diff --git a/1_native_gpu.ipynb b/1_native_gpu.ipynb
new file mode 100644
index 0000000..7f3c3fb
--- /dev/null
+++ b/1_native_gpu.ipynb
@@ -0,0 +1,186 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Inference using Llamacpp on Intel GPUs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to run an LLM inference on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Setup the environment and install required libraries\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-cpp python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-cpp\n",
+ "\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Setup the environment and install required libraries\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-cpp python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-cpp\n",
+ "\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### With the llm-cpp environment active, use pip to install required libraries for suppport. \n",
+ "\n",
+ "```\n",
+ "pip install --pre --upgrade ipex-llm[cpp]\n",
+ "\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### With the llm-cpp environment active, use pip to install required libraries for suppport. \n",
+ "\n",
+ "```\n",
+ "pip install --pre --upgrade ipex-llm[cpp]\n",
+ "\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Create llama-cpp directory\n",
+ "\n",
+ "```\n",
+ "mkdir llama-cpp\n",
+ "cd llama-cpp\n",
+ "\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Create llama-cpp directory\n",
+ "\n",
+ "```\n",
+ "mkdir llama-cpp\n",
+ "cd llama-cpp\n",
+ "\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Please run the following command with administrator privilege in Miniforge Prompt. We should see many soft links of llama.cpp’s executable files in current directory.\n",
+ "```\n",
+ "init-llama-cpp.bat\n",
+ "\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Please run the following command with administrator privilege in Miniforge Prompt. We should see many soft links of llama.cpp’s executable files in current directory.\n",
+ "```\n",
+ "init-llama-cpp.bat\n",
+ "\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Set the following environment variables according to your device to use GPU acceleration\n",
+ "For Intel iGPU:\n",
+ "```\n",
+ "set SYCL_CACHE_PERSISTENT=1\n",
+ "\n",
+ "```\n",
+ "### Below shows a simple example to show how to run a community GGUF model\n",
+ "* Download and run the model for example as below \n",
+ "\n",
+ "```\n",
+ "main -m mistral-7b-instruct-v0.1.Q4_K_M.gguf -n 32 --prompt \"What is AI\" -t 8 -e -ngl 33 --color\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Set the following environment variables according to your device to use GPU acceleration\n",
+ "For Intel iGPU:\n",
+ "```\n",
+ "set SYCL_CACHE_PERSISTENT=1\n",
+ "\n",
+ "```\n",
+ "### Below shows a simple example to show how to run a community GGUF model\n",
+ "* Download and run the model for example as below \n",
+ "\n",
+ "```\n",
+ "main -m mistral-7b-instruct-v0.1.Q4_K_M.gguf -n 32 --prompt \"What is AI\" -t 8 -e -ngl 33 --color\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! C:\\workshop\\llama-cpp\\main.exe -m ../models/llama-2-7b-chat.Q5_K_M.gguf -n 100 --prompt \"What is AI\" -t 16 -ngl 999 --color -e "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/2_ollama_gpu.ipynb b/2_ollama_gpu.ipynb
new file mode 100644
index 0000000..d133c5d
--- /dev/null
+++ b/2_ollama_gpu.ipynb
@@ -0,0 +1,281 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Running LLAMA3 on Intel AI PCs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install Ollama on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install Intel oneAPI Base Toolkit: The oneAPI Base Toolkit (specifically Intel’ SYCL runtime, MKL and OneDNN) is essential for leveraging the performance enhancements offered by Intel's libraries and for ensuring that Ollama can fully utilize the GPU capabilities. By following these steps, your AI PC will be primed for running Ollama leveraging Intel iGPUs.\n",
+ "\n",
+ "```\n",
+ "conda create -n llm-ollama python=3.11 -y\n",
+ "conda activate llm-ollama\n",
+ "conda install libuv -y\n",
+ "pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0\n",
+ "\n",
+ "```\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Ollama with Intel GPU support\n",
+ "\n",
+ "* Now that we have set up the environment, Intel GPU drivers, and runtime libraries, we can configure ollama to leverage the on-chip GPU.\n",
+ "* Open miniforge prompt and run the below commands. We Install IPEX-LLM for llama.cpp and to use llama.cpp with IPEX-LLM, first ensure that ipex-llm[cpp] is installed.\n",
+ "\n",
+ "### With the ollama environment active, use pip to install required libraries for GPU. \n",
+ "```\n",
+ "conda activate llm-ollama\n",
+ "pip install --pre --upgrade ipex-llm[cpp]\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! C:\\workshop\\llama-cpp\\main.exe -m ../models/llama-2-7b-chat.Q5_K_M.gguf -n 100 --prompt \"What is AI\" -t 16 -ngl 999 --color -e "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/2_ollama_gpu.ipynb b/2_ollama_gpu.ipynb
new file mode 100644
index 0000000..d133c5d
--- /dev/null
+++ b/2_ollama_gpu.ipynb
@@ -0,0 +1,281 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Running LLAMA3 on Intel AI PCs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install Ollama on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install Intel oneAPI Base Toolkit: The oneAPI Base Toolkit (specifically Intel’ SYCL runtime, MKL and OneDNN) is essential for leveraging the performance enhancements offered by Intel's libraries and for ensuring that Ollama can fully utilize the GPU capabilities. By following these steps, your AI PC will be primed for running Ollama leveraging Intel iGPUs.\n",
+ "\n",
+ "```\n",
+ "conda create -n llm-ollama python=3.11 -y\n",
+ "conda activate llm-ollama\n",
+ "conda install libuv -y\n",
+ "pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0\n",
+ "\n",
+ "```\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Ollama with Intel GPU support\n",
+ "\n",
+ "* Now that we have set up the environment, Intel GPU drivers, and runtime libraries, we can configure ollama to leverage the on-chip GPU.\n",
+ "* Open miniforge prompt and run the below commands. We Install IPEX-LLM for llama.cpp and to use llama.cpp with IPEX-LLM, first ensure that ipex-llm[cpp] is installed.\n",
+ "\n",
+ "### With the ollama environment active, use pip to install required libraries for GPU. \n",
+ "```\n",
+ "conda activate llm-ollama\n",
+ "pip install --pre --upgrade ipex-llm[cpp]\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "* Create a folder ollama and navigate to the folder\n",
+ "\n",
+ " ```\n",
+ " mkdir ollama\n",
+ " cd ollama\n",
+ " ```\n",
+ "
\n",
+ "\n",
+ "* Create a folder ollama and navigate to the folder\n",
+ "\n",
+ " ```\n",
+ " mkdir ollama\n",
+ " cd ollama\n",
+ " ```\n",
+ " \n",
+ "\n",
+ "* Open another miniforge prompt in administrator privilege mode and run the below command.\n",
+ " \n",
+ "* Navigate to the above \"ollama\" folder that you created and run the below commands\n",
+ " \n",
+ " ```\n",
+ " conda activate llm-ollama\n",
+ " init-ollama.bat # if init-ollama.bat is not available in your environment, restart your terminal\n",
+ "\n",
+ " ```\n",
+ "
\n",
+ "\n",
+ "* Open another miniforge prompt in administrator privilege mode and run the below command.\n",
+ " \n",
+ "* Navigate to the above \"ollama\" folder that you created and run the below commands\n",
+ " \n",
+ " ```\n",
+ " conda activate llm-ollama\n",
+ " init-ollama.bat # if init-ollama.bat is not available in your environment, restart your terminal\n",
+ "\n",
+ " ```\n",
+ "  \n",
+ "\n",
+ "* Open another Miniforge prompt, navigate to the ollama folder where we created the symbolic links above and run the below command\n",
+ "\n",
+ " ```\n",
+ " ollama serve\n",
+ "\n",
+ " ```\n",
+ "* ollama is now running in the backend and we should see as below\n",
+ "\n",
+ "
\n",
+ "\n",
+ "* Open another Miniforge prompt, navigate to the ollama folder where we created the symbolic links above and run the below command\n",
+ "\n",
+ " ```\n",
+ " ollama serve\n",
+ "\n",
+ " ```\n",
+ "* ollama is now running in the backend and we should see as below\n",
+ "\n",
+ "  \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41ca93a8-e995-4e0d-8361-0deb262fbe1c",
+ "metadata": {},
+ "source": [
+ "## Run llama3 using Ollama on AI PC\n",
+ "\n",
+ "Now that we have installed Ollama, let’s see how to run llama 3 on your AI PC!\n",
+ "Pull the Llama 3 8b from ollama repo:\n",
+ "\n",
+ "```\n",
+ "ollama pull llama3\n",
+ "\n",
+ "```\n",
+ "
\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41ca93a8-e995-4e0d-8361-0deb262fbe1c",
+ "metadata": {},
+ "source": [
+ "## Run llama3 using Ollama on AI PC\n",
+ "\n",
+ "Now that we have installed Ollama, let’s see how to run llama 3 on your AI PC!\n",
+ "Pull the Llama 3 8b from ollama repo:\n",
+ "\n",
+ "```\n",
+ "ollama pull llama3\n",
+ "\n",
+ "```\n",
+ " \n",
+ "\n",
+ "* Now, let’s create a custom llama 3 model and also configure all layers to be offloaded to the GPU.\n",
+ "* The main settings in the configuration file include num_gpu, which is set to 999 to ensure all layers utilize the GPU. We also configured the context length to 8192, the maximum supported by Llama 3.\n",
+ "* Additionally, we customized the system prompt to add a more playful touch to the assistant (Pika :)). Here is a sample [Model file](Modelfile/Modelfile.llama3).\n",
+ "\n",
+ "
\n",
+ "\n",
+ "* Now, let’s create a custom llama 3 model and also configure all layers to be offloaded to the GPU.\n",
+ "* The main settings in the configuration file include num_gpu, which is set to 999 to ensure all layers utilize the GPU. We also configured the context length to 8192, the maximum supported by Llama 3.\n",
+ "* Additionally, we customized the system prompt to add a more playful touch to the assistant (Pika :)). Here is a sample [Model file](Modelfile/Modelfile.llama3).\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "* Now that we have created a custom Modelfile, let’s create a custom model:\n",
+ "\n",
+ "```\n",
+ "ollama create llama3-gpu -f Modelfile/Modelfile.llama3\n",
+ "\n",
+ "```\n",
+ "\n",
+ "* Let’s see if the model got created. The new model is ready to be run!.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "* Now that we have created a custom Modelfile, let’s create a custom model:\n",
+ "\n",
+ "```\n",
+ "ollama create llama3-gpu -f Modelfile/Modelfile.llama3\n",
+ "\n",
+ "```\n",
+ "\n",
+ "* Let’s see if the model got created. The new model is ready to be run!.\n",
+ "\n",
+ "  \n",
+ "\n",
+ "* Finally, now let’s run the model.\n",
+ "```\n",
+ "ollama run llama3-gpu\n",
+ "\n",
+ "```\n",
+ "\n",
+ "* As you can see above llama 3 is running on iGPU on the AI PC.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "* Finally, now let’s run the model.\n",
+ "```\n",
+ "ollama run llama3-gpu\n",
+ "\n",
+ "```\n",
+ "\n",
+ "* As you can see above llama 3 is running on iGPU on the AI PC.\n",
+ "\n",
+ " \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f835dae5-ac6a-4a5a-bc12-49da5457dcb3",
+ "metadata": {},
+ "source": [
+ "## Example code to run the models using streamlit on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33b94504-fcc8-454f-8a8d-b7312b7c0d8e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_ollama.py\n",
+ "import ollama\n",
+ "import streamlit as st\n",
+ "\n",
+ "st.title(\"Let's Chat....🐼\")\n",
+ "\n",
+ "# Load ollama models\n",
+ "\n",
+ "model_list = [model[\"name\"] for model in ollama.list()[\"models\"]]\n",
+ "model = st.selectbox(\"Choose a model from the list\", model_list)\n",
+ "\n",
+ "if chat_input := st.chat_input(\"Hi, How are you?\"):\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " with st.chat_message(\"user\"):\n",
+ " st.markdown(chat_input)\n",
+ "\n",
+ " def generate_response(user_input):\n",
+ " response = ollama.chat(model=model, messages=[\n",
+ " {\n",
+ " 'role': 'user',\n",
+ " 'content': chat_input,\n",
+ " },\n",
+ " ],\n",
+ " stream=True,\n",
+ " ) \n",
+ " for res in response:\n",
+ " yield res[\"message\"][\"content\"] \n",
+ " st.write_stream(generate_response(chat_input))\n",
+ " del model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "666c1c8a-3355-4a1c-ae3e-06c4cb700ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_ollama.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ae906f4-6fb4-451b-a7b7-d408db21c694",
+ "metadata": {},
+ "source": [
+ "### Streamlit output runnling llama3\n",
+ "\n",
+ "Below is the screesnhot of llama3 is running on iGPU on the AI PC.\n",
+ "\n",
+ "
\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f835dae5-ac6a-4a5a-bc12-49da5457dcb3",
+ "metadata": {},
+ "source": [
+ "## Example code to run the models using streamlit on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33b94504-fcc8-454f-8a8d-b7312b7c0d8e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_ollama.py\n",
+ "import ollama\n",
+ "import streamlit as st\n",
+ "\n",
+ "st.title(\"Let's Chat....🐼\")\n",
+ "\n",
+ "# Load ollama models\n",
+ "\n",
+ "model_list = [model[\"name\"] for model in ollama.list()[\"models\"]]\n",
+ "model = st.selectbox(\"Choose a model from the list\", model_list)\n",
+ "\n",
+ "if chat_input := st.chat_input(\"Hi, How are you?\"):\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " with st.chat_message(\"user\"):\n",
+ " st.markdown(chat_input)\n",
+ "\n",
+ " def generate_response(user_input):\n",
+ " response = ollama.chat(model=model, messages=[\n",
+ " {\n",
+ " 'role': 'user',\n",
+ " 'content': chat_input,\n",
+ " },\n",
+ " ],\n",
+ " stream=True,\n",
+ " ) \n",
+ " for res in response:\n",
+ " yield res[\"message\"][\"content\"] \n",
+ " st.write_stream(generate_response(chat_input))\n",
+ " del model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "666c1c8a-3355-4a1c-ae3e-06c4cb700ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_ollama.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ae906f4-6fb4-451b-a7b7-d408db21c694",
+ "metadata": {},
+ "source": [
+ "### Streamlit output runnling llama3\n",
+ "\n",
+ "Below is the screesnhot of llama3 is running on iGPU on the AI PC.\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "84ee0974-02d6-452d-8d84-2c3b683357df",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675b6c0f-a230-4413-91c4-c483b70530cb",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5330c0d1-5369-41ac-a354-c2d8369c53a8",
+ "metadata": {},
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/3_llm_pytorch_gpu.ipynb b/3_llm_pytorch_gpu.ipynb
new file mode 100644
index 0000000..2d5d55c
--- /dev/null
+++ b/3_llm_pytorch_gpu.ipynb
@@ -0,0 +1,508 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4bdf80ae-10bd-438b-a5ae-76a5c5f99a6d",
+ "metadata": {},
+ "source": [
+ "# Inference using Pytorch on Intel GPUs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to run LLM inference using pytorch on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Setup the environment and install required libraries\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm python=3.11 libuv\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "\n",
+ "```\n",
+ "conda activate llm\n",
+ "\n",
+ "```\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "84ee0974-02d6-452d-8d84-2c3b683357df",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675b6c0f-a230-4413-91c4-c483b70530cb",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5330c0d1-5369-41ac-a354-c2d8369c53a8",
+ "metadata": {},
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/3_llm_pytorch_gpu.ipynb b/3_llm_pytorch_gpu.ipynb
new file mode 100644
index 0000000..2d5d55c
--- /dev/null
+++ b/3_llm_pytorch_gpu.ipynb
@@ -0,0 +1,508 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4bdf80ae-10bd-438b-a5ae-76a5c5f99a6d",
+ "metadata": {},
+ "source": [
+ "# Inference using Pytorch on Intel GPUs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to run LLM inference using pytorch on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Setup the environment and install required libraries\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm python=3.11 libuv\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "\n",
+ "```\n",
+ "conda activate llm\n",
+ "\n",
+ "```\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm environment active, use pip to install ipex-llm for GPU. \n",
+ "\n",
+ "* pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ (for US)\n",
+ "* pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/ (for CN)\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm environment active, use pip to install ipex-llm for GPU. \n",
+ "\n",
+ "* pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ (for US)\n",
+ "* pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/ (for CN)\n",
+ "\n",
+ " \n",
+ "\n",
+ "## Verify Installation\n",
+ "You can verify if ipex-llm is successfully installed following below steps.\n",
+ "\n",
+ "### Open the Miniforge Prompt and activate the Python environment llm you previously created:\n",
+ "```\n",
+ "conda activate llm\n",
+ "```\n",
+ "\n",
+ "\n",
+ "### Set the following environment variables according to your device:\n",
+ "For Intel iGPU:\n",
+ "\n",
+ "* set SYCL_CACHE_PERSISTENT=1\n",
+ "* set BIGDL_LLM_XMX_DISABLED=1\n",
+ " \n",
+ "
\n",
+ "\n",
+ "## Verify Installation\n",
+ "You can verify if ipex-llm is successfully installed following below steps.\n",
+ "\n",
+ "### Open the Miniforge Prompt and activate the Python environment llm you previously created:\n",
+ "```\n",
+ "conda activate llm\n",
+ "```\n",
+ "\n",
+ "\n",
+ "### Set the following environment variables according to your device:\n",
+ "For Intel iGPU:\n",
+ "\n",
+ "* set SYCL_CACHE_PERSISTENT=1\n",
+ "* set BIGDL_LLM_XMX_DISABLED=1\n",
+ " \n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Run Python Code\n",
+ "Launch the Python interactive shell by typing python in the Miniforge Prompt window and then press Enter.\n",
+ "Copy following code to Miniforge Prompt line by line and press Enter after copying each line.\n",
+ "\n",
+ "```\n",
+ "import torch \n",
+ "from ipex_llm.transformers import AutoModel,AutoModelForCausalLM \n",
+ "tensor_1 = torch.randn(1, 1, 40, 128).to('xpu') \n",
+ "tensor_2 = torch.randn(1, 1, 128, 40).to('xpu') \n",
+ "print(torch.matmul(tensor_1, tensor_2).size()) \n",
+ "\n",
+ "```\n",
+ "\n",
+ "You should see at the end:\n",
+ "torch.Size([1, 1, 40, 40])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "69541b1d-162b-4c8c-9311-df27db43531e",
+ "metadata": {},
+ "source": [
+ "### Install these packages to run the below code\n",
+ "```\n",
+ "pip install tiktoken transformers_stream_generator einops\n",
+ "\n",
+ "```\n",
+ "```\n",
+ "conda install -c conda-forge jupyter\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41ca93a8-e995-4e0d-8361-0deb262fbe1c",
+ "metadata": {},
+ "source": [
+ "## Code Walkthrough\n",
+ "\n",
+ "Now let’s play with a real LLM. We’ll be using the Qwen-1.8B-Chat model, a 1.8 billion parameter LLM for this demonstration. \n",
+ "Follow the steps below to setup and run the model, and observe how it responds to a prompt “What is AI?”.\n",
+ "\n",
+ "Below id the code snippet using Hugging Face's Transformers library to utilize the AutoModelForCausalLM class\n",
+ "\n",
+ "Note: When running LLMs on Intel iGPUs with limited memory size, we recommend setting cpu_embedding=True in the from_pretrained function. This will allow the memory-intensive embedding layer to utilize the CPU instead of GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f6de17b6-dd1a-4d97-be1a-d7a856411146",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from ipex_llm.transformers import AutoModelForCausalLM\n",
+ "from transformers import AutoTokenizer, GenerationConfig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "121808e7-7832-4cc2-8743-b0bc4d956112",
+ "metadata": {},
+ "source": [
+ "AutoModelForCausalLM is a class that automatically selects the appropriate model architecture for causal language modeling based on the pre-trained model specified, and AutoTokenizer is a class that automatically selects the appropriate tokenizer.\n",
+ "We then initialize the tokenizer and the model using the from_pretrained method, which loads the pre-trained "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe7fd7d2-8f01-4171-8cbc-8094fbc971ec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer = AutoTokenizer.from_pretrained(\"Qwen/Qwen-1_8B-Chat\",\n",
+ " trust_remote_code=True)\n",
+ "\n",
+ "# Load Model using ipex-llm and load it to GPU\n",
+ "model = AutoModelForCausalLM.from_pretrained(\"Qwen/Qwen-1_8B-Chat\",\n",
+ " load_in_4bit=True,\n",
+ " cpu_embedding=True,\n",
