Make the file count limit for indexing configurable #3036
Replies: 7 comments 14 replies
-
|
could try disabling indexing or using a pyrightconfig.json file to exclude folders |
Beta Was this translation helpful? Give feedback.
-
|
So I added an include and exclude section to my pyproject file, excluded as much stuff as I could, and went from 13k files to 8.7k files analyzed by Pylance. It's still well above the 2k limit for indexing. This resulted in a small speedup in symbol search but not going below the 30sec bar, and far from being usable. I also tried disabling indexing and it didn't really helped. Since working in repos that contain more than 2k files that need to be analyzed and indexed is pretty much a reality for anyone working in a big monorepo, is there a way to raise this 2k files index limit ? I wouldn't mind paying the cost of indexing once when I start the server and then have it cached on file or in memory even if the cache gets really big, as long as it makes search features usable |
Beta Was this translation helpful? Give feedback.
-
|
In fact that is the current behaviour of Pycharm and probably one of the last things that prevent me from moving away from it to VSC. It indexes your whole repo in a single pass when the language server starts and then saves a complete cache of the index. You also get visual feedback on the indexing operation (which is not the case with Pylance and makes it hard to understand what is happening when) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the feedback, unfortunately, lazy analysis is fundamental to the design of Pyright - the analysis engine that Pylance uses. It deliberately does not cache the analysis results. I don't see this changing in Pyright anytime soon. |
Beta Was this translation helpful? Give feedback.
-
|
I think it's only performance related. Maybe we could look under the hood of VSCode and force overwrite the 2000 limit? Any developments on your side? |
Beta Was this translation helpful? Give feedback.
-
|
i found the relevant code snippet it's hard coded into VSCode we cannot change it easily |
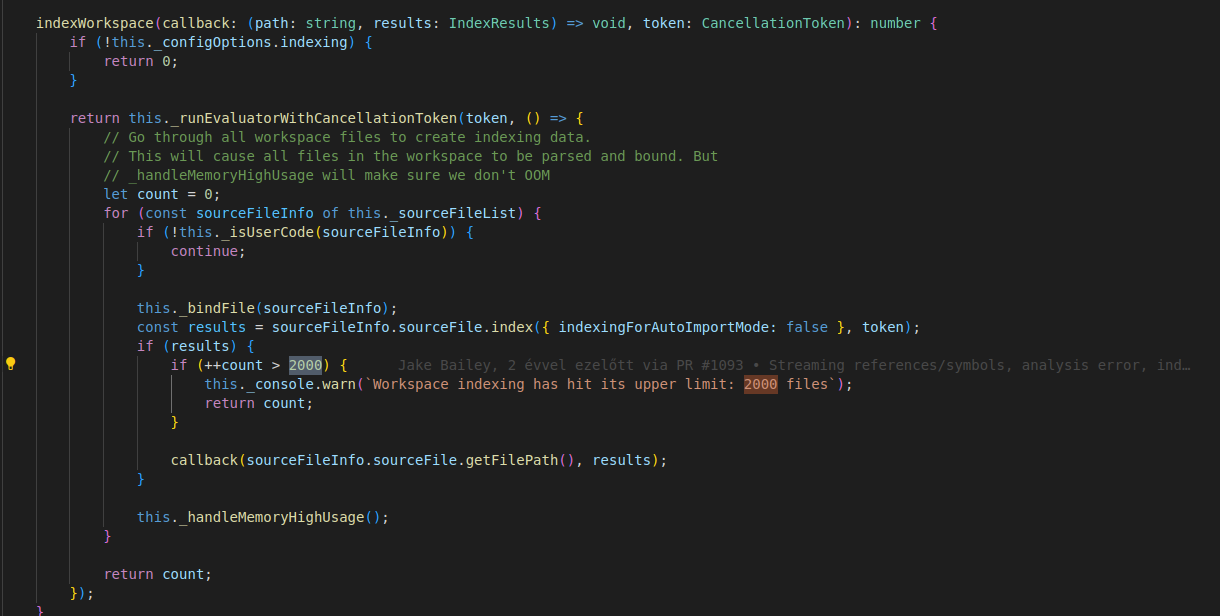
Beta Was this translation helpful? Give feedback.
-
|
this is the path |

Beta Was this translation helpful? Give feedback.
-
|
If you want to try it locally (and will have to redo it each time the extension updates you can manually override it in the pyright bundle) |
Beta Was this translation helpful? Give feedback.
-
|
oh, that's easy, lets make an extension that patches this extension |
Beta Was this translation helpful? Give feedback.
-
|
It says this issue is waiting for response from the user. What response is needed? |
Beta Was this translation helpful? Give feedback.
-
|
Yeah I think the original question is still waiting for a clear answer here, will you add support for indexing more than 2k files? I don't mind pyright using lazy analysis as long as I can force it to keep more files analyzed in memory |
Beta Was this translation helpful? Give feedback.
-
|
@judej & @heejaechang, what concerns do you have (if any) about exposing a configuration option that controls the file count limit for indexing? The 2K default was chosen to limit indexing time to under a minute in most cases. Obviously, indexing more files will take more time when the project is loaded, but if the user is willing to incur this additional cost and time (say, 2 or 3 minutes), that should be their prerogative, no? I don't see memory being a limiting factor here since the in-memory index takes up relatively little space. |
Beta Was this translation helpful? Give feedback.
-
|
Done, a simple fix for people that don't care about the reasons for the limit, save this to a script and run it... it should fix latest and all other versions of the extension |
Beta Was this translation helpful? Give feedback.
-
|
let me ask team on this. usually adding new option, we wait how many people want it. so far we didn't get much upvote so that's why there is no traction on this. but actual change is quite simple. so let me ask PM and team again on how they think. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for both of you! This is a blocker for our 300.000+ LOC codebase 🥳 |
Beta Was this translation helpful? Give feedback.
-
|
@heejaechang, any update from the PM and team? |
Beta Was this translation helpful? Give feedback.
-
|
The indexing limit was added. The setting is called: {
"python.analysis.userFileIndexingLimit": 2000
}It defaults to 2000. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Environment data
Pylance config:
Problem statement
Running Pylance through the official extension, in a large proprietary Python Monorepo, in a python2 virtualenv. Symbol search (Cmd+T) takes more than a minute to find symbols. However Cmd+Clicking a symbol in the code is working instantaneously. From the logs I can read, the index size reaches its limit causing VSCode to drop index cache.
Repro Steps
Repo I use is private and proprietary, cannot share any reproduction steps. At least 13k python files in the repo.
Expected behavior
Symbol search being fast. In particular, PyCharm is able to handle this repo properly and its symbol search is working as expected while VSCode is not.
Actual behavior
Symbol search unusably slow
Logs
Beta Was this translation helpful? Give feedback.
All reactions