You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Полное объяснение того, как работает YDB, получилось бы слишком объемным. Ниже вы можете ознакомиться с несколькими основными моментами, а затем продолжить изучение документации, чтобы узнать больше.
3
+
Полное объяснение того, как работает {{ ydb-short-name }}, получилось бы слишком объемным. Ниже вы можете ознакомиться с несколькими основными моментами, а затем продолжить изучение документации, чтобы узнать больше.
Кластеры YDB обычно работают с shared nothing архитектурой на обычном оборудовании. Уровни вычислений и хранения являются разнёсенными. Они могут работать как на отдельных наборах узлов, так и быть совмещёнными.
9
+
Кластеры {{ ydb-short-name }} обычно работают с shared nothing архитектурой на обычном оборудовании. Уровни вычислений и хранения являются разнёсенными. Они могут работать как на отдельных наборах узлов, так и быть совмещёнными.
10
10
11
-
Один из ключевых элементов вычислительного слоя YDB называется *таблеткой*. Они являются логическими компонентами с состоянием, реализующими различные аспекты YDB.
11
+
Один из ключевых элементов вычислительного слоя {{ ydb-short-name }} называется *таблеткой*. Они являются логическими компонентами с состоянием, реализующими различные аспекты {{ ydb-short-name }}.
12
12
13
-
Более подробная информация об общей архитектуре YDB объясняется в разделе [документации о кластерах YDB](../../cluster/index.md).
13
+
Более подробная информация об общей архитектуре {{ ydb-short-name }} объясняется в разделе [документации о кластерах YDB](../../cluster/index.md).
С точки зрения пользователя, всё внутри YDB организовано в иерархической структуре с использованием каталогов. Она может иметь произвольную глубину в зависимости от того, как вы решили организовать свои данные и проекты. Хотя YDB не имеет фиксированной глубины иерархии, как в других реализациях SQL, она все равно будет знакома, поскольку именно так выглядит любая виртуальная файловая система.
19
+
С точки зрения пользователя, всё внутри {{ ydb-short-name }} организовано в иерархической структуре с использованием каталогов. Она может иметь произвольную глубину в зависимости от того, как вы решили организовать свои данные и проекты. Хотя YDB не имеет фиксированной глубины иерархии, как в других реализациях SQL, она все равно будет знакома, поскольку именно так выглядит любая виртуальная файловая система.
YDB предоставляет пользователям хорошо известную абстракцию: таблицы. В YDB таблицы должны содержать первичный ключ, данные физически сортируются по первичному ключу. Таблицы автоматически шардируются по диапазонам первичных ключей в зависимости от нагрузки и объема данных. Каждый диапазон первичных ключей таблицы обрабатывается определенной таблеткой, называемой *data shard*.
25
+
{{ ydb-short-name}} предоставляет пользователям хорошо известную абстракцию — таблицы. В {{ ydb-short-name }} существует два основных типа таблиц:
26
+
*[Строковые таблицы](../../datamodel/table.md#row-tables) предназначены для OLTP-нагрузок.
27
+
*[Колоночные таблицы](../../datamodel/table.md#column-tables) предназначены для OLAP-нагрузок.
28
+
29
+
Логически, с точки зрения пользователя, оба вида таблиц выглядят одинаково. Основное отличие между строковыми и колоночными таблицами заключается в способе хранения данных. В строковых таблицах значения всех колонок каждой строки располагаются рядом, а в колоночных таблицах — наоборот, каждая колонка хранится отдельно, и рядом оказываются ячейки, относящиеся к разным строкам.
30
+
31
+
Независимо от типа таблицы, она должна содержать первичный ключ. В первичном ключе колоночных таблиц можно использовать только колонки с `NOT NULL`. Данные в таблицах физически сортируются по первичному ключу. Строковые таблицы автоматически партицируются по диапазонам первичных ключей в зависимости от объёма данных, а данные в колоночных таблицах партицируются не по первичному ключу, а по хешу от колонок партицирования. Каждый диапазон первичных ключей таблицы обрабатывается определённой [таблеткой](../../cluster/common_scheme_ydb.md#tablets), называемой *data shard* для строчных таблиц и *column shard* — для колоночных.