+ " trust_remote_code=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f4a7d9a-e1b6-4627-a507-1b537e533bdb",
+ "metadata": {},
+ "source": [
+ "#### Load it to the GPU"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cebdd91b-bd33-46d9-88b4-ac11c2eb09bb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = model.to('xpu')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "88c88efc-88cd-49f5-9f85-17fbd2824b53",
+ "metadata": {},
+ "source": [
+ "We define a text prompt that the model will use as a starting point to generate text."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32528937-3c95-400d-bb23-e059b45c1e67",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "question = \"What is AI?\"\n",
+ "prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "413c9731-a6f2-4da0-a27d-545b775d49b6",
+ "metadata": {},
+ "source": [
+ "* We use the tokenizer to encode the text prompt into a format that the model can understand. The return_tensors='pt' argument tells the tokenizer to return PyTorch tensors.\n",
+ "* We use the model's generate method to generate a sequence of text based on the input prompt. The max_length argument specifies the maximum length of the generated text. \n",
+ "* The temperature argument controls the randomness of the output (lower values make the output more deterministic and higher values make it more random).\n",
+ "* The num_return_sequences argument specifies the number of different sequences to generate.\n",
+ "* We use the tokenizer's decode method to convert the generated sequence of tokens back into human-readable text."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3f72f2e-fe84-455b-ad59-5a1391c51a4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "generation_config = GenerationConfig(use_cache=True)\n",
+ "with torch.inference_mode():\n",
+ " input_ids = tokenizer.encode(prompt, return_tensors=\"pt\").to('xpu')\n",
+ "\n",
+ " print('--------------------------------------Note-----------------------------------------')\n",
+ " print('| For the first time that each model runs on Intel iGPU/Intel Arc™ A300-Series or |')\n",
+ " print('| Pro A60, it may take several minutes for GPU kernels to compile and initialize. |')\n",
+ " print('| Please be patient until it finishes warm-up... |')\n",
+ " print('-----------------------------------------------------------------------------------')\n",
+ "\n",
+ " # To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks.\n",
+ " # If you're developing an application, you can incorporate this warm-up step into start-up or loading routine to enhance the user experience.\n",
+ " output = model.generate(input_ids,\n",
+ " do_sample=False,\n",
+ " max_new_tokens=32,\n",
+ " generation_config=generation_config) # warm-up\n",
+ "\n",
+ " print('Successfully finished warm-up, now start generation...')\n",
+ "\n",
+ " output = model.generate(input_ids,\n",
+ " do_sample=False,\n",
+ " max_new_tokens=32,\n",
+ " generation_config=generation_config).cpu()\n",
+ " output_str = tokenizer.decode(output[0], skip_special_tokens=True)\n",
+ " print(output_str)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Complete code snippet using Streamlit\n",
+ "\n",
+ "### Install streamlit\n",
+ "```\n",
+ "pip install streamlit\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "666c1c8a-3355-4a1c-ae3e-06c4cb700ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/chat.py\n",
+ "import os\n",
+ "\n",
+ "os.environ[\"SYCL_CACHE_PERSISTENT\"]=\"1\"\n",
+ "os.environ[\"BIGDL_LLM_XMX_DISABLED\"]=\"1\"\n",
+ "\n",
+ "import threading\n",
+ "\n",
+ "import streamlit as st\n",
+ "\n",
+ "from ipex_llm.transformers import AutoModelForCausalLM\n",
+ "from transformers import AutoTokenizer, GenerationConfig, TextIteratorStreamer\n",
+ "import torch\n",
+ "\n",
+ "\n",
+ "MODEL_CACHE = {}\n",
+ "\n",
+ "\n",
+ "def save_model_thread(model, model_path):\n",
+ " model.save_low_bit(model_path)\n",
+ " print(f\"Model saved to {model_path}\")\n",
+ "\n",
+ "\n",
+ "def warmup_model(model, tokenizer):\n",
+ " question = \"Hello, how are you?\"\n",
+ " tokenizer.pad_token = tokenizer.eos_token\n",
+ " if model.name_or_path.startswith(\"microsoft\"):\n",
+ " prompt = f\"<|user|>\\n{question}<|end|>\\n<|assistant|>\"\n",
+ " else:\n",
+ " prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)\n",
+ " dummy_input = tokenizer(prompt, return_tensors=\"pt\").to(\"xpu\")\n",
+ " generation_config = GenerationConfig(use_cache=True,\n",
+ " top_k=50,\n",
+ " top_p=0.95,\n",
+ " temperature=0.7, do_sample=True,\n",
+ " )\n",
+ " _ = model.generate(**dummy_input, generation_config=generation_config)\n",
+ " print(\"Model warmed up successfully!\")\n",
+ "\n",
+ "\n",
+ "def load_model(model_name: str = \"Qwen/Qwen-1_8B-Chat\"):\n",
+ " if model_name in MODEL_CACHE:\n",
+ " return MODEL_CACHE[model_name]\n",
+ "\n",
+ " tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)\n",
+ " model_path = f\"./model_local_cache/{model_name}\"\n",
+ "\n",
+ " if os.path.exists(model_path):\n",
+ " print(f\"Loading model from {model_path}\")\n",
+ " model = AutoModelForCausalLM.load_low_bit(\n",
+ " model_path, cpu_embedding=True, trust_remote_code=True\n",
+ " )\n",
+ " else:\n",
+ " print(f\"Loading model from {model_name}\")\n",
+ " model = AutoModelForCausalLM.from_pretrained(\n",
+ " model_name,\n",
+ " load_in_4bit=True,\n",
+ " cpu_embedding=True,\n",
+ " trust_remote_code=True\n",
+ " )\n",
+ " save_model_thread(model, model_path)\n",
+ "\n",
+ " model = model.to(\"xpu\")\n",
+ "\n",
+ " MODEL_CACHE[model_name] = (model, tokenizer)\n",
+ " print(\"Model loaded successfully!\")\n",
+ " return model, tokenizer\n",
+ "\n",
+ "\n",
+ "def get_response(model, tokenizer, input_text: str):\n",
+ " question = input_text\n",
+ " tokenizer.pad_token = tokenizer.eos_token\n",
+ " if model.name_or_path.startswith(\"microsoft\"):\n",
+ " prompt = f\"<|user|>\\n{question}<|end|>\\n<|assistant|>\"\n",
+ " else:\n",
+ " prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)\n",
+ "\n",
+ " with torch.inference_mode():\n",
+ " input_ids = tokenizer(prompt, return_tensors=\"pt\").to(\"xpu\")\n",
+ " streamer = TextIteratorStreamer(\n",
+ " tokenizer, skip_prompt=False, skip_special_tokens=True\n",
+ " )\n",
+ "\n",
+ " generation_config = GenerationConfig(\n",
+ " use_cache=True, top_k=50, top_p=0.95,\n",
+ " temperature=0.7, do_sample=True,\n",
+ " )\n",
+ "\n",
+ " kwargs = dict(\n",
+ " input_ids,\n",
+ " streamer=streamer,\n",
+ " max_new_tokens=256,\n",
+ " generation_config=generation_config,\n",
+ " )\n",
+ " thread = threading.Thread(target=model.generate, kwargs=kwargs)\n",
+ " thread.start()\n",
+ " return streamer\n",
+ "\n",
+ "\n",
+ "def main():\n",
+ " if \"model\" not in st.session_state:\n",
+ " st.session_state.model = None\n",
+ " if \"tokenizer\" not in st.session_state:\n",
+ " st.session_state.tokenizer = None\n",
+ "\n",
+ " st.header(\"Lets chat... 🐻❄️\")\n",
+ " selected_model = st.selectbox(\n",
+ " \"Please select a model\", (\"Qwen/Qwen-1_8B-Chat\", \"microsoft/Phi-3-mini-4k-instruct\")\n",
+ " )\n",
+ "\n",
+ " if st.button(\"Load Model\"):\n",
+ " with st.spinner(\"Loading...\"):\n",
+ " st.session_state.model, st.session_state.tokenizer = load_model(\n",
+ " model_name=selected_model\n",
+ " )\n",
+ " if (\n",
+ " st.session_state.model is not None\n",
+ " and st.session_state.tokenizer is not None\n",
+ " ):\n",
+ " st.success(\"Model loaded successfully!\")\n",
+ " st.info(\"Warming up the model...\")\n",
+ " warmup_model(st.session_state.model, st.session_state.tokenizer)\n",
+ " st.success(\"Model warmed up and ready to use!\")\n",
+ " else:\n",
+ " st.error(\"Failed to load the model.\")\n",
+ "\n",
+ " chat_container = st.container()\n",
+ " with chat_container:\n",
+ " st.subheader(\"Chat\")\n",
+ " input_text = st.text_input(\"Enter your input here...\")\n",
+ " if st.button(\"Generate\"):\n",
+ " if st.session_state.model is None or st.session_state.tokenizer is None:\n",
+ " st.warning(\"Please load the model first.\")\n",
+ " else:\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " streamer = get_response(\n",
+ " st.session_state.model, st.session_state.tokenizer, input_text\n",
+ " )\n",
+ " st.write_stream(streamer)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " main()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "55460213-46a0-4d12-b7e2-38245a7bd9aa",
+ "metadata": {},
+ "source": [
+ "### Sample output stream\n",
+ "\n",
+ "Below is the screenshot of sample output and offloaded to the iGPU\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Run Python Code\n",
+ "Launch the Python interactive shell by typing python in the Miniforge Prompt window and then press Enter.\n",
+ "Copy following code to Miniforge Prompt line by line and press Enter after copying each line.\n",
+ "\n",
+ "```\n",
+ "import torch \n",
+ "from ipex_llm.transformers import AutoModel,AutoModelForCausalLM \n",
+ "tensor_1 = torch.randn(1, 1, 40, 128).to('xpu') \n",
+ "tensor_2 = torch.randn(1, 1, 128, 40).to('xpu') \n",
+ "print(torch.matmul(tensor_1, tensor_2).size()) \n",
+ "\n",
+ "```\n",
+ "\n",
+ "You should see at the end:\n",
+ "torch.Size([1, 1, 40, 40])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "69541b1d-162b-4c8c-9311-df27db43531e",
+ "metadata": {},
+ "source": [
+ "### Install these packages to run the below code\n",
+ "```\n",
+ "pip install tiktoken transformers_stream_generator einops\n",
+ "\n",
+ "```\n",
+ "```\n",
+ "conda install -c conda-forge jupyter\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41ca93a8-e995-4e0d-8361-0deb262fbe1c",
+ "metadata": {},
+ "source": [
+ "## Code Walkthrough\n",
+ "\n",
+ "Now let’s play with a real LLM. We’ll be using the Qwen-1.8B-Chat model, a 1.8 billion parameter LLM for this demonstration. \n",
+ "Follow the steps below to setup and run the model, and observe how it responds to a prompt “What is AI?”.\n",
+ "\n",
+ "Below id the code snippet using Hugging Face's Transformers library to utilize the AutoModelForCausalLM class\n",
+ "\n",
+ "Note: When running LLMs on Intel iGPUs with limited memory size, we recommend setting cpu_embedding=True in the from_pretrained function. This will allow the memory-intensive embedding layer to utilize the CPU instead of GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f6de17b6-dd1a-4d97-be1a-d7a856411146",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from ipex_llm.transformers import AutoModelForCausalLM\n",
+ "from transformers import AutoTokenizer, GenerationConfig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "121808e7-7832-4cc2-8743-b0bc4d956112",
+ "metadata": {},
+ "source": [
+ "AutoModelForCausalLM is a class that automatically selects the appropriate model architecture for causal language modeling based on the pre-trained model specified, and AutoTokenizer is a class that automatically selects the appropriate tokenizer.\n",
+ "We then initialize the tokenizer and the model using the from_pretrained method, which loads the pre-trained "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe7fd7d2-8f01-4171-8cbc-8094fbc971ec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer = AutoTokenizer.from_pretrained(\"Qwen/Qwen-1_8B-Chat\",\n",
+ " trust_remote_code=True)\n",
+ "\n",
+ "# Load Model using ipex-llm and load it to GPU\n",
+ "model = AutoModelForCausalLM.from_pretrained(\"Qwen/Qwen-1_8B-Chat\",\n",
+ " load_in_4bit=True,\n",
+ " cpu_embedding=True,\n",
+ " trust_remote_code=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f4a7d9a-e1b6-4627-a507-1b537e533bdb",
+ "metadata": {},
+ "source": [
+ "#### Load it to the GPU"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cebdd91b-bd33-46d9-88b4-ac11c2eb09bb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = model.to('xpu')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "88c88efc-88cd-49f5-9f85-17fbd2824b53",
+ "metadata": {},
+ "source": [
+ "We define a text prompt that the model will use as a starting point to generate text."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32528937-3c95-400d-bb23-e059b45c1e67",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "question = \"What is AI?\"\n",
+ "prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "413c9731-a6f2-4da0-a27d-545b775d49b6",
+ "metadata": {},
+ "source": [
+ "* We use the tokenizer to encode the text prompt into a format that the model can understand. The return_tensors='pt' argument tells the tokenizer to return PyTorch tensors.\n",
+ "* We use the model's generate method to generate a sequence of text based on the input prompt. The max_length argument specifies the maximum length of the generated text. \n",
+ "* The temperature argument controls the randomness of the output (lower values make the output more deterministic and higher values make it more random).\n",
+ "* The num_return_sequences argument specifies the number of different sequences to generate.\n",
+ "* We use the tokenizer's decode method to convert the generated sequence of tokens back into human-readable text."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3f72f2e-fe84-455b-ad59-5a1391c51a4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "generation_config = GenerationConfig(use_cache=True)\n",
+ "with torch.inference_mode():\n",
+ " input_ids = tokenizer.encode(prompt, return_tensors=\"pt\").to('xpu')\n",
+ "\n",
+ " print('--------------------------------------Note-----------------------------------------')\n",
+ " print('| For the first time that each model runs on Intel iGPU/Intel Arc™ A300-Series or |')\n",
+ " print('| Pro A60, it may take several minutes for GPU kernels to compile and initialize. |')\n",
+ " print('| Please be patient until it finishes warm-up... |')\n",
+ " print('-----------------------------------------------------------------------------------')\n",
+ "\n",
+ " # To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks.\n",
+ " # If you're developing an application, you can incorporate this warm-up step into start-up or loading routine to enhance the user experience.\n",
+ " output = model.generate(input_ids,\n",
+ " do_sample=False,\n",
+ " max_new_tokens=32,\n",
+ " generation_config=generation_config) # warm-up\n",
+ "\n",
+ " print('Successfully finished warm-up, now start generation...')\n",
+ "\n",
+ " output = model.generate(input_ids,\n",
+ " do_sample=False,\n",
+ " max_new_tokens=32,\n",
+ " generation_config=generation_config).cpu()\n",
+ " output_str = tokenizer.decode(output[0], skip_special_tokens=True)\n",
+ " print(output_str)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Complete code snippet using Streamlit\n",
+ "\n",
+ "### Install streamlit\n",
+ "```\n",
+ "pip install streamlit\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "666c1c8a-3355-4a1c-ae3e-06c4cb700ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/chat.py\n",
+ "import os\n",
+ "\n",
+ "os.environ[\"SYCL_CACHE_PERSISTENT\"]=\"1\"\n",
+ "os.environ[\"BIGDL_LLM_XMX_DISABLED\"]=\"1\"\n",
+ "\n",
+ "import threading\n",
+ "\n",
+ "import streamlit as st\n",
+ "\n",
+ "from ipex_llm.transformers import AutoModelForCausalLM\n",
+ "from transformers import AutoTokenizer, GenerationConfig, TextIteratorStreamer\n",
+ "import torch\n",
+ "\n",
+ "\n",
+ "MODEL_CACHE = {}\n",
+ "\n",
+ "\n",
+ "def save_model_thread(model, model_path):\n",
+ " model.save_low_bit(model_path)\n",
+ " print(f\"Model saved to {model_path}\")\n",
+ "\n",
+ "\n",
+ "def warmup_model(model, tokenizer):\n",
+ " question = \"Hello, how are you?\"\n",
+ " tokenizer.pad_token = tokenizer.eos_token\n",
+ " if model.name_or_path.startswith(\"microsoft\"):\n",
+ " prompt = f\"<|user|>\\n{question}<|end|>\\n<|assistant|>\"\n",
+ " else:\n",
+ " prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)\n",
+ " dummy_input = tokenizer(prompt, return_tensors=\"pt\").to(\"xpu\")\n",
+ " generation_config = GenerationConfig(use_cache=True,\n",
+ " top_k=50,\n",
+ " top_p=0.95,\n",
+ " temperature=0.7, do_sample=True,\n",
+ " )\n",
+ " _ = model.generate(**dummy_input, generation_config=generation_config)\n",
+ " print(\"Model warmed up successfully!\")\n",
+ "\n",
+ "\n",
+ "def load_model(model_name: str = \"Qwen/Qwen-1_8B-Chat\"):\n",
+ " if model_name in MODEL_CACHE:\n",
+ " return MODEL_CACHE[model_name]\n",
+ "\n",
+ " tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)\n",
+ " model_path = f\"./model_local_cache/{model_name}\"\n",
+ "\n",
+ " if os.path.exists(model_path):\n",
+ " print(f\"Loading model from {model_path}\")\n",
+ " model = AutoModelForCausalLM.load_low_bit(\n",
+ " model_path, cpu_embedding=True, trust_remote_code=True\n",
+ " )\n",
+ " else:\n",
+ " print(f\"Loading model from {model_name}\")\n",
+ " model = AutoModelForCausalLM.from_pretrained(\n",
+ " model_name,\n",
+ " load_in_4bit=True,\n",
+ " cpu_embedding=True,\n",
+ " trust_remote_code=True\n",
+ " )\n",
+ " save_model_thread(model, model_path)\n",
+ "\n",
+ " model = model.to(\"xpu\")\n",
+ "\n",
+ " MODEL_CACHE[model_name] = (model, tokenizer)\n",
+ " print(\"Model loaded successfully!\")\n",
+ " return model, tokenizer\n",
+ "\n",
+ "\n",
+ "def get_response(model, tokenizer, input_text: str):\n",
+ " question = input_text\n",
+ " tokenizer.pad_token = tokenizer.eos_token\n",
+ " if model.name_or_path.startswith(\"microsoft\"):\n",
+ " prompt = f\"<|user|>\\n{question}<|end|>\\n<|assistant|>\"\n",
+ " else:\n",
+ " prompt = \"user: {prompt}\\n\\nassistant:\".format(prompt=question)\n",
+ "\n",
+ " with torch.inference_mode():\n",
+ " input_ids = tokenizer(prompt, return_tensors=\"pt\").to(\"xpu\")\n",
+ " streamer = TextIteratorStreamer(\n",
+ " tokenizer, skip_prompt=False, skip_special_tokens=True\n",
+ " )\n",
+ "\n",
+ " generation_config = GenerationConfig(\n",
+ " use_cache=True, top_k=50, top_p=0.95,\n",
+ " temperature=0.7, do_sample=True,\n",
+ " )\n",
+ "\n",
+ " kwargs = dict(\n",
+ " input_ids,\n",
+ " streamer=streamer,\n",
+ " max_new_tokens=256,\n",
+ " generation_config=generation_config,\n",
+ " )\n",
+ " thread = threading.Thread(target=model.generate, kwargs=kwargs)\n",
+ " thread.start()\n",
+ " return streamer\n",
+ "\n",
+ "\n",
+ "def main():\n",
+ " if \"model\" not in st.session_state:\n",
+ " st.session_state.model = None\n",
+ " if \"tokenizer\" not in st.session_state:\n",
+ " st.session_state.tokenizer = None\n",
+ "\n",
+ " st.header(\"Lets chat... 🐻❄️\")\n",
+ " selected_model = st.selectbox(\n",
+ " \"Please select a model\", (\"Qwen/Qwen-1_8B-Chat\", \"microsoft/Phi-3-mini-4k-instruct\")\n",
+ " )\n",
+ "\n",
+ " if st.button(\"Load Model\"):\n",
+ " with st.spinner(\"Loading...\"):\n",
+ " st.session_state.model, st.session_state.tokenizer = load_model(\n",
+ " model_name=selected_model\n",
+ " )\n",
+ " if (\n",
+ " st.session_state.model is not None\n",
+ " and st.session_state.tokenizer is not None\n",
+ " ):\n",
+ " st.success(\"Model loaded successfully!\")\n",
+ " st.info(\"Warming up the model...\")\n",
+ " warmup_model(st.session_state.model, st.session_state.tokenizer)\n",
+ " st.success(\"Model warmed up and ready to use!\")\n",
+ " else:\n",
+ " st.error(\"Failed to load the model.\")\n",
+ "\n",
+ " chat_container = st.container()\n",
+ " with chat_container:\n",
+ " st.subheader(\"Chat\")\n",
+ " input_text = st.text_input(\"Enter your input here...\")\n",
+ " if st.button(\"Generate\"):\n",
+ " if st.session_state.model is None or st.session_state.tokenizer is None:\n",
+ " st.warning(\"Please load the model first.\")\n",
+ " else:\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " streamer = get_response(\n",
+ " st.session_state.model, st.session_state.tokenizer, input_text\n",
+ " )\n",
+ " st.write_stream(streamer)\n",
+ "\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " main()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "55460213-46a0-4d12-b7e2-38245a7bd9aa",
+ "metadata": {},
+ "source": [
+ "### Sample output stream\n",
+ "\n",
+ "Below is the screenshot of sample output and offloaded to the iGPU\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c3a79f8-6b8e-4db8-8ac7-534b3518201e",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "326a0eec-e519-4325-93ec-be1cdb261dfd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/chat.py"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df414428-f466-412b-a1a1-8706ffd7adf1",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/4_llm-rag.ipynb b/4_llm-rag.ipynb
new file mode 100644
index 0000000..327e68f
--- /dev/null
+++ b/4_llm-rag.ipynb
@@ -0,0 +1,543 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "02a561f4",
+ "metadata": {},
+ "source": [
+ "# Create a RAG system on AIPC\n",
+ "\n",
+ "**Retrieval-augmented generation (RAG)** is a technique for augmenting LLM knowledge with additional, often private or real-time, data. LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG)."
