push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Un Trainer",
+ explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
+ correct: true
+ }
+ ]}
+/>
+
+{:else}
+push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Toate cele trei cu un callback dedicat",
+ explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
+
+huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
+ },
+ {
+ text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
+ explain: "Comanda upload-model nu există."
+ }
+ ]}
+/>
+
+### 8. Carele operații git poți face cu clasa `Repository`?
+
+git_pull()",
+ correct: true
+ },
+ {
+ text: "Un push",
+ explain: "Metoda git_push() face acest lucru.",
+ correct: true
+ },
+ {
+ text: "Un merge",
+ explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
+ }
+ ]}
+/>
\ No newline at end of file
From 1c9d20a761c0883404096211aac071e86a27953d Mon Sep 17 00:00:00 2001
From: Angroys <120798951+Angroys@users.noreply.github.com>
Date: Sun, 5 Jan 2025 01:42:24 +0200
Subject: [PATCH 05/37] Finished chapter 5 for the ro language
---
chapters/en/chapter5/3.mdx | 1 -
chapters/ro/chapter5/1.mdx | 22 ++
chapters/ro/chapter5/2.mdx | 173 +++++++++
chapters/ro/chapter5/3.mdx | 748 +++++++++++++++++++++++++++++++++++++
chapters/ro/chapter5/4.mdx | 287 ++++++++++++++
chapters/ro/chapter5/5.mdx | 404 ++++++++++++++++++++
chapters/ro/chapter5/6.mdx | 517 +++++++++++++++++++++++++
chapters/ro/chapter5/7.mdx | 16 +
chapters/ro/chapter5/8.mdx | 228 +++++++++++
9 files changed, 2395 insertions(+), 1 deletion(-)
create mode 100644 chapters/ro/chapter5/1.mdx
create mode 100644 chapters/ro/chapter5/2.mdx
create mode 100644 chapters/ro/chapter5/3.mdx
create mode 100644 chapters/ro/chapter5/4.mdx
create mode 100644 chapters/ro/chapter5/5.mdx
create mode 100644 chapters/ro/chapter5/6.mdx
create mode 100644 chapters/ro/chapter5/7.mdx
create mode 100644 chapters/ro/chapter5/8.mdx
diff --git a/chapters/en/chapter5/3.mdx b/chapters/en/chapter5/3.mdx
index 9e6e738bc..8bde80552 100644
--- a/chapters/en/chapter5/3.mdx
+++ b/chapters/en/chapter5/3.mdx
@@ -526,7 +526,6 @@ train_df = drug_dataset["train"][:]
-
From here we can use all the Pandas functionality that we want. For example, we can do fancy chaining to compute the class distribution among the `condition` entries:
```py
diff --git a/chapters/ro/chapter5/1.mdx b/chapters/ro/chapter5/1.mdx
new file mode 100644
index 000000000..7fd54a2ad
--- /dev/null
+++ b/chapters/ro/chapter5/1.mdx
@@ -0,0 +1,22 @@
+# Introducere[[introduction]]
+
+| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
+ +
+
+
+Dacă ați da clic pe una dintre aceste issue-uri veți găsi că aceasta conține un titlu, o descriere și un set de labeluri care caracterizează issue-ul. Un exemplu este prezentat în screenshotul următor.
+
+
+
+ +
+
+
+Pentru a descărca toate issue-urile din repositoriu, vom folosi [GitHub REST API](https://docs.github.com/en/rest) pentru a enumera [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues). Aceast endpoint returnează o listă de obiecte JSON, cu fiecare obiect conținând un număr mare de câmpuri care includ titlul și descrierea precum și metadata despre starea issue-ului și așa mai departe.
+
+Un mod convenabil de descărcare a issue-urilor este prin utilizarea librăriei `requests`, care este modalitatea standard pentru a face cereri HTTP în Python. Puteți instala libraria rulând comanda:
+
+```python
+!pip install requests
+```
+
+Odată cu instalarea librariei, puteți face cereri GET la `Issues` endpoint prin invocarea funcției `requests.get()`. De exemplu, puteți rula următorul cod pentru a obține primul issue din prima pagină:
+
+```py
+import requests
+
+url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
+response = requests.get(url)
+```
+
+Obiectul `response` conține o cantitate mare de informații utile despre requestul efectuat, inclusiv HTTP status code:
+
+```py
+response.status_code
+```
+
+```python out
+200
+```
+
+unde statusul `200` înseamnă că cererea a fost reușită (puteți găsi o listă completă de status coduri [aici](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)). De ceea ce suntem însă interesați este _payload_, care poate fi accesat în diverse formaturi precum bytes, string sau JSON. Deoarece știm că issue-urile noastre sunt în format JSON, să inspectăm payload-ul astfel:
+
+```py
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
+ 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
+ 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
+ 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'id': 968650274,
+ 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
+ 'number': 2792,
+ 'title': 'Update GooAQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'labels': [],
+ 'state': 'open',
+ 'locked': False,
+ 'assignee': None,
+ 'assignees': [],
+ 'milestone': None,
+ 'comments': 1,
+ 'created_at': '2021-08-12T11:40:18Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'closed_at': None,
+ 'author_association': 'CONTRIBUTOR',
+ 'active_lock_reason': None,
+ 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
+ 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
+ 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
+ 'performed_via_github_app': None}]
+```
+
+Uau, aceasta e o cantitate mare de informație! Putem vedea câmpuri utile cum ar fi `title`, `body` și `number` care descriu problema, precum și informații despre utilizatorul GitHub care a deschis issue-ul.
+
+
+
+ +
+
+
+GitHub REST API oferă un endpoint [`Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) care returnează toate comentariile asociate numărului problemei. Să testăm endpointul pentru a vedea ce returnează:
+
+```py
+issue_number = 2792
+url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+response = requests.get(url, headers=headers)
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
+ 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'id': 897594128,
+ 'node_id': 'IC_kwDODunzps41gDMQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'created_at': '2021-08-12T12:21:52Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'author_association': 'CONTRIBUTOR',
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'performed_via_github_app': None}]
+```
+
+Putem vedea că comentariul este stocat în câmpul `body`, așa că putem scrie o funcție simplă care returnează toate comentariile asociate unei probleme prin extragerea conținutului `body` pentru fiecare element în `response.json()`:
+
+```py
+def get_comments(issue_number):
+ url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+ response = requests.get(url, headers=headers)
+ return [r["body"] for r in response.json()]
+
+
+# Testăm dacă funcția lucrează cum ne dorim
+get_comments(2792)
+```
+
+```python out
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+```
+
+Arată bine. Acum hai să folosim `Dataset.map()` pentru a adăuga noi coloane `comments` fiecărui issue în datasetul nostru:
+
+```py
+# Depending on your internet connection, this can take a few minutes...
+issues_with_comments_dataset = issues_dataset.map(
+ lambda x: {"comments": get_comments(x["number"])}
+)
+```
+
+Ultimul pas este să facem push datasetului nostru pe Hub. Să vedem cum putem face asta.
+
+## Încărcarea datasetului pe Hugging Face Hub[[uploading-the-dataset-to-the-hugging-face-hub]]
+
+
+
+ +
+
+
+2. Citiți [ghidul 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) despre crearea de dataset cards informative și utilizați-l ca șablon.
+
+Puteți crea fișierul *README.md* direct pe Hub și puteți găsi un template pentru dataset card în repositoriul `lewtun/github-issues`. Un screenshot a dataset card completată este afișată mai jos.
+
+
+
+ +
+
+
+
+
+ +
+ +
+
+
+## Încărcarea și pregătirea datasetului[[loading-and-preparing-the-dataset]]
+
+Prima lucru pe care trebuie să îl facem este să descărcăm datasetul nostru cu GitHub issues, așa că folosim funcția `load_dataset()` ca de obicei:
+
+```py
+from datasets import load_dataset
+
+issues_dataset = load_dataset("lewtun/github-issues", split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
+Aici am specificat splitul default `train` în `load_dataset()`, astfel încât returnează un `Dataset` în loc de `DatasetDict`. Primul lucru care treubuie făcut este să filtrăm pull requesturile, deoarece acestea rareori tind să fie utilizate pentru a răspunde la întrebările utilizatorilor și vor introduce noise în motorul nostru de căutare. Așa cum ar trebuie deja să știți, putem utiliza funcția `Dataset.filter()` pentru a exclude aceste rânduri din datasetul nostru. În timp ce suntem aici, putem să filtrăm și rândurile fără comentari, deoarece acestea nu oferă niciun răspuns la întrebările utilizatorilor:
+
+```py
+issues_dataset = issues_dataset.filter(
+ lambda x: (x["is_pull_request"] == False și len(x["comments"]) > 0)
+)
+issues_dataset
+```
+
+```python out
+Dataset({
+ caracteristici: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 771
+})
+```
+
+Putem vedea că există multe coloane în datasetul nostru, majoritatea dintre care nu sunt necesare pentru a construi motorul nostru de căutare. Din perspectiva căutării, cele mai informative coloane sunt `title`, `body` și `comments`, în timp ce `html_url` ne oferă un link înapoi la problema sursă. Hai să utilizăm funcția `Dataset.remove_columns()` pentru a elimina restul:
+
+```py
+columns = issues_dataset.column_names
+columns_to_keep = ["title", "body", "html_url", "comments"]
+columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
+issues_dataset = issues_dataset.remove_columns(columns_to_remove)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 771
+})
+```
+
+Pentru a crea embeddedurile noastre, vom completa fiecare comentariu cu titlul și body-ul problemei, deoarece aceste câmpuri adesea includ informații contextuale utile. Deoarece coloana noastră `comments` este în prezent o listă de comentarii pentru fiecare issue, trebuie să "explodăm" coloana, astfel încât fiecare rând să fie format dintr-un tuple `(html_url, title, body, comment)`. În Pandas, putem face acest lucru cu funcția [`DataFrame.explode()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), care creează un rând nou pentru fiecare element dintr-o coloană asemănătoare cu o listă, în timp ce copiază toate celelalte valori ale coloanelor. Pentru a vedea acest lucru în acțiune, să trecem la formatul pandas `DataFrame` main întâi:
+
+```py
+issues_dataset.set_format("pandas")
+df = issues_dataset[:]
+```
+
+Dacă inspectăm primul rând din acest `DataFrame`, putem vedea că există patru comentarii asociate acestei probleme:
+
+```py
+df["comments"][0].tolist()
+```
+
+```python out
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+ 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
+```
+
+Când facem explode `df`, ne așteptăm să obținem un rând pentru fiecare dintre aceste comentarii. Haideți să verificăm dacă ăsta e cazul:
+
+```py
+comments_df = df.explode("comments", ignore_index=True)
+comments_df.head(4)
+```
+
+
+
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
dataset.shuffle().select(range(50))",
+ explain: "Corect! Așa cum ați văzut în acest capitol, mai întâi faceți shuffle datasetului și apoi selectați exemplele din el.",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "Acest lucru este incorect -- deși codul va rula, va amesteca doar primele 50 de elemente din setul de date."
+ }
+ ]}
+/>
+
+### 3. Presupunem că aveți un set de date despre animale de companie numit `pets_dataset`, care are o coloană `name` care denotă numele fiecărui animal de companie. Care dintre următoarele abordări v-ar permite să filtrați setul de date pentru toate animalele de companie ale căror nume încep cu litera "L"?
+
+pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "Acest lucru este incorect -- o funcție lambda are forma generală lambda *arguments* : *expression*, deci trebuie să furnizați argumente în acest caz."
+ },
+ {
+ text: "Creați o funcție ca def filter_names(x): return x['name'].startswith('L') și rulați pets_dataset.filter(filter_names).",
+ explain: "Corect! La fel ca și cu Dataset.map(), puteți trece funcții explicite la Dataset.filter(). Acest lucru este util atunci când aveți o logică complexă care nu este potrivită pentru o funcție lambda. Care dintre celelalte soluții ar mai funcționa?",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Ce este memory mapping?
+
+IterableDataset este un generator, nu un container, deci ar trebui să accesați elementele sale utilizând next(iter(dataset)).",
+ correct: true
+ },
+ {
+ text: "Datasetul allocine nu are o un split train.",
+ explain: "Acest lucru este incorect -- consultați cardul datasetului allocine de pe Hub pentru a vedea ce splituri conține."
+ }
+ ]}
+/>
+
+### 7. Care sunt principalele beneficii ale creării unui dataset card?
+
+
+ +
+ +
+
+
+Cu maparea aceasta, suntem gat a să reproducem(aproape în total) rezultat primului pipeline -- noi putem lua scorul și labelul fiecărui token care nu a fost clasificat ca `O`:
+
+```py
+results = []
+tokens = inputs.tokens()
+
+for idx, pred in enumerate(predictions):
+ label = model.config.id2label[pred]
+ if label != "O":
+ results.append(
+ {"entity": label, "score": probabilities[idx][pred], "word": tokens[idx]}
+ )
+
+print(results)
+```
+
+```python out
+[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S'},
+ {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl'},
+ {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va'},
+ {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in'},
+ {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu'},
+ {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging'},
+ {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face'},
+ {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn'}]
+```
+
+Acest lucru este foarte similar cu ce am avut mai devreme, cu o excepție: pipelineul de asemenea ne-a oferit informație despre `start` și `end` al fiecărei entități în propoziția originală. Acum e momentul când offset mappingul nostru ne va ajuta. Pentru a obține offseturile, noi trebuie să setăm `return_offsets_mapping=True` când aplicăm tokenizerul pe inputurile noastre:
+
+```py
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+inputs_with_offsets["offset_mapping"]
+```
+
+```python out
+[(0, 0), (0, 2), (3, 7), (8, 10), (11, 12), (12, 14), (14, 16), (16, 18), (19, 22), (23, 24), (25, 29), (30, 32),
+ (33, 35), (35, 40), (41, 45), (46, 48), (49, 57), (57, 58), (0, 0)]
+```
+
+Fiecare tuple este spanul de text care corespunde fiecărui token, unde `(0, 0)` este rezervat pentru tokenii speciali. Noi am văzut înainte că tokenul la indexul 5 este `##yl`, care are aici `(12, 14)` ca offsets. Dacă luăm sliceul corespunzător în exemplul nostru:
+
+```py
+example[12:14]
+```
+
+noi obținem spanul propriu de text fără `##`:
+
+```python out
+yl
+```
+
+Folosind aceasta, putem acum completa rezultatele anterioare:
+
+
+```py
+results = []
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+tokens = inputs_with_offsets.tokens()
+offsets = inputs_with_offsets["offset_mapping"]
+
+for idx, pred in enumerate(predictions):
+ label = model.config.id2label[pred]
+ if label != "O":
+ start, end = offsets[idx]
+ results.append(
+ {
+ "entity": label,
+ "score": probabilities[idx][pred],
+ "word": tokens[idx],
+ "start": start,
+ "end": end,
+ }
+ )
+
+print(results)
+```
+
+```python out
+[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
+ {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
+ {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
+ {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
+ {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
+ {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
+ {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
+ {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Acest răspuns e același răspuns pe care l-am primit de la primul pipeline:
+
+### Gruparea entităților[[grouping-entities]]
+
+Utilizarea offseturilor pentru a determina cheile de start și de sfârșit pentru fiecare entitate este util, dar această informație nu este strict necesară. Când dorim să grupăm entitățile împreună, totuși, offseturile ne vor salva o mulțime de messy code. De exemplu, dacă am dori să grupăm împreună tokenii `Hu`, `##gging` și `Face`, am putea crea reguli speciale care să spună că primele două ar trebui să fie atașate și să înlăturăm `##`, iar `Face` ar trebui adăugat cu un spațiu, deoarece nu începe cu `##` -- dar acest lucru ar funcționa doar pentru acest tip particular de tokenizer. Ar trebui să scriem un alt set de reguli pentru un tokenizer SentencePiece sau unul Byte-Pair-Encoding (discutat mai târziu în acest capitol).
+
+Cu offseturile, tot acel cod custom dispare: pur și simplu putem lua spanul din textul original care începe cu primul token și se termină cu ultimul token. Deci, în cazul tokenurilor `Hu`, `##gging` și `Face`, ar trebui să începem la caracterul 33 (începutul lui `Hu`) și să ne oprim înainte de caracterul 45 (sfârșitul lui `Face`):
+
+```py
+example[33:45]
+```
+
+```python out
+Hugging Face
+```
+
+Pentru a scrie codul care post-procesează predicțiile în timp ce grupăm entitățile, vom grupa entitățile care sunt consecutive și labeled cu `I-XXX`, cu excepția primeia, care poate fi labeled ca `B-XXX` sau `I-XXX` (decidem să oprim gruparea unei entități atunci când întâlnim un `O`, un nou tip de entitate, sau un `B-XXX` care ne spune că o entitate de același tip începe):
+
+```py
+import numpy as np
+
+results = []
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+tokens = inputs_with_offsets.tokens()
+offsets = inputs_with_offsets["offset_mapping"]
+
+idx = 0
+while idx < len(predictions):
+ pred = predictions[idx]
+ label = model.config.id2label[pred]
+ if label != "O":
+ # Remove the B- or I-
+ label = label[2:]
+ start, _ = offsets[idx]
+
+ # Grab all the tokens labeled with I-label
+ all_scores = []
+ while (
+ idx < len(predictions)
+ and model.config.id2label[predictions[idx]] == f"I-{label}"
+ ):
+ all_scores.append(probabilities[idx][pred])
+ _, end = offsets[idx]
+ idx += 1
+
+ # The score is the mean of all the scores of the tokens in that grouped entity
+ score = np.mean(all_scores).item()
+ word = example[start:end]
+ results.append(
+ {
+ "entity_group": label,
+ "score": score,
+ "word": word,
+ "start": start,
+ "end": end,
+ }
+ )
+ idx += 1
+
+print(results)
+```
+
+Și obținem aceleași răspuns ca de la pipelineul secundar!
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Alt exemplu de sarcină unde offseturile sunt extrem de useful pentru răspunderea la întrebări. Scufundându-ne în pipelineuri, un lucru pe care îl vom face în următoarea secțiune, ne vom premite să ne uităm peste o caracteristică a tokenizerului în librăria 🤗 Transformers: vom avea de-a face cu overflowing tokens când truncăm un input de o anumită lungime.
+
diff --git a/chapters/ro/chapter 6/3b.mdx b/chapters/ro/chapter 6/3b.mdx
new file mode 100644
index 000000000..08acea387
--- /dev/null
+++ b/chapters/ro/chapter 6/3b.mdx
@@ -0,0 +1,643 @@
+
+
+
+ +
+ +
+
+
+Modelele create pentru răspunderea la întrebări funcționează puțin diferit de modelele pe care le-am văzut până acum. Folosind imaginea de mai sus ca exemplu, modelul a fost antrenat pentru a prezice indicele tokenului cu care începe răspunsului (aici 21) și indicele simbolului la care se termină răspunsul (aici 24). Acesta este motivul pentru care modelele respective nu returnează un singur tensor de logits, ci două: unul pentru logits-ul corespunzători tokenului cu care începe răspunsului și unul pentru logits-ul corespunzător tokenului de sfârșit al răspunsului. Deoarece în acest caz avem un singur input care conține 66 de token-uri, obținem:
+
+```py
+start_logits = outputs.start_logits
+end_logits = outputs.end_logits
+print(start_logits.shape, end_logits.shape)
+```
+
+{#if fw === 'pt'}
+
+```python out
+torch.Size([1, 66]) torch.Size([1, 66])
+```
+
+{:else}
+
+```python out
+(1, 66) (1, 66)
+```
+
+{/if}
+
+Pentru a converti acești logits în probabilități, vom aplica o funcție softmax - dar înainte de aceasta, trebuie să ne asigurăm că mascăm indicii care nu fac parte din context. Inputul nostru este `[CLS] întrebare [SEP] context [SEP]`, deci trebuie să mascăm token-urile întrebării, precum și tokenul `[SEP]`. Cu toate acestea, vom păstra simbolul `[CLS]`, deoarece unele modele îl folosesc pentru a indica faptul că răspunsul nu se află în context.
+
+Deoarece vom aplica ulterior un softmax, trebuie doar să înlocuim logiturile pe care dorim să le mascăm cu un număr negativ mare. Aici, folosim `-10000`:
+
+{#if fw === 'pt'}
+
+```py
+import torch
+
+sequence_ids = inputs.sequence_ids()
+# Mask everything apart from the tokens of the context
+mask = [i != 1 for i in sequence_ids]
+# Unmask the [CLS] token
+mask[0] = False
+mask = torch.tensor(mask)[None]
+
+start_logits[mask] = -10000
+end_logits[mask] = -10000
+```
+
+{:else}
+
+```py
+import tensorflow as tf
+
+sequence_ids = inputs.sequence_ids()
+# Mask everything apart from the tokens of the context
+mask = [i != 1 for i in sequence_ids]
+# Unmask the [CLS] token
+mask[0] = False
+mask = tf.constant(mask)[None]
+
+start_logits = tf.where(mask, -10000, start_logits)
+end_logits = tf.where(mask, -10000, end_logits)
+```
+
+{/if}
+
+Acum că am mascat în mod corespunzător logiturile corespunzătoare pozițiilor pe care nu dorim să le prezicem, putem aplica softmax:
+
+{#if fw === 'pt'}
+
+```py
+start_probabilities = torch.nn.functional.softmax(start_logits, dim=-1)[0]
+end_probabilities = torch.nn.functional.softmax(end_logits, dim=-1)[0]
+```
+
+{:else}
+
+```py
+start_probabilities = tf.math.softmax(start_logits, axis=-1)[0].numpy()
+end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
+```
+
+{/if}
+
+La acest stadiu, am putea lua argmax al probabilităților de început și de sfârșit - dar am putea ajunge la un indice de început care este mai mare decât indicele de sfârșit, deci trebuie să luăm câteva precauții suplimentare. Vom calcula probabilitățile fiecărui `start_index` și `end_index` posibil în cazul în care `start_index <= end_index`, apoi vom lua un tuple `(start_index, end_index)` cu cea mai mare probabilitate.
+
+Presupunând că evenimentele "The answer starts at `start_index`" și "The answer ends at `end_index`" sunt independente, probabilitatea ca răspunsul să înceapă la `start_index` și să se termine la `end_index` este:
+
+$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
+
+Deci, pentru a calcula toate scorurile, trebuie doar să calculăm toate produsele \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) unde `start_index <= end_index`.
