diff --git a/configs/twins/README.md b/configs/twins/README.md
new file mode 100644
index 000000000..bc41106b5
--- /dev/null
+++ b/configs/twins/README.md
@@ -0,0 +1,92 @@
+
+# Twins
+> [Twins: Revisiting the Design of Spatial Attention in Vision Transformers](https://openreview.net/pdf?id=5kTlVBkzSRx)
+
+## Introduction
+
+Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins- PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks including image- level classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks.
+
+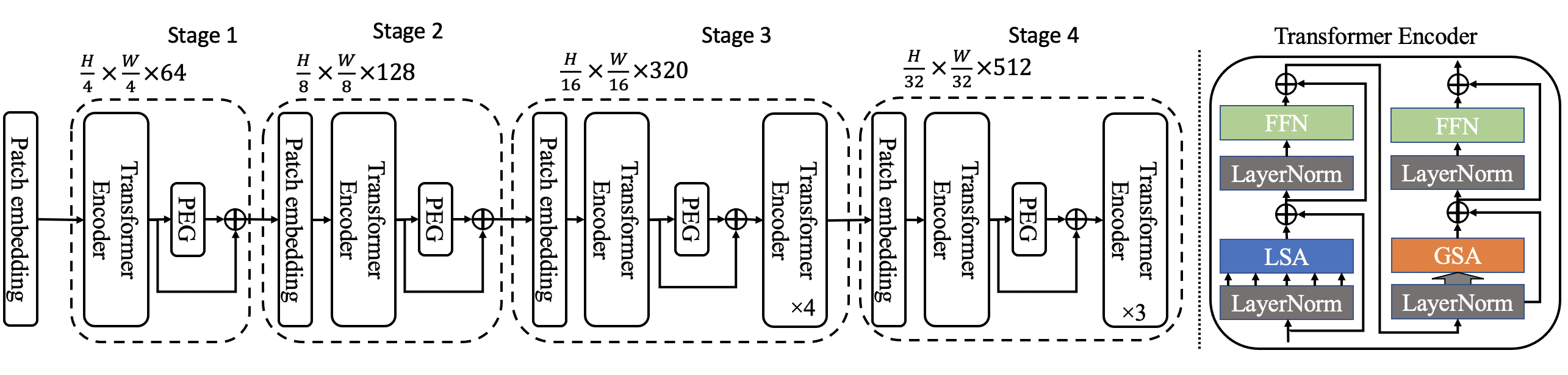 +
+Twins-SVT-S Architecture (Right side shows the inside of two consecutive Transformer Encoders).
+
+## Results
+
+**Implementation and configs for training were taken and adjusted from [this repository](https://gitee.com/cvisionlab/models/tree/twins/release/research/cv/Twins), which implements Twins models in mindspore.**
+
+Our reproduced model performance on ImageNet-1K is reported as follows.
+
+
+
+Twins-SVT-S Architecture (Right side shows the inside of two consecutive Transformer Encoders).
+
+## Results
+
+**Implementation and configs for training were taken and adjusted from [this repository](https://gitee.com/cvisionlab/models/tree/twins/release/research/cv/Twins), which implements Twins models in mindspore.**
+
+Our reproduced model performance on ImageNet-1K is reported as follows.
+
+
+
+| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
+|----------|----------|-----------|-----------|------------|-----------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+| svt_small | Converted from PyTorch | 81 | 95.38 | - | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/svt_s_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_s_new.ckpt) |
+| svt_base | Converted from PyTorch | 82.63 | 96.17 | - | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/svt_s_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_b_new.ckpt) |
+| svt_large | Converted from PyTorch | 83.04 | 96.35 | - | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/svt_s_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_l_new.ckpt) |
+| pcpvt_small | Converted from Pytorch | 80.58 | 95.40 | - |[yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/pcpvt_l_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_s_new.ckpt) |
+| pcpvt_base | Converted from Pytorch | 82.19 | 96.08 | - | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/pcpvt_l_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_b_new.ckpt) |
+| pcpvt_large | Converted from PyTorch | 82.51 | 96.37 | - | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/twins/pcpvt_l_gpu.yaml) | [weights](https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_l_new.ckpt)
+
+
+
+#### Notes
+
+- Context: The weights in the table were taken from [official repository](https://github.com/Meituan-AutoML/Twins) and converted to mindspore format
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+
+## Quick Start
+
+### Preparation
+
+#### Installation
+Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
+
+#### Dataset Preparation
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+### Training
+
+* Distributed Training
+
+
+```shell
+# distrubted training on multiple GPU/Ascend devices
+mpirun -n 8 python train.py --config configs/twins/svt_s_gpu.yaml --data_dir /path/to/imagenet --distributed True
+```
+
+> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
+
+Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
+
+For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+
+* Standalone Training
+
+If you want to train or finetune the model on a smaller dataset without distributed training, please run:
+
+```shell
+# standalone training on a CPU/GPU/Ascend device
+python train.py --config configs/twins/svt__gpus.yaml --data_dir /path/to/dataset --distribute False
+```
+
+### Validation
+
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+
+```shell
+python validate.py -c configs/twins/svt_s_gpu.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
+```
+
+### Deployment
+
+Please refer to the [deployment tutorial](https://github.com/mindspore-lab/mindcv/blob/main/tutorials/deployment.md) in MindCV.