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "4fb8b0e4",
+ "metadata": {},
+ "source": [
+ "## Run QA over Document\n",
+ "\n",
+ "Now, when model created, we can setup Chatbot interface using Streamlit\n",
+ "\n",
+ "A typical RAG application has two main components:\n",
+ "\n",
+ "- **Indexing**: a pipeline for ingesting data from a source and indexing it. This usually happen offline.\n",
+ "\n",
+ "- **Retrieval and generation**: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.\n",
+ "\n",
+ "The most common full sequence from raw data to answer looks like:\n",
+ "\n",
+ "**Indexing**\n",
+ "\n",
+ "1. `Load`: First we need to load our data. We’ll use DocumentLoaders for this.\n",
+ "2. `Split`: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t in a model’s finite context window.\n",
+ "3. `Store`: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.\n",
+ "\n",
+ "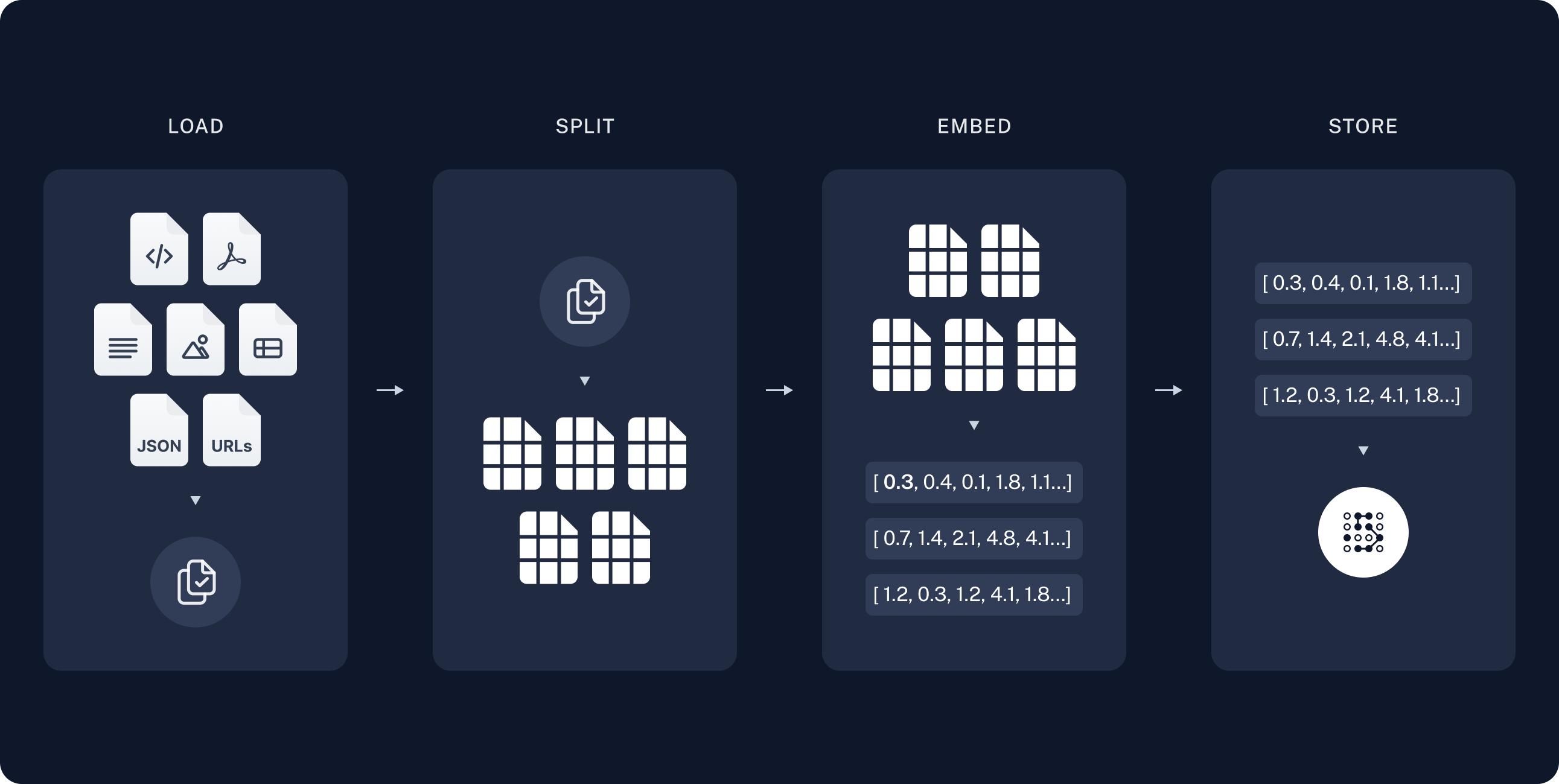\n",
+ "\n",
+ "**Retrieval and generation**\n",
+ "\n",
+ "1. `Retrieve`: Given a user input, relevant splits are retrieved from storage using a Retriever.\n",
+ "2. `Generate`: A LLM produces an answer using a prompt that includes the question and the retrieved data.\n",
+ "\n",
+ "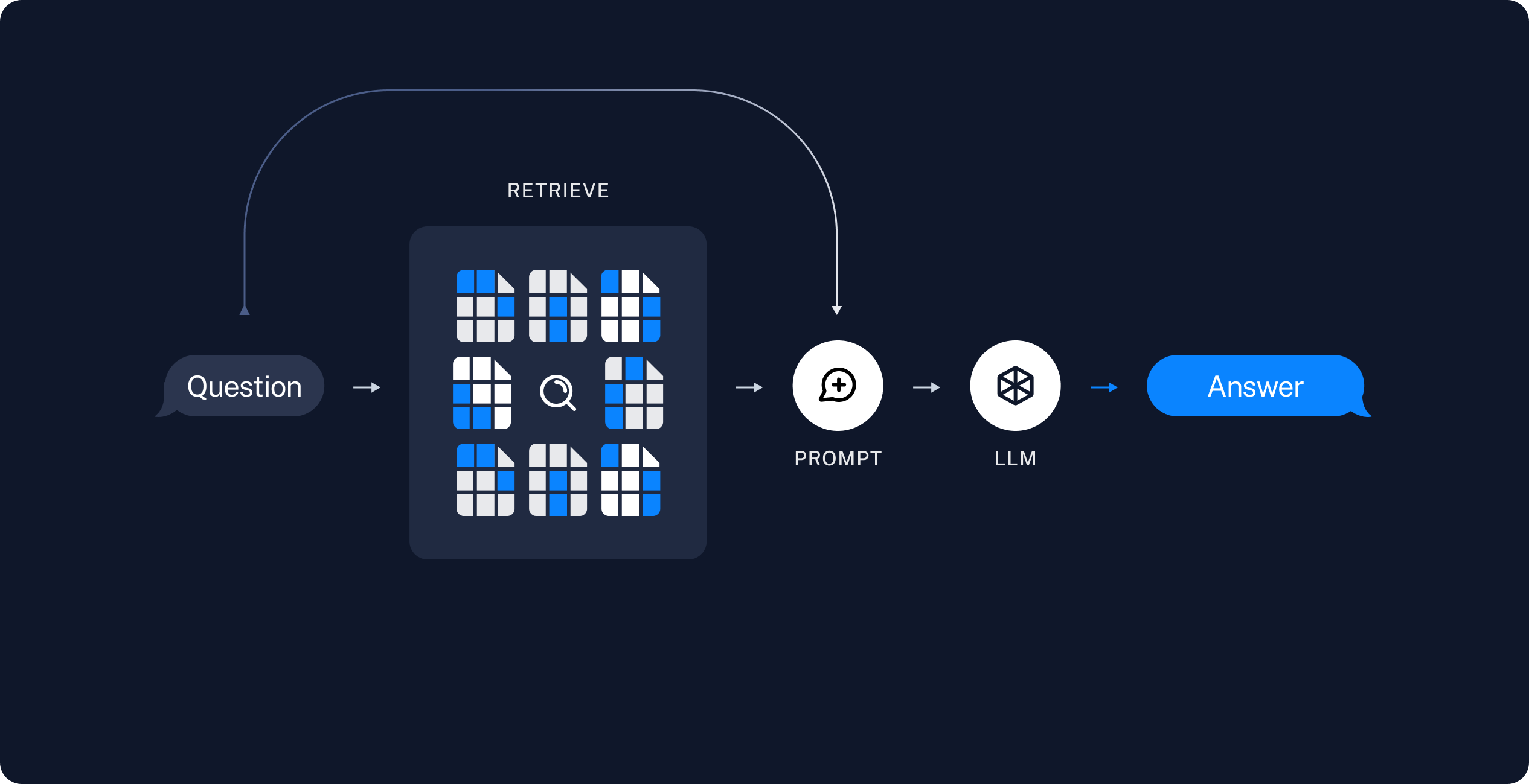\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "602f8ebd-789c-4eb2-b54d-b23d8f1d8e7b",
+ "metadata": {},
+ "source": [
+ "We can build a RAG pipeline of LangChain through [`create_retrieval_chain`](https://python.langchain.com/docs/modules/chains/), which will help to create a chain to connect RAG components including:\n",
+ "\n",
+ "- [`Vector stores`](https://python.langchain.com/docs/modules/data_connection/vectorstores/),\n",
+ "- [`Retrievers`](https://python.langchain.com/docs/modules/data_connection/retrievers/)\n",
+ "- [`LLM`](https://python.langchain.com/docs/integrations/llms/)\n",
+ "- [`Embedding`](https://python.langchain.com/docs/integrations/text_embedding/)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "34cc6ae1-3321-4a10-83a8-fb4169516391",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "import warnings\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "\n",
+ "from langchain_community import document_loaders, embeddings, vectorstores, llms\n",
+ "from langchain_community.embeddings.fastembed import FastEmbedEmbeddings\n",
+ "from langchain import chains, text_splitter, PromptTemplate\n",
+ "\n",
+ "OLLAMA_BASE_URL = \"http://localhost:11434\"\n",
+ "VECTOR_DB_DIR = \"vector_dbs\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c179e7c1-8152-4d5c-b2a2-b5aaff8773bd",
+ "metadata": {},
+ "source": [
+ "### Document Loaders in RAG\n",
+ "\n",
+ "* Document loaders in RAG are used to load and preprocess the documents that will be used for retrieval during the question answering process.\n",
+ "* Document loaders are responsible for preprocessing the documents. This includes tokenizing the text, converting it to the format expected by the retriever, and creating batches of documents.\n",
+ "* Document loaders work in conjunction with the retriever in RAG. The retriever uses the documents loaded by the document loader to find the most relevant documents for a given query.\n",
+ "* The WebBaseLoader in Retrieval Augmented Generation (RAG) is a type of document loader that is designed to load documents from the web.\n",
+ "* The WebBaseLoader is used when the documents for retrieval are not stored locally or in a Hugging Face dataset, but are instead located on the web. This can be useful when you want to use the most up-to-date information available on the internet for your question answering system\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd29cec6-0ec9-4074-9068-b12fb4be5ca9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def load_document(url):\n",
+ " print(\"Loading document from URL...\")\n",
+ " loader = document_loaders.WebBaseLoader(url)\n",
+ " return loader.load()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a21a5840-ac75-448d-b3d8-f86a40fe8a73",
+ "metadata": {},
+ "source": [
+ "### Text splitter\n",
+ "\n",
+ "* RecursiveCharacterTextSplitter is used to split text into smaller pieces recursively at the character level. \n",
+ "* split_documents fuctions splits larger documents into smaller chunks, for easier processing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6488b84c-830c-41e9-96a4-5fcf728ad6d6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def split_document(text, chunk_size=3000, overlap=200):\n",
+ " print(\"Splitting document into chunks...\")\n",
+ " text_splitter_instance = text_splitter.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)\n",
+ " return text_splitter_instance.split_documents(text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc257b5f-1e36-4273-9b41-4c45c2b21106",
+ "metadata": {},
+ "source": [
+ "### Huggingface emdeggings\n",
+ "In Retrieval Augmented Generation (RAG) embeddings play a crucial role in the retrieval of relevant documents for a given query.\n",
+ "\n",
+ "* In RAG, each document in the knowledge base is represented as a dense vector, also known as an embedding. These embeddings are typically generated by a transformer model.\n",
+ "* When a query is received, it is also converted into an embedding using the same transformer model. This ensures that the query and the documents are in the same vector space, making it possible to compare them.\n",
+ "* Retrieval: The retrieval step in RAG involves finding the documents whose embeddings are most similar to the query embedding. This is typically done using a nearest neighbor search.\n",
+ "\n",
+ "#### Sentence transformers\n",
+ "\n",
+ "* You can use a Sentence Transformer to generate embeddings for each document in your knowledge base. Since Sentence Transformers are designed to capture the semantic meaning of sentences, these embeddings should do a good job of representing the content of the documents.\n",
+ "* You can also use a Sentence Transformer to generate an embedding for the query. This ensures that the query and the documents are in the same vector space, making it possible to compare them.\n",
+ "* By using Sentence Transformers, you can potentially improve the quality of the retrieval step in RAG. Since Sentence Transformers are designed to capture the semantic meaning of sentences, they should be able to find documents that are semantically relevant to the query, even if the query and the documents do not share any exact words.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b55af744-4ffd-4dfd-b85a-aa5ff401b6a2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def initialize_embedding_fn(embedding_type=\"huggingface\", model_name=\"sentence-transformers/all-MiniLM-l6-v2\"):\n",
+ " print(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " if embedding_type == \"ollama\":\n",
+ " model_name = chat_model\n",
+ " return embeddings.OllamaEmbeddings(model=model_name, base_url=OLLAMA_BASE_URL)\n",
+ " elif embedding_type == \"huggingface\":\n",
+ " model_name = \"sentence-transformers/paraphrase-MiniLM-L3-v2\"\n",
+ " return embeddings.HuggingFaceEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"nomic\":\n",
+ " return embeddings.NomicEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"fastembed\":\n",
+ " return FastEmbedEmbeddings(threads=16)\n",
+ " else:\n",
+ " raise ValueError(f\"Unsupported embedding type: {embedding_type}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "177d4ccf-fd68-4380-9a98-01de673e83c9",
+ "metadata": {},
+ "source": [
+ "### Create and get embeddings using ChromaDB\n",
+ "\n",
+ "Here's a flow chart that describes how embeddings work in a RAG model with ChromaDB:\n",
+ "\n",
+ "* Query Input: The user inputs a query.\n",
+ "* Query Embedding: The query is passed through a transformer-based encoder (like BERT or RoBERTa) to generate a query embedding.\n",
+ "* Document Embedding: Each document in the ChromaDB is also passed through a transformer-based encoder to generate a document embedding. This is typically done offline and the embeddings are stored in the database for efficient retrieval.\n",
+ "* Embedding Comparison: The query embedding is compared with each document embedding in the ChromaDB. This is done by calculating the cosine similarity or dot product between the query embedding and each document embedding.\n",
+ "* Document Retrieval: The documents with the highest similarity scores are retrieved. The number of documents retrieved is a hyperparameter that can be tuned.\n",
+ "* Answer Generation: The retrieved documents and the query are passed to a sequence-to-sequence model (like BART or T5) to generate an answer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2b872757-5f72-45e3-ab86-de4edae8af7f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_or_create_embeddings(document_url, embedding_fn, persist_dir=VECTOR_DB_DIR):\n",
+ " vector_store_path = os.path.join(os.getcwd(), persist_dir) \n",
+ " if os.path.exists(vector_store_path):\n",
+ " print(\"Loading existing vector store...\")\n",
+ " return vectorstores.Chroma(persist_directory=persist_dir, embedding_function=embedding_fn)\n",
+ " else:\n",
+ " start_time = time.time()\n",
+ " print(\"No existing vector store found. Creating new one...\")\n",
+ " document = load_document(document_url)\n",
+ " documents = split_document(document)\n",
+ " vector_store = vectorstores.Chroma.from_documents(\n",
+ " documents=documents,\n",
+ " embedding=embedding_fn,\n",
+ " persist_directory=persist_dir\n",
+ " )\n",
+ " vector_store.persist()\n",
+ " print(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " return vector_store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c806373-8179-4b95-adfb-8eebbb613baf",
+ "metadata": {},
+ "source": [
+ "### Retrievers\n",
+ "\n",
+ "* Retrievers are responsible for fetching relevant documents from a document store or knowledge base given a query. The retrieved documents are then used by the generator to produce a response.\n",
+ "* RetrievalQA is a type of question answering system that uses a retriever to fetch relevant documents given a question, and then uses a reader to extract the answer from the retrieved documents.\n",
+ "* RetrievalQA can be seen as a two-step process:\n",
+ " * Retrieval: The retriever fetches relevant documents from the document store given a query. \n",
+ " * Generation: The generator uses the retrieved documents to generate a response.\n",
+ "* This two-step process allows RAG to leverage the strengths of both retrieval-based and generation-based approaches to question answering. The retriever allows RAG to efficiently search a large document store, while the generator allows RAG to generate detailed and coherent responses.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2b92cbb3-a9be-4d9a-810f-92b8e43105df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def handle_user_interaction(vector_store, chat_model):\n",
+ " prompt_template = \"\"\"\n",
+ " Use the following pieces of context to answer the question at the end. \n",
+ " If you do not know the answer, answer 'I don't know', limit your response to the answer and nothing more. \n",
+ "\n",
+ " {context}\n",
+ "\n",
+ " Question: {question}\n",
+ " \"\"\"\n",
+ " prompt = PromptTemplate(template=prompt_template, input_variables=[\"context\", \"question\"])\n",
+ " chain_type_kwargs = {\"prompt\": prompt}\n",
+ " retriever = vector_store.as_retriever(search_kwargs={\"k\": 4})\n",
+ " qachain = chains.RetrievalQA.from_chain_type(llm=chat_model, retriever=retriever, chain_type=\"stuff\", chain_type_kwargs=chain_type_kwargs)\n",
+ " qachain.invoke({\"query\": \"what is this about?\"})\n",
+ " print(f\"Model warmup complete...\")\n",
+ " while True:\n",
+ " question = input(\"Enter your question (or 'quit' to exit): \")\n",
+ " if question.lower() == 'quit':\n",
+ " break\n",
+ " start_time = time.time()\n",
+ " answer = qachain.invoke({\"query\": question})\n",
+ " print(f\"Answer: {answer['result']}\")\n",
+ " print(f\"Response time: {time.time() - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8bc1652-788e-4f1b-9684-313a82cb25f3",
+ "metadata": {},
+ "source": [
+ "### Run the application"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "114cd97b-9aec-4d59-a97e-c2bab0767336",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "def main(document_url, embedding_type, chat_model):\n",
+ " embedding_fn = initialize_embedding_fn(embedding_type)\n",
+ " vector_store = get_or_create_embeddings(document_url, embedding_fn)\n",
+ " chat_model_instance = llms.Ollama(base_url=OLLAMA_BASE_URL, model=chat_model)\n",
+ " handle_user_interaction(vector_store, chat_model_instance)\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " document_url = \"https://www.gutenberg.org/files/1727/1727-h/1727-h.htm\" \n",
+ " embedding_type = \"huggingface\"\n",
+ " chat_model = \"llama3:latest\"\n",
+ " main(document_url, embedding_type, chat_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6b0da830-f207-4035-8d63-bb6f4884b4a6",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c33911e-84ab-4346-92a4-3ead03f9d257",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_rag_chromadb.py\n",
+ "import streamlit as st\n",
+ "import time\n",
+ "import os\n",
+ "import warnings\n",
+ "import ollama\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "\n",
+ "from langchain_community import document_loaders, embeddings, vectorstores, llms\n",
+ "from langchain_community.embeddings.fastembed import FastEmbedEmbeddings\n",
+ "from langchain import chains, text_splitter, PromptTemplate\n",
+ "\n",
+ "OLLAMA_BASE_URL = \"http://localhost:11434\"\n",
+ "VECTOR_DB_DIR = \"vector_dbs\"\n",
+ "\n",
+ "st.header(\"LLM Rag 🐻❄️\")\n",
+ "\n",
+ "\n",
+ "models = [model[\"name\"] for model in ollama.list()[\"models\"]]\n",
+ "model = st.selectbox(\"Choose a model from the list\", models)\n",
+ "\n",
+ "# Input text to load the document\n",
+ "url_path = st.text_input(\"Enter the URL to load for RAG:\",value=\"https://www.gutenberg.org/files/1727/1727-h/1727-h.htm\", key=\"url_path\")\n",
+ "\n",
+ "# Select embedding type\n",
+ "embedding_type = st.selectbox(\"Please select an embedding type\", (\"ollama\", \"huggingface\", \"nomic\", \"fastembed\"),index=1)\n",
+ "\n",
+ "# Input for RAG\n",
+ "question = st.text_input(\"Enter the question for RAG:\", value=\"What is this about\", key=\"question\")\n",
+ "\n",
+ "## Load the document using document_loaders\n",
+ "def load_document(url):\n",
+ " print(\"Loading document from URL...\")\n",
+ " st.markdown(''' :green[Loading document from URL...] ''')\n",
+ " loader = document_loaders.WebBaseLoader(url)\n",
+ " return loader.load()\n",
+ "\n",
+ "\n",
+ "## Split the document into multiple chunks\n",
+ "def split_document(text, chunk_size=3000, overlap=200):\n",
+ " print(\"Splitting document into chunks...\")\n",
+ " st.markdown(''' :green[Splitting document into chunks...] ''')\n",
+ " text_splitter_instance = text_splitter.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)\n",
+ " return text_splitter_instance.split_documents(text)\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "## Initialize embeddings for these chunks of data. we can use one of the below four embedding types\n",
+ "\n",
+ "def initialize_embedding_fn(embedding_type=\"huggingface\", model_name=\"sentence-transformers/all-MiniLM-l6-v2\"):\n",
+ " print(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " st.write(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " if embedding_type == \"ollama\":\n",
+ " model_name = chat_model\n",
+ " return embeddings.OllamaEmbeddings(model=model_name, base_url=OLLAMA_BASE_URL)\n",
+ " elif embedding_type == \"huggingface\":\n",
+ " model_name = \"sentence-transformers/paraphrase-MiniLM-L3-v2\"\n",
+ " return embeddings.HuggingFaceEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"nomic\":\n",
+ " return embeddings.NomicEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"fastembed\":\n",
+ " return FastEmbedEmbeddings(threads=16)\n",
+ " else:\n",
+ " raise ValueError(f\"Unsupported embedding type: {embedding_type}\")\n",
+ " \n",
+ "## Create embeddings for these chunks of data and store it in chromaDB\n",
+ "\n",
+ "def get_or_create_embeddings(document_url, embedding_fn, persist_dir=VECTOR_DB_DIR):\n",
+ " vector_store_path = os.path.join(os.getcwd(), persist_dir) \n",
+ " start_time = time.time()\n",
+ " print(\"No existing vector store found. Creating new one...\")\n",
+ " st.markdown(''' :green[No existing vector store found. Creating new one......] ''')\n",
+ " document = load_document(document_url)\n",
+ " documents = split_document(document)\n",
+ " vector_store = vectorstores.Chroma.from_documents(\n",
+ " documents=documents,\n",
+ " embedding=embedding_fn,\n",
+ " persist_directory=persist_dir\n",
+ " )\n",
+ " vector_store.persist()\n",
+ " print(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " st.write(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " return vector_store\n",
+ "# Create the user prompt and generate the response\n",
+ "def handle_user_interaction(vector_store, chat_model):\n",
+ " prompt_template = \"\"\"\n",
+ " Use the following pieces of context to answer the question at the end. \n",
+ " If you do not know the answer, answer 'I don't know', limit your response to the answer and nothing more. \n",
+ "\n",
+ " {context}\n",
+ "\n",
+ " Question: {question}\n",
+ " \"\"\"\n",
+ " prompt = PromptTemplate(template=prompt_template, input_variables=[\"context\", \"question\"])\n",
+ " chain_type_kwargs = {\"prompt\": prompt}\n",
+ " # Use retrievers to retrieve the data from the database\n",
+ " st.markdown(''' :green[Using retrievers to retrieve the data from the database...] ''')\n",
+ " retriever = vector_store.as_retriever(search_kwargs={\"k\": 4})\n",
