FFT of very large arrays (>100GB) #13842
Replies: 4 comments 6 replies
-
|
I've made some progress, now being able to perform FFT of a (48_000,40_000) array, via Google Cloud TPU v2-8 (8 devices of 8GB each): There are still some hurdles. Two of which are:
My next step would be to use larger TPU topologies, i.e. slices & pods. I'd greatly appreciate any advice on this effort. |
Beta Was this translation helpful? Give feedback.
-
|
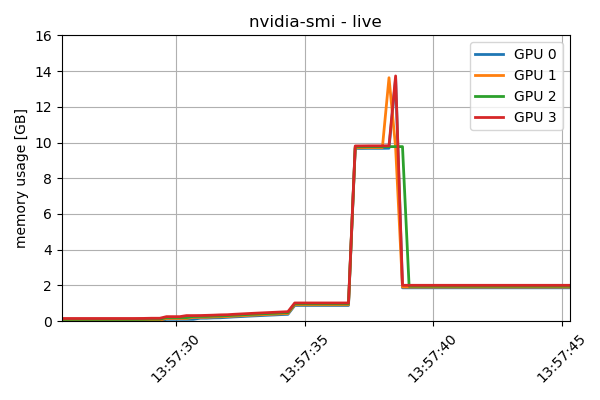
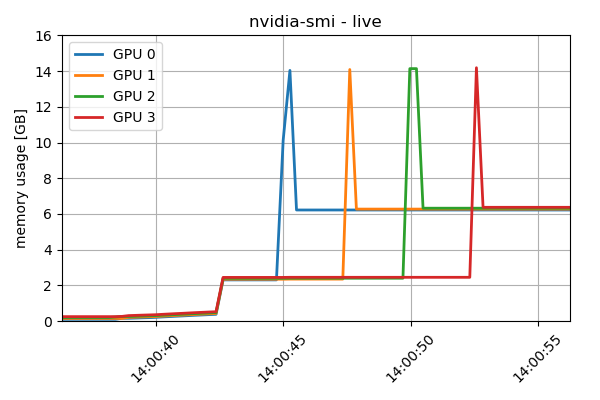
Note: the previous comments in this thread are not a prerequisite for this question, although part of the same effort. Gist of the matterGiven an array sharded appropriately (see below) across several devices, I'm unable instruct JIT/AOT to perform FFT while using only each local slice. It seems that each device is loading the entire array (although not needed), evident both by tracing the memory usage, as well as looking at compiled HLO output. Further detailsFor this example, I'm using a Google Cloud VM with 4 x NVidia T4 GPUs, 16GB each. , it seems that the compiled result is using, as some intermediate stage, the entire array, thus negating the main reason for sharding it: Although I'm only taking baby steps in looking at HLO code, it seems that although the main function is using the expected input & output parameter shapes ( This is, obviously, what I trying to avoid. Another indication of such memory usage is demonstrated by monitoring it during the execution; The plateau at 13:57:35 is synthetically inserted (time.sleep), to discern between the input memory allocation and the FFT. Similarly, the plateau at 13:57:40 onwards is after the FFT. Manually FFT-ing each shardTo demonstrate (mainly to myself...) that this kind of sharded FFT is indeed feasible, I've iterated over all the shards, sequantially performing FFT only on each local shard, and finally reassembling the results to a single array. As expected, this method enabled a 4-fold larger array to be used, i.e. c128[32000,32768]. Seen here, with a synthetic sleep between iterations (to visually discern memory usage), each device is using only its local shard.
Obviously, such a method not desired for real use, mainly due to the sequential nature of operation (as well as several other reasons). Full ExampleAs this message is long enough as it is, I've uploaded the entire example, containing both methods (the desired jit'ing with local shards only, and the sequential independent devices one), with HLO outputs of https://gist.github.com/ItayKishon-Remondo/d04de8ccc5f19a683538235380ffc5c3 HW & SW Details
Thank you for reaching so far. Any help or reference would be greatly appreciated. |
Beta Was this translation helpful? Give feedback.
