diff --git a/chapters/rum/_toctree.yml b/chapters/rum/_toctree.yml
index f25c69af5..7ce8f28cd 100644
--- a/chapters/rum/_toctree.yml
+++ b/chapters/rum/_toctree.yml
@@ -211,3 +211,51 @@
title: Quiz de final de capitol
quiz: 10
+- title: 11. Fine-tuning pentru modele mari de limbaj
+ subtitle: Folosiți fine-tuningul supervizat și adaptarea de rang scăzut pentru a ajusta fin un model mare de limbaj
+ sections:
+ - local: chapter11/1
+ title: Introducere
+ - local: chapter11/2
+ title: Template-uri de chat
+ - local: chapter11/3
+ title: Fine-tuning cu SFTTrainer
+ - local: chapter11/4
+ title: LoRA (Adaptarea de rang scăzut)
+ - local: chapter11/5
+ title: Evaluarea
+ - local: chapter11/6
+ title: Concluzie
+ - local: chapter11/7
+ title: E timpul examenului!
+ quiz: 11
+
+- title: 12. Construiește Modele de Raționament
+ subtitle: Învață cum să construiești modele de raționament precum DeepSeek R1
+ new: true
+ sections:
+ - local: chapter12/1
+ title: Introducere
+ - local: chapter12/2
+ title: Învățarea prin Întărire pe LLM-uri
+ - local: chapter12/3
+ title: Momentul Aha în Lucrarea DeepSeek R1
+ - local: chapter12/3a
+ title: Înțelegerea Avansată a GRPO în DeepSeekMath
+ - local: chapter12/4
+ title: Implementarea GRPO în TRL
+ - local: chapter12/5
+ title: Exercițiu Practic pentru Ajustarea Fină a unui Model cu GRPO
+ - local: chapter12/6
+ title: Exercițiu Practic cu Unsloth
+ - local: chapter12/7
+ title: În curând...
+
+- title: Evenimente Curs
+ sections:
+ - local: events/1
+ title: Sesiuni live și workshop-uri
+ - local: events/2
+ title: Evenimentul de lansare a părții 2
+ - local: events/3
+ title: Petrecerea Gradio Blocks
diff --git a/chapters/rum/chapter11/1.mdx b/chapters/rum/chapter11/1.mdx
new file mode 100644
index 000000000..967010bab
--- /dev/null
+++ b/chapters/rum/chapter11/1.mdx
@@ -0,0 +1,33 @@
+# Fine-tuning supervizat
+
+În [Capitolul 2 Secțiunea 2](/course/chapter2/2), am văzut că modelele de limbaj generativ pot fi ajustate pentru sarcini specifice, cum ar fi rezumarea și răspunsul la întrebări. Cu toate acestea, în zilele noastre este mult mai frecvent să ajustăm modelele de limbaj pe o gamă largă de sarcini simultan; o metodă cunoscută sub numele de fine-tuning supervizat (SFT). Acest proces ajută modelele să devină mai versatile și capabile să gestioneze diverse cazuri de utilizare. Majoritatea LLM-urilor cu care oamenii interacționează pe platforme precum ChatGPT au trecut prin SFT pentru a fi mai utile și aliniate cu preferințele umane. Vom împărți acest capitol în patru secțiuni:
+
+## 1️⃣ Template-uri de chat
+
+Template-urile de chat structurează interacțiunile dintre utilizatori și modelele AI, asigurând răspunsuri consecvente și adecvate contextual. Acestea includ componente precum prompturi de sistem și mesaje bazate pe roluri.
+
+## 2️⃣ Fine-tuning supervizat
+
+Fine-tuningul supervizat (SFT) este un proces critic pentru adaptarea modelelor de limbaj pre-antrenate la sarcini specifice. Aceasta implică antrenarea modelului pe un set de date specific sarcinii cu exemple etichetate. Pentru un ghid detaliat despre SFT, inclusiv pașii cheie și cele mai bune practici, consultați [secțiunea de fine-tuning supervizat din documentația TRL](https://huggingface.co/docs/trl/en/sft_trainer).
+
+## 3️⃣ Adaptarea de rang scăzut (LoRA)
+
+Adaptarea de rang scăzut (LoRA) este o tehnică pentru fine-tuningul modelelor de limbaj prin adăugarea de matrice de rang scăzut la straturile modelului. Aceasta permite un fine-tuning eficient păstrând în același timp cunoștințele pre-antrenate ale modelului. Unul dintre beneficiile cheie ale LoRA este economia semnificativă de memorie pe care o oferă, făcând posibilă ajustarea modelelor mari pe hardware cu resurse limitate.
+
+## 4️⃣ Evaluarea
+
+Evaluarea este un pas crucial în procesul de fine-tuning. Ne permite să măsurăm performanța modelului pe un set de date specific sarcinii.
+
+
+⚠️ Pentru a beneficia de toate funcționalitățile disponibile cu Model Hub și 🤗 Transformers, recomandăm crearea unui cont.
+
+
+## Referințe
+
+- [Documentația Transformers despre template-urile de chat](https://huggingface.co/docs/transformers/main/en/chat_templating)
+- [Script pentru fine-tuning supervizat în TRL](https://github.com/huggingface/trl/blob/main/trl/scripts/sft.py)
+- [`SFTTrainer` în TRL](https://huggingface.co/docs/trl/main/en/sft_trainer)
+- [Lucrarea despre optimizarea directă a preferințelor](https://arxiv.org/abs/2305.18290)
+- [Fine-tuning supervizat cu TRL](https://huggingface.co/docs/trl/sft_trainer)
+- [Cum să faceți fine-tuning la Google Gemma cu ChatML și Hugging Face TRL](https://github.com/huggingface/alignment-handbook)
+- [Fine-tuning LLM pentru a genera cataloage de produse persane în format JSON](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/2.mdx b/chapters/rum/chapter11/2.mdx
new file mode 100644
index 000000000..b5fe8d46a
--- /dev/null
+++ b/chapters/rum/chapter11/2.mdx
@@ -0,0 +1,253 @@
+
+
+# Template-uri de chat
+
+## Introducere
+
+Template-urile de chat sunt esențiale pentru structurarea interacțiunilor dintre modelele de limbaj și utilizatori. Indiferent dacă construiți un chatbot simplu sau un agent AI complex, înțelegerea modului de a formata corect conversațiile este crucială pentru a obține cele mai bune rezultate de la modelul dumneavoastră. În acest ghid, vom explora ce sunt template-urile de chat, de ce sunt importante și cum să le folosiți eficient.
+
+
+Template-urile de chat sunt cruciale pentru:
+- Menținerea unei structuri consecvente de conversație
+- Asigurarea identificării corecte a rolurilor
+- Gestionarea contextului pe mai multe tururi
+- Suportarea funcționalităților avansate precum utilizarea instrumentelor
+
+
+## Tipuri de modele și template-uri
+
+### Modele de bază versus modele instruct
+Un model de bază este antrenat pe date text brute pentru a prezice următorul token, în timp ce un model instruct este ajustat specific pentru a urma instrucțiuni și a se angaja în conversații. De exemplu, [`SmolLM2-135M`](https://huggingface.co/HuggingFaceTB/SmolLM2-135M) este un model de bază, în timp ce [`SmolLM2-135M-Instruct`](https://huggingface.co/HuggingFaceTB/SmolLM2-135M-Instruct) este varianta sa ajustată pentru instrucțiuni.
+
+Modelele ajustate pentru instrucțiuni sunt antrenate să urmeze o structură conversațională specifică, făcându-le mai potrivite pentru aplicații de chatbot. Mai mult, modelele instruct pot gestiona interacțiuni complexe, inclusiv utilizarea instrumentelor, intrări multimodale și apeluri de funcții.
+
+Pentru a face ca un model de bază să se comporte ca un model instruct, trebuie să formatăm prompturile într-un mod consecvent pe care modelul să îl înțeleagă. Aici intervin template-urile de chat. ChatML este unul dintre aceste formate de template care structurează conversațiile cu indicatori clari de rol (sistem, utilizator, asistent). Iată un ghid despre [ChatML](https://huggingface.co/HuggingFaceTB/SmolLM2-135M-Instruct/blob/e2c3f7557efbdec707ae3a336371d169783f1da1/tokenizer_config.json#L146).
+
+
+Când folosiți un model instruct, verificați întotdeauna că folosiți formatul corect de template de chat. Folosirea unui template greșit poate duce la performanțe slabe ale modelului sau comportament neașteptat. Cea mai ușoară modalitate de a vă asigura de acest lucru este să verificați configurația tokenizer-ului modelului pe Hub. De exemplu, modelul `SmolLM2-135M-Instruct` folosește această configurație.
+
+
+### Formate comune de template
+
+Înainte de a aprofunda implementări specifice, este important să înțelegem cum diferite modele se așteaptă ca conversațiile lor să fie formatate. Să explorăm câteva formate comune de template folosind un exemplu simplu de conversație:
+
+Vom folosi următoarea structură de conversație pentru toate exemplele:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Hello!"},
+ {"role": "assistant", "content": "Hi! How can I help you today?"},
+ {"role": "user", "content": "What's the weather?"},
+]
+```
+
+Acesta este template-ul ChatML folosit în modele precum SmolLM2 și Qwen 2:
+
+```sh
+<|im_start|>system
+You are a helpful assistant.<|im_end|>
+<|im_start|>user
+Hello!<|im_end|>
+<|im_start|>assistant
+Hi! How can I help you today?<|im_end|>
+<|im_start|>user
+What's the weather?<|im_start|>assistant
+```
+
+Acesta folosește formatul de template `mistral`:
+
+```sh
+[INST] You are a helpful assistant. [/INST]
+Hi! How can I help you today?
+[INST] Hello! [/INST]
+```
+
+Diferențele cheie între aceste formate includ:
+1. **Gestionarea mesajelor de sistem**:
+ - Llama 2 înfășoară mesajele de sistem în etichete `<>`
+ - Llama 3 folosește etichete `<|system|>` cu încheierea ``
+ - Mistral include mesajul de sistem în prima instrucțiune
+ - Qwen folosește rolul explicit `system` cu etichete `<|im_start|>`
+ - ChatGPT folosește prefixul `SYSTEM:`
+
+2. **Granițele mesajelor**:
+ - Llama 2 folosește etichete `[INST]` și `[/INST]`
+ - Llama 3 folosește etichete specifice rolurilor (`<|system|>`, `<|user|>`, `<|assistant|>`) cu încheierea ``
+ - Mistral folosește `[INST]` și `[/INST]` cu `` și ``
+ - Qwen folosește token-uri de start/sfârșit specifice rolurilor
+
+3. **Token-uri speciale**:
+ - Llama 2 folosește `` și `` pentru granițele conversației
+ - Llama 3 folosește `` pentru a încheia fiecare mesaj
+ - Mistral folosește `` și `` pentru granițele turului
+ - Qwen folosește token-uri de start/sfârșit specifice rolurilor
+
+Înțelegerea acestor diferențe este cheia pentru a lucra cu modele variate. Să vedem cum biblioteca transformers ne ajută să gestionăm aceste variații automat:
+
+```python
+from transformers import AutoTokenizer
+
+# Acestea vor folosi template-uri diferite automat
+mistral_tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
+qwen_tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat")
+smol_tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
+
+messages = [
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Hello!"},
+]
+
+# Fiecare va formata conform template-ului modelului său
+mistral_chat = mistral_tokenizer.apply_chat_template(messages, tokenize=False)
+qwen_chat = qwen_tokenizer.apply_chat_template(messages, tokenize=False)
+smol_chat = smol_tokenizer.apply_chat_template(messages, tokenize=False)
+```
+
+
+Faceți clic pentru a vedea exemplele de template
+
+Template ChatML pentru Qwen 2 și SmolLM2:
+
+```sh
+<|im_start|>system
+You are a helpful assistant.<|im_end|>
+<|im_start|>user
+Hello!<|im_end|>
+<|im_start|>assistant
+Hi! How can I help you today?<|im_end|>
+<|im_start|>user
+What's the weather?<|im_start|>assistant
+```
+
+Template Mistral:
+
+```sh
+[INST] You are a helpful assistant. [/INST]
+Hi! How can I help you today?
+[INST] Hello! [/INST]
+```
+
+
+
+### Funcționalități avansate
+Template-urile de chat pot gestiona scenarii mai complexe dincolo de simpla interacțiune conversațională, inclusiv:
+
+1. **Utilizarea instrumentelor**: Când modelele trebuie să interacționeze cu instrumente externe sau API-uri
+2. **Intrări multimodale**: Pentru gestionarea imaginilor, audio sau alte tipuri de media
+3. **Apeluri de funcții**: Pentru executarea structurată de funcții
+4. **Context multi-turn**: Pentru menținerea istoricului conversației
+
+
+Când implementați funcționalități avansate:
+- Testați temeinic cu modelul dumneavoastră specific. Template-urile de viziune și utilizare a instrumentelor sunt deosebit de diverse.
+- Monitorizați cu atenție utilizarea token-urilor între fiecare funcționalitate și model.
+- Documentați formatul așteptat pentru fiecare funcționalitate
+
+
+Pentru conversații multimodale, template-urile de chat pot include referințe la imagini sau imagini codificate în base64:
+
+```python
+messages = [
+ {
+ "role": "system",
+ "content": "You are a helpful vision assistant that can analyze images.",
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What's in this image?"},
+ {"type": "image", "image_url": "https://example.com/image.jpg"},
+ ],
+ },
+]
+```
+
+Iată un exemplu de template de chat cu utilizarea instrumentelor:
+
+```python
+messages = [
+ {
+ "role": "system",
+ "content": "You are an AI assistant that can use tools. Available tools: calculator, weather_api",
+ },
+ {"role": "user", "content": "What's 123 * 456 and is it raining in Paris?"},
+ {
+ "role": "assistant",
+ "content": "Let me help you with that.",
+ "tool_calls": [
+ {
+ "tool": "calculator",
+ "parameters": {"operation": "multiply", "x": 123, "y": 456},
+ },
+ {"tool": "weather_api", "parameters": {"city": "Paris", "country": "France"}},
+ ],
+ },
+ {"role": "tool", "tool_name": "calculator", "content": "56088"},
+ {
+ "role": "tool",
+ "tool_name": "weather_api",
+ "content": "{'condition': 'rain', 'temperature': 15}",
+ },
+]
+```
+
+## Cele mai bune practici
+
+### Ghiduri generale
+Când lucrați cu template-uri de chat, urmați aceste practici cheie:
+
+1. **Formatare consecventă**: Folosiți întotdeauna același format de template în toată aplicația
+2. **Definirea clară a rolurilor**: Specificați clar rolurile (sistem, utilizator, asistent, instrument) pentru fiecare mesaj
+3. **Gestionarea contextului**: Fiți atenți la limitele token-urilor când mențineți istoricul conversației
+4. **Gestionarea erorilor**: Includeți gestionarea adecvată a erorilor pentru apelurile de instrumente și intrările multimodale
+5. **Validare**: Validați structura mesajelor înainte de a le trimite la model
+
+
+Capcane comune de evitat:
+- Amestecarea diferitelor formate de template în aceeași aplicație
+- Depășirea limitelor de token-uri cu istoricuri lungi de conversație
+- Neescaparea corespunzătoare a caracterelor speciale în mesaje
+- Uitarea validării structurii mesajelor de intrare
+- Ignorarea cerințelor specifice de template ale modelului
+
+
+## Exercițiu practic
+
+Să exersăm implementarea template-urilor de chat cu un exemplu din lumea reală.
+
+
+Urmați acești pași pentru a converti setul de date `HuggingFaceTB/smoltalk` în formatul chatml:
+
+1. Încărcați setul de date:
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("HuggingFaceTB/smoltalk")
+```
+
+2. Creați o funcție de procesare:
+```python
+def convert_to_chatml(example):
+ return {
+ "messages": [
+ {"role": "user", "content": example["input"]},
+ {"role": "assistant", "content": example["output"]},
+ ]
+ }
+```
+
+3. Aplicați template-ul de chat folosind tokenizer-ul modelului ales
+
+Amintiți-vă să validați că formatul de ieșire se potrivește cu cerințele modelului țintă!
+
+
+## Resurse adiționale
+
+- [Ghidul Hugging Face pentru template-uri de chat](https://huggingface.co/docs/transformers/main/en/chat_templating)
+- [Documentația Transformers](https://huggingface.co/docs/transformers)
+- [Depozitul de exemple pentru template-uri de chat](https://github.com/chujiezheng/chat_templates)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/3.mdx b/chapters/rum/chapter11/3.mdx
new file mode 100644
index 000000000..1d9f924a2
--- /dev/null
+++ b/chapters/rum/chapter11/3.mdx
@@ -0,0 +1,384 @@
+
+
+# Fine-tuning supervizat
+
+Fine-tuningul supervizat (SFT) este un proces folosit în principal pentru a adapta modelele de limbaj pre-antrenate să urmeze instrucțiuni, să se angajeze în dialog și să folosească formate specifice de ieșire. În timp ce modelele pre-antrenate au capacități generale impresionante, SFT ajută la transformarea lor în modele asemănătoare asistentului care pot înțelege și răspunde mai bine la prompturile utilizatorilor. Acest lucru se realizează de obicei prin antrenare pe seturi de date cu conversații și instrucțiuni scrise de oameni.
+
+Această pagină oferă un ghid pas cu pas pentru fine-tuningul modelului [`deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B`](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) folosind [`SFTTrainer`](https://huggingface.co/docs/trl/en/sft_trainer). Urmând acești pași, puteți adapta modelul să îndeplinească anumite sarcini mai eficient.
+
+## Când să utilizați SFT
+
+Înainte de a se adânci în implementare, este important să înțelegem când SFT este alegerea potrivită pentru proiectul dumneavoastră. Ca primul pas, ar trebui să considerați dacă folosirea unui model existent ajustat pentru instrucțiuni cu prompturi bine elaborate ar fi suficientă pentru cazul dumneavoastră de utilizare. SFT implică resurse computaționale semnificative și efort de inginerie, așa că ar trebui urmărit doar când promptarea modelelor existente se dovedește insuficientă.
+
+
+Considerați SFT doar dacă:
+- Aveți nevoie de performanțe suplimentare dincolo de ceea ce poate realiza promptarea
+- Aveți un caz de utilizare specific în care costul folosirii unui model mare de uz general depășește costul fine-tuningului unui model mai mic
+- Aveți nevoie de formate de ieșire specializate sau cunoștințe specifice domeniului cu care modelele existente se confruntă
+
+
+Dacă determinați că SFT este necesar, decizia de a continua depinde de doi factori principali:
+
+### Controlul template-ului
+SFT permite control precis asupra structurii de ieșire a modelului. Acest lucru este deosebit de valoros când aveți nevoie ca modelul să:
+1. Genereze răspunsuri într-un format specific de template de chat
+2. Urmeze scheme stricte de ieșire
+3. Mențină stiluri consecvente în toate răspunsurile
+
+### Adaptarea la domeniu
+Când lucrați în domenii specializate, SFT ajută la alinierea modelului cu cerințele specifice domeniului prin:
+1. Predarea terminologiei și conceptelor domeniului
+2. Impunerea standardelor profesionale
+3. Gestionarea adecvată a întrebărilor tehnice
+4. Urmarea ghidurilor specifice industriei
+
+
+Înainte de a începe SFT, evaluați dacă cazul dumneavoastră de utilizare necesită:
+- Formatare precisă de ieșire
+- Cunoștințe specifice domeniului
+- Modele consecvente de răspuns
+- Aderarea la ghiduri specifice
+
+Această evaluare va ajuta să determinați dacă SFT este abordarea potrivită pentru nevoile dumneavoastră.
+
+
+## Pregătirea setului de date
+
+Procesul de fine-tuning supervizat necesită un set de date specific sarcinii structurat cu perechi intrare-ieșire. Fiecare pereche ar trebui să conțină:
+1. Un prompt de intrare
+2. Răspunsul așteptat al modelului
+3. Orice context sau metadate suplimentare
+
+Calitatea datelor de antrenare este crucială pentru succesul fine-tuningului. Să vedem cum să pregătim și să validăm setul de date:
+
+
+
+## Configurația antrenamentului
+
+Succesul fine-tuningului depinde în mare măsură de alegerea parametrilor de antrenare corecți. Să explorăm fiecare parametru important și cum să îi configurați eficient:
+
+Configurația SFTTrainer necesită considerarea mai multor parametri care controlează procesul de antrenare. Să explorăm fiecare parametru și scopul lor:
+
+1. **Parametrii duratei antrenamentului**:
+ - `num_train_epochs`: Controlează durata totală a antrenamentului
+ - `max_steps`: Alternativă la epoci, stabilește numărul maxim de pași de antrenare
+ - Mai multe epoci permit învățare mai bună dar riscă supraadaptarea
+
+2. **Parametrii dimensiunii batch-ului**:
+ - `per_device_train_batch_size`: Determină utilizarea memoriei și stabilitatea antrenamentului
+ - `gradient_accumulation_steps`: Permite dimensiuni efective mai mari ale batch-ului
+ - Batch-uri mai mari oferă gradienți mai stabili dar necesită mai multă memorie
+
+3. **Parametrii ratei de învățare**:
+ - `learning_rate`: Controlează dimensiunea actualizărilor greutăților
+ - `warmup_ratio`: Porțiunea de antrenament folosită pentru încălzirea ratei de învățare
+ - Prea mare poate cauza instabilitate, prea mică rezultă în învățare lentă
+
+4. **Parametrii de monitorizare**:
+ - `logging_steps`: Frecvența înregistrării metricilor
+ - `eval_steps`: Cât de des să evalueze pe datele de validare
+ - `save_steps`: Frecvența salvării punctelor de verificare ale modelului
+
+
+Începeți cu valori conservatoare și ajustați bazat pe monitorizare:
+- Începeți cu 1-3 epoci
+- Folosiți dimensiuni mai mici ale batch-ului inițial
+- Monitorizați metricile de validare atent
+- Ajustați rata de învățare dacă antrenamentul este instabil
+
+
+## Implementare cu TRL
+
+Acum că înțelegem componentele cheie, să implementăm antrenamentul cu validare și monitorizare adecvate. Vom folosi clasa `SFTTrainer` din biblioteca Transformers Reinforcement Learning (TRL), care este construită pe biblioteca `transformers`. Iată un exemplu complet folosind biblioteca TRL:
+
+```python
+from datasets import load_dataset
+from trl import SFTConfig, SFTTrainer
+import torch
+
+# Setați dispozitivul
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+# Încărcați setul de date
+dataset = load_dataset("HuggingFaceTB/smoltalk", "all")
+
+# Configurați modelul și tokenizer-ul
+model_name = "HuggingFaceTB/SmolLM2-135M"
+model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path=model_name).to(
+ device
+)
+tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=model_name)
+# Configurați template-ul de chat
+model, tokenizer = setup_chat_format(model=model, tokenizer=tokenizer)
+
+# Configurați trainer-ul
+training_args = SFTConfig(
+ output_dir="./sft_output",
+ max_steps=1000,
+ per_device_train_batch_size=4,
+ learning_rate=5e-5,
+ logging_steps=10,
+ save_steps=100,
+ eval_strategy="steps",
+ eval_steps=50,
+)
+
+# Inițializați trainer-ul
+trainer = SFTTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ processing_class=tokenizer,
+)
+
+# Începeți antrenamentul
+trainer.train()
+```
+
+
+Când folosiți un set de date cu un câmp "messages" (ca exemplul de mai sus), SFTTrainer aplică automat template-ul de chat al modelului, pe care îl recuperează de pe hub. Aceasta înseamnă că nu aveți nevoie de nicio configurație suplimentară pentru a gestiona conversațiile în stil chat - trainer-ul va formata mesajele conform formatului de template așteptat al modelului.
+
+
+## Împachetarea setului de date
+
+SFTTrainer suportă împachetarea exemplelor pentru a optimiza eficiența antrenamentului. Această funcționalitate permite ca mai multe exemple scurte să fie împachetate în aceeași secvență de intrare, maximizând utilizarea GPU în timpul antrenamentului. Pentru a activa împachetarea, pur și simplu setați `packing=True` în constructorul SFTConfig. Când folosiți seturi de date împachetate cu `max_steps`, fiți conștienți că s-ar putea să antrenați pentru mai multe epoci decât ați așteptat, în funcție de configurația de împachetare. Puteți personaliza modul în care exemplele sunt combinate folosind o funcție de formatare - deosebit de utilă când lucrați cu seturi de date care au mai multe câmpuri precum perechi întrebare-răspuns. Pentru seturile de date de evaluare, puteți dezactiva împachetarea setând `eval_packing=False` în SFTConfig. Iată un exemplu de bază de personalizare a configurației de împachetare:
+
+```python
+# Configurați împachetarea
+training_args = SFTConfig(packing=True)
+
+trainer = SFTTrainer(model=model, train_dataset=dataset, args=training_args)
+
+trainer.train()
+```
+
+Când împachetați setul de date cu mai multe câmpuri, puteți defini o funcție de formatare personalizată pentru a combina câmpurile într-o singură secvență de intrare. Această funcție ar trebui să ia o listă de exemple și să returneze un dicționar cu secvența de intrare împachetată. Iată un exemplu de funcție de formatare personalizată:
+
+```python
+def formatting_func(example):
+ text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
+ return text
+
+
+training_args = SFTConfig(packing=True)
+trainer = SFTTrainer(
+ "facebook/opt-350m",
+ train_dataset=dataset,
+ args=training_args,
+ formatting_func=formatting_func,
+)
+```
+
+## Monitorizarea progresului antrenamentului
+
+Monitorizarea eficientă este crucială pentru succesul fine-tuningului. Să explorăm ce să urmărim în timpul antrenamentului:
+
+### Înțelegerea modelelor de pierdere
+
+Pierderea antrenamentului urmează de obicei trei faze distincte:
+1. Scădere abruptă inițială: Adaptare rapidă la noua distribuție de date
+2. Stabilizare graduală: Rata de învățare încetinește pe măsură ce modelul se ajustează fin
+3. Convergența: Valorile pierderilor se stabilizează, indicând finalizarea antrenamentului
+
+ +
+### Metrici de monitorizat
+
+Monitorizarea eficientă implică urmărirea metricilor cantitative și evaluarea metricilor calitative. Metricile disponibile sunt:
+
+- Pierderea antrenamentului
+- Pierderea validării
+- Progresia ratei de învățare
+- Normele gradientului
+
+
+Urmăriți aceste semne de avertizare în timpul antrenamentului:
+1. Pierderea validării crește în timp ce pierderea antrenamentului scade (supraadaptare)
+2. Nicio îmbunătățire semnificativă în valorile pierderilor (subadaptare)
+3. Valori extrem de mici ale pierderilor (posibilă memorizare)
+4. Formatare inconsistentă a ieșirii (probleme de învățare a template-ului)
+
+
+### Calea către convergență
+
+Pe măsură ce antrenamentul progresează, curba pierderii ar trebui să se stabilizeze treptat. Indicatorul cheie al antrenamentului sănătos este un decalaj mic între pierderea antrenamentului și cea de validare, sugerând că modelul învață modele generalizabile mai degrabă decât să memoreze exemple specifice. Valorile absolute ale pierderilor vor varia în funcție de sarcina și setul de date.
+
+### Monitorizarea progresului antrenamentului
+
+Graficul de mai sus arată o progresie tipică a antrenamentului. Observați cum atât pierderea antrenamentului, cât și cea de validare scad brusc la început, apoi se nivelează treptat. Acest model indică faptul că modelul învață eficient menținând în același timp capacitatea de generalizare.
+
+### Semne de avertizare de urmărit
+
+Mai multe modele în curbele pierderilor pot indica probleme potențiale. Mai jos ilustrăm semne comune de avertizare și soluții pe care le putem considera.
+
+
+
+### Metrici de monitorizat
+
+Monitorizarea eficientă implică urmărirea metricilor cantitative și evaluarea metricilor calitative. Metricile disponibile sunt:
+
+- Pierderea antrenamentului
+- Pierderea validării
+- Progresia ratei de învățare
+- Normele gradientului
+
+
+Urmăriți aceste semne de avertizare în timpul antrenamentului:
+1. Pierderea validării crește în timp ce pierderea antrenamentului scade (supraadaptare)
+2. Nicio îmbunătățire semnificativă în valorile pierderilor (subadaptare)
+3. Valori extrem de mici ale pierderilor (posibilă memorizare)
+4. Formatare inconsistentă a ieșirii (probleme de învățare a template-ului)
+
+
+### Calea către convergență
+
+Pe măsură ce antrenamentul progresează, curba pierderii ar trebui să se stabilizeze treptat. Indicatorul cheie al antrenamentului sănătos este un decalaj mic între pierderea antrenamentului și cea de validare, sugerând că modelul învață modele generalizabile mai degrabă decât să memoreze exemple specifice. Valorile absolute ale pierderilor vor varia în funcție de sarcina și setul de date.
+
+### Monitorizarea progresului antrenamentului
+
+Graficul de mai sus arată o progresie tipică a antrenamentului. Observați cum atât pierderea antrenamentului, cât și cea de validare scad brusc la început, apoi se nivelează treptat. Acest model indică faptul că modelul învață eficient menținând în același timp capacitatea de generalizare.