+ " st.markdown(''' :green[Answering the query...] ''')\n",
+ " qachain = chains.RetrievalQA.from_chain_type(llm=chat_model, retriever=retriever, chain_type=\"stuff\", chain_type_kwargs=chain_type_kwargs)\n",
+ " qachain.invoke({\"query\": \"what is this about?\"})\n",
+ " print(f\"Model warmup complete...\")\n",
+ " st.markdown(''' :green[Model warmup complete...] ''')\n",
+ " \n",
+ " \n",
+ " \n",
+ " start_time = time.time()\n",
+ " answer = qachain.invoke({\"query\": question})\n",
+ " print(f\"Answer: {answer['result']}\") \n",
+ " print(f\"Response time: {time.time() - start_time:.2f} seconds\")\n",
+ " st.write(f\"Response time: {time.time() - start_time:.2f} seconds\")\n",
+ " \n",
+ " \n",
+ " return answer['result']\n",
+ " \n",
+ " \n",
+ "\n",
+ "# Main Function to load the document, initialize the embeddings , create the vector database and invoke the model\n",
+ "def getfinalresponse(document_url, embedding_type, chat_model): \n",
+ " \n",
+ " document_url = url_path \n",
+ " chat_model = model\n",
+ " \n",
+ " embedding_fn = initialize_embedding_fn(embedding_type)\n",
+ " vector_store = get_or_create_embeddings(document_url, embedding_fn) \n",
+ " chat_model_instance = llms.Ollama(base_url=OLLAMA_BASE_URL, model=chat_model)\n",
+ " return handle_user_interaction(vector_store, chat_model_instance)\n",
+ "\n",
+ " \n",
+ "submit=st.button(\"Generate\")\n",
+ "\n",
+ "\n",
+ "# generate response\n",
+ "if submit: \n",
+ " document_url = url_path \n",
+ " chat_model = model\n",
+ " \n",
+ " with st.spinner(\"Loading document....🐎\"): \n",
+ " st.write(getfinalresponse(document_url, embedding_type, chat_model))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7336754e-43ed-4818-b31c-040847c916d2",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6f4b5a84-bebf-49b9-b2fa-5e788ed2cbac",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_rag_chromadb.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4a1e0683-569f-45a1-938d-017f03eb8cd9",
+ "metadata": {},
+ "source": [
+ "### Streamlit sample output\n",
+ "\n",
+ "Below is the output of a sample run from the streamlit application and offloaded to iGPU\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c3a79f8-6b8e-4db8-8ac7-534b3518201e",
+ "metadata": {},
+ "source": [
+ "* Reference: https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "326a0eec-e519-4325-93ec-be1cdb261dfd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/chat.py"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df414428-f466-412b-a1a1-8706ffd7adf1",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/4_llm-rag.ipynb b/4_llm-rag.ipynb
new file mode 100644
index 0000000..327e68f
--- /dev/null
+++ b/4_llm-rag.ipynb
@@ -0,0 +1,543 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "02a561f4",
+ "metadata": {},
+ "source": [
+ "# Create a RAG system on AIPC\n",
+ "\n",
+ "**Retrieval-augmented generation (RAG)** is a technique for augmenting LLM knowledge with additional, often private or real-time, data. LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG)."
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "4fb8b0e4",
+ "metadata": {},
+ "source": [
+ "## Run QA over Document\n",
+ "\n",
+ "Now, when model created, we can setup Chatbot interface using Streamlit\n",
+ "\n",
+ "A typical RAG application has two main components:\n",
+ "\n",
+ "- **Indexing**: a pipeline for ingesting data from a source and indexing it. This usually happen offline.\n",
+ "\n",
+ "- **Retrieval and generation**: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.\n",
+ "\n",
+ "The most common full sequence from raw data to answer looks like:\n",
+ "\n",
+ "**Indexing**\n",
+ "\n",
+ "1. `Load`: First we need to load our data. We’ll use DocumentLoaders for this.\n",
+ "2. `Split`: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t in a model’s finite context window.\n",
+ "3. `Store`: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.\n",
+ "\n",
+ "\n",
+ "\n",
+ "**Retrieval and generation**\n",
+ "\n",
+ "1. `Retrieve`: Given a user input, relevant splits are retrieved from storage using a Retriever.\n",
+ "2. `Generate`: A LLM produces an answer using a prompt that includes the question and the retrieved data.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "602f8ebd-789c-4eb2-b54d-b23d8f1d8e7b",
+ "metadata": {},
+ "source": [
+ "We can build a RAG pipeline of LangChain through [`create_retrieval_chain`](https://python.langchain.com/docs/modules/chains/), which will help to create a chain to connect RAG components including:\n",
+ "\n",
+ "- [`Vector stores`](https://python.langchain.com/docs/modules/data_connection/vectorstores/),\n",
+ "- [`Retrievers`](https://python.langchain.com/docs/modules/data_connection/retrievers/)\n",
+ "- [`LLM`](https://python.langchain.com/docs/integrations/llms/)\n",
+ "- [`Embedding`](https://python.langchain.com/docs/integrations/text_embedding/)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "34cc6ae1-3321-4a10-83a8-fb4169516391",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "import warnings\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "\n",
+ "from langchain_community import document_loaders, embeddings, vectorstores, llms\n",
+ "from langchain_community.embeddings.fastembed import FastEmbedEmbeddings\n",
+ "from langchain import chains, text_splitter, PromptTemplate\n",
+ "\n",
+ "OLLAMA_BASE_URL = \"http://localhost:11434\"\n",
+ "VECTOR_DB_DIR = \"vector_dbs\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c179e7c1-8152-4d5c-b2a2-b5aaff8773bd",
+ "metadata": {},
+ "source": [
+ "### Document Loaders in RAG\n",
+ "\n",
+ "* Document loaders in RAG are used to load and preprocess the documents that will be used for retrieval during the question answering process.\n",
+ "* Document loaders are responsible for preprocessing the documents. This includes tokenizing the text, converting it to the format expected by the retriever, and creating batches of documents.\n",
+ "* Document loaders work in conjunction with the retriever in RAG. The retriever uses the documents loaded by the document loader to find the most relevant documents for a given query.\n",
+ "* The WebBaseLoader in Retrieval Augmented Generation (RAG) is a type of document loader that is designed to load documents from the web.\n",
+ "* The WebBaseLoader is used when the documents for retrieval are not stored locally or in a Hugging Face dataset, but are instead located on the web. This can be useful when you want to use the most up-to-date information available on the internet for your question answering system\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd29cec6-0ec9-4074-9068-b12fb4be5ca9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def load_document(url):\n",
+ " print(\"Loading document from URL...\")\n",
+ " loader = document_loaders.WebBaseLoader(url)\n",
+ " return loader.load()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a21a5840-ac75-448d-b3d8-f86a40fe8a73",
+ "metadata": {},
+ "source": [
+ "### Text splitter\n",
+ "\n",
+ "* RecursiveCharacterTextSplitter is used to split text into smaller pieces recursively at the character level. \n",
+ "* split_documents fuctions splits larger documents into smaller chunks, for easier processing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6488b84c-830c-41e9-96a4-5fcf728ad6d6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def split_document(text, chunk_size=3000, overlap=200):\n",
+ " print(\"Splitting document into chunks...\")\n",
+ " text_splitter_instance = text_splitter.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)\n",
+ " return text_splitter_instance.split_documents(text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc257b5f-1e36-4273-9b41-4c45c2b21106",
+ "metadata": {},
+ "source": [
+ "### Huggingface emdeggings\n",
+ "In Retrieval Augmented Generation (RAG) embeddings play a crucial role in the retrieval of relevant documents for a given query.\n",
+ "\n",
+ "* In RAG, each document in the knowledge base is represented as a dense vector, also known as an embedding. These embeddings are typically generated by a transformer model.\n",
+ "* When a query is received, it is also converted into an embedding using the same transformer model. This ensures that the query and the documents are in the same vector space, making it possible to compare them.\n",
+ "* Retrieval: The retrieval step in RAG involves finding the documents whose embeddings are most similar to the query embedding. This is typically done using a nearest neighbor search.\n",
+ "\n",
+ "#### Sentence transformers\n",
+ "\n",
+ "* You can use a Sentence Transformer to generate embeddings for each document in your knowledge base. Since Sentence Transformers are designed to capture the semantic meaning of sentences, these embeddings should do a good job of representing the content of the documents.\n",
+ "* You can also use a Sentence Transformer to generate an embedding for the query. This ensures that the query and the documents are in the same vector space, making it possible to compare them.\n",
+ "* By using Sentence Transformers, you can potentially improve the quality of the retrieval step in RAG. Since Sentence Transformers are designed to capture the semantic meaning of sentences, they should be able to find documents that are semantically relevant to the query, even if the query and the documents do not share any exact words.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b55af744-4ffd-4dfd-b85a-aa5ff401b6a2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def initialize_embedding_fn(embedding_type=\"huggingface\", model_name=\"sentence-transformers/all-MiniLM-l6-v2\"):\n",
+ " print(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " if embedding_type == \"ollama\":\n",
+ " model_name = chat_model\n",
+ " return embeddings.OllamaEmbeddings(model=model_name, base_url=OLLAMA_BASE_URL)\n",
+ " elif embedding_type == \"huggingface\":\n",
+ " model_name = \"sentence-transformers/paraphrase-MiniLM-L3-v2\"\n",
+ " return embeddings.HuggingFaceEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"nomic\":\n",
+ " return embeddings.NomicEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"fastembed\":\n",
+ " return FastEmbedEmbeddings(threads=16)\n",
+ " else:\n",
+ " raise ValueError(f\"Unsupported embedding type: {embedding_type}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "177d4ccf-fd68-4380-9a98-01de673e83c9",
+ "metadata": {},
+ "source": [
+ "### Create and get embeddings using ChromaDB\n",
+ "\n",
+ "Here's a flow chart that describes how embeddings work in a RAG model with ChromaDB:\n",
+ "\n",
+ "* Query Input: The user inputs a query.\n",
+ "* Query Embedding: The query is passed through a transformer-based encoder (like BERT or RoBERTa) to generate a query embedding.\n",
+ "* Document Embedding: Each document in the ChromaDB is also passed through a transformer-based encoder to generate a document embedding. This is typically done offline and the embeddings are stored in the database for efficient retrieval.\n",
+ "* Embedding Comparison: The query embedding is compared with each document embedding in the ChromaDB. This is done by calculating the cosine similarity or dot product between the query embedding and each document embedding.\n",
+ "* Document Retrieval: The documents with the highest similarity scores are retrieved. The number of documents retrieved is a hyperparameter that can be tuned.\n",
+ "* Answer Generation: The retrieved documents and the query are passed to a sequence-to-sequence model (like BART or T5) to generate an answer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2b872757-5f72-45e3-ab86-de4edae8af7f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_or_create_embeddings(document_url, embedding_fn, persist_dir=VECTOR_DB_DIR):\n",
+ " vector_store_path = os.path.join(os.getcwd(), persist_dir) \n",
+ " if os.path.exists(vector_store_path):\n",
+ " print(\"Loading existing vector store...\")\n",
+ " return vectorstores.Chroma(persist_directory=persist_dir, embedding_function=embedding_fn)\n",
+ " else:\n",
+ " start_time = time.time()\n",
+ " print(\"No existing vector store found. Creating new one...\")\n",
+ " document = load_document(document_url)\n",
+ " documents = split_document(document)\n",
+ " vector_store = vectorstores.Chroma.from_documents(\n",
+ " documents=documents,\n",
+ " embedding=embedding_fn,\n",
+ " persist_directory=persist_dir\n",
+ " )\n",
+ " vector_store.persist()\n",
+ " print(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " return vector_store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c806373-8179-4b95-adfb-8eebbb613baf",
+ "metadata": {},
+ "source": [
+ "### Retrievers\n",
+ "\n",
+ "* Retrievers are responsible for fetching relevant documents from a document store or knowledge base given a query. The retrieved documents are then used by the generator to produce a response.\n",
+ "* RetrievalQA is a type of question answering system that uses a retriever to fetch relevant documents given a question, and then uses a reader to extract the answer from the retrieved documents.\n",
+ "* RetrievalQA can be seen as a two-step process:\n",
+ " * Retrieval: The retriever fetches relevant documents from the document store given a query. \n",
+ " * Generation: The generator uses the retrieved documents to generate a response.\n",
+ "* This two-step process allows RAG to leverage the strengths of both retrieval-based and generation-based approaches to question answering. The retriever allows RAG to efficiently search a large document store, while the generator allows RAG to generate detailed and coherent responses.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2b92cbb3-a9be-4d9a-810f-92b8e43105df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def handle_user_interaction(vector_store, chat_model):\n",
+ " prompt_template = \"\"\"\n",
+ " Use the following pieces of context to answer the question at the end. \n",
+ " If you do not know the answer, answer 'I don't know', limit your response to the answer and nothing more. \n",
+ "\n",
+ " {context}\n",
+ "\n",
+ " Question: {question}\n",
+ " \"\"\"\n",
+ " prompt = PromptTemplate(template=prompt_template, input_variables=[\"context\", \"question\"])\n",
+ " chain_type_kwargs = {\"prompt\": prompt}\n",
+ " retriever = vector_store.as_retriever(search_kwargs={\"k\": 4})\n",
+ " qachain = chains.RetrievalQA.from_chain_type(llm=chat_model, retriever=retriever, chain_type=\"stuff\", chain_type_kwargs=chain_type_kwargs)\n",
+ " qachain.invoke({\"query\": \"what is this about?\"})\n",
+ " print(f\"Model warmup complete...\")\n",
+ " while True:\n",
+ " question = input(\"Enter your question (or 'quit' to exit): \")\n",
+ " if question.lower() == 'quit':\n",
+ " break\n",
+ " start_time = time.time()\n",
+ " answer = qachain.invoke({\"query\": question})\n",
+ " print(f\"Answer: {answer['result']}\")\n",
+ " print(f\"Response time: {time.time() - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8bc1652-788e-4f1b-9684-313a82cb25f3",
+ "metadata": {},
+ "source": [
+ "### Run the application"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "114cd97b-9aec-4d59-a97e-c2bab0767336",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "def main(document_url, embedding_type, chat_model):\n",
+ " embedding_fn = initialize_embedding_fn(embedding_type)\n",
+ " vector_store = get_or_create_embeddings(document_url, embedding_fn)\n",
+ " chat_model_instance = llms.Ollama(base_url=OLLAMA_BASE_URL, model=chat_model)\n",
+ " handle_user_interaction(vector_store, chat_model_instance)\n",
+ "\n",
+ "if __name__ == \"__main__\":\n",
+ " document_url = \"https://www.gutenberg.org/files/1727/1727-h/1727-h.htm\" \n",
+ " embedding_type = \"huggingface\"\n",
+ " chat_model = \"llama3:latest\"\n",
+ " main(document_url, embedding_type, chat_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6b0da830-f207-4035-8d63-bb6f4884b4a6",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c33911e-84ab-4346-92a4-3ead03f9d257",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_rag_chromadb.py\n",
+ "import streamlit as st\n",
+ "import time\n",
+ "import os\n",
+ "import warnings\n",
+ "import ollama\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "\n",
+ "from langchain_community import document_loaders, embeddings, vectorstores, llms\n",
+ "from langchain_community.embeddings.fastembed import FastEmbedEmbeddings\n",
+ "from langchain import chains, text_splitter, PromptTemplate\n",
+ "\n",
+ "OLLAMA_BASE_URL = \"http://localhost:11434\"\n",
+ "VECTOR_DB_DIR = \"vector_dbs\"\n",
+ "\n",
+ "st.header(\"LLM Rag 🐻❄️\")\n",
+ "\n",
+ "\n",
+ "models = [model[\"name\"] for model in ollama.list()[\"models\"]]\n",
+ "model = st.selectbox(\"Choose a model from the list\", models)\n",
+ "\n",
+ "# Input text to load the document\n",
+ "url_path = st.text_input(\"Enter the URL to load for RAG:\",value=\"https://www.gutenberg.org/files/1727/1727-h/1727-h.htm\", key=\"url_path\")\n",
+ "\n",
+ "# Select embedding type\n",
+ "embedding_type = st.selectbox(\"Please select an embedding type\", (\"ollama\", \"huggingface\", \"nomic\", \"fastembed\"),index=1)\n",
+ "\n",
+ "# Input for RAG\n",
+ "question = st.text_input(\"Enter the question for RAG:\", value=\"What is this about\", key=\"question\")\n",
+ "\n",
+ "## Load the document using document_loaders\n",
+ "def load_document(url):\n",
+ " print(\"Loading document from URL...\")\n",
+ " st.markdown(''' :green[Loading document from URL...] ''')\n",
+ " loader = document_loaders.WebBaseLoader(url)\n",
+ " return loader.load()\n",
+ "\n",
+ "\n",
+ "## Split the document into multiple chunks\n",
+ "def split_document(text, chunk_size=3000, overlap=200):\n",
+ " print(\"Splitting document into chunks...\")\n",