+
+## References
+
+Paper - https://openreview.net/pdf?id=5kTlVBkzSRx
+
+Official repo - https://github.com/Meituan-AutoML/Twins
+
+Mindspore implementation - https://gitee.com/cvisionlab/models/tree/twins/release/research/cv/Twins
diff --git a/configs/twins/pcpvt_l_gpu.yaml b/configs/twins/pcpvt_l_gpu.yaml
new file mode 100644
index 000000000..13f63a160
--- /dev/null
+++ b/configs/twins/pcpvt_l_gpu.yaml
@@ -0,0 +1,67 @@
+# system
+mode: 0
+distribute: False
+num_parallel_workers: 2
+val_while_train: True
+
+# dataset
+dataset: 'imagenet'
+data_dir: 'path/to/imagenet/'
+shuffle: True
+dataset_download: False
+batch_size: 16
+drop_remainder: True
+val_split: val
+train_split: val
+
+# augmentation
+image_resize: 224
+scale: [0.08, 1.0]
+ratio: [0.75, 1.333]
+hflip: 0.5
+auto_augment: 'randaug-m9-mstd0.5-inc1'
+interpolation: bicubic
+re_prob: 0.24
+re_value: 'random'
+cutmix: 1.0
+mixup: 0.8
+mixup_prob: 1.0
+mixup_mode: 'batch'
+mixup_off_epoch: 0.0
+switch_prob: 0.5
+crop_pct: 0.9
+
+# model
+model: 'pcpvt_large'
+num_classes: 1000
+pretrained: False
+ckpt_path: ''
+
+keep_checkpoint_max: 10
+ckpt_save_dir: './ckpt'
+
+epoch_size: 300
+dataset_sink_mode: True
+amp_level: 'O0'
+ema: False
+clip_grad: True
+clip_value: 5.0
+drop_rate: 0.0
+drop_path_rate: 0.1
+
+# loss
+loss: 'CE'
+label_smoothing: 0.5
+
+# lr scheduler
+lr_scheduler: 'cosine_decay'
+warmup_epochs: 20
+lr: 0.0001
+warmup_factor: 0.001
+min_lr: 0.00001
+
+# optimizer
+opt: 'adamw'
+eps: 1e-8
+weight_decay: 0.05
+dynamic_loss_scale: True
diff --git a/configs/twins/svt_s_gpu.yaml b/configs/twins/svt_s_gpu.yaml
new file mode 100644
index 000000000..6e8c25c3d
--- /dev/null
+++ b/configs/twins/svt_s_gpu.yaml
@@ -0,0 +1,67 @@
+# system
+mode: 0
+distribute: False
+num_parallel_workers: 2
+val_while_train: True
+
+# dataset
+dataset: 'imagenet'
+data_dir: 'path/to/imagenet/'
+shuffle: True
+dataset_download: False
+batch_size: 32
+drop_remainder: True
+val_split: val
+train_split: val
+
+# augmentation
+image_resize: 224
+scale: [0.08, 1.0]
+ratio: [0.75, 1.333]
+hflip: 0.5
+auto_augment: 'randaug-m9-mstd0.5-inc1'
+interpolation: bicubic
+re_prob: 0.24
+re_value: 'random'
+cutmix: 1.0
+mixup: 0.8
+mixup_prob: 1.0
+mixup_mode: 'batch'
+mixup_off_epoch: 0.0
+switch_prob: 0.5
+crop_pct: 0.9
+
+# model
+model: 'alt_gvt_small'
+num_classes: 1000
+pretrained: False
+ckpt_path: ''
+
+keep_checkpoint_max: 10
+ckpt_save_dir: './ckpt'
+
+epoch_size: 300
+dataset_sink_mode: True
+amp_level: 'O0'
+ema: False
+clip_grad: True
+clip_value: 5.0
+drop_rate: 0.0
+drop_path_rate: 0.1
+
+# loss
+loss: 'CE'
+label_smoothing: 0.5
+
+# lr scheduler
+lr_scheduler: 'cosine_decay'
+warmup_epochs: 20
+lr: 0.0001
+warmup_factor: 0.001
+min_lr: 0.00001
+
+# optimizer
+opt: 'adamw'
+eps: 1e-8
+weight_decay: 0.05
+dynamic_loss_scale: True
diff --git a/mindcv/models/__init__.py b/mindcv/models/__init__.py
index d0521efff..3c4e4f169 100644
--- a/mindcv/models/__init__.py
