Description
Background information
What version of Open MPI are you using? (e.g., v3.0.5, v4.0.2, git branch name and hash, etc.)
v4.1.2rc4
Describe how Open MPI was installed (e.g., from a source/distribution tarball, from a git clone, from an operating system distribution package, etc.)
I'm currently using a benchmark tool osu_bw included in NVIDIA HPC-X that is a precompiled OpenMPI package with CUDA support.
If you are building/installing from a git clone, please copy-n-paste the output from git submodule status.
I'm not building/installing from a git clone by myself but using a precompiled binary provided by NVIDIA.
Please describe the system on which you are running
- Operating system/version: Ubuntu 20.04
- Computer hardware: two of DGX A100 machines with 8 GPUs and 2 Infiniband HCAs
- Network type: 200Gbps HDR Infiniband x 2
Details of the problem
We are conducting the performance benchmark using osu_bw.
We want to see how much performance can be delivered when leveraging RDMA & GDR(NVIDIA GPUDirect RDMA) with OpenMPI.
We could not understand some benchmark results by ourselves and hope you help us for that.
Any advices are welcoming and we believe they will be very helpful.
Our environment:
- Two of the NVIDIA DGX A100 machines are used.
- They are connected over 400Gbps Infiniband fabric (each machine has two of 200Gbps HDR Infiniband HCA).
- We use osu_bw included in the NVIDIA HPC-X package that is a precompiled OpenMPI and UCX packages with CUDA support. (ref: Link)
- We run four osu_bw entities in total by using the mpirun command. The following is an example:
$ mpirun -np 2 -v -H $N1,$N2 --cpu-set 16-31 -x LD_LIBRARY_PATH -x UCX_NET_DEVICES=mlx5_6:1 -x CUDA_VISIBLE_DEVICES=2 -x UCX_RNDV_SCHEME=get_zcopy $HPCX_OSU_CUDA_DIR/osu_bw D D > out1 &
$ mpirun -np 2 -v -H $N1,$N2 --cpu-set 112-127 -x LD_LIBRARY_PATH -x UCX_NET_DEVICES=mlx5_2:1 -x CUDA_VISIBLE_DEVICES=4 -x UCX_RNDV_SCHEME=get_zcopy $HPCX_OSU_CUDA_DIR/osu_bw D D > out2 &Result:
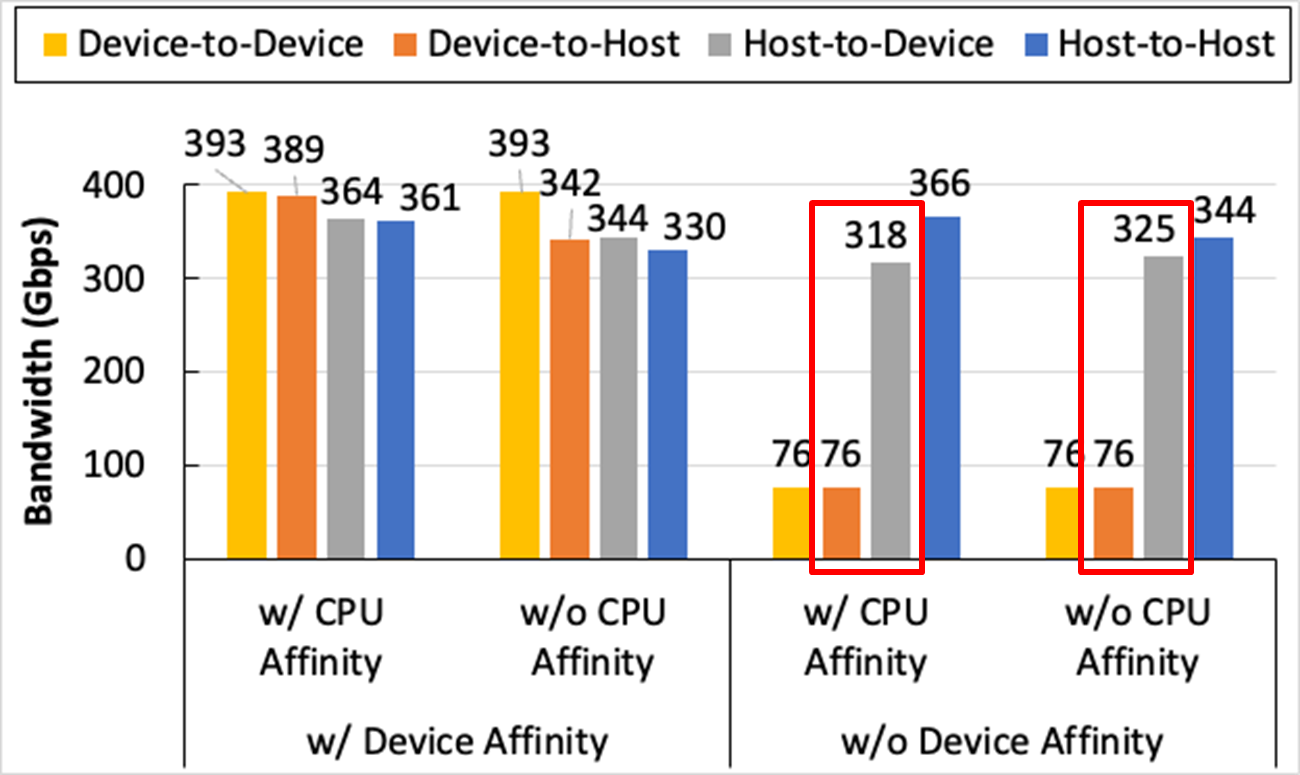
- 'Device-to-Device' is the case where both of the sender and receiver of osu_bw use GPU memory.
- 'Device-to-Host' is the case where the sender uses GPU memory and the receiver uses the host memory.