+ " st.markdown(''' :green[Splitting document into chunks...] ''')\n",
+ " text_splitter_instance = text_splitter.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)\n",
+ " return text_splitter_instance.split_documents(text)\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "## Initialize embeddings for these chunks of data. we can use one of the below four embedding types\n",
+ "\n",
+ "def initialize_embedding_fn(embedding_type=\"huggingface\", model_name=\"sentence-transformers/all-MiniLM-l6-v2\"):\n",
+ " print(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " st.write(f\"Initializing {embedding_type} model with {model_name}...\")\n",
+ " if embedding_type == \"ollama\":\n",
+ " model_name = chat_model\n",
+ " return embeddings.OllamaEmbeddings(model=model_name, base_url=OLLAMA_BASE_URL)\n",
+ " elif embedding_type == \"huggingface\":\n",
+ " model_name = \"sentence-transformers/paraphrase-MiniLM-L3-v2\"\n",
+ " return embeddings.HuggingFaceEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"nomic\":\n",
+ " return embeddings.NomicEmbeddings(model_name=model_name)\n",
+ " elif embedding_type == \"fastembed\":\n",
+ " return FastEmbedEmbeddings(threads=16)\n",
+ " else:\n",
+ " raise ValueError(f\"Unsupported embedding type: {embedding_type}\")\n",
+ " \n",
+ "## Create embeddings for these chunks of data and store it in chromaDB\n",
+ "\n",
+ "def get_or_create_embeddings(document_url, embedding_fn, persist_dir=VECTOR_DB_DIR):\n",
+ " vector_store_path = os.path.join(os.getcwd(), persist_dir) \n",
+ " start_time = time.time()\n",
+ " print(\"No existing vector store found. Creating new one...\")\n",
+ " st.markdown(''' :green[No existing vector store found. Creating new one......] ''')\n",
+ " document = load_document(document_url)\n",
+ " documents = split_document(document)\n",
+ " vector_store = vectorstores.Chroma.from_documents(\n",
+ " documents=documents,\n",
+ " embedding=embedding_fn,\n",
+ " persist_directory=persist_dir\n",
+ " )\n",
+ " vector_store.persist()\n",
+ " print(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " st.write(f\"Embedding time: {time.time() - start_time:.2f} seconds\")\n",
+ " return vector_store\n",
+ "# Create the user prompt and generate the response\n",
+ "def handle_user_interaction(vector_store, chat_model):\n",
+ " prompt_template = \"\"\"\n",
+ " Use the following pieces of context to answer the question at the end. \n",
+ " If you do not know the answer, answer 'I don't know', limit your response to the answer and nothing more. \n",
+ "\n",
+ " {context}\n",
+ "\n",
+ " Question: {question}\n",
+ " \"\"\"\n",
+ " prompt = PromptTemplate(template=prompt_template, input_variables=[\"context\", \"question\"])\n",
+ " chain_type_kwargs = {\"prompt\": prompt}\n",
+ " # Use retrievers to retrieve the data from the database\n",
+ " st.markdown(''' :green[Using retrievers to retrieve the data from the database...] ''')\n",
+ " retriever = vector_store.as_retriever(search_kwargs={\"k\": 4})\n",
+ " st.markdown(''' :green[Answering the query...] ''')\n",
+ " qachain = chains.RetrievalQA.from_chain_type(llm=chat_model, retriever=retriever, chain_type=\"stuff\", chain_type_kwargs=chain_type_kwargs)\n",
+ " qachain.invoke({\"query\": \"what is this about?\"})\n",
+ " print(f\"Model warmup complete...\")\n",
+ " st.markdown(''' :green[Model warmup complete...] ''')\n",
+ " \n",
+ " \n",
+ " \n",
+ " start_time = time.time()\n",
+ " answer = qachain.invoke({\"query\": question})\n",
+ " print(f\"Answer: {answer['result']}\") \n",
+ " print(f\"Response time: {time.time() - start_time:.2f} seconds\")\n",
+ " st.write(f\"Response time: {time.time() - start_time:.2f} seconds\")\n",
+ " \n",
+ " \n",
+ " return answer['result']\n",
+ " \n",
+ " \n",
+ "\n",
+ "# Main Function to load the document, initialize the embeddings , create the vector database and invoke the model\n",
+ "def getfinalresponse(document_url, embedding_type, chat_model): \n",
+ " \n",
+ " document_url = url_path \n",
+ " chat_model = model\n",
+ " \n",
+ " embedding_fn = initialize_embedding_fn(embedding_type)\n",
+ " vector_store = get_or_create_embeddings(document_url, embedding_fn) \n",
+ " chat_model_instance = llms.Ollama(base_url=OLLAMA_BASE_URL, model=chat_model)\n",
+ " return handle_user_interaction(vector_store, chat_model_instance)\n",
+ "\n",
+ " \n",
+ "submit=st.button(\"Generate\")\n",
+ "\n",
+ "\n",
+ "# generate response\n",
+ "if submit: \n",
+ " document_url = url_path \n",
+ " chat_model = model\n",
+ " \n",
+ " with st.spinner(\"Loading document....🐎\"): \n",
+ " st.write(getfinalresponse(document_url, embedding_type, chat_model))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7336754e-43ed-4818-b31c-040847c916d2",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6f4b5a84-bebf-49b9-b2fa-5e788ed2cbac",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_rag_chromadb.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4a1e0683-569f-45a1-938d-017f03eb8cd9",
+ "metadata": {},
+ "source": [
+ "### Streamlit sample output\n",
+ "\n",
+ "Below is the output of a sample run from the streamlit application and offloaded to iGPU\n",
+ "\n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "61940d35-bd5b-4199-98a7-2f7d845e7e50",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-agent-langchain"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ },
+ "openvino_notebooks": {
+ "imageUrl": "https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/304aa048-f10c-41c6-bb31-6d2bfdf49cf5",
+ "tags": {
+ "categories": [
+ "Model Demos",
+ "AI Trends"
+ ],
+ "libraries": [],
+ "other": [
+ "LLM"
+ ],
+ "tasks": [
+ "Text Generation"
+ ]
+ }
+ },
+ "widgets": {
+ "application/vnd.jupyter.widget-state+json": {
+ "state": {},
+ "version_major": 2,
+ "version_minor": 0
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/5_llm_quantization_sycl.ipynb b/5_llm_quantization_sycl.ipynb
new file mode 100644
index 0000000..2d7d7a4
--- /dev/null
+++ b/5_llm_quantization_sycl.ipynb
@@ -0,0 +1,599 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Quantization using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to quantize a model on Windows AI PC with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "61940d35-bd5b-4199-98a7-2f7d845e7e50",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-agent-langchain"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.5"
+ },
+ "openvino_notebooks": {
+ "imageUrl": "https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/304aa048-f10c-41c6-bb31-6d2bfdf49cf5",
+ "tags": {
+ "categories": [
+ "Model Demos",
+ "AI Trends"
+ ],
+ "libraries": [],
+ "other": [
+ "LLM"
+ ],
+ "tasks": [
+ "Text Generation"
+ ]
+ }
+ },
+ "widgets": {
+ "application/vnd.jupyter.widget-state+json": {
+ "state": {},
+ "version_major": 2,
+ "version_minor": 0
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/5_llm_quantization_sycl.ipynb b/5_llm_quantization_sycl.ipynb
new file mode 100644
index 0000000..2d7d7a4
--- /dev/null
+++ b/5_llm_quantization_sycl.ipynb
@@ -0,0 +1,599 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Quantization using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to quantize a model on Windows AI PC with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ " \n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp\n",
+ "\n",
+ "* git clone the llama.cpp repo\n",
+ " \n",
+ " ```\n",
+ " git clone https://github.com/ggerganov/llama.cpp.git\n",
+ "\n",
+ " ```\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " # Option 1: Use FP32 (recommended for better performance in most cases)\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release\n",
+ " \n",
+ " # Option 2: Or FP16\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release -DGGML_SYCL_F16=ON\n",
+ " \n",
+ " cmake --build build --config Release -j\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model for example as below\n",
+ "* Open the mini-forge prompt, activate the llm-sycl environment and enable oneAPI enviroment as below\n",
+ "\n",
+ " ```\n",
+ " \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 \n",
+ " ```\n",
+ "* List the sycl devices as below\n",
+ "\n",
+ " ```\n",
+ " build\\bin\\ls-sycl-device.exe\n",
+ "\n",
+ " ```\n",
+ "* Run inference\n",
+ "```\n",
+ "build\\bin\\llama-cli.exe -m models\\llama-2-7b.Q4_0.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp\n",
+ "\n",
+ "* git clone the llama.cpp repo\n",
+ " \n",
+ " ```\n",
+ " git clone https://github.com/ggerganov/llama.cpp.git\n",
+ "\n",
+ " ```\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " # Option 1: Use FP32 (recommended for better performance in most cases)\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release\n",
+ " \n",
+ " # Option 2: Or FP16\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release -DGGML_SYCL_F16=ON\n",
+ " \n",
+ " cmake --build build --config Release -j\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model for example as below\n",
+ "* Open the mini-forge prompt, activate the llm-sycl environment and enable oneAPI enviroment as below\n",
+ "\n",
+ " ```\n",
+ " \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 \n",
+ " ```\n",
+ "* List the sycl devices as below\n",
+ "\n",
+ " ```\n",
+ " build\\bin\\ls-sycl-device.exe\n",
+ "\n",
+ " ```\n",
+ "* Run inference\n",
+ "```\n",
+ "build\\bin\\llama-cli.exe -m models\\llama-2-7b.Q4_0.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3ad64c2-2432-4cb0-8a3d-856daad1dc18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m Qwen1.5-4B.Q4_K_M.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 25 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b36ad00-2c2f-4005-9a20-e42c0c533aa1",
+ "metadata": {},
+ "source": [
+ "## Quantization of the Models on AI PC\n",
+ "\n",
+ "* Quantization: Reduces the precision of the model's parameters (e.g., from 32-bit floating-point to 8-bit or 4-bit integers), decreasing the model size and often speeding up inference with minimal impact on accuracy.\n",
+ "\n",
+ "* When quantizing to 4 bits, each value is represented with only 4 bits, significantly reducing the amount of data needed to store and process information. This reduction in data size leads to several advantages, including decreased memory usage and faster processing speeds, which are particularly beneficial for deploying models on AI PCs.\n",
+ "\n",
+ "* Additionally, 4-bit quantization can lead to lower power consumption, making it an attractive option for AI PCs with GPUs and NPus\n",
+ "\n",
+ "* **llama-3-8b-instruct** - Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. More details about model can be found in [Meta blog post](https://ai.meta.com/blog/meta-llama-3/), [model website](https://llama.meta.com/llama3) and [model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct).\n",
+ ">**Note**: run model with demo, you will need to accept license agreement. \n",
+ ">You must be a registered user in 🤗 Hugging Face Hub. Please visit [HuggingFace model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).\n",
+ ">You can login on Hugging Face Hub in notebook environment, using following code:\n",
+ "\n",
+ "* **llama-2-7b-chat** - LLama 2 is the second generation of LLama models developed by Meta. Llama 2 is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. llama-2-7b-chat is 7 billions parameters version of LLama 2 finetuned and optimized for dialogue use case. More details about model can be found in the [paper](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/), [repository](https://github.com/facebookresearch/llama) and [HuggingFace model card](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf).\n",
+ ">**Note**: run model with demo, you will need to accept license agreement. \n",
+ ">You must be a registered user in 🤗 Hugging Face Hub. Please visit [HuggingFace model card](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).\n",
+ ">You can login on Hugging Face Hub in notebook environment, using following code:\n",
+ " \n",
+ "```python\n",
+ " ## login to huggingfacehub to get access to pretrained model \n",
+ "\n",
+ " from huggingface_hub import notebook_login, whoami\n",
+ "\n",
+ " try:\n",
+ " whoami()\n",
+ " print('Authorization token already provided')\n",
+ " except OSError:\n",
+ " notebook_login()\n",
+ "```\n",
+ "\n",
+ "* **phi3-mini-instruct** - The Phi-3-Mini is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties. More details about model can be found in [model card](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct), [Microsoft blog](https://aka.ms/phi3blog-april) and [technical report](https://aka.ms/phi3-tech-report).\n",
+ "* **qwen2-1.5b-instruct/qwen2-7b-instruct** - Qwen2 is the new series of Qwen large language models.Compared with the state-of-the-art open source language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most open source models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.\n",
+ "For more details, please refer to [model_card](https://huggingface.co/Qwen/Qwen2-7B-Instruct), [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).\n",
+ "\n",
+ "* **neural-chat-7b-v3-1** - Mistral-7b model fine-tuned using Intel Gaudi. The model fine-tuned on the open source dataset [Open-Orca/SlimOrca](https://huggingface.co/datasets/Open-Orca/SlimOrca) and aligned with [Direct Preference Optimization (DPO) algorithm](https://arxiv.org/abs/2305.18290). More details can be found in [model card](https://huggingface.co/Intel/neural-chat-7b-v3-1) and [blog post](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e2f5a77a-dc31-4202-b12e-94beabc90a9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login, whoami\n",
+ "try:\n",
+ " whoami()\n",
+ " print('Authorization token already provided')\n",
+ "except OSError:\n",
+ " notebook_login()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d48253fa-3ec0-44db-bf86-c2060e59eccc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install ipywidgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff9b63a3-4f1d-40c5-a34b-49f755021f4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ipywidgets as widgets\n",
+ "\n",
+ "model = widgets.Dropdown(\n",
+ " options=['phi3-mini-instruct', 'llama-2-7b-chat', 'qwen2-1.5b-instruct', 'llama-3-8b-instruct', 'neural-chat-7b-v3-1' ],\n",
+ " value='llama-3-8b-instruct', # Default value\n",
+ " description=\"Select Model:\",\n",
+ " disabled=False,\n",
+ ")\n",
+ "\n",
+ "model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9cee80c1-1f86-41b7-977c-e7207e123aab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = \"microsoft/Phi-3-mini-4k-instruct\"\n",
+ "model_path = \"./phi3/\"\n",
+ "\n",
+ "if model.value == \"phi3-mini-instruct\":\n",
+ " model_id = \"microsoft/Phi-3-mini-4k-instruct\"\n",
+ " model_path = \"./phi3/\"\n",
+ " model_fp16 = \"Phi-3-mini-4k-instruct.Fp16.gguf\"\n",
+ " model_gguf = \"Phi-3-mini-4k-instruct.Q4_K_M.gguf\"\n",
+ "elif model.value == \"llama-2-7b-chat\":\n",
+ " model_id = \"meta-llama/Llama-2-7b-chat-hf\"\n",
+ " model_fp16 = \"Llama-2-7b-chat-hf.Fp16.gguf\"\n",
+ " model_path = \"./llama2/\"\n",
+ " model_gguf = \"Llama-2-7b-chat-hf.Q4_K_M.gguf\"\n",
+ "elif model.value == \"llama-3-8b-instruct\":\n",
+ " model_id = \"meta-llama/Meta-Llama-3-8B-Instruct\"\n",
+ " model_fp16 = \"llama-3-8b-instruct.Fp16.gguf\"\n",
+ " model_path = \"./llama3/\"\n",
+ " model_gguf = \"llama-3-8b-instruct.Q4_K_M.gguf\"\n",
+ "elif model.value == \"qwen2-1.5b-instruct\":\n",
+ " model_id = \"Qwen/Qwen1.5-4B-Chat\"\n",
+ " model_fp16 = \"Qwen1.5-4B-Chat.Fp16.gguf\"\n",
+ " model_path = \"./Qwen/\"\n",
+ " model_gguf = \"Qwen1.5-4B-Chat.Q4_K_M.gguf\"\n",
+ "elif model.value == \"neural-chat-7b-v3-1\":\n",
+ " model_id = \"Intel/neural-chat-7b-v3-1\"\n",
+ " model_fp16 = \"neural-chat-7b-v3-1.Fp16.gguf\"\n",
+ " model_path = \"./Intel_neural_chat/\"\n",
+ " model_gguf = \"neural-chat-7b-v3-1.Q4_K_M.gguf\"\n",
+ "else:\n",
+ " model_id = \"meta-llama/Meta-Llama-3-8B-Instruct\"\n",
+ " model_fp16 = \"llama-3-8b-instruct.Fp16.gguf\"\n",
+ " model_path = \"./llama3/\"\n",
+ " model_gguf = \"llama-3-8b-instruct.Q4_K_M.gguf\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd1af28e-0c46-4f5c-bc43-ea10106d7175",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Selected model {model.value}\")\n",
+ "print(f\"Selected model \", model_id)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7fe1fbc0-39a1-45c3-9cff-82550de83345",
+ "metadata": {},
+ "source": [
+ "### Initialize oneAPI environment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28cf0670-a537-4c08-a1dc-44b6e87e90ee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f0ebe9e1-037c-4800-afcb-9e2f0b512a2d",
+ "metadata": {},
+ "source": [
+ "### Download the model from Huggingface to local folder"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9ad6f11-17c8-4fde-988d-63b94f1cccbe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import snapshot_download"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f11f272-1d1d-4288-8904-4760fe64a176",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "snapshot_download(repo_id = model_id,local_dir = model_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f0cd8b4f-3cdd-4ac6-a197-3ab101701491",
+ "metadata": {},
+ "source": [
+ "### Convert the model to GGUF format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3d8fbafc-4d27-41b4-821f-91fc5b958910",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "start_time = time.time()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4573ac8c-ad6f-4326-ad5b-b4d475e61bfd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!python ..\\git_llamacpp\\llama.cpp\\convert-hf-to-gguf.py {model_path} --outtype f16 --outfile ./converted_models/{model_fp16}\n",
+ "\n",
+ "end_time = time.time()\n",
+ "total_time = end_time - start_time\n",
