matplotlib 3.4.2
networkx 2.2
numpy 1.20.3
pytorch 1.9.0
scipy 1.6.2
# initialize plane parameters randomly
plane_info = get_default_param(25, 5, random_init = True, percent_broken = 0.05)
# create an AirME instance
r = RepairEnv(25, 5,
plane_info['num_parts_list'], plane_info['scale_lists'],
plane_info['shape_lists'], plane_info['prob_uses'], plane_info['hour_scales'],
plane_info['hours_list'], plane_info['num_landings_list'],
plane_info['broken_list'], plane_info['reward_list'],
num_crews = 4)
# print info
print(r.total_hours, r.crews[2-1].progress, r.planes[10-1].task.progress)
# one step without scheduling decisions
r.step()
# with one scheduling decision: crew #2 to plane # 10
r.step(2, 10)
# print sampled task duration & updated info
print('task duration %d' % r.planes[10-1].task.duration)
print(r.total_hours, r.crews[2-1].progress, r.planes[10-1].task.progress)
# with multiple scheduling decisions
cost, reward, avail_count = r.step_multi(crew_list, plane_list)HetGPO-Full
python train_gpo.py --folder R1md01 --Rtype R1 --Stype MD --lr 1e-3 --lr_gamma 0.4 --ent_coef 0.02
HetGPO-Skip
python train_gpo.py --folder R1void01 --Rtype R1 --Stype void --lr 1e-3 --lr_gamma 0.4 --ent_coef 0.01
HetGPO-Single
python train_gpo.py --folder R1sd01 --Rtype R1 --Stype SD --lr 5e-4 --lr_gamma 0.4 --ent_coef 0.01
Use --Stype to specify decision generation schemes.
assert Stype in ['void', 'MD', 'SD']Use --Rtype to specify environment reward/objective function type.
assert Rtype in ['R1', 'R2', 'R3']Note: All evaluation commands should be run inside the benchmark folder
We provide trained models used in the paper here
Evaluation data set can be downloaded here
Full results can be downloaded here
HetGPO-Full
python gpo_eval.py --checkpoint ../models/R1_gpomd.tar --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/gpomd --end-no 100 --Rtype R1 --Stype MD
HetGPO-Skip
python gpo_eval.py --checkpoint ../models/R1_gpovoid.tar --data-folder ../testdata/large --save-folder ../eval/R1/large/gpovoid --end-no 100 --Rtype R1 --Stype void
HetGPO-Single
python gpo_eval.py --checkpoint ../models/R2_gposd.tar --data-folder ../testdata/small --save-folder ../eval/R2/small/gposd --end-no 100 --Rtype R2 --Stype SD
Use --data-folder to specify test set and --save-folder to specify store location.
Random Scheduler
python eval_multi.py --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/ --h-type random --Rtype R1
Corrective Scheduler
python eval_multi.py --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/ --h-type simple --Rtype R1
Condition-based Scheduler
python eval_multi.py --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/ --h-type hybrid_hour --hy-th 40 --Rtype R1
Periodic Scheduler
python periodic_eval.py --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge --interval 6 --Rtype R1
Model-based Planning
python eval_multi.py --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/ --Rtype R1 --h-type prob --hy-th 4
DeepRM Train
python train_base.py --folder ./exlargeR1drm01 --Rtype R1 --Stype drm --lr 1e-3 --total_batches 4000 --ep_start 200.0 --ep_length 0.01 --scale extra
DeepRM Evaluation
python base_eval.py --checkpoint ../exlargeR1drm01/R1_exlarge_drm.tar --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/drm01 --end-no 100 --Rtype R1 --Stype drm --scale extra
Decima Train
python train_base.py --folder ./R1decima01 --Rtype R1 --Stype decima --lr 1e-3 --total_batches 5000
Decima Evaluation
python base_eval.py --checkpoint ../models/R1_decima.tar --data-folder ../testdata/exlarge --save-folder ../eval/R1/exlarge/decima --end-no 100 --Rtype R1 --Stype decima