+
+Mai întâi hai să calculăm toate produsele posibile:
+
+```py
+scores = start_probabilities[:, None] * end_probabilities[None, :]
+```
+
+{#if fw === 'pt'}
+
+Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `torch.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
+
+```py
+scores = torch.triu(score)
+```
+
+{:else}
+
+Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `np.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
+
+```py
+import numpy as np
+
+scores = np.triu(scores)
+```
+
+{/if}
+
+Acum trebuie doar să obținem indicele maximului. Deoarece PyTorch va returna indicele în tensorul aplatizat, trebuie să folosim operațiile floor division `//` și modulusul `%` pentru a obține `start_index` și `end_index`:
+
+```py
+max_index = scores.argmax().item()
+start_index = max_index // scores.shape[1]
+end_index = max_index % scores.shape[1]
+print(scores[start_index, end_index])
+```
+
+Nu am terminat încă, dar cel puțin avem deja scorul corect pentru răspuns (puteți verifica acest lucru comparându-l cu primul rezultat din secțiunea anterioară):
+
+```python out
+0.97773
+```
+
+
+
+
+ +
+ +
+
+
+Înainte de a împărți un text în subtokens (în conformitate cu modelul său), tokenizerul efectuează doi pași: _normalization__ și _pre-tokenization_.
+
+## Normalization[[normalization]]
+
+
+
+
+
+
+
+
+Biblioteca 🤗 Tokenizers a fost construită pentru a oferi mai multe opțiuni pentru fiecare dintre acești pași, pe care le puteți amesteca și combina împreună. În această secțiune vom vedea cum putem construi un tokenizer de la zero, spre deosebire de antrenarea unui tokenizer nou dintr-unul vechi, așa cum am făcut în [secțiunea 2](/course/chapter6/2). Veți putea apoi să construiți orice fel de tokenizer la care vă puteți gândi!
+
+
+
+`` și '' cu " și orice secvență de două sau mai multe spații cu un singur spațiu, precum și ștergerea accentelor în textele ce trebuie tokenizate.
+
+Pre-tokenizerul care trebuie utilizat pentru orice tokenizer SentencePiece este `Metaspace`:
+
+```python
+tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
+```
+
+Putem arunca o privire la pre-tokenizarea unui exemplu de text ca mai înainte:
+
+```python
+tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
+```
+
+```python out
+[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
+```
+
+Urmează modelul, care are nevoie de antrenare. XLNet are destul de mulți tokeni speciali:
+
+```python
+special_tokens = ["[CLS] la început, dar nu este singurul lucru necesar!"
+ },
+ {
+ text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2 [SEP]",
+ explain: "Corect!",
+ correct: true
+ },
+ {
+ text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2",
+ explain: "Este nevoie atât de un token special [CLS] la început, cât și de un token special [SEP] pentru a separa cele două propoziții, dar mai lipsește ceva!"
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 4. Care sunt avantajele metodei `Dataset.map()`?
+
+DataLoader. Noi am folosit funcția DataCollatorWithPadding, care împachetează toate elementele dintr-un lot astfel încât să aibă aceeași lungime.",
+ correct: true
+ },
+ {
+ text: "Preprocesează întregul set de date.",
+ explain: "Aceasta ar fi o funcție de preprocessing, nu o funcție de collate."
+ },
+ {
+ text: "Trunchiază secvențele din setul de date.",
+ explain: "O funcție de collate se ocupă de manipularea loturilor individuale, nu a întregului set de date. Dacă sunteți interesați de trunchiere, puteți folosi argumentul truncate al tokenizer."
+ }
+ ]}
+/>
+
+### 7. Ce se întâmplă când instanțiați una dintre clasele `AutoModelForXxx` cu un model de limbaj preantrenat (cum ar fi `bert-base-uncased`), care corespunde unei alte sarcini decât cea pentru care a fost antrenat?
+
+bert-base-uncased, am primit avertismente la instanțierea modelului. Head-ul preantrenat nu este folosit pentru sarcina de clasificare secvențială, așa că este eliminat și un nou head este instanțiat cu greutăți inițializate aleator.",
+ correct: true
+ },
+ {
+ text: "Head-ul modelului preantrenat este eliminat.",
+ explain: "Mai trebuie să se întâmple și altceva. Încercați din nou!"
+ },
+ {
+ text: "Nimic, pentru că modelul poate fi ajustat fin (fine-tuned) chiar și pentru o altă sarcină.",
+ explain: "Head-ul preantrenat al modelului nu a fost antrenat pentru această sarcină, deci trebuie eliminat!"
+ }
+ ]}
+/>
+
+### 8. Care este scopul folosirii `TrainingArguments`?
+
+TrainingArguments."
+ },
+ {
+ text: "Conține doar hiperparametrii folosiți pentru evaluare.",
+ explain: "În exemplu, am specificat și unde va fi salvat modelul și checkpoint-urile. Încercați din nou!"
+ },
+ {
+ text: "Conține doar hiperparametrii folosiți pentru antrenare.",
+ explain: "În exemplu, am folosit și un evaluation_strategy, așadar acest lucru afectează evaluarea. Încercați din nou!"
+ }
+ ]}
+/>
+
+### 9. De ce ar trebui să folosiți biblioteca 🤗 Accelerate?
+
+bert-base-uncased, am primit avertismente la instanțierea modelului. Head-ul preantrenat nu este folosit pentru sarcina de clasificare secvențială, așa că este eliminat și un nou head este instanțiat cu greutăți inițializate aleator.",
+ correct: true
+ },
+ {
+ text: "Head-ul modelului preantrenat este eliminat.",
+ explain: "Mai trebuie să se întâmple și altceva. Încercați din nou!"
+ },
+ {
+ text: "Nimic, pentru că modelul poate fi ajustat fin (fine-tuned) chiar și pentru o altă sarcină.",
+ explain: "Head-ul preantrenat al modelului nu a fost antrenat pentru această sarcină, deci trebuie eliminat!"
+ }
+ ]}
+/>
+
+### 5. Modelele TensorFlow din `transformers` sunt deja modele Keras. Ce avantaj oferă acest lucru?
+
+compile(), fit() și predict().",
+ explain: "Corect! Odată ce aveți datele, antrenarea necesită foarte puțin efort.",
+ correct: true
+ },
+ {
+ text: "Învățați atât Keras, cât și transformers.",
+ explain: "Corect, dar căutăm altceva :)",
+ correct: true
+ },
+ {
+ text: "Puteți calcula cu ușurință metrici legate de dataset.",
+ explain: "Keras ne ajută la antrenarea și evaluarea modelului, nu la calcularea metricilor legate de dataset."
+ }
+ ]}
+/>
+
+### 6. Cum vă puteți defini propria metrică personalizată?
+
+metric_fn(y_true, y_pred).",
+ explain: "Corect!",
+ correct: true
+ },
+ {
+ text: "Căutând pe Google.",
+ explain: "Nu este răspunsul pe care îl căutăm, dar probabil v-ar putea ajuta să-l găsiți.",
+ correct: true
+ }
+ ]}
+/>
+
+{/if}
\ No newline at end of file
From 3b79756af2d004b5885b3fad7df31d440c827c68 Mon Sep 17 00:00:00 2001
From: Angroys <120798951+Angroys@users.noreply.github.com>
Date: Thu, 9 Jan 2025 00:24:58 +0200
Subject: [PATCH 08/37] Done the first three sections of the 7th chapter
---
chapters/ro/{chapter 6 => chapter6}/1.mdx | 0
chapters/ro/{chapter 6 => chapter6}/10.mdx | 0
chapters/ro/{chapter 6 => chapter6}/2.mdx | 0
chapters/ro/{chapter 6 => chapter6}/3.mdx | 0
chapters/ro/{chapter 6 => chapter6}/3b.mdx | 0
chapters/ro/{chapter 6 => chapter6}/4.mdx | 0
chapters/ro/{chapter 6 => chapter6}/5.mdx | 0
chapters/ro/{chapter 6 => chapter6}/6.mdx | 0
chapters/ro/{chapter 6 => chapter6}/7.mdx | 0
chapters/ro/{chapter 6 => chapter6}/8.mdx | 0
chapters/ro/{chapter 6 => chapter6}/9.mdx | 0
chapters/ro/chapter7/1.mdx | 38 +
chapters/ro/chapter7/2.mdx | 983 ++++++++++++++++
chapters/ro/chapter7/3.mdx | 1044 +++++++++++++++++
chapters/ro/chapter7/4.mdx | 1002 ++++++++++++++++
chapters/ro/chapter7/5.mdx | 1072 +++++++++++++++++
chapters/ro/chapter7/6.mdx | 914 +++++++++++++++
chapters/ro/chapter7/7.mdx | 1203 ++++++++++++++++++++
chapters/ro/chapter7/8.mdx | 22 +
chapters/ro/chapter7/9.mdx | 329 ++++++
20 files changed, 6607 insertions(+)
rename chapters/ro/{chapter 6 => chapter6}/1.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/10.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/2.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/3.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/3b.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/4.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/5.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/6.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/7.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/8.mdx (100%)
rename chapters/ro/{chapter 6 => chapter6}/9.mdx (100%)
create mode 100644 chapters/ro/chapter7/1.mdx
create mode 100644 chapters/ro/chapter7/2.mdx
create mode 100644 chapters/ro/chapter7/3.mdx
create mode 100644 chapters/ro/chapter7/4.mdx
create mode 100644 chapters/ro/chapter7/5.mdx
create mode 100644 chapters/ro/chapter7/6.mdx
create mode 100644 chapters/ro/chapter7/7.mdx
create mode 100644 chapters/ro/chapter7/8.mdx
create mode 100644 chapters/ro/chapter7/9.mdx
diff --git a/chapters/ro/chapter 6/1.mdx b/chapters/ro/chapter6/1.mdx
similarity index 100%
rename from chapters/ro/chapter 6/1.mdx
rename to chapters/ro/chapter6/1.mdx
diff --git a/chapters/ro/chapter 6/10.mdx b/chapters/ro/chapter6/10.mdx
similarity index 100%
rename from chapters/ro/chapter 6/10.mdx
rename to chapters/ro/chapter6/10.mdx
diff --git a/chapters/ro/chapter 6/2.mdx b/chapters/ro/chapter6/2.mdx
similarity index 100%
rename from chapters/ro/chapter 6/2.mdx
rename to chapters/ro/chapter6/2.mdx
diff --git a/chapters/ro/chapter 6/3.mdx b/chapters/ro/chapter6/3.mdx
similarity index 100%
rename from chapters/ro/chapter 6/3.mdx
rename to chapters/ro/chapter6/3.mdx
diff --git a/chapters/ro/chapter 6/3b.mdx b/chapters/ro/chapter6/3b.mdx
similarity index 100%
rename from chapters/ro/chapter 6/3b.mdx
rename to chapters/ro/chapter6/3b.mdx
diff --git a/chapters/ro/chapter 6/4.mdx b/chapters/ro/chapter6/4.mdx
similarity index 100%
rename from chapters/ro/chapter 6/4.mdx
rename to chapters/ro/chapter6/4.mdx
diff --git a/chapters/ro/chapter 6/5.mdx b/chapters/ro/chapter6/5.mdx
similarity index 100%
rename from chapters/ro/chapter 6/5.mdx
rename to chapters/ro/chapter6/5.mdx
diff --git a/chapters/ro/chapter 6/6.mdx b/chapters/ro/chapter6/6.mdx
similarity index 100%
rename from chapters/ro/chapter 6/6.mdx
rename to chapters/ro/chapter6/6.mdx
diff --git a/chapters/ro/chapter 6/7.mdx b/chapters/ro/chapter6/7.mdx
similarity index 100%
rename from chapters/ro/chapter 6/7.mdx
rename to chapters/ro/chapter6/7.mdx
diff --git a/chapters/ro/chapter 6/8.mdx b/chapters/ro/chapter6/8.mdx
similarity index 100%
rename from chapters/ro/chapter 6/8.mdx
rename to chapters/ro/chapter6/8.mdx
diff --git a/chapters/ro/chapter 6/9.mdx b/chapters/ro/chapter6/9.mdx
similarity index 100%
rename from chapters/ro/chapter 6/9.mdx
rename to chapters/ro/chapter6/9.mdx
diff --git a/chapters/ro/chapter7/1.mdx b/chapters/ro/chapter7/1.mdx
new file mode 100644
index 000000000..82f8c9611
--- /dev/null
+++ b/chapters/ro/chapter7/1.mdx
@@ -0,0 +1,38 @@
+ +
+ +
+
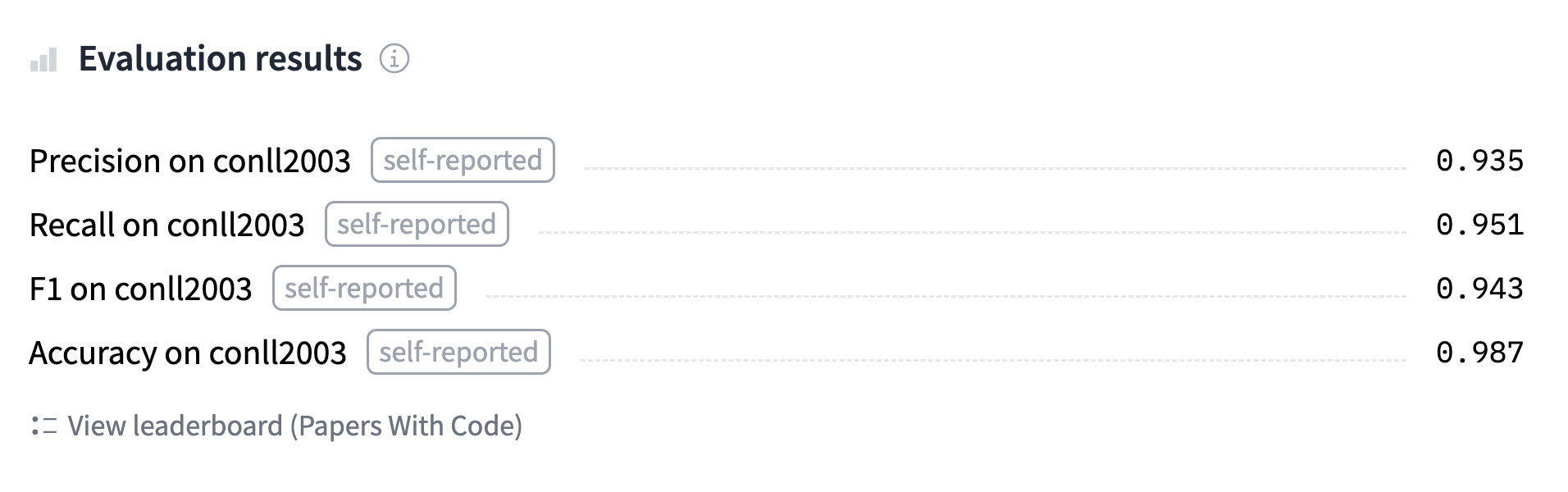
+Puteți găsi modelul pe care îl vom antrena și încărca în Hub și puteți verifica de două ori predicțiile sale [aici](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).
+
+## Pregătirea datelor[[preparing-the-data]]
+
+În primul rând, avem nevoie de un dataset adecvat pentru clasificarea simbolurilor. În această secțiune vom utiliza [datasetul CoNLL-2003] (https://huggingface.co/datasets/conll2003), care conține știri de la Reuters.
+
+
+
+
+Puteți găsi modelul pe care îl vom antrena și încărca în Hub și puteți verifica de două ori predicțiile sale [aici](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).
+
+## Pregătirea datelor[[preparing-the-data]]
+
+În primul rând, avem nevoie de un dataset adecvat pentru clasificarea simbolurilor. În această secțiune vom utiliza [datasetul CoNLL-2003] (https://huggingface.co/datasets/conll2003), care conține știri de la Reuters.
+
+
+ +
+ +
+
+
+By the end of this section you'll have a [masked language model](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.) on the Hub that can autocomplete sentences as shown below:
+
+
+
+Let's dive in!
+
+
+
+
+ +
+
+
+Although the BERT and RoBERTa family of models are the most downloaded, we'll use a model called [DistilBERT](https://huggingface.co/distilbert-base-uncased)
+that can be trained much faster with little to no loss in downstream performance. This model was trained using a special technique called [_knowledge distillation_](https://en.wikipedia.org/wiki/Knowledge_distillation), where a large "teacher model" like BERT is used to guide the training of a "student model" that has far fewer parameters. An explanation of the details of knowledge distillation would take us too far afield in this section, but if you're interested you can read all about it in [_Natural Language Processing with Transformers_](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (colloquially known as the Transformers textbook).
+
+{#if fw === 'pt'}
+
+Let's go ahead and download DistilBERT using the `AutoModelForMaskedLM` class:
+
+```python
+from transformers import AutoModelForMaskedLM
+
+model_checkpoint = "distilbert-base-uncased"
+model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+We can see how many parameters this model has by calling the `num_parameters()` method:
+
+```python
+distilbert_num_parameters = model.num_parameters() / 1_000_000
+print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
+print(f"'>>> BERT number of parameters: 110M'")
+```
+
+```python out
+'>>> DistilBERT number of parameters: 67M'
+'>>> BERT number of parameters: 110M'
+```
+
+{:else}
+
+Let's go ahead and download DistilBERT using the `AutoModelForMaskedLM` class:
+
+```python
+from transformers import TFAutoModelForMaskedLM
+
+model_checkpoint = "distilbert-base-uncased"
+model = TFAutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+We can see how many parameters this model has by calling the `summary()` method:
+
+```python
+model.summary()
+```
+
+```python out
+Model: "tf_distil_bert_for_masked_lm"
+_________________________________________________________________
+Layer (type) Output Shape Param #
+=================================================================
+distilbert (TFDistilBertMain multiple 66362880
+_________________________________________________________________
+vocab_transform (Dense) multiple 590592
+_________________________________________________________________
+vocab_layer_norm (LayerNorma multiple 1536
+_________________________________________________________________
+vocab_projector (TFDistilBer multiple 23866170
+=================================================================
+Total params: 66,985,530
+Trainable params: 66,985,530
+Non-trainable params: 0
+_________________________________________________________________
+```
+
+{/if}
+
+With around 67 million parameters, DistilBERT is approximately two times smaller than the BERT base model, which roughly translates into a two-fold speedup in training -- nice! Let's now see what kinds of tokens this model predicts are the most likely completions of a small sample of text:
+
+```python
+text = "This is a great [MASK]."
+```
+
+As humans, we can imagine many possibilities for the `[MASK]` token, such as "day", "ride", or "painting". For pretrained models, the predictions depend on the corpus the model was trained on, since it learns to pick up the statistical patterns present in the data. Like BERT, DistilBERT was pretrained on the [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [BookCorpus](https://huggingface.co/datasets/bookcorpus) datasets, so we expect the predictions for `[MASK]` to reflect these domains. To predict the mask we need DistilBERT's tokenizer to produce the inputs for the model, so let's download that from the Hub as well:
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+With a tokenizer and a model, we can now pass our text example to the model, extract the logits, and print out the top 5 candidates:
+
+{#if fw === 'pt'}
+
+```python
+import torch
+
+inputs = tokenizer(text, return_tensors="pt")
+token_logits = model(**inputs).logits
+# Find the location of [MASK] and extract its logits
+mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
+mask_token_logits = token_logits[0, mask_token_index, :]
+# Pick the [MASK] candidates with the highest logits
+top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
+
+for token in top_5_tokens:
+ print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")
+```
+
+{:else}
+
+```python
+import numpy as np
+import tensorflow as tf
+
+inputs = tokenizer(text, return_tensors="np")
+token_logits = model(**inputs).logits
+# Find the location of [MASK] and extract its logits
+mask_token_index = np.argwhere(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
+mask_token_logits = token_logits[0, mask_token_index, :]
+# Pick the [MASK] candidates with the highest logits
+# We negate the array before argsort to get the largest, not the smallest, logits
+top_5_tokens = np.argsort(-mask_token_logits)[:5].tolist()
+
+for token in top_5_tokens:
+ print(f">>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}")
+```
+
+{/if}
+
+```python out
+'>>> This is a great deal.'
+'>>> This is a great success.'
+'>>> This is a great adventure.'
+'>>> This is a great idea.'
+'>>> This is a great feat.'
+```
+
+We can see from the outputs that the model's predictions refer to everyday terms, which is perhaps not surprising given the foundation of English Wikipedia. Let's see how we can change this domain to something a bit more niche -- highly polarized movie reviews!
+
+
+## The dataset[[the-dataset]]
+
+To showcase domain adaptation, we'll use the famous [Large Movie Review Dataset](https://huggingface.co/datasets/imdb) (or IMDb for short), which is a corpus of movie reviews that is often used to benchmark sentiment analysis models. By fine-tuning DistilBERT on this corpus, we expect the language model will adapt its vocabulary from the factual data of Wikipedia that it was pretrained on to the more subjective elements of movie reviews. We can get the data from the Hugging Face Hub with the `load_dataset()` function from 🤗 Datasets:
+
+```python
+from datasets import load_dataset
+
+imdb_dataset = load_dataset("imdb")
+imdb_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label'],
+ num_rows: 25000
+ })
+ test: Dataset({
+ features: ['text', 'label'],
+ num_rows: 25000
+ })
+ unsupervised: Dataset({
+ features: ['text', 'label'],
+ num_rows: 50000
+ })
+})
+```
+
+We can see that the `train` and `test` splits each consist of 25,000 reviews, while there is an unlabeled split called `unsupervised` that contains 50,000 reviews. Let's take a look at a few samples to get an idea of what kind of text we're dealing with. As we've done in previous chapters of the course, we'll chain the `Dataset.shuffle()` and `Dataset.select()` functions to create a random sample:
+
+```python
+sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
+
+for row in sample:
+ print(f"\n'>>> Review: {row['text']}'")
+ print(f"'>>> Label: {row['label']}'")
+```
+
+```python out
+
+'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.
+Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.' +'>>> Label: 0' + +'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.
The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.' +'>>> Label: 0' + +'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version.
My 4 and 6 year old children love this movie and have been asking again and again to watch it.
I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.
I do not have older children so I do not know what they would think of it.
The songs are very cute. My daughter keeps singing them over and over.
Hope this helps.' +'>>> Label: 1' +``` + +Yep, these are certainly movie reviews, and if you're old enough you may even understand the comment in the last review about owning a VHS version 😜! Although we won't need the labels for language modeling, we can already see that a `0` denotes a negative review, while a `1` corresponds to a positive one. + +
 +
+ +
+
+As in the previous sections, you can find the actual model that we'll train and upload to the Hub using the code below and double-check its predictions [here](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## Preparing the data[[preparing-the-data]]
+
+To fine-tune or train a translation model from scratch, we will need a dataset suitable for the task. As mentioned previously, we'll use the [KDE4 dataset](https://huggingface.co/datasets/kde4) in this section, but you can adapt the code to use your own data quite easily, as long as you have pairs of sentences in the two languages you want to translate from and into. Refer back to [Chapter 5](/course/chapter5) if you need a reminder of how to load your custom data in a `Dataset`.