+ "print(f\"Model conversion time: {total_time} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "732b4e61-4d1f-474f-858e-05279bc20367",
+ "metadata": {},
+ "source": [
+ "### Quantize the model to 4bit (Q4_K_M) format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "172d0733-b8dc-4beb-a329-e77aafb6d9de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-quantize.exe ./converted_models/{model_fp16} ./quantized_models/{model_gguf} Q4_K_M"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "18016571-9389-442f-9d30-cce4258c4c84",
+ "metadata": {},
+ "source": [
+ "### Run the Inference using the quantized model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c3ae993-66b9-44ec-b4eb-74c0eff3c417",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "start_time = time.time()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d150b2b-31f0-436e-a46c-2b118f1f2d1f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./quantized_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "\n",
+ "end_time = time.time()\n",
+ "total_time = end_time - start_time\n",
+ "print(f\"Model warmup and Inference time: {total_time} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6b3d9dbd-3f6d-406f-ade6-3c20bc7a92fb",
+ "metadata": {},
+ "source": [
+ "### Upload the model to Huggingface hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ec02187c-d515-4031-b15a-2e6eec1b4793",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import login\n",
+ "login()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8741dd0-8aff-4870-8153-039d53e255fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, HfFolder, Repository, create_repo, upload_file\n",
+ "#from huggingface_hub import HfApi, HfFolder, create_repo, upload_file\n",
+ "import os\n",
+ "\n",
+ "# Authentication\n",
+ "token = HfFolder.get_token() # Make sure you have logged in using `huggingface-cli login` or set the token manually\n",
+ "if token is None:\n",
+ " raise ValueError(\"Hugging Face token not found. Please login using `huggingface-cli login`.\")\n",
+ "\n",
+ "# Define repository details\n",
+ "model_file_path = \"./quantized_models/\" + model_gguf # Your GGUG model file name\n",
+ "model_file_name = model_gguf\n",
+ "repo_name = model.value # Repository name\n",
+ "organization = \"Your org name\" # Change this to your Hugging Face username or organization\n",
+ "repo_url = f\"{organization}/{repo_name}\"\n",
+ "\n",
+ "# Initialize HfApi to interact with Hugging Face Hub\n",
+ "api = HfApi()\n",
+ "\n",
+ "# Check if the repository exists, if not, create it\n",
+ "\n",
+ "api.create_repo(repo_id=repo_name, token=token, private=True) # Set `private=True` for a private repository\n",
+ "\n",
+ "# Clone the repository locally (if not already cloned)\n",
+ "\n",
+ "api.upload_file(\n",
+ " path_or_fileobj=model_file_path,\n",
+ " path_in_repo=model_file_name,\n",
+ " repo_id=repo_url,\n",
+ " repo_type=\"model\",\n",
+ ")\n",
+ "\n",
+ "print(f\"Model file {model_file_name} successfully uploaded to Hugging Face at {repo_url}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a4d70ebd-10d3-488a-baff-5ac2d39b41ae",
+ "metadata": {},
+ "source": [
+ "### Download model from huggingface_hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c107346-dcfc-461e-945e-115e723a90d2",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import snapshot_download\n",
+ "snapshot_download(repo_id=repo_url, local_dir=\"./download_models/\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd47d1d9-414b-4cd2-b20e-4c36871f1145",
+ "metadata": {},
+ "source": [
+ "#### Run the inference locally on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./download_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3ad64c2-2432-4cb0-8a3d-856daad1dc18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m Qwen1.5-4B.Q4_K_M.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 25 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b36ad00-2c2f-4005-9a20-e42c0c533aa1",
+ "metadata": {},
+ "source": [
+ "## Quantization of the Models on AI PC\n",
+ "\n",
+ "* Quantization: Reduces the precision of the model's parameters (e.g., from 32-bit floating-point to 8-bit or 4-bit integers), decreasing the model size and often speeding up inference with minimal impact on accuracy.\n",
+ "\n",
+ "* When quantizing to 4 bits, each value is represented with only 4 bits, significantly reducing the amount of data needed to store and process information. This reduction in data size leads to several advantages, including decreased memory usage and faster processing speeds, which are particularly beneficial for deploying models on AI PCs.\n",
+ "\n",
+ "* Additionally, 4-bit quantization can lead to lower power consumption, making it an attractive option for AI PCs with GPUs and NPus\n",
+ "\n",
+ "* **llama-3-8b-instruct** - Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. More details about model can be found in [Meta blog post](https://ai.meta.com/blog/meta-llama-3/), [model website](https://llama.meta.com/llama3) and [model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct).\n",
+ ">**Note**: run model with demo, you will need to accept license agreement. \n",
+ ">You must be a registered user in 🤗 Hugging Face Hub. Please visit [HuggingFace model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).\n",
+ ">You can login on Hugging Face Hub in notebook environment, using following code:\n",
+ "\n",
+ "* **llama-2-7b-chat** - LLama 2 is the second generation of LLama models developed by Meta. Llama 2 is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. llama-2-7b-chat is 7 billions parameters version of LLama 2 finetuned and optimized for dialogue use case. More details about model can be found in the [paper](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/), [repository](https://github.com/facebookresearch/llama) and [HuggingFace model card](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf).\n",
+ ">**Note**: run model with demo, you will need to accept license agreement. \n",
+ ">You must be a registered user in 🤗 Hugging Face Hub. Please visit [HuggingFace model card](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).\n",
+ ">You can login on Hugging Face Hub in notebook environment, using following code:\n",
+ " \n",
+ "```python\n",
+ " ## login to huggingfacehub to get access to pretrained model \n",
+ "\n",
+ " from huggingface_hub import notebook_login, whoami\n",
+ "\n",
+ " try:\n",
+ " whoami()\n",
+ " print('Authorization token already provided')\n",
+ " except OSError:\n",
+ " notebook_login()\n",
+ "```\n",
+ "\n",
+ "* **phi3-mini-instruct** - The Phi-3-Mini is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties. More details about model can be found in [model card](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct), [Microsoft blog](https://aka.ms/phi3blog-april) and [technical report](https://aka.ms/phi3-tech-report).\n",
+ "* **qwen2-1.5b-instruct/qwen2-7b-instruct** - Qwen2 is the new series of Qwen large language models.Compared with the state-of-the-art open source language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most open source models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.\n",
+ "For more details, please refer to [model_card](https://huggingface.co/Qwen/Qwen2-7B-Instruct), [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).\n",
+ "\n",
+ "* **neural-chat-7b-v3-1** - Mistral-7b model fine-tuned using Intel Gaudi. The model fine-tuned on the open source dataset [Open-Orca/SlimOrca](https://huggingface.co/datasets/Open-Orca/SlimOrca) and aligned with [Direct Preference Optimization (DPO) algorithm](https://arxiv.org/abs/2305.18290). More details can be found in [model card](https://huggingface.co/Intel/neural-chat-7b-v3-1) and [blog post](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e2f5a77a-dc31-4202-b12e-94beabc90a9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import notebook_login, whoami\n",
+ "try:\n",
+ " whoami()\n",
+ " print('Authorization token already provided')\n",
+ "except OSError:\n",
+ " notebook_login()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d48253fa-3ec0-44db-bf86-c2060e59eccc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install ipywidgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff9b63a3-4f1d-40c5-a34b-49f755021f4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ipywidgets as widgets\n",
+ "\n",
+ "model = widgets.Dropdown(\n",
+ " options=['phi3-mini-instruct', 'llama-2-7b-chat', 'qwen2-1.5b-instruct', 'llama-3-8b-instruct', 'neural-chat-7b-v3-1' ],\n",
+ " value='llama-3-8b-instruct', # Default value\n",
+ " description=\"Select Model:\",\n",
+ " disabled=False,\n",
+ ")\n",
+ "\n",
+ "model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9cee80c1-1f86-41b7-977c-e7207e123aab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = \"microsoft/Phi-3-mini-4k-instruct\"\n",
+ "model_path = \"./phi3/\"\n",
+ "\n",
+ "if model.value == \"phi3-mini-instruct\":\n",
+ " model_id = \"microsoft/Phi-3-mini-4k-instruct\"\n",
+ " model_path = \"./phi3/\"\n",
+ " model_fp16 = \"Phi-3-mini-4k-instruct.Fp16.gguf\"\n",
+ " model_gguf = \"Phi-3-mini-4k-instruct.Q4_K_M.gguf\"\n",
+ "elif model.value == \"llama-2-7b-chat\":\n",
+ " model_id = \"meta-llama/Llama-2-7b-chat-hf\"\n",
+ " model_fp16 = \"Llama-2-7b-chat-hf.Fp16.gguf\"\n",
+ " model_path = \"./llama2/\"\n",
+ " model_gguf = \"Llama-2-7b-chat-hf.Q4_K_M.gguf\"\n",
+ "elif model.value == \"llama-3-8b-instruct\":\n",
+ " model_id = \"meta-llama/Meta-Llama-3-8B-Instruct\"\n",
+ " model_fp16 = \"llama-3-8b-instruct.Fp16.gguf\"\n",
+ " model_path = \"./llama3/\"\n",
+ " model_gguf = \"llama-3-8b-instruct.Q4_K_M.gguf\"\n",
+ "elif model.value == \"qwen2-1.5b-instruct\":\n",
+ " model_id = \"Qwen/Qwen1.5-4B-Chat\"\n",
+ " model_fp16 = \"Qwen1.5-4B-Chat.Fp16.gguf\"\n",
+ " model_path = \"./Qwen/\"\n",
+ " model_gguf = \"Qwen1.5-4B-Chat.Q4_K_M.gguf\"\n",
+ "elif model.value == \"neural-chat-7b-v3-1\":\n",
+ " model_id = \"Intel/neural-chat-7b-v3-1\"\n",
+ " model_fp16 = \"neural-chat-7b-v3-1.Fp16.gguf\"\n",
+ " model_path = \"./Intel_neural_chat/\"\n",
+ " model_gguf = \"neural-chat-7b-v3-1.Q4_K_M.gguf\"\n",
+ "else:\n",
+ " model_id = \"meta-llama/Meta-Llama-3-8B-Instruct\"\n",
+ " model_fp16 = \"llama-3-8b-instruct.Fp16.gguf\"\n",
+ " model_path = \"./llama3/\"\n",
+ " model_gguf = \"llama-3-8b-instruct.Q4_K_M.gguf\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd1af28e-0c46-4f5c-bc43-ea10106d7175",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Selected model {model.value}\")\n",
+ "print(f\"Selected model \", model_id)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7fe1fbc0-39a1-45c3-9cff-82550de83345",
+ "metadata": {},
+ "source": [
+ "### Initialize oneAPI environment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28cf0670-a537-4c08-a1dc-44b6e87e90ee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f0ebe9e1-037c-4800-afcb-9e2f0b512a2d",
+ "metadata": {},
+ "source": [
+ "### Download the model from Huggingface to local folder"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9ad6f11-17c8-4fde-988d-63b94f1cccbe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import snapshot_download"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f11f272-1d1d-4288-8904-4760fe64a176",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "snapshot_download(repo_id = model_id,local_dir = model_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f0cd8b4f-3cdd-4ac6-a197-3ab101701491",
+ "metadata": {},
+ "source": [
+ "### Convert the model to GGUF format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3d8fbafc-4d27-41b4-821f-91fc5b958910",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "start_time = time.time()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4573ac8c-ad6f-4326-ad5b-b4d475e61bfd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!python ..\\git_llamacpp\\llama.cpp\\convert-hf-to-gguf.py {model_path} --outtype f16 --outfile ./converted_models/{model_fp16}\n",
+ "\n",
+ "end_time = time.time()\n",
+ "total_time = end_time - start_time\n",
+ "print(f\"Model conversion time: {total_time} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "732b4e61-4d1f-474f-858e-05279bc20367",
+ "metadata": {},
+ "source": [
+ "### Quantize the model to 4bit (Q4_K_M) format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "172d0733-b8dc-4beb-a329-e77aafb6d9de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-quantize.exe ./converted_models/{model_fp16} ./quantized_models/{model_gguf} Q4_K_M"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "18016571-9389-442f-9d30-cce4258c4c84",
+ "metadata": {},
+ "source": [
+ "### Run the Inference using the quantized model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c3ae993-66b9-44ec-b4eb-74c0eff3c417",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "start_time = time.time()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d150b2b-31f0-436e-a46c-2b118f1f2d1f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./quantized_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "\n",
+ "end_time = time.time()\n",
+ "total_time = end_time - start_time\n",
+ "print(f\"Model warmup and Inference time: {total_time} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6b3d9dbd-3f6d-406f-ade6-3c20bc7a92fb",
+ "metadata": {},
+ "source": [
+ "### Upload the model to Huggingface hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ec02187c-d515-4031-b15a-2e6eec1b4793",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import login\n",
+ "login()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8741dd0-8aff-4870-8153-039d53e255fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import HfApi, HfFolder, Repository, create_repo, upload_file\n",
+ "#from huggingface_hub import HfApi, HfFolder, create_repo, upload_file\n",
+ "import os\n",
+ "\n",
+ "# Authentication\n",
+ "token = HfFolder.get_token() # Make sure you have logged in using `huggingface-cli login` or set the token manually\n",
+ "if token is None:\n",
+ " raise ValueError(\"Hugging Face token not found. Please login using `huggingface-cli login`.\")\n",
+ "\n",
+ "# Define repository details\n",
+ "model_file_path = \"./quantized_models/\" + model_gguf # Your GGUG model file name\n",
+ "model_file_name = model_gguf\n",
+ "repo_name = model.value # Repository name\n",
+ "organization = \"Your org name\" # Change this to your Hugging Face username or organization\n",
+ "repo_url = f\"{organization}/{repo_name}\"\n",
+ "\n",
+ "# Initialize HfApi to interact with Hugging Face Hub\n",
+ "api = HfApi()\n",
+ "\n",
+ "# Check if the repository exists, if not, create it\n",
+ "\n",
+ "api.create_repo(repo_id=repo_name, token=token, private=True) # Set `private=True` for a private repository\n",
+ "\n",
+ "# Clone the repository locally (if not already cloned)\n",
+ "\n",
+ "api.upload_file(\n",
+ " path_or_fileobj=model_file_path,\n",
+ " path_in_repo=model_file_name,\n",
+ " repo_id=repo_url,\n",
+ " repo_type=\"model\",\n",
+ ")\n",
+ "\n",
+ "print(f\"Model file {model_file_name} successfully uploaded to Hugging Face at {repo_url}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a4d70ebd-10d3-488a-baff-5ac2d39b41ae",
+ "metadata": {},
+ "source": [
+ "### Download model from huggingface_hub"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c107346-dcfc-461e-945e-115e723a90d2",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import snapshot_download\n",
+ "snapshot_download(repo_id=repo_url, local_dir=\"./download_models/\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd47d1d9-414b-4cd2-b20e-4c36871f1145",
+ "metadata": {},
+ "source": [
+ "#### Run the inference locally on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./download_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/6_llm_sycl_gpu.ipynb b/6_llm_sycl_gpu.ipynb
new file mode 100644
index 0000000..9f0c58c
--- /dev/null
+++ b/6_llm_sycl_gpu.ipynb
@@ -0,0 +1,248 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Inference using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {
+ "jp-MarkdownHeadingCollapsed": true
+ },
+ "source": [
+ "## Step 2: Install Llamacpp for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp\n",
+ "\n",
+ "* git clone the llama.cpp repo\n",
+ " \n",
+ " ```\n",
+ " git clone https://github.com/ggerganov/llama.cpp.git\n",
+ "\n",
+ " ```\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " # Option 1: Use FP32 (recommended for better performance in most cases)\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release\n",
+ " \n",
+ " # Option 2: Or FP16\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release -DGGML_SYCL_F16=ON\n",
+ " \n",
+ " cmake --build build --config Release -j\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model for example as below\n",
+ "* Open the mini-forge prompt, activate the llm-sycl environment and enable oneAPI enviroment as below\n",
+ "\n",
+ " ```\n",
+ " \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 \n",
+ " ```\n",
+ "* List the sycl devices as below\n",
+ "\n",
+ " ```\n",
+ " build\\bin\\ls-sycl-device.exe\n",
+ "\n",
+ " ```\n",
+ "* Run inference\n",
+ "```\n",
+ "build\\bin\\llama-cli.exe -m models\\llama-2-7b.Q4_0.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3ad64c2-2432-4cb0-8a3d-856daad1dc18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m Qwen1.5-4B.Q4_K_M.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 25 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd47d1d9-414b-4cd2-b20e-4c36871f1145",
+ "metadata": {},
+ "source": [
+ "#### Run the inference locally on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./download_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/7_llm_sycl_gpu_python.ipynb b/7_llm_sycl_gpu_python.ipynb
new file mode 100644
index 0000000..c4f000a
--- /dev/null
