This project is part of the Udacity Azure ML Nanodegree. In this project, we build and optimize an Azure ML pipeline using the Python SDK and a provided Scikit-learn model. This model is then compared to an Azure AutoML run.
This dataset contains data about clients / prospective for cold-calling regarding financial / banking products offer we seek to predict data value (outcome or lastcolumn 'y') based on the prior observations provided in the dataset. For that we'll compare 2 methods to fine the best performing model :
- first with a python script + Hyperdrive tuning
- second with using autoML.
The best methodology in this case look to be with the use of autoMl with a classification model and a VotingEnsemble algorithm.
Explain the pipeline architecture, including data, hyperparameter tuning, and classification algorithm.
The Scikit-learn Pipline in the train.py file is based on the following main parts:
-
A Collection of data. In here we pick the data .csv from a public url, and pass it into a Dataset.
-
A cleaning function. In this function which takes the Dataset as input, we clean the data in order for it to be easily processes by algorithm - months and days are replaced by numerical values - one-hot encoding of categorical data (marital, housing, loan...)
2 dataframes are returned from this function.
-
A splitting function, leaving 33% of data for testing in a random fashion
-
Finally in the main - the parameters for the LogisticRegression are given to the model (maximal number of iteration & Inverse of regularization strength) - the scoring metric is set for Accuracy with the test data - and the model is saved in a folder outputs (so that the model in train.py could be run and saved seperately)
With the help of Hyperdrive, we can further tweak the before-set-up model:
- Setting up random parameer sampling on both the maximal number of iteration & Inverse of regularization strength.
- Giving a stopping policy
- Creating a SKLearn estimator
- And Finally making sure the compute cluster previsouly created is used for the run.
What are the benefits of the parameter sampler you chose?
"--max_iter": choice(5,10,25,100,1000)" Allows for a wide array of comparison when using bigger number iterations. This can help selecting the appropriate iteration number for a wished accuracy.
"--C": uniform(0.1, 1) Here, instead of giving a choice in a discrete number of value we specify a uniform distribution of regularization stength tested between 0.1 to 1.
What are the benefits of the early stopping policy you chose?
policy = BanditPolicy(evaluation_interval=3, slack_factor=0.1) - This exit policy is mostly set as "low" so that I can test properly the model without having a "too soon" stop. Nevertheless once slack-factor of 0.1 to the best_run perfomance is reached I'm assured with this policy that the run of model will stop.
In 1-2 sentences, describe the model and hyperparameters generated by AutoML.
In the second part of the project we use AutoML to replicate the prediction. In this part we do not specify which algorithm to use and let the autoML service test out different ones wihtin the boundaries given in the config (less then 30 minutes run, focusing on accuracy, cleaning the data with the same function, and trying to predict the column 'y').
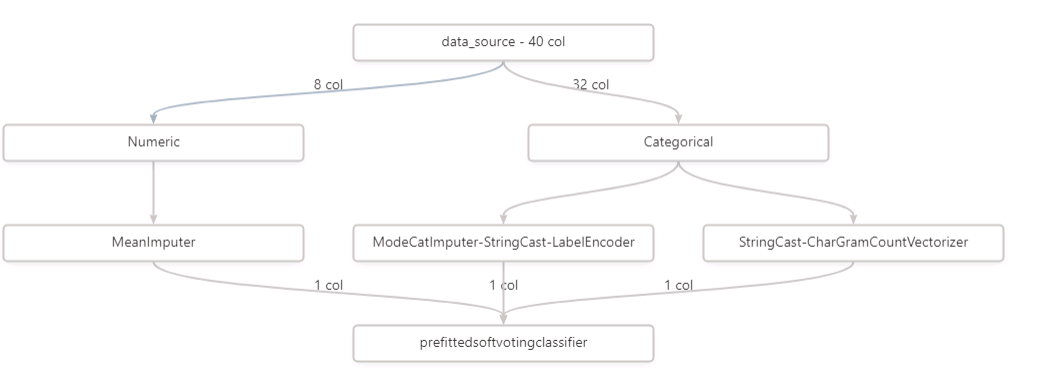
Compare the two models and their performance. What are the differences in accuracy? In architecture? If there was a difference, why do you think there was one?