+
+### Semne de avertizare de urmărit
+
+Mai multe modele în curbele pierderilor pot indica probleme potențiale. Mai jos ilustrăm semne comune de avertizare și soluții pe care le putem considera.
+
+ +
+Dacă pierderea validării scade cu o rată semnificativ mai lentă decât pierderea antrenamentului, modelul probabil se supraadaptează la datele de antrenare. Considerați:
+- Reducerea pașilor de antrenare
+- Creșterea dimensiunii setului de date
+- Validarea calității și diversității setului de date
+
+
+
+Dacă pierderea validării scade cu o rată semnificativ mai lentă decât pierderea antrenamentului, modelul probabil se supraadaptează la datele de antrenare. Considerați:
+- Reducerea pașilor de antrenare
+- Creșterea dimensiunii setului de date
+- Validarea calității și diversității setului de date
+
+ +
+Dacă pierderea nu arată îmbunătățiri semnificative, modelul ar putea să:
+- Învețe prea încet (încercați să creșteți rata de învățare)
+- Se confrunte cu sarcina (verificați calitatea datelor și complexitatea sarcinii)
+- Atingă limitările arhitecturii (considerați un model diferit)
+
+
+
+Dacă pierderea nu arată îmbunătățiri semnificative, modelul ar putea să:
+- Învețe prea încet (încercați să creșteți rata de învățare)
+- Se confrunte cu sarcina (verificați calitatea datelor și complexitatea sarcinii)
+- Atingă limitările arhitecturii (considerați un model diferit)
+
+ +
+Valori extrem de mici ale pierderilor ar putea sugera memorizare mai degrabă decât învățare. Acest lucru este deosebit de îngrijorător dacă:
+- Modelul performează slab pe exemple noi, similare
+- Ieșirile lipsesc de diversitate
+- Răspunsurile sunt prea similare cu exemplele de antrenare
+
+
+Monitorizați atât valorile pierderilor, cât și ieșirile efective ale modelului în timpul antrenamentului. Uneori pierderea poate arăta bine în timp ce modelul dezvoltă comportamente nedorite. Evaluarea calitativă regulată a răspunsurilor modelului ajută la detectarea problemelor pe care metricile singure le-ar putea rata.
+
+
+Ar trebui să observăm că interpretarea valorilor pierderilor pe care o descriem aici este destinată cazului cel mai comun, și de fapt, valorile pierderilor se pot comporta în moduri diferite în funcție de model, setul de date, parametrii de antrenare, etc. Dacă sunteți interesați să explorați mai multe despre modelele descrise, ar trebui să consultați acest articol de blog de la oamenii de la [Fast AI](https://www.fast.ai/posts/2023-09-04-learning-jumps/).
+
+## Evaluarea după SFT
+
+În secțiunea [11.4](/en/chapter11/4) vom învăța cum să evaluăm modelul folosind seturi de date de referință. Pentru moment, ne vom concentra pe evaluarea calitativă a modelului.
+
+După finalizarea SFT, considerați aceste acțiuni de urmărire:
+
+1. Evaluați modelul temeinic pe datele de test păstrate deoparte
+2. Validați aderarea la template pe diverse intrări
+3. Testați reținerea cunoștințelor specifice domeniului
+4. Monitorizați metricile de performanță din lumea reală
+
+
+Documentați procesul de antrenare, inclusiv:
+- Caracteristicile setului de date
+- Parametrii antrenamentului
+- Metricile de performanță
+- Limitările cunoscute
+Această documentație va fi valoroasă pentru iterațiile viitoare ale modelului.
+
+
+## Chestionar
+
+### 1. Ce parametri controlează durata antrenamentului în SFT?
+
+
+
+### 2. Ce model în curbele pierderilor indică supraadaptarea potențială?
+
+
+
+### 3. Pentru ce este folosit gradient_accumulation_steps?
+
+
+
+### 4. Ce ar trebui să monitorizați în timpul antrenamentului SFT?
+
+
+
+### 5. Ce indică convergența sănătoasă în timpul antrenamentului?
+
+
+
+## 💐 Bună treabă!
+
+Ați învățat cum să faceți fine-tuning la modele folosind SFT! Pentru a continua învățarea:
+1. Încercați notebook-ul cu parametri diferiți
+2. Experimentați cu alte seturi de date
+3. Contribuiți cu îmbunătățiri la materialul cursului
+
+## Resurse adiționale
+
+- [Documentația TRL](https://huggingface.co/docs/trl)
+- [Depozitul de exemple SFT](https://github.com/huggingface/trl/blob/main/trl/scripts/sft.py)
+- [Cele mai bune practici pentru fine-tuning](https://huggingface.co/docs/transformers/training)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/4.mdx b/chapters/rum/chapter11/4.mdx
new file mode 100644
index 000000000..f243b94e3
--- /dev/null
+++ b/chapters/rum/chapter11/4.mdx
@@ -0,0 +1,171 @@
+
+
+# LoRA (Adaptarea de rang scăzut)
+
+Fine-tuningul modelelor mari de limbaj este un proces intensiv în resurse. LoRA este o tehnică care ne permite să facem fine-tuning la modele mari de limbaj cu un număr mic de parametri. Funcționează prin adăugarea și optimizarea unor matrice mai mici la greutățile atenției, reducând de obicei parametrii antrenabili cu aproximativ 90%.
+
+## Înțelegerea LoRA
+
+LoRA (Adaptarea de rang scăzut) este o tehnică de fine-tuning eficientă din punct de vedere al parametrilor care îngheață greutățile modelului pre-antrenat și injectează matrice de descompunere de rang antrenabile în straturile modelului. În loc să antreneze toți parametrii modelului în timpul fine-tuningului, LoRA descompune actualizările greutăților în matrice mai mici prin descompunere de rang scăzut, reducând semnificativ numărul de parametri antrenabili menținând în același timp performanța modelului. De exemplu, când este aplicat la GPT-3 175B, LoRA a redus parametrii antrenabili de 10.000 de ori și cerințele de memorie GPU de 3 ori comparativ cu fine-tuningul complet. Puteți citi mai multe despre LoRA în [lucrarea LoRA](https://arxiv.org/pdf/2106.09685).
+
+LoRA funcționează prin adăugarea de perechi de matrice de descompunere de rang la straturile transformer, concentrându-se de obicei pe greutățile atenției. În timpul inferenței, aceste greutăți ale adaptorului pot fi îmbinate cu modelul de bază, rezultând în nicio latență suplimentară. LoRA este deosebit de util pentru adaptarea modelelor mari de limbaj la sarcini sau domenii specifice menținând în același timp cerințele de resurse gestionabile.
+
+## Avantajele cheie ale LoRA
+
+1. **Eficiența memoriei**:
+ - Doar parametrii adaptorului sunt stocați în memoria GPU
+ - Greutățile modelului de bază rămân înghețate și pot fi încărcate la precizie mai mică
+ - Permite fine-tuningul modelelor mari pe GPU-uri de consum
+
+2. **Caracteristici de antrenare**:
+ - Integrare nativă PEFT/LoRA cu configurare minimă
+ - Suport pentru QLoRA (LoRA cuantificat) pentru eficiență de memorie și mai bună
+
+3. **Gestionarea adaptorului**:
+ - Salvarea greutăților adaptorului în timpul punctelor de verificare
+ - Funcționalități pentru îmbinarea adaptorilor înapoi în modelul de bază
+
+## Încărcarea adaptorilor LoRA cu PEFT
+
+[PEFT](https://github.com/huggingface/peft) este o bibliotecă care oferă o interfață unificată pentru încărcarea și gestionarea metodelor PEFT, inclusiv LoRA. Vă permite să încărcați și să comutați cu ușurință între diferite metode PEFT, făcând mai ușor să experimentați cu diferite tehnici de fine-tuning.
+
+Adaptorii pot fi încărcați pe un model pre-antrenat cu `load_adapter()`, care este util pentru a încerca adaptori diferiți ale căror greutăți nu sunt îmbinate. Setați greutățile adaptorului activ cu funcția `set_adapter()`. Pentru a reveni la modelul de bază, ați putea folosi unload() pentru a descărca toate modulele LoRA. Acest lucru face ușor să comutați între greutăți specifice sarcinilor diferite.
+
+```python
+from peft import PeftModel, PeftConfig
+
+config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
+model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
+lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora")
+```
+
+
+
+## Fine-tuning LLM folosind `trl` și `SFTTrainer` cu LoRA
+
+[SFTTrainer](https://huggingface.co/docs/trl/sft_trainer) din `trl` oferă integrare cu adaptorii LoRA prin biblioteca [PEFT](https://huggingface.co/docs/peft/en/index). Aceasta înseamnă că putem face fine-tuning la un model în același mod ca și cu SFT, dar folosim LoRA pentru a reduce numărul de parametri pe care trebuie să îi antrenăm.
+
+Vom folosi clasa `LoRAConfig` din PEFT în exemplul nostru. Configurarea necesită doar câțiva pași de configurare:
+
+1. Definiți configurația LoRA (rang, alfa, dropout)
+2. Creați SFTTrainer cu configurația PEFT
+3. Antrenați și salvați greutățile adaptorului
+
+## Configurația LoRA
+
+Să parcurgem configurația LoRA și parametrii cheie.
+
+| Parametru | Descriere |
+|-----------|-----------|
+| `r` (rang) | Dimensiunea matricelor de rang scăzut folosite pentru actualizările greutăților. De obicei între 4-32. Valori mai mici oferă mai multă compresie dar potențial mai puțină expresivitate. |
+| `lora_alpha` | Factor de scalare pentru straturile LoRA, de obicei setat la 2x valoarea rangului. Valori mai mari rezultă în efecte de adaptare mai puternice. |
+| `lora_dropout` | Probabilitatea dropout pentru straturile LoRA, de obicei 0.05-0.1. Valori mai mari ajută la prevenirea supraadaptării în timpul antrenamentului. |
+| `bias` | Controlează antrenarea termenilor de bias. Opțiunile sunt "none", "all" sau "lora_only". "none" este cel mai comun pentru eficiența memoriei. |
+| `target_modules` | Specifică la care module ale modelului să aplice LoRA. Poate fi "all-linear" sau module specifice precum "q_proj,v_proj". Mai multe module permit o adaptabilitate mai mare dar cresc utilizarea memoriei. |
+
+
+Când implementați metode PEFT, începeți cu valori mici ale rangului (4-8) pentru LoRA și monitorizați pierderea antrenamentului. Folosiți seturi de validare pentru a preveni supraadaptarea și comparați rezultatele cu liniile de bază de fine-tuning complet când este posibil. Eficacitatea diferitelor metode poate varia în funcție de sarcină, așa că experimentarea este cheia.
+
+
+## Folosirea TRL cu PEFT
+
+Metodele PEFT pot fi combinate cu TRL pentru fine-tuning pentru a reduce cerințele de memorie. Putem trece `LoraConfig` la model când îl încărcăm.
+
+```python
+from peft import LoraConfig
+
+# TODO: Configurați parametrii LoRA
+# r: dimensiunea rangului pentru matricele de actualizare LoRA (mai mică = mai multă compresie)
+rank_dimension = 6
+# lora_alpha: factor de scalare pentru straturile LoRA (mai mare = adaptare mai puternică)
+lora_alpha = 8
+# lora_dropout: probabilitatea dropout pentru straturile LoRA (ajută la prevenirea supraadaptării)
+lora_dropout = 0.05
+
+peft_config = LoraConfig(
+ r=rank_dimension, # Dimensiunea rangului - de obicei între 4-32
+ lora_alpha=lora_alpha, # Factor de scalare LoRA - de obicei 2x rangul
+ lora_dropout=lora_dropout, # Probabilitatea dropout pentru straturile LoRA
+ bias="none", # Tipul bias pentru LoRA. bias-urile corespunzătoare vor fi actualizate în timpul antrenamentului.
+ target_modules="all-linear", # La care module să aplice LoRA
+ task_type="CAUSAL_LM", # Tipul sarcinii pentru arhitectura modelului
+)
+```
+
+Mai sus, am folosit `device_map="auto"` pentru a atribui automat modelul la dispozitivul corect. De asemenea, puteți atribui manual modelul la un dispozitiv specific folosind `device_map={"": device_index}`.
+
+Vom avea nevoie, de asemenea, să definim `SFTTrainer` cu configurația LoRA.
+
+```python
+# Creați SFTTrainer cu configurația LoRA
+trainer = SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=dataset["train"],
+ peft_config=peft_config, # Configurația LoRA
+ max_seq_length=max_seq_length, # Lungimea maximă a secvenței
+ processing_class=tokenizer,
+)
+```
+
+
+
+✏️ **Încercați!** Construiți pe modelul dumneavoastră ajustat fin din secțiunea anterioară, dar faceți fine-tuning cu LoRA. Folosiți setul de date `HuggingFaceTB/smoltalk` pentru a face fine-tuning la un model `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B`, folosind configurația LoRA pe care am definit-o mai sus.
+
+
+
+## Îmbinarea adaptorilor LoRA
+
+După antrenarea cu LoRA, s-ar putea să doriți să îmbinați greutățile adaptorului înapoi în modelul de bază pentru implementare mai ușoară. Aceasta creează un singur model cu greutățile combinate, eliminând necesitatea de a încărca adaptorii separat în timpul inferenței.
+
+Procesul de îmbinare necesită atenție la gestionarea memoriei și precizie. Deoarece va trebui să încărcați atât modelul de bază, cât și greutățile adaptorului simultan, asigurați-vă că există memorie GPU/CPU suficientă disponibilă. Folosirea `device_map="auto"` în `transformers` va găsi dispozitivul corect pentru model bazat pe hardware-ul dumneavoastră.
+
+Mențineți precizia consistentă (de ex. float16) pe tot parcursul procesului, potrivind precizia folosită în timpul antrenamentului și salvând modelul îmbinat în același format pentru implementare.
+
+## Implementarea îmbinării
+
+După antrenarea unui adaptor LoRA, puteți îmbina greutățile adaptorului înapoi în modelul de bază. Iată cum să faceți acest lucru:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM
+from peft import PeftModel
+
+# 1. Încărcați modelul de bază
+base_model = AutoModelForCausalLM.from_pretrained(
+ "base_model_name", torch_dtype=torch.float16, device_map="auto"
+)
+
+# 2. Încărcați modelul PEFT cu adaptorul
+peft_model = PeftModel.from_pretrained(
+ base_model, "path/to/adapter", torch_dtype=torch.float16
+)
+
+# 3. Îmbinați greutățile adaptorului cu modelul de bază
+merged_model = peft_model.merge_and_unload()
+```
+
+Dacă întâmpinați discrepanțe de dimensiune în modelul salvat, asigurați-vă că salvați și tokenizer-ul:
+
+```python
+# Salvați atât modelul, cât și tokenizer-ul
+tokenizer = AutoTokenizer.from_pretrained("base_model_name")
+merged_model.save_pretrained("path/to/save/merged_model")
+tokenizer.save_pretrained("path/to/save/merged_model")
+```
+
+
+
+✏️ **Încercați!** Îmbinați greutățile adaptorului înapoi în modelul de bază. Folosiți setul de date `HuggingFaceTB/smoltalk` pentru a face fine-tuning la un model `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B`, folosind configurația LoRA pe care am definit-o mai sus.
+
+
+
+# Resurse
+
+- [LoRA: Adaptarea de rang scăzut a modelelor mari de limbaj](https://arxiv.org/pdf/2106.09685)
+- [Documentația PEFT](https://huggingface.co/docs/peft)
+- [Articolul de blog Hugging Face despre PEFT](https://huggingface.co/blog/peft)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/5.mdx b/chapters/rum/chapter11/5.mdx
new file mode 100644
index 000000000..61ca3c867
--- /dev/null
+++ b/chapters/rum/chapter11/5.mdx
@@ -0,0 +1,254 @@
+# Evaluarea
+
+Cu un model ajustat fin prin SFT sau LoRA SFT, ar trebui să îl evaluăm pe criterii de referință standard. Ca ingineri de machine learning, ar trebui să mențineți o suită de evaluări relevante pentru domeniul dumneavoastră țintă de interes. În această pagină, vom privi la unele dintre criteriile de referință cele mai comune și cum să le folosiți pentru a evalua modelul dumneavoastră. De asemenea, vom vedea cum să creați criterii de referință personalizate pentru cazul specific de utilizare.
+
+## Criterii de referință automate
+
+Criteriile de referință automate servesc ca instrumente standardizate pentru evaluarea modelelor de limbaj pe diferite sarcini și capacități. În timp ce acestea oferă un punct de plecare util pentru înțelegerea performanței modelului, este important să recunoaștem că reprezintă doar o piesă dintr-o strategie de evaluare cuprinzătoare.
+
+## Înțelegerea criteriilor de referință automate
+
+Criteriile de referință automate constau de obicei din seturi de date curate cu sarcini și metrici de evaluare predefinite. Aceste criterii de referință au ca scop să evalueze diverse aspecte ale capacității modelului, de la înțelegerea de bază a limbajului la raționament complex. Avantajul cheie al folosirii criteriilor de referință automate este standardizarea lor - permit compararea consistentă între modele diferite și oferă rezultate reproductibile.
+
+Cu toate acestea, este crucial să înțelegem că performanța la criterii de referință nu se traduce întotdeauna direct în eficacitate din lumea reală. Un model care excelează la criterii de referință academice poate totuși să se confrunte cu aplicații de domeniu specifice sau cazuri de utilizare practice.
+
+## Criterii de referință pentru cunoștințe generale
+
+[MMLU](https://huggingface.co/datasets/cais/mmlu) (Massive Multitask Language Understanding) testează cunoștințele pe 57 de subiecte, de la știință la științe umane. Deși cuprinzător, poate să nu reflecte profunzimea expertizei necesare pentru domenii specifice. TruthfulQA evaluează tendința unui model de a reproduce concepții greșite comune, deși nu poate captura toate formele de dezinformare.
+
+## Criterii de referință pentru raționament
+
+[BBH](https://huggingface.co/datasets/lukaemon/bbh) (Big Bench Hard) și [GSM8K](https://huggingface.co/datasets/openai/gsm8k) se concentrează pe sarcini de raționament complex. BBH testează gândirea logică și planificarea, în timp ce GSM8K vizează specific rezolvarea problemelor matematice. Aceste criterii de referință ajută la evaluarea capacităților analitice dar pot să nu captureze raționamentul nuanțat necesar în scenarii din lumea reală.
+
+## Înțelegerea limbajului
+
+[HELM](https://github.com/stanford-crfm/helm) oferă un cadru de evaluare holistic. Criterii de referință precum HELM oferă perspective asupra capacităților de procesare a limbajului pe aspecte precum bunul simț, cunoștințele despre lume și raționamentul. Dar pot să nu reprezinte complet complexitatea conversației naturale sau terminologia specifică domeniului.
+
+## Criterii de referință specifice domeniului
+
+Să ne uităm la câteva criterii de referință care se concentrează pe domenii specifice precum matematica, codarea și chatul.
+
+[Criteriul de referință MATH](https://huggingface.co/papers/2103.03874) este un alt instrument important de evaluare pentru raționamentul matematic. Constă din 12.500 de probleme din competiții de matematică, acoperind algebra, geometria, teoria numerelor, numărarea, probabilitatea și altele. Ceea ce face MATH deosebit de provocator este că necesită raționament în mai mulți pași, înțelegerea notației matematice formale și capacitatea de a genera soluții pas cu pas. Spre deosebire de sarcinile aritmetice mai simple, problemele MATH necesită adesea strategii sofisticate de rezolvare a problemelor și aplicații de concepte matematice.
+
+[Criteriul de referință HumanEval](https://github.com/openai/human-eval) este un set de date de evaluare axat pe codare format din 164 de probleme de programare. Criteriul de referință testează capacitatea unui model de a genera cod Python funcțional corect care rezolvă sarcinile de programare date. Ceea ce face HumanEval deosebit de valoros este că evaluează atât capacitățile de generare de cod, cât și corectitudinea funcțională prin executarea efectivă a cazurilor de test, mai degrabă decât doar similaritatea superficială cu soluțiile de referință. Problemele variază de la manipularea de bază a șirurilor la algoritmi și structuri de date mai complexe.
+
+[Alpaca Eval](https://tatsu-lab.github.io/alpaca_eval/) este un cadru de evaluare automatizat conceput pentru a evalua calitatea modelelor de limbaj care urmează instrucțiuni. Folosește GPT-4 ca judecător pentru a evalua ieșirile modelului pe diverse dimensiuni, inclusiv utilitatea, onestitatea și inofensivitatea. Cadrul include un set de date cu 805 de prompturi atent curate și poate evalua răspunsurile față de modele multiple de referință precum Claude, GPT-4 și altele. Ceea ce face Alpaca Eval deosebit de util este capacitatea sa de a oferi evaluări consistente, scalabile fără a necesita adnotatori umani, în timp ce încă capturează aspecte nuanțate ale performanței modelului pe care metricile tradiționale le-ar putea rata.
+
+## Abordări alternative de evaluare
+
+Multe organizații au dezvoltat metode alternative de evaluare pentru a aborda limitările criteriilor de referință standard:
+
+### LLM-ca-judecător
+
+Folosirea unui model de limbaj pentru a evalua ieșirile altuia a devenit din ce în ce mai populară. Această abordare poate oferi feedback mai nuanțat decât metricile tradiționale, deși vine cu propriile sale prejudecăți și limitări.
+
+### Arene de evaluare
+
+Arenele de evaluare precum [Chatbot Arena](https://lmarena.ai/) oferă o abordare unică pentru evaluarea LLM prin feedback crowdsourced. În aceste platforme, utilizatorii se angajează în "bătălii" anonime între două LLM-uri, punând întrebări și votând care model oferă răspunsuri mai bune. Această abordare capturează modelele de utilizare și preferințele din lumea reală prin întrebări diverse, provocatoare, cu studii care arată acord puternic între voturile crowdsourced și evaluările experților. Deși puternice, aceste platforme au limitări, inclusiv prejudecăți potențiale ale bazei de utilizatori, distribuții distorsionate ale prompturilor și o concentrare principală pe utilitate mai degrabă decât pe considerațiile de siguranță.
+
+### Suite de criterii de referință personalizate
+
+Organizațiile dezvoltă adesea suite interne de criterii de referință adaptate nevoilor și cazurilor lor specifice de utilizare. Acestea ar putea include teste de cunoștințe specifice domeniului sau scenarii de evaluare care reflectă condițiile reale de implementare.
+
+## Evaluare personalizată
+
+În timp ce criteriile de referință standard oferă o linie de bază utilă, nu ar trebui să fie singura metodă de evaluare. Iată cum să dezvoltați o abordare mai cuprinzătoare:
+
+1. Începeți cu criterii de referință standard relevante pentru a stabili o linie de bază și a permite comparația cu alte modele.
+
+2. Identificați cerințele și provocările specifice ale cazului dumneavoastră de utilizare. Ce sarcini va îndeplini efectiv modelul? Ce tipuri de erori ar fi cele mai problematice?
+
+3. Dezvoltați seturi de date de evaluare personalizate care reflectă cazul real de utilizare. Aceasta ar putea include:
+ - Întrebări reale ale utilizatorilor din domeniul dumneavoastră
+ - Cazuri comune de margine pe care le-ați întâlnit
+ - Exemple de scenarii deosebit de provocatoare
+
+4. Considerați implementarea unei strategii de evaluare pe mai multe niveluri:
+ - Metrici automate pentru feedback rapid
+ - Evaluare umană pentru înțelegere nuanțată
+ - Revizuire de experți de domeniu pentru aplicații specializate
+ - Testare A/B în medii controlate
+
+## Implementarea evaluărilor personalizate
+
+În această secțiune, vom implementa evaluarea pentru modelul nostru ajustat fin. Putem folosi [`lighteval`](https://github.com/huggingface/lighteval) pentru a evalua modelul nostru ajustat fin pe criterii de referință standard, care conține o gamă largă de sarcini încorporate în bibliotecă. Trebuie doar să definim sarcinile pe care dorim să le evaluăm și parametrii pentru evaluare.
+
+Sarcinile LightEval sunt definite folosind un format specific:
+
+```
+{suite}|{task}|{num_few_shot}|{auto_reduce}
+```
+
+| Parametru | Descriere |
+|-----------|-----------|
+| `suite` | Suita de criterii de referință (de ex., 'mmlu', 'truthfulqa') |
+| `task` | Sarcina specifică din suită (de ex., 'abstract_algebra') |
+| `num_few_shot` | Numărul de exemple de inclus în prompt (0 pentru zero-shot) |
+| `auto_reduce` | Dacă să reducă automat exemplele few-shot dacă promptul este prea lung (0 sau 1) |
+
+Exemplu: `"mmlu|abstract_algebra|0|0"` evaluează pe sarcina de algebră abstractă MMLU cu inferență zero-shot.
+
+## Exemplu de pipeline de evaluare
+
+Să configurăm un pipeline de evaluare pentru modelul nostru ajustat fin. Vom evalua modelul pe un set de sub-sarcini care se raportează la domeniul medicinei.
+
+Iată un exemplu complet de evaluare pe criterii de referință automate relevante pentru un domeniu specific folosind Lighteval cu backend-ul VLLM:
+
+```bash
+lighteval accelerate \
+ "pretrained=your-model-name" \
+ "mmlu|anatomy|0|0" \
+ "mmlu|high_school_biology|0|0" \
+ "mmlu|high_school_chemistry|0|0" \
+ "mmlu|professional_medicine|0|0" \
+ --max_samples 40 \
+ --batch_size 1 \
+ --output_path "./results" \
+ --save_generations true
+```
+
+Rezultatele sunt afișate în format tabular arătând:
+
+```
+| Task |Version|Metric|Value | |Stderr|
+|----------------------------------------|------:|------|-----:|---|-----:|
+|all | |acc |0.3333|± |0.1169|
+|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
+|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
+|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
+```
+
+Lighteval include, de asemenea, un API Python pentru sarcini de evaluare mai detaliate, care este util pentru manipularea rezultatelor într-un mod mai flexibil. Consultați [documentația Lighteval](https://huggingface.co/docs/lighteval/using-the-python-api) pentru mai multe informații.
+
+
+
+✏️ **Încercați!** Evaluați modelul dumneavoastră ajustat fin pe o sarcină specifică în lighteval.
+
+
+
+# Chestionar de sfârșit de capitol[[end-of-chapter-quiz]]
+
+
+
+### 1. Care sunt principalele avantaje ale folosirii criteriilor de referință automate pentru evaluarea modelului?
+
+
+
+### 2. Care criteriu de referință testează specific cunoștințele pe 57 de subiecte diferite?
+
+
+
+### 3. Ce este LLM-ca-judecător?
+
+
+
+### 4. Ce ar trebui inclus într-o strategie de evaluare cuprinzătoare?
+
+
+
+### 5. Care este o limitare a criteriilor de referință automate?
+
+
+
+### 6. Care este scopul creării seturilor de date de evaluare personalizate?
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter11/6.mdx b/chapters/rum/chapter11/6.mdx
new file mode 100644
index 000000000..89356375e
--- /dev/null
+++ b/chapters/rum/chapter11/6.mdx
@@ -0,0 +1,13 @@
+# Concluzie
+
+În acest capitol, am explorat componentele esențiale ale fine-tuningului modelelor de limbaj:
+
+1. **Template-urile de chat** oferă structură interacțiunilor cu modelul, asigurând răspunsuri consecvente și adecvate prin formatare standardizată.
+
+2. **Fine-tuningul supervizat (SFT)** permite adaptarea modelelor pre-antrenate la sarcini specifice menținând în același timp cunoștințele lor fundamentale.
+
+3. **LoRA** oferă o abordare eficientă pentru fine-tuning prin reducerea parametrilor antrenabili păstrând în același timp performanța modelului.
+
+4. **Evaluarea** ajută la măsurarea și validarea eficacității fine-tuningului prin diverse metrici și criterii de referință.
+
+Aceste tehnici, când sunt combinate, permit crearea de modele specializate de limbaj care pot excela în sarcini specifice rămânând în același timp eficiente din punct de vedere computațional. Indiferent dacă construiți un bot de servicii pentru clienți sau un asistent specific domeniului, înțelegerea acestor concepte este crucială pentru adaptarea cu succes a modelului.
\ No newline at end of file
diff --git a/chapters/rum/chapter11/7.mdx b/chapters/rum/chapter11/7.mdx
new file mode 100644
index 000000000..2ef2c530e
--- /dev/null
+++ b/chapters/rum/chapter11/7.mdx
@@ -0,0 +1,31 @@
+# E timpul examenului!
+
+E timpul să vă puneți cunoștințele la încercare! Am pregătit un scurt chestionar pentru a vă testa înțelegerea conceptelor abordate în acest capitol.
+
+Pentru a face chestionarul, va trebui să urmați acești pași:
+
+1. Conectați-vă la contul dumneavoastră Hugging Face.
+2. Răspundeți la întrebările din chestionar.
+3. Trimiteți răspunsurile dumneavoastră.