26
32
27
33
#### Разделение по нагрузке
28
34
@@ -40,16 +46,16 @@ Data shard также автоматически разделяются при
YDB равномерно распределяет таблетки среди доступных узлов. Она перемещает тяжело загруженные таблетки с перегруженных узлов. Метрики CPU, памяти и сети отслеживаются для облегчения этого процесса.
49
+
{{ ydb-short-name }} равномерно распределяет таблетки среди доступных узлов. Она перемещает тяжело загруженные таблетки с перегруженных узлов. Метрики CPU, памяти и сети отслеживаются для облегчения этого процесса.
44
50
45
51
### Внутреннее устройство распределенного хранилища
46
52
47
53
48
54
49
-
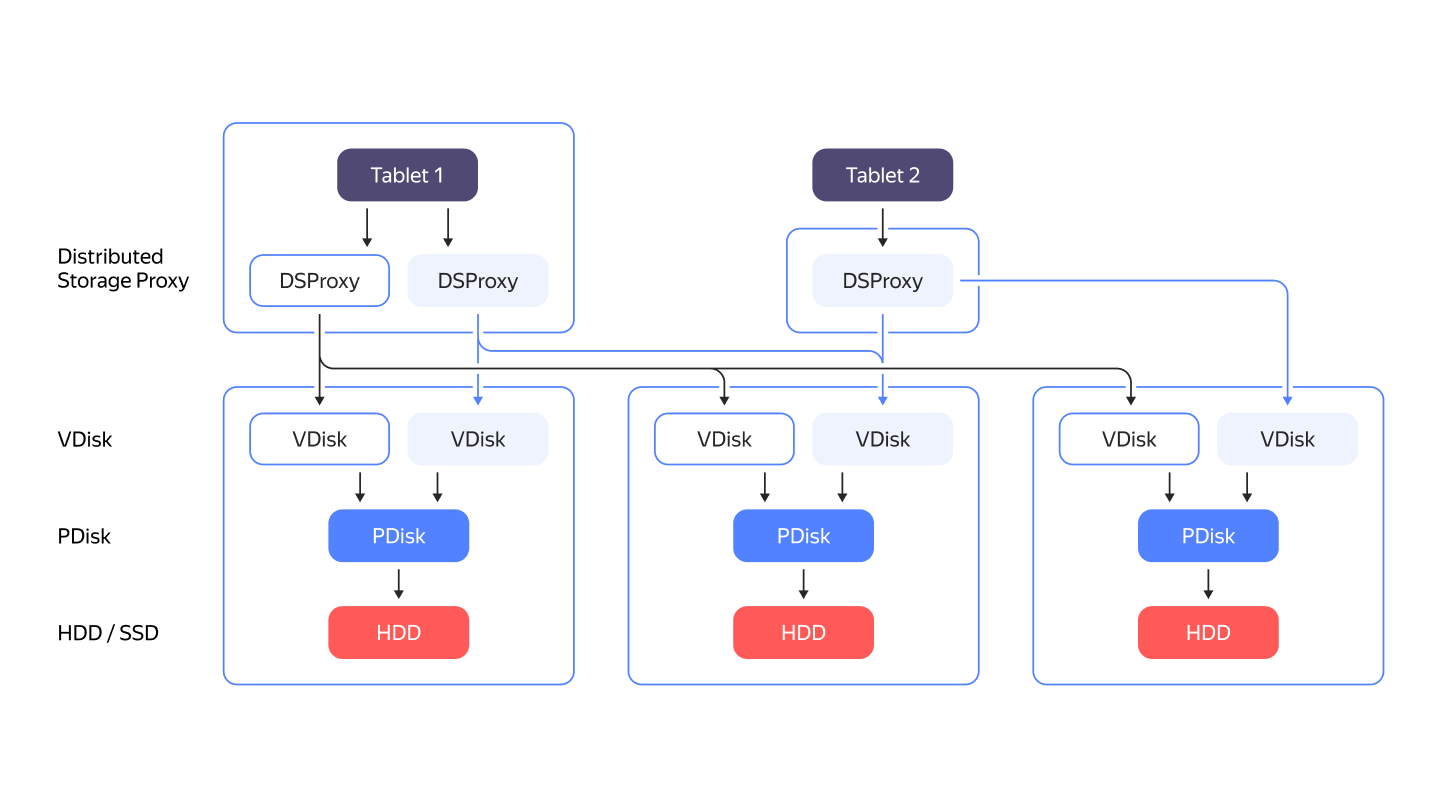
YDB не полагается на сторонние файловые системы. Она хранит данные, работая непосредственно с дисковыми накопителями как блочными устройствами. Поддерживаются все основные типы дисков: NVMe, SSD или HDD. За работу с конкретным блочным устройством отвечает компонент PDisk. Уровень абстракции выше PDisk называется VDisk. Также есть специальный компонент, называемый DSProxy, между таблеткой и VDisk. DSProxy анализирует доступность и характеристики дисков и выбирает, какие диски будут обрабатывать запрос, а какие нет.
