Replies: 3 comments 4 replies
-
|
When I open debug mode by setting os.environ, I find that row counting is consuming(34s). After row counting, writing stage costs 37s. Total cost time is 74s. pandas costs 36s. When I set return_type=arrow, no need to row counting but writing costs 60s. |
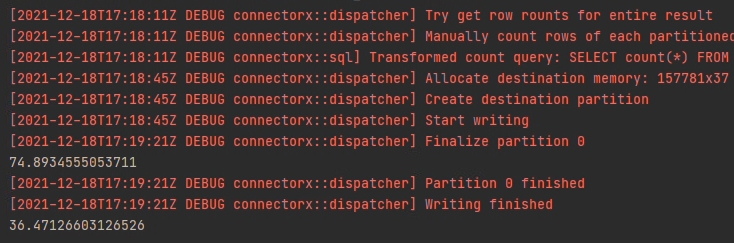
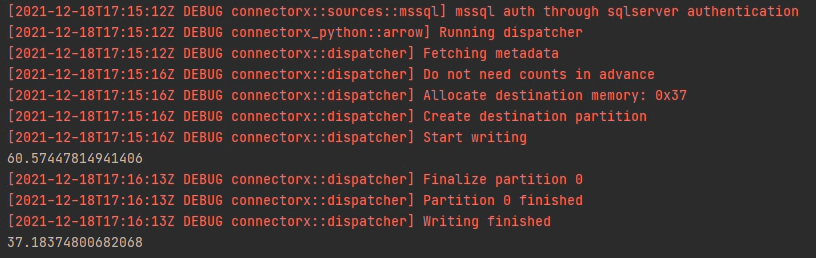
Beta Was this translation helpful? Give feedback.
-
|
https://github.com/sfu-db/connector-x/discussions/156 Oh I see... In MSSQL it will execute twice. Will you optimize getting metadata in MSSQL? |
Beta Was this translation helpful? Give feedback.
-
|
Hi @cufewxy , thanks for the example and the logs! In our benchmark, connectorx could achieve 5x less time than pandas. We directly select the TPC-H lineitem table, which has 60M rows and 16 columns using 4 partitions. We also tested connectorx using 1 partition and it outperforms pandas by >3x. connectorx is targeting on the large query result fetching scenario. It speeds up the process by optimizing the client-side execution as well as saturating both network and machine resource through parallelism. However, when query execution on the database server is the bottleneck (e.g. query execution time is long but the result is relatively small), the improvement ConnectorX could get will become minor and sometimes it can be even slower than Pandas due to the overhead in fetching metadata. It is interesting to see that in your case although the query is not very complex, the performance is worse than pandas. We can see if we could try to reproduce your case in our environment and see whether we could further improve it. It would be great if you could share more detailed information of the query with us:
We are currently trying to find a more efficient way to get schema in order to speed up the process for mssql. But I think in your case it is not the main issue (in figure 2 the schema fetching procedure only uses 4 seconds). |
Beta Was this translation helpful? Give feedback.
-
|
Thansk for replying. I tried again and connectorX performs better this time, all cost time is much shortter than yesterday(for connectorX, 8s VS 74s)... I mainly do finance analysis and this table records stock price timeseries. But neither code column nor date column is Integer so there's no appropriate column for partitioning. Will you support varchar column to be partitioned in the future? |
Beta Was this translation helpful? Give feedback.
-
|
Oh, that's great!
We don't have plan for this for now. We are still collecting the needs for this as well as more automatic ways to do query partitioning. But for non-numerical columns, a workaround is to manually partition the query. For example, if the columns is date: q1 = "select * from test where date < '2021-01-01'"
q2 = "select * from test where date >= '2021-01-01'"
df = cx.read_sql(url, [q1, q2])connectorx will return a single dataframe combine the result of the two queries |
Beta Was this translation helpful? Give feedback.
-
|
Thanks, it really works! When I split sql into 4 parts, it speeds up 4x. I plan to wrap read_sql func in which varchar column can be sent. First use |
Beta Was this translation helpful? Give feedback.
-
|
Awesome!
Yeah, for some simple queries, maybe mssql can leverage the index or collected statistics to directly answer the distinct query. (Not so sure about more complex ones, but I guess the overhead should be similar to the count query when the number of distinct value is not so large.) Looking forward to your wrapped function! |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hey, I have been trying to find a better module than pandas.read_sql and feel that it is almost there.
When I tried in mysql, connectorx performs better than pandas. But when I tried mssql, connectorx costs about 2x time than pandas(still connectorx's memory consuming is better).
The query is very simple: filter a table that one column is greater than a value. In pandas, I use pd.read_sql(xxx, engine) and engine is defined as sqlalchemy.create_engine('mssql+pymssql:xxx'). I also tried pyodbc and connectorx is again slower than pandas.
Beta Was this translation helpful? Give feedback.
All reactions