+++ b/mindcv/models/__init__.py
@@ -20,6 +20,7 @@
mobilenet_v3,
model_factory,
nasnet,
+ pcpvt,
pnasnet,
poolformer,
pvt,
@@ -36,6 +37,7 @@
shufflenetv2,
sknet,
squeezenet,
+ svt,
swin_transformer,
vgg,
visformer,
@@ -62,6 +64,7 @@
from .mobilenet_v3 import *
from .model_factory import *
from .nasnet import *
+from .pcpvt import *
from .pnasnet import *
from .poolformer import *
from .pvt import *
@@ -78,6 +81,7 @@
from .shufflenetv2 import *
from .sknet import *
from .squeezenet import *
+from .svt import *
from .swin_transformer import *
from .utils import *
from .vgg import *
@@ -109,6 +113,7 @@
__all__.extend(model_factory.__all__)
__all__.extend(["NASNetAMobile", "nasnet"])
__all__.extend(["Pnasnet", "pnasnet"])
+__all__.extend(pcpvt.__all__)
__all__.extend(poolformer.__all__)
__all__.extend(pvt.__all__)
__all__.extend(pvtv2.__all__)
@@ -124,6 +129,7 @@
__all__.extend(shufflenetv2.__all__)
__all__.extend(sknet.__all__)
__all__.extend(squeezenet.__all__)
+__all__.extend(svt.__all__)
__all__.extend(swin_transformer.__all__)
__all__.extend(vgg.__all__)
__all__.extend(visformer.__all__)
diff --git a/mindcv/models/layers/__init__.py b/mindcv/models/layers/__init__.py
index 2810dbca1..a7628af01 100644
--- a/mindcv/models/layers/__init__.py
+++ b/mindcv/models/layers/__init__.py
@@ -1,9 +1,21 @@
"""layers init"""
-from . import activation, conv_norm_act, drop_path, identity, pooling, selective_kernel, squeeze_excite
+from . import (
+ activation,
+ conv_norm_act,
+ drop_path,
+ identity,
+ mlp,
+ patch_embed,
+ pooling,
+ selective_kernel,
+ squeeze_excite,
+)
from .activation import *
from .conv_norm_act import *
from .drop_path import *
from .identity import *
+from .mlp import *
+from .patch_embed import *
from .pooling import *
from .selective_kernel import *
from .squeeze_excite import *
diff --git a/mindcv/models/pcpvt.py b/mindcv/models/pcpvt.py
new file mode 100644
index 000000000..3cd3b2489
--- /dev/null
+++ b/mindcv/models/pcpvt.py
@@ -0,0 +1,493 @@
+"""PCPVT model implementation"""
+
+import math
+from functools import partial
+
+import numpy as np
+
+import mindspore as ms
+import mindspore.common.initializer as weight_init
+import mindspore.ops.functional as F
+import mindspore.ops.operations as P
+from mindspore import Parameter, nn
+
+from .layers import DropPath, Identity, Mlp
+from .layers.helpers import to_2tuple
+from .registry import register_model
+from .utils import load_pretrained
+
+__all__ = [
+ "pcpvt_small",
+ "pcpvt_base",
+ "pcpvt_large"
+]
+
+
+class PatchEmbed(nn.Cell):
+ """ Image to Patch Embedding
+ """
+
+ def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768, name=''):
+ super().__init__()
+
+ def set_name(src):
+ return 'p{}.{}'.format(name, src)
+
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+
+ self.img_size = img_size
+ self.patch_size = patch_size
+ assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
+ f"img_size {img_size} should be divided by patch_size {patch_size}."
