Why there is no activation on the last layer of ResNET block? #1355
IIIBlueberry
started this conversation in
General
Replies: 1 comment
-
|
We follow the ResNet block design used by Johnson et al's amazing repo https://github.com/jcjohnson/fast-neural-style, which contains two Conv layers per block. The word "resnet block" might be overladed in different papers. We refer you to the original fast style transfer paper for more details. |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
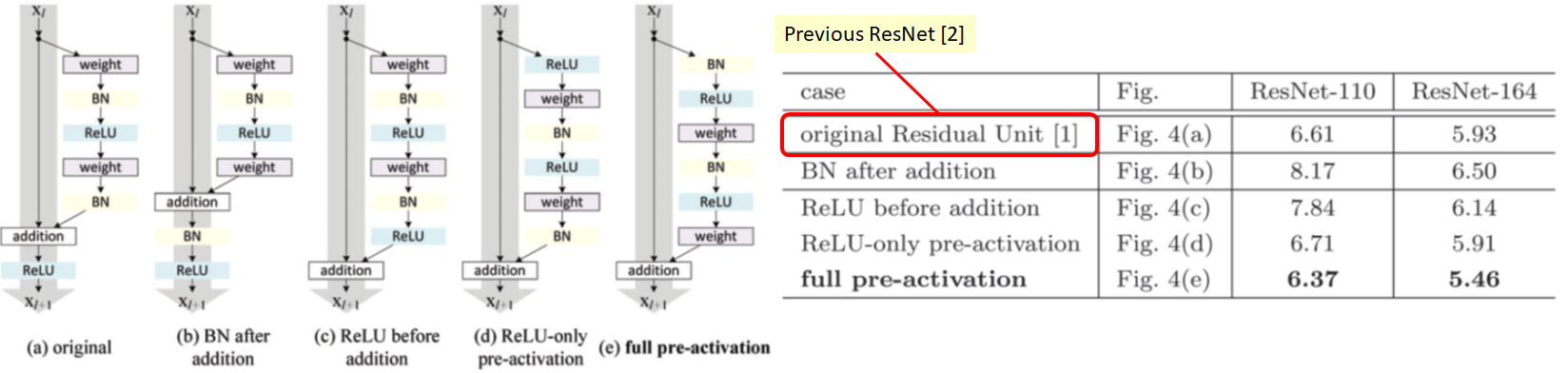
Current implementation of this git ResNET block is [x>Conv>Norm>ReLU>Conv>Norm>Add x] shouldn't there should be an activation layer after 'Add x' so that the next resnet block first Conv input is Activated(relu(x))
Or this resnet block implementation supposed to have pre-activation layer?
Beta Was this translation helpful? Give feedback.
All reactions