You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+34-26Lines changed: 34 additions & 26 deletions
Original file line number
Diff line number
Diff line change
@@ -8,15 +8,14 @@ Blazingly fast API-compatible UTF-8 validation for Rust using SIMD extensions, b
8
8
[simdjson](https://github.com/simdjson/simdjson). Originally ported to Rust by the developers of [simd-json.rs](https://simd-json.rs).
9
9
10
10
## Disclaimer
11
-
This software should be considered alpha quality and should not (yet) be used in production, though it has been tested
12
-
with sample data as well as a fuzzer and there are no known bugs. It will be tested more rigorously before the first
13
-
production release.
11
+
This software should not (yet) be used in production, though it has been tested with sample data as well as
12
+
fuzzing and there are no known bugs.
14
13
15
14
## Features
16
15
*`basic` API for the fastest validation, optimized for valid UTF-8
17
16
*`compat` API as a fully compatible replacement for `std::str::from_utf8()`
18
-
* Up to twenty times faster than the std library on non-ASCII, up to twice as fast on ASCII
19
-
*Up to 28% faster on non-ASCII input compared to the original simdjson implementation
17
+
* Up to 22 times faster than the std library on non-ASCII, up to three times faster on ASCII
18
+
*As fast as or faster than the original simdjson implementation
20
19
* Supports AVX 2 and SSE 4.2 implementations on x86 and x86-64. ARMv7 and ARMv8 neon support is planned
21
20
* Selects the fastest implementation at runtime based on CPU support
22
21
* Written in pure Rust
@@ -28,7 +27,7 @@ production release.
28
27
Add the dependency to your Cargo.toml file:
29
28
```toml
30
29
[dependencies]
31
-
simdutf8 = { version = "0.1.0" }
30
+
simdutf8 = { version = "0.1.1" }
32
31
```
33
32
34
33
Use `simdutf8::basic::from_utf8` as a drop-in replacement for `std::str::from_utf8()`.
@@ -59,7 +58,8 @@ is not valid UTF-8. `simdutf8::basic::Utf8Error` is a zero-sized error struct.
59
58
60
59
### Compat flavor
61
60
The `compat` flavor is fully API-compatible with `std::str::from_utf8`. In particular, `simdutf8::compat::from_utf8()`
62
-
returns a `simdutf8::compat::Utf8Error`, which has `valid_up_to()` and `error_len()` methods. The first is useful for verification of streamed data. The second is useful e.g. for replacing invalid byte sequences with a replacement character.
61
+
returns a `simdutf8::compat::Utf8Error`, which has `valid_up_to()` and `error_len()` methods. The first is useful for
62
+
verification of streamed data. The second is useful e.g. for replacing invalid byte sequences with a replacement character.
63
63
64
64
It also fails early: errors are checked on-the-fly as the string is processed and once
65
65
an invalid UTF-8 sequence is encountered, it returns without processing the rest of the data.
@@ -75,47 +75,56 @@ For no-std support (compiled with `--no-default-features`) the implementation is
75
75
the targeted CPU. Use `RUSTFLAGS="-C target-feature=+avx2"` for the AVX 2 implementation or `RUSTFLAGS="-C target-feature=+sse4.2"`
76
76
for the SSE 4.2 implementation.
77
77
78
-
If you want to be able to call A SIMD implementation directly, use the `public_imp` feature flag. The validation
78
+
If you want to be able to call a SIMD implementation directly, use the `public_imp` feature flag. The validation
79
79
implementations are then accessible via `simdutf8::(basic|compat)::imp::x86::(avx2|sse42)::validate_utf8()`.
80
80
81
81
## When not to use
82
-
If you are only processing short byte sequences (less than 64 bytes), the excellent scalar algorithm in the standard
83
-
library is likely faster. Also, this library uses unsafe code which has not been battle-tested and should not (yet)
84
-
be used in production.
82
+
This library uses unsafe code which has not been battle-tested and should not (yet) be used in production.
85
83
86
84
## Minimum Supported Rust Version (MSRV)
87
85
This crate's minimum supported Rust version is 1.38.0.
88
86
89
87
## Benchmarks
90
-
91
88
The benchmarks have been done with [criterion](https://bheisler.github.io/criterion.rs/book/index.html), the tables
92
89
are created with [critcmp](https://github.com/BurntSushi/critcmp). Source code and data are in the
since I could not get simdjson to reach maximum performance on Windows with any C++ toolchain (see also simdjson issues
106
+
[847](https://github.com/simdjson/simdjson/issues/847) and [848](https://github.com/simdjson/simdjson/issues/848)).