+++ b/7_llm_sycl_gpu_python.ipynb
@@ -0,0 +1,339 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Inference using SYCL backend on AI PC using Llamacpp Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp python for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp Python\n",
+ "\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " Open a new terminal and perform the following steps:\n",
+ "\n",
+ "\n",
+ "# Set the environment variables\n",
+ " set CMAKE_GENERATOR=Ninja\n",
+ " set CMAKE_C_COMPILER=cl\n",
+ " set CMAKE_CXX_COMPILER=icx\n",
+ " set CXX=icx\n",
+ " set CC=cl\n",
+ " set CMAKE_ARGS=\"-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl\"\n",
+ " \n",
+ " pip install llama-cpp-python -U --force --no-cache-dir –-verbose\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model as below"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32f188eb-4cbf-49cd-8e88-0f3c6da19894",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\\\Program Files (x86)\\\\Intel\\\\oneAPI\\\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f0f21fb7-cb4a-421e-97f1-d763d989cebd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "prompt = \"Write a story about Pandas\"\n",
+ "prompt_template=f'''SYSTEM: You are a helpful, respectful and honest assistant. Always answer as helpfully.\n",
+ "\n",
+ "USER: {prompt}\n",
+ "\n",
+ "ASSISTANT:\n",
+ "'''"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8c71841b-7f2f-4907-a2e7-ac112ea9b0d7",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "llm = Llama(\n",
+ " model_path=\".\\models\\phi-2.Q5_K_M.gguf\",\n",
+ " chat_format=\"llama-2\",\n",
+ " n_gpu_layers=-1, # use GPU acceleration\n",
+ " seed=1337, # set a specific seed\n",
+ " n_ctx=2048, # set the context window\n",
+ " n_threads=16,\n",
+ " f16_kv=True,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08ba9c09-568c-4535-8bb1-0bcba22c31b6",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bedf4abc-9837-4d6f-90f2-aa4a5d0f6eec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " { \"role\": \"system\", \"content\": \"You are a story writing assistant.\" },\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": prompt\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ ")\n",
+ "\n",
+ "for chunk in output:\n",
+ " delta = chunk['choices'][0]['delta']\n",
+ " if 'content' in delta: \n",
+ " print(delta['content'], end='', flush=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58e65241-f87d-42b0-9b6d-41826a6583a0",
+ "metadata": {},
+ "source": [
+ "## Pulling models from Huggingface hub\n",
+ "\n",
+ "The below code loads the pre-trained Llama model from huggingface repository specified by the repository ID, filename, and other parameters for the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c777d38-6990-47d9-9333-5470cd80b68b",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "\n",
+ "prompt = \"Write a story about Pandas\"\n",
+ "\n",
+ "llm = Llama.from_pretrained(repo_id=\"TheBloke/phi-2-GGUF\",\n",
+ " filename=\"*Q5_K_M.gguf\",\n",
+ " chat_format=\"llama-2\",\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed\n",
+ " n_ctx=2048, # Uncomment to increase the context window\n",
+ " n_threads=16,\n",
+ " f16_kv=True,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4785f66e-a0f1-43fb-8195-7314c41e0438",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2843365-7c12-412f-ba93-3dd89ec7f857",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " { \"role\": \"system\", \"content\": \"You are a story writing assistant.\" },\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": prompt\n",
+ " }\n",
+ " ],\n",
+ " max_tokens=256,\n",
+ " stream=True\n",
+ ")\n",
+ "\n",
+ "for chunk in output:\n",
+ " delta = chunk['choices'][0]['delta']\n",
+ " if 'content' in delta: \n",
+ " print(delta['content'], end='', flush=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "061ce086-54e6-41b7-8283-e1e66bcd4a47",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/8_llm_sycl_multimodal.ipynb b/8_llm_sycl_multimodal.ipynb
new file mode 100644
index 0000000..38f882a
--- /dev/null
+++ b/8_llm_sycl_multimodal.ipynb
@@ -0,0 +1,426 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Visual-language assistant using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp python for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp Python\n",
+ "\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " Open a new terminal and perform the following steps:\n",
+ "\n",
+ "\n",
+ "# Set the environment variables\n",
+ " set CMAKE_GENERATOR=Ninja\n",
+ " set CMAKE_C_COMPILER=cl\n",
+ " set CMAKE_CXX_COMPILER=icx\n",
+ " set CXX=icx\n",
+ " set CC=cl\n",
+ " set CMAKE_ARGS=\"-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl\"\n",
+ " Install Llamacpp-Python bindings\n",
+ " pip install llama-cpp-python -U --force --no-cache-dir –verbose ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model as below"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58e65241-f87d-42b0-9b6d-41826a6583a0",
+ "metadata": {},
+ "source": [
+ "## Pulling models from Huggingface hub\n",
+ "\n",
+ "The below code loads the pre-trained Llama model from huggingface repository specified by the repository ID, filename, and other parameters for the model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "462980cc-f9c2-468e-9705-e8b99948d220",
+ "metadata": {},
+ "source": [
+ "### Initialize oneAPI environment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8d0962b-6000-44fe-a92b-d95c6458fcc2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\\\Program Files (x86)\\\\Intel\\\\oneAPI\\\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c777d38-6990-47d9-9333-5470cd80b68b",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "from llama_cpp.llama_chat_format import MoondreamChatHandler\n",
+ "\n",
+ "# Initialize the chat handler with a pre-trained model\n",
+ "chat_handler = MoondreamChatHandler.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\", # Repository ID for the pre-trained model\n",
+ " filename=\"*mmproj*\", # Filename pattern for the model\n",
+ ")\n",
+ "\n",
+ "# Initialize the model with the pre-trained model and chat handler\n",
+ "llm = Llama.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\", # Repository ID for the pre-trained model\n",
+ " filename=\"*text-model*\", # Filename pattern for the text model\n",
+ " chat_handler=chat_handler, # Chat handler for formatting\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed for reproducibility\n",
+ " n_ctx=2048, # Uncomment to increase the context window size\n",
+ " n_threads=16, # Number of threads to use\n",
+ ")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4785f66e-a0f1-43fb-8195-7314c41e0438",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2843365-7c12-412f-ba93-3dd89ec7f857",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ " # Create a chat completion request with a user message\n",
+ "response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\", # Role of the message sender\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": \"What is unuusal int this picture?\"}, # Text content of the message\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": \"https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/d5fbbd1a-d484-415c-88cb-9986625b7b11\"}} # Image URL content of the message\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True # Stream the response\n",
+ ")\n",
+ "\n",
+ "# Stream and print the response content\n",
+ "for chunk in response:\n",
+ " delta = chunk['choices'][0]['delta'] # Extract the delta from the response chunk\n",
+ " if 'content' in delta: # Check if the delta contains content\n",
+ " print(delta['content'], end='', flush=True) # Print the content without a newline and flush the output buffer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f5cf673-15d0-4fdc-9e27-9b708e86bb35",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77723b93-b914-4728-81b8-047711a178ae",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! pip install streamlit"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31a1b16a-83ed-46d3-bf34-64ee50773b8c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_visual_answering.py\n",
+ "import time\n",
+ "from threading import Thread\n",
+ "import streamlit as st\n",
+ "from llama_cpp import Llama\n",
+ "from llama_cpp.llama_chat_format import MoondreamChatHandler\n",
+ "import tempfile\n",
+ "from PIL import Image\n",
+ "import base64\n",
+ "\n",
+ "# Create a StreamliVisual-language assistantt app that displays the response word by word\n",
+ "st.header(\"Visual-language assistant with SYCL 🐻❄️\")\n",
+ "\n",
+ "# Dropdown to select a model\n",
+ "selected_model = st.selectbox(\n",
+ " \"Please select a model\", \n",
+ " (\"vikhyatk/moondream2\", \"microsoft/Phi-3-vision-128k-instruct\", \"Intel/llava-gemma-2b\"), \n",
+ " index=0\n",
+ ")\n",
+ "\n",
+ "# File uploader for image\n",
+ "img_file_buffer = st.file_uploader('Upload a PNG image', type=[\"jpg\", \"png\", \"gif\"])\n",
+ "\n",
+ "# Input for image URL\n",
+ "# Input for image URL\n",
+ "url = st.text_input(\"Enter the URL of the Image:\",value=\"Enter the URL of the Image\", key=\"url_path\")\n",
+ "\n",
+ "# Display the uploaded image or the image from the URL\n",
+ "if img_file_buffer is not None:\n",
+ " try:\n",
+ " image = Image.open(img_file_buffer)\n",
+ " st.image(image, width=600) # Manually Adjust the width of the image as per requirement\n",
+ " except Exception as e:\n",
+ " st.error(f\"Error loading image: {e}\")\n",
+ "else:\n",
+ " st.error(\"Please provide an image URL or upload an image.\")\n",
+ "\n",
+ "\n",
+ "# Input prompt for the question\n",
+ "question = st.text_input(\"Enter the question:\", value=\"What's the content of the image?\", key=\"question\")\n",
+ "\n",
+ "def getfinalresponse(input_text):\n",
+ " try:\n",
+ " # Create a temporary file if an image is uploaded\n",
+ " if img_file_buffer is not None:\n",
+ " with tempfile.NamedTemporaryFile(delete=False) as tmp_file:\n",
+ " tmp_file.write(img_file_buffer.getvalue())\n",
+ " file_path = tmp_file.name\n",
+ "\n",
+ " def image_to_base64_data_uri(): \n",
+ " with open(file_path, \"rb\") as img_file:\n",
+ " base64_data = base64.b64encode(img_file.read()).decode('utf-8')\n",
+ " return f\"data:image/jpg;base64,{base64_data}\" \n",
+ "\n",
+ " # Initialize the chat handler with a pre-trained model\n",
+ " chat_handler = MoondreamChatHandler.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\",\n",
+ " filename=\"*mmproj*\",\n",
+ " )\n",
+ "\n",
+ " # Initialize the Llama model with the pre-trained model and chat handler\n",
+ " llm = Llama.from_pretrained(\n",
+ " repo_id=selected_model,\n",
+ " filename=\"*text-model*\",\n",
+ " chat_handler=chat_handler,\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed\n",
+ " n_ctx=2048, # Uncomment to increase the context window\n",
+ " n_threads=16,\n",
+ " )\n",
+ "\n",
+ " # Create a chat completion request with the appropriate image URL\n",
+ " if img_file_buffer is not None:\n",
+ " response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": question},\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": image_to_base64_data_uri()}}\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ " )\n",
+ " else:\n",
+ " response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": question},\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": url}}\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ " )\n",
+ "\n",
+ " # Stream and yield the response content word by word\n",
+ " for chunk in response:\n",
+ " res = chunk['choices'][0]['delta']\n",
+ " if 'content' in res:\n",
+ " word = res['content'].split()\n",
+ " for token in word:\n",
+ " yield token + \" \"\n",
+ " except Exception as e:\n",
+ " st.error(f\"An error occurred: {e}\")\n",
+ "\n",
+ "# Generate response when the button is clicked\n",
+ "if st.button(\"Generate\"):\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " if not question.strip():\n",
+ " st.error(\"Please enter a question.\")\n",
+ " elif not url.strip() and img_file_buffer is None:\n",
+ " st.error(\"Please provide an image URL or upload an image.\")\n",
+ " else:\n",
+ " st.write_stream(getfinalresponse(question))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15a8d984-5e92-4de1-bf88-f8a2e150476d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_visual_answering.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "905150b4-874d-4bf2-aec6-3dffc69a09a6",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md\n",
+ "* https://github.com/abetlen/llama-cpp-python"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Assets/cmd1.png b/Assets/cmd1.png
new file mode 100644
index 0000000..406bac3
Binary files /dev/null and b/Assets/cmd1.png differ
diff --git a/Assets/npu.png b/Assets/npu.png
new file mode 100644
index 0000000..b38109a
Binary files /dev/null and b/Assets/npu.png differ
diff --git a/Assets/oneapi1.png b/Assets/oneapi1.png
new file mode 100644
index 0000000..205f5e7
Binary files /dev/null and b/Assets/oneapi1.png differ
diff --git a/Assets/oneapi2.png b/Assets/oneapi2.png
new file mode 100644
index 0000000..0539d36
Binary files /dev/null and b/Assets/oneapi2.png differ
diff --git a/Assets/out1.png b/Assets/out1.png
new file mode 100644
index 0000000..6965c3c
Binary files /dev/null and b/Assets/out1.png differ
diff --git a/Assets/output_latest.png b/Assets/output_latest.png
new file mode 100644
index 0000000..1ed3e9e
Binary files /dev/null and b/Assets/output_latest.png differ
diff --git a/src/st_rag_chromadb.py b/src/st_rag_chromadb.py
index 7887339..a8f8aed 100644
--- a/src/st_rag_chromadb.py
+++ b/src/st_rag_chromadb.py
@@ -161,8 +161,10 @@ def getfinalresponse(document_url, embedding_type, chat_model):
# generate response
if submit:
- document_url = url_path
- chat_model = model
-
- with st.spinner("Loading document....🐎"):
- st.write(getfinalresponse(document_url, embedding_type, chat_model))
+ if not url_path.strip():
+ st.error("Please enter a valid URL.")
+ elif not question.strip():
+ st.error("Please enter a valid question.")
+ else:
+ with st.spinner("Loading document....🐎"):
+ st.write(getfinalresponse(url_path, embedding_type, model))
diff --git a/src/st_visual_answering.py b/src/st_visual_answering.py
new file mode 100644
index 0000000..db01f5f
--- /dev/null
+++ b/src/st_visual_answering.py
@@ -0,0 +1,117 @@
+import time
+from threading import Thread
+import streamlit as st
+from llama_cpp import Llama
+from llama_cpp.llama_chat_format import MoondreamChatHandler
+import tempfile
+from PIL import Image
+import base64
+
+# Create a StreamliVisual-language assistantt app that displays the response word by word
+st.header("Visual-language assistant with SYCL 🐻❄️")
+
+# Dropdown to select a model
+selected_model = st.selectbox(
+ "Please select a model",
+ ("vikhyatk/moondream2", "microsoft/Phi-3-vision-128k-instruct", "Intel/llava-gemma-2b"),
+ index=0
+)
+
+# File uploader for image
+img_file_buffer = st.file_uploader('Upload a PNG image', type=["jpg", "png", "gif"])
+
+# Input for image URL
+# Input for image URL
+url = st.text_input("Enter the URL of the Image:",value="Enter the URL of the Image", key="url_path")
+
+# Display the uploaded image or the image from the URL
+if img_file_buffer is not None:
+ try:
+ image = Image.open(img_file_buffer)
+ st.image(image, width=600) # Manually Adjust the width of the image as per requirement
+ except Exception as e:
+ st.error(f"Error loading image: {e}")
+else:
+ st.error("Please provide an image URL or upload an image.")
+
+
+# Input prompt for the question
+question = st.text_input("Enter the question:", value="What's the content of the image?", key="question")
+
+def getfinalresponse(input_text):
+ try:
+ # Create a temporary file if an image is uploaded
+ if img_file_buffer is not None:
+ with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
+ tmp_file.write(img_file_buffer.getvalue())
+ file_path = tmp_file.name
+
+ def image_to_base64_data_uri():
+ with open(file_path, "rb") as img_file:
+ base64_data = base64.b64encode(img_file.read()).decode('utf-8')
+ return f"data:image/jpg;base64,{base64_data}"
+
+ # Initialize the chat handler with a pre-trained model
+ chat_handler = MoondreamChatHandler.from_pretrained(
+ repo_id="vikhyatk/moondream2",
+ filename="*mmproj*",
+ )
+
+ # Initialize the Llama model with the pre-trained model and chat handler
+ llm = Llama.from_pretrained(
+ repo_id=selected_model,
+ filename="*text-model*",
+ chat_handler=chat_handler,
+ n_gpu_layers=-1, # Uncomment to use GPU acceleration
+ seed=1337, # Uncomment to set a specific seed
+ n_ctx=2048, # Uncomment to increase the context window
+ n_threads=16,
+ )
+
+ # Create a chat completion request with the appropriate image URL
+ if img_file_buffer is not None:
+ response = llm.create_chat_completion(
+ messages=[
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": question},
+ {"type": "image_url", "image_url": {"url": image_to_base64_data_uri()}}
+ ]
+ }
+ ],
+ stream=True
+ )
+ else:
+ response = llm.create_chat_completion(
+ messages=[
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": question},
+ {"type": "image_url", "image_url": {"url": url}}
+ ]
+ }
+ ],
+ stream=True
+ )
+
+ # Stream and yield the response content word by word
+ for chunk in response:
+ res = chunk['choices'][0]['delta']
+ if 'content' in res:
+ word = res['content'].split()
+ for token in word:
+ yield token + " "
+ except Exception as e:
+ st.error(f"An error occurred: {e}")
+
+# Generate response when the button is clicked
+if st.button("Generate"):
+ with st.spinner("Running....🐎"):
+ if not question.strip():
+ st.error("Please enter a question.")
+ elif not url.strip() and img_file_buffer is None:
+ st.error("Please provide an image URL or upload an image.")