-
|
Amazing work! I'm curious, how did it go? |
Beta Was this translation helpful? Give feedback.
-
|
I'm also currently trying to use JAX for large 3D-FFTs and am stuck at the fact that already a simple example gives different and incorrect results with JIT/GPU vs. no-JIT or CPU: #16909 |
Beta Was this translation helpful? Give feedback.
-
|
Hi all, Following #15680, I've implemented a native JAX solution using shmap. Although it's working, it is far from being elegant & efficient, and furthermore - it won't scale to multi-host (which is obviously required for >100GB arrays). @Findus23, it seems you're in a much more advanced state than I am, utilizing cuFFTMp (which I believe is the correct (scalable) solution to this problem). Going forward, I'm afraid I won't be the one implementing that. I'm handing this over to @ChaimDryzun-Remondo, which I hope will keep both updating here & make use of this great community. Cheers, |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your notes. |
Beta Was this translation helpful? Give feedback.
-
|
In case it helps anyone else: I have now updated my script to work with distributed hosts allowing me to use more than 2 GPUs. One thing I struggled with was accessing the distributed output array. Using This gist contains a full example (requires jax 0.4.8). Using 2 hosts with each 2 A40 GPUs (46GB RAM) I can calculate the 3d rfftn of a 2048^3 array (so roughly the same size as the 10_000^2 from the original post) in about 12s. https://gist.github.com/Findus23/eb5ecb9f65ccf13152cda7c7e521cbdd |
Beta Was this translation helpful? Give feedback.
-
You might be interested in using |
Beta Was this translation helpful? Give feedback.
-
Thanks @Findus23 and @ItayKishon-Remondo for this interesting work. I am trying to solve a similar problem whereby I need to currently calculate 1000s of 2D FFTs in parallel each of image size 256x256, but I would want to scale this up in the future. I have access to two 3090s with 48Gb of VRAM in total currently. One problem I have run into when trying to use CUPY to solve this problem on a single GPU, that causes issues with running out of memory, is that cuda (cufft package) does not seem to calculate the fourier transform inplace - see the features section of this open source alternative - https://github.com/vincefn/pyvkfft. This effectively halves the amount of available VRAM, since cuda seems to make a copy of the array. This might be part of the reason why it uses more VRAM than it should. It might be irrelevant to JAX considering it's immutability requirements, anyway, of the above solutions posted, which would you recommend for solving this problem: The JAX+CUFFTMp approach https://github.com/NVIDIA/CUDALibrarySamples/tree/master/cuFFTMp/JAX_FFT or the approach shared by you @Findus23 in this gist https://gist.github.com/Findus23/eb5ecb9f65ccf13152cda7c7e521cbdd? |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Update (17.04.2023): The last question in this thread is independent of the previous ones (albeit related).
You may skip directly to it: #13842 (comment)
Hi,
I apologize in advance for such a lengthy question, and would like to thank you for reading & assisting.
I'm building a wave optics simulation, in which one of the primary functions used are FFTs. Currently I'm running a preliminary phase (pardon the pun) of the system, where the array size I'm using is (10_000,10_000), yet for the appropriate volume & sampling eventually required I will need at least (100_000,100_000).
I've noticed the memory limit when attempting to use a (20_000,20_000) array, which for complex64 (single precision) amounts to about 3.0GB. The FFT operation itself, jnp.fft.fft(), seemed to require peak memory of about 5-fold during the calculation, which exceeded my A4000's 16GB.
The expected array size (80GB for 100_000^2, complex64) will probably not fit on a single GPU's RAM, not to mention other arrays which are also required for other parts of the calculation, as well as FFT's mid-calculation memory requirements.
I understand that I probably need a grid of GPU/TPUs, e.g. Google's Cloud TPU.
In that case, I have several questions:
I do understand that these are not trivial requirements, and I do hope that such a calculation is even feasible.
Any help, suggestion or reference would be highly appreciated. Thanks!
Beta Was this translation helpful? Give feedback.
All reactions