|
1 | 1 | # Unit 4: Going Further with Diffusion Models |
2 | 2 |
|
3 | | -Welcome to Unit 4 of the Hugging Face Diffusion Models Course! |
| 3 | +Welcome to Unit 4 of the Hugging Face Diffusion Models Course! In this unit we will look at some of the many improvements and extensions to diffusion models appearing in the latest research. It will be less code-heavy than previous units have been, and is designed to give you a jumping off point for further research and set up for possible additional units in the future. |
4 | 4 |
|
5 | 5 | ## Start this Unit :rocket: |
6 | 6 |
|
7 | 7 | Here are the steps for this unit: |
8 | 8 |
|
9 | | -- Make sure you've [signed up for this course](https://huggingface.us17.list-manage.com/subscribe?u=7f57e683fa28b51bfc493d048&id=ef963b4162) so that you can be notified when new material is released |
| 9 | +- Make sure you've [signed up for this course](https://huggingface.us17.list-manage.com/subscribe?u=7f57e683fa28b51bfc493d048&id=ef963b4162) so that you can be notified when additional units are added to the course |
10 | 10 | - Read through the material below for an overview of the different topics covered in this unit |
11 | 11 | - Dive deeper into any specific topics with the linked videos and resources |
12 | 12 | - Complete the [TODO some sort of exercise/capstone project] |
13 | 13 |
|
14 | | - |
15 | 14 | :loudspeaker: Don't forget to join the [Discord](https://huggingface.co/join/discord), where you can discuss the material and share what you've made in the `#diffusion-models-class` channel. |
16 | 15 |
|
17 | 16 | ## Introduction |
18 | 17 |
|
19 | 18 | By the end of Unit 3... |
20 | 19 |
|
21 | | -Things to cover |
22 | | -- Better Training (different aspect ratios, additional losses) |
23 | | -- Fancier models (MoE, versatile difusion for more conditioning) |
24 | | -- Faster Inference (Distillation) |
25 | | -- Maybe a rundown of specific models (DALL-E 2, Imagen, eDiffi) |
26 | | -- Video |
27 | | -- Audio |
28 | | -- Moving beyond diffusion (MaskGIT/MUSE, Paella and co) |
| 20 | +## Faster Sampling via Distillation |
| 21 | + |
| 22 | +Introduce the idea... The core mechanism is illustrated in this diagram from the [paper that introduced the idea](http://arxiv.org/abs/2202.00512): |
| 23 | + |
| 24 | +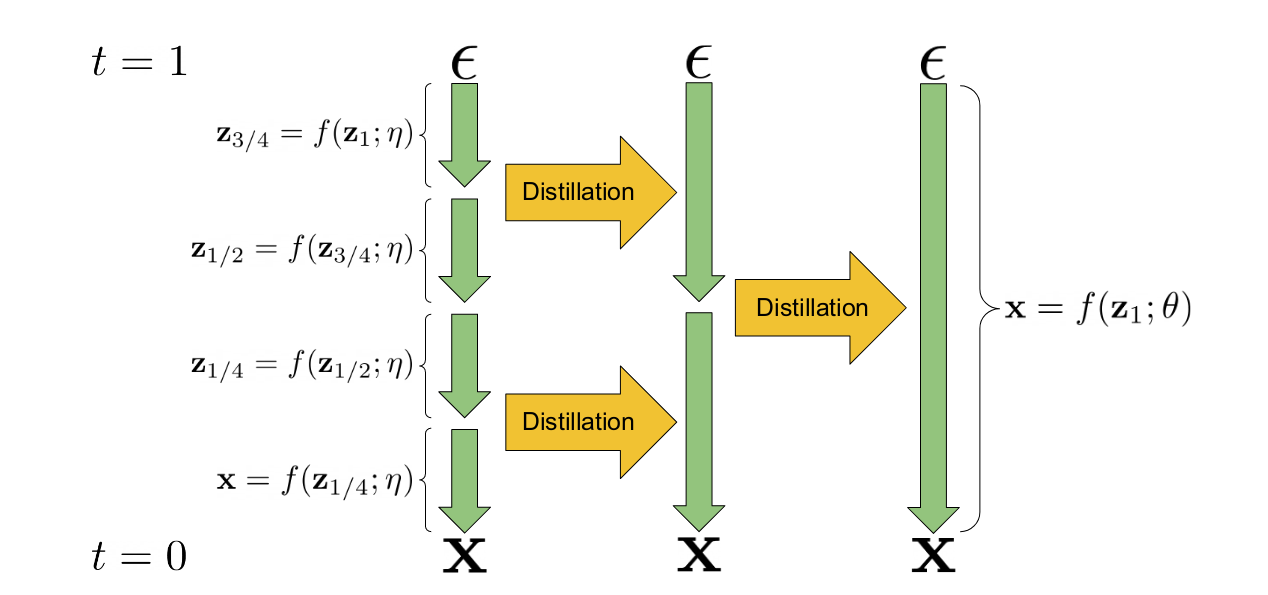 |
| 25 | + |
| 26 | +The idea of using an existing model to 'teach' a new model can be extended to create guided models where the classifier-free guidance technique is used by the teacher model and the student model must learn to produce an equivalent output in a single step based on an additional input specifying the targeted guidance scale. This further reduces the number of model evaluations required to produce high-quality samples. |