55
+
{{ ydb-short-name }} не полагается на сторонние файловые системы. Она хранит данные, работая непосредственно с дисковыми накопителями как блочными устройствами. Поддерживаются все основные типы дисков: NVMe, SSD или HDD. За работу с конкретным блочным устройством отвечает компонент PDisk. Уровень абстракции выше PDisk называется VDisk. Также есть специальный компонент, называемый DSProxy, между таблеткой и VDisk. DSProxy анализирует доступность и характеристики дисков и выбирает, какие диски будут обрабатывать запрос, а какие нет.
Геораспределенная и отказоустойчивая конфигурация YDB обычно охватывает 3 датацентра или зоны доступности (Availability Zone - AZ). Когда YDB записывает данные на 3 зоны доступности, он не отправляет запросы на явно некорректные диски и продолжает работать без прерываний даже если одна зона доступности и диск в другой зоне доступности потеряны.
61
+
Геораспределенная и отказоустойчивая конфигурация {{ ydb-short-name }} обычно охватывает 3 датацентра или зоны доступности (Availability Zone - AZ). Когда {{ ydb-short-name }} записывает данные на 3 зоны доступности, он не отправляет запросы на явно некорректные диски и продолжает работать без прерываний даже если одна зона доступности и диск в другой зоне доступности потеряны.
Copy file name to clipboardExpand all lines: ydb/docs/ru/core/concepts/_includes/index/intro.md
+2-2Lines changed: 2 additions & 2 deletions
Original file line number
Diff line number
Diff line change
@@ -17,11 +17,11 @@ description: 'YDB — это горизонтально масштабируем
17
17
18
18
Для взаимодействия с {{ ydb-short-name }} доступен [{{ ydb-short-name }} CLI](../../../reference/ydb-cli/index.md), а также [SDK](../../../reference/ydb-sdk/index.md) для C++, C#, Go, Java, Node.js, PHP, Python и Rust.
19
19
20
-
{{ ydb-short-name }} поддерживает реляционную [модель данных](../../../concepts/datamodel/table.md) и оперирует [таблицами](../../datamodel/table.md) с предопределенной схемой. Для удобства организации таблиц поддерживается создание директорий по аналогии с файловой системой. Помимо таблиц {{ ydb-short-name }} поддерживает [топики](../../topic.md), которые представляют собой сущность для хранения неструктурированных сообщений и доставки их множеству подписчиков.
20
+
{{ ydb-short-name }} поддерживает реляционную модель данных и оперирует [строковыми](../../datamodel/table.md#row-tables) и [колоночными](../../datamodel/table.md#column-tables) таблицами с предопределенной схемой. Для удобства организации таблиц поддерживается создание директорий по аналогии с файловой системой. Помимо таблиц {{ ydb-short-name }} поддерживает [топики](../../topic.md), которые представляют собой сущность для хранения неструктурированных сообщений и доставки их множеству подписчиков.
21
21
22
22
В качестве основного способа формирования команд к базе данных используется язык YQL, являющийся диалектом SQL. Таким образом, пользователю предлагается мощный и, в то же время, привычный способ взаимодействия с БД.
