Replies: 2 comments 5 replies
-
|
The map_blocks trick should be unnecessary given dask/dask#8015 is in 2021.09.0. Your error is because you're using I don't know what's happening. Is there any difference in the memory usage? It would really help if you could provide a reproducible example |
Beta Was this translation helpful? Give feedback.
-
|
@dcherian Thanks for the quick response.
I do not see significant difference in memory usage in test examples on my personal laptop. On the other hand, I saw huge memory usage (with isel approach) when was running on hpc cluster with dask-mpi. It was probably because I set memory target, spill, pause options to False in distributed.yaml file to check actual memory usage (>32gb for 300 GB data). Eventually, my code crashed.
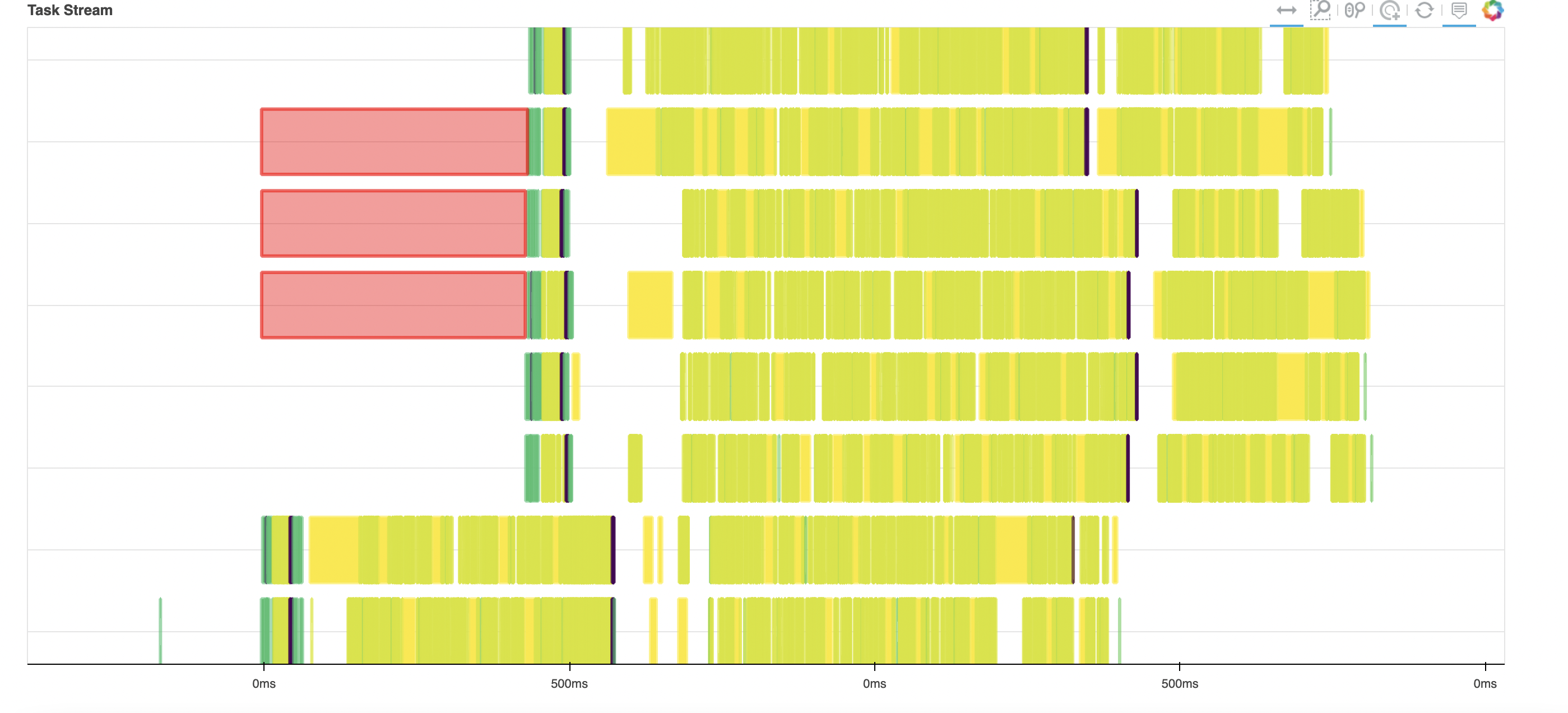
Here is an reproducible example On my Mac, the first approach takes double time and there is lot of reds in the task streams. From 1st approach (isel and then mean)
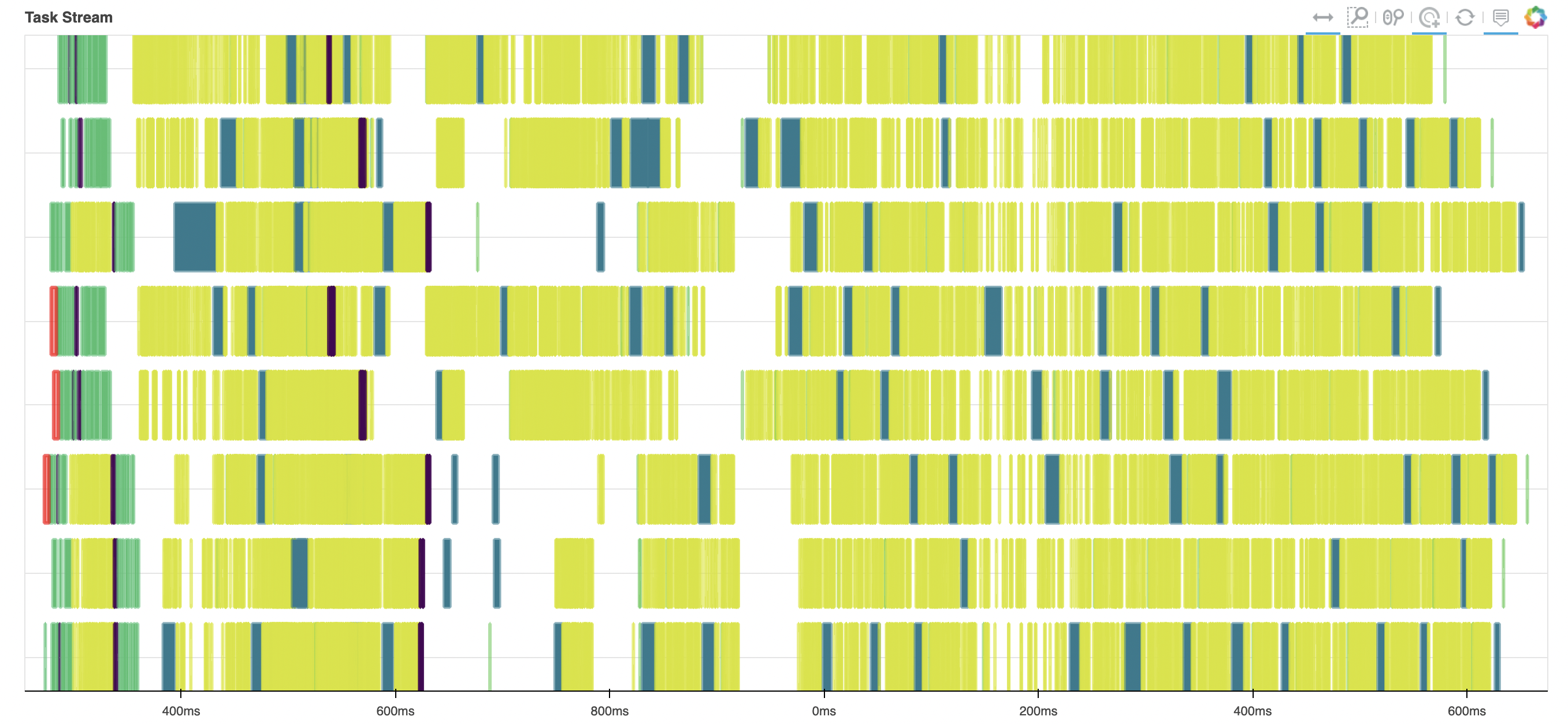
From 2nd approach (mean from data snapshot)
Also, I observed that using I do not know what is going wrong. I though that |
Beta Was this translation helpful? Give feedback.
-
The core problem is that the "first approach" is creating a very large number of tasks. The overhead of transferring this graph between workers is what is causing the red you see in your dashboard. It can be very instructive to look at the reprs for your dask arrays. I made your problem smaller to just focus on the dask part: (nt,ny,nx)=(72,100,100)
dummy=xr.DataArray(data=np.random.randn(nt,ny,nx),dims=['t','y','x'])
ds = dummy.to_dataset(name = 'data') # full data for all time steps
ds['data_snapshot'] = dummy.isel(t=0) # data for one time step
ds.to_netcdf('test.nc')
ds = []
for ensemble in range(0,10):
d = xr.open_dataset("test.nc", chunks={'t':1, 'y':10, 'x':10})
ds.append(d)
ds = xr.concat(ds, dim='r')
You can see that there are already > 86000 tasks in the It's important to remember that chaining computations on top of this array will only ever increase the number of tasks. With that in mind, I would remove this: ds = ds.chunk({'r':-1})as it is not really helping with anything. It just creates another layer of tasks. The same is happening with Maybe pinging a dask expert would help? In the meantime, try to do whatever you can to reduce the number of tasks. In general, writing code like xr.open_mfdataset(ensemble + "*.nc", chunks={'time':1, 'lat':45, 'lon':60})is kind of just wishful thinking unless the underlying netCDF file is chunked suitably on disk. It's unlikely that specifying arbitrary chunks will lead to an I/O pattern that can parallelize efficiently against the data on disk. |

Beta Was this translation helpful? Give feedback.