+
+### The KDE4 dataset[[the-kde4-dataset]]
+
+As usual, we download our dataset using the `load_dataset()` function:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+If you want to work with a different pair of languages, you can specify them by their codes. A total of 92 languages are available for this dataset; you can see them all by expanding the language tags on its [dataset card](https://huggingface.co/datasets/kde4).
+
+
+
+
+As in the previous sections, you can find the actual model that we'll train and upload to the Hub using the code below and double-check its predictions [here](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## Preparing the data[[preparing-the-data]]
+
+To fine-tune or train a translation model from scratch, we will need a dataset suitable for the task. As mentioned previously, we'll use the [KDE4 dataset](https://huggingface.co/datasets/kde4) in this section, but you can adapt the code to use your own data quite easily, as long as you have pairs of sentences in the two languages you want to translate from and into. Refer back to [Chapter 5](/course/chapter5) if you need a reminder of how to load your custom data in a `Dataset`.
+
+### The KDE4 dataset[[the-kde4-dataset]]
+
+As usual, we download our dataset using the `load_dataset()` function:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+If you want to work with a different pair of languages, you can specify them by their codes. A total of 92 languages are available for this dataset; you can see them all by expanding the language tags on its [dataset card](https://huggingface.co/datasets/kde4).
+
+ +
+Let's have a look at the dataset:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+We have 210,173 pairs of sentences, but in one single split, so we will need to create our own validation set. As we saw in [Chapter 5](/course/chapter5), a `Dataset` has a `train_test_split()` method that can help us. We'll provide a seed for reproducibility:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+We can rename the `"test"` key to `"validation"` like this:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Now let's take a look at one element of the dataset:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+We get a dictionary with two sentences in the pair of languages we requested. One particularity of this dataset full of technical computer science terms is that they are all fully translated in French. However, French engineers leave most computer science-specific words in English when they talk. Here, for instance, the word "threads" might well appear in a French sentence, especially in a technical conversation; but in this dataset it has been translated into the more correct "fils de discussion." The pretrained model we use, which has been pretrained on a larger corpus of French and English sentences, takes the easier option of leaving the word as is:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Another example of this behavior can be seen with the word "plugin," which isn't officially a French word but which most native speakers will understand and not bother to translate.
+In the KDE4 dataset this word has been translated in French into the more official "module d'extension":
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Our pretrained model, however, sticks with the compact and familiar English word:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+It will be interesting to see if our fine-tuned model picks up on those particularities of the dataset (spoiler alert: it will).
+
+
+
+Let's have a look at the dataset:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+We have 210,173 pairs of sentences, but in one single split, so we will need to create our own validation set. As we saw in [Chapter 5](/course/chapter5), a `Dataset` has a `train_test_split()` method that can help us. We'll provide a seed for reproducibility:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+We can rename the `"test"` key to `"validation"` like this:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Now let's take a look at one element of the dataset:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+We get a dictionary with two sentences in the pair of languages we requested. One particularity of this dataset full of technical computer science terms is that they are all fully translated in French. However, French engineers leave most computer science-specific words in English when they talk. Here, for instance, the word "threads" might well appear in a French sentence, especially in a technical conversation; but in this dataset it has been translated into the more correct "fils de discussion." The pretrained model we use, which has been pretrained on a larger corpus of French and English sentences, takes the easier option of leaving the word as is:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Another example of this behavior can be seen with the word "plugin," which isn't officially a French word but which most native speakers will understand and not bother to translate.
+In the KDE4 dataset this word has been translated in French into the more official "module d'extension":
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Our pretrained model, however, sticks with the compact and familiar English word:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+It will be interesting to see if our fine-tuned model picks up on those particularities of the dataset (spoiler alert: it will).
+
+
+ +
+ +
+
+
+To deal with this, we'll filter out the examples with very short titles so that our model can produce more interesting summaries. Since we're dealing with English and Spanish texts, we can use a rough heuristic to split the titles on whitespace and then use our trusty `Dataset.filter()` method as follows:
+
+```python
+books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
+```
+
+Now that we've prepared our corpus, let's take a look at a few possible Transformer models that one might fine-tune on it!
+
+## Models for text summarization[[models-for-text-summarization]]
+
+If you think about it, text summarization is a similar sort of task to machine translation: we have a body of text like a review that we'd like to "translate" into a shorter version that captures the salient features of the input. Accordingly, most Transformer models for summarization adopt the encoder-decoder architecture that we first encountered in [Chapter 1](/course/chapter1), although there are some exceptions like the GPT family of models which can also be used for summarization in few-shot settings. The following table lists some popular pretrained models that can be fine-tuned for summarization.
+
+| Transformer model | Description | Multilingual? |
+| :---------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-----------: |
+| [GPT-2](https://huggingface.co/gpt2-xl) | Although trained as an auto-regressive language model, you can make GPT-2 generate summaries by appending "TL;DR" at the end of the input text. | ❌ |
+| [PEGASUS](https://huggingface.co/google/pegasus-large) | Uses a pretraining objective to predict masked sentences in multi-sentence texts. This pretraining objective is closer to summarization than vanilla language modeling and scores highly on popular benchmarks. | ❌ |
+| [T5](https://huggingface.co/t5-base) | A universal Transformer architecture that formulates all tasks in a text-to-text framework; e.g., the input format for the model to summarize a document is `summarize: ARTICLE`. | ❌ |
+| [mT5](https://huggingface.co/google/mt5-base) | A multilingual version of T5, pretrained on the multilingual Common Crawl corpus (mC4), covering 101 languages. | ✅ |
+| [BART](https://huggingface.co/facebook/bart-base) | A novel Transformer architecture with both an encoder and a decoder stack trained to reconstruct corrupted input that combines the pretraining schemes of BERT and GPT-2. | ❌ |
+| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | A multilingual version of BART, pretrained on 50 languages. | ✅ |
+
+As you can see from this table, the majority of Transformer models for summarization (and indeed most NLP tasks) are monolingual. This is great if your task is in a "high-resource" language like English or German, but less so for the thousands of other languages in use across the world. Fortunately, there is a class of multilingual Transformer models, like mT5 and mBART, that come to the rescue. These models are pretrained using language modeling, but with a twist: instead of training on a corpus of one language, they are trained jointly on texts in over 50 languages at once!
+
+We'll focus on mT5, an interesting architecture based on T5 that was pretrained in a text-to-text framework. In T5, every NLP task is formulated in terms of a prompt prefix like `summarize:` which conditions the model to adapt the generated text to the prompt. As shown in the figure below, this makes T5 extremely versatile, as you can solve many tasks with a single model!
+
+
+
+
+ +
+ +
+
+
+mT5 doesn't use prefixes, but shares much of the versatility of T5 and has the advantage of being multilingual. Now that we've picked a model, let's take a look at preparing our data for training.
+
+
+
+
+
+ +
+ +
+
+
+Let's see exactly how this works by looking at the first two examples:
+
+```py
+from transformers import AutoTokenizer
+
+context_length = 128
+tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
+
+outputs = tokenizer(
+ raw_datasets["train"][:2]["content"],
+ truncation=True,
+ max_length=context_length,
+ return_overflowing_tokens=True,
+ return_length=True,
+)
+
+print(f"Input IDs length: {len(outputs['input_ids'])}")
+print(f"Input chunk lengths: {(outputs['length'])}")
+print(f"Chunk mapping: {outputs['overflow_to_sample_mapping']}")
+```
+
+```python out
+Input IDs length: 34
+Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 117, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 41]
+Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```
+
+We can see that we get 34 segments in total from those two examples. Looking at the chunk lengths, we can see that the chunks at the ends of both documents have less than 128 tokens (117 and 41, respectively). These represent just a small fraction of the total chunks that we have, so we can safely throw them away. With the `overflow_to_sample_mapping` field, we can also reconstruct which chunks belonged to which input samples.
+
+With this operation we're using a handy feature of the `Dataset.map()` function in 🤗 Datasets, which is that it does not require one-to-one maps; as we saw in [section 3](/course/chapter7/3), we can create batches with more or fewer elements than the input batch. This is useful when doing operations like data augmentation or data filtering that change the number of elements. In our case, when tokenizing each element into chunks of the specified context size, we create many samples from each document. We just need to make sure to delete the existing columns, since they have a conflicting size. If we wanted to keep them, we could repeat them appropriately and return them within the `Dataset.map()` call:
+
+```py
+def tokenize(element):
+ outputs = tokenizer(
+ element["content"],
+ truncation=True,
+ max_length=context_length,
+ return_overflowing_tokens=True,
+ return_length=True,
+ )
+ input_batch = []
+ for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
+ if length == context_length:
+ input_batch.append(input_ids)
+ return {"input_ids": input_batch}
+
+
+tokenized_datasets = raw_datasets.map(
+ tokenize, batched=True, remove_columns=raw_datasets["train"].column_names
+)
+tokenized_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['input_ids'],
+ num_rows: 16702061
+ })
+ valid: Dataset({
+ features: ['input_ids'],
+ num_rows: 93164
+ })
+})
+```
+
+We now have 16.7 million examples with 128 tokens each, which corresponds to about 2.1 billion tokens in total. For reference, OpenAI's GPT-3 and Codex models are trained on 300 and 100 billion tokens, respectively, where the Codex models are initialized from the GPT-3 checkpoints. Our goal in this section is not to compete with these models, which can generate long, coherent texts, but to create a scaled-down version providing a quick autocomplete function for data scientists.
+
+Now that we have the dataset ready, let's set up the model!
+
+
+
+
+ +
+ +
+
+
+In this case the context is not too long, but some of the examples in the dataset have very long contexts that will exceed the maximum length we set (which is 384 in this case). As we saw in [Chapter 6](/course/chapter6/4) when we explored the internals of the `question-answering` pipeline, we will deal with long contexts by creating several training features from one sample of our dataset, with a sliding window between them.
+
+To see how this works using the current example, we can limit the length to 100 and use a sliding window of 50 tokens. As a reminder, we use:
+
+- `max_length` to set the maximum length (here 100)
+- `truncation="only_second"` to truncate the context (which is in the second position) when the question with its context is too long
+- `stride` to set the number of overlapping tokens between two successive chunks (here 50)
+- `return_overflowing_tokens=True` to let the tokenizer know we want the overflowing tokens
+
+```py
+inputs = tokenizer(
+ question,
+ context,
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+)
+
+for ids in inputs["input_ids"]:
+ print(tokenizer.decode(ids))
+```
+
+```python out
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basi [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
+```
+
+As we can see, our example has been in split into four inputs, each of them containing the question and some part of the context. Note that the answer to the question ("Bernadette Soubirous") only appears in the third and last inputs, so by dealing with long contexts in this way we will create some training examples where the answer is not included in the context. For those examples, the labels will be `start_position = end_position = 0` (so we predict the `[CLS]` token). We will also set those labels in the unfortunate case where the answer has been truncated so that we only have the start (or end) of it. For the examples where the answer is fully in the context, the labels will be the index of the token where the answer starts and the index of the token where the answer ends.
+
+The dataset provides us with the start character of the answer in the context, and by adding the length of the answer, we can find the end character in the context. To map those to token indices, we will need to use the offset mappings we studied in [Chapter 6](/course/chapter6/4). We can have our tokenizer return these by passing along `return_offsets_mapping=True`:
+
+```py
+inputs = tokenizer(
+ question,
+ context,
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+)
+inputs.keys()
+```
+
+```python out
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])
+```
+
+As we can see, we get back the usual input IDs, token type IDs, and attention mask, as well as the offset mapping we required and an extra key, `overflow_to_sample_mapping`. The corresponding value will be of use to us when we tokenize several texts at the same time (which we should do to benefit from the fact that our tokenizer is backed by Rust). Since one sample can give several features, it maps each feature to the example it originated from. Because here we only tokenized one example, we get a list of `0`s:
+
+```py
+inputs["overflow_to_sample_mapping"]
+```
+
+```python out
+[0, 0, 0, 0]
+```
+
+But if we tokenize more examples, this will become more useful:
+
+```py
+inputs = tokenizer(
+ raw_datasets["train"][2:6]["question"],
+ raw_datasets["train"][2:6]["context"],
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+)
+
+print(f"The 4 examples gave {len(inputs['input_ids'])} features.")
+print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")
+```
+
+```python out
+'The 4 examples gave 19 features.'
+'Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].'
+```
+
+As we can see, the first three examples (at indices 2, 3, and 4 in the training set) each gave four features and the last example (at index 5 in the training set) gave 7 features.
+
+This information will be useful to map each feature we get to its corresponding label. As mentioned earlier, those labels are:
+
+- `(0, 0)` if the answer is not in the corresponding span of the context
+- `(start_position, end_position)` if the answer is in the corresponding span of the context, with `start_position` being the index of the token (in the input IDs) at the start of the answer and `end_position` being the index of the token (in the input IDs) where the answer ends
+
+To determine which of these is the case and, if relevant, the positions of the tokens, we first find the indices that start and end the context in the input IDs. We could use the token type IDs to do this, but since those do not necessarily exist for all models (DistilBERT does not require them, for instance), we'll instead use the `sequence_ids()` method of the `BatchEncoding` our tokenizer returns.
+
+Once we have those token indices, we look at the corresponding offsets, which are tuples of two integers representing the span of characters inside the original context. We can thus detect if the chunk of the context in this feature starts after the answer or ends before the answer begins (in which case the label is `(0, 0)`). If that's not the case, we loop to find the first and last token of the answer:
+
+```py
+answers = raw_datasets["train"][2:6]["answers"]
+start_positions = []
+end_positions = []
+
+for i, offset in enumerate(inputs["offset_mapping"]):
+ sample_idx = inputs["overflow_to_sample_mapping"][i]
+ answer = answers[sample_idx]
+ start_char = answer["answer_start"][0]
+ end_char = answer["answer_start"][0] + len(answer["text"][0])
+ sequence_ids = inputs.sequence_ids(i)
+
+ # Find the start and end of the context
+ idx = 0
+ while sequence_ids[idx] != 1:
+ idx += 1
+ context_start = idx
+ while sequence_ids[idx] == 1:
+ idx += 1
+ context_end = idx - 1
+
+ # If the answer is not fully inside the context, label is (0, 0)
+ if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
+ start_positions.append(0)
+ end_positions.append(0)
+ else:
+ # Otherwise it's the start and end token positions
+ idx = context_start
+ while idx <= context_end and offset[idx][0] <= start_char:
+ idx += 1
+ start_positions.append(idx - 1)
+
+ idx = context_end
+ while idx >= context_start and offset[idx][1] >= end_char:
+ idx -= 1
+ end_positions.append(idx + 1)
+
+start_positions, end_positions
+```
+
+```python out
+([83, 51, 19, 0, 0, 64, 27, 0, 34, 0, 0, 0, 67, 34, 0, 0, 0, 0, 0],
+ [85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0])
+```
+
+Let's take a look at a few results to verify that our approach is correct. For the first feature we find `(83, 85)` as labels, so let's compare the theoretical answer with the decoded span of tokens from 83 to 85 (inclusive):
+
+```py
+idx = 0
+sample_idx = inputs["overflow_to_sample_mapping"][idx]
+answer = answers[sample_idx]["text"][0]
+
+start = start_positions[idx]
+end = end_positions[idx]
+labeled_answer = tokenizer.decode(inputs["input_ids"][idx][start : end + 1])
+
+print(f"Theoretical answer: {answer}, labels give: {labeled_answer}")
+```
+
+```python out
+'Theoretical answer: the Main Building, labels give: the Main Building'
+```
+
+So that's a match! Now let's check index 4, where we set the labels to `(0, 0)`, which means the answer is not in the context chunk of that feature:
+
+```py
+idx = 4
+sample_idx = inputs["overflow_to_sample_mapping"][idx]
+answer = answers[sample_idx]["text"][0]
+
+decoded_example = tokenizer.decode(inputs["input_ids"][idx])
+print(f"Theoretical answer: {answer}, decoded example: {decoded_example}")
+```
+
+```python out
+'Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]'
+```
+
+Indeed, we don't see the answer inside the context.
+
+
+
+-100 as the label for tokens we want to ignore in the loss."
+ },
+ {
+ text: "We need to make sure to truncate or pad the labels to the same size as the inputs, when applying truncation/padding.",
+ explain: "Indeed! That's not the only difference, though.",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. What problem arises when we tokenize the words in a token classification problem and want to label the tokens?
+
+targets=....",
+ explain: "This might be an API we add in the future, but that's not possible right now."
+ },
+ {
+ text: "The inputs and the targets both have to be preprocessed, in two separate calls to the tokenizer.",
+ explain: "That is true, but incomplete. There is something you need to do to make sure the tokenizer processes both properly."
+ },
+ {
+ text: "As usual, we just have to tokenize the inputs.",
+ explain: "Not in a sequence classification problem; the targets are also texts we need to convert into numbers!"
+ },
+ {
+ text: "The inputs have to be sent to the tokenizer, and the targets too, but under a special context manager.",
+ explain: "That's correct, the tokenizer needs to be put into target mode by that context manager.",
+ correct: true
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+
+### 8. Why is there a specific subclass of `Trainer` for sequence-to-sequence problems?
+
+generate() method.",
+ correct: true
+ },
+ {
+ text: "Because the targets are texts in sequence-to-sequence problems",
+ explain: "The Trainer doesn't really care about that since they have been preprocessed before."
+ },
+ {
+ text: "Because we use two models in sequence-to-sequence problems",
+ explain: "We do use two models in a way, an encoder and a decoder, but they are grouped together in one model."
+ }
+ ]}
+/>
+
+{:else}
+
+### 9. Why is it often unnecessary to specify a loss when calling `compile()` on a Transformer model?
+
+
-
+
+
-As in the previous sections, you can find the actual model that we'll train and upload to the Hub using the code below and double-check its predictions [here](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+Ca și în secțiunile anterioare, puteți găsi modelul pe care îl vom antrena și încărca în Hub utilizând codul de mai jos și puteți verifica predicțiile acestuia [aici](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
-## Preparing the data[[preparing-the-data]]
+## Pregătirea datelor[[preparing-the-data]]
-To fine-tune or train a translation model from scratch, we will need a dataset suitable for the task. As mentioned previously, we'll use the [KDE4 dataset](https://huggingface.co/datasets/kde4) in this section, but you can adapt the code to use your own data quite easily, as long as you have pairs of sentences in the two languages you want to translate from and into. Refer back to [Chapter 5](/course/chapter5) if you need a reminder of how to load your custom data in a `Dataset`.
+Pentru a face fine-tune sau a antrena un model de traducere de la zero, vom avea nevoie de un dataset adecvat pentru această sarcină. După cum am menționat anterior, vom utiliza [datasetul KDE4](https://huggingface.co/datasets/kde4) în această secțiune, dar puteți adapta codul pentru a utiliza propriile date destul de ușor, atâta timp cât aveți perechi de propoziții în cele două limbi din și în care doriți să traduceți. Consultați [Capitolul 5](/course/chapter5) dacă aveți nevoie de o reamintire a modului de încărcare a datelor personalizate într-un `Dataset`.
-### The KDE4 dataset[[the-kde4-dataset]]
+### Datasetul KDE4[[the-kde4-dataset]]
-As usual, we download our dataset using the `load_dataset()` function:
+Ca de obicei, descărcăm datasetul nostru folosind funcția `load_dataset()`:
```py
from datasets import load_dataset
@@ -58,11 +58,11 @@ from datasets import load_dataset
raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
```
-If you want to work with a different pair of languages, you can specify them by their codes. A total of 92 languages are available for this dataset; you can see them all by expanding the language tags on its [dataset card](https://huggingface.co/datasets/kde4).
+Dacă doriți să lucrați cu o pereche de limbi diferită, le puteți specifica prin codurile lor. Un total de 92 de limbi sunt disponibile pentru acest dataset; le puteți vedea pe toate prin extinderea labelurilor de limbă pe [dataset cardul acesteia](https://huggingface.co/datasets/kde4).
-
+
-Let's have a look at the dataset:
+Să aruncăm o privire la dataset:
```py
raw_datasets
@@ -77,7 +77,7 @@ DatasetDict({
})
```
-We have 210,173 pairs of sentences, but in one single split, so we will need to create our own validation set. As we saw in [Chapter 5](/course/chapter5), a `Dataset` has a `train_test_split()` method that can help us. We'll provide a seed for reproducibility:
+Avem 210 173 de perechi de propoziții, dar într-o singură împărțire, deci va trebui să ne creăm propriul set de validare. Așa cum am văzut în [Capitolul 5](/course/chapter5), un `Dataset` are o metodă `train_test_split()` care ne poate ajuta. Vom furniza un seed pentru reproductibilitate:
```py
split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
@@ -97,13 +97,13 @@ DatasetDict({
})
```
-We can rename the `"test"` key to `"validation"` like this:
+Putem redenumi cheia `"test"` în `"validation"` astfel:
```py
split_datasets["validation"] = split_datasets.pop("test")
```
-Now let's take a look at one element of the dataset:
+Acum să aruncăm o privire la un element al datasetului:
```py
split_datasets["train"][1]["translation"]
@@ -114,7 +114,7 @@ split_datasets["train"][1]["translation"]
'fr': 'Par défaut, développer les fils de discussion'}
```
-We get a dictionary with two sentences in the pair of languages we requested. One particularity of this dataset full of technical computer science terms is that they are all fully translated in French. However, French engineers leave most computer science-specific words in English when they talk. Here, for instance, the word "threads" might well appear in a French sentence, especially in a technical conversation; but in this dataset it has been translated into the more correct "fils de discussion." The pretrained model we use, which has been pretrained on a larger corpus of French and English sentences, takes the easier option of leaving the word as is:
+Obținem un dicționar cu două propoziții în perechea de limbi solicitate. O particularitate a acestui dataset plin de termeni tehnici din domeniul informaticii este că toate sunt traduse integral în franceză. Cu toate acestea, inginerii francezi lasă majoritatea cuvintelor specifice informaticii în engleză atunci când vorbesc. Aici, de exemplu, cuvântul "threads" ar putea foarte bine să apară într-o propoziție în limba franceză, în special într-o conversație tehnică; dar în acest dataset a fost tradus în "fils de discussion". Modelul preantrenat pe care îl folosim, care a fost preantrenat pe un corpus mai mare de propoziții în franceză și engleză, alege opțiunea mai ușoară de a lăsa cuvântul așa cum este:
```py
from transformers import pipeline
@@ -128,8 +128,8 @@ translator("Default to expanded threads")
[{'translation_text': 'Par défaut pour les threads élargis'}]
```
-Another example of this behavior can be seen with the word "plugin," which isn't officially a French word but which most native speakers will understand and not bother to translate.
-In the KDE4 dataset this word has been translated in French into the more official "module d'extension":
+Un alt exemplu al acestui comportament poate fi văzut cu cuvântul "plugin", care nu este oficial un cuvânt francez, dar pe care majoritatea vorbitorilor nativi îl vor înțelege și nu se vor obosi să îl traducă.
