 +
+ +
+
+
+
+
+ +
+కోర్సు పూర్తి చేసిన తర్వాత మీరు మరింత ప్రాక్టీస్ చేయాలనుకుంటే, ఫోరమ్లలో [ప్రాజెక్ట్ ఐడియాల](https://discuss.huggingface.co/c/course/course-event/25) జాబితా కూడా అందుబాటులో ఉందని గమనించండి.
+
+- **ఈ కోర్సు కోసం కోడ్ను ఎలా పొందాలి?**
+ ప్రతి విభాగం కోసం, Google Colab లేదా Amazon SageMaker Studio Lab లో కోడ్ను రన్ చేయడానికి పేజీ పైభాగంలో ఉన్న బ్యానర్పై క్లిక్ చేయండి:
+
+
+
+కోర్సు పూర్తి చేసిన తర్వాత మీరు మరింత ప్రాక్టీస్ చేయాలనుకుంటే, ఫోరమ్లలో [ప్రాజెక్ట్ ఐడియాల](https://discuss.huggingface.co/c/course/course-event/25) జాబితా కూడా అందుబాటులో ఉందని గమనించండి.
+
+- **ఈ కోర్సు కోసం కోడ్ను ఎలా పొందాలి?**
+ ప్రతి విభాగం కోసం, Google Colab లేదా Amazon SageMaker Studio Lab లో కోడ్ను రన్ చేయడానికి పేజీ పైభాగంలో ఉన్న బ్యానర్పై క్లిక్ చేయండి:
+
+ +
+కోర్సులోని మొత్తం కోడ్ను కలిగి ఉన్న Jupyter నోట్బుక్లు [`huggingface/notebooks`](https://github.com/huggingface/notebooks) రిపోలో హోస్ట్ చేయబడ్డాయి. మీరు వాటిని స్థానికంగా (locally) రూపొందించాలనుకుంటే, GitHub లోని [`course`](https://github.com/huggingface/course#-jupyter-notebooks) రిపోలోని సూచనలను చూడండి.
+
+- **How can I contribute to the course?**
+ There are many ways to contribute to the course! If you find a typo or a bug, please open an issue on the [`course`](https://github.com/huggingface/course) repo. If you would like to help translate the course into your native language, check out the instructions [here](https://github.com/huggingface/course#translating-the-course-into-your-language).
+
+- **నేను కోర్సుకు ఎలా సహకరించగలను?**
+ కోర్సుకు సహకరించడానికి చాలా మార్గాలు ఉన్నాయి! మీరు ఏదైనా అక్షర దోషం (typo) లేదా బగ్ కనుగొంటే, దయచేసి [`course`](https://github.com/huggingface/course) రిపోలో ఒక ఇష్యూను ఓపెన్ చేయండి. మీరు కోర్సును మీ మాతృభాషలోకి అనువదించడానికి సహాయం చేయాలనుకుంటే, [ఇక్కడ](https://github.com/huggingface/course#translating-the-course-into-your-language) సూచనలను చూడండి.
+
+**ప్రతి అనువాదం కోసం తీసుకున్న నిర్ణయాలు ఏమిటి?**
+ప్రతి అనువాదం కోసం, మేము అనువాదంలో తీసుకున్న నిర్ణయాలను వివరించే ఒక `TRANSLATING.txt` ఫైల్ను కలిగి ఉన్నాము. ఈ ఫైల్లో మేము యంత్ర అభ్యాసం పదజాలం మరియు ఇతర సాంకేతిక పదజాలం కోసం చేసిన ఎంపికలను వివరించాము. ఉదాహరణకు, జర్మన్ కోసం [ఇక్కడ](https://github.com/huggingface/course/blob/main/chapters/de/TRANSLATING.txt) చూడండి.
+
+- **నేను ఈ కోర్సును తిరిగి ఉపయోగించుకోవచ్చా?**
+ తప్పకుండా! ఈ కోర్సు అనుమతి గల Apache 2 license క్రింద విడుదల చేయబడింది. దీని అర్థం మీరు తగిన క్రెడిట్ ఇవ్వాలి, లైసెన్సుకు లింక్ అందించాలి, మరియు ఏవైనా మార్పులు చేసినట్లయితే సూచించాలి. మీరు దీనిని ఏ సహేతుకమైన పద్ధతిలోనైనా చేయవచ్చు, కానీ లైసెన్సర్ మిమ్మల్ని లేదా మీ వినియోగాన్ని ఆమోదించినట్లు సూచించే ఏ విధంగానూ చేయకూడదు. మీరు కోర్సును ఉదహరించాలనుకుంటే, దయచేసి ఈ క్రింది BibTeX ను ఉపయోగించండి:
+
+```
+@misc{huggingfacecourse,
+ author = {Hugging Face},
+ title = {The Hugging Face Course, 2022},
+ howpublished = "\url{https://huggingface.co/course}",
+ year = {2022},
+ note = "[Online; accessed
+
+కోర్సులోని మొత్తం కోడ్ను కలిగి ఉన్న Jupyter నోట్బుక్లు [`huggingface/notebooks`](https://github.com/huggingface/notebooks) రిపోలో హోస్ట్ చేయబడ్డాయి. మీరు వాటిని స్థానికంగా (locally) రూపొందించాలనుకుంటే, GitHub లోని [`course`](https://github.com/huggingface/course#-jupyter-notebooks) రిపోలోని సూచనలను చూడండి.
