What exactly does open_mfdataset hold in memory? Whatever it is won't fit #6452
Unanswered
openSourcerer9000
asked this question in
Q&A
Replies: 1 comment
-
|
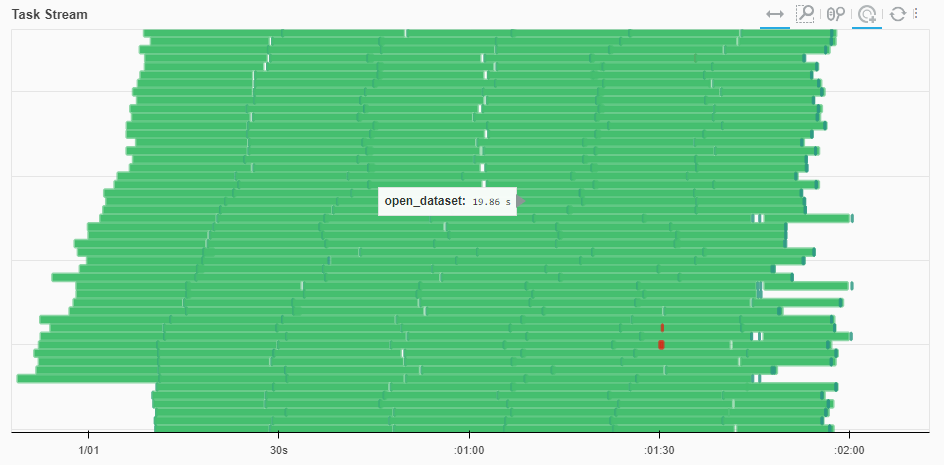
So I've since discovered Dask Distributed and life is much better, I'm able to schedule things efficiently and keep the job in memory. I'm still finding it takes 20 sec just to open each little grib, and I have no idea why: |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
So I'm trying to open 800 of these grib2's, which are 700KB compressed and 100MB uncompressed, using
After at least several hrs (not sure, I ran it overnight), it just gives me
MemoryError. I was under the impression that xarray just lazily created pointers to the data in the files on disk. Is it really trying to read 80GB into memory, exceeding my 32GB RAM? Reading files has always been instant and appeared lazy to me; this is my first experience with open_mfdataset.How can I process this data then (regionmask, interpolate_na, then serialize to .nc)? Also, if it will take forever to open, how can I at least see its progress? I was trying to sneak a progress bar into the preprocess function, but it hides all the print statements until the it finishes and displays the dataset (using Jupyter extension in vscode FYI).
xr version 0.20.2
Thanks!
Beta Was this translation helpful? Give feedback.
All reactions