Unofficial implementation of Miipher-2: High-quality speech enhancement via HuBERT + Parallel Adapter
Key Features • Demo • Quick Start • Model Zoo • Training • Evaluation • Citation
- Speech enhancement based on Miipher-2 architecture
- Lightweight Parallel Adapter design for efficient feature adaptation
- Pre-trained models available on 🤗 Hugging Face
- Comprehensive evaluation pipeline with multiple metrics
Experience the power of our model speech enhancement:
| 🔊 Degraded Audio | ✨ Enhanced Audio |
|---|---|
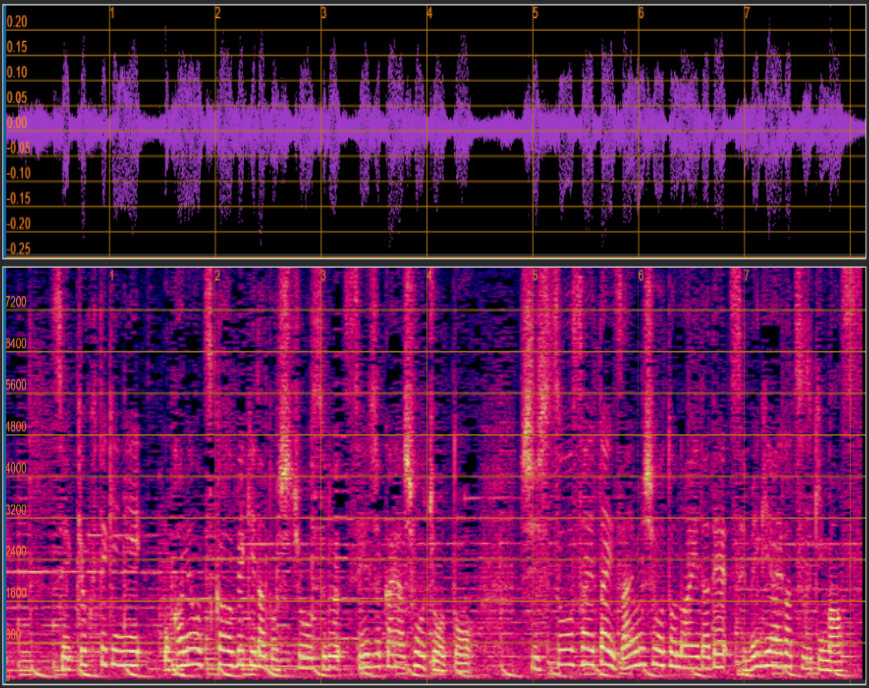
Noisy input |
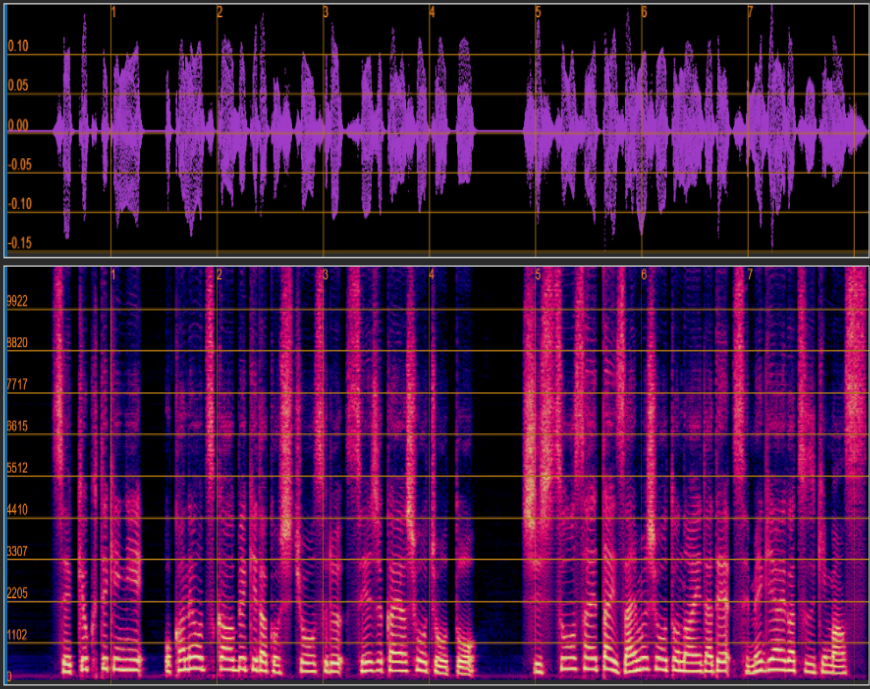
Clean output |
# Install dependencies using uv
uv syncopen-miipher-2/
├── configs/ # Hydra configuration files
├── src/miipher_2/ # Core Python modules
├── cmd/ # CLI entry points
├── exp/ # Model checkpoints
└── docs/ # Documentation
Use our pre-trained model for instant speech enhancement:
# Download pre-trained model from Hugging Face
# Model: miipher-2-HuBERT-HiFi-GAN-v0.1
# Run inference on your audio files
uv run cmd/inference_dir.py --config-name infer_dir| Model | SSL Backbone | Adapter Layers | Vocoder | Download |
|---|---|---|---|---|
| miipher-2 HuBERT HiFi-GAN v0.1 | mHuBERT-147 | Layer 6 | HiFi-GAN | 🤗 HuggingFace |
Generate pseudo-degraded dataset from clean speech:
# Process JVS corpus (Japanese)
uv run cmd/preprocess.py --config-name preprocess_jvs
# Process LibriTTS (English)
uv run cmd/preprocess.py --config-name preprocess_libritts_r
# Process FLEURS (Multilingual)
uv run cmd/preprocess.py --config-name preprocess_fleurs_rOutput is saved in WebDataset format for efficient data loading.