+În datasetul KDE4, acest cuvânt a fost tradus în franceză în termenul puțin mai oficial "module d'extension":
```py
split_datasets["train"][172]["translation"]
@@ -140,7 +140,7 @@ split_datasets["train"][172]["translation"]
'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
```
-Our pretrained model, however, sticks with the compact and familiar English word:
+Modelul nostru preantrenat, cu toate acestea, rămâne la cuvântul englez compact și familiar:
```py
translator(
@@ -152,21 +152,21 @@ translator(
[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
```
-It will be interesting to see if our fine-tuned model picks up on those particularities of the dataset (spoiler alert: it will).
+Va fi interesant de văzut dacă modelul nostru fine-tuned reține aceste particularități ale datasetului(spoiler alert: va reține).
-
-
+
+
-To deal with this, we'll filter out the examples with very short titles so that our model can produce more interesting summaries. Since we're dealing with English and Spanish texts, we can use a rough heuristic to split the titles on whitespace and then use our trusty `Dataset.filter()` method as follows:
+Pentru a rezolva acest lucru, vom filtra exemplele cu titluri foarte scurte, astfel încât modelul nostru să poată produce rezumate mai interesante. Deoarece avem de-a face cu texte în engleză și spaniolă, putem folosi rough heuristic pentru a face split titlurilor pe baza spațiului alb și apoi să folosim metoda noastră de încredere `Dataset.filter()` după cum urmează:
```python
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
@@ -203,34 +204,34 @@ books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) >
Now that we've prepared our corpus, let's take a look at a few possible Transformer models that one might fine-tune on it!
-## Models for text summarization[[models-for-text-summarization]]
+## Modele pentru sumarizarea textului[[models-for-text-summarization]]
-If you think about it, text summarization is a similar sort of task to machine translation: we have a body of text like a review that we'd like to "translate" into a shorter version that captures the salient features of the input. Accordingly, most Transformer models for summarization adopt the encoder-decoder architecture that we first encountered in [Chapter 1](/course/chapter1), although there are some exceptions like the GPT family of models which can also be used for summarization in few-shot settings. The following table lists some popular pretrained models that can be fine-tuned for summarization.
+Dacă vă gândiți bine, rezumarea textului este o sarcină similară cu machine translation: avem un corp de text, cum ar fi o recenzie, pe care am dori să o "traducem" într-o versiune mai scurtă care să capteze caracteristicile principale ale datelor de intrare. În consecință, majoritatea modelelor Transformer pentru rezumare adoptă arhitectura codificator-decodificator pe care am întâlnit-o pentru prima dată în [Capitolul 1](/course/chapter1), deși există unele excepții, cum ar fi familia de modele GPT, care poate fi, de asemenea, utilizată pentru rezumare în few-shot settings. Tabelul de mai jos enumeră câteva modele preantrenate populare care pot fi ajustate pentru sumarizare.
| Transformer model | Description | Multilingual? |
| :---------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-----------: |
-| [GPT-2](https://huggingface.co/gpt2-xl) | Although trained as an auto-regressive language model, you can make GPT-2 generate summaries by appending "TL;DR" at the end of the input text. | ❌ |
-| [PEGASUS](https://huggingface.co/google/pegasus-large) | Uses a pretraining objective to predict masked sentences in multi-sentence texts. This pretraining objective is closer to summarization than vanilla language modeling and scores highly on popular benchmarks. | ❌ |
-| [T5](https://huggingface.co/t5-base) | A universal Transformer architecture that formulates all tasks in a text-to-text framework; e.g., the input format for the model to summarize a document is `summarize: ARTICLE`. | ❌ |
-| [mT5](https://huggingface.co/google/mt5-base) | A multilingual version of T5, pretrained on the multilingual Common Crawl corpus (mC4), covering 101 languages. | ✅ |
-| [BART](https://huggingface.co/facebook/bart-base) | A novel Transformer architecture with both an encoder and a decoder stack trained to reconstruct corrupted input that combines the pretraining schemes of BERT and GPT-2. | ❌ |
-| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | A multilingual version of BART, pretrained on 50 languages. | ✅ |
+| [GPT-2](https://huggingface.co/gpt2-xl) | Deși este antrenat ca un model lingvistic autoregresiv, puteți face GPT-2 să genereze rezumate prin adăugarea "TL;DR" la sfârșitul textului de intrare. | ❌ |
+| [PEGASUS](https://huggingface.co/google/pegasus-large) | Utilizează un obiectiv de preantrenare pentru a prezice propoziții mascate în texte cu mai multe propoziții. Acest obiectiv de preantrenare este mai apropiat de rezumare decât de vanilla language modeling și obține scoruri ridicate la standardele populare. | ❌ |
+| [T5](https://huggingface.co/t5-base) | O arhitectură Transformer universală care formulează toate sarcinile într-un framework text-text; de exemplu, formatul de intrare pentru modelul de rezumare a unui document este `summarize: ARTICOL`. | ❌ |
+| [mT5](https://huggingface.co/google/mt5-base) | O versiune multilingvă a T5, preantrenată pe corpusul multilingv Common Crawl (mC4), care acoperă 101 limbi. | ✅ |
+| [BART](https://huggingface.co/facebook/bart-base) | O nouă arhitectură Transformer cu un encoder și un stack de decodere antrenate pentru a reconstrui intrarea coruptă care combină schemele de preantrenare ale BERT și GPT-2. | ❌ |
+| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | O versiune multilingvă a BART, preantrenată pe 50 de limbi. | ✅ |
-As you can see from this table, the majority of Transformer models for summarization (and indeed most NLP tasks) are monolingual. This is great if your task is in a "high-resource" language like English or German, but less so for the thousands of other languages in use across the world. Fortunately, there is a class of multilingual Transformer models, like mT5 and mBART, that come to the rescue. These models are pretrained using language modeling, but with a twist: instead of training on a corpus of one language, they are trained jointly on texts in over 50 languages at once!
+După cum puteți vedea din acest tabel, majoritatea modelelor Transformer pentru rezumare (și, într-adevăr, majoritatea sarcinilor NLP) sunt monolingve. Acest lucru este grozav dacă sarcina voastrăeste într-o limbă cu multe resurse precum engleza sau germana, dar mai puțin pentru miile de alte limbi utilizate în întreaga lume. Din fericire, există o clasă de modele Transformer multilingve, precum mT5 și mBART, care vin în ajutor. Aceste modele sunt preantrenate folosind modelarea limbajului, dar cu o întorsătură: în loc să fie antrenate pe un corpus dintr-o singură limbă, ele sunt antrenate împreună pe texte în peste 50 de limbi deodată!
-We'll focus on mT5, an interesting architecture based on T5 that was pretrained in a text-to-text framework. In T5, every NLP task is formulated in terms of a prompt prefix like `summarize:` which conditions the model to adapt the generated text to the prompt. As shown in the figure below, this makes T5 extremely versatile, as you can solve many tasks with a single model!
+Ne vom concentra asupra mT5, o arhitectură interesantă bazată pe T5, care a fost preantrenată într-un cadru text-to-text. În T5, fiecare sarcină NLP este formulată în termenii unui prompt prefix precum `summarize:` care condiționează modelul să adapteze textul generat la prompt. După cum se arată în figura de mai jos, acest lucru face T5 extrem de versatil, deoarece puteți rezolva multe sarcini cu un singur model!
-
+
+
-
-
+
+
-mT5 doesn't use prefixes, but shares much of the versatility of T5 and has the advantage of being multilingual. Now that we've picked a model, let's take a look at preparing our data for training.
+mT5 nu utilizează prefixe, dar împărtășește o mare parte din versatilitatea T5 și are avantajul de a fi multilingv. Acum că am ales un model, să aruncăm o privire la pregătirea datelor noastre pentru antrenare.
-
+
+
-
-
+
+
-Let's see exactly how this works by looking at the first two examples:
+Să vedem exact cum funcționează acest lucru analizând primele două exemple:
```py
from transformers import AutoTokenizer
@@ -209,9 +209,9 @@ Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128
Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
-We can see that we get 34 segments in total from those two examples. Looking at the chunk lengths, we can see that the chunks at the ends of both documents have less than 128 tokens (117 and 41, respectively). These represent just a small fraction of the total chunks that we have, so we can safely throw them away. With the `overflow_to_sample_mapping` field, we can also reconstruct which chunks belonged to which input samples.
+Putem vedea că obținem 34 de segmente în total din aceste două exemple. Uitându-ne la lungimea segmentelor, putem vedea că segmentele de la sfârșitul ambelor documente au mai puțin de 128 de token-uri (117 și, respectiv, 41). Acestea reprezintă doar o mică parte din totalul segmentelor pe care le avem, așa că le putem șterge în siguranță. Cu ajutorul câmpului `overflow_to_sample_mapping`, putem, de asemenea, să reconstituim care segmente au aparținut căror probe de intrare.
-With this operation we're using a handy feature of the `Dataset.map()` function in 🤗 Datasets, which is that it does not require one-to-one maps; as we saw in [section 3](/course/chapter7/3), we can create batches with more or fewer elements than the input batch. This is useful when doing operations like data augmentation or data filtering that change the number of elements. In our case, when tokenizing each element into chunks of the specified context size, we create many samples from each document. We just need to make sure to delete the existing columns, since they have a conflicting size. If we wanted to keep them, we could repeat them appropriately and return them within the `Dataset.map()` call:
+Cu această operațiune folosim o caracteristică utilă a funcției `Dataset.map()` din 🤗 Datasets, și anume că nu necesită one-to-one maps; așa cum am văzut în [secțiunea 3](/course/chaptero7/3), putem crea batch-uri cu mai multe sau mai puține elemente decât batch-ul de intrare. Acest lucru este util atunci când efectuăm operațiuni precum augmentarea sau filtrarea datelor care modifică numărul de elemente. În cazul nostru, atunci când tokenizăm fiecare element în segmente de dimensiunea contextului specificat, creăm multe probe din fiecare document. Trebuie doar să ne asigurăm că ștergem coloanele existente, deoarece acestea au o dimensiune conflictuală. Dacă am dori să le păstrăm, am putea să le repetăm în mod corespunzător și să le returnăm în cadrul apelului `Dataset.map()`:
```py
def tokenize(element):
@@ -248,20 +248,20 @@ DatasetDict({
})
```
-We now have 16.7 million examples with 128 tokens each, which corresponds to about 2.1 billion tokens in total. For reference, OpenAI's GPT-3 and Codex models are trained on 300 and 100 billion tokens, respectively, where the Codex models are initialized from the GPT-3 checkpoints. Our goal in this section is not to compete with these models, which can generate long, coherent texts, but to create a scaled-down version providing a quick autocomplete function for data scientists.
+Avem acum 16,7 milioane de exemple cu 128 de tokenii fiecare, ceea ce corespunde unui total de aproximativ 2,1 miliarde de tokeni. Ca referință, modelele GPT-3 și Codex ale OpenAI sunt antrenate pe 300 și, respectiv, 100 de miliarde de tokeni, unde modelele Codex sunt inițializate din checkpointurile GPT-3. Scopul nostru în această secțiune nu este de a concura cu aceste modele, care pot genera texte lungi și coerente, ci de a crea o versiune la scară redusă care să ofere o funcție rapidă de autocompletare pentru data scientists.
-Now that we have the dataset ready, let's set up the model!
+Acum că avem datasetul gata, hai să configurăm modelul!
-
+
+
-
-
+
+
-In this case the context is not too long, but some of the examples in the dataset have very long contexts that will exceed the maximum length we set (which is 384 in this case). As we saw in [Chapter 6](/course/chapter6/4) when we explored the internals of the `question-answering` pipeline, we will deal with long contexts by creating several training features from one sample of our dataset, with a sliding window between them.
+În acest caz, contextul nu este prea lung, dar unele dintre exemplele din dataset au contexte foarte lungi care vor depăși lungimea maximă pe care am stabilit-o (care este de 384 în acest caz). După cum am văzut în [Capitolul 6](/course/chapter6/4) când am explorat elementele interne ale pipelineului `question-answering`, vom trata contextele lungi prin crearea mai multor caracteristici de antrenare dintr-un sample din datasetul nostru, cu un sliding window între ele.
-To see how this works using the current example, we can limit the length to 100 and use a sliding window of 50 tokens. As a reminder, we use:
+Pentru a vedea cum funcționează acest lucru folosind exemplul curent, putem limita lungimea la 100 și putem utiliza un sliding window de 50 de tokeni. Vă reamintim că folosim:
-- `max_length` to set the maximum length (here 100)
-- `truncation="only_second"` to truncate the context (which is in the second position) when the question with its context is too long
-- `stride` to set the number of overlapping tokens between two successive chunks (here 50)
-- `return_overflowing_tokens=True` to let the tokenizer know we want the overflowing tokens
+- `max_length` pentru a stabili lungimea maximă (aici 100)
+- `truncation="only_second"` pentru a trunchia contextul (care este în poziția a doua) atunci când întrebarea cu contextul său este prea lungă
+- `stride` pentru a seta numărul de tokeni care se suprapun între două bucăți succesive (aici 50)
+- `return_overflowing_tokens=True` pentru ca tokenizerul să știe că dorim tokenii care se suprapun
```py
inputs = tokenizer(
@@ -215,9 +215,9 @@ for ids in inputs["input_ids"]:
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
```
-As we can see, our example has been in split into four inputs, each of them containing the question and some part of the context. Note that the answer to the question ("Bernadette Soubirous") only appears in the third and last inputs, so by dealing with long contexts in this way we will create some training examples where the answer is not included in the context. For those examples, the labels will be `start_position = end_position = 0` (so we predict the `[CLS]` token). We will also set those labels in the unfortunate case where the answer has been truncated so that we only have the start (or end) of it. For the examples where the answer is fully in the context, the labels will be the index of the token where the answer starts and the index of the token where the answer ends.
+După cum se poate observa, exemplul nostru a fost împărțit în patru inputuri, fiecare dintre acestea conținând întrebarea și o parte din context. Rețineți că răspunsul la întrebare ("Bernadette Soubirous") apare doar în al treilea și ultimul input, astfel încât, prin tratarea contextelor lungi în acest mod, vom crea câteva exemple de antrenament în care răspunsul nu este inclus în context. Pentru aceste exemple, labelurile vor fi `start_position = end_position = 0` (deci vom prezice tokenul `[CLS]`). Vom seta aceste labeluri și în cazul nefericit în care răspunsul a fost trunchiat, astfel încât avem doar începutul (sau sfârșitul) acestuia. Pentru exemplele în care răspunsul este complet în context, labelurile vor fi indicele tokenului în care începe răspunsul și indicele tokenului în care se termină răspunsul.
-The dataset provides us with the start character of the answer in the context, and by adding the length of the answer, we can find the end character in the context. To map those to token indices, we will need to use the offset mappings we studied in [Chapter 6](/course/chapter6/4). We can have our tokenizer return these by passing along `return_offsets_mapping=True`:
+Datasetul ne oferă caracterul de început al răspunsului în context, iar prin adăugarea lungimii răspunsului, putem găsi caracterul de sfârșit în context. Pentru a le corela cu indicii tokenilor, va trebui să folosim offset mapping pe care le-am studiat în [Capitolul 6](/course/chapter6/4). Putem face ca tokenizatorul nostru să le returneze trecând `return_offsets_mapping=True`:
```py
inputs = tokenizer(
@@ -236,7 +236,7 @@ inputs.keys()
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])
```
-As we can see, we get back the usual input IDs, token type IDs, and attention mask, as well as the offset mapping we required and an extra key, `overflow_to_sample_mapping`. The corresponding value will be of use to us when we tokenize several texts at the same time (which we should do to benefit from the fact that our tokenizer is backed by Rust). Since one sample can give several features, it maps each feature to the example it originated from. Because here we only tokenized one example, we get a list of `0`s:
+După cum putem vedea, primim înapoi ID-urile obișnuite de intrare, ID-urile tipului de token și attention maskul, precum și offset mapping necesar și o cheie suplimentară, `overflow_to_sample_mapping`. Valoarea corespunzătoare ne va fi de folos atunci când vom tokeniza mai multe texte în același timp (ceea ce ar trebui să facem pentru a beneficia de faptul că tokenizerul nostru este susținut de Rust). Deoarece un sample poate oferi mai multe caracteristici, aceasta mapează fiecare caracteristică la exemplul din care provine. Deoarece aici am tokenizat un singur exemplu, obținem o listă de `0`:
```py
inputs["overflow_to_sample_mapping"]
@@ -246,7 +246,7 @@ inputs["overflow_to_sample_mapping"]
[0, 0, 0, 0]
```
-But if we tokenize more examples, this will become more useful:
+Dar dacă vom tokeniza mai multe exemple, acest lucru va deveni mai util:
```py
inputs = tokenizer(
@@ -268,16 +268,16 @@ print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")
'Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].'
```
-As we can see, the first three examples (at indices 2, 3, and 4 in the training set) each gave four features and the last example (at index 5 in the training set) gave 7 features.
+După cum se poate observa, primele trei exemple (la indicii 2, 3 și 4 din setul de antrenare) au dat fiecare câte patru caracteristici, iar ultimul exemplu (la indicele 5 din setul de antrenare) a dat 7 caracteristici.
-This information will be useful to map each feature we get to its corresponding label. As mentioned earlier, those labels are:
+Aceste informații vor fi utile pentru a corela fiecare caracteristică obținută cu labeul corespunzător. După cum am menționat anterior, aceste labelurile sunt:
-- `(0, 0)` if the answer is not in the corresponding span of the context
-- `(start_position, end_position)` if the answer is in the corresponding span of the context, with `start_position` being the index of the token (in the input IDs) at the start of the answer and `end_position` being the index of the token (in the input IDs) where the answer ends
+- `(0, 0)` dacă răspunsul nu se află în intervalul corespunzător al contextului
+- `(start_position, end_position)` dacă răspunsul se află în intervalul corespunzător al contextului, cu `start_position` fiind indicele tokenului (în ID-urile de intrare) la începutul răspunsului și `end_position` fiind indicele tokenului (în ID-urile de intrare) unde se termină răspunsul
-To determine which of these is the case and, if relevant, the positions of the tokens, we first find the indices that start and end the context in the input IDs. We could use the token type IDs to do this, but since those do not necessarily exist for all models (DistilBERT does not require them, for instance), we'll instead use the `sequence_ids()` method of the `BatchEncoding` our tokenizer returns.
+Pentru a determina care dintre acestea este cazul și, dacă este relevant, pozițiile tokenilor, vom găsi mai întâi indicii care încep și termină contextul în ID-urile de intrare. Am putea folosi ID-urile tipului de token pentru a face acest lucru, dar deoarece acestea nu există neapărat pentru toate modelele (DistilBERT nu le solicită, de exemplu), vom folosi în schimb metoda `sequence_ids()` a `BatchEncoding` pe care tokenizerul nostru o returnează.
-Once we have those token indices, we look at the corresponding offsets, which are tuples of two integers representing the span of characters inside the original context. We can thus detect if the chunk of the context in this feature starts after the answer or ends before the answer begins (in which case the label is `(0, 0)`). If that's not the case, we loop to find the first and last token of the answer:
+Odată ce avem indicii tokenilor, ne uităm la offseturile corespunzătoare, care sunt tupeluri de două numere întregi reprezentând intervalul de caractere din contextul original. Astfel, putem detecta dacă bucățica de context din această caracteristică începe după răspuns sau se termină înainte de începerea răspunsului (caz în care eticheta este `(0, 0)`). Dacă nu este cazul, facem o buclă pentru a găsi primul și ultimul token al răspunsului:
```py
answers = raw_datasets["train"][2:6]["answers"]
@@ -324,7 +324,7 @@ start_positions, end_positions
[85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0])
```
-Let's take a look at a few results to verify that our approach is correct. For the first feature we find `(83, 85)` as labels, so let's compare the theoretical answer with the decoded span of tokens from 83 to 85 (inclusive):
+Să aruncăm o privire la câteva rezultate pentru a verifica dacă abordarea noastră este corectă. Pentru prima caracteristică găsim `(83, 85)` ca labeluri, așa că comparăm răspunsul teoretic cu intervalul decodat de tokeni de la 83 la 85 (inclusiv):
```py
idx = 0
@@ -342,7 +342,7 @@ print(f"Theoretical answer: {answer}, labels give: {labeled_answer}")
'Theoretical answer: the Main Building, labels give: the Main Building'
```
-So that's a match! Now let's check index 4, where we set the labels to `(0, 0)`, which means the answer is not in the context chunk of that feature:
+Deci, asta e o potrivire! Acum să verificăm indexul 4, unde am setat labelurile la `(0, 0)`, ceea ce înseamnă că răspunsul nu se află în chunkul de context al acelei caracteristici:
```py
idx = 4
@@ -357,15 +357,15 @@ print(f"Theoretical answer: {answer}, decoded example: {decoded_example}")
'Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]'
```
-Indeed, we don't see the answer inside the context.
+Într-adevăr, nu vedem răspunsul în interiorul contextului.
-
+
+
-100 as the label for tokens we want to ignore in the loss."
+ text: "Folosim -100 pentru a eticheta tokenii speciali.",
+ explain: "Acest lucru nu este specific clasificării tokenilor - folosim întotdeauna -100 ca label pentru tokenii pe care dorim să îi ignorăm în pierdere."
},
{
- text: "We need to make sure to truncate or pad the labels to the same size as the inputs, when applying truncation/padding.",
- explain: "Indeed! That's not the only difference, though.",
+ text: "Trebuie să ne asigurăm că labelurile sunt trunchiate sau padded la aceeași dimensiune ca și inputurile, atunci când aplicăm trunchierea/paddingul.",
+ explain: "Într-adevăr! Totuși, aceasta nu este singura diferență.",
correct: true
}
]}
/>
-### 3. What problem arises when we tokenize the words in a token classification problem and want to label the tokens?
+### 3. Ce problemă apare atunci când tokenizăm cuvintele într-o problemă de clasificare a tokenilor și dorim să etichetăm tokenii?
-100, astfel încât acestea să fie ignorate în pierdere."
},
{
- text: "Each word can produce several tokens, so we end up with more tokens than we have labels.",
- explain: "That is the main problem, and we need to align the original labels with the tokens.",
+ text: "Fiecare cuvânt poate produce mai mulți tokeni, astfel încât ajungem să avem mai multe tokeni decât labeluri.",
+ explain: "Aceasta este problema principală, iar noi trebuie să aliniem labelurile originale cu tokenii.",
correct: true
},
{
- text: "The added tokens have no labels, so there is no problem.",
- explain: "That's incorrect; we need as many labels as we have tokens or our models will error out."