107
+
108
+
### simdutf8 basic vs simdjson UTF-8 validation on AMD Zen 2
109
+

102
110
103
-
### simdutf8 basic vs simdjson UTF-8 validation
104
-
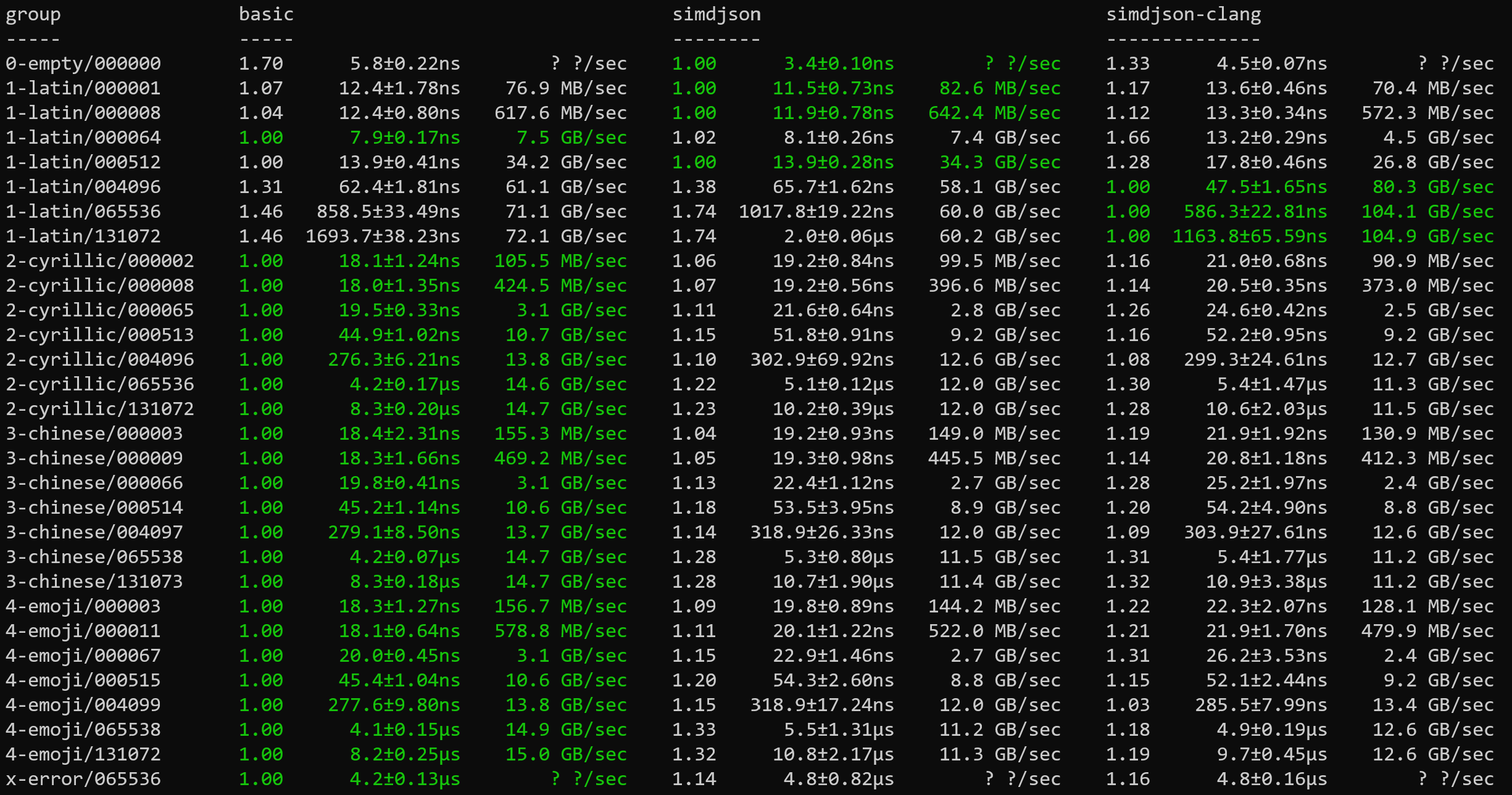
105
-
simdutf8 is faster than simdjson except for some crazy optimization by clang for the pure ASCII
106
-
loop (to be investigated). simdjson is compiled using clang and gcc from MSYS.
111
+
On AMD Zen 2 aligning reads apparently does not matter at all. The extra step for aligning even hurts performance a bit around
112
+
an input size of 4096.