+ self.h, self.w = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
+ self.num_patches = self.h * self.w
+ self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size,
+ has_bias=True)
+ self.proj.weight.name = set_name(self.proj.weight.name)
+ self.proj.bias.name = set_name(self.proj.bias.name)
+ self.norm = nn.LayerNorm([embed_dim])
+ self.norm.beta.name = set_name(self.norm.beta.name)
+ self.norm.gamma.name = set_name(self.norm.gamma.name)
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ # b, c, h, w = x.shape
+
+ x = self.proj(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = self.norm(x)
+
+ return x
+
+
+class PosCNN(nn.Cell):
+ """Position embedding module from https://arxiv.org/abs/2102.10882"""
+
+ def __init__(self, in_channels, embed_dim=768, s=1,
+ name='', h=0, w=0):
+ super(PosCNN, self).__init__()
+ self.proj = nn.SequentialCell([nn.Conv2d(
+ in_channels, embed_dim, 3, s,
+ pad_mode='pad', padding=1, has_bias=True, group=embed_dim
+ )])
+ for elem in self.proj:
+ elem.weight.name = '{}.{}'.format(name, elem.weight.name)
+ elem.bias.name = '{}.{}'.format(name, elem.bias.name)
+ self.s = s
+ self.h, self.w = h, w
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ b, _, c = x.shape
+ feat_token = x
+ cnn_feat = feat_token.transpose((0, 2, 1)).view(b, c, self.h, self.w)
+ if self.s == 1:
+ x = self.proj(cnn_feat) + cnn_feat
+ else:
+ x = self.proj(cnn_feat)
+ x = x.reshape((x.shape[0], x.shape[1], -1)).transpose((0, 2, 1))
+ return x
+
+
+class Attention(nn.Cell):
+ """Attention"""
+
+ def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1,
+ name='', h=0, w=0):
+ super().__init__()
+ self.dim = dim
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.head_dim = head_dim
+ # NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
+ self.scale = qk_scale or head_dim ** -0.5
+
+ self.q = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
+ self.kv = nn.Dense(in_channels=dim, out_channels=dim * 2, has_bias=qkv_bias)
+ self.attn_drop = nn.Dropout(keep_prob=1.0 - attn_drop)
+ self.proj = nn.Dense(in_channels=dim, out_channels=dim, has_bias=True)
+ self.proj_drop = nn.Dropout(keep_prob=1.0 - proj_drop)
+ self.softmax = nn.Softmax(axis=-1)
+ self.matmul = P.BatchMatMul()
+
+ self.sr_ratio = sr_ratio
+ if sr_ratio > 1:
+ self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio, has_bias=True)
+ self.norm = nn.LayerNorm([dim])
+ self.norm.beta.name = '{}.{}'.format(name, self.norm.beta.name)
+ self.norm.gamma.name = '{}.{}'.format(name, self.norm.gamma.name)
+ self.h, self.w = h, w
+
+ def construct(self, *inputs, **kwargs):
+ """Attention construct"""
+ x = inputs[0]
+ b, n, c = x.shape
+
+ q = self.q(x).reshape(b, n, self.num_heads, c // self.num_heads
+ ).transpose((0, 2, 1, 3))
+
+ if self.sr_ratio > 1:
+ x_ = x.transpose((0, 2, 1)).reshape(b, c, self.h, self.w)
+ x_ = self.sr(x_).reshape(b, c, -1).transpose((0, 2, 1))
+ x_ = self.norm(x_)
+ kv = self.kv(x_).reshape(b, -1, 2, self.num_heads, c // self.num_heads).transpose((2, 0, 3, 1, 4))
+ else:
+ kv = self.kv(x).reshape(b, -1, 2, self.num_heads, c // self.num_heads).transpose((2, 0, 3, 1, 4))
+ k, v = kv[0], kv[1]
+
+ attn = self.matmul(q, k.transpose(0, 1, 3, 2)) * self.scale
+ attn = self.softmax(attn)
+ attn = self.attn_drop(attn)
+
+ x = self.matmul(attn, v).transpose((0, 2, 1, 3)).reshape(b, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class GroupAttention(nn.Cell):
+ """
+ LSA: self attention within a group
+ """
+ def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., ws=1,
+ name='', h=0, w=0):
+ _ = name # no parameter renaming
+ assert ws != 1
+ super(GroupAttention, self).__init__()
+ assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
+
+ self.dim = dim
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim ** -0.5
+
+ self.qkv = nn.Dense(dim, dim * 3, has_bias=qkv_bias)
+ self.attn_drop = nn.Dropout(1.0 - attn_drop)
+ self.proj = nn.Dense(dim, dim)
+ self.proj_drop = nn.Dropout(1.0 - proj_drop)
+ self.ws = ws
+ self.softmax = nn.Softmax(axis=-1)
+ self.matmul = P.BatchMatMul()
+ self.h, self.w = h, w
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ b, n, c = x.shape