-
|
@rabernat thanks for the detailed explanation. For now, I will avoid providing chunks and stick with One thing I noticed in the test example is that performing |
Beta Was this translation helpful? Give feedback.
-
|
I tried an failed to reproduce this problem at the dask level Create a chunked array import dask.array as da
a = da.random.random(4, chunks=1)
a.visualize(optimize_graph=True)
Select just the first chunk a[0].visualize(optimize_graph=True)
Stack two such arrays b = da.stack([da.random.random(4, chunks=1), da.random.random(4, chunks=1)])
b.visualize(optimize_graph=True)
Take the mean across the stacked dimension of the first chunk b[:, 0].mean(axis=0).visualize(optimize_graph=True)
This shows that dask should in principle be able to optimize this operation. But is this type of optimization happening in @hmkhatri's example? If not, why not? |

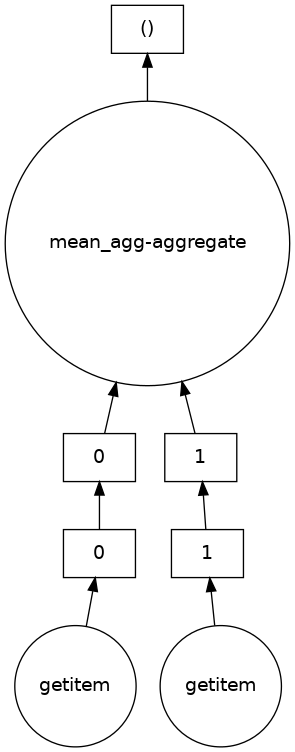
Beta Was this translation helpful? Give feedback.
-
I think you can safely chunk the time dimension, as this is the slowest varying dimension of the data. But chunking lon and lat probably doesn't accomplish anything. Do you happen to know if you original real data files use NetCDF chunking? |
Beta Was this translation helpful? Give feedback.
-
@rabernat The original data seems to have chunking. I did the following On the other hand, reading with Xarray does not seem to make any chunks.
|
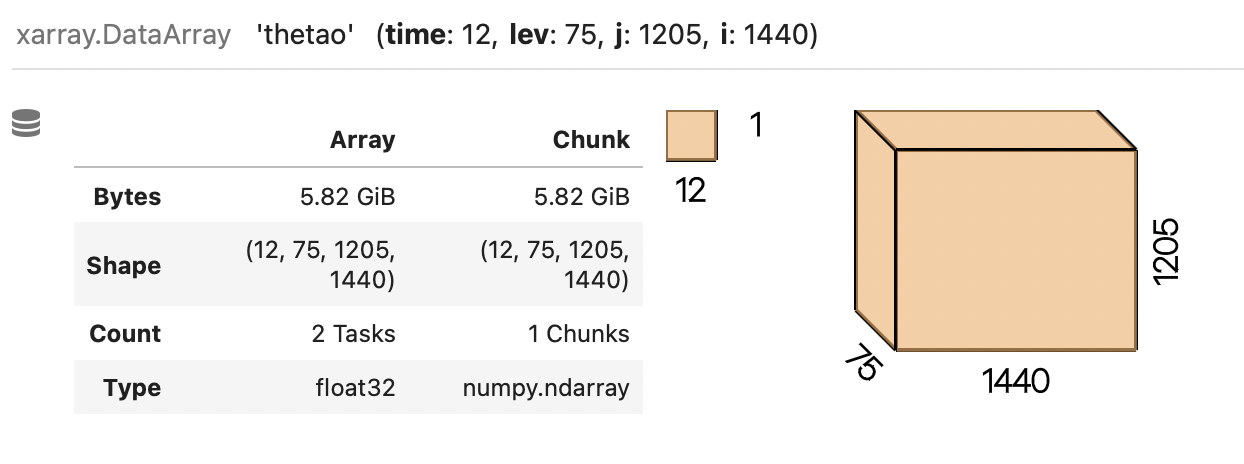
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I am working with multi-ensemble output and I use
concatoperation to combine multiple files into one xarray dataset.The main issue
I want to compute mean over ensemble members for a specific time snapshot. I compared the required calculation using two methods (for consistency, chunks were defined the same way in both)
I was expecting both methods to have similar efficiencies. However, method 1 tends to be significantly slower with a lot of inter-worker communication and data transfer (see task stream below).