+
+## Chestionar cu alegere multiplă
+
+În acest chestionar, vi se va cere să selectați răspunsul corect dintr-o listă de opțiuni. Vă vom testa pe elementele fundamentale ale fine-tuningului supervizat.
+
+
+
+## Chestionar de cod
+
+În acest chestionar, vi se va cere să scrieți cod pentru a completa o sarcină. Vă vom testa pe codul pe care l-ați studiat în curs din biblioteci precum `datasets`, `transformers`, `peft` și `TRL`.
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter12/1.mdx b/chapters/rum/chapter12/1.mdx
new file mode 100644
index 000000000..4dbae17fa
--- /dev/null
+++ b/chapters/rum/chapter12/1.mdx
@@ -0,0 +1,93 @@
+# Open R1 pentru Studenți
+
+Bun venit într-o călătorie captivantă în lumea AI-ului open-source cu învățarea prin întărire! Acest capitol este conceput pentru a ajuta studenții să înțeleagă învățarea prin întărire și rolul acesteia în LLM-uri.
+
+De asemenea, vom explora [Open R1](https://github.com/huggingface/open-r1), un proiect comunitar revoluționar care face AI-ul avansat accesibil pentru toată lumea. În mod specific, acest curs este pentru a ajuta studenții și cursanții să folosească și să contribuie la [Open R1](https://github.com/huggingface/open-r1).
+
+## Ce Vei Învăța
+
+În acest capitol, vom descompune concepte complexe în părți ușor de înțeles și îți vom arăta cum poți fi parte din acest proiect captivant de a face LLM-urile să raționeze asupra problemelor complexe.
+
+LLM-urile au demonstrat performanțe excelente pe multe sarcini generative. Cu toate acestea, până recent, au avut dificultăți cu problemele complexe care necesită raționament. De exemplu, le este greu să se descurce cu puzzle-uri sau probleme de matematică care necesită mai mulți pași de raționament.
+
+Open R1 este un proiect care își propune să facă LLM-urile să raționeze asupra problemelor complexe. Face acest lucru folosind învățarea prin întărire pentru a încuraja LLM-urile să 'gândească' și să raționeze.
+
+În termeni simpli, modelul este antrenat să genereze gânduri precum și rezultate, și să structureze aceste gânduri și rezultate astfel încât să poată fi gestionate separat de către utilizator.
+
+Să aruncăm o privire la un exemplu. Dacă ne-am dat nouă înșine sarcina de a rezolva următoarea problemă, am putea gândi astfel:
+
+```sh
+Problemă: "Am 3 mere și 2 portocale. Câte bucăți de fructe am în total?"
+
+Gând: "Trebuie să adun numărul de mere și portocale pentru a obține numărul total de bucăți de fructe."
+
+Răspuns: "5"
+```
+
+Putem apoi să structurăm acest gând și răspuns astfel încât să poată fi gestionate separat de către utilizator. Pentru sarcinile de raționament, LLM-urile pot fi antrenate să genereze gânduri și răspunsuri în următorul format:
+
+```sh
+Trebuie să adun numărul de mere și portocale pentru a obține numărul total de bucăți de fructe.
+5
+```
+
+Ca utilizator, putem apoi să extragem gândul și răspunsul din rezultatul modelului și să le folosim pentru a rezolva problema.
+
+## De Ce Este Important Pentru Studenți
+
+Ca student, înțelegerea Open R1 și a rolului învățării prin întărire în LLM-uri este valoroasă pentru că:
+- Îți arată cum se dezvoltă AI-ul de ultimă generație
+- Îți oferă oportunități practice de a învăța și contribui
+- Te ajută să înțelegi înspre unde se îndreaptă tehnologia AI
+- Îți deschide uși către viitoare oportunități de carieră în AI
+
+## Prezentarea Capitolului
+
+Acest capitol este împărțit în patru secțiuni, fiecare concentrându-se pe un aspect diferit al Open R1:
+
+### 1️⃣ Introducere în Învățarea prin Întărire și rolul acesteia în LLM-uri
+Vom explora elementele de bază ale Învățării prin Întărire (RL) și rolul acesteia în antrenarea LLM-urilor.
+- Ce este RL?
+- Cum este folosit RL în LLM-uri?
+- Ce este DeepSeek R1?
+- Care sunt inovațiile cheie ale DeepSeek R1?
+
+### 2️⃣ Înțelegerea Lucrării DeepSeek R1
+Vom descompune lucrarea de cercetare care a inspirat [Open R1](https://huggingface.co/open-r1):
+- Inovații și descoperiri cheie
+- Procesul de antrenare și arhitectura
+- Rezultate și semnificația lor
+
+### 3️⃣ Implementarea GRPO în TRL
+Vom deveni practici cu exemple de cod:
+- Cum să folosești biblioteca Transformer Reinforcement Learning (TRL)
+- Configurarea antrenamentului GRPO
+
+### 4️⃣ Caz de utilizare practic pentru alinierea unui model
+Vom privi un caz de utilizare practic pentru alinierea unui model folosind Open R1.
+- Cum să antrenezi un model folosind GRPO în TRL
+- Să-ți partajezi modelul pe [Hugging Face Hub](https://huggingface.co/models)
+
+## Cerințe Prealabile
+
+Pentru a obține cel mai mult din acest capitol, este util să ai:
+- Înțelegere solidă a programării Python
+- Familiaritate cu conceptele de machine learning
+- Interes pentru AI și modelele de limbaj
+
+Nu-ți face griji dacă îți lipsesc unele dintre acestea – vom explica conceptele cheie pe măsură ce mergem! 🚀
+
+
+
+Dacă nu ai toate cerințele prealabile, consultă acest [curs](/course/chapter1/1) de la unitățile 1 la 11
+
+
+
+## Cum să Folosești Acest Capitol
+
+1. **Citește Secvențial**: Secțiunile se construiesc una pe alta, așa că este mai bine să le citești în ordine
+2. **Partajează Notițe**: Scrie conceptele cheie și întrebările și discută-le cu comunitatea în [Discord](https://discord.gg/F3vZujJH)
+3. **Încearcă Codul**: Când ajungem la exemplele practice, încearcă-le singur
+4. **Alătură-te Comunității**: Folosește resursele pe care le oferim pentru a te conecta cu alți cursanți
+
+Să începem explorarea Open R1 și să descoperim cum poți fi parte din a face AI-ul mai accesibil pentru toată lumea! 🚀
\ No newline at end of file
diff --git a/chapters/rum/chapter12/2.mdx b/chapters/rum/chapter12/2.mdx
new file mode 100644
index 000000000..fc76264eb
--- /dev/null
+++ b/chapters/rum/chapter12/2.mdx
@@ -0,0 +1,245 @@
+# Introducere în Învățarea prin Întărire și rolul acesteia în LLM-uri
+
+Bun venit la prima pagină!
+
+Vom începe călătoria noastră în lumea captivantă a Învățării prin Întărire (RL) și vom descoperi cum aceasta revoluționează modul în care antrenăm Modelele de Limbaj precum cele pe care le-ai putea folosi în fiecare zi.
+
+
+
+În acest capitol, ne concentrăm pe învățarea prin întărire pentru modelele de limbaj. Cu toate acestea, învățarea prin întărire este un domeniu larg cu multe aplicații dincolo de modelele de limbaj. Dacă ești interesat să înveți mai multe despre învățarea prin întărire, ar trebui să consulți [Cursul de Învățare prin Întărire Profundă](https://huggingface.co/courses/deep-rl-course/en/unit1/introduction).
+
+
+
+Această pagină îți va oferi o introducere prietenoasă și clară în RL, chiar dacă nu ai întâlnit-o niciodată înainte. Vom descompune ideile principale și vom vedea de ce RL devine atât de important în domeniul Modelelor Mari de Limbaj (LLM-uri).
+
+## Ce este Învățarea prin Întărire (RL)?
+
+Imaginează-ți că antrenezi un câine. Vrei să-l înveți să stea. Ai putea spune "Stai!" și apoi, dacă câinele stă, îi dai o recompensă și îl lauzi. Dacă nu stă, ai putea să-l ghidezi blând sau doar să încerci din nou. De-a lungul timpului, câinele învață să asocieze statul cu recompensa pozitivă (recompensa și lauda) și este mai probabil să stea când spui "Stai!" din nou. În învățarea prin întărire, ne referim la acest feedback ca **recompensă**.
+
+Aceasta, pe scurt, este ideea de bază din spatele Învățării prin Întărire! În loc de un câine, avem un **model de limbaj** (în învățarea prin întărire, îl numim **agent**), și în loc de tine, avem **mediul** care oferă feedback.
+
+
+
+Să descompunem elementele cheie ale RL:
+
+### Agent
+
+Acesta este cel care învață. În exemplul cu câinele, câinele este agentul. În contextul LLM-urilor, LLM-ul însuși devine agentul pe care vrem să-l antrenăm. Agentul este cel care ia decizii și învață din mediu și din recompensele sale.
+
+### Mediu
+
+Acesta este lumea în care trăiește și interacționează agentul. Pentru câine, mediul este casa ta și tu. Pentru un LLM, mediul este puțin mai abstract – ar putea fi utilizatorii cu care interacționează, sau un scenariu simulat pe care îl configurăm pentru el. Mediul oferă feedback agentului.
+
+### Acțiune
+
+Acestea sunt alegerile pe care agentul le poate face în mediu. Acțiunile câinelui sunt lucruri precum "stai", "ridică-te", "latră", etc. Pentru un LLM, acțiunile ar putea fi generarea de cuvinte într-o propoziție, alegerea ce răspuns să dea la o întrebare, sau deciderea cum să răspundă într-o conversație.
+
+### Recompensă
+
+Acesta este feedback-ul pe care mediul îl oferă agentului după ce acesta întreprinde o acțiune. Recompensele sunt de obicei numere.
+
+**Recompensele pozitive** sunt ca recompensele și laudele – îi spun agentului "bună treabă, ai făcut ceva corect!".
+
+**Recompensele negative** (sau penalitățile) sunt ca un "nu" blând – îi spun agentului "nu a fost tocmai corect, încearcă altceva". Pentru câine, recompensa este răsplata.
+
+Pentru un LLM, recompensele sunt concepute să reflecte cât de bine se descurcă LLM-ul la o sarcină specifică – poate fi cât de util, adevărat sau inofensiv este răspunsul său.
+
+### Politică
+
+Aceasta este strategia agentului pentru alegerea acțiunilor. Este ca înțelegerea câinelui despre ce ar trebui să facă când spui "Stai!". În RL, politica este ceea ce încercăm cu adevărat să învățăm și să îmbunătățim. Este un set de reguli sau o funcție care îi spune agentului ce acțiune să întreprindă în diferite situații. Inițial, politica ar putea fi aleatorie, dar pe măsură ce agentul învață, politica devine mai bună la alegerea acțiunilor care duc la recompense mai mari.
+
+## Procesul RL: Încercări și Erori
+
+
+
+Învățarea prin Întărire se întâmplă printr-un proces de încercări și erori:
+
+| Pas | Proces | Descriere |
+|------|---------|-------------|
+| 1. Observație | Agentul observă mediul | Agentul preia informații despre starea sa actuală și împrejurimile |
+| 2. Acțiune | Agentul întreprinde o acțiune bazată pe politica sa actuală | Folosind strategia sa învățată (politica), agentul decide ce să facă în continuare |
+| 3. Feedback | Mediul îi oferă agentului o recompensă | Agentul primește feedback despre cât de bună sau rea a fost acțiunea sa |
+| 4. Învățare | Agentul își actualizează politica bazată pe recompensă | Agentul își ajustează strategia - întărind acțiunile care au dus la recompense mari și evitând pe cele care au dus la recompense mici |
+| 5. Iterație | Repetă procesul | Acest ciclu continuă, permițând agentului să-și îmbunătățească continuu luarea deciziilor |
+
+Gândește-te la învățarea mersului pe bicicletă. Ai putea să te legeni și să cazi la început (recompensă negativă!). Dar când reușești să te echilibrezi și să pedalezi lin, te simți bine (recompensă pozitivă!). Îți ajustezi acțiunile bazat pe acest feedback – înclinându-te puțin, pedalând mai repede, etc. – până când înveți să mergi bine. RL este similar – se referă la învățarea prin interacțiune și feedback.
+
+## Rolul RL în Modelele Mari de Limbaj (LLM-uri)
+
+Acum, de ce este RL atât de important pentru Modelele Mari de Limbaj?
+
+Ei bine, antrenarea LLM-urilor cu adevărat bune este complicată. Le putem antrena pe cantități masive de text de pe internet, și devin foarte bune la prezicerea următorului cuvânt într-o propoziție. Astfel învață să genereze text fluent și corect din punct de vedere gramatical, după cum am învățat în [capitolul 2](/course/chapter2/1).
+
+Cu toate acestea, a fi doar fluent nu este suficient. Vrem ca LLM-urile noastre să fie mai mult decât bune la înșiruirea cuvintelor. Vrem ca ele să fie:
+
+* **Utile:** Să ofere informații utile și relevante.
+* **Inofensive:** Să evite generarea de conținut toxic, părtinitor sau dăunător.
+* **Aliniate cu Preferințele Umane:** Să răspundă în moduri pe care oamenii le găsesc naturale, utile și captivante.
+
+Metodele de pre-antrenare LLM, care se bazează în principal pe prezicerea următorului cuvânt din datele text, uneori nu reușesc în aceste aspecte.
+
+În timp ce antrenamentul supervizat este excelent la producerea de rezultate structurate, poate fi mai puțin eficient la producerea de răspunsuri utile, inofensive și aliniate. Explorăm antrenamentul supervizat în [capitolul 11](/course/chapter11/1).
+
+Modelele ajustate fin ar putea genera text fluent și structurat care este încă factual incorect, părtinitor, sau nu răspunde cu adevărat la întrebarea utilizatorului într-un mod util.
+
+**Intră Învățarea prin Întărire!** RL ne oferă o modalitate de a ajusta fin aceste LLM-uri pre-antrenate pentru a atinge mai bine aceste calități dorite. Este ca să-i dai câinelui nostru LLM antrenament suplimentar pentru a deveni un companion bine comportat și util, nu doar un câine care știe să latre fluent!
+
+## Învățarea prin Întărire din Feedback Uman (RLHF)
+
+O tehnică foarte populară pentru alinierea modelelor de limbaj este **Învățarea prin Întărire din Feedback Uman (RLHF)**. În RLHF, folosim feedback-ul uman ca proxy pentru semnalul de "recompensă" în RL. Iată cum funcționează:
+
+1. **Obține Preferințe Umane:** Am putea cere oamenilor să compare diferite răspunsuri generate de LLM pentru aceeași intrare și să ne spună ce răspuns preferă. De exemplu, am putea arăta unui om două răspunsuri diferite la întrebarea "Care este capitala Franței?" și să îl întrebăm "Care răspuns este mai bun?".
+
+2. **Antrenează un Model de Recompensă:** Folosim aceste date de preferință umană pentru a antrena un model separat numit **model de recompensă**. Acest model de recompensă învață să prezică ce fel de răspunsuri vor prefera oamenii. Învață să evalueze răspunsurile bazat pe utilitate, inofensivitate și alinierea cu preferințele umane.
+
+3. **Ajustează fin LLM-ul cu RL:** Acum folosim modelul de recompensă ca mediu pentru agentul nostru LLM. LLM-ul generează răspunsuri (acțiuni), și modelul de recompensă evaluează aceste răspunsuri (oferă recompense). În esență, antrenăm LLM-ul să producă text pe care modelul nostru de recompensă (care a învățat din preferințele umane) îl consideră bun.
+
+
+
+Dintr-o perspectivă generală, să privim beneficiile folosirii RL în LLM-uri:
+
+| Beneficiu | Descriere |
+|---------|-------------|
+| Control Îmbunătățit | RL ne permite să avem mai mult control asupra tipului de text pe care îl generează LLM-urile. Le putem ghida să producă text care este mai aliniat cu obiective specifice, cum ar fi a fi util, creativ sau concis. |
+| Alinierea Îmbunătățită cu Valorile Umane | RLHF, în particular, ne ajută să aliniată LLM-urile cu preferințele umane complexe și adesea subiective. Este greu să scrii reguli pentru "ce face un răspuns bun," dar oamenii pot judeca și compara ușor răspunsurile. RLHF permite modelului să învețe din aceste judecăți umane. |
+| Reducerea Comportamentelor Nedorite | RL poate fi folosit pentru a reduce comportamentele negative în LLM-uri, cum ar fi generarea de limbaj toxic, răspândirea dezinformării sau exhibarea prejudecăților. Prin conceperea recompenselor care penalizează aceste comportamente, putem îndemna modelul să le evite. |
+
+Învățarea prin Întărire din Feedback Uman a fost folosită pentru a antrena multe dintre cele mai populare LLM-uri de astăzi, cum ar fi GPT-4 de la OpenAI, Gemini de la Google și R1 de la DeepSeek. Există o gamă largă de tehnici pentru RLHF, cu grade variate de complexitate și sofisticare. În acest capitol, ne vom concentra pe Optimizarea Relativă a Politicii de Grup (GRPO), care este o tehnică pentru RLHF care s-a dovedit eficientă la antrenarea LLM-urilor care sunt utile, inofensive și aliniate cu preferințele umane.
+
+## De ce ar trebui să ne pese de GRPO (Optimizarea Relativă a Politicii de Grup)?
+
+Există multe tehnici pentru RLHF, dar acest curs se concentrează pe GRPO pentru că reprezintă un progres semnificativ în învățarea prin întărire pentru modelele de limbaj.
+
+Să considerăm pe scurt două dintre celelalte tehnici populare pentru RLHF:
+
+- Optimizarea Politicii Proximale (PPO)
+- Optimizarea Directă a Preferinței (DPO)
+
+Optimizarea Politicii Proximale (PPO) a fost una dintre primele tehnici foarte eficiente pentru RLHF. Folosește o metodă de gradient de politică pentru a actualiza politica bazată pe recompensa de la un model de recompensă separat.
+
+Optimizarea Directă a Preferinței (DPO) a fost dezvoltată mai târziu ca o tehnică mai simplă care elimină nevoia unui model de recompensă separat folosind datele de preferință direct. În esență, încadrează problema ca o sarcină de clasificare între răspunsurile alese și respinse.
+
+
+
+DPO și PPO sunt algoritmi complecși de învățare prin întărire în sine, pe care nu îi vom acoperi în acest curs. Dacă ești interesat să înveți mai multe despre ei, poți consulta următoarele resurse:
+
+- [Optimizarea Politicii Proximale](https://huggingface.co/docs/trl/main/en/ppo_trainer)
+- [Optimizarea Directă a Preferinței](https://huggingface.co/docs/trl/main/en/dpo_trainer)
+
+
+
+Spre deosebire de DPO și PPO, GRPO grupează eșantioane similare împreună și le compară ca grup. Abordarea bazată pe grup oferă gradienți mai stabili și proprietăți de convergență mai bune comparativ cu alte metode.
+
+GRPO nu folosește date de preferință cum face DPO, ci în schimb compară grupuri de eșantioane similare folosind un semnal de recompensă de la un model sau funcție.
+
+GRPO este flexibil în modul în care obține semnalele de recompensă - poate funcționa cu un model de recompensă (cum face PPO) dar nu necesită în mod strict unul. Aceasta pentru că GRPO poate încorpora semnale de recompensă de la orice funcție sau model care poate evalua calitatea răspunsurilor.
+
+De exemplu, am putea folosi o funcție de lungime pentru a recompensa răspunsuri mai scurte, un rezolvitor matematic pentru a verifica corectitudinea soluției, sau o funcție de corectitudine factuală pentru a recompensa răspunsurile care sunt mai precise din punct de vedere factual. Această flexibilitate face GRPO deosebit de versatil pentru diferite tipuri de sarcini de aliniere.
+
+---
+
+Felicitări pentru completarea Modulului 1! Acum ai o introducere solidă în Învățarea prin Întărire și rolul său crucial în modelarea viitorului Modelelor Mari de Limbaj. Înțelegi conceptele de bază ale RL, de ce este folosit pentru LLM-uri, și ai fost introdus la GRPO, un algoritm cheie în acest domeniu.
+
+În următorul modul, ne vom murdări mâinile și ne vom scufunda în lucrarea DeepSeek R1 pentru a vedea aceste concepte în acțiune!
+
+## Quiz
+
+### 1. Care sunt componentele cheie ale Învățării prin Întărire?
+
+
+
+### 2. Care este principalul avantaj al RLHF pentru antrenarea modelelor de limbaj?
+
+
+
+### 3. În contextul RL pentru LLM-uri, ce reprezintă o "acțiune"?
+
+
+
+### 4. Care este rolul recompenselor în antrenamentul RL al modelelor de limbaj?
+
+
+
+### 5. Ce este o recompensă în contextul RL pentru LLM-uri?
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter12/3.mdx b/chapters/rum/chapter12/3.mdx
new file mode 100644
index 000000000..1cd3a12e2
--- /dev/null
+++ b/chapters/rum/chapter12/3.mdx
@@ -0,0 +1,334 @@
+# Înțelegerea Lucrării DeepSeek R1
+
+Acest capitol este un curs intensiv de lectură a unei lucrări. Vom parcurge lucrarea în termeni simpli, și apoi vom descompune conceptele cheie și concluziile.
+
+DeepSeek R1 reprezintă un progres semnificativ în antrenarea modelelor de limbaj, în special în dezvoltarea capacităților de raționament prin învățarea prin întărire. Lucrarea introduce un nou algoritm de învățare prin întărire numit Optimizarea Relativă a Politicii de Grup (GRPO).
+
+
+
+În următorul capitol, vom construi pe această cunoaștere și vom implementa GRPO în practică.
+
+Obiectivul inițial al lucrării a fost să exploreze dacă învățarea prin întărire pură ar putea dezvolta capacități de raționament fără ajustarea fină supervizată.
+
+
+
+Până la acel moment, toate LLM-urile populare necesitau o anumită ajustare fină supervizată, pe care am explorat-o în [capitolul 11](/course/chapter11/1).
+
+
+
+## Momentul Revoluționar 'Aha'
+
+
+
+Una dintre cele mai remarcabile descoperiri în antrenarea R1-Zero a fost apariția unui fenomen cunoscut ca "Momentul Aha." Acest fenomen este oarecum similar cu modul în care oamenii experimentează realizări bruște în timpul rezolvării problemelor. Iată cum funcționează:
+
+1. Încercare Inițială: Modelul face o încercare inițială de a rezolva o problemă
+2. Recunoaștere: Recunoaște erori potențiale sau inconsistențe
+3. Auto-Corecție: Își ajustează abordarea bazat pe această recunoaștere
+4. Explicație: Poate explica de ce noua abordare este mai bună
+
+Această descoperire rezonează cu cursanții și se simte ca un moment "Eureka". Demonstrează învățarea mai degrabă decât memorarea simplă, așa că să ne luăm un moment să ne imaginăm cum se simte să ai un moment "Aha".
+
+De exemplu, imaginează-ți că încerci să rezolvi un puzzle:
+- Prima încercare: "Această piesă ar trebui să meargă aici bazat pe culoare"
+- Recunoaștere: "Dar stai, forma nu se potrivește destul de bine"
+- Corecție: "Ah, de fapt merge acolo"
+- Explicație: "Pentru că atât culoarea cât și modelul de formă se potrivesc în această poziție"
+
+Această abilitate a apărut natural din antrenamentul RL, fără a fi programată explicit, demonstrând învățarea mai degrabă decât memorarea simplă a unui proces din datele de antrenare.
+
+Cel mai ușor mod de a înțelege momentul 'Aha' este să-l vezi în acțiune. Să aruncăm o privire la un exemplu. În chat-ul de mai jos, întrebăm modelul să rezolve o problemă și UI-ul arată procesul de gândire al modelului pe măsură ce rezolvă problema.
+
+
+
+Dacă vrei să încerci Deepseek's R1, poți de asemenea să consulți [Hugging Chat](https://huggingface.co/chat/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B).
+
+## Procesul de Antrenare
+
+Antrenarea R1 a fost un proces cu mai multe faze. Să descompunem fazele și inovațiile cheie în fiecare fază.
+
+Procesul final rezultă în două modele:
+- DeepSeek-R1-Zero: Un model antrenat pur folosind învățarea prin întărire.
+- DeepSeek-R1: Un model care construiește pe fundația DeepSeek-R1-Zero și adaugă ajustare fină supervizată.
+
+| Caracteristică | DeepSeek-R1-Zero | DeepSeek-R1 |
+|---------|------------------|--------------|
+| Abordarea de Antrenare | RL Pur | Multi-fază (SFT + RL) |
+| Ajustare Fină | Niciuna | Ajustare fină supervizată |
+| Capacitate de Raționament | Emergentă | Îmbunătățită |
+| Performanța AIME | 71.0% | 79.8% |
+| Caracteristici Cheie | Raționament puternic dar probleme de lizibilitate | Consistență și lizibilitate mai bună a limbajului |
+
+În timp ce DeepSeek-R1-Zero demonstrează potențialul învățării prin întărire pure pentru dezvoltarea capacităților de raționament, DeepSeek-R1 construiește pe această fundație cu o abordare mai echilibrată care prioritizează atât performanța de raționament cât și utilizabilitatea.
+
+Procesul de antrenare implică patru faze:
+
+1. Faza de Pornire la Rece
+2. Faza RL de Raționament
+3. Faza de Eșantionare prin Respingere
+4. Faza RL Diversă
+
+Să descompunem fiecare fază:
+
+### Faza de Pornire la Rece (Fundația Calității)
+
+
+
+Această fază este concepută pentru a stabili o fundație solidă pentru lizibilitatea și calitatea răspunsurilor modelului. Folosește un set de date mic de eșantioane de înaltă calitate de la R1-Zero pentru a ajusta fin modelul V3-Base. Începând cu modelul DeepSeek-V3-Base, echipa a folosit mii de eșantioane validate, de înaltă calitate de la R1-Zero pentru ajustarea fină supervizată. Această abordare inovatoare folosește un set de date mic dar de înaltă calitate pentru a stabili o lizibilitate de bază puternică și calitatea răspunsurilor.
+
+### Faza RL de Raționament (Construirea Capacităților)
+
+
+
+Faza RL de Raționament se concentrează pe dezvoltarea capacităților de raționament de bază în domenii incluzând matematica, codarea, știința și logica. Această fază folosește învățarea prin întărire bazată pe reguli, cu recompense direct legate de corectitudinea soluției.
+
+Crucial, toate sarcinile din această fază sunt 'verificabile' deci putem verifica dacă răspunsul modelului este corect sau nu. De exemplu, în cazul matematicii, putem verifica dacă răspunsul modelului este corect folosind un rezolvitor matematic.
+
+Ceea ce face această fază deosebit de inovatoare este abordarea sa de optimizare directă care elimină nevoia unui model de recompensă separat, simplificând procesul de antrenare.
+
+### Faza de Eșantionare prin Respingere (Controlul Calității)
+
+
+
+În timpul Fazei de Eșantionare prin Respingere, modelul generează eșantioane care sunt apoi filtrate printr-un proces de control al calității. DeepSeek-V3 servește ca judecător al calității, evaluând rezultatele într-un domeniu larg care se extinde dincolo de sarcinile pure de raționament. Datele filtrate sunt apoi folosite pentru ajustarea fină supervizată. Inovația acestei faze constă în abilitatea sa de a combina multiple semnale de calitate pentru a asigura rezultate de înalt standard.
+
+### Faza RL Diversă (Alinierea Largă)
+
+
+
+Faza finală RL Diversă abordează multiple tipuri de sarcini folosind o abordare hibridă sofisticată. Pentru sarcinile deterministe, folosește recompense bazate pe reguli, în timp ce sarcinile subiective sunt evaluate prin feedback LLM. Această fază își propune să atingă alinierea preferințelor umane prin abordarea sa inovatoare de recompense hibride, combinând precizia sistemelor bazate pe reguli cu flexibilitatea evaluării modelelor de limbaj.
+
+## Algoritmul: Optimizarea Relativă a Politicii de Grup (GRPO)
+
+Acum că avem o înțelegere bună a procesului de antrenare, să privim algoritmul care a fost folosit pentru a antrena modelul.
+
+Autorii descriu GRPO ca o descoperire în ajustarea fină a modelelor:
+
+
+
+Noutatea GRPO constă în capacitatea sa de a "optimiza direct pentru rectificarea preferințelor." Aceasta semnifică o rută mai directă și eficientă către alinierea modelului cu rezultatele dorite, contrastând cu algoritmii tradiționali de Învățare prin Întărire precum PPO. Să descompunem cum funcționează GRPO prin cele trei componente principale ale sale.
+
+### Formarea Grupurilor: Crearea de Multiple Soluții
+
+Primul pas în GRPO este remarcabil de intuitiv - este similar cu modul în care un student ar putea rezolva o problemă dificilă încercând multiple abordări. Când primește o comandă, modelul nu generează doar un răspuns; în schimb, creează multiple încercări de a rezolva aceeași problemă (de obicei 4, 8 sau 16 încercări diferite).