+
+- **How can I contribute to the course?**
+ There are many ways to contribute to the course! If you find a typo or a bug, please open an issue on the [`course`](https://github.com/huggingface/course) repo. If you would like to help translate the course into your native language, check out the instructions [here](https://github.com/huggingface/course#translating-the-course-into-your-language).
+
+- **నేను కోర్సుకు ఎలా సహకరించగలను?**
+ కోర్సుకు సహకరించడానికి చాలా మార్గాలు ఉన్నాయి! మీరు ఏదైనా అక్షర దోషం (typo) లేదా బగ్ కనుగొంటే, దయచేసి [`course`](https://github.com/huggingface/course) రిపోలో ఒక ఇష్యూను ఓపెన్ చేయండి. మీరు కోర్సును మీ మాతృభాషలోకి అనువదించడానికి సహాయం చేయాలనుకుంటే, [ఇక్కడ](https://github.com/huggingface/course#translating-the-course-into-your-language) సూచనలను చూడండి.
+
+**ప్రతి అనువాదం కోసం తీసుకున్న నిర్ణయాలు ఏమిటి?**
+ప్రతి అనువాదం కోసం, మేము అనువాదంలో తీసుకున్న నిర్ణయాలను వివరించే ఒక `TRANSLATING.txt` ఫైల్ను కలిగి ఉన్నాము. ఈ ఫైల్లో మేము యంత్ర అభ్యాసం పదజాలం మరియు ఇతర సాంకేతిక పదజాలం కోసం చేసిన ఎంపికలను వివరించాము. ఉదాహరణకు, జర్మన్ కోసం [ఇక్కడ](https://github.com/huggingface/course/blob/main/chapters/de/TRANSLATING.txt) చూడండి.
+
+- **నేను ఈ కోర్సును తిరిగి ఉపయోగించుకోవచ్చా?**
+ తప్పకుండా! ఈ కోర్సు అనుమతి గల Apache 2 license క్రింద విడుదల చేయబడింది. దీని అర్థం మీరు తగిన క్రెడిట్ ఇవ్వాలి, లైసెన్సుకు లింక్ అందించాలి, మరియు ఏవైనా మార్పులు చేసినట్లయితే సూచించాలి. మీరు దీనిని ఏ సహేతుకమైన పద్ధతిలోనైనా చేయవచ్చు, కానీ లైసెన్సర్ మిమ్మల్ని లేదా మీ వినియోగాన్ని ఆమోదించినట్లు సూచించే ఏ విధంగానూ చేయకూడదు. మీరు కోర్సును ఉదహరించాలనుకుంటే, దయచేసి ఈ క్రింది BibTeX ను ఉపయోగించండి:
+
+```
+@misc{huggingfacecourse,
+ author = {Hugging Face},
+ title = {The Hugging Face Course, 2022},
+ howpublished = "\url{https://huggingface.co/course}",
+ year = {2022},
+ note = "[Online; accessed  +
+
+
+ +
+[🤗 Transformers లైబ్రరీ](https://github.com/huggingface/transformers) ఆ పంచుకున్న మోడల్స్ను సృష్టించడానికి మరియు ఉపయోగించడానికి ఫంక్షనాలిటీని అందిస్తుంది. [మోడల్ హబ్](https://huggingface.co/models) లో మిలియన్ల కొద్దీ ముందుగా శిక్షణ పొందిన మోడల్స్ ఉన్నాయి, వాటిని ఎవరైనా డౌన్లోడ్ చేసి ఉపయోగించవచ్చు. మీరు మీ స్వంత మోడల్స్ను కూడా హబ్కు అప్లోడ్ చేయవచ్చు!
+
+
+
+[🤗 Transformers లైబ్రరీ](https://github.com/huggingface/transformers) ఆ పంచుకున్న మోడల్స్ను సృష్టించడానికి మరియు ఉపయోగించడానికి ఫంక్షనాలిటీని అందిస్తుంది. [మోడల్ హబ్](https://huggingface.co/models) లో మిలియన్ల కొద్దీ ముందుగా శిక్షణ పొందిన మోడల్స్ ఉన్నాయి, వాటిని ఎవరైనా డౌన్లోడ్ చేసి ఉపయోగించవచ్చు. మీరు మీ స్వంత మోడల్స్ను కూడా హబ్కు అప్లోడ్ చేయవచ్చు!