# Train adapter module
uv run cmd/train_adapter.py --config-name adapter_layer_6_mhubert_147
# Resume from checkpoint
uv run cmd/train_adapter.py \
checkpoint.resume_from="exp/adapter_layer_6_mhubert_147/checkpoint_199k.pt" \
--config-name adapter_layer_6_mhubert_147# Pre-train Lightning SSL-Vocoder
uv run cmd/pre_train_vocoder.py --config-name hifigan_pretrain_layer_6_mhubert_147💡 Note: Configuration is automatically inherited from checkpoint unless explicitly overridden.
Create evaluation dataset with various noise conditions:
uv run cmd/degrade.py \
--clean_dir <path_to_clean_audio> \
--noise_dir <path_to_noise_samples> \
--out_dir <output_directory>Process degraded audio through the model:
uv run cmd/inference_dir.py --config-name infer_dirEvaluate enhancement quality with multiple metrics:
uv run cmd/evaluate.py \
--clean_dir <clean_audio_dir> \
--degraded_dir <degraded_audio_dir> \
--restored_dir <enhanced_audio_dir> \
--outfile results.csvMetrics include:
- PESQ (Perceptual Evaluation of Speech Quality)
- STOI (Short-Time Objective Intelligibility)
- SI-SDR (Scale-Invariant Signal-to-Distortion Ratio)
- MOS-LQO (Mean Opinion Score)

- HuBERT Feature Extractor: Multilingual HuBERT (mHuBERT-147) for robust speech representations
- Parallel Adapter: Lightweight feed-forward network inserted at specific layers
- Feature Cleaner: Denoising module operating on SSL features
- Lightning SSL-Vocoder: HiFi-GAN-based vocoder
All configurations are managed through Hydra. Key config files:
configs/adapter_layer_6_mhubert_147.yaml- Adapter trainingconfigs/infer_dir.yaml- Inference settingsconfigs/preprocess_*.yaml- Data preprocessing