Welcome to this repository about Cross-Validation 📂, an essential technique in Machine Learning for evaluating a model's generalization performance. You'll find theory and a hands-on Python exercise.
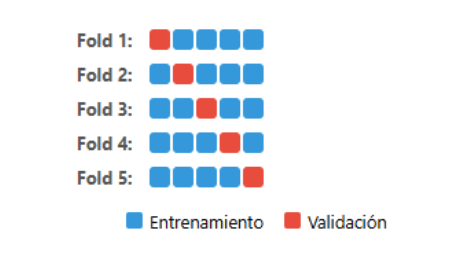
- What is Cross-Validation?
- Generalization and Expected Risk
- Types of Validation
- Practical Exercise
- Advantages and Disadvantages
- Presentation
- Contributors
Cross-Validation is a technique to estimate how well a machine learning model will perform on unseen data. It splits the dataset into "folds" and repeatedly trains on some folds while testing on others.
👉 Goal: Minimize generalization error (Expected Risk) and prevent overfitting.
When we train a model, we want it to perform well not just on training data but also on new, unseen data — this is called generalization.
| Concept | Definition |
|---|---|
| 📈 Expected Risk | The model’s error on new, unseen data. |
| 🏋️ Empirical Risk | The model’s error on training data. |
| 🔥 Overfitting | When a model has low training error but high error on new data. |
| 🔍 Cross-Validation | A technique to estimate the expected risk by splitting data and averaging results. |
| Type | Description | Pros | Cons | When to Use |
|---|---|---|---|---|
| Hold-Out | Splits dataset into training and validation sets. | Simple, fast. | Sensitive to split randomness. | Large datasets or quick evaluations. |
| K-Fold (K=5) | Splits into K parts; each fold is test once. | Balances bias and variance. | Can be slow on large models. | Robust estimates without extreme costs. |
| Stratified K-Fold | Like K-Fold but preserves class proportions. | Respects class imbalance. | Only for classification. | Classification tasks with imbalanced classes. |
| LOOCV (Leave-One-Out) | Each point is a test set once. | Almost unbiased. | Very costly, high variance. | Small datasets or theoretical cases. |
| Group K-Fold | Like K-Fold but keeps groups (users, patients...) intact. | Prevents data leakage within groups. | Depends on group sizes. | Data with group dependencies. |
| Time Series Split | Respects time order; uses past data to predict future. | Essential for time series. | Less data for training at the start. | Forecasting and causal models. |
| Nested CV | Two-level validation: outer loop for model eval, inner for hyperparameter tuning. | Rigorous, prevents data leakage. | Very computationally expensive. | Model comparison or tuning in research. |
- This repository includes a hands-on Cross-Validation exercise using the Iris dataset from Scikit-learn.
- ✅ Don’t forget to run the file and explore results across different models!
✅ Advantages:
-
More robust performance estimation.
-
Reduces the risk of overfitting.
-
Useful for small to medium datasets.
-
More computationally expensive.
-
Slower for large datasets and models.
-
May need adaptation for specific data types (time series, classification, etc.).
You can access the presentation on Cross Validation at the following Canva link:
-
This repository was created by:
Thank you for visiting! If you find this helpful, give it a ⭐️ on the repo. 🚀