+
+Imaginează-ți că înveți un model să rezolve probleme de matematică. Pentru o întrebare despre numărarea puilor de pe o fermă, modelul ar putea genera mai multe soluții diferite:
+- O soluție ar putea descompune problema pas cu pas: prima numărarea puilor totali, apoi scăderea cocoșilor, și în final contabilizarea găinilor care nu produc ouă
+- Altă soluție ar putea folosi o abordare diferită dar la fel de validă
+- Unele încercări ar putea conține greșeli sau soluții mai puțin eficiente
+
+Toate aceste încercări sunt păstrate împreună ca grup, aproape ca să ai mai mulți studenti cu soluții de comparat și din care să înveți.
+
+
+
+### Învățarea Preferințelor: Înțelegerea Ce Face o Soluție Bună
+
+Aici este unde GRPO cu adevărat strălucește în simplitatea sa. Spre deosebire de alte metode pentru RLHF care întotdeauna necesită un model de recompensă separat pentru a prezice cât de bună ar putea fi o soluție, GRPO poate folosi orice funcție sau model pentru a evalua calitatea unei soluții. De exemplu, am putea folosi o funcție de lungime pentru a recompensa răspunsuri mai scurte sau un rezolvitor matematic pentru a recompensa soluții matematice precise.
+
+Procesul de evaluare privește la diverse aspecte ale fiecărei soluții:
+- Este răspunsul final corect?
+- A urmat soluția formatarea corespunzătoare (cum ar fi folosirea tag-urilor XML corecte)?
+- Se potrivește raționamentul cu răspunsul oferit?
+
+Ceea ce face această abordare deosebit de inteligentă este modul în care gestionează evaluarea. În loc să dea doar scoruri absolute, GRPO normalizează recompensele în cadrul fiecărui grup. Folosește o formulă simplă dar eficientă pentru estimarea avantajului relativ al grupului:
+
+```
+Avantaj = (recompensă - mean(recompense_grup)) / std(recompense_grup)
+```
+
+
+
+Această normalizare este ca să notezi pe o curbă, dar pentru AI. Ajută modelul să înțeleagă care soluții din cadrul grupului au fost mai bune sau mai rele comparativ cu colegii lor, mai degrabă decât să se uite doar la scoruri absolute.
+
+### Optimizarea: Învățarea din Experiență
+
+Pasul final este unde GRPO îi învață modelul să se îmbunătățească bazat pe ceea ce a învățat din evaluarea grupului de soluții. Acest proces este atât puternic cât și stabil, folosind două principii principale:
+
+1. Încurajează modelul să producă mai multe soluții ca cele de succes în timp ce se îndepărtează de abordările mai puțin eficiente
+2. Include un mecanism de siguranță (numit penalitate de divergență KL) care previne modelul să se schimbe prea drastic dintr-o dată
+
+Această abordare se dovedește mai stabilă decât metodele tradiționale pentru că:
+- Se uită la multiple soluții împreună mai degrabă decât să compare doar două pe rând
+- Normalizarea bazată pe grup ajută la prevenirea problemelor cu scalarea recompenselor
+- Penalitatea KL acționează ca o plasă de siguranță, asigurându-se că modelul nu uită ce știa deja în timp ce învață lucruri noi
+
+
+
+Inovațiile cheie ale GRPO sunt:
+- Învățarea direct din orice funcție sau model, eliminând dependența de un model de recompensă separat.
+- Învățarea bazată pe grup, care este mai stabilă și eficientă decât metodele tradiționale cum ar fi comparațiile perechi.
+
+
+
+Această descompunere este complexă, dar concluzia cheie este că GRPO este o modalitate mai eficientă și stabilă de a antrena un model să raționeze.
+
+### Algoritmul GRPO în Pseudocod
+
+Acum că înțelegem componentele cheie ale GRPO, să privim algoritmul în pseudocod. Aceasta este o versiune simplificată a algoritmului, dar surprinde ideile cheie.
+
+```
+Input:
+- initial_policy: Modelul de început care va fi antrenat
+- reward_function: Funcția care evaluează rezultatele
+- training_prompts: Set de exemple de antrenare
+- group_size: Numărul de rezultate per comandă (de obicei 4-16)
+
+Algoritm GRPO:
+1. Pentru fiecare iterație de antrenare:
+ a. Setează reference_policy = initial_policy (captura politica actuală)
+ b. Pentru fiecare comandă în lot:
+ i. Generează group_size rezultate diferite folosind initial_policy
+ ii. Calculează recompensele pentru fiecare rezultat folosind reward_function
+ iii. Normalizează recompensele în cadrul grupului:
+ normalized_advantage = (recompensă - mean(recompense)) / std(recompense)
+ iv. Actualizează politica maximizând rația tăiată:
+ min(prob_ratio * normalized_advantage,
+ clip(prob_ratio, 1-epsilon, 1+epsilon) * normalized_advantage)
+ - kl_weight * KL(initial_policy || reference_policy)
+
+ unde prob_ratio este current_prob / reference_prob
+
+Output: Model de politică optimizat
+```
+
+Acest algoritm arată cum GRPO combină estimarea avantajului bazat pe grup cu optimizarea politicii menținând în același timp stabilitatea prin tăiere și constrângeri de divergență KL.
+
+## Rezultate și Impact
+
+Acum că am explorat algoritmul, să privim rezultatele. DeepSeek R1 atinge performanțe de ultimă generație în multiple domenii:
+
+| Domeniu | Rezultate Cheie |
+|--------|-------------|
+| Matematică | • 79.8% pe AIME 2024
+
+Valori extrem de mici ale pierderilor ar putea sugera memorizare mai degrabă decât învățare. Acest lucru este deosebit de îngrijorător dacă:
+- Modelul performează slab pe exemple noi, similare
+- Ieșirile lipsesc de diversitate
+- Răspunsurile sunt prea similare cu exemplele de antrenare
+
+
+Monitorizați atât valorile pierderilor, cât și ieșirile efective ale modelului în timpul antrenamentului. Uneori pierderea poate arăta bine în timp ce modelul dezvoltă comportamente nedorite. Evaluarea calitativă regulată a răspunsurilor modelului ajută la detectarea problemelor pe care metricile singure le-ar putea rata.
+
+
+Ar trebui să observăm că interpretarea valorilor pierderilor pe care o descriem aici este destinată cazului cel mai comun, și de fapt, valorile pierderilor se pot comporta în moduri diferite în funcție de model, setul de date, parametrii de antrenare, etc. Dacă sunteți interesați să explorați mai multe despre modelele descrise, ar trebui să consultați acest articol de blog de la oamenii de la [Fast AI](https://www.fast.ai/posts/2023-09-04-learning-jumps/).
+
+## Evaluarea după SFT
+
+În secțiunea [11.4](/en/chapter11/4) vom învăța cum să evaluăm modelul folosind seturi de date de referință. Pentru moment, ne vom concentra pe evaluarea calitativă a modelului.
+
+După finalizarea SFT, considerați aceste acțiuni de urmărire:
+
+1. Evaluați modelul temeinic pe datele de test păstrate deoparte
+2. Validați aderarea la template pe diverse intrări
+3. Testați reținerea cunoștințelor specifice domeniului
+4. Monitorizați metricile de performanță din lumea reală
+
+
+Documentați procesul de antrenare, inclusiv:
+- Caracteristicile setului de date
+- Parametrii antrenamentului
+- Metricile de performanță
+- Limitările cunoscute
+Această documentație va fi valoroasă pentru iterațiile viitoare ale modelului.
+
+
+## Chestionar
+
+### 1. Ce parametri controlează durata antrenamentului în SFT?
+
+
+
+### 2. Ce model în curbele pierderilor indică supraadaptarea potențială?
+
+
+
+### 3. Pentru ce este folosit gradient_accumulation_steps?
+
+
+
+### 4. Ce ar trebui să monitorizați în timpul antrenamentului SFT?
+
+
+
+### 5. Ce indică convergența sănătoasă în timpul antrenamentului?
+
+
+
+## 💐 Bună treabă!
+
+Ați învățat cum să faceți fine-tuning la modele folosind SFT! Pentru a continua învățarea:
+1. Încercați notebook-ul cu parametri diferiți
+2. Experimentați cu alte seturi de date
+3. Contribuiți cu îmbunătățiri la materialul cursului
+
+## Resurse adiționale
+
+- [Documentația TRL](https://huggingface.co/docs/trl)
+- [Depozitul de exemple SFT](https://github.com/huggingface/trl/blob/main/trl/scripts/sft.py)
+- [Cele mai bune practici pentru fine-tuning](https://huggingface.co/docs/transformers/training)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/4.mdx b/chapters/rum/chapter11/4.mdx
new file mode 100644
index 000000000..f243b94e3
--- /dev/null
+++ b/chapters/rum/chapter11/4.mdx
@@ -0,0 +1,171 @@
+
+
+# LoRA (Adaptarea de rang scăzut)
+
+Fine-tuningul modelelor mari de limbaj este un proces intensiv în resurse. LoRA este o tehnică care ne permite să facem fine-tuning la modele mari de limbaj cu un număr mic de parametri. Funcționează prin adăugarea și optimizarea unor matrice mai mici la greutățile atenției, reducând de obicei parametrii antrenabili cu aproximativ 90%.
+
+## Înțelegerea LoRA
+
+LoRA (Adaptarea de rang scăzut) este o tehnică de fine-tuning eficientă din punct de vedere al parametrilor care îngheață greutățile modelului pre-antrenat și injectează matrice de descompunere de rang antrenabile în straturile modelului. În loc să antreneze toți parametrii modelului în timpul fine-tuningului, LoRA descompune actualizările greutăților în matrice mai mici prin descompunere de rang scăzut, reducând semnificativ numărul de parametri antrenabili menținând în același timp performanța modelului. De exemplu, când este aplicat la GPT-3 175B, LoRA a redus parametrii antrenabili de 10.000 de ori și cerințele de memorie GPU de 3 ori comparativ cu fine-tuningul complet. Puteți citi mai multe despre LoRA în [lucrarea LoRA](https://arxiv.org/pdf/2106.09685).
+
+LoRA funcționează prin adăugarea de perechi de matrice de descompunere de rang la straturile transformer, concentrându-se de obicei pe greutățile atenției. În timpul inferenței, aceste greutăți ale adaptorului pot fi îmbinate cu modelul de bază, rezultând în nicio latență suplimentară. LoRA este deosebit de util pentru adaptarea modelelor mari de limbaj la sarcini sau domenii specifice menținând în același timp cerințele de resurse gestionabile.
+
+## Avantajele cheie ale LoRA
+
+1. **Eficiența memoriei**:
+ - Doar parametrii adaptorului sunt stocați în memoria GPU
+ - Greutățile modelului de bază rămân înghețate și pot fi încărcate la precizie mai mică
+ - Permite fine-tuningul modelelor mari pe GPU-uri de consum
+
+2. **Caracteristici de antrenare**:
+ - Integrare nativă PEFT/LoRA cu configurare minimă
+ - Suport pentru QLoRA (LoRA cuantificat) pentru eficiență de memorie și mai bună
+
+3. **Gestionarea adaptorului**:
+ - Salvarea greutăților adaptorului în timpul punctelor de verificare
+ - Funcționalități pentru îmbinarea adaptorilor înapoi în modelul de bază
+
+## Încărcarea adaptorilor LoRA cu PEFT
+
+[PEFT](https://github.com/huggingface/peft) este o bibliotecă care oferă o interfață unificată pentru încărcarea și gestionarea metodelor PEFT, inclusiv LoRA. Vă permite să încărcați și să comutați cu ușurință între diferite metode PEFT, făcând mai ușor să experimentați cu diferite tehnici de fine-tuning.
+
+Adaptorii pot fi încărcați pe un model pre-antrenat cu `load_adapter()`, care este util pentru a încerca adaptori diferiți ale căror greutăți nu sunt îmbinate. Setați greutățile adaptorului activ cu funcția `set_adapter()`. Pentru a reveni la modelul de bază, ați putea folosi unload() pentru a descărca toate modulele LoRA. Acest lucru face ușor să comutați între greutăți specifice sarcinilor diferite.
+
+```python
+from peft import PeftModel, PeftConfig
+
+config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
+model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
+lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora")
+```
+
+
+
+## Fine-tuning LLM folosind `trl` și `SFTTrainer` cu LoRA
+
+[SFTTrainer](https://huggingface.co/docs/trl/sft_trainer) din `trl` oferă integrare cu adaptorii LoRA prin biblioteca [PEFT](https://huggingface.co/docs/peft/en/index). Aceasta înseamnă că putem face fine-tuning la un model în același mod ca și cu SFT, dar folosim LoRA pentru a reduce numărul de parametri pe care trebuie să îi antrenăm.
+
+Vom folosi clasa `LoRAConfig` din PEFT în exemplul nostru. Configurarea necesită doar câțiva pași de configurare:
+
+1. Definiți configurația LoRA (rang, alfa, dropout)
+2. Creați SFTTrainer cu configurația PEFT
+3. Antrenați și salvați greutățile adaptorului
+
+## Configurația LoRA
+
+Să parcurgem configurația LoRA și parametrii cheie.
+
+| Parametru | Descriere |
+|-----------|-----------|
+| `r` (rang) | Dimensiunea matricelor de rang scăzut folosite pentru actualizările greutăților. De obicei între 4-32. Valori mai mici oferă mai multă compresie dar potențial mai puțină expresivitate. |
+| `lora_alpha` | Factor de scalare pentru straturile LoRA, de obicei setat la 2x valoarea rangului. Valori mai mari rezultă în efecte de adaptare mai puternice. |
+| `lora_dropout` | Probabilitatea dropout pentru straturile LoRA, de obicei 0.05-0.1. Valori mai mari ajută la prevenirea supraadaptării în timpul antrenamentului. |
+| `bias` | Controlează antrenarea termenilor de bias. Opțiunile sunt "none", "all" sau "lora_only". "none" este cel mai comun pentru eficiența memoriei. |
+| `target_modules` | Specifică la care module ale modelului să aplice LoRA. Poate fi "all-linear" sau module specifice precum "q_proj,v_proj". Mai multe module permit o adaptabilitate mai mare dar cresc utilizarea memoriei. |
+
+
+Când implementați metode PEFT, începeți cu valori mici ale rangului (4-8) pentru LoRA și monitorizați pierderea antrenamentului. Folosiți seturi de validare pentru a preveni supraadaptarea și comparați rezultatele cu liniile de bază de fine-tuning complet când este posibil. Eficacitatea diferitelor metode poate varia în funcție de sarcină, așa că experimentarea este cheia.
+
+
+## Folosirea TRL cu PEFT
+
+Metodele PEFT pot fi combinate cu TRL pentru fine-tuning pentru a reduce cerințele de memorie. Putem trece `LoraConfig` la model când îl încărcăm.
+
+```python
+from peft import LoraConfig
+
+# TODO: Configurați parametrii LoRA
+# r: dimensiunea rangului pentru matricele de actualizare LoRA (mai mică = mai multă compresie)
+rank_dimension = 6
+# lora_alpha: factor de scalare pentru straturile LoRA (mai mare = adaptare mai puternică)
+lora_alpha = 8
+# lora_dropout: probabilitatea dropout pentru straturile LoRA (ajută la prevenirea supraadaptării)
+lora_dropout = 0.05
+
+peft_config = LoraConfig(
+ r=rank_dimension, # Dimensiunea rangului - de obicei între 4-32
+ lora_alpha=lora_alpha, # Factor de scalare LoRA - de obicei 2x rangul
+ lora_dropout=lora_dropout, # Probabilitatea dropout pentru straturile LoRA
+ bias="none", # Tipul bias pentru LoRA. bias-urile corespunzătoare vor fi actualizate în timpul antrenamentului.
+ target_modules="all-linear", # La care module să aplice LoRA
+ task_type="CAUSAL_LM", # Tipul sarcinii pentru arhitectura modelului
+)
+```
+
+Mai sus, am folosit `device_map="auto"` pentru a atribui automat modelul la dispozitivul corect. De asemenea, puteți atribui manual modelul la un dispozitiv specific folosind `device_map={"": device_index}`.
+
+Vom avea nevoie, de asemenea, să definim `SFTTrainer` cu configurația LoRA.
+
+```python
+# Creați SFTTrainer cu configurația LoRA
+trainer = SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=dataset["train"],
+ peft_config=peft_config, # Configurația LoRA
+ max_seq_length=max_seq_length, # Lungimea maximă a secvenței
+ processing_class=tokenizer,
+)
+```
+
+
+
+✏️ **Încercați!** Construiți pe modelul dumneavoastră ajustat fin din secțiunea anterioară, dar faceți fine-tuning cu LoRA. Folosiți setul de date `HuggingFaceTB/smoltalk` pentru a face fine-tuning la un model `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B`, folosind configurația LoRA pe care am definit-o mai sus.
+
+
+
+## Îmbinarea adaptorilor LoRA
+
+După antrenarea cu LoRA, s-ar putea să doriți să îmbinați greutățile adaptorului înapoi în modelul de bază pentru implementare mai ușoară. Aceasta creează un singur model cu greutățile combinate, eliminând necesitatea de a încărca adaptorii separat în timpul inferenței.
+
+Procesul de îmbinare necesită atenție la gestionarea memoriei și precizie. Deoarece va trebui să încărcați atât modelul de bază, cât și greutățile adaptorului simultan, asigurați-vă că există memorie GPU/CPU suficientă disponibilă. Folosirea `device_map="auto"` în `transformers` va găsi dispozitivul corect pentru model bazat pe hardware-ul dumneavoastră.
+
+Mențineți precizia consistentă (de ex. float16) pe tot parcursul procesului, potrivind precizia folosită în timpul antrenamentului și salvând modelul îmbinat în același format pentru implementare.
+
+## Implementarea îmbinării
+
+După antrenarea unui adaptor LoRA, puteți îmbina greutățile adaptorului înapoi în modelul de bază. Iată cum să faceți acest lucru:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM
+from peft import PeftModel
+
+# 1. Încărcați modelul de bază
+base_model = AutoModelForCausalLM.from_pretrained(
+ "base_model_name", torch_dtype=torch.float16, device_map="auto"
+)
+
+# 2. Încărcați modelul PEFT cu adaptorul
+peft_model = PeftModel.from_pretrained(
+ base_model, "path/to/adapter", torch_dtype=torch.float16
+)
+
+# 3. Îmbinați greutățile adaptorului cu modelul de bază
+merged_model = peft_model.merge_and_unload()
+```
+
+Dacă întâmpinați discrepanțe de dimensiune în modelul salvat, asigurați-vă că salvați și tokenizer-ul:
+
+```python
+# Salvați atât modelul, cât și tokenizer-ul
+tokenizer = AutoTokenizer.from_pretrained("base_model_name")
+merged_model.save_pretrained("path/to/save/merged_model")
+tokenizer.save_pretrained("path/to/save/merged_model")
+```
+
+
+
+✏️ **Încercați!** Îmbinați greutățile adaptorului înapoi în modelul de bază. Folosiți setul de date `HuggingFaceTB/smoltalk` pentru a face fine-tuning la un model `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B`, folosind configurația LoRA pe care am definit-o mai sus.
+
+
+
+# Resurse
+
+- [LoRA: Adaptarea de rang scăzut a modelelor mari de limbaj](https://arxiv.org/pdf/2106.09685)
+- [Documentația PEFT](https://huggingface.co/docs/peft)
+- [Articolul de blog Hugging Face despre PEFT](https://huggingface.co/blog/peft)
\ No newline at end of file
diff --git a/chapters/rum/chapter11/5.mdx b/chapters/rum/chapter11/5.mdx
new file mode 100644
index 000000000..61ca3c867
--- /dev/null
+++ b/chapters/rum/chapter11/5.mdx
@@ -0,0 +1,254 @@
+# Evaluarea
+
+Cu un model ajustat fin prin SFT sau LoRA SFT, ar trebui să îl evaluăm pe criterii de referință standard. Ca ingineri de machine learning, ar trebui să mențineți o suită de evaluări relevante pentru domeniul dumneavoastră țintă de interes. În această pagină, vom privi la unele dintre criteriile de referință cele mai comune și cum să le folosiți pentru a evalua modelul dumneavoastră. De asemenea, vom vedea cum să creați criterii de referință personalizate pentru cazul specific de utilizare.
+
+## Criterii de referință automate
+
+Criteriile de referință automate servesc ca instrumente standardizate pentru evaluarea modelelor de limbaj pe diferite sarcini și capacități. În timp ce acestea oferă un punct de plecare util pentru înțelegerea performanței modelului, este important să recunoaștem că reprezintă doar o piesă dintr-o strategie de evaluare cuprinzătoare.
+
+## Înțelegerea criteriilor de referință automate
+
+Criteriile de referință automate constau de obicei din seturi de date curate cu sarcini și metrici de evaluare predefinite. Aceste criterii de referință au ca scop să evalueze diverse aspecte ale capacității modelului, de la înțelegerea de bază a limbajului la raționament complex. Avantajul cheie al folosirii criteriilor de referință automate este standardizarea lor - permit compararea consistentă între modele diferite și oferă rezultate reproductibile.
+
+Cu toate acestea, este crucial să înțelegem că performanța la criterii de referință nu se traduce întotdeauna direct în eficacitate din lumea reală. Un model care excelează la criterii de referință academice poate totuși să se confrunte cu aplicații de domeniu specifice sau cazuri de utilizare practice.
+
+## Criterii de referință pentru cunoștințe generale
+
+[MMLU](https://huggingface.co/datasets/cais/mmlu) (Massive Multitask Language Understanding) testează cunoștințele pe 57 de subiecte, de la știință la științe umane. Deși cuprinzător, poate să nu reflecte profunzimea expertizei necesare pentru domenii specifice. TruthfulQA evaluează tendința unui model de a reproduce concepții greșite comune, deși nu poate captura toate formele de dezinformare.
+
+## Criterii de referință pentru raționament
+
+[BBH](https://huggingface.co/datasets/lukaemon/bbh) (Big Bench Hard) și [GSM8K](https://huggingface.co/datasets/openai/gsm8k) se concentrează pe sarcini de raționament complex. BBH testează gândirea logică și planificarea, în timp ce GSM8K vizează specific rezolvarea problemelor matematice. Aceste criterii de referință ajută la evaluarea capacităților analitice dar pot să nu captureze raționamentul nuanțat necesar în scenarii din lumea reală.
+
+## Înțelegerea limbajului
+
+[HELM](https://github.com/stanford-crfm/helm) oferă un cadru de evaluare holistic. Criterii de referință precum HELM oferă perspective asupra capacităților de procesare a limbajului pe aspecte precum bunul simț, cunoștințele despre lume și raționamentul. Dar pot să nu reprezinte complet complexitatea conversației naturale sau terminologia specifică domeniului.
+
+## Criterii de referință specifice domeniului
+
+Să ne uităm la câteva criterii de referință care se concentrează pe domenii specifice precum matematica, codarea și chatul.
+
+[Criteriul de referință MATH](https://huggingface.co/papers/2103.03874) este un alt instrument important de evaluare pentru raționamentul matematic. Constă din 12.500 de probleme din competiții de matematică, acoperind algebra, geometria, teoria numerelor, numărarea, probabilitatea și altele. Ceea ce face MATH deosebit de provocator este că necesită raționament în mai mulți pași, înțelegerea notației matematice formale și capacitatea de a genera soluții pas cu pas. Spre deosebire de sarcinile aritmetice mai simple, problemele MATH necesită adesea strategii sofisticate de rezolvare a problemelor și aplicații de concepte matematice.
+
+[Criteriul de referință HumanEval](https://github.com/openai/human-eval) este un set de date de evaluare axat pe codare format din 164 de probleme de programare. Criteriul de referință testează capacitatea unui model de a genera cod Python funcțional corect care rezolvă sarcinile de programare date. Ceea ce face HumanEval deosebit de valoros este că evaluează atât capacitățile de generare de cod, cât și corectitudinea funcțională prin executarea efectivă a cazurilor de test, mai degrabă decât doar similaritatea superficială cu soluțiile de referință. Problemele variază de la manipularea de bază a șirurilor la algoritmi și structuri de date mai complexe.
+
+[Alpaca Eval](https://tatsu-lab.github.io/alpaca_eval/) este un cadru de evaluare automatizat conceput pentru a evalua calitatea modelelor de limbaj care urmează instrucțiuni. Folosește GPT-4 ca judecător pentru a evalua ieșirile modelului pe diverse dimensiuni, inclusiv utilitatea, onestitatea și inofensivitatea. Cadrul include un set de date cu 805 de prompturi atent curate și poate evalua răspunsurile față de modele multiple de referință precum Claude, GPT-4 și altele. Ceea ce face Alpaca Eval deosebit de util este capacitatea sa de a oferi evaluări consistente, scalabile fără a necesita adnotatori umani, în timp ce încă capturează aspecte nuanțate ale performanței modelului pe care metricile tradiționale le-ar putea rata.
+
+## Abordări alternative de evaluare
+
+Multe organizații au dezvoltat metode alternative de evaluare pentru a aborda limitările criteriilor de referință standard:
+
+### LLM-ca-judecător
+
+Folosirea unui model de limbaj pentru a evalua ieșirile altuia a devenit din ce în ce mai populară. Această abordare poate oferi feedback mai nuanțat decât metricile tradiționale, deși vine cu propriile sale prejudecăți și limitări.
+
+### Arene de evaluare
+
+Arenele de evaluare precum [Chatbot Arena](https://lmarena.ai/) oferă o abordare unică pentru evaluarea LLM prin feedback crowdsourced. În aceste platforme, utilizatorii se angajează în "bătălii" anonime între două LLM-uri, punând întrebări și votând care model oferă răspunsuri mai bune. Această abordare capturează modelele de utilizare și preferințele din lumea reală prin întrebări diverse, provocatoare, cu studii care arată acord puternic între voturile crowdsourced și evaluările experților. Deși puternice, aceste platforme au limitări, inclusiv prejudecăți potențiale ale bazei de utilizatori, distribuții distorsionate ale prompturilor și o concentrare principală pe utilitate mai degrabă decât pe considerațiile de siguranță.
+
+### Suite de criterii de referință personalizate
+
+Organizațiile dezvoltă adesea suite interne de criterii de referință adaptate nevoilor și cazurilor lor specifice de utilizare. Acestea ar putea include teste de cunoștințe specifice domeniului sau scenarii de evaluare care reflectă condițiile reale de implementare.
+
+## Evaluare personalizată
+
+În timp ce criteriile de referință standard oferă o linie de bază utilă, nu ar trebui să fie singura metodă de evaluare. Iată cum să dezvoltați o abordare mai cuprinzătoare:
+
+1. Începeți cu criterii de referință standard relevante pentru a stabili o linie de bază și a permite comparația cu alte modele.
+
+2. Identificați cerințele și provocările specifice ale cazului dumneavoastră de utilizare. Ce sarcini va îndeplini efectiv modelul? Ce tipuri de erori ar fi cele mai problematice?
+
+3. Dezvoltați seturi de date de evaluare personalizate care reflectă cazul real de utilizare. Aceasta ar putea include:
+ - Întrebări reale ale utilizatorilor din domeniul dumneavoastră
+ - Cazuri comune de margine pe care le-ați întâlnit
+ - Exemple de scenarii deosebit de provocatoare
+
+4. Considerați implementarea unei strategii de evaluare pe mai multe niveluri:
+ - Metrici automate pentru feedback rapid
+ - Evaluare umană pentru înțelegere nuanțată
+ - Revizuire de experți de domeniu pentru aplicații specializate
+ - Testare A/B în medii controlate
+
+## Implementarea evaluărilor personalizate
+
+În această secțiune, vom implementa evaluarea pentru modelul nostru ajustat fin. Putem folosi [`lighteval`](https://github.com/huggingface/lighteval) pentru a evalua modelul nostru ajustat fin pe criterii de referință standard, care conține o gamă largă de sarcini încorporate în bibliotecă. Trebuie doar să definim sarcinile pe care dorim să le evaluăm și parametrii pentru evaluare.
+
+Sarcinile LightEval sunt definite folosind un format specific:
+
+```
+{suite}|{task}|{num_few_shot}|{auto_reduce}
+```
+
+| Parametru | Descriere |
+|-----------|-----------|
+| `suite` | Suita de criterii de referință (de ex., 'mmlu', 'truthfulqa') |
+| `task` | Sarcina specifică din suită (de ex., 'abstract_algebra') |
+| `num_few_shot` | Numărul de exemple de inclus în prompt (0 pentru zero-shot) |
+| `auto_reduce` | Dacă să reducă automat exemplele few-shot dacă promptul este prea lung (0 sau 1) |
+
+Exemplu: `"mmlu|abstract_algebra|0|0"` evaluează pe sarcina de algebră abstractă MMLU cu inferență zero-shot.
+
+## Exemplu de pipeline de evaluare
+
+Să configurăm un pipeline de evaluare pentru modelul nostru ajustat fin. Vom evalua modelul pe un set de sub-sarcini care se raportează la domeniul medicinei.