- 'Host-to-Device' is the case where the sender used the host memory and the receiver uses the GPU memory.
- 'Host-to-Host' is the case where both use the host memory.
- 'w/ Device Affinity' is an affinity between GPU and IB HCA. When we use GPU and IB HCA connected to the same PCIe root complex, we call it 'w/ Device Affinity'. When GPU and IB HCA are not located below the same root complex, then we call it 'w/o Device Affinity'. When they are in the same root complex, the GDR feature can be used in the communication and deliver better performance because host CPU is not involved in the transmission.
- 'w/ CPU Affinity' is a NUMA affinity between IB HCA and CPU cores. When we run osu_bw benchmark on the CPU cores that have affinity with IB HCA, we call it 'w/ CPU Affinity'. We call the case where they don't have affinity 'w/o CPU Affinity'.
Topology
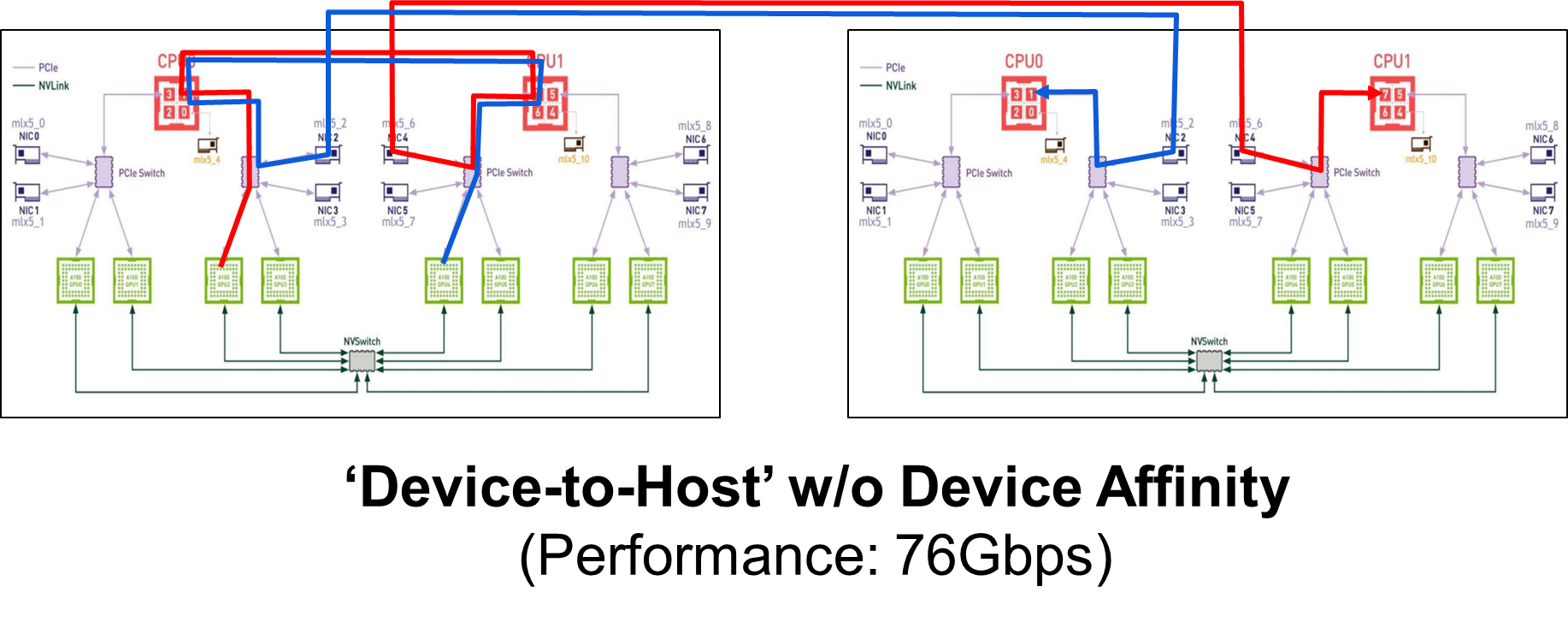
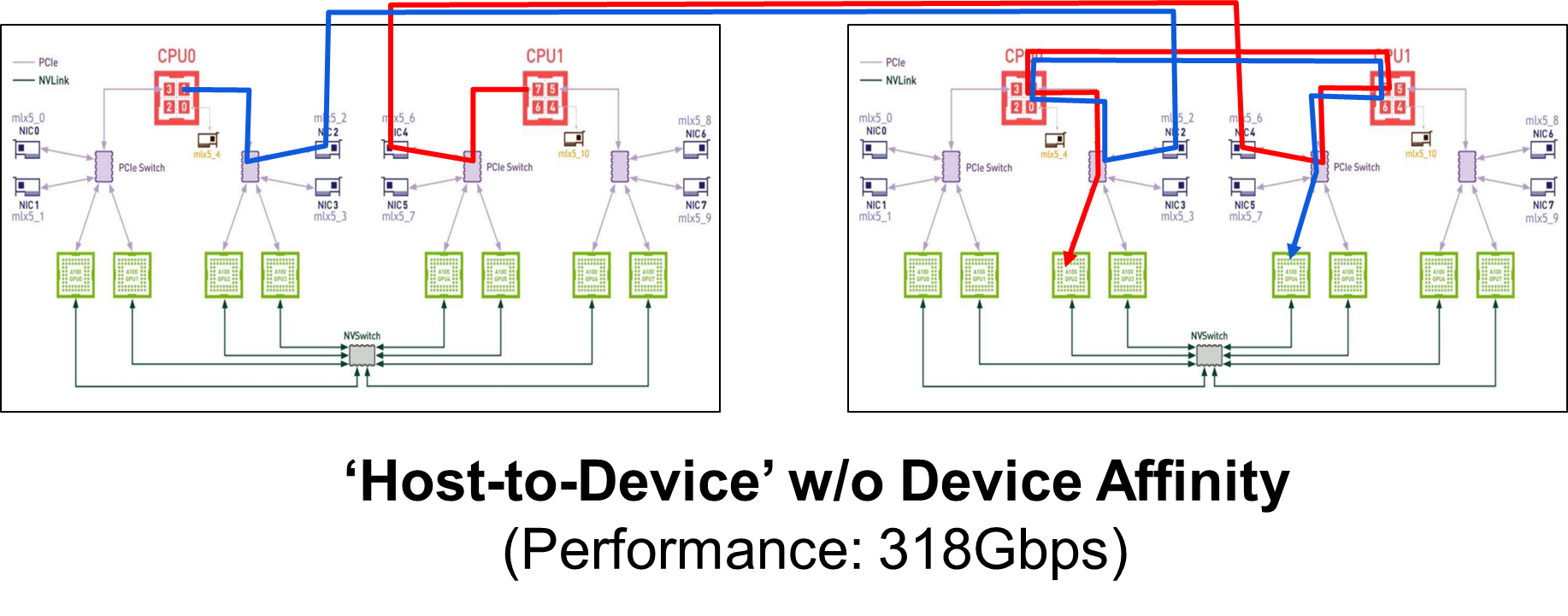
Question:
We couldn't understand the result of the cases 'Device-to-Host' and 'Host-to-Device' w/o Device Affinity.