+ text: "Tokenii adăugați nu au etichete, deci nu există nicio problemă.",
+ explain: "Incorect; avem nevoie de atâtea etichete câțo tokeni avem, altfel modelele noastre vor da erori."
}
]}
/>
-### 4. What does "domain adaptation" mean?
+### 4. Ce înseamnă "domain adaptation"??
targets=....",
- explain: "This might be an API we add in the future, but that's not possible right now."
+ text: "Inputurile și targeturile trebuie trimise împreună la tokenizer cu inputs=... și targets=....",
+ explain: "Acesta ar putea fi un API pe care îl vom adăuga în viitor, dar nu este disponibil acum."
},
{
- text: "The inputs and the targets both have to be preprocessed, in two separate calls to the tokenizer.",
- explain: "That is true, but incomplete. There is something you need to do to make sure the tokenizer processes both properly."
+ text: "Inputurile și targturile trebuie preprocesate, în două apeluri separate către tokenizer.",
+ explain: "Acest lucru este adevărat, dar incomplet. Trebuie să faceți ceva pentru a vă asigura că tokenizerul le procesează pe ambele în mod corespunzător."
},
{
- text: "As usual, we just have to tokenize the inputs.",
- explain: "Not in a sequence classification problem; the targets are also texts we need to convert into numbers!"
+ text: "Ca de obicei, trebuie doar să tokenizăm inputurile.",
+ explain: "Nu într-o problemă de clasificare a secvențelor; targeturile sunt de asemenea texte pe care trebuie să le convertim în numere!"
},
{
- text: "The inputs have to be sent to the tokenizer, and the targets too, but under a special context manager.",
- explain: "That's correct, the tokenizer needs to be put into target mode by that context manager.",
+ text: "Inputurile trebuie să fie trimise către tokenizer, la fel și targeturile, dar în cadrul unui manager de context special.",
+ explain: "Corect, tokenizerul trebuie să fie pus în target mode de către acel context manager.",
correct: true
}
]}
@@ -182,148 +182,148 @@ Let's test what you learned in this chapter!
{#if fw === 'pt'}
-### 8. Why is there a specific subclass of `Trainer` for sequence-to-sequence problems?
+### 8. De ce există o subclasă specifică a `Trainer` pentru problemele sequence-to-sequence?
-100",
+ explain: "Aceasta nu este deloc o pierdere personalizată, ci modul în care pierderea este întotdeauna calculată."
},
{
- text: "Because sequence-to-sequence problems require a special evaluation loop",
- explain: "That's correct. Sequence-to-sequence models' predictions are often run using the generate() method.",
+ text: "Deoarece problemele de sequence-to-sequence la secvență necesită o buclă de evaluare specială",
+ explain: "Acest lucru este corect. Predicțiile modelelor sequence-to-sequence sunt de obicei rulate cu metoda generate().",
correct: true
},
{
- text: "Because the targets are texts in sequence-to-sequence problems",
- explain: "The Trainer doesn't really care about that since they have been preprocessed before."
+ text: "Deoarece targeturile sunt texte în probleme sequence-to-sequence",
+ explain: "Trainer-ului nu prea îi pasă de asta, deoarece acestea au fost preprocesate înainte."
},
{
- text: "Because we use two models in sequence-to-sequence problems",
- explain: "We do use two models in a way, an encoder and a decoder, but they are grouped together in one model."
+ text: "Deoarece folosim două modele în problemele sequence-to-sequence",
+ explain: "Într-un fel, folosim două modele, un codificator și un decodificator, dar acestea sunt grupate într-un singur model."
}
]}
/>
{:else}
-### 9. Why is it often unnecessary to specify a loss when calling `compile()` on a Transformer model?
+### 9. De ce este adesea inutil să se specifice o pierdere atunci când se apelează `compile()` pe un model Transformer?
- -
-
-
-Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
-
-```
-!pip install transformers
-```
-
-Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
-
-```
-import transformers
-```
-
-
-
- -
-
-
-Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
-
-```
-!pip install transformers[sentencepiece]
-```
-
-Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
-
-## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
-
-Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
-
-Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
-
-Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
-
-În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
-
-În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
-
-```
-mkdir ~/transformers-course
-cd ~/transformers-course
-```
-
-Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
-
-```
-python -m venv .env
-```
-
-Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
-
-```
-ls -a
-```
-
-```out
-. .. .env
-```
-
-Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
-
-```
-# Activează mediul virtual
-source .env/bin/activate
-
-# Dezactivează virtual environment-ul
-deactivate
-```
-
-Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
-
-```
-which python
-```
-
-```out
-/home/
-
- -
- -
-
-
-Să trecem rapid prin fiecare dintre acestea.
-
-## Preprocesarea cu un tokenizator[[preprocesarea-cu-un-tokenizerator]]
-
-La fel ca alte rețele neuronale, modelele Transformer nu pot procesa direct text brut, astfel încât primul pas al pipeline-ului nostru este de a converti intrările de text în numere pe care modelul le poate înțelege. Pentru a face acest lucru, folosim un *tokenizer*, care va fi responsabil pentru:
-
-- Împărțirea datelor de intrare în cuvinte, părți de cuvinte sau simboluri (cum ar fi punctuația) care se numesc *tokens*
-- Maparea fiecărui token într-un număr întreg
-- Adăugarea de intrări suplimentare care pot fi utile pentru model
-
-Toată această preprocesare trebuie efectuată exact în același mod ca atunci când modelul a fost preinstruit, așa că mai întâi trebuie să descărcăm aceste informații din [Model Hub] (https://huggingface.co/models). Pentru a face acest lucru, folosim clasa `AutoTokenizer` și metoda sa `from_pretrained()`. Folosind numele checkpoint-ului modelului nostru, aceasta va prelua automat datele asociate cu tokenizer-ul modelului și le va stoca în cache (astfel încât acestea să fie descărcate doar prima dată când executați codul de mai jos).
-
-Deoarece punctul de control implicit al pipeline-ului `sentiment-analysis` este `distilbert-base-uncased-finetuned-sst-2-english` (puteți vedea fișa modelului [aici](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)), executăm următoarele:
-
-```python
-from transformers import AutoTokenizer
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-```
-
-Odată ce avem tokenizatorul, putem să îi transmitem direct propozițiile noastre și vom primi înapoi un dicționar care este gata să fie introdus în modelul nostru! Singurul lucru rămas de făcut este să convertim lista de ID-uri de intrare în tensori.
-
-Puteți utiliza 🤗 Transformers fără a trebui să vă faceți griji cu privire la cadrul ML utilizat ca backend; ar putea fi PyTorch sau TensorFlow, sau Flax pentru unele modele. Cu toate acestea, modelele Transformer acceptă numai *tensori * ca intrare. Dacă este prima dată când auziți despre tensori, vă puteți gândi la ei ca la matrici NumPy. Un array NumPy poate fi un scalar (0D), un vector (1D), o matrice (2D) sau poate avea mai multe dimensiuni. Este de fapt un tensor; tensorii altor cadre ML se comportă similar și sunt de obicei la fel de simplu de instanțiat ca și array-urile NumPy.
-
-Pentru a specifica tipul de tensori pe care dorim să îi primim înapoi (PyTorch, TensorFlow sau NumPy simplu), folosim argumentul `return_tensors`:
-
-
-{#if fw === 'pt'}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
-print(inputs)
-```
-{:else}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
-print(inputs)
-```
-{/if}
-
-
-Nu vă faceți încă griji cu privire la padding și trunchiere; le vom explica mai târziu. Principalele lucruri de reținut aici sunt că puteți trece o propoziție sau o listă de propoziții, precum și specificarea tipului de tensori pe care doriți să îi primiți înapoi (dacă nu este trecut niciun tip, veți primi o listă de liste ca rezultat)
-{#if fw === 'pt'}
-
-Iată cum arată rezultatele ca tensori PyTorch:
-
-```python out
-{
- 'input_ids': tensor([
- [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
- [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
- ]),
- 'attention_mask': tensor([
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- ])
-}
-```
-{:else}
-
-Iată cum arată rezultatele ca tensori TensorFlow:
-
-```python out
-{
- 'input_ids':
-
-
- -
- -
-
-
-
-Rezultatul modelului Transformer este trimis direct la head-ul modelului pentru a fi prelucrat.
-
-În această diagramă, modelul este reprezentat de stratul său de încorporare și de straturile următoare. Stratul de încorporare convertește fiecare ID de intrare din intrarea tokenizată într-un vector care reprezintă tokenul asociat. Straturile ulterioare manipulează acești vectori folosind mecanismul de atenție pentru a produce reprezentarea finală a propozițiilor.
-
-Există multe arhitecturi diferite disponibile în 🤗 Transformers, fiecare fiind concepută în jurul abordării unei sarcini specifice. Iată o listă neexhaustivă:
-
-- `*Model` (extragerea stărilor ascunse)
-- `*ForCausalLM`
-- `*ForMaskedLM`
-- `*ForMultipleChoice`
-- `*ForQuestionAnswering`
-- `*ForSequenceClassification`
-- `*ForTokenClassification`
-- și altele 🤗
-
-{#if fw === 'pt'}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `AutoModel`, ci `AutoModelForSequenceClassification`:
-
-```python
-from transformers import AutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(**inputs)
-```
-{:else}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `TFAutoModel`, ci `TFAutoModelForSequenceClassification`:
-
-```python
-from transformers import TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(inputs)
-```
-{/if}
-
-Acum, dacă ne uităm la forma ieșirilor noastre, dimensiunea va fi mult mai mică: head-ul modelului ia ca intrare vectorii multidimensionali pe care i-am văzut înainte și scoate vectori care conțin două valori (una pentru fiecare etichetă):
-
-```python
-print(outputs.logits.shape)
-```
-
-{#if fw === 'pt'}
-```python out
-torch.Size([2, 2])
-```
-{:else}
-```python out
-(2, 2)
-```
-{/if}
-
-
-Deoarece avem doar două propoziții și două etichete, rezultatul pe care îl obținem din modelul nostru este de forma 2 x 2.
-
-## Postprocesarea rezultatului[[postprocesarea-rezultatului]]
-
-Valorile pe care le obținem ca rezultat al modelului nostru nu au neapărat sens în sine. Să aruncăm o privire:
-
-```python
-print(outputs.logits)
-```
-
-{#if fw === 'pt'}
-```python out
-tensor([[-1.5607, 1.6123],
- [ 4.1692, -3.3464]], grad_fn=
-
-
-  -
-  -
-
-
-
-Există diferite moduri de a împărți textul. De exemplu, am putea folosi spațiu pentru a tokeniza textul în cuvinte prin aplicarea funcției `split()` din Python:
-
-
-```py
-tokenized_text = "Jim Henson was a puppeteer".split()
-print(tokenized_text)
-```
-
-```python out
-['Jim', 'Henson', 'was', 'a', 'puppeteer']
-```
-
-Există, de asemenea, variații ale tokenizerelor de cuvinte care au reguli suplimentare pentru punctuație. Cu acest tip de tokenizator, putem ajunge la „vocabulare” destul de mari, unde un vocabular este definit de numărul total de token-uri independente pe care le avem în corpus.
-
-Fiecărui cuvânt i se atribuie un ID, începând de la 0 și mergând până la dimensiunea vocabularului. Modelul utilizează aceste ID-uri pentru a identifica fiecare cuvânt.
-
-Dacă dorim să acoperim complet o limbă cu un tokenizer bazat pe cuvinte, va trebui să avem un identificator pentru fiecare cuvânt din limbă, ceea ce va genera o cantitate uriașă de token-uri. De exemplu, există peste 500 000 de cuvinte în limba engleză, astfel încât, pentru a construi o hartă de la fiecare cuvânt la un ID de intrare, ar trebui să ținem evidența unui număr atât de mare de ID-uri. În plus, cuvinte precum „dog” sunt reprezentate diferit de cuvinte precum „dogs”, iar modelul nu va avea inițial nicio modalitate de a ști că „dog” și „dogs” sunt similare: va identifica cele două cuvinte ca neavând legătură. Același lucru este valabil și pentru alte cuvinte similare, precum „run” și „running”, pe care modelul nu le va vedea inițial ca fiind similare.
-
-În cele din urmă, avem nevoie de un token personalizat pentru a reprezenta cuvintele care nu se află în vocabularul nostru. Acesta este cunoscut sub numele de token "necunoscut", adesea reprezentat ca "[UNK]" sau "<unk>". În general, este un indiciu rău dacă vedeți că tokenizatorul produce o mulțime de astfel de token-uri, deoarece nu a fost capabil să recupereze reprezentarea sensibilă a unui cuvânt și veți pierde informații pe parcurs. Scopul elaborării vocabularului este de a face în așa fel încât tokenizatorul să tokenizeze cât mai puține cuvinte posibil în tokenul necunoscut.
-
-O modalitate de a reduce numărul de token-uri necunoscute este de a merge un nivel mai adânc, folosind un tokenizer _character-based_.
-
-## Character-based[[character-based]]
-
-
-
-
-  -
-  -
-
-
-
-Nici această abordare nu este perfectă. Deoarece reprezentarea se bazează acum pe caractere și nu pe cuvinte, s-ar putea spune că, din punct de vedere intuitiv, este mai puțin relevantă: fiecare caracter nu înseamnă mult în sine, în timp ce în cazul cuvintelor situația este diferită. Totuși, acest lucru variază din nou în funcție de limbă; în chineză, de exemplu, fiecare caracter conține mai multe informații decât un caracter într-o limbă latină.
-
-Un alt lucru care trebuie luat în considerare este faptul că ne vom trezi cu o cantitate foarte mare de token-uri care vor fi prelucrate de modelul nostru: în timp ce un cuvânt ar fi un singur token cu un tokenizator bazat pe cuvinte, acesta se poate transforma cu ușurință în 10 sau mai multe token-uri atunci când este convertit în caractere.
-
-Pentru a obține ce este mai bun din ambele lumi, putem utiliza o a treia tehnică care combină cele două abordări: *subword tokenization*.
-
-## Subword tokenization[[subword-tokenization]]
-
-
-
-
-  -
-  -
-
-
-Aceste părți de cuvinte oferă în cele din urmă o mulțime de semnificații semantice: în exemplul de mai sus, "tokenization" a fost împărțit în "token" și "ization", două cuvinte care au o semnificație semantică, fiind în același timp eficiente din punct de vedere al spațiului (sunt necesare doar două cuvinte pentru a reprezenta un cuvânt lung). Acest lucru ne permite să avem o acoperire relativ bună cu vocabulare de dimensiuni mici și aproape fără token-uri necunoscute.
-
-Această abordare este utilă în special în limbile aglutinative, cum ar fi turca, în care se pot forma cuvinte complexe (aproape) arbitrar de lungi prin combinarea părților de cuvinte.
-
-### Și nu numai![[și-nu-numai]]
-
-Nu este surprinzător faptul că există mult mai multe tehnici. Iată câteva:
-
-- BPE la nivel de byte, utilizată în GPT-2
-- WordPiece, utilizată în BERT
-- SentencePiece sau Unigram, utilizate în mai multe modele multilingve
-
-Acum ar trebui să cunoașteți destul de bine cum funcționează tokenizerele pentru a începe să utilizați API-
-
-## Încărcarea și salvarea[[încărcarea-și-salvarea]]
-
-Încărcarea și salvarea tokenizerelor este la fel de simplă ca în cazul modelelor. De fapt, se bazează pe aceleași două metode: `from_pretrained()` și `save_pretrained()`. Aceste metode vor încărca sau salva algoritmul utilizat de tokenizator (un pic ca *arhitectura* modelului), precum și vocabularul său (un pic ca *weight-urile* modelului).
-
-Încărcarea tokenizatorului BERT antrenat cu același punct de control ca BERT se face în același mod ca și încărcarea modelului, cu excepția faptului că folosim clasa `BertTokenizer`:
-
-```py
-from transformers import BertTokenizer
-
-tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
-```
-
-{#if fw === 'pt'}
-Similar cu `AutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{:else}
-Similar cu `TFAutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{/if}
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-```
-
-Acum putem utiliza tokenizatorul așa cum am arătat în secțiunea anterioară:
-
-```python
-tokenizer("Using a Transformer network is simple")
-```
-
-```python out
-{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
-```
-
-Salvarea unui tokenizer este identică cu salvarea unui model:
-
-```py
-tokenizer.save_pretrained("directory_on_my_computer")
-```
-
-Vom vorbi mai mult despre `token_type_ids` în [Capitolul 3](/course/chapter3) și vom explica cheia `attention_mask` puțin mai târziu. Mai întâi, să vedem cum sunt generate `input_ids`. Pentru a face acest lucru, va trebui să ne uităm la metodele intermediare ale tokenizatorului.
-
-## Codificarea[[codificarea]]
-
-
-
-AutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{:else}
-### 5. What is an TFAutoModel?
-
-TFAutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{/if}
-
-### 6. What are the techniques to be aware of when batching sequences of different lengths together?
-
-encode method does exist on tokenizers, it does not exist on models."
- },
- {
- text: "Calling the tokenizer object directly.",
- explain: "Exactly! The __call__ method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
- correct: true
- },
- {
- text: "pad",
- explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
- },
- {
- text: "tokenize",
- explain: "The tokenize method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
- }
- ]}
-/>
-
-### 9. What does the `result` variable contain in this code sample?
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-result = tokenizer.tokenize("Hello!")
-```
-
-convert_tokens_to_ids method is for!"
- },
- {
- text: "A string containing all of the tokens",
- explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 10. Is there something wrong with the following code?
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = AutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Un Trainer",
- explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
- correct: true
- }
- ]}
-/>
-
-{:else}
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Toate cele trei cu un callback dedicat",
- explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
- correct: true
- }
- ]}
-/>
-{/if}
-
-### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
-
-huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
- },
- {
- text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
- explain: "Comanda upload-model nu există."
- }
- ]}
-/>
-
-### 8. Carele operații git poți face cu clasa `Repository`?
-
-git_pull()",
- correct: true
- },
- {
- text: "Un push",
- explain: "Metoda git_push() face acest lucru.",
- correct: true
- },
- {
- text: "Un merge",
- explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
- }
- ]}
-/>
\ No newline at end of file
From 0904819e120adb0d2f043f4a379c8d747c55690d Mon Sep 17 00:00:00 2001
From: eduard-balamatiuc
+ +
+
+
+Alegem checkpointul „camembert-base” pentru al încerca. Identificatorul `camembert-base` este tot de ce avem nevoie pentru a începe. În capitolele precedente, am văzut cum putem inițializa modelul folosind funcția `pipeline()`:
+
+```py
+from transformers import pipeline
+
+camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
+results = camembert_fill_mask("Le camembert est
+
+ +
+
+
+Puteți inițializa checkpointul în mod direct folosind arhitectura modelului:
+
+{#if fw === 'pt'}
+```py
+from transformers import CamembertTokenizer, CamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = CamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+Însă, recomandăm utilizarea [claselor `Auto*`](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes), deoarece acestea sunt proiectate să fie architecture-agnostic. În timp ce codul precedent limita utilizatorii la checkpoints loadable în CamemBERT architecture, utilizarea claselor `Auto*` face schimbarea checkpointurilor simplă:
+
+```py
+from transformers import AutoTokenizer, AutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = AutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{:else}
+```py
+from transformers import CamembertTokenizer, TFCamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = TFCamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+Însă, recomandăm utilizarea [claselor `TFAuto*`](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes), deoarece acestea sunt proiectate să fie architecture-agnostic. În timp ce codul precedent limita utilizatorii la checkpoints loadable în CamemBERT architecture, utilizarea claselor `TFAuto*` face schimbarea checkpointurilor simplă:
+
+```py
+from transformers import AutoTokenizer, TFAutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = TFAutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{/if}
+
+
+
+  +
+
+
+{:else}
+
+Dacă utilizați Keras pentru a antrena modelul dumneavoastră, cea mai ușoară modalitate de a încărca-o pe Hub este să transmiteți un `PushToHubCallback` când chemați `model.fit()`:
+
+```py
+from transformers import PushToHubCallback
+
+callback = PushToHubCallback(
+ "bert-finetuned-mrpc", save_strategy="epoch", tokenizer=tokenizer
+)
+```
+
+Apoi, adăugați `callbacks=[callback]` în apelul la `model.fit()`. Callback-ul va încărca apoi modelul pe Hub de fiecare dată când se salvează(aici, la fiecare epocă) într-un repository din namespaceul tău. Acest repository va fi numit după output directory ales (aici `bert-finetuned-mrpc`), dar puteți alege un alt nume cu `hub_model_id = "un_nume_diferit"`.
+
+Pentru a încărca modelul într-o organizație din care faceți parte, este suficient să introduceți aceasta în `hub_model_id = "organizația_mea/numele_repositoriului"`.
+
+{/if}
+
+La un nivel inferior, accesarea Hub-ului se poate face direct pe modele, tokenizers și configurations objects prin metoda `push_to_hub()`. Această metodă se ocupă atât de crearea repositoriului cât si de încărcarea modelului și tokenizerului direct în el. Nu este nevoie de o interacțiune manuală, precum fața de API-ul pe care îl vom vedea mai jos.
+
+Pentru a înțelege cum funcționează, luați în considerare inițializarea unui model și a unui tokenizer:
+
+{#if fw === 'pt'}
+```py
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = AutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{:else}
+```py
+from transformers import TFAutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{/if}
+
+Sunteți liberi să faceți orice ați vrea cu acestea - adăugați tokens la tokenizer, antrenați modelul sau faceți fine-tune. Odată ce sunteți mulțumiți de modelul obținut, weighturile și tokenizerul acestuia , puteți folosi metoda `push_to_hub()` disponibilă direct pe obiectul `model`:
+
+```py
+model.push_to_hub("dummy-model")
+```
+Acest lucru va crea un nou repository `dummy-model` în profilul tău și o va popula cu fișierele modelului tău.
+Încercați același lucru cu tokenizerul, astfel încât toate fișierele să fie acum disponibile în acest repository:
+
+```py
+tokenizer.push_to_hub("dummy-model")
+```
+
+Dacă apartineți unei organizații, specificați doar argumentul `organization` pentru a încărca în namespaceul acestei organizații:
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface")
+```
+
+Dacă doriți să utilizați un anumit token Hugging Face, sunteți liberi să specificați acest lucru metodei `push_to_hub()`:
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="
+
+ +
+
+{:else}
+
+
+ +
+
+{/if}
+
+
+
+ +
+
+
+În primul rând, specificați deținătorul repositoriului: acesta puteți fi dumneavoastră, fie orice organizație cu care sunteți afiliat. Dacă alegeți o organizație, modelul va fi prezent pe pagina organizației și toți membrii acesteia vor avea posibilitatea să contribuie la repositoriu.
+
+În al doilea rând, introduceți numele modelului dumneavoastră. Acest lucru va fi și denumirea repositoriului. În final, puteți specifica dacă doriți ca modelul dumneavoastră să fie public sau privat. Modelele private nu sunt vizibile ceilorlalți.