+ else:
+ st.write_stream(getfinalresponse(question))
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/6_llm_sycl_gpu.ipynb b/6_llm_sycl_gpu.ipynb
new file mode 100644
index 0000000..9f0c58c
--- /dev/null
+++ b/6_llm_sycl_gpu.ipynb
@@ -0,0 +1,248 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Inference using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {
+ "jp-MarkdownHeadingCollapsed": true
+ },
+ "source": [
+ "## Step 2: Install Llamacpp for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp\n",
+ "\n",
+ "* git clone the llama.cpp repo\n",
+ " \n",
+ " ```\n",
+ " git clone https://github.com/ggerganov/llama.cpp.git\n",
+ "\n",
+ " ```\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " # Option 1: Use FP32 (recommended for better performance in most cases)\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release\n",
+ " \n",
+ " # Option 2: Or FP16\n",
+ " cmake -B build -G \"Ninja\" -DGGML_SYCL=ON -DCMAKE_C_COMPILER=cl -DCMAKE_CXX_COMPILER=icx -DCMAKE_BUILD_TYPE=Release -DGGML_SYCL_F16=ON\n",
+ " \n",
+ " cmake --build build --config Release -j\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model for example as below\n",
+ "* Open the mini-forge prompt, activate the llm-sycl environment and enable oneAPI enviroment as below\n",
+ "\n",
+ " ```\n",
+ " \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 \n",
+ " ```\n",
+ "* List the sycl devices as below\n",
+ "\n",
+ " ```\n",
+ " build\\bin\\ls-sycl-device.exe\n",
+ "\n",
+ " ```\n",
+ "* Run inference\n",
+ "```\n",
+ "build\\bin\\llama-cli.exe -m models\\llama-2-7b.Q4_0.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 33 -s 0 -sm none -mg 0\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Below is an example output\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3ad64c2-2432-4cb0-8a3d-856daad1dc18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m Qwen1.5-4B.Q4_K_M.gguf -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 400 -e -ngl 25 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd47d1d9-414b-4cd2-b20e-4c36871f1145",
+ "metadata": {},
+ "source": [
+ "#### Run the inference locally on AI PC"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65e5cd95-18a4-4879-9d3d-05e302448ff6",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "! ..\\git_llamacpp\\llama.cpp\\build\\bin\\llama-cli.exe -m ./download_models/{model_gguf} -p \"Building a website can be done in 10 simple steps:\\nStep 1:\" -n 100 -e -ngl 33 -s 0 -sm none -mg 0"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec180ac3-e74a-41d9-a9b9-65478dcea556",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/7_llm_sycl_gpu_python.ipynb b/7_llm_sycl_gpu_python.ipynb
new file mode 100644
index 0000000..c4f000a
--- /dev/null
+++ b/7_llm_sycl_gpu_python.ipynb
@@ -0,0 +1,339 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Inference using SYCL backend on AI PC using Llamacpp Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1) from Intel:\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp python for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp Python\n",
+ "\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " Open a new terminal and perform the following steps:\n",
+ "\n",
+ "\n",
+ "# Set the environment variables\n",
+ " set CMAKE_GENERATOR=Ninja\n",
+ " set CMAKE_C_COMPILER=cl\n",
+ " set CMAKE_CXX_COMPILER=icx\n",
+ " set CXX=icx\n",
+ " set CC=cl\n",
+ " set CMAKE_ARGS=\"-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl\"\n",
+ " \n",
+ " pip install llama-cpp-python -U --force --no-cache-dir –-verbose\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model as below"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32f188eb-4cbf-49cd-8e88-0f3c6da19894",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\\\Program Files (x86)\\\\Intel\\\\oneAPI\\\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f0f21fb7-cb4a-421e-97f1-d763d989cebd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "prompt = \"Write a story about Pandas\"\n",
+ "prompt_template=f'''SYSTEM: You are a helpful, respectful and honest assistant. Always answer as helpfully.\n",
+ "\n",
+ "USER: {prompt}\n",
+ "\n",
+ "ASSISTANT:\n",
+ "'''"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01173f7a-0725-4b34-aabc-7e6582b87da4",
+ "metadata": {},
+ "source": [
+ "## Run the inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8c71841b-7f2f-4907-a2e7-ac112ea9b0d7",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "llm = Llama(\n",
+ " model_path=\".\\models\\phi-2.Q5_K_M.gguf\",\n",
+ " chat_format=\"llama-2\",\n",
+ " n_gpu_layers=-1, # use GPU acceleration\n",
+ " seed=1337, # set a specific seed\n",
+ " n_ctx=2048, # set the context window\n",
+ " n_threads=16,\n",
+ " f16_kv=True,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08ba9c09-568c-4535-8bb1-0bcba22c31b6",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bedf4abc-9837-4d6f-90f2-aa4a5d0f6eec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " { \"role\": \"system\", \"content\": \"You are a story writing assistant.\" },\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": prompt\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ ")\n",
+ "\n",
+ "for chunk in output:\n",
+ " delta = chunk['choices'][0]['delta']\n",
+ " if 'content' in delta: \n",
+ " print(delta['content'], end='', flush=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58e65241-f87d-42b0-9b6d-41826a6583a0",
+ "metadata": {},
+ "source": [
+ "## Pulling models from Huggingface hub\n",
+ "\n",
+ "The below code loads the pre-trained Llama model from huggingface repository specified by the repository ID, filename, and other parameters for the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c777d38-6990-47d9-9333-5470cd80b68b",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "\n",
+ "prompt = \"Write a story about Pandas\"\n",
+ "\n",
+ "llm = Llama.from_pretrained(repo_id=\"TheBloke/phi-2-GGUF\",\n",
+ " filename=\"*Q5_K_M.gguf\",\n",
+ " chat_format=\"llama-2\",\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed\n",
+ " n_ctx=2048, # Uncomment to increase the context window\n",
+ " n_threads=16,\n",
+ " f16_kv=True,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4785f66e-a0f1-43fb-8195-7314c41e0438",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2843365-7c12-412f-ba93-3dd89ec7f857",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " { \"role\": \"system\", \"content\": \"You are a story writing assistant.\" },\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": prompt\n",
+ " }\n",
+ " ],\n",
+ " max_tokens=256,\n",
+ " stream=True\n",
+ ")\n",
+ "\n",
+ "for chunk in output:\n",
+ " delta = chunk['choices'][0]['delta']\n",
+ " if 'content' in delta: \n",
+ " print(delta['content'], end='', flush=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "061ce086-54e6-41b7-8283-e1e66bcd4a47",
+ "metadata": {},
+ "source": [
+ "## Example output\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92387fa9-2376-49a7-a94b-a29f254a0471",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/8_llm_sycl_multimodal.ipynb b/8_llm_sycl_multimodal.ipynb
new file mode 100644
index 0000000..38f882a
--- /dev/null
+++ b/8_llm_sycl_multimodal.ipynb
@@ -0,0 +1,426 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "652ea6c8-8d13-4228-853e-fad46db470f5",
+ "metadata": {},
+ "source": [
+ "# Visual-language assistant using SYCL backend on AI PC"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71e0aeac-58b1-4114-95f1-7d3a7a4c34f2",
+ "metadata": {},
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This notebook demonstrates how to install LLamacpp for SYCL on Windows with Intel GPUs. It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97cf7db8-9529-47dd-b41d-81b22c8d5848",
+ "metadata": {},
+ "source": [
+ "## What is an AIPC\n",
+ "\n",
+ "What is an AI PC you ask?\n",
+ "\n",
+ "Here is an [explanation](https://www.intel.com/content/www/us/en/newsroom/news/what-is-an-ai-pc.htm#gs.a55so1):\n",
+ "\n",
+ "”An AI PC has a CPU, a GPU and an NPU, each with specific AI acceleration capabilities. An NPU, or neural processing unit, is a specialized accelerator that handles artificial intelligence (AI) and machine learning (ML) tasks right on your PC instead of sending data to be processed in the cloud. The GPU and CPU can also process these workloads, but the NPU is especially good at low-power AI calculations. The AI PC represents a fundamental shift in how our computers operate. It is not a solution for a problem that didn’t exist before. Instead, it promises to be a huge improvement for everyday PC usages.”"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4682eb3e-540b-4814-8142-c54efc32f31b",
+ "metadata": {},
+ "source": [
+ "## Install Prerequisites"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f8b6d2-34af-44ad-8363-dea57660bc00",
+ "metadata": {},
+ "source": [
+ "### Step 1: System Preparation\n",
+ "\n",
+ "To set up your AIPC for running with Intel iGPUs, follow these essential steps:\n",
+ "\n",
+ "1. Update Intel GPU Drivers: Ensure your system has the latest Intel GPU drivers, which are crucial for optimal performance and compatibility. You can download these directly from Intel's [official website](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) . Once you have installed the official drivers, you could also install Intel ARC Control to monitor the gpu:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "2. Install Visual Studio 2022 Community edition with C++: Visual Studio 2022, along with the “Desktop Development with C++” workload, is required. This prepares your environment for C++ based extensions used by the intel SYCL backend that powers accelerated Ollama. You can download VS 2022 Community edition from the official site, [here](https://visualstudio.microsoft.com/downloads/).\n",
+ "\n",
+ "3. Install conda-forge: conda-forge will manage your Python environments and dependencies efficiently, providing a clean, minimal base for your Python setup. Visit conda-forge's [installation site](https://conda-forge.org/download/) to install for windows.\n",
+ "\n",
+ "4. Install [Intel® oneAPI Base Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "8040fd21-7782-4b97-a0eb-327816328f17",
+ "metadata": {},
+ "source": [
+ "## Step 2: Install Llamacpp python for SYCL\n",
+ "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n",
+ "\n",
+ "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n",
+ " ```\n",
+ " conda create -n llm-sycl python=3.11\n",
+ "\n",
+ " ```\n",
+ "\n",
+ "### Activate the new environment\n",
+ "```\n",
+ "conda activate llm-sycl\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### With the llm-sycl environment active, enable oneAPI environment. \n",
+ "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n",
+ "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n",
+ "\n",
+ "```\n",
+ "sycl-ls\n",
+ "\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Install build tools\n",
+ "\n",
+ "* Download & install [cmake for Windows](https://cmake.org/download/):\n",
+ "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n",
+ "\n",
+ "### Install llama.cpp Python\n",
+ "\n",
+ " \n",
+ "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n",
+ " \n",
+ " ```\n",
+ " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n",
+ "\n",
+ " Open a new terminal and perform the following steps:\n",
+ "\n",
+ "\n",
+ "# Set the environment variables\n",
+ " set CMAKE_GENERATOR=Ninja\n",
+ " set CMAKE_C_COMPILER=cl\n",
+ " set CMAKE_CXX_COMPILER=icx\n",
+ " set CXX=icx\n",
+ " set CC=cl\n",
+ " set CMAKE_ARGS=\"-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl\"\n",
+ " Install Llamacpp-Python bindings\n",
+ " pip install llama-cpp-python -U --force --no-cache-dir –verbose ```\n",
+ "\n",
+ "### Below shows a simple example to show how to run a community GGUF model with llama.cpp for SYCL\n",
+ "* Download the model from huggingface and prepare the model for inference\n",
+ "* Run the model as below"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58e65241-f87d-42b0-9b6d-41826a6583a0",
+ "metadata": {},
+ "source": [
+ "## Pulling models from Huggingface hub\n",
+ "\n",
+ "The below code loads the pre-trained Llama model from huggingface repository specified by the repository ID, filename, and other parameters for the model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "462980cc-f9c2-468e-9705-e8b99948d220",
+ "metadata": {},
+ "source": [
+ "### Initialize oneAPI environment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8d0962b-6000-44fe-a92b-d95c6458fcc2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!@call \"C:\\\\Program Files (x86)\\\\Intel\\\\oneAPI\\\\setvars.bat\" intel64 --force"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c777d38-6990-47d9-9333-5470cd80b68b",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "from llama_cpp import Llama\n",
+ "from llama_cpp.llama_chat_format import MoondreamChatHandler\n",
+ "\n",
+ "# Initialize the chat handler with a pre-trained model\n",
+ "chat_handler = MoondreamChatHandler.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\", # Repository ID for the pre-trained model\n",
+ " filename=\"*mmproj*\", # Filename pattern for the model\n",
+ ")\n",
+ "\n",
+ "# Initialize the model with the pre-trained model and chat handler\n",
+ "llm = Llama.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\", # Repository ID for the pre-trained model\n",
+ " filename=\"*text-model*\", # Filename pattern for the text model\n",
+ " chat_handler=chat_handler, # Chat handler for formatting\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed for reproducibility\n",
+ " n_ctx=2048, # Uncomment to increase the context window size\n",
+ " n_threads=16, # Number of threads to use\n",
+ ")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4785f66e-a0f1-43fb-8195-7314c41e0438",
+ "metadata": {},
+ "source": [
+ "The below code creates a chat completion object specifies the input messages and tells the model to generate text in a streaming fashion.\n",
+ "Then we iterates over the generated chunks of text to generate streaming response"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2843365-7c12-412f-ba93-3dd89ec7f857",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ " # Create a chat completion request with a user message\n",
+ "response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\", # Role of the message sender\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": \"What is unuusal int this picture?\"}, # Text content of the message\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": \"https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/d5fbbd1a-d484-415c-88cb-9986625b7b11\"}} # Image URL content of the message\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True # Stream the response\n",
+ ")\n",
+ "\n",
+ "# Stream and print the response content\n",
+ "for chunk in response:\n",
+ " delta = chunk['choices'][0]['delta'] # Extract the delta from the response chunk\n",
+ " if 'content' in delta: # Check if the delta contains content\n",
+ " print(delta['content'], end='', flush=True) # Print the content without a newline and flush the output buffer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f5cf673-15d0-4fdc-9e27-9b708e86bb35",
+ "metadata": {},
+ "source": [
+ "### Streamlit Demo"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77723b93-b914-4728-81b8-047711a178ae",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! pip install streamlit"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31a1b16a-83ed-46d3-bf34-64ee50773b8c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%writefile src/st_visual_answering.py\n",
+ "import time\n",
+ "from threading import Thread\n",
+ "import streamlit as st\n",
+ "from llama_cpp import Llama\n",
+ "from llama_cpp.llama_chat_format import MoondreamChatHandler\n",
+ "import tempfile\n",
+ "from PIL import Image\n",
+ "import base64\n",
+ "\n",
+ "# Create a StreamliVisual-language assistantt app that displays the response word by word\n",
+ "st.header(\"Visual-language assistant with SYCL 🐻❄️\")\n",
+ "\n",
+ "# Dropdown to select a model\n",
+ "selected_model = st.selectbox(\n",
+ " \"Please select a model\", \n",
+ " (\"vikhyatk/moondream2\", \"microsoft/Phi-3-vision-128k-instruct\", \"Intel/llava-gemma-2b\"), \n",
+ " index=0\n",
+ ")\n",
+ "\n",
+ "# File uploader for image\n",
+ "img_file_buffer = st.file_uploader('Upload a PNG image', type=[\"jpg\", \"png\", \"gif\"])\n",
+ "\n",
+ "# Input for image URL\n",
+ "# Input for image URL\n",
+ "url = st.text_input(\"Enter the URL of the Image:\",value=\"Enter the URL of the Image\", key=\"url_path\")\n",
+ "\n",
+ "# Display the uploaded image or the image from the URL\n",
+ "if img_file_buffer is not None:\n",
+ " try:\n",
+ " image = Image.open(img_file_buffer)\n",
+ " st.image(image, width=600) # Manually Adjust the width of the image as per requirement\n",
+ " except Exception as e:\n",
+ " st.error(f\"Error loading image: {e}\")\n",
+ "else:\n",
+ " st.error(\"Please provide an image URL or upload an image.\")\n",
+ "\n",
+ "\n",
+ "# Input prompt for the question\n",
+ "question = st.text_input(\"Enter the question:\", value=\"What's the content of the image?\", key=\"question\")\n",
+ "\n",
+ "def getfinalresponse(input_text):\n",
+ " try:\n",
+ " # Create a temporary file if an image is uploaded\n",
+ " if img_file_buffer is not None:\n",
+ " with tempfile.NamedTemporaryFile(delete=False) as tmp_file:\n",
+ " tmp_file.write(img_file_buffer.getvalue())\n",
+ " file_path = tmp_file.name\n",
+ "\n",
+ " def image_to_base64_data_uri(): \n",
+ " with open(file_path, \"rb\") as img_file:\n",
+ " base64_data = base64.b64encode(img_file.read()).decode('utf-8')\n",
+ " return f\"data:image/jpg;base64,{base64_data}\" \n",
+ "\n",
+ " # Initialize the chat handler with a pre-trained model\n",
+ " chat_handler = MoondreamChatHandler.from_pretrained(\n",
+ " repo_id=\"vikhyatk/moondream2\",\n",
+ " filename=\"*mmproj*\",\n",
+ " )\n",
+ "\n",
+ " # Initialize the Llama model with the pre-trained model and chat handler\n",
+ " llm = Llama.from_pretrained(\n",
+ " repo_id=selected_model,\n",
+ " filename=\"*text-model*\",\n",
+ " chat_handler=chat_handler,\n",
+ " n_gpu_layers=-1, # Uncomment to use GPU acceleration\n",
+ " seed=1337, # Uncomment to set a specific seed\n",
+ " n_ctx=2048, # Uncomment to increase the context window\n",
+ " n_threads=16,\n",
+ " )\n",
+ "\n",
+ " # Create a chat completion request with the appropriate image URL\n",
+ " if img_file_buffer is not None:\n",
+ " response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": question},\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": image_to_base64_data_uri()}}\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ " )\n",
+ " else:\n",
+ " response = llm.create_chat_completion(\n",
+ " messages=[\n",
+ " {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": [\n",
+ " {\"type\": \"text\", \"text\": question},\n",
+ " {\"type\": \"image_url\", \"image_url\": {\"url\": url}}\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " stream=True\n",
+ " )\n",
+ "\n",
+ " # Stream and yield the response content word by word\n",
+ " for chunk in response:\n",
+ " res = chunk['choices'][0]['delta']\n",
+ " if 'content' in res:\n",
+ " word = res['content'].split()\n",
+ " for token in word:\n",
+ " yield token + \" \"\n",
+ " except Exception as e:\n",
+ " st.error(f\"An error occurred: {e}\")\n",
+ "\n",
+ "# Generate response when the button is clicked\n",
+ "if st.button(\"Generate\"):\n",
+ " with st.spinner(\"Running....🐎\"):\n",
+ " if not question.strip():\n",
+ " st.error(\"Please enter a question.\")\n",
+ " elif not url.strip() and img_file_buffer is None:\n",
+ " st.error(\"Please provide an image URL or upload an image.\")\n",
+ " else:\n",
+ " st.write_stream(getfinalresponse(question))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15a8d984-5e92-4de1-bf88-f8a2e150476d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! streamlit run src/st_visual_answering.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "905150b4-874d-4bf2-aec6-3dffc69a09a6",
+ "metadata": {},
+ "source": [
+ "* Reference:https://github.com/ggerganov/llama.cpp/blob/master/docs/backend/SYCL.md\n",
+ "* https://github.com/abetlen/llama-cpp-python"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ac73234-1851-42ad-9b6c-67ba9562db32",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Assets/cmd1.png b/Assets/cmd1.png
new file mode 100644
index 0000000..406bac3
Binary files /dev/null and b/Assets/cmd1.png differ
diff --git a/Assets/npu.png b/Assets/npu.png
new file mode 100644
index 0000000..b38109a
Binary files /dev/null and b/Assets/npu.png differ
diff --git a/Assets/oneapi1.png b/Assets/oneapi1.png
new file mode 100644
index 0000000..205f5e7
Binary files /dev/null and b/Assets/oneapi1.png differ
diff --git a/Assets/oneapi2.png b/Assets/oneapi2.png
new file mode 100644
index 0000000..0539d36
Binary files /dev/null and b/Assets/oneapi2.png differ
diff --git a/Assets/out1.png b/Assets/out1.png
new file mode 100644
index 0000000..6965c3c
Binary files /dev/null and b/Assets/out1.png differ
diff --git a/Assets/output_latest.png b/Assets/output_latest.png
new file mode 100644
index 0000000..1ed3e9e
Binary files /dev/null and b/Assets/output_latest.png differ
diff --git a/src/st_rag_chromadb.py b/src/st_rag_chromadb.py
index 7887339..a8f8aed 100644
--- a/src/st_rag_chromadb.py
+++ b/src/st_rag_chromadb.py
@@ -161,8 +161,10 @@ def getfinalresponse(document_url, embedding_type, chat_model):
# generate response
if submit:
- document_url = url_path
- chat_model = model
-
- with st.spinner("Loading document....🐎"):
- st.write(getfinalresponse(document_url, embedding_type, chat_model))
+ if not url_path.strip():
+ st.error("Please enter a valid URL.")
+ elif not question.strip():
+ st.error("Please enter a valid question.")
+ else:
+ with st.spinner("Loading document....🐎"):
+ st.write(getfinalresponse(url_path, embedding_type, model))
diff --git a/src/st_visual_answering.py b/src/st_visual_answering.py
new file mode 100644
index 0000000..db01f5f
--- /dev/null
+++ b/src/st_visual_answering.py
@@ -0,0 +1,117 @@
+import time
+from threading import Thread
+import streamlit as st
+from llama_cpp import Llama
+from llama_cpp.llama_chat_format import MoondreamChatHandler
+import tempfile
+from PIL import Image
+import base64
+
+# Create a StreamliVisual-language assistantt app that displays the response word by word
+st.header("Visual-language assistant with SYCL 🐻❄️")
+
+# Dropdown to select a model
+selected_model = st.selectbox(
+ "Please select a model",
+ ("vikhyatk/moondream2", "microsoft/Phi-3-vision-128k-instruct", "Intel/llava-gemma-2b"),
+ index=0
+)
+
+# File uploader for image
+img_file_buffer = st.file_uploader('Upload a PNG image', type=["jpg", "png", "gif"])
+
+# Input for image URL
+# Input for image URL
+url = st.text_input("Enter the URL of the Image:",value="Enter the URL of the Image", key="url_path")
+
+# Display the uploaded image or the image from the URL
+if img_file_buffer is not None:
+ try:
+ image = Image.open(img_file_buffer)
+ st.image(image, width=600) # Manually Adjust the width of the image as per requirement
+ except Exception as e:
+ st.error(f"Error loading image: {e}")
+else:
+ st.error("Please provide an image URL or upload an image.")
+
+
+# Input prompt for the question
+question = st.text_input("Enter the question:", value="What's the content of the image?", key="question")
+
+def getfinalresponse(input_text):
+ try:
+ # Create a temporary file if an image is uploaded
+ if img_file_buffer is not None:
+ with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
+ tmp_file.write(img_file_buffer.getvalue())
+ file_path = tmp_file.name
+
+ def image_to_base64_data_uri():
+ with open(file_path, "rb") as img_file:
+ base64_data = base64.b64encode(img_file.read()).decode('utf-8')
+ return f"data:image/jpg;base64,{base64_data}"
+
+ # Initialize the chat handler with a pre-trained model
+ chat_handler = MoondreamChatHandler.from_pretrained(
+ repo_id="vikhyatk/moondream2",
+ filename="*mmproj*",
+ )
+
+ # Initialize the Llama model with the pre-trained model and chat handler
+ llm = Llama.from_pretrained(
+ repo_id=selected_model,
+ filename="*text-model*",
+ chat_handler=chat_handler,
+ n_gpu_layers=-1, # Uncomment to use GPU acceleration
+ seed=1337, # Uncomment to set a specific seed
+ n_ctx=2048, # Uncomment to increase the context window
+ n_threads=16,
+ )
+
+ # Create a chat completion request with the appropriate image URL
+ if img_file_buffer is not None:
+ response = llm.create_chat_completion(
+ messages=[
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": question},
+ {"type": "image_url", "image_url": {"url": image_to_base64_data_uri()}}
+ ]
+ }
+ ],
+ stream=True
+ )
+ else:
+ response = llm.create_chat_completion(
+ messages=[
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": question},
+ {"type": "image_url", "image_url": {"url": url}}
+ ]
+ }
+ ],
+ stream=True
+ )
+
+ # Stream and yield the response content word by word
+ for chunk in response:
+ res = chunk['choices'][0]['delta']
+ if 'content' in res:
+ word = res['content'].split()
+ for token in word:
+ yield token + " "
+ except Exception as e:
+ st.error(f"An error occurred: {e}")
+
+# Generate response when the button is clicked
+if st.button("Generate"):
+ with st.spinner("Running....🐎"):
+ if not question.strip():
+ st.error("Please enter a question.")
+ elif not url.strip() and img_file_buffer is None:
+ st.error("Please provide an image URL or upload an image.")
+ else:
+ st.write_stream(getfinalresponse(question))