+
+Iată un exemplu complet de evaluare pe criterii de referință automate relevante pentru un domeniu specific folosind Lighteval cu backend-ul VLLM:
+
+```bash
+lighteval accelerate \
+ "pretrained=your-model-name" \
+ "mmlu|anatomy|0|0" \
+ "mmlu|high_school_biology|0|0" \
+ "mmlu|high_school_chemistry|0|0" \
+ "mmlu|professional_medicine|0|0" \
+ --max_samples 40 \
+ --batch_size 1 \
+ --output_path "./results" \
+ --save_generations true
+```
+
+Rezultatele sunt afișate în format tabular arătând:
+
+```
+| Task |Version|Metric|Value | |Stderr|
+|----------------------------------------|------:|------|-----:|---|-----:|
+|all | |acc |0.3333|± |0.1169|
+|leaderboard:mmlu:_average:5 | |acc |0.3400|± |0.1121|
+|leaderboard:mmlu:anatomy:5 | 0|acc |0.4500|± |0.1141|
+|leaderboard:mmlu:high_school_biology:5 | 0|acc |0.1500|± |0.0819|
+```
+
+Lighteval include, de asemenea, un API Python pentru sarcini de evaluare mai detaliate, care este util pentru manipularea rezultatelor într-un mod mai flexibil. Consultați [documentația Lighteval](https://huggingface.co/docs/lighteval/using-the-python-api) pentru mai multe informații.
+
+
+
+✏️ **Încercați!** Evaluați modelul dumneavoastră ajustat fin pe o sarcină specifică în lighteval.
+
+
+
+# Chestionar de sfârșit de capitol[[end-of-chapter-quiz]]
+
+
+
+### 1. Care sunt principalele avantaje ale folosirii criteriilor de referință automate pentru evaluarea modelului?
+
+
+
+### 2. Care criteriu de referință testează specific cunoștințele pe 57 de subiecte diferite?
+
+
+
+### 3. Ce este LLM-ca-judecător?
+
+
+
+### 4. Ce ar trebui inclus într-o strategie de evaluare cuprinzătoare?
+
+
+
+### 5. Care este o limitare a criteriilor de referință automate?
+
+
+
+### 6. Care este scopul creării seturilor de date de evaluare personalizate?
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter11/6.mdx b/chapters/rum/chapter11/6.mdx
new file mode 100644
index 000000000..89356375e
--- /dev/null
+++ b/chapters/rum/chapter11/6.mdx
@@ -0,0 +1,13 @@
+# Concluzie
+
+În acest capitol, am explorat componentele esențiale ale fine-tuningului modelelor de limbaj:
+
+1. **Template-urile de chat** oferă structură interacțiunilor cu modelul, asigurând răspunsuri consecvente și adecvate prin formatare standardizată.
+
+2. **Fine-tuningul supervizat (SFT)** permite adaptarea modelelor pre-antrenate la sarcini specifice menținând în același timp cunoștințele lor fundamentale.
+
+3. **LoRA** oferă o abordare eficientă pentru fine-tuning prin reducerea parametrilor antrenabili păstrând în același timp performanța modelului.
+
+4. **Evaluarea** ajută la măsurarea și validarea eficacității fine-tuningului prin diverse metrici și criterii de referință.
+
+Aceste tehnici, când sunt combinate, permit crearea de modele specializate de limbaj care pot excela în sarcini specifice rămânând în același timp eficiente din punct de vedere computațional. Indiferent dacă construiți un bot de servicii pentru clienți sau un asistent specific domeniului, înțelegerea acestor concepte este crucială pentru adaptarea cu succes a modelului.
\ No newline at end of file
diff --git a/chapters/rum/chapter11/7.mdx b/chapters/rum/chapter11/7.mdx
new file mode 100644
index 000000000..2ef2c530e
--- /dev/null
+++ b/chapters/rum/chapter11/7.mdx
@@ -0,0 +1,31 @@
+# E timpul examenului!
+
+E timpul să vă puneți cunoștințele la încercare! Am pregătit un scurt chestionar pentru a vă testa înțelegerea conceptelor abordate în acest capitol.
+
+Pentru a face chestionarul, va trebui să urmați acești pași:
+
+1. Conectați-vă la contul dumneavoastră Hugging Face.
+2. Răspundeți la întrebările din chestionar.
+3. Trimiteți răspunsurile dumneavoastră.
+
+## Chestionar cu alegere multiplă
+
+În acest chestionar, vi se va cere să selectați răspunsul corect dintr-o listă de opțiuni. Vă vom testa pe elementele fundamentale ale fine-tuningului supervizat.
+
+
+
+## Chestionar de cod
+
+În acest chestionar, vi se va cere să scrieți cod pentru a completa o sarcină. Vă vom testa pe codul pe care l-ați studiat în curs din biblioteci precum `datasets`, `transformers`, `peft` și `TRL`.
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter12/1.mdx b/chapters/rum/chapter12/1.mdx
new file mode 100644
index 000000000..4dbae17fa
--- /dev/null
+++ b/chapters/rum/chapter12/1.mdx
@@ -0,0 +1,93 @@
+# Open R1 pentru Studenți
+
+Bun venit într-o călătorie captivantă în lumea AI-ului open-source cu învățarea prin întărire! Acest capitol este conceput pentru a ajuta studenții să înțeleagă învățarea prin întărire și rolul acesteia în LLM-uri.
+
+De asemenea, vom explora [Open R1](https://github.com/huggingface/open-r1), un proiect comunitar revoluționar care face AI-ul avansat accesibil pentru toată lumea. În mod specific, acest curs este pentru a ajuta studenții și cursanții să folosească și să contribuie la [Open R1](https://github.com/huggingface/open-r1).
+
+## Ce Vei Învăța
+
+În acest capitol, vom descompune concepte complexe în părți ușor de înțeles și îți vom arăta cum poți fi parte din acest proiect captivant de a face LLM-urile să raționeze asupra problemelor complexe.
+
+LLM-urile au demonstrat performanțe excelente pe multe sarcini generative. Cu toate acestea, până recent, au avut dificultăți cu problemele complexe care necesită raționament. De exemplu, le este greu să se descurce cu puzzle-uri sau probleme de matematică care necesită mai mulți pași de raționament.
+
+Open R1 este un proiect care își propune să facă LLM-urile să raționeze asupra problemelor complexe. Face acest lucru folosind învățarea prin întărire pentru a încuraja LLM-urile să 'gândească' și să raționeze.
+
+În termeni simpli, modelul este antrenat să genereze gânduri precum și rezultate, și să structureze aceste gânduri și rezultate astfel încât să poată fi gestionate separat de către utilizator.
+
+Să aruncăm o privire la un exemplu. Dacă ne-am dat nouă înșine sarcina de a rezolva următoarea problemă, am putea gândi astfel:
+
+```sh
+Problemă: "Am 3 mere și 2 portocale. Câte bucăți de fructe am în total?"
+
+Gând: "Trebuie să adun numărul de mere și portocale pentru a obține numărul total de bucăți de fructe."
+
+Răspuns: "5"
+```
+
+Putem apoi să structurăm acest gând și răspuns astfel încât să poată fi gestionate separat de către utilizator. Pentru sarcinile de raționament, LLM-urile pot fi antrenate să genereze gânduri și răspunsuri în următorul format:
+
+```sh
+Trebuie să adun numărul de mere și portocale pentru a obține numărul total de bucăți de fructe.
+5
+```
+
+Ca utilizator, putem apoi să extragem gândul și răspunsul din rezultatul modelului și să le folosim pentru a rezolva problema.
+
+## De Ce Este Important Pentru Studenți
+
+Ca student, înțelegerea Open R1 și a rolului învățării prin întărire în LLM-uri este valoroasă pentru că:
+- Îți arată cum se dezvoltă AI-ul de ultimă generație
+- Îți oferă oportunități practice de a învăța și contribui
+- Te ajută să înțelegi înspre unde se îndreaptă tehnologia AI
+- Îți deschide uși către viitoare oportunități de carieră în AI
+
+## Prezentarea Capitolului
+
+Acest capitol este împărțit în patru secțiuni, fiecare concentrându-se pe un aspect diferit al Open R1:
+
+### 1️⃣ Introducere în Învățarea prin Întărire și rolul acesteia în LLM-uri
+Vom explora elementele de bază ale Învățării prin Întărire (RL) și rolul acesteia în antrenarea LLM-urilor.
+- Ce este RL?
+- Cum este folosit RL în LLM-uri?
+- Ce este DeepSeek R1?
+- Care sunt inovațiile cheie ale DeepSeek R1?
+
+### 2️⃣ Înțelegerea Lucrării DeepSeek R1
+Vom descompune lucrarea de cercetare care a inspirat [Open R1](https://huggingface.co/open-r1):
+- Inovații și descoperiri cheie
+- Procesul de antrenare și arhitectura
+- Rezultate și semnificația lor
+
+### 3️⃣ Implementarea GRPO în TRL
+Vom deveni practici cu exemple de cod:
+- Cum să folosești biblioteca Transformer Reinforcement Learning (TRL)
+- Configurarea antrenamentului GRPO
+
+### 4️⃣ Caz de utilizare practic pentru alinierea unui model
+Vom privi un caz de utilizare practic pentru alinierea unui model folosind Open R1.
+- Cum să antrenezi un model folosind GRPO în TRL
+- Să-ți partajezi modelul pe [Hugging Face Hub](https://huggingface.co/models)
+
+## Cerințe Prealabile
+
+Pentru a obține cel mai mult din acest capitol, este util să ai:
+- Înțelegere solidă a programării Python
+- Familiaritate cu conceptele de machine learning
+- Interes pentru AI și modelele de limbaj
+
+Nu-ți face griji dacă îți lipsesc unele dintre acestea – vom explica conceptele cheie pe măsură ce mergem! 🚀
+
+
+
+Dacă nu ai toate cerințele prealabile, consultă acest [curs](/course/chapter1/1) de la unitățile 1 la 11
+
+
+
+## Cum să Folosești Acest Capitol
+
+1. **Citește Secvențial**: Secțiunile se construiesc una pe alta, așa că este mai bine să le citești în ordine
+2. **Partajează Notițe**: Scrie conceptele cheie și întrebările și discută-le cu comunitatea în [Discord](https://discord.gg/F3vZujJH)
+3. **Încearcă Codul**: Când ajungem la exemplele practice, încearcă-le singur
+4. **Alătură-te Comunității**: Folosește resursele pe care le oferim pentru a te conecta cu alți cursanți
+
+Să începem explorarea Open R1 și să descoperim cum poți fi parte din a face AI-ul mai accesibil pentru toată lumea! 🚀
\ No newline at end of file
diff --git a/chapters/rum/chapter12/2.mdx b/chapters/rum/chapter12/2.mdx
new file mode 100644
index 000000000..fc76264eb
--- /dev/null
+++ b/chapters/rum/chapter12/2.mdx
@@ -0,0 +1,245 @@
+# Introducere în Învățarea prin Întărire și rolul acesteia în LLM-uri
+
+Bun venit la prima pagină!
+
+Vom începe călătoria noastră în lumea captivantă a Învățării prin Întărire (RL) și vom descoperi cum aceasta revoluționează modul în care antrenăm Modelele de Limbaj precum cele pe care le-ai putea folosi în fiecare zi.
+
+
+
+În acest capitol, ne concentrăm pe învățarea prin întărire pentru modelele de limbaj. Cu toate acestea, învățarea prin întărire este un domeniu larg cu multe aplicații dincolo de modelele de limbaj. Dacă ești interesat să înveți mai multe despre învățarea prin întărire, ar trebui să consulți [Cursul de Învățare prin Întărire Profundă](https://huggingface.co/courses/deep-rl-course/en/unit1/introduction).
+
+
+
+Această pagină îți va oferi o introducere prietenoasă și clară în RL, chiar dacă nu ai întâlnit-o niciodată înainte. Vom descompune ideile principale și vom vedea de ce RL devine atât de important în domeniul Modelelor Mari de Limbaj (LLM-uri).
+
+## Ce este Învățarea prin Întărire (RL)?
+
+Imaginează-ți că antrenezi un câine. Vrei să-l înveți să stea. Ai putea spune "Stai!" și apoi, dacă câinele stă, îi dai o recompensă și îl lauzi. Dacă nu stă, ai putea să-l ghidezi blând sau doar să încerci din nou. De-a lungul timpului, câinele învață să asocieze statul cu recompensa pozitivă (recompensa și lauda) și este mai probabil să stea când spui "Stai!" din nou. În învățarea prin întărire, ne referim la acest feedback ca **recompensă**.
+
+Aceasta, pe scurt, este ideea de bază din spatele Învățării prin Întărire! În loc de un câine, avem un **model de limbaj** (în învățarea prin întărire, îl numim **agent**), și în loc de tine, avem **mediul** care oferă feedback.
+
+
+
+Să descompunem elementele cheie ale RL:
+
+### Agent
+
+Acesta este cel care învață. În exemplul cu câinele, câinele este agentul. În contextul LLM-urilor, LLM-ul însuși devine agentul pe care vrem să-l antrenăm. Agentul este cel care ia decizii și învață din mediu și din recompensele sale.
+
+### Mediu
+
+Acesta este lumea în care trăiește și interacționează agentul. Pentru câine, mediul este casa ta și tu. Pentru un LLM, mediul este puțin mai abstract – ar putea fi utilizatorii cu care interacționează, sau un scenariu simulat pe care îl configurăm pentru el. Mediul oferă feedback agentului.
+
+### Acțiune
+
+Acestea sunt alegerile pe care agentul le poate face în mediu. Acțiunile câinelui sunt lucruri precum "stai", "ridică-te", "latră", etc. Pentru un LLM, acțiunile ar putea fi generarea de cuvinte într-o propoziție, alegerea ce răspuns să dea la o întrebare, sau deciderea cum să răspundă într-o conversație.
+
+### Recompensă
+
+Acesta este feedback-ul pe care mediul îl oferă agentului după ce acesta întreprinde o acțiune. Recompensele sunt de obicei numere.
+
+**Recompensele pozitive** sunt ca recompensele și laudele – îi spun agentului "bună treabă, ai făcut ceva corect!".
+
+**Recompensele negative** (sau penalitățile) sunt ca un "nu" blând – îi spun agentului "nu a fost tocmai corect, încearcă altceva". Pentru câine, recompensa este răsplata.
+
+Pentru un LLM, recompensele sunt concepute să reflecte cât de bine se descurcă LLM-ul la o sarcină specifică – poate fi cât de util, adevărat sau inofensiv este răspunsul său.
+
+### Politică
+
+Aceasta este strategia agentului pentru alegerea acțiunilor. Este ca înțelegerea câinelui despre ce ar trebui să facă când spui "Stai!". În RL, politica este ceea ce încercăm cu adevărat să învățăm și să îmbunătățim. Este un set de reguli sau o funcție care îi spune agentului ce acțiune să întreprindă în diferite situații. Inițial, politica ar putea fi aleatorie, dar pe măsură ce agentul învață, politica devine mai bună la alegerea acțiunilor care duc la recompense mai mari.
+
+## Procesul RL: Încercări și Erori
+
+
+
+Învățarea prin Întărire se întâmplă printr-un proces de încercări și erori:
+
+| Pas | Proces | Descriere |
+|------|---------|-------------|
+| 1. Observație | Agentul observă mediul | Agentul preia informații despre starea sa actuală și împrejurimile |
+| 2. Acțiune | Agentul întreprinde o acțiune bazată pe politica sa actuală | Folosind strategia sa învățată (politica), agentul decide ce să facă în continuare |
+| 3. Feedback | Mediul îi oferă agentului o recompensă | Agentul primește feedback despre cât de bună sau rea a fost acțiunea sa |
+| 4. Învățare | Agentul își actualizează politica bazată pe recompensă | Agentul își ajustează strategia - întărind acțiunile care au dus la recompense mari și evitând pe cele care au dus la recompense mici |
+| 5. Iterație | Repetă procesul | Acest ciclu continuă, permițând agentului să-și îmbunătățească continuu luarea deciziilor |
+
+Gândește-te la învățarea mersului pe bicicletă. Ai putea să te legeni și să cazi la început (recompensă negativă!). Dar când reușești să te echilibrezi și să pedalezi lin, te simți bine (recompensă pozitivă!). Îți ajustezi acțiunile bazat pe acest feedback – înclinându-te puțin, pedalând mai repede, etc. – până când înveți să mergi bine. RL este similar – se referă la învățarea prin interacțiune și feedback.
+
+## Rolul RL în Modelele Mari de Limbaj (LLM-uri)
+
+Acum, de ce este RL atât de important pentru Modelele Mari de Limbaj?
+
+Ei bine, antrenarea LLM-urilor cu adevărat bune este complicată. Le putem antrena pe cantități masive de text de pe internet, și devin foarte bune la prezicerea următorului cuvânt într-o propoziție. Astfel învață să genereze text fluent și corect din punct de vedere gramatical, după cum am învățat în [capitolul 2](/course/chapter2/1).
+
+Cu toate acestea, a fi doar fluent nu este suficient. Vrem ca LLM-urile noastre să fie mai mult decât bune la înșiruirea cuvintelor. Vrem ca ele să fie:
+
+* **Utile:** Să ofere informații utile și relevante.
+* **Inofensive:** Să evite generarea de conținut toxic, părtinitor sau dăunător.
+* **Aliniate cu Preferințele Umane:** Să răspundă în moduri pe care oamenii le găsesc naturale, utile și captivante.
+
+Metodele de pre-antrenare LLM, care se bazează în principal pe prezicerea următorului cuvânt din datele text, uneori nu reușesc în aceste aspecte.
+
+În timp ce antrenamentul supervizat este excelent la producerea de rezultate structurate, poate fi mai puțin eficient la producerea de răspunsuri utile, inofensive și aliniate. Explorăm antrenamentul supervizat în [capitolul 11](/course/chapter11/1).
+
+Modelele ajustate fin ar putea genera text fluent și structurat care este încă factual incorect, părtinitor, sau nu răspunde cu adevărat la întrebarea utilizatorului într-un mod util.
+
+**Intră Învățarea prin Întărire!** RL ne oferă o modalitate de a ajusta fin aceste LLM-uri pre-antrenate pentru a atinge mai bine aceste calități dorite. Este ca să-i dai câinelui nostru LLM antrenament suplimentar pentru a deveni un companion bine comportat și util, nu doar un câine care știe să latre fluent!
+
+## Învățarea prin Întărire din Feedback Uman (RLHF)
+
+O tehnică foarte populară pentru alinierea modelelor de limbaj este **Învățarea prin Întărire din Feedback Uman (RLHF)**. În RLHF, folosim feedback-ul uman ca proxy pentru semnalul de "recompensă" în RL. Iată cum funcționează:
+
+1. **Obține Preferințe Umane:** Am putea cere oamenilor să compare diferite răspunsuri generate de LLM pentru aceeași intrare și să ne spună ce răspuns preferă. De exemplu, am putea arăta unui om două răspunsuri diferite la întrebarea "Care este capitala Franței?" și să îl întrebăm "Care răspuns este mai bun?".
+
+2. **Antrenează un Model de Recompensă:** Folosim aceste date de preferință umană pentru a antrena un model separat numit **model de recompensă**. Acest model de recompensă învață să prezică ce fel de răspunsuri vor prefera oamenii. Învață să evalueze răspunsurile bazat pe utilitate, inofensivitate și alinierea cu preferințele umane.
+
+3. **Ajustează fin LLM-ul cu RL:** Acum folosim modelul de recompensă ca mediu pentru agentul nostru LLM. LLM-ul generează răspunsuri (acțiuni), și modelul de recompensă evaluează aceste răspunsuri (oferă recompense). În esență, antrenăm LLM-ul să producă text pe care modelul nostru de recompensă (care a învățat din preferințele umane) îl consideră bun.
+
+
+
+Dintr-o perspectivă generală, să privim beneficiile folosirii RL în LLM-uri:
+
+| Beneficiu | Descriere |
+|---------|-------------|
+| Control Îmbunătățit | RL ne permite să avem mai mult control asupra tipului de text pe care îl generează LLM-urile. Le putem ghida să producă text care este mai aliniat cu obiective specifice, cum ar fi a fi util, creativ sau concis. |
+| Alinierea Îmbunătățită cu Valorile Umane | RLHF, în particular, ne ajută să aliniată LLM-urile cu preferințele umane complexe și adesea subiective. Este greu să scrii reguli pentru "ce face un răspuns bun," dar oamenii pot judeca și compara ușor răspunsurile. RLHF permite modelului să învețe din aceste judecăți umane. |
+| Reducerea Comportamentelor Nedorite | RL poate fi folosit pentru a reduce comportamentele negative în LLM-uri, cum ar fi generarea de limbaj toxic, răspândirea dezinformării sau exhibarea prejudecăților. Prin conceperea recompenselor care penalizează aceste comportamente, putem îndemna modelul să le evite. |
+
+Învățarea prin Întărire din Feedback Uman a fost folosită pentru a antrena multe dintre cele mai populare LLM-uri de astăzi, cum ar fi GPT-4 de la OpenAI, Gemini de la Google și R1 de la DeepSeek. Există o gamă largă de tehnici pentru RLHF, cu grade variate de complexitate și sofisticare. În acest capitol, ne vom concentra pe Optimizarea Relativă a Politicii de Grup (GRPO), care este o tehnică pentru RLHF care s-a dovedit eficientă la antrenarea LLM-urilor care sunt utile, inofensive și aliniate cu preferințele umane.
+
+## De ce ar trebui să ne pese de GRPO (Optimizarea Relativă a Politicii de Grup)?
+
+Există multe tehnici pentru RLHF, dar acest curs se concentrează pe GRPO pentru că reprezintă un progres semnificativ în învățarea prin întărire pentru modelele de limbaj.
+
+Să considerăm pe scurt două dintre celelalte tehnici populare pentru RLHF:
+
+- Optimizarea Politicii Proximale (PPO)
+- Optimizarea Directă a Preferinței (DPO)
+
+Optimizarea Politicii Proximale (PPO) a fost una dintre primele tehnici foarte eficiente pentru RLHF. Folosește o metodă de gradient de politică pentru a actualiza politica bazată pe recompensa de la un model de recompensă separat.
+
+Optimizarea Directă a Preferinței (DPO) a fost dezvoltată mai târziu ca o tehnică mai simplă care elimină nevoia unui model de recompensă separat folosind datele de preferință direct. În esență, încadrează problema ca o sarcină de clasificare între răspunsurile alese și respinse.
+
+
+
+DPO și PPO sunt algoritmi complecși de învățare prin întărire în sine, pe care nu îi vom acoperi în acest curs. Dacă ești interesat să înveți mai multe despre ei, poți consulta următoarele resurse:
+
+- [Optimizarea Politicii Proximale](https://huggingface.co/docs/trl/main/en/ppo_trainer)
+- [Optimizarea Directă a Preferinței](https://huggingface.co/docs/trl/main/en/dpo_trainer)
+
+
+
+Spre deosebire de DPO și PPO, GRPO grupează eșantioane similare împreună și le compară ca grup. Abordarea bazată pe grup oferă gradienți mai stabili și proprietăți de convergență mai bune comparativ cu alte metode.
+
+GRPO nu folosește date de preferință cum face DPO, ci în schimb compară grupuri de eșantioane similare folosind un semnal de recompensă de la un model sau funcție.
+
+GRPO este flexibil în modul în care obține semnalele de recompensă - poate funcționa cu un model de recompensă (cum face PPO) dar nu necesită în mod strict unul. Aceasta pentru că GRPO poate încorpora semnale de recompensă de la orice funcție sau model care poate evalua calitatea răspunsurilor.
+
+De exemplu, am putea folosi o funcție de lungime pentru a recompensa răspunsuri mai scurte, un rezolvitor matematic pentru a verifica corectitudinea soluției, sau o funcție de corectitudine factuală pentru a recompensa răspunsurile care sunt mai precise din punct de vedere factual. Această flexibilitate face GRPO deosebit de versatil pentru diferite tipuri de sarcini de aliniere.
+
+---
+
+Felicitări pentru completarea Modulului 1! Acum ai o introducere solidă în Învățarea prin Întărire și rolul său crucial în modelarea viitorului Modelelor Mari de Limbaj. Înțelegi conceptele de bază ale RL, de ce este folosit pentru LLM-uri, și ai fost introdus la GRPO, un algoritm cheie în acest domeniu.
+
+În următorul modul, ne vom murdări mâinile și ne vom scufunda în lucrarea DeepSeek R1 pentru a vedea aceste concepte în acțiune!
+
+## Quiz
+
+### 1. Care sunt componentele cheie ale Învățării prin Întărire?
+
+
+
+### 2. Care este principalul avantaj al RLHF pentru antrenarea modelelor de limbaj?
+
+
+
+### 3. În contextul RL pentru LLM-uri, ce reprezintă o "acțiune"?
+
+
+
+### 4. Care este rolul recompenselor în antrenamentul RL al modelelor de limbaj?
+
+
+
+### 5. Ce este o recompensă în contextul RL pentru LLM-uri?
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter12/3.mdx b/chapters/rum/chapter12/3.mdx
new file mode 100644
index 000000000..1cd3a12e2
--- /dev/null
+++ b/chapters/rum/chapter12/3.mdx
@@ -0,0 +1,334 @@
+# Înțelegerea Lucrării DeepSeek R1
+
+Acest capitol este un curs intensiv de lectură a unei lucrări. Vom parcurge lucrarea în termeni simpli, și apoi vom descompune conceptele cheie și concluziile.
+
+DeepSeek R1 reprezintă un progres semnificativ în antrenarea modelelor de limbaj, în special în dezvoltarea capacităților de raționament prin învățarea prin întărire. Lucrarea introduce un nou algoritm de învățare prin întărire numit Optimizarea Relativă a Politicii de Grup (GRPO).
+
+
+
+În următorul capitol, vom construi pe această cunoaștere și vom implementa GRPO în practică.
+
+Obiectivul inițial al lucrării a fost să exploreze dacă învățarea prin întărire pură ar putea dezvolta capacități de raționament fără ajustarea fină supervizată.
+
+
+
+Până la acel moment, toate LLM-urile populare necesitau o anumită ajustare fină supervizată, pe care am explorat-o în [capitolul 11](/course/chapter11/1).
+
+
+
+## Momentul Revoluționar 'Aha'
+
+
+
+Una dintre cele mai remarcabile descoperiri în antrenarea R1-Zero a fost apariția unui fenomen cunoscut ca "Momentul Aha." Acest fenomen este oarecum similar cu modul în care oamenii experimentează realizări bruște în timpul rezolvării problemelor. Iată cum funcționează:
+
+1. Încercare Inițială: Modelul face o încercare inițială de a rezolva o problemă
+2. Recunoaștere: Recunoaște erori potențiale sau inconsistențe
+3. Auto-Corecție: Își ajustează abordarea bazat pe această recunoaștere
+4. Explicație: Poate explica de ce noua abordare este mai bună
+
+Această descoperire rezonează cu cursanții și se simte ca un moment "Eureka". Demonstrează învățarea mai degrabă decât memorarea simplă, așa că să ne luăm un moment să ne imaginăm cum se simte să ai un moment "Aha".
+
+De exemplu, imaginează-ți că încerci să rezolvi un puzzle:
+- Prima încercare: "Această piesă ar trebui să meargă aici bazat pe culoare"
+- Recunoaștere: "Dar stai, forma nu se potrivește destul de bine"
+- Corecție: "Ah, de fapt merge acolo"
+- Explicație: "Pentru că atât culoarea cât și modelul de formă se potrivesc în această poziție"
+
+Această abilitate a apărut natural din antrenamentul RL, fără a fi programată explicit, demonstrând învățarea mai degrabă decât memorarea simplă a unui proces din datele de antrenare.
+
+Cel mai ușor mod de a înțelege momentul 'Aha' este să-l vezi în acțiune. Să aruncăm o privire la un exemplu. În chat-ul de mai jos, întrebăm modelul să rezolve o problemă și UI-ul arată procesul de gândire al modelului pe măsură ce rezolvă problema.
+
+
+
+Dacă vrei să încerci Deepseek's R1, poți de asemenea să consulți [Hugging Chat](https://huggingface.co/chat/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B).
+
+## Procesul de Antrenare
+
+Antrenarea R1 a fost un proces cu mai multe faze. Să descompunem fazele și inovațiile cheie în fiecare fază.
+
+Procesul final rezultă în două modele:
+- DeepSeek-R1-Zero: Un model antrenat pur folosind învățarea prin întărire.
+- DeepSeek-R1: Un model care construiește pe fundația DeepSeek-R1-Zero și adaugă ajustare fină supervizată.
+
+| Caracteristică | DeepSeek-R1-Zero | DeepSeek-R1 |
+|---------|------------------|--------------|
+| Abordarea de Antrenare | RL Pur | Multi-fază (SFT + RL) |
+| Ajustare Fină | Niciuna | Ajustare fină supervizată |
+| Capacitate de Raționament | Emergentă | Îmbunătățită |
+| Performanța AIME | 71.0% | 79.8% |
+| Caracteristici Cheie | Raționament puternic dar probleme de lizibilitate | Consistență și lizibilitate mai bună a limbajului |
+
+În timp ce DeepSeek-R1-Zero demonstrează potențialul învățării prin întărire pure pentru dezvoltarea capacităților de raționament, DeepSeek-R1 construiește pe această fundație cu o abordare mai echilibrată care prioritizează atât performanța de raționament cât și utilizabilitatea.