| 27 | + |
| 28 | +Key papers: |
| 29 | +- [PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS](http://arxiv.org/abs/2202.00512) |
| 30 | +- [ON DISTILLATION OF GUIDED DIFFUSION MODELS](http://arxiv.org/abs/2210.03142) |
| 31 | + |
| 32 | +## Training Improvements |
| 33 | + |
| 34 | +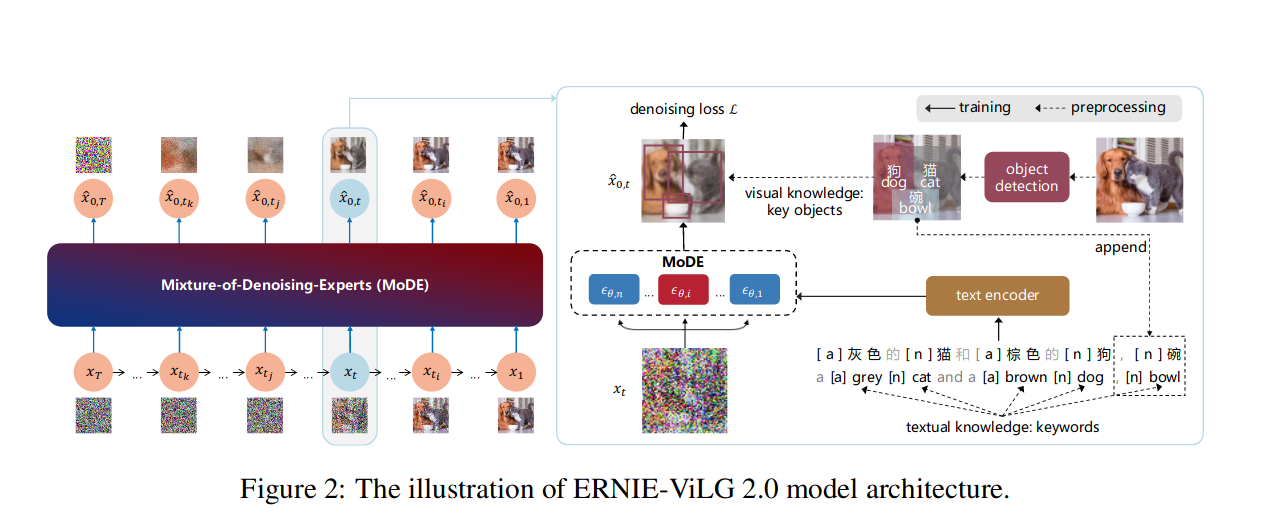 |
| 35 | +_Figure 2 from the [ERNIE-ViLG 2.0 paper](http://arxiv.org/abs/2210.15257)_ |
| 36 | + |
| 37 | +There have been a number of additional tricks developed to improve training. A few key ones are |
| 38 | +- Tuning the noise schedule, loss weighting and sampling trajectories (Karras et al) |
| 39 | +- Training on diverse aspect rations [TODO link patrick's talk from the launch event] |
| 40 | +- Cascading diffusion models, training one model at low resolution and then one or more super-res models (D2, Imagen, eDiffi) |
| 41 | +- Rich text embeddings (Imagen) or multiple types of conditioning (eDiffi) |
| 42 | +- Incorporating pre-trained image captioning and object detection models into the training process to create more informative captions and produce better performance in a process known as 'knowledge enhancement' (ERNIE-ViLG 2.0) |
| 43 | +- MoE training different variants of the model ('experts') for different noise levels... |
| 44 | + |
| 45 | +Key Papers: |
| 46 | +- [Elucidating the Design Space of Diffusion-Based Generative Models](http://arxiv.org/abs/2206.00364) |
| 47 | +- [eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers](http://arxiv.org/abs/2211.01324) |
| 48 | +- [ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts](http://arxiv.org/abs/2210.15257) |
| 49 | +- [Imagen][TODO] |
| 50 | + |
| 51 | +## Inference Improvements |
| 52 | + |
| 53 | +- eDiffi paint with words, |
| 54 | +- Image editing with diffusion models video |
| 55 | +- Textual inversion, null text inversion |
| 56 | +- ?? |
| 57 | + |
| 58 | +## Video |
| 59 | + |
| 60 | +Video diffusion, Imagen Video |
| 61 | + |
| 62 | +Key Papers: |
| 63 | +- [Video Diffusion Models](https://video-diffusion.github.io/) |
| 64 | +- [IMAGEN VIDEO: HIGH DEFINITION VIDEO GENERATION WITH DIFFUSION MODELS](https://imagen.research.google/video/paper.pdf) |
| 65 | + |
| 66 | +## Audio |
| 67 | + |
| 68 | +- Riffusion (and possibly notebook on the idea) |
| 69 | +- Non-spectrogram paper |
| 70 | + |
| 71 | +## New Architectures and Approaches |
| 72 | + |
| 73 | +Transformer in place of UNet (DiT) |
| 74 | + |
| 75 | +Recurrent Interface Networks (https://arxiv.org/pdf/2212.11972.pdf) |
| 76 | + |
| 77 | +MUSE/MaskGIT and Paella |
| 78 | + |
29 | 79 |
|
30 | 80 | ## Project Time |
31 | 81 |
|
|
0 commit comments