+ h_group, w_group = self.h // self.ws, self.w // self.ws
+
+ total_groups = h_group * w_group
+
+ x = x.reshape(b, h_group, self.ws, w_group, self.ws, c)
+ x = x.transpose((0, 1, 3, 2, 4, 5))
+
+ qkv = self.qkv(x).reshape(b, total_groups, -1, 3, self.num_heads, c // self.num_heads
+ ).transpose((3, 0, 1, 4, 2, 5))
+ # B, hw, ws*ws, 3, n_head, head_dim -> 3, B, hw, n_head, ws*ws, head_dim
+ q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
+ attn = self.matmul(q, k.transpose((0, 1, 2, 4, 3))) * self.scale # B, hw, n_head, ws*ws, ws*ws
+ attn = self.softmax(attn)
+ attn = self.attn_drop(
+ attn) # attn @ v-> B, hw, n_head, ws*ws, head_dim -> (t(2,3)) B, hw, ws*ws, n_head, head_dim
+ attn = self.matmul(attn, v)
+ attn = attn.transpose((0, 1, 3, 2, 4)).reshape(b, h_group, w_group, self.ws, self.ws, c)
+ x = attn.transpose((0, 1, 3, 2, 4, 5)).reshape(b, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Block(nn.Cell):
+ """Base PCPVT block class"""
+
+ def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1,
+ name='', h=0, w=0):
+ super().__init__()
+ self.norm1 = norm_layer([dim])
+ self.norm1.beta.name = '{}1.{}'.format(name, self.norm1.beta)
+ self.norm1.gamma.name = '{}1.{}'.format(name, self.norm1.gamma)
+ self.attn = Attention(
+ dim,
+ num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
+ attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio,
+ name=name + '_attn', h=h, w=w
+ )
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
+ self.norm2 = norm_layer([dim])
+ self.norm2.beta.name = '{}2.{}'.format(name, self.norm2.beta)
+ self.norm2.gamma.name = '{}2.{}'.format(name, self.norm2.gamma)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+ self.h, self.w = h, w
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ x = x + self.drop_path(self.attn(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+
+class PyramidVisionTransformer(nn.Cell):
+ """PVT base model architecture from https://github.com/whai362/PVT.git"""
+
+ def __init__(self, img_size=224, patch_size=16, in_channels=3, num_classes=1000, embed_dims=(64, 128, 256, 512),
+ num_heads=(1, 2, 4, 8), mlp_ratios=(4, 4, 4, 4), qkv_bias=False, qk_scale=None, drop_rate=0.,
+ attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
+ depths=(3, 4, 6, 3), sr_ratios=(8, 4, 2, 1), block_cls=Block):
+ super().__init__()
+ self.num_classes = num_classes
+ self.depths = depths
+
+ # patch_embed
+ self.patch_embeds = []
+ self.pos_embeds = []
+ self.pos_drops = []
+ self.blocks = []
+
+ for i in range(len(depths)):
+ if i == 0:
+ self.patch_embeds.append(PatchEmbed(img_size, patch_size, in_channels, embed_dims[i], name=i))
+ else:
+ self.patch_embeds.append(
+ PatchEmbed(img_size // patch_size // 2 ** (i - 1), 2, embed_dims[i - 1], embed_dims[i],
+ name=i))
+ patch_num = self.patch_embeds[-1].num_patches + 1 if i == len(embed_dims) - 1 else self.patch_embeds[
+ -1].num_patches
+ self.pos_embeds.append(Parameter(
+ weight_init.initializer(weight_init.Zero(),
+ (1, patch_num, embed_dims[i]),
+ ms.dtype.float32)
+ ))
+ self.pos_drops.append(nn.Dropout(1.0 - drop_rate))
+ self.patch_embeds = nn.CellList(self.patch_embeds)
+
+ dpr = np.linspace(0, drop_path_rate, sum(depths)
+ ) # stochastic depth decay rule
+ cur = 0
+ for k in range(len(depths)):
+ block = [block_cls(
+ dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
+ sr_ratio=sr_ratios[k],
+ name='b{}.{}'.format(k, i), h=self.patch_embeds[k].h, w=self.patch_embeds[k].w
+ ) for i in range(depths[k])]
+ self.blocks.extend(block)
+ cur += depths[k]
+
+ self.norm = norm_layer([embed_dims[-1]])
+ self.cls_token = Parameter(
+ weight_init.initializer(weight_init.Zero(),
+ (1, 1, embed_dims[-1]),
+ ms.dtype.float32)
+ )
+
+ # classification head
+ self.head = nn.Dense(embed_dims[-1], num_classes) if num_classes > 0 else Identity()
+
+ # init weights
+ for pos_emb in self.pos_embeds:
+ # trunc_normal_(pos_emb, std=.02)
+ pos_emb.set_data(weight_init.initializer(
+ weight_init.TruncatedNormal(sigma=0.02),
+ pos_emb.shape,
+ pos_emb.dtype
+ ))
+
+ def reset_drop_path(self, drop_path_rate):
+ dpr = np.linspace(0, drop_path_rate, sum(self.depths))
+ cur = 0