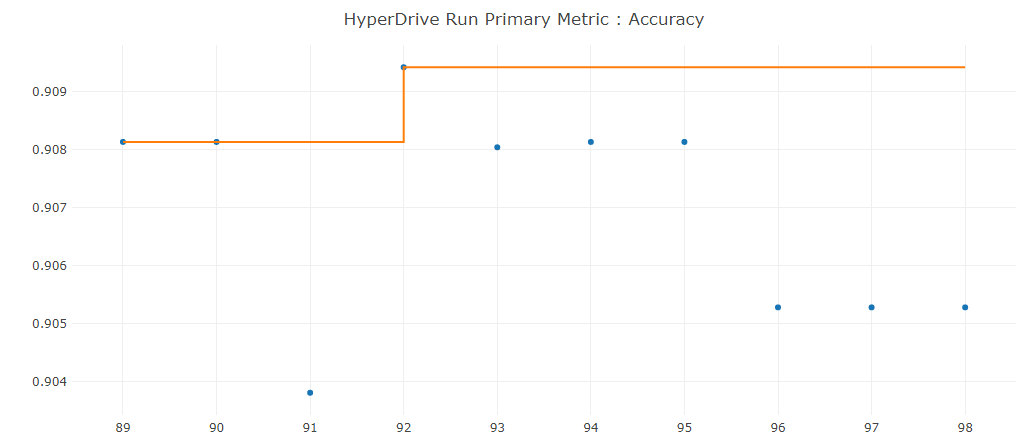
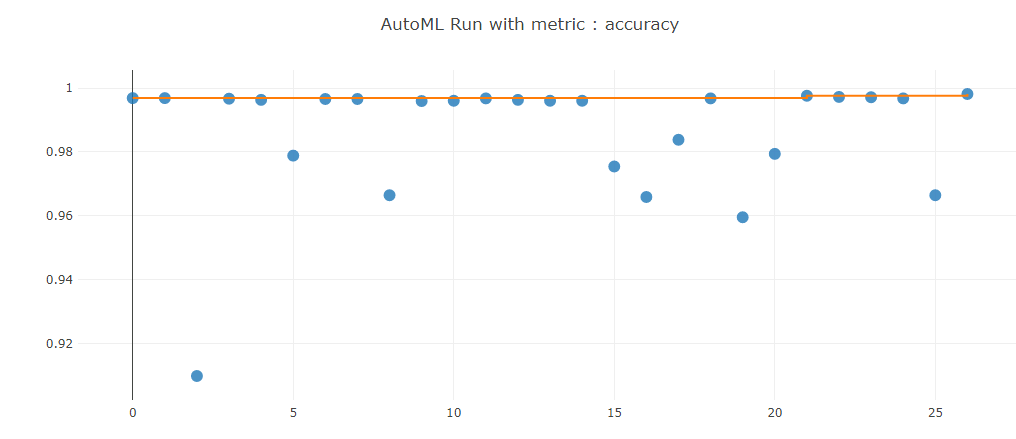
Generally speaking the autoML model performance were higher with .08% (90-91% for the first part and 98% with autoML). The main difference lies in the multitude of different algorithm used in autoML compared only to Logistic Regression.
Accuracy of the model without AutoML:
Accuracy of the autoML Model:
Architecture differences lie mainly in the fact that the first model is actually run from a python script, whereas the second part is all run using azureML components. This could lead in some perormance and or difficulty if such a set up would be deployed (eg.mainteance / improvement ...)
What are some areas of improvement for future experiments? Why might these improvements help the model?
I believe a first step of improvement would be to run the first model with another classification algorithm (eg. voting Ensemble) and compare again with autoML results.
In order to improve further experiments I would also exclude low scored algorithm and focus solely on the top performing, maybe testing on the larger dataset (or newer) but also allowing more iterations.
If you did not delete your compute cluster in the code, please complete this section. Otherwise, delete this section.