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
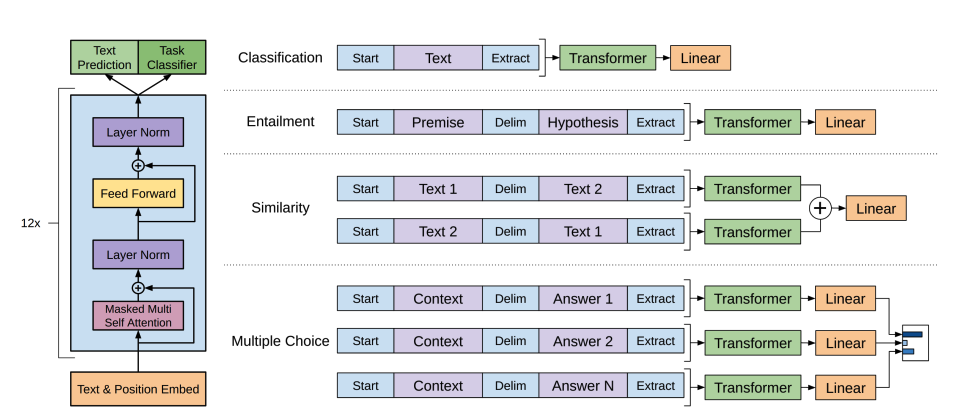
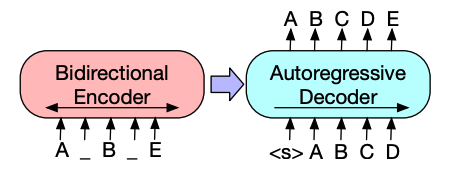
+[CLS])ను ఉపయోగిస్తాయి, రెండూ వాటి ఎంబెడ్డింగ్లకు స్థాన సమాచారాన్ని జోడిస్తాయి, మరియు రెండూ టోకెన్లు/ప్యాచ్ల క్రమాన్ని ప్రాసెస్ చేయడానికి ఒక Transformer ఎన్కోడర్ను ఉపయోగిస్తాయి.
+
+ +
+text-generation పైప్లైన్ అవుతుంది.",
+ },
+ {
+ text: "ఇది వ్యక్తులు, సంస్థలు లేదా ప్రదేశాలను సూచించే పదాలను తిరిగి ఇస్తుంది.",
+ explain: "అంతేకాకుండా, grouped_entities=True తో, ఇది \"Hugging Face\" వంటి ఒకే ఎంటిటీకి చెందిన పదాలను సమూహపరుస్తుంది.",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. ఈ కోడ్ నమూనాలో ... స్థానంలో ఏమి ఉండాలి??
+
+```py
+from transformers import pipeline
+
+filler = pipeline("fill-mask", model="bert-base-cased")
+result = filler("...")
+```
+
+bert-base-cased మోడల్ కార్డును తనిఖీ చేసి మీ పొరపాటును గుర్తించడానికి ప్రయత్నించండి.",
+ },
+ {
+ text: "This [MASK] has been waiting for you.",
+ explain: "ఈ మోడల్ యొక్క మాస్క్ టోకెన్ [MASK].",
+ correct: true,
+ },
+ {
+ text: "This man has been waiting for you.",
+ explain:
+ "ఇది తప్పు. ఈ పైప్లైన్ మాస్క్ చేయబడిన పదాలను నింపుతుంది, కాబట్టి దీనికి ఎక్కడో ఒక మాస్క్ టోకెన్ అవసరం.",
+ },
+ ]}
+/>
+
+### 4. ఈ కోడ్ ఎందుకు విఫలమవుతుంది??
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+result = classifier("This is a course about the Transformers library")
+```
+
+ +
+తదుపరి టోకెన్ను అంచనా వేయడానికి అత్యంత సంబంధిత పదాలను గుర్తించే ఈ ప్రక్రియ అద్భుతంగా ప్రభావవంతమైనదని నిరూపించబడింది. BERT మరియు GPT-2 కాలం నుండి LLMలకు శిక్షణ ఇచ్చే ప్రాథమిక సూత్రం — తదుపరి టోకెన్ను అంచనా వేయడం — సాధారణంగా స్థిరంగా ఉన్నప్పటికీ, న్యూరల్ నెట్వర్క్లను స్కేల్ చేయడంలో మరియు అటెన్షన్ మెకానిజంను తక్కువ ఖర్చుతో, సుదీర్ఘమైన సీక్వెన్స్ల కోసం పనిచేసేలా చేయడంలో గణనీయమైన పురోగతి సాధించబడింది.
+
+
+
+తదుపరి టోకెన్ను అంచనా వేయడానికి అత్యంత సంబంధిత పదాలను గుర్తించే ఈ ప్రక్రియ అద్భుతంగా ప్రభావవంతమైనదని నిరూపించబడింది. BERT మరియు GPT-2 కాలం నుండి LLMలకు శిక్షణ ఇచ్చే ప్రాథమిక సూత్రం — తదుపరి టోకెన్ను అంచనా వేయడం — సాధారణంగా స్థిరంగా ఉన్నప్పటికీ, న్యూరల్ నెట్వర్క్లను స్కేల్ చేయడంలో మరియు అటెన్షన్ మెకానిజంను తక్కువ ఖర్చుతో, సుదీర్ఘమైన సీక్వెన్స్ల కోసం పనిచేసేలా చేయడంలో గణనీయమైన పురోగతి సాధించబడింది.
+
+