107
113
108
114
### simdutf8 basic vs simdutf8 compat UTF-8 validation
109
-
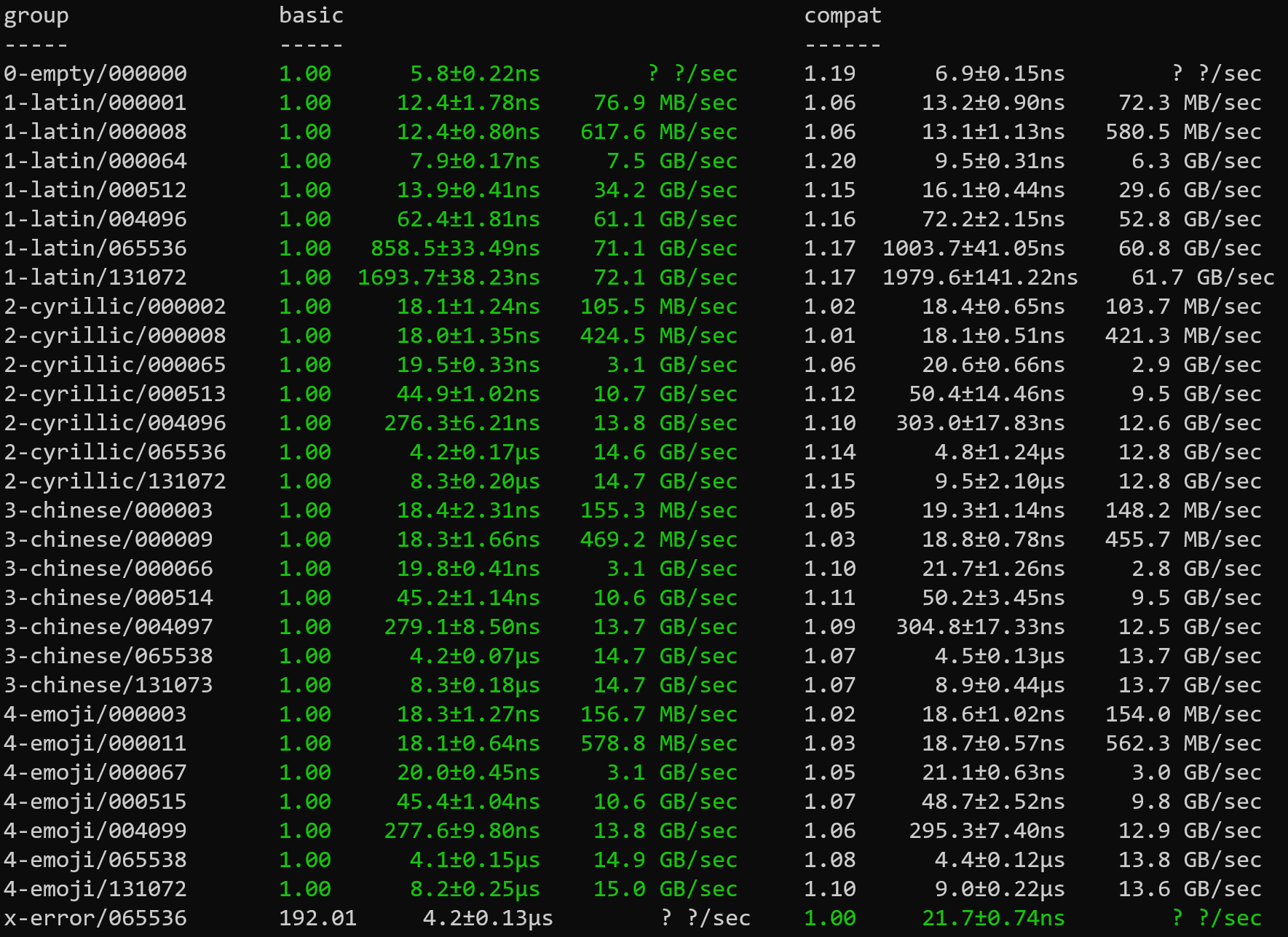
There is a small performance penalty to continuously checking the error status while processing data, but detecting
111
117
errors early provides a huge benefit for the _x-error/66536_ benchmark.
112
118
113
119
## Technical details
114
-
The implementation is similar to the one in simdjson except that it aligns reads to the block size of the
115
-
SIMD extension, which leads to better peak performance compared to the implementation in simdjson. This alignment
116
-
means that an incomplete block needs to be processed before the aligned data is read, which would lead to worse
117
-
performance on short byte sequences. Thus, aligned reads are only used with 2048 bytes of data or more. Incomplete
118
-
reads for the first unaligned and the last incomplete block are done in two aligned 64-byte buffers.
120
+
On X86 for inputs shorter than 64 bytes validation is delegated to `core::str::from_utf8()`.
121
+
122
+
The SIMD implementation is similar to the one in simdjson except that it aligns reads to the block size of the
123
+
SIMD extension, which leads to better peak performance compared to the implementation in simdjson on some CPUs.
124
+
This alignment means that an incomplete block needs to be processed before the aligned data is read, which
125
+
leads to worse performance on byte sequences shorter than 2048 bytes. Thus, aligned reads are only used with
126
+
2048 bytes of data or more. Incomplete reads for the first unaligned and the last incomplete block are done in
127
+
two aligned 64-byte buffers.
119
128
120
129
For the compat API we need to check the error buffer on each 64-byte block instead of just aggregating it. If an
121
130
error is found, the last bytes of the previous block are checked for a cross-block continuation and then
@@ -137,5 +146,4 @@ the MIT license and Apache 2.0 license.
137
146
simdjson itself is distributed under the Apache License 2.0.
138
147
139
148
## References
140
-
141
149
John Keiser, Daniel Lemire, [Validating UTF-8 In Less Than One Instruction Per Byte](https://arxiv.org/abs/2010.03090), Software: Practice and Experience 51 (5), 2021
0 commit comments