23
23
24
-
В {{ ydb-short-name }} поддерживаются высокопроизводительные распределенные [ACID](https://en.wikipedia.org/wiki/ACID_(computer_science))-транзакции, которые могут затрагивать несколько записей из разных таблиц. Обеспечивается самый строгий уровень изоляции транзакций — serializable. Также имеется возможность ослабления уровня изоляции для увеличения производительности.
24
+
В {{ ydb-short-name }} поддерживаются высокопроизводительные распределенные [ACID](https://en.wikipedia.org/wiki/ACID_(computer_science))-транзакции, которые могут затрагивать несколько записей из разных таблиц одного типа. Обеспечивается самый строгий уровень изоляции транзакций — serializable. Также имеется возможность ослабления уровня изоляции для увеличения производительности.
25
25
26
26
В дизайн {{ ydb-short-name }} заложена поддержка разных сценариев нагрузки, таких как [OLTP](https://en.wikipedia.org/wiki/Online_transaction_processing) и [OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing). В текущей реализации поддержка аналитических запросов ограничена. Поэтому можно говорить, что в данный момент {{ ydb-short-name }} — это OLTP-база данных.
Copy file name to clipboardExpand all lines: ydb/docs/ru/core/concepts/_includes/index/when_use.md
+1Lines changed: 1 addition & 0 deletions
Original file line number
Diff line number
Diff line change
@@ -9,3 +9,4 @@
9
9
* В системах с плохо предсказуемой или сезонно меняющейся нагрузкой (используя возможность добавления/уменьшения вычислительных ресурсов по запросу и/или в режиме бессерверных вычислений).
10
10
* В высоконагруженных системах, которые шардируют нагрузку между инстансами реляционной базы данных.
11
11
* При разработке нового продукта, для которого нет надежного прогноза будущей нагрузки, или ожидается большая нагрузка, превышающая возможности традиционных реляционных баз данных.
12
+
* В проектах, где требуются одновременная работа с транзакционными и аналитическими нагрузками.
Copy file name to clipboardExpand all lines: ydb/docs/ru/core/concepts/_includes/scan_query.md
+6-2Lines changed: 6 additions & 2 deletions
Original file line number
Diff line number
Diff line change
@@ -9,13 +9,13 @@
9
9
* Результат запроса — это стрим данных ([grpc stream](https://grpc.io/docs/what-is-grpc/core-concepts/)). Таким образом, у скан запросов нет лимита на количество строк в результате.
10
10
* Из-за высоких накладных расходов подходит только для ad-hoc запросов.
11
11
12
-
{% node info %}
12
+
{% note info %}
13
13
14
14
Через интерфейс *Scan Queries* можно выполнять запросы к [системным таблицам](../../dev/system-views.md).
15
15
16
16
{% endnote %}
17
17
18
-
На текущий момент скан запросы не могут считаться полноценным способом выполнения OLAP-запросов, поскольку они обладают рядом технических ограничений (которые со временем будут сняты):
18
+
Скан запросы не считаются полноценным способом выполнения OLAP-запросов, поскольку они обладают рядом технических ограничений (которые со временем будут сняты):
19
19
20
20
* Длительность запроса ограничена 5 минутами.
21
21
* Многие операции (включая сортировку) выполняются целиком в памяти, поэтому на сложных запросах можно получить ошибку нехватки ресурсов.
@@ -24,6 +24,8 @@
24
24
* Нет оптимизаций под точечные чтения и чтения небольших диапазонов данных.
25
25
* В SDK не поддерживается автоматический retry.
26
26
27
+
Для работы с OLAP-нагрузками в {{ ydb-short-name }} существует специализированный тип таблиц — [колоночные](../datamodel/table.md#column-tables) таблицы. Они хранят данные каждого столбца отдельно от других столбцов. Благодаря этому при выполнении запроса считываются только те столбцы, которые непосредственно участвуют в запросе.
28
+
27
29
{% note info %}
28
30
29
31
Несмотря на то, что *Scan Queries* явно не мешают выполнению OLTP-транзакций, они все же используют общие ресурсы базы: СPU, память, диск, сеть. Поэтому выполнение тяжелых запросов **может привести к голоданию по ресурсам**, что скажется на производительности всей базы.
0 commit comments