+
+Procesul de antrenare implică patru faze:
+
+1. Faza de Pornire la Rece
+2. Faza RL de Raționament
+3. Faza de Eșantionare prin Respingere
+4. Faza RL Diversă
+
+Să descompunem fiecare fază:
+
+### Faza de Pornire la Rece (Fundația Calității)
+
+
+
+Această fază este concepută pentru a stabili o fundație solidă pentru lizibilitatea și calitatea răspunsurilor modelului. Folosește un set de date mic de eșantioane de înaltă calitate de la R1-Zero pentru a ajusta fin modelul V3-Base. Începând cu modelul DeepSeek-V3-Base, echipa a folosit mii de eșantioane validate, de înaltă calitate de la R1-Zero pentru ajustarea fină supervizată. Această abordare inovatoare folosește un set de date mic dar de înaltă calitate pentru a stabili o lizibilitate de bază puternică și calitatea răspunsurilor.
+
+### Faza RL de Raționament (Construirea Capacităților)
+
+
+
+Faza RL de Raționament se concentrează pe dezvoltarea capacităților de raționament de bază în domenii incluzând matematica, codarea, știința și logica. Această fază folosește învățarea prin întărire bazată pe reguli, cu recompense direct legate de corectitudinea soluției.
+
+Crucial, toate sarcinile din această fază sunt 'verificabile' deci putem verifica dacă răspunsul modelului este corect sau nu. De exemplu, în cazul matematicii, putem verifica dacă răspunsul modelului este corect folosind un rezolvitor matematic.
+
+Ceea ce face această fază deosebit de inovatoare este abordarea sa de optimizare directă care elimină nevoia unui model de recompensă separat, simplificând procesul de antrenare.
+
+### Faza de Eșantionare prin Respingere (Controlul Calității)
+
+
+
+În timpul Fazei de Eșantionare prin Respingere, modelul generează eșantioane care sunt apoi filtrate printr-un proces de control al calității. DeepSeek-V3 servește ca judecător al calității, evaluând rezultatele într-un domeniu larg care se extinde dincolo de sarcinile pure de raționament. Datele filtrate sunt apoi folosite pentru ajustarea fină supervizată. Inovația acestei faze constă în abilitatea sa de a combina multiple semnale de calitate pentru a asigura rezultate de înalt standard.
+
+### Faza RL Diversă (Alinierea Largă)
+
+
+
+Faza finală RL Diversă abordează multiple tipuri de sarcini folosind o abordare hibridă sofisticată. Pentru sarcinile deterministe, folosește recompense bazate pe reguli, în timp ce sarcinile subiective sunt evaluate prin feedback LLM. Această fază își propune să atingă alinierea preferințelor umane prin abordarea sa inovatoare de recompense hibride, combinând precizia sistemelor bazate pe reguli cu flexibilitatea evaluării modelelor de limbaj.
+
+## Algoritmul: Optimizarea Relativă a Politicii de Grup (GRPO)
+
+Acum că avem o înțelegere bună a procesului de antrenare, să privim algoritmul care a fost folosit pentru a antrena modelul.
+
+Autorii descriu GRPO ca o descoperire în ajustarea fină a modelelor:
+
+
+
+Noutatea GRPO constă în capacitatea sa de a "optimiza direct pentru rectificarea preferințelor." Aceasta semnifică o rută mai directă și eficientă către alinierea modelului cu rezultatele dorite, contrastând cu algoritmii tradiționali de Învățare prin Întărire precum PPO. Să descompunem cum funcționează GRPO prin cele trei componente principale ale sale.
+
+### Formarea Grupurilor: Crearea de Multiple Soluții
+
+Primul pas în GRPO este remarcabil de intuitiv - este similar cu modul în care un student ar putea rezolva o problemă dificilă încercând multiple abordări. Când primește o comandă, modelul nu generează doar un răspuns; în schimb, creează multiple încercări de a rezolva aceeași problemă (de obicei 4, 8 sau 16 încercări diferite).
+
+Imaginează-ți că înveți un model să rezolve probleme de matematică. Pentru o întrebare despre numărarea puilor de pe o fermă, modelul ar putea genera mai multe soluții diferite:
+- O soluție ar putea descompune problema pas cu pas: prima numărarea puilor totali, apoi scăderea cocoșilor, și în final contabilizarea găinilor care nu produc ouă
+- Altă soluție ar putea folosi o abordare diferită dar la fel de validă
+- Unele încercări ar putea conține greșeli sau soluții mai puțin eficiente
+
+Toate aceste încercări sunt păstrate împreună ca grup, aproape ca să ai mai mulți studenti cu soluții de comparat și din care să înveți.
+
+
+
+### Învățarea Preferințelor: Înțelegerea Ce Face o Soluție Bună
+
+Aici este unde GRPO cu adevărat strălucește în simplitatea sa. Spre deosebire de alte metode pentru RLHF care întotdeauna necesită un model de recompensă separat pentru a prezice cât de bună ar putea fi o soluție, GRPO poate folosi orice funcție sau model pentru a evalua calitatea unei soluții. De exemplu, am putea folosi o funcție de lungime pentru a recompensa răspunsuri mai scurte sau un rezolvitor matematic pentru a recompensa soluții matematice precise.
+
+Procesul de evaluare privește la diverse aspecte ale fiecărei soluții:
+- Este răspunsul final corect?
+- A urmat soluția formatarea corespunzătoare (cum ar fi folosirea tag-urilor XML corecte)?
+- Se potrivește raționamentul cu răspunsul oferit?
+
+Ceea ce face această abordare deosebit de inteligentă este modul în care gestionează evaluarea. În loc să dea doar scoruri absolute, GRPO normalizează recompensele în cadrul fiecărui grup. Folosește o formulă simplă dar eficientă pentru estimarea avantajului relativ al grupului:
+
+```
+Avantaj = (recompensă - mean(recompense_grup)) / std(recompense_grup)
+```
+
+
+
+Această normalizare este ca să notezi pe o curbă, dar pentru AI. Ajută modelul să înțeleagă care soluții din cadrul grupului au fost mai bune sau mai rele comparativ cu colegii lor, mai degrabă decât să se uite doar la scoruri absolute.
+
+### Optimizarea: Învățarea din Experiență
+
+Pasul final este unde GRPO îi învață modelul să se îmbunătățească bazat pe ceea ce a învățat din evaluarea grupului de soluții. Acest proces este atât puternic cât și stabil, folosind două principii principale:
+
+1. Încurajează modelul să producă mai multe soluții ca cele de succes în timp ce se îndepărtează de abordările mai puțin eficiente
+2. Include un mecanism de siguranță (numit penalitate de divergență KL) care previne modelul să se schimbe prea drastic dintr-o dată
+
+Această abordare se dovedește mai stabilă decât metodele tradiționale pentru că:
+- Se uită la multiple soluții împreună mai degrabă decât să compare doar două pe rând
+- Normalizarea bazată pe grup ajută la prevenirea problemelor cu scalarea recompenselor
+- Penalitatea KL acționează ca o plasă de siguranță, asigurându-se că modelul nu uită ce știa deja în timp ce învață lucruri noi
+
+
+
+Inovațiile cheie ale GRPO sunt:
+- Învățarea direct din orice funcție sau model, eliminând dependența de un model de recompensă separat.
+- Învățarea bazată pe grup, care este mai stabilă și eficientă decât metodele tradiționale cum ar fi comparațiile perechi.
+
+
+
+Această descompunere este complexă, dar concluzia cheie este că GRPO este o modalitate mai eficientă și stabilă de a antrena un model să raționeze.
+
+### Algoritmul GRPO în Pseudocod
+
+Acum că înțelegem componentele cheie ale GRPO, să privim algoritmul în pseudocod. Aceasta este o versiune simplificată a algoritmului, dar surprinde ideile cheie.
+
+```
+Input:
+- initial_policy: Modelul de început care va fi antrenat
+- reward_function: Funcția care evaluează rezultatele
+- training_prompts: Set de exemple de antrenare
+- group_size: Numărul de rezultate per comandă (de obicei 4-16)
+
+Algoritm GRPO:
+1. Pentru fiecare iterație de antrenare:
+ a. Setează reference_policy = initial_policy (captura politica actuală)
+ b. Pentru fiecare comandă în lot:
+ i. Generează group_size rezultate diferite folosind initial_policy
+ ii. Calculează recompensele pentru fiecare rezultat folosind reward_function
+ iii. Normalizează recompensele în cadrul grupului:
+ normalized_advantage = (recompensă - mean(recompense)) / std(recompense)
+ iv. Actualizează politica maximizând rația tăiată:
+ min(prob_ratio * normalized_advantage,
+ clip(prob_ratio, 1-epsilon, 1+epsilon) * normalized_advantage)
+ - kl_weight * KL(initial_policy || reference_policy)
+
+ unde prob_ratio este current_prob / reference_prob
+
+Output: Model de politică optimizat
+```
+
+Acest algoritm arată cum GRPO combină estimarea avantajului bazat pe grup cu optimizarea politicii menținând în același timp stabilitatea prin tăiere și constrângeri de divergență KL.
+
+## Rezultate și Impact
+
+Acum că am explorat algoritmul, să privim rezultatele. DeepSeek R1 atinge performanțe de ultimă generație în multiple domenii:
+
+| Domeniu | Rezultate Cheie |
+|--------|-------------|
+| Matematică | • 79.8% pe AIME 2024
• 97.3% pe MATH-500 |
+| Codare | • Rating Codeforces: 2029
• LiveCodeBench: 65.9% |
+| Cunoștințe Generale | • MMLU: 90.8%
• GPQA Diamond: 71.5% |
+| Sarcini de Limbaj | • AlpacaEval 2.0: 87.6% rată de câștig
• FRAMES: 82.5% |
+
+Impactul practic al modelului se extinde dincolo de benchmark-uri prin prețurile sale cost-eficiente ale API-ului ($0.14 per milion de token-uri de intrare) și distilarea cu succes a modelului în diverse dimensiuni (1.5B la 70B parametri). În mod notabil, chiar și modelul de 7B atinge 55.5% pe AIME 2024, în timp ce versiunea distilată de 70B se apropie de performanța o1-mini pe MATH-500 (94.5%), demonstrând conservarea eficientă a capacităților la diferite scale.
+
+## Limitări și Provocări ale GRPO
+
+În timp ce GRPO reprezintă un progres semnificativ în învățarea prin întărire pentru modelele de limbaj, este important să înțelegem limitările și provocările sale:
+
+- **Costul Generării**: Generarea de multiple completări (4-16) pentru fiecare prompt crește cerințele computaționale comparativ cu metodele care generează doar una sau două completări.
+- **Constrângerile Dimensiunii Lotului**: Nevoia de a procesa grupuri de completări împreună poate limita dimensiunile eficiente ale loturilor, adăugând complexitate procesului de antrenare și potențial încetinind antrenarea.
+- **Designul Funcției de Recompensă**: Calitatea antrenamentului depinde foarte mult de funcții de recompensă bine concepute. Recompensele prost concepute pot duce la comportamente neintenționate sau optimizarea pentru obiectivele greșite.
+- **Compromisurile Dimensiunii Grupului**: Alegerea dimensiunii optime a grupului implică echilibrarea diversității soluțiilor împotriva costului computațional. Prea puține eșantioane s-ar putea să nu ofere suficientă diversitate, în timp ce prea multe cresc timpul de antrenare și cerințele de resurse.
+- **Reglarea Divergenței KL**: Găsirea echilibrului potrivit pentru penalitatea divergenței KL necesită reglare atentă - prea mare și modelul nu va învăța eficient, prea mică și poate devia prea departe de capacitățile sale inițiale.
+
+## Concluzie
+
+Lucrarea DeepSeek R1 reprezintă o piatră de hotar semnificativă în dezvoltarea modelelor de limbaj. Algoritmul Group Relative Policy Optimization (GRPO) a demonstrat că învățarea prin întărire pură poate într-adevăr dezvolta capacități puternice de raționament, provocând presupunerile anterioare despre necesitatea ajustării fine supervizate.
+
+Poate cel mai important, DeepSeek R1 a arătat că este posibil să echilibrezi performanța înaltă cu considerații practice precum cost-eficiența și accesibilitatea. Distilarea cu succes a capacităților modelului în diferite dimensiuni, de la 1.5B la 70B parametri, demonstrează o cale înainte pentru a face capacitățile AI avansate mai larg disponibile.
+
+---
+
+În următoarea secțiune, vom explora implementări practice ale acestor concepte, concentrându-ne pe cum să folosești GRPO și RFTrans în propriile tale proiecte de dezvoltare a modelelor de limbaj.
+
+## Quiz
+
+### 1. Care este principala inovație a lucrării DeepSeek R1?
+
+
+
+### 2. Care sunt cele patru faze ale procesului de antrenare DeepSeek R1?
+
+
+
+### 3. Ce este fenomenul 'Momentul Aha' în antrenarea R1-Zero?
+
+
+
+### 4. Cum funcționează formarea grupurilor în GRPO?
+
+
+
+### 5. Care este diferența cheie între DeepSeek-R1-Zero și DeepSeek-R1?
+
+
\ No newline at end of file
diff --git a/chapters/rum/chapter12/3a.mdx b/chapters/rum/chapter12/3a.mdx
new file mode 100644
index 000000000..9d4522cb6
--- /dev/null
+++ b/chapters/rum/chapter12/3a.mdx
@@ -0,0 +1,391 @@
+# Înțelegerea Avansată a Optimizării Relative a Politicii de Grup (GRPO) în DeepSeekMath
+
+
+
+Această secțiune se scufundă în detaliile tehnice și matematice ale GRPO. A fost scrisă de [Shirin Yamani](https://github.com/shirinyamani).
+
+
+
+Să ne aprofundăm înțelegerea GRPO astfel încât să putem îmbunătăți procesul de antrenare al modelului nostru.
+
+GRPO evaluează direct răspunsurile generate de model comparându-le în cadrul grupurilor de generare pentru a optimiza modelul de politică, în loc să antreneze un model de valoare separat (Critic). Această abordare duce la o reducere semnificativă a costului computațional!
+
+GRPO poate fi aplicat la orice sarcină verificabilă unde corectitudinea răspunsului poate fi determinată. De exemplu, în raționamentul matematic, corectitudinea răspunsului poate fi ușor verificată prin compararea acestuia cu adevărul de bază.
+
+Înainte de a ne scufunda în detaliile tehnice, să vizualizăm cum funcționează GRPO la un nivel înalt:
+
+
+
+Acum că avem o prezentare vizuală, să descompunem cum funcționează GRPO pas cu pas.
+
+## Algoritmul GRPO
+
+Inovația principală a GRPO este abordarea sa de evaluare și învățare din multiple răspunsuri generate simultan. În loc să se bazeze pe un model de recompensă separat, compară rezultatele din același grup pentru a determina care ar trebui să fie întărite.
+
+Să parcurgem fiecare pas al algoritmului în detaliu:
+
+### Pasul 1: Eșantionarea Grupului
+
+Primul pas este să genereze multiple răspunsuri posibile pentru fiecare întrebare. Aceasta creează un set divers de rezultate care pot fi comparate între ele.
+
+Pentru fiecare întrebare $q$, modelul va genera $G$ rezultate (dimensiunea grupului) din politica antrenată: ${o_1, o_2, o_3, \dots, o_G}\pi_{\theta_{\text{old}}}$, $G=8$ unde fiecare $o_i$ reprezintă o completare din model.
+
+#### Exemplu:
+
+Pentru a face acest lucru concret, să ne uităm la o problemă aritmetică simplă:
+
+- **Întrebarea** $q$ : $\text{Calculează}\space2 + 2 \times 6$
+- **Rezultatele** $(G = 8)$: $\{o_1:14 \text{ (corect)}, o_2:16 \text{ (greșit)}, o_3:10 \text{ (greșit)}, \ldots, o_8:14 \text{ (corect)}\}$
+
+Observă cum unele dintre răspunsurile generate sunt corecte (14) în timp ce altele sunt greșite (16 sau 10). Această diversitate este crucială pentru următorul pas.
+
+### Pasul 2: Calculul Avantajului
+
+Odată ce avem multiple răspunsuri, avem nevoie de o modalitate de a determina care sunt mai bune decât altele. Aici intervine calculul avantajului.
+
+#### Distribuția Recompenselor:
+
+În primul rând, atribuim un scor de recompensă fiecărui răspuns generat. În acest exemplu, vom folosi un model de recompensă, dar după cum am învățat în secțiunea anterioară, putem folosi orice funcție care returnează recompense.
+
+Atribuie un scor RM fiecăruia dintre răspunsurile generate bazat pe corectitudine $r_i$ *(de exemplu, 1 pentru răspuns corect, 0 pentru răspuns greșit)* apoi pentru fiecare dintre $r_i$ calculează următoarea valoare de Avantaj
+
+#### Formula Valorii Avantajului:
+
+Ideea cheie a GRPO este că nu avem nevoie de măsuri absolute ale calității - putem compara rezultatele în cadrul aceluiași grup. Aceasta se face folosind standardizarea:
+
+$$A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \ldots, r_G\})}{\text{std}(\{r_1, r_2, \ldots, r_G\})}$$
+
+#### Exemplu:
+
+Continuând cu exemplul nostru aritmetic pentru același exemplu de mai sus, imaginează-ți că avem 8 răspunsuri, 4 dintre care sunt corecte și restul greșite, prin urmare:
+- Media Grupului: $mean(r_i) = 0.5$
+- Std: $std(r_i) = 0.53$
+- Valoarea Avantajului:
+ - Răspuns corect: $A_i = \frac{1 - 0.5}{0.53}= 0.94$
+ - Răspuns greșit: $A_i = \frac{0 - 0.5}{0.53}= -0.94$
+
+#### Interpretarea:
+
+Acum că am calculat valorile avantajului, să înțelegem ce înseamnă:
+
+Această standardizare (adică ponderarea $A_i$) permite modelului să evalueze performanța relativă a fiecărui răspuns, ghidând procesul de optimizare să favorizeze răspunsurile care sunt mai bune decât media (recompensă mare) și să descurajeze pe cele care sunt mai rele. De exemplu, dacă $A_i > 0$, atunci $o_i$ este un răspuns mai bun decât nivelul mediu din grupul său; și dacă $A_i < 0$, atunci $o_i$ atunci calitatea răspunsului este mai mică decât media (adică calitate/performanță slabă).
+
+Pentru exemplul de mai sus, dacă $A_i = 0.94 \text{(rezultat corect)}$ atunci în timpul pașilor de optimizare probabilitatea sa de generare va fi crescută.
+
+Cu valorile avantajului noastre calculate, suntem acum gata să actualizăm politica.
+
+### Pasul 3: Actualizarea Politicii
+
+Pasul final este să folosim aceste valori ale avantajului pentru a actualiza modelul nostru astfel încât să devină mai probabil să genereze răspunsuri bune în viitor.
+
+Funcția țintă pentru actualizarea politicii este:
+
+$$J_{GRPO}(\theta) = \left[\frac{1}{G} \sum_{i=1}^{G} \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right)\right]- \beta D_{KL}(\pi_{\theta} || \pi_{ref})$$
+
+Această formulă ar putea părea intimidantă la început, dar este construită din mai multe componente care fiecare servesc un scop important. Să le descompunem una câte una.
+
+## Componentele Cheie ale Funcției Țintă
+
+Funcția de actualizare GRPO combină mai multe tehnici pentru a asigura o învățare stabilă și eficientă. Să examinăm fiecare componentă:
+
+### 1. Raportul de Probabilitate
+
+Raportul de probabilitate este definit ca:
+
+$\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}\right)$
+
+Intuitiv, formula compară cât de mult diferă probabilitatea de răspuns a modelului nou de probabilitatea de răspuns a modelului vechi în timp ce încorporează o preferință pentru răspunsuri care îmbunătățesc rezultatul așteptat.
+
+#### Interpretarea:
+- Dacă $\text{raport} > 1$, modelul nou atribuie o probabilitate mai mare răspunsului $o_i$ decât modelul vechi.
+- Dacă $\text{raport} < 1$, modelul nou atribuie o probabilitate mai mică lui $o_i$
+
+Acest raport ne permite să controlăm cât de mult se schimbă modelul la fiecare pas, ceea ce ne duce la următoarea componentă.
+
+### 2. Funcția de Tăiere
+
+Funcția de tăiere este definită ca:
+
+$\text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon\right)$
+
+Limitează raportul discutat mai sus să fie în intervalul $[1 - \epsilon, 1 + \epsilon]$ pentru a evita/controla schimbări drastice sau actualizări nebunești și să nu pășească prea departe de politica veche. Cu alte cuvinte, limitează cât de mult poate crește raportul de probabilitate pentru a ajuta la menținerea stabilității prin evitarea actualizărilor care împing modelul nou prea departe de cel vechi.
+
+#### Exemplu $\space \text{să presupunem}(\epsilon = 0.2)$
+Să ne uităm la două scenarii diferite pentru a înțelege mai bine această funcție de tăiere:
+
+- **Cazul 1**: dacă noua politică are o probabilitate de 0.9 pentru un răspuns specific și vechea politică are o probabilitate de 0.5, înseamnă că acest răspuns este întărit de noua politică să aibă o probabilitate mai mare, dar într-o limită controlată care este tăierea pentru a-și strânge mâinile să nu devină drastică
+ - $\text{Raport}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.9}{0.5} = 1.8 → \text{Clip}\space1.2$ (limita superioară 1.2)
+- **Cazul 2**: Dacă noua politică nu este în favoarea unui răspuns (probabilitate mai mică de exemplu 0.2), însemnând dacă răspunsul nu este benefic creșterea ar putea fi incorectă, și modelul ar fi penalizat.
+ - $\text{Raport}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.2}{0.5} = 0.4 →\text{Clip}\space0.8$ (limita inferioară 0.8)
+#### Interpretarea:
+- Formula încurajează modelul nou să favorizeze răspunsuri pe care modelul vechi le-a subponderat **dacă ele îmbunătățesc rezultatul**.
+- Dacă modelul vechi deja favoriza un răspuns cu o probabilitate mare, modelul nou poate totuși să-l întărească **dar doar într-o limită controlată $[1 - \epsilon, 1 + \epsilon]$, $\text{(de exemplu, }\epsilon = 0.2, \space \text{deci} \space [0.8-1.2])$**.
+- Dacă modelul vechi a supraestimat un răspuns care performează prost, modelul nou este **descurajat** să mențină acea probabilitate mare.
+- Prin urmare, intuitiv, prin încorporarea raportului de probabilitate, funcția obiectiv asigură că actualizările politicii sunt proporționale cu avantajul $A_i$ în timp ce sunt moderate pentru a preveni schimbări drastice.
+
+În timp ce funcția de tăiere ajută la prevenirea schimbărilor drastice, avem nevoie de încă o măsură de protecție pentru a ne asigura că modelul nostru nu deviază prea departe de comportamentul său original.
+
+### 3. Divergența KL
+
+Termenul de divergență KL este:
+
+$\beta D_{KL}(\pi_{\theta} || \pi_{ref})$
+
+În termenul de divergență KL, $\pi_{ref}$ este practic rezultatul modelului pre-actualizare, `per_token_logps` și $\pi_{\theta}$ este rezultatul modelului nou, `new_per_token_logps`. Teoretic, divergența KL este minimizată pentru a preveni modelul să devieze prea departe de comportamentul său original în timpul optimizării. Aceasta ajută să găsească un echilibru între îmbunătățirea performanței bazată pe semnalul de recompensă și menținerea coerenței. În acest context, minimizarea divergenței KL reduce riscul ca modelul să genereze text fără sens sau, în cazul raționamentului matematic, să producă răspunsuri extrem de incorecte.
+
+#### Interpretarea
+- O penalitate de divergență KL păstrează rezultatele modelului aproape de distribuția sa originală, prevenind schimbări extreme.
+- În loc să derive către rezultate complet iraționale, modelul și-ar rafina înțelegerea în timp ce încă permite unele explorări
+
+#### Definiția Matematică
+Pentru cei interesați de detaliile matematice, să ne uităm la definiția formală:
+
+Să ne amintim că distanța KL este definită după cum urmează:
+$$D_{KL}(P || Q) = \sum_{x \in X} P(x) \log \frac{P(x)}{Q(x)}$$
+În RLHF, cele două distribuții de interes sunt adesea distribuția versiunii noului model, P(x), și o distribuție a politicii de referință, Q(x).
+
+#### Rolul Parametrului $\beta$
+
+Coeficientul $\beta$ controlează cât de puternic impunem constrângerea divergenței KL:
+
+- **$\beta$ Mai Mare (Penalitate KL Mai Puternică)**
+ - Mai multă constrângere asupra actualizărilor politicii. Modelul rămâne aproape de distribuția sa de referință.
+ - Poate încetini adaptarea: Modelul ar putea avea dificultăți să exploreze răspunsuri mai bune.
+- **$\beta$ Mai Mic (Penalitate KL Mai Slabă)**
+ - Mai multă libertate să actualizeze politica: Modelul poate devia mai mult de la referință.
+ - Adaptare mai rapidă dar risc de instabilitate: Modelul ar putea învăța comportamente de hack-uire a recompenselor.
+ - Risc de supra-optimizare: Dacă modelul de recompensă este defectuos, politica ar putea genera rezultate fără sens.
+- **Originala** [DeepSeekMath](https://arxiv.org/abs/2402.03300) lucrare a setat acest $\beta= 0.04$
+
+Acum că înțelegem componentele GRPO, să vedem cum funcționează împreună într-un exemplu complet.
+
+## Exemplu Lucrat cu GRPO
+
+Pentru a ne solidifica înțelegerea GRPO, să parcurgem un exemplu complet de la început la sfârșit.
+
+### Problema Exemplu
+
+$$\text{Î: Calculează}\space2 + 2 \times 6$$
+
+### Pasul 1: Eșantionarea Grupului
+
+În primul rând, generăm multiple răspunsuri din modelul nostru:
+
+Generează $(G = 8)$ răspunsuri, $4$ dintre care sunt răspunsul corect ($14, \text{recompensă=} 1$) și $4$ incorecte $\text{(recompensă= 0)}$, Prin urmare:
+
+$${o_1:14(corect), o_2:10 (greșit), o_3:16 (greșit), ... o_G:14(corect)}$$
+
+### Pasul 2: Calculul Avantajului
+
+Apoi, calculăm valorile avantajului pentru a determina care răspunsuri sunt mai bune decât media:
+
+- Media Grupului:
+$$mean(r_i) = 0.5$$
+- Std: $$std(r_i) = 0.53$$
+- Valoarea Avantajului:
+ - Răspuns corect: $A_i = \frac{1 - 0.5}{0.53}= 0.94$
+ - Răspuns greșit: $A_i = \frac{0 - 0.5}{0.53}= -0.94$
+
+### Pasul 3: Actualizarea Politicii
+
+În final, actualizăm modelul nostru pentru a întări răspunsurile corecte:
+
+- Presupunând că probabilitatea vechii politici ($\pi_{\theta_{old}}$) pentru un rezultat corect $o_1$ este $0.5$ și noua politică o crește la $0.7$ atunci:
+$$\text{Raport}: \frac{0.7}{0.5} = 1.4 →\text{după Clip}\space1.2 \space (\epsilon = 0.2)$$
+- Apoi când funcția țintă este re-ponderată, modelul tinde să întărească generarea rezultatului corect, și $\text{Divergența KL}$ limitează deviația de la politica de referință.
+
+Cu înțelegerea teoretică la locul ei, să vedem cum poate fi implementat GRPO în cod.
+
+## Exemplu de Implementare
+
+Să punem totul împreună într-un exemplu practic. Următorul cod demonstrează cum să implementezi GRPO în PyTorch.
+
+### 1. Încărcarea Modelului și Generarea Răspunsurilor
+
+În primul rând, trebuie să încărcăm un model și să generăm multiple răspunsuri pentru o întrebare dată:
+
+```python
+import torch
+import torch.nn.functional as F
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+# Încarcă modelul și tokenizer-ul
+model_name = "Qwen/Qwen2-Math-1.5B"
+model = AutoModelForCausalLM.from_pretrained(model_name)
+tokenizer = AutoTokenizer.from_pretrained(model_name)
+model.eval()
+
+# Mută modelul pe GPU dacă este disponibil
+device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+model.to(device)
+
+# Prompt de intrare
+prompt = "Rezolvă y = 2x + 1 pentru x = 2, y = " # Răspuns corect: 5
+inputs = tokenizer(prompt, return_tensors="pt", padding=True)
+input_ids = inputs["input_ids"].to(device) # Forma: (1, prompt_len)
+attention_mask = inputs["attention_mask"].to(device)
+
+# Pasul 1: Generează 8 răspunsuri (B = 2 grupuri, G = 4 răspunsuri per grup)
+batch_size, num_generations = 2, 4
+outputs = model.generate(
+ input_ids=input_ids, # Forma: (1, prompt_len)
+ attention_mask=attention_mask,
+ max_new_tokens=1, # seq_len = 1 (un singur token per răspuns)
+ num_return_sequences=batch_size * num_generations, # 8 răspunsuri în total
+ do_sample=True,
+ top_k=10,
+ temperature=0.7,
+ pad_token_id=tokenizer.eos_token_id,
+ return_dict_in_generate=True,
+ output_scores=True,
+)
+```
+
+această Generare inițială (Înainte de Orice Pași) va produce ceva de genul:
+
+```text
+Rezultatul 1: 5.0
+Rezultatul 2: 6.0
+Rezultatul 3: 7.0
+Rezultatul 4: 5.0
+Rezultatul 5: 10.0
+Rezultatul 6: 2.0
+Rezultatul 7: 5.0
+Rezultatul 8: 5.0
+```
+
+### 2. Calcularea Recompenselor
+
+Acum, trebuie să determinăm care răspunsuri sunt corecte și să atribuim recompense în consecință:
+
+Cu GRPO, cu același prompt de eșantion, generăm multiple completări. Deci, de exemplu, pentru prompt-urile noastre de `"Rezolvă y = 2x + 1 pentru x = 2, y = "` și `Rezolvă y = 2x + 1 pentru x = 4, y = "` avem două grupuri de rezultate generate pentru prompt-ul dat unul este să zicem
+- `[5, 6, 7, 5]` și celălalt este
+- `[10, 2, 9, 9]` în timp ce răspunsul corect este 5 și 9.