+ for k in range(len(self.depths)):
+ for i in range(self.depths[k]):
+ self.blocks[k][i].drop_path.drop_prob = dpr[cur + i]
+ cur += self.depths[k]
+
+ def no_weight_decay(self):
+ return {'cls_token'}
+
+ def get_classifier(self):
+ return self.head
+
+ def reset_classifier(self, num_classes, global_pool=''):
+ _ = global_pool
+ self.num_classes = num_classes
+ self.head = nn.Dense(self.embed_dim, num_classes) if num_classes > 0 else Identity()
+
+ def forward_features(self, x):
+ """Base feature processing method"""
+ b = x.shape[0]
+ for i in range(len(self.depths)):
+ x = self.patch_embeds[i](x)
+ if i == len(self.depths) - 1:
+ cls_tokens = self.cls_token.expand(b, -1, -1)
+ x = F.concat((cls_tokens, x), axis=1)
+ x = x + self.pos_embeds[i]
+ x = self.pos_drops[i](x)
+ for blk in self.blocks[i]:
+ x = blk(x)
+ if i < len(self.depths) - 1:
+ x = x.reshape(b, self.patch_embeds[i].h, self.patch_embeds[i].w, -1
+ ).transpose((0, 3, 1, 2)).contiguous()
+
+ x = self.norm(x)
+
+ return x[:, 0]
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ x = self.forward_features(x)
+ x = self.head(x)
+
+ return x
+
+
+class CPVTV2(PyramidVisionTransformer):
+ """
+ Use useful results from CPVT. PEG and GAP.
+ Therefore, cls token is no longer required.
+ PEG is used to encode the absolute position on the fly, which greatly affects the performance when input resolution
+ changes during the training (such as segmentation, detection)
+ """
+ def __init__(self, img_size=224, patch_size=4, in_channels=3, num_classes=1000, embed_dims=(64, 128, 256, 512),
+ num_heads=(1, 2, 4, 8), mlp_ratios=(4, 4, 4, 4), qkv_bias=False, qk_scale=None, drop_rate=0.,
+ attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
+ depths=(3, 4, 6, 3), sr_ratios=(8, 4, 2, 1), block_cls=Block):
+ super(CPVTV2, self).__init__(img_size, patch_size, in_channels, num_classes, embed_dims, num_heads, mlp_ratios,
+ qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate, norm_layer, depths,
+ sr_ratios, block_cls)
+ del self.pos_embeds
+ del self.cls_token
+ self.pos_block = nn.CellList([
+ PosCNN(embed_dims[k], embed_dims[k], name=k,
+ h=self.patch_embeds[k].h, w=self.patch_embeds[k].w)
+ for k, embed_dim in enumerate(embed_dims)
+ ])
+ self.merge_blocks = nn.CellList()
+ total = 0
+ self.inds = []
+ for k, d in enumerate(self.depths):
+ self.merge_blocks.append(nn.SequentialCell([
+ self.blocks[total],
+ self.pos_block[k]
+ ] + self.blocks[total + 1:total + d]))
+ self.inds.append([total, -1 - k] + list(range(total + 1, total + d)))
+ total += d
+ # self.apply(self._init_weights)
+
+ def _init_weights(self):
+ """init_weights"""
+ for _, cell in self.cells_and_names():
+ if isinstance(cell, nn.Dense):
+ cell.weight.set_data(weight_init.initializer(weight_init.TruncatedNormal(sigma=0.02),
+ cell.weight.shape,
+ cell.weight.dtype))
+ if isinstance(cell, nn.Dense) and cell.bias is not None:
+ cell.bias.set_data(weight_init.initializer(weight_init.Zero(),
+ cell.bias.shape,
+ cell.bias.dtype))
+ elif isinstance(cell, nn.LayerNorm):
+ cell.gamma.set_data(weight_init.initializer(weight_init.One(),
+ cell.gamma.shape,
+ cell.gamma.dtype))
+ cell.beta.set_data(weight_init.initializer(weight_init.Zero(),
+ cell.beta.shape,
+ cell.beta.dtype))
+ elif isinstance(cell, nn.BatchNorm2d):
+ cell.gamma.set_data(weight_init.initializer(weight_init.One(),
+ cell.gamma.shape,
+ cell.gamma.dtype))
+ cell.beta.set_data(weight_init.initializer(weight_init.Zero(),
+ cell.beta.shape,
+ cell.beta.dtype))
+ elif isinstance(cell, nn.Conv2d):
+ fan_out = cell.kernel_size[0] * cell.kernel_size[1] * cell.out_channels
+ fan_out //= cell.groups
+ cell.gamma.set_data(weight_init.initializer(weight_init.Normal(0.0, math.sqrt(2.0 / fan_out)),
+ cell.gamma.shape,
+ cell.gamma.dtype))
+ if isinstance(cell, nn.Conv2d) and cell.bias is not None:
+ cell.beta.set_data(weight_init.initializer(weight_init.Zero(),
+ cell.beta.shape,
+ cell.beta.dtype))
+
+ def forward_features(self, x):
+ b = x.shape[0]
+
+ for i in range(len(self.depths)):
+ # x, (H, W) = self.patch_embeds[i](x)
+ x = self.patch_embeds[i](x)
+ h, w = self.patch_embeds[i].w, self.patch_embeds[i].w