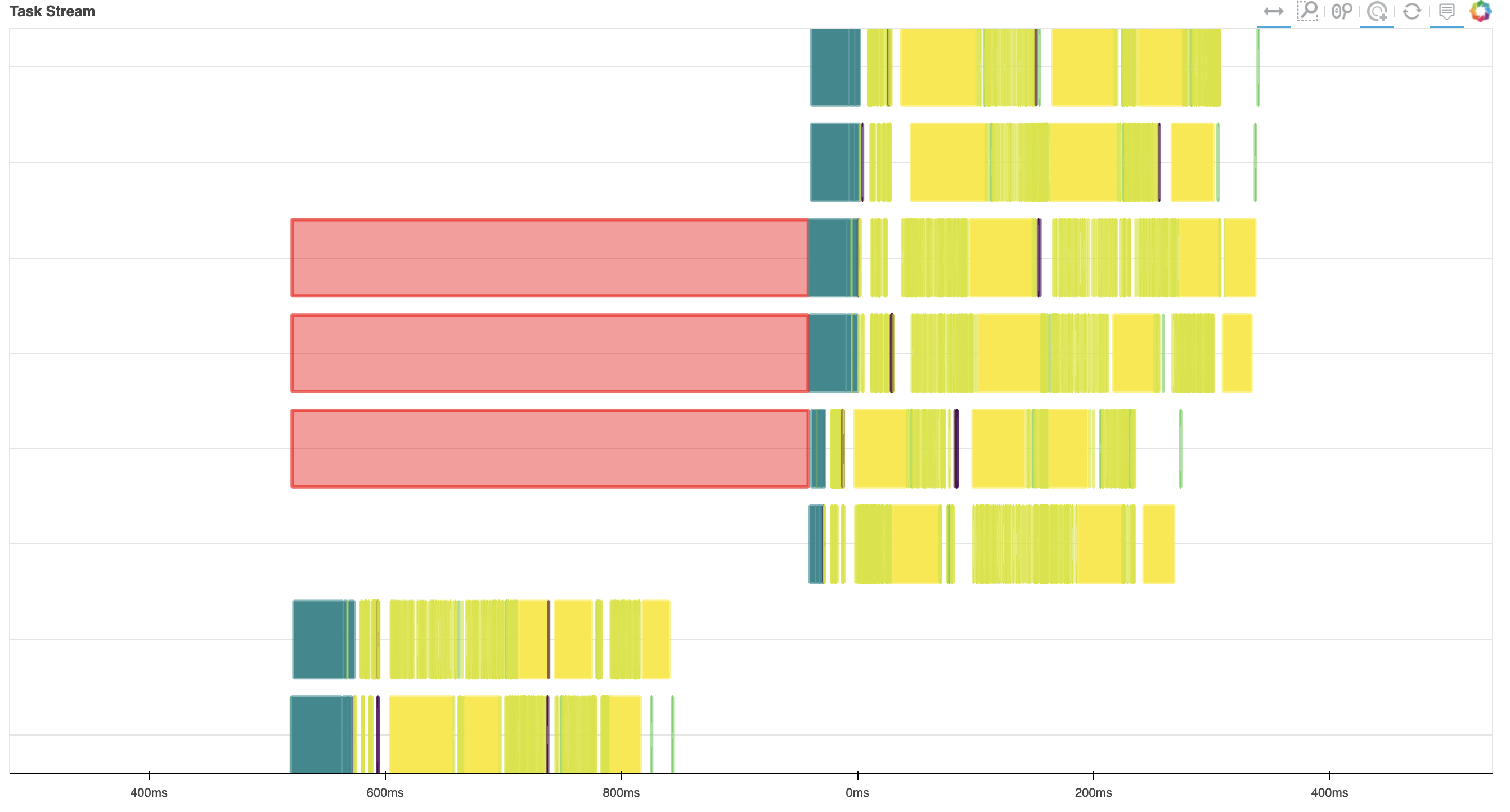
On the other hand, method 2 works very smoothly.
It seems that, in method 1, data for a lot of time snapshots is being loaded before slicing. This issue is related to issue dask/dask#3595. Based on suggestions @dcherian and others,
map_blocks(numpy.copy)should work fine. However, I could not make it work (I am new to map_blocks) and I get the following error.I don't know what is going is wrong with
map_blockscommand. Could someone help with this? Are there better ways to handle slicing of large datasets?I am using
dask 2021.10.0
Xarray 0.19.0
Beta Was this translation helpful? Give feedback.
All reactions