+
+Observă că în practică aceste scoruri de recompensă sunt obținute printr-o funcție de recompensă bazată pe reguli care atribuie recompense bazate pe corectitudinea răspunsului sau un model mai complex bazat pe rețele neuronale care poate fi antrenat să atribuie recompense bazate pe corectitudinea răspunsului sau un amestec din ambele. Dar pentru simplitate să spunem că recompensa noastră per răspuns este 1 dacă răspunsul este corect și 0 dacă este greșit, prin urmare:
+```python
+reward_1 = [1, 0, 0, 1]
+reward_2 = [0, 0, 1, 1]
+```
+apoi obținem media și std-ul grupului de recompense;
+
+```python
+# Forma: (B * G,) = (8,) pentru că avem 2 grupuri de 4 generări pe care le aplatizăm
+rewards = torch.tensor([1, 0, 0, 1, 0, 0, 1, 1], dtype=torch.float32)
+num_generations = 4
+
+# Recompense grupate: Forma (B, G) = 2, 4)
+rewards_grouped = rewards.view(-1, num_generations)
+
+# Media per grup: Forma (B,) = (2,)
+mean_grouped_rewards = rewards_grouped.mean(dim=1)
+
+# Std per grup: Forma (B,) = (2,)
+std_grouped_rewards = rewards_grouped.std(dim=1)
+
+# Difuzează pentru a se potrivi cu recompensele și normalizează: Forma (B * G,) = (8,)
+# de ce avem nevoie să difuzăm? pentru că trebuie să calculăm valorile avantajului pentru fiecare răspuns din grup
+mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(num_generations, dim=0)
+std_grouped_rewards = std_grouped_rewards.repeat_interleave(num_generations, dim=0)
+```
+aceasta va produce:
+```text
+Recompense Grupate: tensor([[1., 0., 0., 1.],
+ [0., 0., 1., 1.]])
+Media per grup: tensor([0.5000, 0.5000])
+Std per grup: tensor([0.5774, 0.5774])
+Media Difuzată: tensor([0.5000, 0.5000, 0.5000, 0.5000, 0.5000, 0.5000, 0.5000, 0.5000])
+Std Difuzat: tensor([0.5774, 0.5774, 0.5774, 0.5774, 0.5774, 0.5774, 0.5774, 0.5774])
+```
+Acum putem calcula valorile avantajului pentru fiecare răspuns:
+```python
+# Avantaje: Forma (B * G,) = (8,)
+advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-8)
+```
+aceasta va produce:
+```text
+Avantaje: tensor([ 0.8659, -0.8660, -0.8660, 0.8659, -0.8660, -0.8660, 0.8659, 0.8659])
+```
+care vine din formula Avantajului de mai sus, deci:
+```text
+Pentru reward_1 = [1, 0, 0, 1]:
+1 - 0.5 / 0.5774 ≈ 0.8659
+0 - 0.5 / 0.5774 ≈ -0.8660
+Pentru reward_2 = [0, 0, 1, 1]: Același model.
+```
+cu toate acestea, forma aici este `(B*G,) = (8,)` dar în practică, avem nevoie să avem forma de `(B, G) = (2, 4)` pentru a se potrivi cu forma logits, nu? Prin urmare, trebuie să unsqueeze tensor-ul avantajelor pentru a avea forma de `(B*G, 1) = (8, 1)` pentru a se potrivi cu forma logits.
+```python
+# Forma (B * G, 1) = (8, 1) pentru a se potrivi cu forma logits
+advantages = advantages.unsqueeze(1)
+```
+care va produce:
+```text
+Avantaje: tensor([[ 0.8659],
+ [-0.8660],
+ [-0.8660],
+ [ 0.8659],
+ [-0.8660],
+ [-0.8660],
+ [ 0.8659],
+ [ 0.8659]])
+```
+acum suntem bine, să trecem la următorul pas de actualizare a modelului de politică bazat pe valorile avantajului.
+
+### 3. Actualizarea Politicii
+În final, folosim valorile avantajului pentru a actualiza modelul nostru:
+
+```python
+# Calculează raportul de probabilitate între politicile noi și vechi
+ratio = torch.exp(
+ new_per_token_logps - per_token_logps
+) # Forma: (B*G, seq_len) seq_len este lungimea rezultatului adică numărul de token-uri generate deci aici pentru simplitate să presupunem că este 1 # (8, 1)
+```
+
+Observă că `per_token_logps` poate fi obținut prin trecerea rezultatelor generate la model și obținerea logits-urilor și apoi aplicarea funcției softmax pentru a obține probabilitățile `F.softmax(logits, dim=-1)`.
+
+```python
+# Funcția de Tăiere
+eps = self.cliprange # de exemplu 0.2
+pg_losses1 = -advantages * ratio # Forma: (B*G, seq_len) #(8, 1)
+pg_losses2 = -advantages * torch.clamp(
+ ratio, 1.0 - eps, 1.0 + eps
+) # Forma: (B*G, seq_len) #(8, 1)
+pg_loss_max = torch.max(pg_losses1, pg_losses2) # Forma: (B*G, seq_len) #(8, 1)
+
+
+# Acum Combină cu penalitatea KL # Forma: (B*G, seq_len) #(8, 1)
+per_token_loss = pg_loss_max + self.beta * per_token_kl
+```
+
+`per_token_kl` poate fi de asemenea calculat după cum urmează:
+
+```python
+# Forma: (B*G, seq_len) #(8, 1)
+per_token_kl = F.kl_div(
+ F.log_softmax(new_per_token_logps, dim=-1),
+ F.softmax(per_token_logps, dim=-1),
+ reduction="none",
+).sum(dim=-1, keepdim=True)
+```
+
+Exemplul complet poate fi găsit [aici](./basic_example.py). GRPO este de asemenea implementat de excelenta echipă TRL, poți verifica implementarea [TRL/GRPO_trainer](https://github.com/huggingface/trl/blob/main/trl/trainer/grpo_trainer.py) pentru mai multe detalii.
+
+## Rezumat și Pași Următori
+
+Felicitări! Acum ai învățat despre Optimizarea Relativă a Politicii de Grup (GRPO). Pentru a recapitula ce am acoperit:
+
+1. GRPO compară multiple rezultate în cadrul unui grup pentru a determina care sunt mai bune decât altele, fără a necesita un model de valoare separat.
+2. Calculul avantajului standardizează recompensele pentru a identifica care răspunsuri sunt peste sau sub medie.
+3. Actualizarea politicii folosește o funcție obiectiv tăiată cu o penalitate de divergență KL pentru a asigura învățarea stabilă.
+
+Această abordare este deosebit de puternică pentru sarcinile de raționament matematic, unde corectitudinea poate fi verificată obiectiv. Metoda GRPO permite antrenare mai eficientă comparativ cu abordările RLHF tradiționale care necesită un model critic separat.
+
+Pe măsură ce continui să explorezi GRPO, consideră să experimentezi cu diferite dimensiuni de grup, funcții de recompensă și coeficienți de penalitate KL pentru a vedea cum afectează performanța modelului tău.
+
+Antrenare fericită! 🚀
+
+## Referințe
+
+1. [Cartea RLHF de Nathan Lambert](https://github.com/natolambert/rlhf-book)
+2. [Raportul Tehnic DeepSeek-V3](https://huggingface.co/papers/2412.19437)
+3. [DeepSeekMath](https://huggingface.co/papers/2402.03300)
\ No newline at end of file
diff --git a/chapters/rum/chapter12/4.mdx b/chapters/rum/chapter12/4.mdx
new file mode 100644
index 000000000..bc50b2c7b
--- /dev/null
+++ b/chapters/rum/chapter12/4.mdx
@@ -0,0 +1,233 @@
+# Implementarea GRPO în TRL
+
+În această pagină, vom învăța cum să implementăm Optimizarea Relativă a Politicii de Grup (GRPO) folosind biblioteca Transformer Reinforcement Learning (TRL). Ne vom concentra pe implementarea practică cu cod minimal.
+
+Vom explora conceptele centrale ale GRPO așa cum sunt întruchipate în GRPOTrainer din TRL, folosind fragmente din documentația oficială TRL pentru a ne ghida.
+
+
+
+Acest capitol este destinat începătorilor TRL. Dacă ești deja familiar cu TRL, ai putea de asemenea să consulți [implementarea Open R1](https://github.com/huggingface/open-r1/blob/main/src/open_r1/grpo.py) a GRPO.
+
+
+
+În primul rând, să ne reamintim unele dintre conceptele importante ale algoritmului GRPO:
+
+- Formarea Grupului: Modelul generează multiple completări pentru fiecare prompt.
+- Învățarea Preferințelor: Modelul învață dintr-o funcție de recompensă care compară grupuri de completări.
+- Configurația Antrenamentului: Modelul folosește o configurație pentru a controla procesul de antrenare.
+
+Ce trebuie să facem pentru a implementa GRPO?
+
+- Să definim un set de date de prompt-uri.
+- Să definim o funcție de recompensă care ia o listă de completări și returnează o listă de recompense.
+- Să configurăm procesul de antrenare cu un GRPOConfig.
+- Să antrenăm modelul folosind GRPOTrainer.
+
+Iată un exemplu minimal pentru a începe antrenamentul GRPO:
+
+```python
+from trl import GRPOTrainer, GRPOConfig
+from datasets import load_dataset
+
+# 1. Încarcă setul tău de date
+dataset = load_dataset("setul_tau_de_date", split="train")
+
+
+# 2. Definește o funcție de recompensă simplă
+def reward_func(completions, **kwargs):
+ """Exemplu: Recompensează completările mai lungi"""
+ return [float(len(completion)) for completion in completions]
+
+
+# 3. Configurează antrenamentul
+training_args = GRPOConfig(
+ output_dir="output",
+ num_train_epochs=3,
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=2,
+ logging_steps=10,
+)
+
+# 4. Inițializează și antrenează
+trainer = GRPOTrainer(
+ model="modelul_tau", # de exemplu "Qwen/Qwen2-0.5B-Instruct"
+ args=training_args,
+ train_dataset=dataset,
+ reward_funcs=reward_func,
+)
+trainer.train()
+```
+
+## Componentele Cheie
+
+### 1. Formatul Setului de Date
+
+Setul tău de date ar trebui să conțină prompt-uri la care modelul va răspunde. Antrenorul GRPO va genera multiple completări pentru fiecare prompt și va folosi funcția de recompensă pentru a le compara.
+
+### 2. Funcția de Recompensă
+
+Funcția de recompensă este crucială - determină cum învață modelul. Iată două exemple practice:
+
+```python
+# Exemplul 1: Recompensă bazată pe lungimea completării
+def reward_length(completions, **kwargs):
+ return [float(len(completion)) for completion in completions]
+
+
+# Exemplul 2: Recompensă bazată pe potrivirea unui model
+import re
+
+
+def reward_format(completions, **kwargs):
+ pattern = r"^.*?.*?$"
+ return [1.0 if re.match(pattern, c) else 0.0 for c in completions]
+```
+
+### 3. Configurația Antrenamentului
+
+Parametrii cheie de considerat în `GRPOConfig`:
+
+```python
+training_args = GRPOConfig(
+ # Parametrii esențiali
+ output_dir="output",
+ num_train_epochs=3,
+ num_generation=4, # Numărul de completări de generat pentru fiecare prompt
+ per_device_train_batch_size=4, # Vrem să obținem toate generările într-un lot de dispozitiv
+ # Opțional dar util
+ gradient_accumulation_steps=2,
+ learning_rate=1e-5,
+ logging_steps=10,
+ # Specific GRPO (opțional)
+ use_vllm=True, # Accelerează generarea
+)
+```
+
+Parametrul `num_generation` este deosebit de important pentru GRPO deoarece definește dimensiunea grupului - câte completări diferite va genera modelul pentru fiecare prompt. Acesta este un diferențiator cheie de alte metode RL:
+
+- Prea mic (de exemplu, 2-3): S-ar putea să nu ofere suficientă diversitate pentru comparații semnificative
+- Recomandat (4-16): Oferă un echilibru bun între diversitate și eficiența computațională
+- Valori mai mari: Pot îmbunătăți învățarea dar cresc semnificativ costul computațional
+
+Dimensiunea grupului ar trebui aleasă în funcție de resursele tale computaționale și complexitatea sarcinii tale. Pentru sarcini simple, grupuri mai mici (4-8) pot fi suficiente, în timp ce sarcinile de raționament mai complexe ar putea beneficia de grupuri mai mari (8-16).
+
+## Sfaturi pentru Succes
+
+1. **Gestionarea Memoriei**: Ajustează `per_device_train_batch_size` și `gradient_accumulation_steps` în funcție de memoria GPU-ului tău.
+2. **Viteza**: Activează `use_vllm=True` pentru generare mai rapidă dacă modelul tău este suportat.
+3. **Monitorizarea**: Urmărește metricile înregistrate în timpul antrenamentului:
+ - `reward`: Recompensa medie pe completări
+ - `reward_std`: Deviația standard în cadrul grupurilor de recompense
+ - `kl`: Divergența KL de la modelul de referință
+
+## Designul Funcției de Recompensă
+
+Lucrarea DeepSeek R1 demonstrează mai multe abordări eficiente pentru designul funcției de recompensă pe care le poți adapta pentru propria ta implementare GRPO:
+
+### 1. Recompense Bazate pe Lungime
+
+Una dintre cele mai ușoare recompense de implementat este o recompensă bazată pe lungime. Poți recompensa completări mai lungi:
+
+```python
+def reward_len(completions, **kwargs):
+ ideal_length = 20
+ return [-abs(ideal_length - len(completion)) for completion in completions]
+```
+
+Această funcție de recompensă penalizează completările care sunt prea scurte sau prea lungi, încurajând modelul să genereze completări care sunt aproape de lungimea ideală de 20 de token-uri.
+
+
+
+
+
+## 2. Recompense Bazate pe Reguli pentru Sarcini Verificabile
+
+Pentru sarcini cu răspunsuri obiectiv corecte (cum ar fi matematica sau codarea), poți implementa funcții de recompensă bazate pe reguli:
+
+```python
+def problem_reward(completions, answers, **kwargs):
+ """Funcție de recompensă pentru probleme de matematică cu răspunsuri verificabile
+ completions: lista de completări de evaluat
+ answers: lista de răspunsuri la problemele din setul de date
+ """
+
+ rewards = []
+ for completion, correct_answer in zip(completions, answers):
+ # Extrage răspunsul din completare
+ try:
+ # Acesta este un exemplu simplificat - ai avea nevoie de parsing corespunzător
+ answer = extract_final_answer(completion)
+ # Recompensă binară: 1 pentru corect, 0 pentru incorect
+ reward = 1.0 if answer == correct_answer else 0.0
+ rewards.append(reward)
+ except:
+ # Dacă nu putem parsa un răspuns, dăm o recompensă mică
+ rewards.append(0.0)
+
+ return rewards
+```
+
+
+
+
+
+## 3. Recompense Bazate pe Format
+
+Poți de asemenea să recompensezi formatarea corespunzătoare, care a fost importantă în antrenamentul DeepSeek R1:
+
+```python
+def format_reward(completions, **kwargs):
+ """Recompensează completările care urmează formatul dorit"""
+ # Exemplu: Verifică dacă completarea urmează un format gândește-apoi-răspunde
+ pattern = r"(.*?)\s*(.*?)"
+
+ rewards = []
+ for completion in completions:
+ match = re.search(pattern, completion, re.DOTALL)
+ if match:
+ # Verifică dacă există conținut substanțial în ambele secțiuni
+ think_content = match.group(1).strip()
+ answer_content = match.group(2).strip()
+
+ if len(think_content) > 20 and len(answer_content) > 0:
+ rewards.append(1.0)
+ else:
+ rewards.append(
+ 0.5
+ ) # Recompensă parțială pentru format corect dar conținut limitat
+ else:
+ rewards.append(0.0) # Nicio recompensă pentru format incorect
+
+ return rewards
+```
+
+
+
+
+
+Aceste exemple demonstrează cum poți implementa funcții de recompensă inspirate din procesul de antrenare DeepSeek R1, concentrându-se pe corectitudine, formatare și semnale combinate.
+
+## Asta e tot!
+
+În următoarea secțiune, vei urma un exercițiu pentru a implementa GRPO în TRL.
\ No newline at end of file
diff --git a/chapters/rum/chapter12/5.mdx b/chapters/rum/chapter12/5.mdx
new file mode 100644
index 000000000..80b961e2e
--- /dev/null
+++ b/chapters/rum/chapter12/5.mdx
@@ -0,0 +1,238 @@
+
+
+# Exercițiu Practic: Ajustează fin un model cu GRPO
+
+Acum că ai văzut teoria, să o punem în practică! În acest exercițiu, vei ajusta fin un model cu GRPO.
+
+
+
+Acest exercițiu a fost scris de expertul în ajustarea fină LLM [@mlabonne](https://huggingface.co/mlabonne).
+
+
+
+## Instalează dependențele
+
+În primul rând, să instalăm dependențele pentru acest exercițiu.
+
+```bash
+!pip install -qqq datasets==3.2.0 transformers==4.47.1 trl==0.14.0 peft==0.14.0 accelerate==1.2.1 bitsandbytes==0.45.2 wandb==0.19.7 --progress-bar off
+!pip install -qqq flash-attn --no-build-isolation --progress-bar off
+```
+
+Acum vom importa bibliotecile necesare.
+
+```python
+import torch
+from datasets import load_dataset
+from peft import LoraConfig, get_peft_model
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from trl import GRPOConfig, GRPOTrainer
+```
+
+## Importă și loghează în Weights & Biases
+
+Weights & Biases este un instrument pentru înregistrarea și monitorizarea experimentelor tale. Îl vom folosi pentru a înregistra procesul nostru de ajustare fină.
+
+```python
+import wandb
+
+wandb.login()
+```
+
+Poți face acest exercițiu fără să te loghezi în Weights & Biases, dar este recomandat să faci asta pentru a-ți urmări experimentele și pentru a interpreta rezultatele.
+
+## Încarcă setul de date
+
+Acum, să încărcăm setul de date. În acest caz, vom folosi setul de date [`mlabonne/smoltldr`](https://huggingface.co/datasets/mlabonne/smoltldr), care conține o listă de povești scurte.
+
+```python
+dataset = load_dataset("mlabonne/smoltldr")
+print(dataset)
+```
+
+## Încarcă modelul
+
+Acum, să încărcăm modelul.
+
+Pentru acest exercițiu, vom folosi modelul [`SmolLM2-135M`](https://huggingface.co/HuggingFaceTB/SmolLM2-135M).
+
+Acesta este un model mic de 135M parametri care rulează pe hardware limitat. Aceasta face modelul ideal pentru învățare, dar nu este cel mai puternic model de acolo. Dacă ai acces la hardware mai puternic, poți încerca să ajustezi fin un model mai mare precum [`SmolLM2-1.7B`](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B).
+
+```python
+model_id = "HuggingFaceTB/SmolLM-135M-Instruct"
+model = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ torch_dtype="auto",
+ device_map="auto",
+ attn_implementation="flash_attention_2",
+)
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+```
+
+## Încarcă LoRA
+
+Acum, să încărcăm configurația LoRA. Vom profita de LoRA pentru a reduce numărul de parametri antrenabili, și prin urmare amprenta de memorie de care avem nevoie pentru a ajusta fin modelul.
+
+Dacă nu ești familiar cu LoRA, poți citi mai multe despre aceasta în [Capitolul 11](https://huggingface.co/learn/course/en/chapter11/3).
+
+```python
+# Încarcă LoRA
+lora_config = LoraConfig(
+ task_type="CAUSAL_LM",
+ r=16,
+ lora_alpha=32,
+ target_modules="all-linear",
+)
+model = get_peft_model(model, lora_config)
+print(model.print_trainable_parameters())
+```
+
+```sh
+Parametri antrenabili totali: 135M
+```
+
+## Definește funcția de recompensă
+
+După cum s-a menționat în secțiunea anterioară, GRPO poate folosi orice funcție de recompensă pentru a îmbunătăți modelul. În acest caz, vom folosi o funcție de recompensă simplă care încurajează modelul să genereze text lung de 50 de token-uri.
+
+```python
+# Funcția de recompensă
+ideal_length = 50
+
+
+def reward_len(completions, **kwargs):
+ return [-abs(ideal_length - len(completion)) for completion in completions]
+```
+
+## Definește argumentele de antrenament
+
+Acum, să definim argumentele de antrenament. Vom folosi clasa `GRPOConfig` pentru a defini argumentele de antrenament într-un stil tipic `transformers`.
+
+Dacă aceasta este prima dată când definești argumente de antrenament, poți verifica clasa [TrainingArguments](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainingarguments) pentru mai multe informații, sau [Capitolul 2](https://huggingface.co/learn/course/en/chapter2/1) pentru o introducere detaliată.
+
+```python
+# Argumentele de antrenament
+training_args = GRPOConfig(
+ output_dir="GRPO",
+ learning_rate=2e-5,
+ per_device_train_batch_size=8,
+ gradient_accumulation_steps=2,
+ max_prompt_length=512,
+ max_completion_length=96,
+ num_generations=8,
+ optim="adamw_8bit",
+ num_train_epochs=1,
+ bf16=True,
+ report_to=["wandb"],
+ remove_unused_columns=False,
+ logging_steps=1,
+)
+```
+
+Acum, putem inițializa antrenorul cu modelul, setul de date și argumentele de antrenament și să începem antrenamentul.
+
+```python
+# Antrenorul
+trainer = GRPOTrainer(
+ model=model,
+ reward_funcs=[reward_len],
+ args=training_args,
+ train_dataset=dataset["train"],
+)
+
+# Antrenează modelul
+wandb.init(project="GRPO")
+trainer.train()
+```
+
+Antrenamentul durează aproximativ 1 oră pe un singur GPU A10G care este disponibil pe Google Colab sau prin Hugging Face Spaces.
+
+## Împinge modelul pe Hub în timpul antrenamentului
+
+Dacă setăm argumentul `push_to_hub` la `True` și argumentul `model_id` la un nume de model valid, modelul va fi împins pe Hugging Face Hub în timp ce antrenăm. Aceasta este utilă dacă vrei să începi să testezi modelul imediat!
+
+## Interpretează rezultatele antrenamentului
+
+`GRPOTrainer` înregistrează recompensa din funcția ta de recompensă, pierderea, și o gamă de alte metrici.
+
+Ne vom concentra pe recompensa din funcția de recompensă și pierderea.
+
+După cum poți vedea, recompensa din funcția de recompensă se apropie de 0 pe măsură ce modelul învață. Acesta este un semn bun că modelul învață să genereze text de lungimea corectă.
+
+
+
+Ai putea observa că pierderea începe de la zero și apoi crește în timpul antrenamentului, ceea ce poate părea contraontuitiv. Acest comportament este așteptat în GRPO și este direct legat de formularea matematică a algoritmului. Pierderea în GRPO este proporțională cu divergența KL (capsula relativă la politica originală). Pe măsură ce antrenamentul progresează, modelul învață să genereze text care se potrivește mai bine cu funcția de recompensă, făcându-l să devieze mai mult de la politica sa inițială. Această divergență crescândă se reflectă în valoarea pierderii în creștere, care de fapt indică că modelul se adaptează cu succes pentru a optimiza funcția de recompensă.
+
+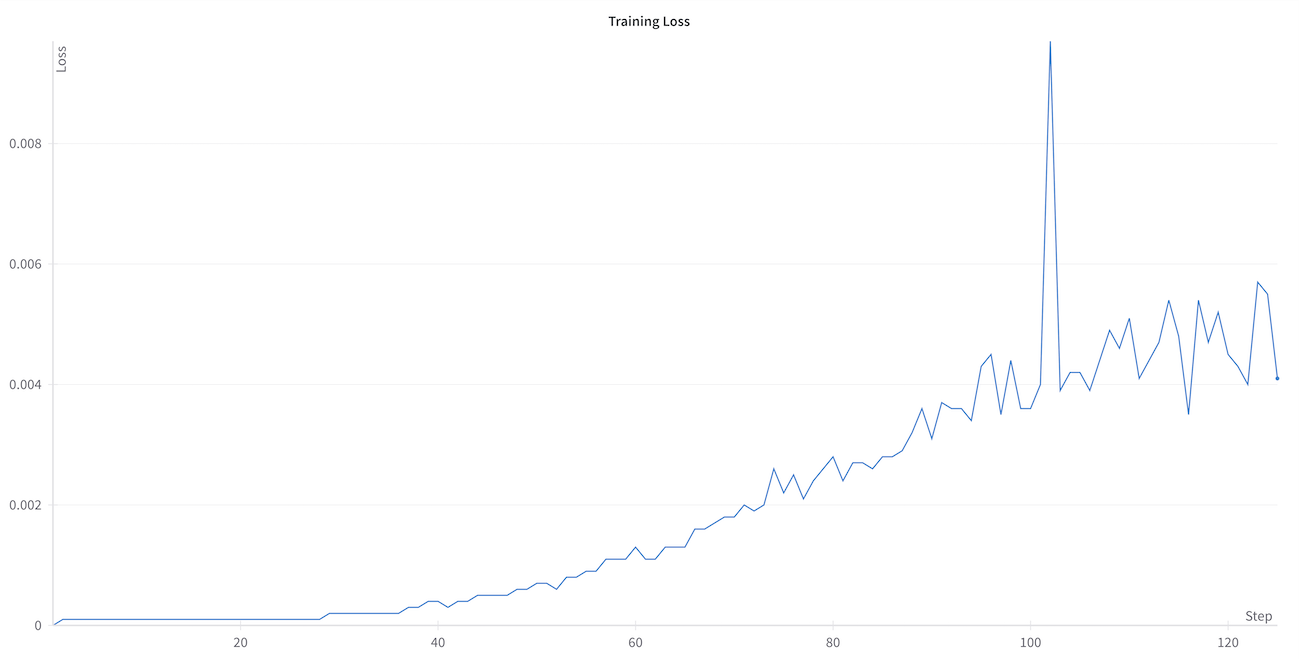
+
+## Salvează și publică modelul
+
+Să partajăm modelul cu comunitatea!
+
+```python
+merged_model = trainer.model.merge_and_unload()
+merged_model.push_to_hub(
+ "SmolGRPO-135M", private=False, tags=["GRPO", "Reasoning-Course"]
+)
+```
+
+## Generează text
+
+🎉 Ai ajustat fin cu succes un model cu GRPO! Acum, să generăm puțin text cu modelul.
+
+În primul rând, vom defini un document foarte lung!
+
+```python
+prompt = """
+# Un document lung despre pisică
+
+Pisica (Felis catus), numită și pisica domestică sau pisica de casă, este un mamifer carnivor
+mic domesticit. Este singura specie domesticită din familia Felidae. Progresele în arheologie
+și genetică au arătat că domesticirea pisicii a avut loc în Orientul Apropiat în jurul anului
+7500 î.Hr. Este ținută în mod obișnuit ca animal de companie și pisică de fermă, dar se află
+și în libertate ca pisică sălbatică evitând contactul uman. Este prețuită de oameni pentru
+companie și capacitatea sa de a ucide dăunători. Ghearele sale retractabile sunt adaptate
+pentru uciderea speciilor de pradă mici precum șoarecii și șobolanii. Are un corp puternic
+și flexibil, reflexe rapide și dinți ascuțiți, iar vederea nocturnă și simțul mirosului sunt
+bine dezvoltate. Este o specie socială, dar un vânător solitar și un prădător crepuscular.
+Comunicarea pisicii include vocalizări—incluzând mieunat, tors, triluri, șuierat, mormăit
+și grunțit—precum și limbajul corpului. Poate auzi sunete prea slabe sau prea înalte în
+frecvență pentru urechile umane, cum ar fi cele făcute de mamiferele mici. Secretă și
+percep feromoni.
+"""
+```
+
+messages = [
+ {"role": "user", "content": prompt},
+]
+
+Acum, putem genera text cu modelul.