+ x = self.pos_drops[i](x)
+ x = self.merge_blocks[i](x)
+ if i < len(self.depths) - 1:
+ x = x.reshape(b, h, w, -1).transpose((0, 3, 1, 2))
+
+ x = self.norm(x)
+
+ return x.mean(axis=1) # GAP here
+
+
+def _cfg(url='', **kwargs):
+ return {
+ 'url': url,
+ 'num_classes': 1000,
+ 'first_conv': 'patch_embed.proj',
+ 'classifier': 'head',
+ **kwargs
+ }
+
+
+default_cfgs = {
+ "pcpvt_small": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_s_new.ckpt"),
+ "pcpvt_base": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_b_new.ckpt"),
+ "pcpvt_large": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/pcpvt_l_new.ckpt")
+
+}
+
+
+@register_model
+def pcpvt_small(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> CPVTV2:
+ model = CPVTV2(
+ patch_size=4, in_channels=in_channels, num_classes=num_classes,
+ embed_dims=(64, 128, 320, 512), num_heads=(1, 2, 5, 8), mlp_ratios=(8, 8, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(3, 4, 6, 3), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["pcpvt_small"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model
+
+
+@register_model
+def pcpvt_base(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> CPVTV2:
+ model = CPVTV2(
+ patch_size=4, in_channels=in_channels, num_classes=num_classes,
+ embed_dims=(64, 128, 320, 512), num_heads=(1, 2, 5, 8), mlp_ratios=(8, 8, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(3, 4, 18, 3), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["pcpvt_base"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model
+
+
+@register_model
+def pcpvt_large(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> CPVTV2:
+ model = CPVTV2(
+ patch_size=4, in_channels=in_channels, num_classes=num_classes,
+ embed_dims=(64, 128, 320, 512), num_heads=(1, 2, 5, 8), mlp_ratios=(8, 8, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(3, 8, 27, 3), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["pcpvt_large"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model
diff --git a/mindcv/models/svt.py b/mindcv/models/svt.py
new file mode 100644
index 000000000..bb5aa646f
--- /dev/null
+++ b/mindcv/models/svt.py
@@ -0,0 +1,194 @@
+"""SVT model implementation"""
+
+from functools import partial
+
+import numpy as np
+
+import mindspore as ms
+import mindspore.ops.functional as F
+from mindspore import Parameter, nn
+
+from .layers import DropPath, Identity, Mlp
+from .pcpvt import CPVTV2, Attention, GroupAttention, _cfg
+from .registry import register_model
+from .utils import load_pretrained
+
+__all__ = [
+ "svt_small",
+ "svt_base",
+ "svt_large"
+]
+
+
+default_cfgs = {
+ "svt_small": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_s_new.ckpt"),
+ "svt_base": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_b_new.ckpt"),
+ "svt_large": _cfg(url="https://storage.googleapis.com/huawei-mindspore-hk/Twins/converted/svt_l_new.ckpt")
+}
+
+
+class LayerScale(nn.Cell):
+ def __init__(self, dim, init_values=1e-5, inplace=False):
+ super().__init__()
+ self.inplace = inplace
+ self.gamma = Parameter(init_values * F.ones(dim, ms.dtype.float32))
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ return x.mul_(self.gamma) if self.inplace else x * self.gamma
+
+
+class Block(nn.Cell):
+ """Base block class for SVT model"""
+
+ def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, name=''):
+ super().__init__()
+ self.norm1 = norm_layer([dim])
+ self.attn = Attention(
+ dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
+ name=name + '_attn'
+ )
+ # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
+ self.norm2 = norm_layer([dim])
+ self.norm2.beta.name = '{}_attn.{}'.format(name, self.norm2.beta)
+ self.norm2.gamma.name = '{}_attn.{}'.format(name, self.norm2.gamma)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ x = x + self.drop_path(self.attn(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class SBlock(Block):
+ def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
+ super(SBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
+ drop_path, act_layer, norm_layer)
+ _ = sr_ratio # for compatibility with other blocks
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ return super(SBlock, self).forward(x)