+
+După crearea repositoriului, ar trebui să vedeți o pagină ca aceasta:
+
+
+
+ +
+
+
+Acesta este locul unde va fi găzduit modelul. Pentru a începe să populați acesta, puteți adăuga un fișier README direct din interfața web.
+
+
+
+ +
+
+
+Fișierul README este scris în format Markdown - vă rugăm să fiți creativi cu el! A treia parte a acestui capitol se ocupă de crearea unui model card. Acestea sunt foarte importante pentru a aduce valoare modelului dumneavoastră, deoarece este acolo unde spuneți celorlalți ce poate face.
+
+Dacă vă uitați la secțiunea "Fișiere și versiuni", veți vedea că nu sunt prea multe fișiere acolo încă - doar *README.md* pe care l-ați creat dumneavoastră și *.gitattributes* care urmărește fișierele mari.
+
+
+
+ +
+
+
+Vom vedea mai târziu cum să adăugați câteva fișiere noi.
+
+## Încărcarea fișierelor modelului[[uploading-the-model-files]]
+
+Sistemul pentru a gestiona fișierele în Hugging Face Hub se bazează pe git pentru fișierele obișnuite, și pe git-lfs (care se descrifrează ca [Git Large File Storage](https://git-lfs.github.com/)) pentru fișierele mai mari.
+
+În secțiunea următoare, vom discuta despre trei metode diferite de încărcare a fișierelor în Hub: prin `huggingface_hub` și prin comanda git.
+
+### Metoda `upload_file`[[the-uploadfile-approach]]
+
+Prin `upload_file` nu este necesar să instalați git și git-lfs pe sistemul dumneavoastră. Acest lucru încarcă direct fișierele în 🤗 Hub folosind HTTP POST requests. O limitare a acestei metode este că ea nu se ocupă de fișiere care sunt mai mari de 5GB.
+Dacă fișierele dumneavoastră sunt mai mari decât 5 GB, vă rugăm să urmați celelalte două metode descrise mai jos.
+
+API-ul poate fi folosit astfel:
+
+```python
+from huggingface_hub import upload_file
+
+upload_file(
+ "
+
+ +
+
+
+Interfața permite explorarea fișierelor modelului și a commiturilor și vizualizarea diferenței introduse de fiecare commit:
+
+
+
+ +
+
+{:else}
+Dacă ne uităm la repositoriul modelului când acest lucru este finalizat, putem vedea toate fișierele recent adăugate:
+
+
+
+ +
+
+
+Interfața permite explorarea fișierelor modelului și a commiturilor și vizualizarea diferenței introduse de fiecare commit:
+
+
+
+ +
+
+{/if}
+```
\ No newline at end of file
diff --git a/chapters/rum/chapter4/4.mdx b/chapters/rum/chapter4/4.mdx
new file mode 100644
index 000000000..f8963f961
--- /dev/null
+++ b/chapters/rum/chapter4/4.mdx
@@ -0,0 +1,88 @@
+# Crearea unui card de model[[building-a-model-card]]
+
+
+
+push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Un Trainer",
+ explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
+ correct: true
+ }
+ ]}
+/>
+
+{:else}
+push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Toate cele trei cu un callback dedicat",
+ explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
+
+huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
+ },
+ {
+ text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
+ explain: "Comanda upload-model nu există."
+ }
+ ]}
+/>
+
+### 8. Carele operații git poți face cu clasa `Repository`?
+
+git_pull()",
+ correct: true
+ },
+ {
+ text: "Un push",
+ explain: "Metoda git_push() face acest lucru.",
+ correct: true
+ },
+ {
+ text: "Un merge",
+ explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
+ }
+ ]}
+/>
\ No newline at end of file
From 6f9882735d57587264b82fca8640b2b0310d9880 Mon Sep 17 00:00:00 2001
From: eduard-balamatiuc
+
+
+
+Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
+
+```
+!pip install transformers
+```
+
+Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
+
+```
+import transformers
+```
+
+
+
+
+
+
+Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
+
+```
+!pip install transformers[sentencepiece]
+```
+
+Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
+
+## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
+
+Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
+
+Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
+
+Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
+
+În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
+
+În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
+
+```
+mkdir ~/transformers-course
+cd ~/transformers-course
+```
+
+Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
+
+```
+python -m venv .env
+```
+
+Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
+
+```
+ls -a
+```
+
+```out
+. .. .env
+```
+
+Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
+
+```
+# Activează mediul virtual
+source .env/bin/activate
+
+# Dezactivează virtual environment-ul
+deactivate
+```
+
+Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
+
+```
+which python
+```
+
+```out
+/home/
+
-
-
-
-Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
-
-```
-!pip install transformers
-```
-
-Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
-
-```
-import transformers
-```
-
-
-
-
-
-
-Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
-
-```
-!pip install transformers[sentencepiece]
-```
-
-Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
-
-## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
-
-Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
-
-Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
-
-Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
-
-În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
-
-În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
-
-```
-mkdir ~/transformers-course
-cd ~/transformers-course
-```
-
-Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
-
-```
-python -m venv .env
-```
-
-Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
-
-```
-ls -a
-```
-
-```out
-. .. .env
-```
-
-Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
-
-```
-# Activează mediul virtual
-source .env/bin/activate
-
-# Dezactivează virtual environment-ul
-deactivate
-```
-
-Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
-
-```
-which python
-```
-
-```out
-/home/
-
-
-
-
-
-Să trecem rapid prin fiecare dintre acestea.
-
-## Preprocesarea cu un tokenizator[[preprocesarea-cu-un-tokenizerator]]
-
-La fel ca alte rețele neuronale, modelele Transformer nu pot procesa direct text brut, astfel încât primul pas al pipeline-ului nostru este de a converti intrările de text în numere pe care modelul le poate înțelege. Pentru a face acest lucru, folosim un *tokenizer*, care va fi responsabil pentru:
-
-- Împărțirea datelor de intrare în cuvinte, părți de cuvinte sau simboluri (cum ar fi punctuația) care se numesc *tokens*
-- Maparea fiecărui token într-un număr întreg
-- Adăugarea de intrări suplimentare care pot fi utile pentru model
-
-Toată această preprocesare trebuie efectuată exact în același mod ca atunci când modelul a fost preinstruit, așa că mai întâi trebuie să descărcăm aceste informații din [Model Hub] (https://huggingface.co/models). Pentru a face acest lucru, folosim clasa `AutoTokenizer` și metoda sa `from_pretrained()`. Folosind numele checkpoint-ului modelului nostru, aceasta va prelua automat datele asociate cu tokenizer-ul modelului și le va stoca în cache (astfel încât acestea să fie descărcate doar prima dată când executați codul de mai jos).
-
-Deoarece punctul de control implicit al pipeline-ului `sentiment-analysis` este `distilbert-base-uncased-finetuned-sst-2-english` (puteți vedea fișa modelului [aici](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)), executăm următoarele:
-
-```python
-from transformers import AutoTokenizer
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-```
-
-Odată ce avem tokenizatorul, putem să îi transmitem direct propozițiile noastre și vom primi înapoi un dicționar care este gata să fie introdus în modelul nostru! Singurul lucru rămas de făcut este să convertim lista de ID-uri de intrare în tensori.
-
-Puteți utiliza 🤗 Transformers fără a trebui să vă faceți griji cu privire la cadrul ML utilizat ca backend; ar putea fi PyTorch sau TensorFlow, sau Flax pentru unele modele. Cu toate acestea, modelele Transformer acceptă numai *tensori * ca intrare. Dacă este prima dată când auziți despre tensori, vă puteți gândi la ei ca la matrici NumPy. Un array NumPy poate fi un scalar (0D), un vector (1D), o matrice (2D) sau poate avea mai multe dimensiuni. Este de fapt un tensor; tensorii altor cadre ML se comportă similar și sunt de obicei la fel de simplu de instanțiat ca și array-urile NumPy.
-
-Pentru a specifica tipul de tensori pe care dorim să îi primim înapoi (PyTorch, TensorFlow sau NumPy simplu), folosim argumentul `return_tensors`:
-
-
-{#if fw === 'pt'}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
-print(inputs)
-```
-{:else}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
-print(inputs)
-```
-{/if}
-
-
-Nu vă faceți încă griji cu privire la padding și trunchiere; le vom explica mai târziu. Principalele lucruri de reținut aici sunt că puteți trece o propoziție sau o listă de propoziții, precum și specificarea tipului de tensori pe care doriți să îi primiți înapoi (dacă nu este trecut niciun tip, veți primi o listă de liste ca rezultat)
-{#if fw === 'pt'}
-
-Iată cum arată rezultatele ca tensori PyTorch:
-
-```python out
-{
- 'input_ids': tensor([
- [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
- [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
- ]),
- 'attention_mask': tensor([
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- ])
-}
-```
-{:else}
-
-Iată cum arată rezultatele ca tensori TensorFlow:
-
-```python out
-{
- 'input_ids':
-
-
-
-
-
-
-
-Rezultatul modelului Transformer este trimis direct la head-ul modelului pentru a fi prelucrat.
-
-În această diagramă, modelul este reprezentat de stratul său de încorporare și de straturile următoare. Stratul de încorporare convertește fiecare ID de intrare din intrarea tokenizată într-un vector care reprezintă tokenul asociat. Straturile ulterioare manipulează acești vectori folosind mecanismul de atenție pentru a produce reprezentarea finală a propozițiilor.
-
-Există multe arhitecturi diferite disponibile în 🤗 Transformers, fiecare fiind concepută în jurul abordării unei sarcini specifice. Iată o listă neexhaustivă:
-
-- `*Model` (extragerea stărilor ascunse)
-- `*ForCausalLM`
-- `*ForMaskedLM`
-- `*ForMultipleChoice`
-- `*ForQuestionAnswering`
-- `*ForSequenceClassification`
-- `*ForTokenClassification`
-- și altele 🤗
-
-{#if fw === 'pt'}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `AutoModel`, ci `AutoModelForSequenceClassification`:
-
-```python
-from transformers import AutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(**inputs)
-```
-{:else}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `TFAutoModel`, ci `TFAutoModelForSequenceClassification`:
-
-```python
-from transformers import TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(inputs)
-```
-{/if}
-
-Acum, dacă ne uităm la forma ieșirilor noastre, dimensiunea va fi mult mai mică: head-ul modelului ia ca intrare vectorii multidimensionali pe care i-am văzut înainte și scoate vectori care conțin două valori (una pentru fiecare etichetă):
-
-```python
-print(outputs.logits.shape)
-```
-
-{#if fw === 'pt'}
-```python out
-torch.Size([2, 2])
-```
-{:else}
-```python out
-(2, 2)
-```
-{/if}
-
-
-Deoarece avem doar două propoziții și două etichete, rezultatul pe care îl obținem din modelul nostru este de forma 2 x 2.
-
-## Postprocesarea rezultatului[[postprocesarea-rezultatului]]
-
-Valorile pe care le obținem ca rezultat al modelului nostru nu au neapărat sens în sine. Să aruncăm o privire:
-
-```python
-print(outputs.logits)
-```
-
-{#if fw === 'pt'}
-```python out
-tensor([[-1.5607, 1.6123],
- [ 4.1692, -3.3464]], grad_fn=
-
-
-
-
-
-
-
-Există diferite moduri de a împărți textul. De exemplu, am putea folosi spațiu pentru a tokeniza textul în cuvinte prin aplicarea funcției `split()` din Python:
-
-
-```py
-tokenized_text = "Jim Henson was a puppeteer".split()
-print(tokenized_text)
-```
-
-```python out
-['Jim', 'Henson', 'was', 'a', 'puppeteer']
-```
-
-Există, de asemenea, variații ale tokenizerelor de cuvinte care au reguli suplimentare pentru punctuație. Cu acest tip de tokenizator, putem ajunge la „vocabulare” destul de mari, unde un vocabular este definit de numărul total de token-uri independente pe care le avem în corpus.
-
-Fiecărui cuvânt i se atribuie un ID, începând de la 0 și mergând până la dimensiunea vocabularului. Modelul utilizează aceste ID-uri pentru a identifica fiecare cuvânt.
-
-Dacă dorim să acoperim complet o limbă cu un tokenizer bazat pe cuvinte, va trebui să avem un identificator pentru fiecare cuvânt din limbă, ceea ce va genera o cantitate uriașă de token-uri. De exemplu, există peste 500 000 de cuvinte în limba engleză, astfel încât, pentru a construi o hartă de la fiecare cuvânt la un ID de intrare, ar trebui să ținem evidența unui număr atât de mare de ID-uri. În plus, cuvinte precum „dog” sunt reprezentate diferit de cuvinte precum „dogs”, iar modelul nu va avea inițial nicio modalitate de a ști că „dog” și „dogs” sunt similare: va identifica cele două cuvinte ca neavând legătură. Același lucru este valabil și pentru alte cuvinte similare, precum „run” și „running”, pe care modelul nu le va vedea inițial ca fiind similare.
-
-În cele din urmă, avem nevoie de un token personalizat pentru a reprezenta cuvintele care nu se află în vocabularul nostru. Acesta este cunoscut sub numele de token "necunoscut", adesea reprezentat ca "[UNK]" sau "<unk>". În general, este un indiciu rău dacă vedeți că tokenizatorul produce o mulțime de astfel de token-uri, deoarece nu a fost capabil să recupereze reprezentarea sensibilă a unui cuvânt și veți pierde informații pe parcurs. Scopul elaborării vocabularului este de a face în așa fel încât tokenizatorul să tokenizeze cât mai puține cuvinte posibil în tokenul necunoscut.
-
-O modalitate de a reduce numărul de token-uri necunoscute este de a merge un nivel mai adânc, folosind un tokenizer _character-based_.
-
-## Character-based[[character-based]]
-
-
-
-
-
-
-
-
-
-Nici această abordare nu este perfectă. Deoarece reprezentarea se bazează acum pe caractere și nu pe cuvinte, s-ar putea spune că, din punct de vedere intuitiv, este mai puțin relevantă: fiecare caracter nu înseamnă mult în sine, în timp ce în cazul cuvintelor situația este diferită. Totuși, acest lucru variază din nou în funcție de limbă; în chineză, de exemplu, fiecare caracter conține mai multe informații decât un caracter într-o limbă latină.
-
-Un alt lucru care trebuie luat în considerare este faptul că ne vom trezi cu o cantitate foarte mare de token-uri care vor fi prelucrate de modelul nostru: în timp ce un cuvânt ar fi un singur token cu un tokenizator bazat pe cuvinte, acesta se poate transforma cu ușurință în 10 sau mai multe token-uri atunci când este convertit în caractere.
-
-Pentru a obține ce este mai bun din ambele lumi, putem utiliza o a treia tehnică care combină cele două abordări: *subword tokenization*.
-
-## Subword tokenization[[subword-tokenization]]
-
-
-
-
-
-
-
-
-Aceste părți de cuvinte oferă în cele din urmă o mulțime de semnificații semantice: în exemplul de mai sus, "tokenization" a fost împărțit în "token" și "ization", două cuvinte care au o semnificație semantică, fiind în același timp eficiente din punct de vedere al spațiului (sunt necesare doar două cuvinte pentru a reprezenta un cuvânt lung). Acest lucru ne permite să avem o acoperire relativ bună cu vocabulare de dimensiuni mici și aproape fără token-uri necunoscute.
-
-Această abordare este utilă în special în limbile aglutinative, cum ar fi turca, în care se pot forma cuvinte complexe (aproape) arbitrar de lungi prin combinarea părților de cuvinte.
-
-### Și nu numai![[și-nu-numai]]
-
-Nu este surprinzător faptul că există mult mai multe tehnici. Iată câteva:
-
-- BPE la nivel de byte, utilizată în GPT-2
-- WordPiece, utilizată în BERT
-- SentencePiece sau Unigram, utilizate în mai multe modele multilingve
-
-Acum ar trebui să cunoașteți destul de bine cum funcționează tokenizerele pentru a începe să utilizați API-
-
-## Încărcarea și salvarea[[încărcarea-și-salvarea]]
-
-Încărcarea și salvarea tokenizerelor este la fel de simplă ca în cazul modelelor. De fapt, se bazează pe aceleași două metode: `from_pretrained()` și `save_pretrained()`. Aceste metode vor încărca sau salva algoritmul utilizat de tokenizator (un pic ca *arhitectura* modelului), precum și vocabularul său (un pic ca *weight-urile* modelului).
-
-Încărcarea tokenizatorului BERT antrenat cu același punct de control ca BERT se face în același mod ca și încărcarea modelului, cu excepția faptului că folosim clasa `BertTokenizer`:
-
-```py
-from transformers import BertTokenizer
-
-tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
-```
-
-{#if fw === 'pt'}
-Similar cu `AutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{:else}
-Similar cu `TFAutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{/if}
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-```
-
-Acum putem utiliza tokenizatorul așa cum am arătat în secțiunea anterioară:
-
-```python
-tokenizer("Using a Transformer network is simple")
-```
-
-```python out
-{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
-```
-
-Salvarea unui tokenizer este identică cu salvarea unui model:
-
-```py
-tokenizer.save_pretrained("directory_on_my_computer")
-```
-
-Vom vorbi mai mult despre `token_type_ids` în [Capitolul 3](/course/chapter3) și vom explica cheia `attention_mask` puțin mai târziu. Mai întâi, să vedem cum sunt generate `input_ids`. Pentru a face acest lucru, va trebui să ne uităm la metodele intermediare ale tokenizatorului.
-
-## Codificarea[[codificarea]]
-
-
-
-AutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{:else}
-### 5. What is an TFAutoModel?
-
-TFAutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{/if}
-
-### 6. What are the techniques to be aware of when batching sequences of different lengths together?
-
-encode method does exist on tokenizers, it does not exist on models."
- },
- {
- text: "Calling the tokenizer object directly.",
- explain: "Exactly! The __call__ method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
- correct: true
- },
- {
- text: "pad",
- explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
- },
- {
- text: "tokenize",
- explain: "The tokenize method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
- }
- ]}
-/>
-
-### 9. What does the `result` variable contain in this code sample?
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-result = tokenizer.tokenize("Hello!")
-```
-
-convert_tokens_to_ids method is for!"
- },
- {
- text: "A string containing all of the tokens",
- explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 10. Is there something wrong with the following code?
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = AutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Un Trainer",
- explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
- correct: true
- }
- ]}
-/>
-
-{:else}
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Toate cele trei cu un callback dedicat",
- explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
- correct: true
- }
- ]}
-/>
-{/if}
-
-### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
-
-huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
- },
- {
- text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
- explain: "Comanda upload-model nu există."
- }
- ]}
-/>
-
-### 8. Carele operații git poți face cu clasa `Repository`?
-
-git_pull()",
- correct: true
- },
- {
- text: "Un push",
- explain: "Metoda git_push() face acest lucru.",
- correct: true
- },
- {
- text: "Un merge",
- explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
- }
- ]}
-/>
\ No newline at end of file
diff --git a/chapters/ro/chapter5/1.mdx b/chapters/ro/chapter5/1.mdx
deleted file mode 100644
index 7fd54a2ad..000000000
--- a/chapters/ro/chapter5/1.mdx
+++ /dev/null
@@ -1,22 +0,0 @@
-# Introducere[[introduction]]
-
-| - | patient_id | -drugName | -condition | -review | -rating | -date | -usefulCount | -review_length | -
|---|---|---|---|---|---|---|---|---|
| 0 | -95260 | -Guanfacine | -adhd | -"My son is halfway through his fourth week of Intuniv..." | -8.0 | -April 27, 2010 | -192 | -141 | -
| 1 | -92703 | -Lybrel | -birth control | -"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | -5.0 | -December 14, 2009 | -17 | -134 | -
| 2 | -138000 | -Ortho Evra | -birth control | -"This is my first time using any form of birth control..." | -8.0 | -November 3, 2015 | -10 | -89 | -
| - | condition | -frequency | -
|---|---|---|
| 0 | -birth control | -27655 | -
| 1 | -depression | -8023 | -
| 2 | -acne | -5209 | -
| 3 | -anxiety | -4991 | -
| 4 | -pain | -4744 | -
-
-
-
-Dacă ați da clic pe una dintre aceste issue-uri veți găsi că aceasta conține un titlu, o descriere și un set de labeluri care caracterizează issue-ul. Un exemplu este prezentat în screenshotul următor.
-
-
-
-
-
-
-Pentru a descărca toate issue-urile din repositoriu, vom folosi [GitHub REST API](https://docs.github.com/en/rest) pentru a enumera [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues). Aceast endpoint returnează o listă de obiecte JSON, cu fiecare obiect conținând un număr mare de câmpuri care includ titlul și descrierea precum și metadata despre starea issue-ului și așa mai departe.
-
-Un mod convenabil de descărcare a issue-urilor este prin utilizarea librăriei `requests`, care este modalitatea standard pentru a face cereri HTTP în Python. Puteți instala libraria rulând comanda:
-
-```python
-!pip install requests
-```
-
-Odată cu instalarea librariei, puteți face cereri GET la `Issues` endpoint prin invocarea funcției `requests.get()`. De exemplu, puteți rula următorul cod pentru a obține primul issue din prima pagină:
-
-```py
-import requests
-
-url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
-response = requests.get(url)
-```
-
-Obiectul `response` conține o cantitate mare de informații utile despre requestul efectuat, inclusiv HTTP status code:
-
-```py
-response.status_code
-```
-
-```python out
-200
-```
-
-unde statusul `200` înseamnă că cererea a fost reușită (puteți găsi o listă completă de status coduri [aici](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)). De ceea ce suntem însă interesați este _payload_, care poate fi accesat în diverse formaturi precum bytes, string sau JSON. Deoarece știm că issue-urile noastre sunt în format JSON, să inspectăm payload-ul astfel:
-
-```py
-response.json()
-```
-
-```python out
-[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
- 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
- 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
- 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
- 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
- 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
- 'id': 968650274,
- 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
- 'number': 2792,
- 'title': 'Update GooAQ',
- 'user': {'login': 'bhavitvyamalik',
- 'id': 19718818,
- 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
- 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
- 'gravatar_id': '',
- 'url': 'https://api.github.com/users/bhavitvyamalik',
- 'html_url': 'https://github.com/bhavitvyamalik',
- 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
- 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
- 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
- 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
- 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
- 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
- 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
- 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
- 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
- 'type': 'User',
- 'site_admin': False},
- 'labels': [],
- 'state': 'open',
- 'locked': False,
- 'assignee': None,
- 'assignees': [],
- 'milestone': None,
- 'comments': 1,
- 'created_at': '2021-08-12T11:40:18Z',
- 'updated_at': '2021-08-12T12:31:17Z',
- 'closed_at': None,
- 'author_association': 'CONTRIBUTOR',
- 'active_lock_reason': None,
- 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
- 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
- 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
- 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
- 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
- 'performed_via_github_app': None}]
-```
-
-Uau, aceasta e o cantitate mare de informație! Putem vedea câmpuri utile cum ar fi `title`, `body` și `number` care descriu problema, precum și informații despre utilizatorul GitHub care a deschis issue-ul.
