On-device Conv-SAE for interpretable, privacy-safe radiology assistance.
Flags pathology-relevant regions, links them to report text, and surfaces misses—without cloud or colossal models.
Hackathon Project built in 36 hours. Click below for video demo:
Reading CT/X-ray studies means scrolling through countless frames to spot small, high-stakes findings. Cloud tools are often blocked by privacy rules; giant ViTs are costly to train/host locally. RadiSpect uses a lightweight Convolutional Sparse Autoencoder (Conv-SAE) to produce interpretable evidence masks on CPU-only hardware, acting as a second set of eyes for clinicians and learners.
To the best of our knowledge (Aug 10, 2025), RadiSpect is the first on-device, CPU-only Conv-SAE used for unsupervised, evidence-grounded localization in chest X-rays, where each accepted finding is backed by a single-latent ablation mask.
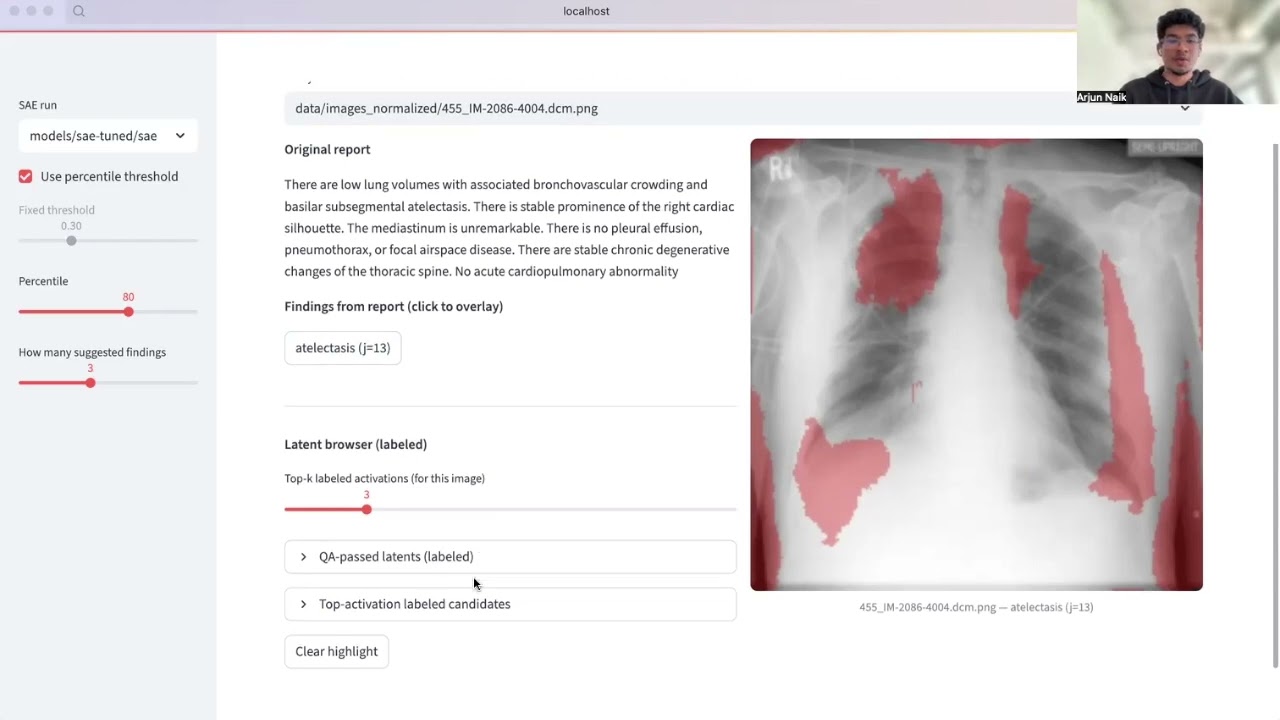
- Safe Spans (peer review of existing reports): Click a finding in the report -> see the corresponding latent-derived mask over the image. Quickly spot potential misses via high-activation latents not mentioned in the report.
- Clinician Assist (drafting a new report): See top-activated latents and their masks to guide where to look; accept useful ones, ignore false positives.
- Report Cross-Check (QA): If you wrote a report, RadiSpect flags high-activation latents that weren’t covered in your text.
Design principles
- Private by default: Fully local, no network/API calls required.
- Adaptable: Train/tune the SAE on your own data; same workflow extends to CT with retraining (no big architectural changes).
Image ──▶ Conv Encoder ──▶ Sparse Bottleneck (Conv-SAE) ──▶ Conv Decoder ──▶ Reconstruct
│
├─▶ Top-K / L1-sparse latents → (per-latent) ablation:
│ set z_i=0, reconstruct', delta = |recon - recon'| -> threshold -> mask_i
│
└─▶ Latent labels: mine common phrases from reports of top-activating images (v0)
- Masks via ablation: Zero one latent, measure reconstruction delta, threshold to a mask, overlay on the original image.
- Labels via mining (v0): For each latent, collect reports from images where it fires strongly; extract frequent phrases as a label.
- Retrain on CT slices (HU-windowed axial or short 2.5D stacks).
- Same Conv-SAE + ablation-to-mask method; expect longer training.
- Optional volume aggregation: max/mean energy across slices to surface top-N frames.
- Unsupervised masks are not clinical segmentations. They are evidence hints for human review.
- False positives happen. Clinicians should ignore irrelevant regions; no mask means no claim.
- Dataset bias: For real deployment, retrain/tune on your institution’s data.
If you use RadiSpect in a project or paper, please cite the repo.
Questions? Reach out to arjunsn@uw.edu