+
+
+class GroupBlock(Block):
+ """Implementation of group-aggregation block for SVT"""
+
+ def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, ws=1,
+ name='', h=0, w=0):
+ super(GroupBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
+ drop_path, act_layer, norm_layer)
+ del self.attn
+ if ws == 1:
+ self.attn = Attention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, sr_ratio, name=name, h=h, w=w)
+ else:
+ self.attn = GroupAttention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, ws, name=name, h=h, w=w)
+ self.h, self.w = h, w
+
+ def construct(self, *inputs, **kwargs):
+ x = inputs[0]
+ x = x + self.drop_path(self.attn(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class PCPVT(CPVTV2):
+ """PCPVT wrapper with some default arguments"""
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=(64, 128, 256),
+ num_heads=(1, 2, 4), mlp_ratios=(4, 4, 4), qkv_bias=False, qk_scale=None, drop_rate=0.,
+ attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
+ depths=(4, 4, 4), sr_ratios=(4, 2, 1), block_cls=SBlock):
+ super(PCPVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
+ mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
+ norm_layer, depths, sr_ratios, block_cls)
+
+
+class ALTGVT(PCPVT):
+ """Twins SVT model"""
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=(64, 128, 256),
+ num_heads=(1, 2, 4), mlp_ratios=(4, 4, 4), qkv_bias=False, qk_scale=None, drop_rate=0.,
+ attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
+ depths=(4, 4, 4), sr_ratios=(4, 2, 1), block_cls=GroupBlock, wss=(7, 7, 7)):
+ super(ALTGVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
+ mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
+ norm_layer, depths, sr_ratios, block_cls)
+ del self.blocks
+ self.wss = wss
+ # transformer encoder
+ dpr = np.linspace(0, drop_path_rate, sum(depths)) # stochastic depth decay rule
+ cur = 0
+ self.blocks = []
+ for k in range(len(depths)):
+ block = nn.CellList([block_cls(
+ dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
+ sr_ratio=sr_ratios[k], ws=1 if i % 2 == 1 else wss[k],
+ name='b{}.{}'.format(k, i), h=self.patch_embeds[k].h, w=self.patch_embeds[k].w
+ ) for i in range(depths[k])])
+ self.blocks.extend(block)
+ cur += depths[k]
+
+ self.merge_blocks = nn.CellList()
+ total = 0
+ self.inds = []
+ for k, d in enumerate(self.depths):
+ self.merge_blocks.append(nn.SequentialCell([
+ self.blocks[total],
+ self.pos_block[k]
+ ] + self.blocks[total + 1:total + d]))
+ self.inds.append([total, -1 - k] + list(range(total + 1, total + d)))
+ total += d
+ # self.apply(self._init_weights)
+
+
+@register_model
+def svt_small(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> ALTGVT:
+ model = ALTGVT(
+ patch_size=4, in_chans=in_channels, num_classes=num_classes,
+ embed_dims=(64, 128, 256, 512), num_heads=(2, 4, 8, 16), mlp_ratios=(4, 4, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(2, 2, 10, 4), wss=(7, 7, 7, 7), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["svt_small"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model
+
+
+@register_model
+def svt_base(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> ALTGVT:
+ model = ALTGVT(
+ patch_size=4, in_chans=in_channels, num_classes=num_classes,
+ embed_dims=(96, 192, 384, 768), num_heads=(3, 6, 12, 24), mlp_ratios=(4, 4, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(2, 2, 18, 2), wss=(7, 7, 7, 7), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["svt_base"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model
+
+
+@register_model
+def svt_large(pretrained: bool = False, num_classes=1000, in_channels=3, **kwargs) -> ALTGVT:
+ model = ALTGVT(
+ patch_size=4, in_chans=in_channels, num_classes=num_classes,
+ embed_dims=(128, 256, 512, 1024), num_heads=(4, 8, 16, 32), mlp_ratios=(4, 4, 4, 4), qkv_bias=True,
+ norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=(2, 2, 18, 2), wss=(7, 7, 7, 7), sr_ratios=(8, 4, 2, 1),
+ **kwargs)
+ default_cfg = default_cfgs["svt_large"]
+
+ if pretrained:
+ load_pretrained(model, default_cfg, num_classes=num_classes, in_channels=in_channels)
+
+ return model