-
-
-
-
-
-
-GitHub REST API oferă un endpoint [`Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) care returnează toate comentariile asociate numărului problemei. Să testăm endpointul pentru a vedea ce returnează:
-
-```py
-issue_number = 2792
-url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
-response = requests.get(url, headers=headers)
-response.json()
-```
-
-```python out
-[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
- 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
- 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
- 'id': 897594128,
- 'node_id': 'IC_kwDODunzps41gDMQ',
- 'user': {'login': 'bhavitvyamalik',
- 'id': 19718818,
- 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
- 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
- 'gravatar_id': '',
- 'url': 'https://api.github.com/users/bhavitvyamalik',
- 'html_url': 'https://github.com/bhavitvyamalik',
- 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
- 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
- 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
- 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
- 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
- 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
- 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
- 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
- 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
- 'type': 'User',
- 'site_admin': False},
- 'created_at': '2021-08-12T12:21:52Z',
- 'updated_at': '2021-08-12T12:31:17Z',
- 'author_association': 'CONTRIBUTOR',
- 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
- 'performed_via_github_app': None}]
-```
-
-Putem vedea că comentariul este stocat în câmpul `body`, așa că putem scrie o funcție simplă care returnează toate comentariile asociate unei probleme prin extragerea conținutului `body` pentru fiecare element în `response.json()`:
-
-```py
-def get_comments(issue_number):
- url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
- response = requests.get(url, headers=headers)
- return [r["body"] for r in response.json()]
-
-
-# Testăm dacă funcția lucrează cum ne dorim
-get_comments(2792)
-```
-
-```python out
-["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
-```
-
-Arată bine. Acum hai să folosim `Dataset.map()` pentru a adăuga noi coloane `comments` fiecărui issue în datasetul nostru:
-
-```py
-# Depending on your internet connection, this can take a few minutes...
-issues_with_comments_dataset = issues_dataset.map(
- lambda x: {"comments": get_comments(x["number"])}
-)
-```
-
-Ultimul pas este să facem push datasetului nostru pe Hub. Să vedem cum putem face asta.
-
-## Încărcarea datasetului pe Hugging Face Hub[[uploading-the-dataset-to-the-hugging-face-hub]]
-
-
-
-
-
-
-2. Citiți [ghidul 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) despre crearea de dataset cards informative și utilizați-l ca șablon.
-
-Puteți crea fișierul *README.md* direct pe Hub și puteți găsi un template pentru dataset card în repositoriul `lewtun/github-issues`. Un screenshot a dataset card completată este afișată mai jos.
-
-
-
-
-
-
-
-
-
-
-
-
-## Încărcarea și pregătirea datasetului[[loading-and-preparing-the-dataset]]
-
-Prima lucru pe care trebuie să îl facem este să descărcăm datasetul nostru cu GitHub issues, așa că folosim funcția `load_dataset()` ca de obicei:
-
-```py
-from datasets import load_dataset
-
-issues_dataset = load_dataset("lewtun/github-issues", split="train")
-issues_dataset
-```
-
-```python out
-Dataset({
- features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
- num_rows: 2855
-})
-```
-
-Aici am specificat splitul default `train` în `load_dataset()`, astfel încât returnează un `Dataset` în loc de `DatasetDict`. Primul lucru care treubuie făcut este să filtrăm pull requesturile, deoarece acestea rareori tind să fie utilizate pentru a răspunde la întrebările utilizatorilor și vor introduce noise în motorul nostru de căutare. Așa cum ar trebuie deja să știți, putem utiliza funcția `Dataset.filter()` pentru a exclude aceste rânduri din datasetul nostru. În timp ce suntem aici, putem să filtrăm și rândurile fără comentari, deoarece acestea nu oferă niciun răspuns la întrebările utilizatorilor:
-
-```py
-issues_dataset = issues_dataset.filter(
- lambda x: (x["is_pull_request"] == False și len(x["comments"]) > 0)
-)
-issues_dataset
-```
-
-```python out
-Dataset({
- caracteristici: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
- num_rows: 771
-})
-```
-
-Putem vedea că există multe coloane în datasetul nostru, majoritatea dintre care nu sunt necesare pentru a construi motorul nostru de căutare. Din perspectiva căutării, cele mai informative coloane sunt `title`, `body` și `comments`, în timp ce `html_url` ne oferă un link înapoi la problema sursă. Hai să utilizăm funcția `Dataset.remove_columns()` pentru a elimina restul:
-
-```py
-columns = issues_dataset.column_names
-columns_to_keep = ["title", "body", "html_url", "comments"]
-columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
-issues_dataset = issues_dataset.remove_columns(columns_to_remove)
-issues_dataset
-```
-
-```python out
-Dataset({
- features: ['html_url', 'title', 'comments', 'body'],
- num_rows: 771
-})
-```
-
-Pentru a crea embeddedurile noastre, vom completa fiecare comentariu cu titlul și body-ul problemei, deoarece aceste câmpuri adesea includ informații contextuale utile. Deoarece coloana noastră `comments` este în prezent o listă de comentarii pentru fiecare issue, trebuie să "explodăm" coloana, astfel încât fiecare rând să fie format dintr-un tuple `(html_url, title, body, comment)`. În Pandas, putem face acest lucru cu funcția [`DataFrame.explode()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), care creează un rând nou pentru fiecare element dintr-o coloană asemănătoare cu o listă, în timp ce copiază toate celelalte valori ale coloanelor. Pentru a vedea acest lucru în acțiune, să trecem la formatul pandas `DataFrame` main întâi:
-
-```py
-issues_dataset.set_format("pandas")
-df = issues_dataset[:]
-```
-
-Dacă inspectăm primul rând din acest `DataFrame`, putem vedea că există patru comentarii asociate acestei probleme:
-
-```py
-df["comments"][0].tolist()
-```
-
-```python out
-['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
- 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
- 'cannot connect,even by Web browser,please check that there is some problems。',
- 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
-```
-
-Când facem explode `df`, ne așteptăm să obținem un rând pentru fiecare dintre aceste comentarii. Haideți să verificăm dacă ăsta e cazul:
-
-```py
-comments_df = df.explode("comments", ignore_index=True)
-comments_df.head(4)
-```
-
-
-
-| - | html_url | -title | -comments | -body | -
|---|---|---|---|---|
| 0 | -https://github.com/huggingface/datasets/issues/2787 | -ConnectionError: Couldn't reach https://raw.githubusercontent.com | -the bug code locate in :\r\n if data_args.task_name is not None... | -Hello,\r\nI am trying to run run_glue.py and it gives me this error... | -
| 1 | -https://github.com/huggingface/datasets/issues/2787 | -ConnectionError: Couldn't reach https://raw.githubusercontent.com | -Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | -Hello,\r\nI am trying to run run_glue.py and it gives me this error... | -
| 2 | -https://github.com/huggingface/datasets/issues/2787 | -ConnectionError: Couldn't reach https://raw.githubusercontent.com | -cannot connect,even by Web browser,please check that there is some problems。 | -Hello,\r\nI am trying to run run_glue.py and it gives me this error... | -
| 3 | -https://github.com/huggingface/datasets/issues/2787 | -ConnectionError: Couldn't reach https://raw.githubusercontent.com | -I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | -Hello,\r\nI am trying to run run_glue.py and it gives me this error... | -
dataset.shuffle().select(range(50))",
- explain: "Corect! Așa cum ați văzut în acest capitol, mai întâi faceți shuffle datasetului și apoi selectați exemplele din el.",
- correct: true
- },
- {
- text: "dataset.select(range(50)).shuffle()",
- explain: "Acest lucru este incorect -- deși codul va rula, va amesteca doar primele 50 de elemente din setul de date."
- }
- ]}
-/>
-
-### 3. Presupunem că aveți un set de date despre animale de companie numit `pets_dataset`, care are o coloană `name` care denotă numele fiecărui animal de companie. Care dintre următoarele abordări v-ar permite să filtrați setul de date pentru toate animalele de companie ale căror nume încep cu litera "L"?
-
-pets_dataset.filter(lambda x['name'].startswith('L'))",
- explain: "Acest lucru este incorect -- o funcție lambda are forma generală lambda *arguments* : *expression*, deci trebuie să furnizați argumente în acest caz."
- },
- {
- text: "Creați o funcție ca def filter_names(x): return x['name'].startswith('L') și rulați pets_dataset.filter(filter_names).",
- explain: "Corect! La fel ca și cu Dataset.map(), puteți trece funcții explicite la Dataset.filter(). Acest lucru este util atunci când aveți o logică complexă care nu este potrivită pentru o funcție lambda. Care dintre celelalte soluții ar mai funcționa?",
- correct: true
- }
- ]}
-/>
-
-### 4. Ce este memory mapping?
-
-IterableDataset este un generator, nu un container, deci ar trebui să accesați elementele sale utilizând next(iter(dataset)).",
- correct: true
- },
- {
- text: "Datasetul allocine nu are o un split train.",
- explain: "Acest lucru este incorect -- consultați cardul datasetului allocine de pe Hub pentru a vedea ce splituri conține."
- }
- ]}
-/>
-
-### 7. Care sunt principalele beneficii ale creării unui dataset card?
-
-
+
+
+
+Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
+
+```
+!pip install transformers
+```
+
+Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
+
+```
+import transformers
+```
+
+
+
+
+
+
+Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
+
+```
+!pip install transformers[sentencepiece]
+```
+
+Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
+
+## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
+
+Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
+
+Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
+
+Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
+
+În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
+
+În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
+
+```
+mkdir ~/transformers-course
+cd ~/transformers-course
+```
+
+Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
+
+```
+python -m venv .env
+```
+
+Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
+
+```
+ls -a
+```
+
+```out
+. .. .env
+```
+
+Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
+
+```
+# Activează mediul virtual
+source .env/bin/activate
+
+# Dezactivează virtual environment-ul
+deactivate
+```
+
+Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
+
+```
+which python
+```
+
+```out
+/home/
+| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
+
+
+
+Dacă ați da clic pe una dintre aceste issue-uri veți găsi că aceasta conține un titlu, o descriere și un set de labeluri care caracterizează issue-ul. Un exemplu este prezentat în screenshotul următor.
+
+
+
+
+
+
+Pentru a descărca toate issue-urile din repositoriu, vom folosi [GitHub REST API](https://docs.github.com/en/rest) pentru a enumera [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues). Aceast endpoint returnează o listă de obiecte JSON, cu fiecare obiect conținând un număr mare de câmpuri care includ titlul și descrierea precum și metadata despre starea issue-ului și așa mai departe.
+
+Un mod convenabil de descărcare a issue-urilor este prin utilizarea librăriei `requests`, care este modalitatea standard pentru a face cereri HTTP în Python. Puteți instala libraria rulând comanda:
+
+```python
+!pip install requests
+```
+
+Odată cu instalarea librariei, puteți face cereri GET la `Issues` endpoint prin invocarea funcției `requests.get()`. De exemplu, puteți rula următorul cod pentru a obține primul issue din prima pagină:
+
+```py
+import requests
+
+url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
+response = requests.get(url)
+```
+
+Obiectul `response` conține o cantitate mare de informații utile despre requestul efectuat, inclusiv HTTP status code:
+
+```py
+response.status_code
+```
+
+```python out
+200
+```
+
+unde statusul `200` înseamnă că cererea a fost reușită (puteți găsi o listă completă de status coduri [aici](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)). De ceea ce suntem însă interesați este _payload_, care poate fi accesat în diverse formaturi precum bytes, string sau JSON. Deoarece știm că issue-urile noastre sunt în format JSON, să inspectăm payload-ul astfel:
+
+```py
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
+ 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
+ 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
+ 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'id': 968650274,
+ 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
+ 'number': 2792,
+ 'title': 'Update GooAQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'labels': [],
+ 'state': 'open',
+ 'locked': False,
+ 'assignee': None,
+ 'assignees': [],
+ 'milestone': None,
+ 'comments': 1,
+ 'created_at': '2021-08-12T11:40:18Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'closed_at': None,
+ 'author_association': 'CONTRIBUTOR',
+ 'active_lock_reason': None,
+ 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
+ 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
+ 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
+ 'performed_via_github_app': None}]
+```
+
+Uau, aceasta e o cantitate mare de informație! Putem vedea câmpuri utile cum ar fi `title`, `body` și `number` care descriu problema, precum și informații despre utilizatorul GitHub care a deschis issue-ul.
+
+
+
+
+
+
+GitHub REST API oferă un endpoint [`Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) care returnează toate comentariile asociate numărului problemei. Să testăm endpointul pentru a vedea ce returnează:
+
+```py
+issue_number = 2792
+url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+response = requests.get(url, headers=headers)
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
+ 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'id': 897594128,
+ 'node_id': 'IC_kwDODunzps41gDMQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'created_at': '2021-08-12T12:21:52Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'author_association': 'CONTRIBUTOR',
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'performed_via_github_app': None}]
+```
+
+Putem vedea că comentariul este stocat în câmpul `body`, așa că putem scrie o funcție simplă care returnează toate comentariile asociate unei probleme prin extragerea conținutului `body` pentru fiecare element în `response.json()`:
+
+```py
+def get_comments(issue_number):
+ url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+ response = requests.get(url, headers=headers)
+ return [r["body"] for r in response.json()]
+
+
+# Testăm dacă funcția lucrează cum ne dorim
+get_comments(2792)
+```
+
+```python out
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+```
+
+Arată bine. Acum hai să folosim `Dataset.map()` pentru a adăuga noi coloane `comments` fiecărui issue în datasetul nostru:
+
+```py
+# Depending on your internet connection, this can take a few minutes...
+issues_with_comments_dataset = issues_dataset.map(
+ lambda x: {"comments": get_comments(x["number"])}
+)
+```
+
+Ultimul pas este să facem push datasetului nostru pe Hub. Să vedem cum putem face asta.
+
+## Încărcarea datasetului pe Hugging Face Hub[[uploading-the-dataset-to-the-hugging-face-hub]]
+
+
+
+
+
+
+2. Citiți [ghidul 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) despre crearea de dataset cards informative și utilizați-l ca șablon.
+
+Puteți crea fișierul *README.md* direct pe Hub și puteți găsi un template pentru dataset card în repositoriul `lewtun/github-issues`. Un screenshot a dataset card completată este afișată mai jos.
+
+
+
+
+
+
+
+
+
+
+
+
+## Încărcarea și pregătirea datasetului[[loading-and-preparing-the-dataset]]
+
+Prima lucru pe care trebuie să îl facem este să descărcăm datasetul nostru cu GitHub issues, așa că folosim funcția `load_dataset()` ca de obicei:
+
+```py
+from datasets import load_dataset
+
+issues_dataset = load_dataset("lewtun/github-issues", split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
+Aici am specificat splitul default `train` în `load_dataset()`, astfel încât returnează un `Dataset` în loc de `DatasetDict`. Primul lucru care treubuie făcut este să filtrăm pull requesturile, deoarece acestea rareori tind să fie utilizate pentru a răspunde la întrebările utilizatorilor și vor introduce noise în motorul nostru de căutare. Așa cum ar trebuie deja să știți, putem utiliza funcția `Dataset.filter()` pentru a exclude aceste rânduri din datasetul nostru. În timp ce suntem aici, putem să filtrăm și rândurile fără comentari, deoarece acestea nu oferă niciun răspuns la întrebările utilizatorilor:
+
+```py
+issues_dataset = issues_dataset.filter(
+ lambda x: (x["is_pull_request"] == False și len(x["comments"]) > 0)
+)
+issues_dataset
+```
+
+```python out
+Dataset({
+ caracteristici: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 771
+})
+```
+
+Putem vedea că există multe coloane în datasetul nostru, majoritatea dintre care nu sunt necesare pentru a construi motorul nostru de căutare. Din perspectiva căutării, cele mai informative coloane sunt `title`, `body` și `comments`, în timp ce `html_url` ne oferă un link înapoi la problema sursă. Hai să utilizăm funcția `Dataset.remove_columns()` pentru a elimina restul:
+
+```py
+columns = issues_dataset.column_names
+columns_to_keep = ["title", "body", "html_url", "comments"]
+columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
+issues_dataset = issues_dataset.remove_columns(columns_to_remove)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 771
+})
+```
+
+Pentru a crea embeddedurile noastre, vom completa fiecare comentariu cu titlul și body-ul problemei, deoarece aceste câmpuri adesea includ informații contextuale utile. Deoarece coloana noastră `comments` este în prezent o listă de comentarii pentru fiecare issue, trebuie să "explodăm" coloana, astfel încât fiecare rând să fie format dintr-un tuple `(html_url, title, body, comment)`. În Pandas, putem face acest lucru cu funcția [`DataFrame.explode()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), care creează un rând nou pentru fiecare element dintr-o coloană asemănătoare cu o listă, în timp ce copiază toate celelalte valori ale coloanelor. Pentru a vedea acest lucru în acțiune, să trecem la formatul pandas `DataFrame` main întâi:
+
+```py
+issues_dataset.set_format("pandas")
+df = issues_dataset[:]
+```
+
+Dacă inspectăm primul rând din acest `DataFrame`, putem vedea că există patru comentarii asociate acestei probleme:
+
+```py
+df["comments"][0].tolist()
+```
+
+```python out
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+ 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
+```
+
+Când facem explode `df`, ne așteptăm să obținem un rând pentru fiecare dintre aceste comentarii. Haideți să verificăm dacă ăsta e cazul:
+
+```py
+comments_df = df.explode("comments", ignore_index=True)
+comments_df.head(4)
+```
+
+
+
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
dataset.shuffle().select(range(50))",
+ explain: "Corect! Așa cum ați văzut în acest capitol, mai întâi faceți shuffle datasetului și apoi selectați exemplele din el.",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "Acest lucru este incorect -- deși codul va rula, va amesteca doar primele 50 de elemente din setul de date."
+ }
+ ]}
+/>
+
+### 3. Presupunem că aveți un set de date despre animale de companie numit `pets_dataset`, care are o coloană `name` care denotă numele fiecărui animal de companie. Care dintre următoarele abordări v-ar permite să filtrați setul de date pentru toate animalele de companie ale căror nume încep cu litera "L"?
+
+pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "Acest lucru este incorect -- o funcție lambda are forma generală lambda *arguments* : *expression*, deci trebuie să furnizați argumente în acest caz."
+ },
+ {
+ text: "Creați o funcție ca def filter_names(x): return x['name'].startswith('L') și rulați pets_dataset.filter(filter_names).",
+ explain: "Corect! La fel ca și cu Dataset.map(), puteți trece funcții explicite la Dataset.filter(). Acest lucru este util atunci când aveți o logică complexă care nu este potrivită pentru o funcție lambda. Care dintre celelalte soluții ar mai funcționa?",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Ce este memory mapping?
+
+IterableDataset este un generator, nu un container, deci ar trebui să accesați elementele sale utilizând next(iter(dataset)).",
+ correct: true
+ },
+ {
+ text: "Datasetul allocine nu are o un split train.",
+ explain: "Acest lucru este incorect -- consultați cardul datasetului allocine de pe Hub pentru a vedea ce splituri conține."
+ }
+ ]}
+/>
+
+### 7. Care sunt principalele beneficii ale creării unui dataset card?
+
+
{/if}
-```
\ No newline at end of file
From 092e1ccc0f64080d5039f215c961c52a43a2aa61 Mon Sep 17 00:00:00 2001
From: eduard-balamatiuc
-
-
-
-
-Cu maparea aceasta, suntem gat a să reproducem(aproape în total) rezultat primului pipeline -- noi putem lua scorul și labelul fiecărui token care nu a fost clasificat ca `O`:
-
-```py
-results = []
-tokens = inputs.tokens()
-
-for idx, pred in enumerate(predictions):
- label = model.config.id2label[pred]
- if label != "O":
- results.append(
- {"entity": label, "score": probabilities[idx][pred], "word": tokens[idx]}
- )
-
-print(results)
-```
-
-```python out
-[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S'},
- {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl'},
- {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va'},
- {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in'},
- {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu'},
- {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging'},
- {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face'},
- {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn'}]
-```
-
-Acest lucru este foarte similar cu ce am avut mai devreme, cu o excepție: pipelineul de asemenea ne-a oferit informație despre `start` și `end` al fiecărei entități în propoziția originală. Acum e momentul când offset mappingul nostru ne va ajuta. Pentru a obține offseturile, noi trebuie să setăm `return_offsets_mapping=True` când aplicăm tokenizerul pe inputurile noastre:
-
-```py
-inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
-inputs_with_offsets["offset_mapping"]
-```
-
-```python out
-[(0, 0), (0, 2), (3, 7), (8, 10), (11, 12), (12, 14), (14, 16), (16, 18), (19, 22), (23, 24), (25, 29), (30, 32),
- (33, 35), (35, 40), (41, 45), (46, 48), (49, 57), (57, 58), (0, 0)]
-```
-
-Fiecare tuple este spanul de text care corespunde fiecărui token, unde `(0, 0)` este rezervat pentru tokenii speciali. Noi am văzut înainte că tokenul la indexul 5 este `##yl`, care are aici `(12, 14)` ca offsets. Dacă luăm sliceul corespunzător în exemplul nostru:
-
-```py
-example[12:14]
-```
-
-noi obținem spanul propriu de text fără `##`:
-
-```python out
-yl
-```
-
-Folosind aceasta, putem acum completa rezultatele anterioare:
-
-
-```py
-results = []
-inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
-tokens = inputs_with_offsets.tokens()
-offsets = inputs_with_offsets["offset_mapping"]
-
-for idx, pred in enumerate(predictions):
- label = model.config.id2label[pred]
- if label != "O":
- start, end = offsets[idx]
- results.append(
- {
- "entity": label,
- "score": probabilities[idx][pred],
- "word": tokens[idx],
- "start": start,
- "end": end,
- }
- )
-
-print(results)
-```
-
-```python out
-[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
- {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
- {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
- {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
- {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
- {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
- {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
- {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-Acest răspuns e același răspuns pe care l-am primit de la primul pipeline:
-
-### Gruparea entităților[[grouping-entities]]
-
-Utilizarea offseturilor pentru a determina cheile de start și de sfârșit pentru fiecare entitate este util, dar această informație nu este strict necesară. Când dorim să grupăm entitățile împreună, totuși, offseturile ne vor salva o mulțime de messy code. De exemplu, dacă am dori să grupăm împreună tokenii `Hu`, `##gging` și `Face`, am putea crea reguli speciale care să spună că primele două ar trebui să fie atașate și să înlăturăm `##`, iar `Face` ar trebui adăugat cu un spațiu, deoarece nu începe cu `##` -- dar acest lucru ar funcționa doar pentru acest tip particular de tokenizer. Ar trebui să scriem un alt set de reguli pentru un tokenizer SentencePiece sau unul Byte-Pair-Encoding (discutat mai târziu în acest capitol).