+
+```python
+# Generează text
+from transformers import pipeline
+
+generator = pipeline("text-generation", model="SmolGRPO-135M")
+
+## Sau folosește modelul și tokenizer-ul pe care le-am definit mai devreme
+# generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+generate_kwargs = {
+ "max_new_tokens": 256,
+ "do_sample": True,
+ "temperature": 0.5,
+ "min_p": 0.1,
+}
+
+generated_text = generator(messages, generate_kwargs=generate_kwargs)
+
+print(generated_text)
+```
+
+# Concluzie
+
+În acest capitol, am văzut cum să ajustăm fin un model cu GRPO. Am văzut de asemenea cum să interpretăm rezultatele antrenamentului și să generăm text cu modelul.
diff --git a/chapters/rum/chapter12/6.mdx b/chapters/rum/chapter12/6.mdx
new file mode 100644
index 000000000..5be72a1ee
--- /dev/null
+++ b/chapters/rum/chapter12/6.mdx
@@ -0,0 +1,379 @@
+
+
+# Exercițiu Practic: GRPO cu Unsloth
+
+În acest exercițiu, vei ajusta fin un model cu GRPO (Optimizarea Relativă a Politicii de Grup) folosind Unsloth, pentru a îmbunătăți capacitățile de raționament ale unui model. Am acoperit GRPO în [Capitolul 3](/course/chapter3/3).
+
+Unsloth este o bibliotecă care accelerează ajustarea fină a LLM-urilor, făcând posibilă antrenarea modelelor mai repede și cu mai puține resurse computaționale. Unsloth se conectează la TRL, deci vom construi pe ceea ce am învățat în secțiunile anterioare, și o vom adapta pentru specificațiile Unsloth.
+
+
+
+Acest exercițiu poate fi rulat pe un GPU T4 Google Colab gratuit. Pentru cea mai bună experiență, urmărește notebook-ul legat mai sus și încearcă-l singur.
+
+
+
+## Instalează dependențele
+
+În primul rând, să instalăm bibliotecile necesare. Vom avea nevoie de Unsloth pentru ajustarea fină accelerată și vLLM pentru inferența rapidă.
+
+```bash
+pip install unsloth vllm
+pip install --upgrade pillow
+```
+
+## Configurarea Unsloth
+
+Unsloth oferă o clasă (`FastLanguageModel`) care integrează transformers cu optimizările Unsloth. Să o importăm:
+
+```python
+from unsloth import FastLanguageModel
+```
+
+Acum, să încărcăm modelul Google Gemma 3 1B Instruct și să-l configurăm pentru ajustarea fină:
+
+```python
+from unsloth import FastLanguageModel
+import torch
+
+max_seq_length = 1024 # Poate crește pentru urme de raționament mai lungi
+lora_rank = 32 # Rang mai mare = mai inteligent, dar mai lent
+
+model, tokenizer = FastLanguageModel.from_pretrained(
+ model_name="google/gemma-3-1b-it",
+ max_seq_length=max_seq_length,
+ load_in_4bit=True, # False pentru LoRA 16bit
+ fast_inference=True, # Activează inferența rapidă vLLM
+ max_lora_rank=lora_rank,
+ gpu_memory_utilization=0.6, # Reduce dacă rămâi fără memorie
+)
+
+model = FastLanguageModel.get_peft_model(
+ model,
+ r=lora_rank, # Alege orice număr > 0 ! Sugerat 8, 16, 32, 64, 128
+ target_modules=[
+ "q_proj",
+ "k_proj",
+ "v_proj",
+ "o_proj",
+ "gate_proj",
+ "up_proj",
+ "down_proj",
+ ], # Elimină QKVO dacă rămâi fără memorie
+ lora_alpha=lora_rank,
+ use_gradient_checkpointing="unsloth", # Activează ajustarea fină pentru context lung
+ random_state=3407,
+)
+```
+
+Acest cod încarcă modelul în cuantizare 4-bit pentru a economisi memoria și aplică LoRA (Adaptarea de Rang Mic) pentru ajustarea fină eficientă. Parametrul `target_modules` specifică care straturi ale modelului să fie ajustate fin, și `use_gradient_checkpointing` permite antrenarea cu contexte mai lungi.
+
+
+
+Nu vom acoperi detaliile LoRA în acest capitol, dar poți învăța mai multe în [Capitolul 11](/course/chapter11/3).
+
+
+
+## Pregătirea Datelor
+
+Pentru acest exercițiu, vom folosi setul de date GSM8K, care conține probleme de matematică de gimnaziu. Vom formata datele pentru a încuraja modelul să-și arate raționamentul înainte de a oferi un răspuns.
+
+În primul rând, vom defini formatul prompt-urilor și răspunsurilor:
+
+```python
+# Definește prompt-ul de sistem care instruiește modelul să folosească un format specific
+SYSTEM_PROMPT = """
+Răspunde în următorul format:
+
+...
+
+
+...
+
+"""
+
+XML_COT_FORMAT = """\
+
+{reasoning}
+
+
+{answer}
+
+"""
+```
+
+Acum, să pregătim setul de date:
+
+```python
+import re
+from datasets import load_dataset, Dataset
+
+
+# Funcții helper pentru a extrage răspunsuri din formate diferite
+def extract_xml_answer(text: str) -> str:
+ answer = text.split("")[-1]
+ answer = answer.split("")[0]
+ return answer.strip()
+
+
+def extract_hash_answer(text: str) -> str | None:
+ if "####" not in text:
+ return None
+ return text.split("####")[1].strip()
+
+
+# Funcție pentru a pregăti setul de date GSM8K
+def get_gsm8k_questions(split="train") -> Dataset:
+ data = load_dataset("openai/gsm8k", "main")[split]
+ data = data.map(
+ lambda x: {
+ "prompt": [
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": x["question"]},
+ ],
+ "answer": extract_hash_answer(x["answer"]),
+ }
+ )
+ return data
+
+
+dataset = get_gsm8k_questions()
+```
+
+Setul de date este pregătit prin extragerea răspunsului din setul de date și formatarea acestuia ca șir de caractere.
+
+## Definirea Funcțiilor de Recompensă
+
+După cum am discutat într-o [pagină anterioară](/course/chapter13/4), GRPO poate folosi funcții de recompensă pentru a ghida învățarea modelului bazată pe criterii verificabile precum lungimea și formatarea.
+
+În acest exercițiu, vom defini mai multe funcții de recompensă care încurajează diferite aspecte ale unui raționament bun. De exemplu, vom recompensa modelul pentru oferirea unui răspuns întreg, și pentru urmarea formatului strict.
+
+```python
+# Funcția de recompensă care verifică dacă răspunsul este corect
+def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
+ responses = [completion[0]["content"] for completion in completions]
+ q = prompts[0][-1]["content"]
+ extracted_responses = [extract_xml_answer(r) for r in responses]
+ print(
+ "-" * 20,
+ f"Întrebare:\n{q}",
+ f"\nRăspuns:\n{answer[0]}",
+ f"\nRăspuns model:\n{responses[0]}",
+ f"\nExtras:\n{extracted_responses[0]}",
+ )
+ return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
+
+
+# Funcția de recompensă care verifică dacă răspunsul este un întreg
+def int_reward_func(completions, **kwargs) -> list[float]:
+ responses = [completion[0]["content"] for completion in completions]
+ extracted_responses = [extract_xml_answer(r) for r in responses]
+ return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
+
+
+# Funcția de recompensă care verifică dacă completarea urmează formatul strict
+def strict_format_reward_func(completions, **kwargs) -> list[float]:
+ pattern = r"^\n.*?\n\n\n.*?\n\n$"
+ responses = [completion[0]["content"] for completion in completions]
+ matches = [re.match(pattern, r) for r in responses]
+ return [0.5 if match else 0.0 for match in matches]
+
+
+# Funcția de recompensă care verifică dacă completarea urmează un format mai relaxat
+def soft_format_reward_func(completions, **kwargs) -> list[float]:
+ pattern = r".*?\s*.*?"
+ responses = [completion[0]["content"] for completion in completions]
+ matches = [re.match(pattern, r) for r in responses]
+ return [0.5 if match else 0.0 for match in matches]
+
+
+# Funcția de recompensă care numără tag-urile XML și penalizează conținutul extra
+def count_xml(text) -> float:
+ count = 0.0
+ if text.count("\n") == 1:
+ count += 0.125
+ if text.count("\n\n") == 1:
+ count += 0.125
+ if text.count("\n\n") == 1:
+ count += 0.125
+ count -= len(text.split("\n\n")[-1]) * 0.001
+ if text.count("\n") == 1:
+ count += 0.125
+ count -= (len(text.split("\n")[-1]) - 1) * 0.001
+ return count
+
+
+def xmlcount_reward_func(completions, **kwargs) -> list[float]:
+ contents = [completion[0]["content"] for completion in completions]
+ return [count_xml(c) for c in contents]
+```
+
+Aceste funcții de recompensă servesc diferite scopuri:
+
+| Funcția de Recompensă | Scopul |
+|-----------------|---------|
+| `correctness_reward_func` | Recompensează modelul când răspunsul său se potrivește cu răspunsul corect |
+| `int_reward_func` | Recompensează modelul pentru oferirea unui răspuns numeric |
+| `strict_format_reward_func` și `soft_format_reward_func` | Recompensează modelul pentru urmarea formatului specificat |
+| `xmlcount_reward_func` | Recompensează utilizarea corectă a tag-urilor XML și penalizează conținutul extra după tag-urile de închidere |
+
+## Antrenarea cu GRPO
+
+Acum vom configura antrenorul GRPO cu modelul nostru, tokenizer-ul și funcțiile de recompensă. Această parte urmează aceeași abordare ca [exercițiul anterior](/course/chapter12/5).
+
+```python
+from trl import GRPOConfig, GRPOTrainer
+
+max_prompt_length = 256
+
+training_args = GRPOConfig(
+ learning_rate=5e-6,
+ adam_beta1=0.9,
+ adam_beta2=0.99,
+ weight_decay=0.1,
+ warmup_ratio=0.1,
+ lr_scheduler_type="cosine",
+ optim="paged_adamw_8bit",
+ logging_steps=1,
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=1, # Crește la 4 pentru antrenare mai lină
+ num_generations=6, # Scade dacă rămâi fără memorie
+ max_prompt_length=max_prompt_length,
+ max_completion_length=max_seq_length - max_prompt_length,
+ # num_train_epochs = 1, # Setează la 1 pentru o rulare completă de antrenare
+ max_steps=250,
+ save_steps=250,
+ max_grad_norm=0.1,
+ report_to="none", # Poate folosi Weights & Biases
+ output_dir="outputs",
+)
+
+trainer = GRPOTrainer(
+ model=model,
+ processing_class=tokenizer,
+ reward_funcs=[
+ xmlcount_reward_func,
+ soft_format_reward_func,
+ strict_format_reward_func,
+ int_reward_func,
+ correctness_reward_func,
+ ],
+ args=training_args,
+ train_dataset=dataset,
+)
+```
+
+`GRPOConfig` setează diferiți hiperparametri pentru antrenare:
+- `use_vllm`: Activează inferența rapidă cu vLLM
+- `learning_rate`: Controlează cât de repede învață modelul
+- `num_generations`: Numărul de completări de generat pentru fiecare prompt
+- `max_steps`: Numărul total de pași de antrenare de efectuat
+
+Acum să începem antrenarea:
+
+```python
+trainer.train()
+```
+
+
+
+Antrenarea poate dura ceva timp. S-ar putea să nu vezi recompensele crescând imediat - poate dura 150-200 de pași înainte să începi să vezi îmbunătățiri. Fii răbdător!
+
+
+
+## Testarea Modelului
+
+După antrenare, să testăm modelul nostru pentru a vedea cum performează. În primul rând, vom salva greutățile LoRA:
+
+```python
+model.save_lora("grpo_saved_lora")
+```
+
+Acum, să testăm modelul cu o întrebare nouă:
+
+```python
+from vllm import SamplingParams
+
+text = tokenizer.apply_chat_template(
+ [
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": "Calculează pi."},
+ ],
+ tokenize=False,
+ add_generation_prompt=True,
+)
+
+sampling_params = SamplingParams(
+ temperature=0.8,
+ top_p=0.95,
+ max_tokens=1024,
+)
+output = (
+ model.fast_generate(
+ text,
+ sampling_params=sampling_params,
+ lora_request=model.load_lora("grpo_saved_lora"),
+ )[0]
+ .outputs[0]
+ .text
+)
+
+print(output)
+```
+
+Ar trebui să vezi că modelul urmează acum formatul specificat, arătându-și raționamentul înainte de a oferi un răspuns.
+
+## Salvarea Modelului
+
+Unsloth oferă mai multe opțiuni pentru salvarea modelului tău ajustat fin, dar ne vom concentra pe cea mai comună.
+
+```python
+# Salvează cu precizie de 16 biți
+model.save_pretrained_merged("model", tokenizer, save_method="merged_16bit")
+```
+
+## Încărcarea pe Hugging Face Hub
+
+Vom încărca modelul pe Hugging Face Hub folosind metoda `push_to_hub_merged`. Această metodă ne permite să încărcăm modelul în multiple formate de cuantizare.
+```python
+# Încarcă pe Hugging Face Hub (necesită un token)
+model.push_to_hub_merged(
+ "numele-tau/numele-modelului",
+ tokenizer,
+ save_method="merged_16bit",
+ token="token-ul-tau",
+)
+```
+
+Unsloth suportă de asemenea salvarea în format GGUF pentru utilizare cu llama.cpp:
+
+```python
+model.push_to_hub_gguf(
+ "numele-tau/numele-modelului",
+ tokenizer,
+ quantization_method=["q4_k_m", "q8_0", "q5_k_m"],
+ token="token-ul-tau",
+)
+```
+
+Fișierele GGUF pot fi folosite cu llama.cpp sau sisteme bazate pe UI precum Jan sau Open WebUI.
+
+## Concluzie
+
+În acest exercițiu, ai învățat cum să:
+1. Configurezi Unsloth pentru ajustarea fină accelerată
+2. Pregătești datele pentru antrenarea GRPO
+3. Definești funcții de recompensă personalizate pentru a ghida învățarea modelului
+4. Antrenezi un model folosind GRPO
+5. Testezi modelul ajustat fin
+6. Salvezi modelul în diverse formate
+
+GRPO este o tehnică puternică pentru alinierea modelelor de limbaj cu comportamente specifice, iar Unsloth o face accesibilă chiar și pe hardware limitat. Prin combinarea mai multor funcții de recompensă, poți ghida modelul să urmeze un format specific în timp ce îi îmbunătățești și capacitățile de raționament.
+
+Pentru mai multe informații și resurse, verifică:
+- [Documentația Unsloth](https://docs.unsloth.ai/)
+- [Discord Unsloth](https://discord.gg/unsloth)
+- [GitHub Unsloth](https://github.com/unslothai/unsloth)
\ No newline at end of file
diff --git a/chapters/rum/chapter12/7.mdx b/chapters/rum/chapter12/7.mdx
new file mode 100644
index 000000000..9f4ec8722
--- /dev/null
+++ b/chapters/rum/chapter12/7.mdx
@@ -0,0 +1,18 @@
+# În curând...
+
+Acest capitol se desfășoară acum ca o cohortă live! Dacă ai terminat materialul până acum, iată la ce să te aștepți:
+
+## Programul Cursului
+
+| Data | Unitatea |
+|------|------|
+| ~7 Martie, 2025~ | ~Examen Fără Cod și Certificare~ |
+| ~14 Martie, 2025~ | ~Următorul Exercițiu Practic~ |
+| 21 Martie, 2025 | Revizuirea interactivă a codului |
+| Aprilie 2025 | Mai mult material scris despre construirea modelelor de raționament |
+| Aprilie 2025 | Sesiuni live despre construirea Open R1 |
+| Aprilie 2025 | Examen de Cod și Certificare |
+
+## Să Rămâi la Curent
+
+Dacă vrei să urmezi cursul, urmărește [The Reasoning Course](https://huggingface.co/reasoning-course) și alătură-te [comunității Discord](https://discord.gg/F3vZujJH)!
\ No newline at end of file
diff --git a/chapters/rum/chapter12/img/1.png b/chapters/rum/chapter12/img/1.png
new file mode 100644
index 000000000..a53e8a186
Binary files /dev/null and b/chapters/rum/chapter12/img/1.png differ
diff --git a/chapters/rum/chapter12/img/2.jpg b/chapters/rum/chapter12/img/2.jpg
new file mode 100644
index 000000000..d1fd22662
Binary files /dev/null and b/chapters/rum/chapter12/img/2.jpg differ
diff --git a/chapters/rum/events/1.mdx b/chapters/rum/events/1.mdx
new file mode 100644
index 000000000..02b584e9a
--- /dev/null
+++ b/chapters/rum/events/1.mdx
@@ -0,0 +1,49 @@
+# Sesiuni live și workshop-uri[[sesiuni-live-si-workshop-uri]]
+
+Pentru lansarea părților 1 și 2 ale cursului, am organizat mai multe sesiuni de codare live și workshop-uri. Puteți găsi linkuri către înregistrările acestor sesiuni și workshop-uri mai jos.
+
+## Sesiuni de codare live[[sesiuni-de-codare-live]]
+
+Pentru prima sesiune, Sylvain trece prin Capitolul 1 al cursului împreună cu voi, explicându-l pas cu pas:
+
+
+
+
+
+În a doua sesiune, este rândul lui Lewis să prezinte Capitolul 2:
+
+
+
+
+
+Pentru că Capitolul 2 este atât de interesant, Sylvain a oferit și el o prezentare pas cu pas!
+
+
+
+
+
+Pentru Capitolul 3, Lewis revine să vă ghideze prin cod:
+
+
+
+
+
+În sfârșit, Omar încheie sesiunile live legate de prima parte a cursului abordând capitolul 4:
+
+
+
+
+
+## Workshop-uri[[workshop-uri]]
+
+În primul workshop, Merve îl primește pe Lewis pentru a discuta secțiunea 7 din capitolul 7 despre [question answering]( https://huggingface.co/course/chapter7/7?fw=pt).
+
+
+
+
+
+Pentru al doilea workshop, Merve îl găzduiește pe Leandro pentru a vorbi despre capitolul 7, secțiunea 6 privind [antrenarea unui model de limbaj cauzal de la zero]( https://huggingface.co/course/chapter7/6?fw=pt) cu o aplicație cu [CodeParrot](https://huggingface.co/codeparrot).
+
+
+
+
\ No newline at end of file
diff --git a/chapters/rum/events/2.mdx b/chapters/rum/events/2.mdx
new file mode 100644
index 000000000..4d4ed3125
--- /dev/null
+++ b/chapters/rum/events/2.mdx
@@ -0,0 +1,165 @@
+# Evenimentul de lansare a părții 2[[evenimentul-de-lansare-a-partii-2]]
+
+Pentru lansarea părții 2 a cursului, am organizat un eveniment live cu două zile de prezentări înainte de un sprint de fine-tuning. Dacă l-ați ratat, puteți urmări prezentările care sunt toate listate mai jos!
+
+## Ziua 1: O viziune de ansamblu asupra Transformers și cum să îi antrenați[[ziua-1-o-viziune-de-ansamblu-asupra-transformers-si-cum-sa-ii-antrenati]]
+
+**Thomas Wolf:** *Transfer Learning și nașterea bibliotecii Transformers*
+
+
+
+
+
+
+ +
+
+
+Thomas Wolf este co-fondator și Chief Science Officer la Hugging Face. Instrumentele create de Thomas Wolf și echipa Hugging Face sunt folosite în peste 5.000 de organizații de cercetare, inclusiv Facebook Artificial Intelligence Research, Google Research, DeepMind, Amazon Research, Apple, Allen Institute for Artificial Intelligence, precum și majoritatea departamentelor universitare. Thomas Wolf este inițiatorul și președintele principal al celei mai mari colaborări de cercetare care a existat vreodată în Inteligența Artificială: ["BigScience"](https://bigscience.huggingface.co), precum și al unui set de [biblioteci și instrumente](https://github.com/huggingface/) utilizate pe scară largă. Thomas Wolf este, de asemenea, un educator prolific, un lider de opinie în domeniul Inteligenței Artificiale și Procesării Limbajului Natural, și un speaker invitat regulat la conferințe din întreaga lume [https://thomwolf.io](https://thomwolf.io).
+
+**Jay Alammar:** *O introducere vizuală ușoară la modelele Transformers*
+
+
+
+
+
+
+ +
+
+
+Prin blog-ul său popular de ML, Jay a ajutat milioane de cercetători și ingineri să înțeleagă vizual instrumentele și conceptele de machine learning de la nivel de bază (ajungând în documentația NumPy, Pandas) până la cele de ultimă generație (Transformers, BERT, GPT-3).
+
+**Margaret Mitchell:** *Despre valori în dezvoltarea ML*
+
+
+
+
+
+
+ +
+
+
+Margaret Mitchell este o cercetătoare care lucrează pe Ethical AI, concentrându-se în prezent pe aspectele dezvoltării AI informate de etică în tehnologie. A publicat peste 50 de lucrări pe generarea limbajului natural, tehnologii asistate, computer vision și etica AI, și deține multiple brevete în domeniile generării de conversații și clasificării sentimentelor. Anterior a lucrat la Google AI ca Staff Research Scientist, unde a fondat și co-condus grupul Ethical AI de la Google, concentrat pe cercetarea fundamentală în etica AI și operaționalizarea eticii AI în cadrul Google. Înainte de a se alătura Google, a fost cercetătoare la Microsoft Research, concentrându-se pe generarea de la computer vision la limbaj; și a fost postdoc la Johns Hopkins, concentrându-se pe modelarea Bayesiană și extragerea informațiilor. Deține un doctorat în Computer Science de la Universitatea din Aberdeen și un master în lingvistică computațională de la Universitatea din Washington. În timp ce și-a luat diplomele, a lucrat din 2005-2012 pe machine learning, tulburări neurologice și tehnologii asistate la Oregon Health and Science University. A condus o serie de workshop-uri și inițiative la intersecția diversității, incluziunii, informaticii și eticii. Munca ei a primit premii de la Secretarul de Apărare Ash Carter și American Foundation for the Blind, și a fost implementată de multiple companii de tehnologie. Îi place grădinăritul, câinii și pisicile.
+
+**Matthew Watson și Chen Qian:** *Workflow-uri NLP cu Keras*
+
+
+
+
+
+
+ +
+
+
+Matthew Watson este inginer de machine learning în echipa Keras, cu focus pe API-uri de modelare de nivel înalt. A studiat Computer Graphics în timpul licenței și unui master la Stanford University. Aproape o majoră în engleză care s-a îndreptat către informatică, este pasionat de lucrul interdisciplinar și de a face NLP accesibil unei audiențe mai largi.
+
+Chen Qian este inginer software din echipa Keras, cu focus pe API-uri de modelare de nivel înalt. Chen a obținut o diplomă de master în Electrical Engineering de la Stanford University, și este interesat în special de simplificarea implementărilor de cod ale sarcinilor ML și ML-ul la scară largă.
+
+**Mark Saroufim:** *Cum să antrenezi un model cu Pytorch*
+
+
+
+
+
+
+ +
+
+
+Mark Saroufim este Partner Engineer la Pytorch lucrând pe instrumente OSS de producție inclusiv TorchServe și Pytorch Enterprise. În viețile sale trecute, Mark a fost Applied Scientist și Product Manager la Graphcore, [yuri.ai](http://yuri.ai/), Microsoft și NASA's JPL. Pasiunea sa principală este să facă programarea mai distractivă.
+
+**Jakob Uszkoreit:** *Nu e stricat, așa că nu-l repara să-l stricăm*
+
+
+
+
+
+
+ +
+
+
+Jakob Uszkoreit este co-fondatorul Inceptive. Inceptive proiectează molecule de ARN pentru vaccinuri și terapeutice folosind deep learning la scară largă într-un ciclu strâns cu experimente de randament ridicat cu scopul de a face medicamentele bazate pe RNA mai accesibile, mai eficiente și mai aplicabile pe scară largă. Anterior, Jakob a lucrat la Google pentru mai mult de un deceniu, conducând echipe de cercetare și dezvoltare în Google Brain, Research și Search lucrând pe fundamentele deep learning, computer vision, înțelegerea limbajului și traducerea automată.
+
+## Ziua 2: Instrumentele de folosit[[ziua-2-instrumentele-de-folosit]]
+
+**Lewis Tunstall:** *Antrenament simplu cu 🤗 Transformers Trainer*
+
+
+
+
+
+Lewis este inginer de machine learning la Hugging Face, concentrându-se pe dezvoltarea de instrumente open-source și pe a le face accesibile comunității mai largi. Este, de asemenea, co-autor al cărții O'Reilly [Natural Language Processing with Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/). Îl puteți urmări pe Twitter (@_lewtun) pentru sfaturi și trucuri NLP!
+
+**Matthew Carrigan:** *Funcționalități noi TensorFlow pentru 🤗 Transformers și 🤗 Datasets*
+
+
+
+
+
+Matt este responsabil pentru întreținerea TensorFlow la Transformers, și în cele din urmă va conduce o lovitură de stat împotriva facțiunii PyTorch incumbente, care probabil va fi coordonată prin contul său de Twitter @carrigmat.
+
+**Lysandre Debut:** *Hugging Face Hub ca mijloc de colaborare și partajare a proiectelor de Machine Learning*
+
+
+
+
+
+
+ +
+
+
+Lysandre este Machine Learning Engineer la Hugging Face unde este implicat în multe proiecte open source. Scopul său este să facă Machine Learning accesibil pentru toată lumea prin dezvoltarea de instrumente puternice cu un API foarte simplu.
+
+**Lucile Saulnier:** *Obțineți propriul tokenizer cu 🤗 Transformers & 🤗 Tokenizers*
+
+
+
+
+
+Lucile este inginer de machine learning la Hugging Face, dezvoltând și susținând utilizarea instrumentelor open source. Este, de asemenea, implicată activ în multe proiecte de cercetare în domeniul Procesării Limbajului Natural, cum ar fi antrenamentul colaborativ și BigScience.
+
+**Sylvain Gugger:** *Supraîncărcați bucla de antrenament PyTorch cu 🤗 Accelerate*
+
+
+
+
+
+Sylvain este Research Engineer la Hugging Face și unul dintre principalii întreținători ai 🤗 Transformers și dezvoltatorul din spatele 🤗 Accelerate. Îi place să facă antrenamentul modelelor mai accesibil.
+
+**Merve Noyan:** *Prezentați demo-urile modelelor cu 🤗 Spaces*
+
+
+
+
+
+Merve este developer advocate la Hugging Face, lucrând la dezvoltarea de instrumente și construirea de conținut în jurul lor pentru a democratiza machine learning pentru toată lumea.
+
+**Abubakar Abid:** *Construirea aplicațiilor de Machine Learning rapid*
+
+
+
+
+
+
+ +
+
+
+Abubakar Abid este CEO-ul [Gradio](www.gradio.app). A primit licența în Bachelor of Science în Electrical Engineering și Computer Science de la MIT în 2015, și doctoratul în Applied Machine Learning de la Stanford în 2021. În rolul său ca CEO al Gradio, Abubakar lucrează pentru a face modelele de machine learning mai ușor de demonstrat, depanat și implementat.
+
+**Mathieu Desvé:** *AWS ML Vision: Făcând Machine Learning accesibil pentru toți clienții*
+
+
+
+
+
+
+ +
+
+
+Entuziast al tehnologiei, maker în timpul liber. Îmi plac provocările și rezolvarea problemelor clienților și utilizatorilor, și lucrul cu oameni talentați pentru a învăța în fiecare zi. Din 2004, lucrez în multiple poziții comutând între frontend, backend, infrastructură, operațiuni și management. Încerc să rezolv probleme tehnice și manageriale comune într-o manieră agilă.
+
+**Philipp Schmid:** *Antrenament gestionat cu Amazon SageMaker și 🤗 Transformers*
+
+
+
+
+
+Philipp Schmid este Machine Learning Engineer și Tech Lead la Hugging Face, unde conduce colaborarea cu echipa Amazon SageMaker. Este pasionat de democratizarea și punerea în producție a modelelor NLP de ultimă generație și îmbunătățirea ușurinței de utilizare pentru Deep Learning.
\ No newline at end of file
diff --git a/chapters/rum/events/3.mdx b/chapters/rum/events/3.mdx
new file mode 100644
index 000000000..c5b706f16
--- /dev/null
+++ b/chapters/rum/events/3.mdx
@@ -0,0 +1,9 @@
+# Petrecerea Gradio Blocks[[petrecerea-gradio-blocks]]
+
+Împreună cu lansarea capitolului Gradio al cursului, Hugging Face a găzduit un eveniment comunitar pentru construirea de demo-uri interesante de machine learning folosind noua funcționalitate Gradio Blocks.
+
+Puteți găsi toate demo-urile pe care le-a creat comunitatea sub organizația [`Gradio-Blocks`](https://huggingface.co/Gradio-Blocks) pe Hub. Iată câteva exemple de la câștigători:
+
+**Limbaj natural către SQL**
+
+
\ No newline at end of file