We initially thought one side of the both cases could not benefit from RDMA and GDR at all so that the performance must be much slower than other cases.
However, as you can see in the figure above, the results of 'Host-to-Device' w/o device affinity are 318Gbps and 325Gbps respectively, which are much higher than the result of 'Device-to-Host' (76Gbps).
Our hypothesis is that the difference would be in the operation type: read or write.
- The write operation cannot leverage GDR and RDMA w/o Device Affinity. In the case 'Device-to-Host', CPU is involved in the sender side communication and the performance drops to 76Gbps.
- The read operation can benefit from GDR and RDMA even in the case w/o Device Affinity. In the case 'Host-to-Device', the receiver is able to retreive data in the GPU memory without the help of CPU so the performance drop is negligible.
Could you give us any comments about our hypothesis?
Thank you so much for reading this long article.
Source Code of osu_bw benchmark tool (Link)
/*
* Copyright (C) 2002-2005 the Network-Based Computing Laboratory
* (NBCL), The Ohio State University.
*/
#include "mpi.h"
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <math.h>
#define MAX_REQ_NUM 1000
#define MAX_ALIGNMENT 16384
#define MAX_MSG_SIZE (1<<22)
#define MYBUFSIZE (MAX_MSG_SIZE + MAX_ALIGNMENT)
int loop = 100;
int window_size = 64;
int skip = 10;
int loop_large = 20;
int window_size_large = 64;
int skip_large = 2;
int large_message_size = 8192;
char s_buf1[MYBUFSIZE];
char r_buf1[MYBUFSIZE];
MPI_Request request[MAX_REQ_NUM];
MPI_Status reqstat[MAX_REQ_NUM];
int main(int argc, char *argv[])
{
int myid, numprocs, i, j;
int size, align_size;
char *s_buf, *r_buf;
double t_start = 0.0, t_end = 0.0, t = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
align_size = getpagesize();
s_buf =
(char *) (((unsigned long) s_buf1 + (align_size - 1)) /
align_size * align_size);
r_buf =
(char *) (((unsigned long) r_buf1 + (align_size - 1)) /
align_size * align_size);
if (myid == 0) {
fprintf(stdout, "# OSU MPI Bandwidth Test (Version 2.0)\n");
fprintf(stdout, "# Size\t\tBandwidth (MB/s) \n");
}
/* Bandwidth test */
for (size = 1; size <= MAX_MSG_SIZE; size *= 2) {
/* touch the data */
for (i = 0; i < size; i++) {
s_buf[i] = 'a';
r_buf[i] = 'b';
}
if (size > large_message_size) {
loop = loop_large;
skip = skip_large;
window_size = window_size_large;
}
if (myid == 0) {
for (i = 0; i < loop + skip; i++) {
if (i == skip)
t_start = MPI_Wtime();
for (j = 0; j < window_size; j++)
MPI_Isend(s_buf, size, MPI_CHAR, 1, 100,
MPI_COMM_WORLD, request + j);
MPI_Waitall(window_size, request, reqstat);
MPI_Recv(r_buf, 4, MPI_CHAR, 1, 101, MPI_COMM_WORLD,
&reqstat[0]);
}
t_end = MPI_Wtime();
t = t_end - t_start;
} else if (myid == 1) {
for (i = 0; i < loop + skip; i++) {
for (j = 0; j < window_size; j++)
MPI_Irecv(r_buf, size, MPI_CHAR, 0, 100,
MPI_COMM_WORLD, request + j);
MPI_Waitall(window_size, request, reqstat);
MPI_Send(s_buf, 4, MPI_CHAR, 0, 101, MPI_COMM_WORLD);
}
}
if (myid == 0) {
double tmp;
tmp = ((size * 1.0) / (1000 * 1000)) * loop * window_size;
fprintf(stdout, "%d\t\t%f\n", size, tmp / t);
}
}
MPI_Finalize();
return 0;
}