-
-Cu offseturile, tot acel cod custom dispare: pur și simplu putem lua spanul din textul original care începe cu primul token și se termină cu ultimul token. Deci, în cazul tokenurilor `Hu`, `##gging` și `Face`, ar trebui să începem la caracterul 33 (începutul lui `Hu`) și să ne oprim înainte de caracterul 45 (sfârșitul lui `Face`):
-
-```py
-example[33:45]
-```
-
-```python out
-Hugging Face
-```
-
-Pentru a scrie codul care post-procesează predicțiile în timp ce grupăm entitățile, vom grupa entitățile care sunt consecutive și labeled cu `I-XXX`, cu excepția primeia, care poate fi labeled ca `B-XXX` sau `I-XXX` (decidem să oprim gruparea unei entități atunci când întâlnim un `O`, un nou tip de entitate, sau un `B-XXX` care ne spune că o entitate de același tip începe):
-
-```py
-import numpy as np
-
-results = []
-inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
-tokens = inputs_with_offsets.tokens()
-offsets = inputs_with_offsets["offset_mapping"]
-
-idx = 0
-while idx < len(predictions):
- pred = predictions[idx]
- label = model.config.id2label[pred]
- if label != "O":
- # Remove the B- or I-
- label = label[2:]
- start, _ = offsets[idx]
-
- # Grab all the tokens labeled with I-label
- all_scores = []
- while (
- idx < len(predictions)
- and model.config.id2label[predictions[idx]] == f"I-{label}"
- ):
- all_scores.append(probabilities[idx][pred])
- _, end = offsets[idx]
- idx += 1
-
- # The score is the mean of all the scores of the tokens in that grouped entity
- score = np.mean(all_scores).item()
- word = example[start:end]
- results.append(
- {
- "entity_group": label,
- "score": score,
- "word": word,
- "start": start,
- "end": end,
- }
- )
- idx += 1
-
-print(results)
-```
-
-Și obținem aceleași răspuns ca de la pipelineul secundar!
-
-```python out
-[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-Alt exemplu de sarcină unde offseturile sunt extrem de useful pentru răspunderea la întrebări. Scufundându-ne în pipelineuri, un lucru pe care îl vom face în următoarea secțiune, ne vom premite să ne uităm peste o caracteristică a tokenizerului în librăria 🤗 Transformers: vom avea de-a face cu overflowing tokens când truncăm un input de o anumită lungime.
-
diff --git a/chapters/ro/chapter 6/3b.mdx b/chapters/ro/chapter 6/3b.mdx
deleted file mode 100644
index 08acea387..000000000
--- a/chapters/ro/chapter 6/3b.mdx
+++ /dev/null
@@ -1,643 +0,0 @@
-
-
-
-
-
-
-
-Modelele create pentru răspunderea la întrebări funcționează puțin diferit de modelele pe care le-am văzut până acum. Folosind imaginea de mai sus ca exemplu, modelul a fost antrenat pentru a prezice indicele tokenului cu care începe răspunsului (aici 21) și indicele simbolului la care se termină răspunsul (aici 24). Acesta este motivul pentru care modelele respective nu returnează un singur tensor de logits, ci două: unul pentru logits-ul corespunzători tokenului cu care începe răspunsului și unul pentru logits-ul corespunzător tokenului de sfârșit al răspunsului. Deoarece în acest caz avem un singur input care conține 66 de token-uri, obținem:
-
-```py
-start_logits = outputs.start_logits
-end_logits = outputs.end_logits
-print(start_logits.shape, end_logits.shape)
-```
-
-{#if fw === 'pt'}
-
-```python out
-torch.Size([1, 66]) torch.Size([1, 66])
-```
-
-{:else}
-
-```python out
-(1, 66) (1, 66)
-```
-
-{/if}
-
-Pentru a converti acești logits în probabilități, vom aplica o funcție softmax - dar înainte de aceasta, trebuie să ne asigurăm că mascăm indicii care nu fac parte din context. Inputul nostru este `[CLS] întrebare [SEP] context [SEP]`, deci trebuie să mascăm token-urile întrebării, precum și tokenul `[SEP]`. Cu toate acestea, vom păstra simbolul `[CLS]`, deoarece unele modele îl folosesc pentru a indica faptul că răspunsul nu se află în context.
-
-Deoarece vom aplica ulterior un softmax, trebuie doar să înlocuim logiturile pe care dorim să le mascăm cu un număr negativ mare. Aici, folosim `-10000`:
-
-{#if fw === 'pt'}
-
-```py
-import torch
-
-sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
-mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
-mask[0] = False
-mask = torch.tensor(mask)[None]
-
-start_logits[mask] = -10000
-end_logits[mask] = -10000
-```
-
-{:else}
-
-```py
-import tensorflow as tf
-
-sequence_ids = inputs.sequence_ids()
-# Mask everything apart from the tokens of the context
-mask = [i != 1 for i in sequence_ids]
-# Unmask the [CLS] token
-mask[0] = False
-mask = tf.constant(mask)[None]
-
-start_logits = tf.where(mask, -10000, start_logits)
-end_logits = tf.where(mask, -10000, end_logits)
-```
-
-{/if}
-
-Acum că am mascat în mod corespunzător logiturile corespunzătoare pozițiilor pe care nu dorim să le prezicem, putem aplica softmax:
-
-{#if fw === 'pt'}
-
-```py
-start_probabilities = torch.nn.functional.softmax(start_logits, dim=-1)[0]
-end_probabilities = torch.nn.functional.softmax(end_logits, dim=-1)[0]
-```
-
-{:else}
-
-```py
-start_probabilities = tf.math.softmax(start_logits, axis=-1)[0].numpy()
-end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
-```
-
-{/if}
-
-La acest stadiu, am putea lua argmax al probabilităților de început și de sfârșit - dar am putea ajunge la un indice de început care este mai mare decât indicele de sfârșit, deci trebuie să luăm câteva precauții suplimentare. Vom calcula probabilitățile fiecărui `start_index` și `end_index` posibil în cazul în care `start_index <= end_index`, apoi vom lua un tuple `(start_index, end_index)` cu cea mai mare probabilitate.
-
-Presupunând că evenimentele "The answer starts at `start_index`" și "The answer ends at `end_index`" sunt independente, probabilitatea ca răspunsul să înceapă la `start_index` și să se termine la `end_index` este:
-
-$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
-
-Deci, pentru a calcula toate scorurile, trebuie doar să calculăm toate produsele \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) unde `start_index <= end_index`.
-
-Mai întâi hai să calculăm toate produsele posibile:
-
-```py
-scores = start_probabilities[:, None] * end_probabilities[None, :]
-```
-
-{#if fw === 'pt'}
-
-Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `torch.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
-
-```py
-scores = torch.triu(score)
-```
-
-{:else}
-
-Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `np.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
-
-```py
-import numpy as np
-
-scores = np.triu(scores)
-```
-
-{/if}
-
-Acum trebuie doar să obținem indicele maximului. Deoarece PyTorch va returna indicele în tensorul aplatizat, trebuie să folosim operațiile floor division `//` și modulusul `%` pentru a obține `start_index` și `end_index`:
-
-```py
-max_index = scores.argmax().item()
-start_index = max_index // scores.shape[1]
-end_index = max_index % scores.shape[1]
-print(scores[start_index, end_index])
-```
-
-Nu am terminat încă, dar cel puțin avem deja scorul corect pentru răspuns (puteți verifica acest lucru comparându-l cu primul rezultat din secțiunea anterioară):
-
-```python out
-0.97773
-```
-
-
-
-
-
-
-
-
-Înainte de a împărți un text în subtokens (în conformitate cu modelul său), tokenizerul efectuează doi pași: _normalization__ și _pre-tokenization_.
-
-## Normalization[[normalization]]
-
-
-
-
-
-
-
-
-Biblioteca 🤗 Tokenizers a fost construită pentru a oferi mai multe opțiuni pentru fiecare dintre acești pași, pe care le puteți amesteca și combina împreună. În această secțiune vom vedea cum putem construi un tokenizer de la zero, spre deosebire de antrenarea unui tokenizer nou dintr-unul vechi, așa cum am făcut în [secțiunea 2](/course/chapter6/2). Veți putea apoi să construiți orice fel de tokenizer la care vă puteți gândi!
-
-
-
-`` și '' cu " și orice secvență de două sau mai multe spații cu un singur spațiu, precum și ștergerea accentelor în textele ce trebuie tokenizate.
-
-Pre-tokenizerul care trebuie utilizat pentru orice tokenizer SentencePiece este `Metaspace`:
-
-```python
-tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
-```
-
-Putem arunca o privire la pre-tokenizarea unui exemplu de text ca mai înainte:
-
-```python
-tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
-```
-
-```python out
-[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
-```
-
-Urmează modelul, care are nevoie de antrenare. XLNet are destul de mulți tokeni speciali:
-
-```python
-special_tokens = ["
-
-
-
-Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
-
-```
-!pip install transformers
-```
-
-Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
-
-```
-import transformers
-```
-
-
-
-
-
-
-Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
-
-```
-!pip install transformers[sentencepiece]
-```
-
-Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
-
-## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
-
-Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
-
-Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
-
-Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
-
-În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
-
-În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
-
-```
-mkdir ~/transformers-course
-cd ~/transformers-course
-```
-
-Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
-
-```
-python -m venv .env
-```
-
-Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
-
-```
-ls -a
-```
-
-```out
-. .. .env
-```
-
-Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
-
-```
-# Activează mediul virtual
-source .env/bin/activate
-
-# Dezactivează virtual environment-ul
-deactivate
-```
-
-Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
-
-```
-which python
-```
-
-```out
-/home/
-
-
-
-
-
-Să trecem rapid prin fiecare dintre acestea.
-
-## Preprocesarea cu un tokenizator[[preprocesarea-cu-un-tokenizerator]]
-
-La fel ca alte rețele neuronale, modelele Transformer nu pot procesa direct text brut, astfel încât primul pas al pipeline-ului nostru este de a converti intrările de text în numere pe care modelul le poate înțelege. Pentru a face acest lucru, folosim un *tokenizer*, care va fi responsabil pentru:
-
-- Împărțirea datelor de intrare în cuvinte, părți de cuvinte sau simboluri (cum ar fi punctuația) care se numesc *tokens*
-- Maparea fiecărui token într-un număr întreg
-- Adăugarea de intrări suplimentare care pot fi utile pentru model
-
-Toată această preprocesare trebuie efectuată exact în același mod ca atunci când modelul a fost preinstruit, așa că mai întâi trebuie să descărcăm aceste informații din [Model Hub] (https://huggingface.co/models). Pentru a face acest lucru, folosim clasa `AutoTokenizer` și metoda sa `from_pretrained()`. Folosind numele checkpoint-ului modelului nostru, aceasta va prelua automat datele asociate cu tokenizer-ul modelului și le va stoca în cache (astfel încât acestea să fie descărcate doar prima dată când executați codul de mai jos).
-
-Deoarece punctul de control implicit al pipeline-ului `sentiment-analysis` este `distilbert-base-uncased-finetuned-sst-2-english` (puteți vedea fișa modelului [aici](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)), executăm următoarele:
-
-```python
-from transformers import AutoTokenizer
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-```
-
-Odată ce avem tokenizatorul, putem să îi transmitem direct propozițiile noastre și vom primi înapoi un dicționar care este gata să fie introdus în modelul nostru! Singurul lucru rămas de făcut este să convertim lista de ID-uri de intrare în tensori.
-
-Puteți utiliza 🤗 Transformers fără a trebui să vă faceți griji cu privire la cadrul ML utilizat ca backend; ar putea fi PyTorch sau TensorFlow, sau Flax pentru unele modele. Cu toate acestea, modelele Transformer acceptă numai *tensori * ca intrare. Dacă este prima dată când auziți despre tensori, vă puteți gândi la ei ca la matrici NumPy. Un array NumPy poate fi un scalar (0D), un vector (1D), o matrice (2D) sau poate avea mai multe dimensiuni. Este de fapt un tensor; tensorii altor cadre ML se comportă similar și sunt de obicei la fel de simplu de instanțiat ca și array-urile NumPy.
-
-Pentru a specifica tipul de tensori pe care dorim să îi primim înapoi (PyTorch, TensorFlow sau NumPy simplu), folosim argumentul `return_tensors`:
-
-
-{#if fw === 'pt'}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
-print(inputs)
-```
-{:else}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
-print(inputs)
-```
-{/if}
-
-
-Nu vă faceți încă griji cu privire la padding și trunchiere; le vom explica mai târziu. Principalele lucruri de reținut aici sunt că puteți trece o propoziție sau o listă de propoziții, precum și specificarea tipului de tensori pe care doriți să îi primiți înapoi (dacă nu este trecut niciun tip, veți primi o listă de liste ca rezultat)
-{#if fw === 'pt'}
-
-Iată cum arată rezultatele ca tensori PyTorch:
-
-```python out
-{
- 'input_ids': tensor([
- [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
- [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
- ]),
- 'attention_mask': tensor([
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- ])
-}
-```
-{:else}
-
-Iată cum arată rezultatele ca tensori TensorFlow:
-
-```python out
-{
- 'input_ids':
-
-
-
-
-
-
-
-Rezultatul modelului Transformer este trimis direct la head-ul modelului pentru a fi prelucrat.
-
-În această diagramă, modelul este reprezentat de stratul său de încorporare și de straturile următoare. Stratul de încorporare convertește fiecare ID de intrare din intrarea tokenizată într-un vector care reprezintă tokenul asociat. Straturile ulterioare manipulează acești vectori folosind mecanismul de atenție pentru a produce reprezentarea finală a propozițiilor.
-
-Există multe arhitecturi diferite disponibile în 🤗 Transformers, fiecare fiind concepută în jurul abordării unei sarcini specifice. Iată o listă neexhaustivă:
-
-- `*Model` (extragerea stărilor ascunse)
-- `*ForCausalLM`
-- `*ForMaskedLM`
-- `*ForMultipleChoice`
-- `*ForQuestionAnswering`
-- `*ForSequenceClassification`
-- `*ForTokenClassification`
-- și altele 🤗
-
-{#if fw === 'pt'}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `AutoModel`, ci `AutoModelForSequenceClassification`:
-
-```python
-from transformers import AutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(**inputs)
-```
-{:else}
- Pentru exemplul nostru, vom avea nevoie de un model cu un head de clasificare a secvențelor (pentru a putea clasifica propozițiile ca fiind pozitive sau negative). Așadar, nu vom utiliza clasa `TFAutoModel`, ci `TFAutoModelForSequenceClassification`:
-
-```python
-from transformers import TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(inputs)
-```
-{/if}
-
-Acum, dacă ne uităm la forma ieșirilor noastre, dimensiunea va fi mult mai mică: head-ul modelului ia ca intrare vectorii multidimensionali pe care i-am văzut înainte și scoate vectori care conțin două valori (una pentru fiecare etichetă):
-
-```python
-print(outputs.logits.shape)
-```
-
-{#if fw === 'pt'}
-```python out
-torch.Size([2, 2])
-```
-{:else}
-```python out
-(2, 2)
-```
-{/if}
-
-
-Deoarece avem doar două propoziții și două etichete, rezultatul pe care îl obținem din modelul nostru este de forma 2 x 2.
-
-## Postprocesarea rezultatului[[postprocesarea-rezultatului]]
-
-Valorile pe care le obținem ca rezultat al modelului nostru nu au neapărat sens în sine. Să aruncăm o privire:
-
-```python
-print(outputs.logits)
-```
-
-{#if fw === 'pt'}
-```python out
-tensor([[-1.5607, 1.6123],
- [ 4.1692, -3.3464]], grad_fn=
-
-
-
-
-
-
-
-Există diferite moduri de a împărți textul. De exemplu, am putea folosi spațiu pentru a tokeniza textul în cuvinte prin aplicarea funcției `split()` din Python:
-
-
-```py
-tokenized_text = "Jim Henson was a puppeteer".split()
-print(tokenized_text)
-```
-
-```python out
-['Jim', 'Henson', 'was', 'a', 'puppeteer']
-```
-
-Există, de asemenea, variații ale tokenizerelor de cuvinte care au reguli suplimentare pentru punctuație. Cu acest tip de tokenizator, putem ajunge la „vocabulare” destul de mari, unde un vocabular este definit de numărul total de token-uri independente pe care le avem în corpus.
-
-Fiecărui cuvânt i se atribuie un ID, începând de la 0 și mergând până la dimensiunea vocabularului. Modelul utilizează aceste ID-uri pentru a identifica fiecare cuvânt.
-
-Dacă dorim să acoperim complet o limbă cu un tokenizer bazat pe cuvinte, va trebui să avem un identificator pentru fiecare cuvânt din limbă, ceea ce va genera o cantitate uriașă de token-uri. De exemplu, există peste 500 000 de cuvinte în limba engleză, astfel încât, pentru a construi o hartă de la fiecare cuvânt la un ID de intrare, ar trebui să ținem evidența unui număr atât de mare de ID-uri. În plus, cuvinte precum „dog” sunt reprezentate diferit de cuvinte precum „dogs”, iar modelul nu va avea inițial nicio modalitate de a ști că „dog” și „dogs” sunt similare: va identifica cele două cuvinte ca neavând legătură. Același lucru este valabil și pentru alte cuvinte similare, precum „run” și „running”, pe care modelul nu le va vedea inițial ca fiind similare.
-
-În cele din urmă, avem nevoie de un token personalizat pentru a reprezenta cuvintele care nu se află în vocabularul nostru. Acesta este cunoscut sub numele de token "necunoscut", adesea reprezentat ca "[UNK]" sau "<unk>". În general, este un indiciu rău dacă vedeți că tokenizatorul produce o mulțime de astfel de token-uri, deoarece nu a fost capabil să recupereze reprezentarea sensibilă a unui cuvânt și veți pierde informații pe parcurs. Scopul elaborării vocabularului este de a face în așa fel încât tokenizatorul să tokenizeze cât mai puține cuvinte posibil în tokenul necunoscut.
-
-O modalitate de a reduce numărul de token-uri necunoscute este de a merge un nivel mai adânc, folosind un tokenizer _character-based_.
-
-## Character-based[[character-based]]
-
-
-
-
-
-
-
-
-
-Nici această abordare nu este perfectă. Deoarece reprezentarea se bazează acum pe caractere și nu pe cuvinte, s-ar putea spune că, din punct de vedere intuitiv, este mai puțin relevantă: fiecare caracter nu înseamnă mult în sine, în timp ce în cazul cuvintelor situația este diferită. Totuși, acest lucru variază din nou în funcție de limbă; în chineză, de exemplu, fiecare caracter conține mai multe informații decât un caracter într-o limbă latină.
-
-Un alt lucru care trebuie luat în considerare este faptul că ne vom trezi cu o cantitate foarte mare de token-uri care vor fi prelucrate de modelul nostru: în timp ce un cuvânt ar fi un singur token cu un tokenizator bazat pe cuvinte, acesta se poate transforma cu ușurință în 10 sau mai multe token-uri atunci când este convertit în caractere.
-
-Pentru a obține ce este mai bun din ambele lumi, putem utiliza o a treia tehnică care combină cele două abordări: *subword tokenization*.
-
-## Subword tokenization[[subword-tokenization]]
-
-
-
-
-
-
-
-
-Aceste părți de cuvinte oferă în cele din urmă o mulțime de semnificații semantice: în exemplul de mai sus, "tokenization" a fost împărțit în "token" și "ization", două cuvinte care au o semnificație semantică, fiind în același timp eficiente din punct de vedere al spațiului (sunt necesare doar două cuvinte pentru a reprezenta un cuvânt lung). Acest lucru ne permite să avem o acoperire relativ bună cu vocabulare de dimensiuni mici și aproape fără token-uri necunoscute.
-
-Această abordare este utilă în special în limbile aglutinative, cum ar fi turca, în care se pot forma cuvinte complexe (aproape) arbitrar de lungi prin combinarea părților de cuvinte.
-
-### Și nu numai![[și-nu-numai]]
-
-Nu este surprinzător faptul că există mult mai multe tehnici. Iată câteva:
-
-- BPE la nivel de byte, utilizată în GPT-2
-- WordPiece, utilizată în BERT
-- SentencePiece sau Unigram, utilizate în mai multe modele multilingve
-
-Acum ar trebui să cunoașteți destul de bine cum funcționează tokenizerele pentru a începe să utilizați API-
-
-## Încărcarea și salvarea[[încărcarea-și-salvarea]]
-
-Încărcarea și salvarea tokenizerelor este la fel de simplă ca în cazul modelelor. De fapt, se bazează pe aceleași două metode: `from_pretrained()` și `save_pretrained()`. Aceste metode vor încărca sau salva algoritmul utilizat de tokenizator (un pic ca *arhitectura* modelului), precum și vocabularul său (un pic ca *weight-urile* modelului).
-
-Încărcarea tokenizatorului BERT antrenat cu același punct de control ca BERT se face în același mod ca și încărcarea modelului, cu excepția faptului că folosim clasa `BertTokenizer`:
-
-```py
-from transformers import BertTokenizer
-
-tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
-```
-
-{#if fw === 'pt'}
-Similar cu `AutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{:else}
-Similar cu `TFAutoModel`, clasa `AutoTokenizer` va prelua clasa tokenizer corespunzătoare din bibliotecă pe baza numelui checkpoint-ului și poate fi utilizată direct cu orice checkpoint:
-
-{/if}
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-```
-
-Acum putem utiliza tokenizatorul așa cum am arătat în secțiunea anterioară:
-
-```python
-tokenizer("Using a Transformer network is simple")
-```
-
-```python out
-{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
-```
-
-Salvarea unui tokenizer este identică cu salvarea unui model:
-
-```py
-tokenizer.save_pretrained("directory_on_my_computer")
-```
-
-Vom vorbi mai mult despre `token_type_ids` în [Capitolul 3](/course/chapter3) și vom explica cheia `attention_mask` puțin mai târziu. Mai întâi, să vedem cum sunt generate `input_ids`. Pentru a face acest lucru, va trebui să ne uităm la metodele intermediare ale tokenizatorului.
-
-## Codificarea[[codificarea]]
-
-
-
-AutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{:else}
-### 5. What is an TFAutoModel?
-
-TFAutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{/if}
-
-### 6. What are the techniques to be aware of when batching sequences of different lengths together?
-
-encode method does exist on tokenizers, it does not exist on models."
- },
- {
- text: "Calling the tokenizer object directly.",
- explain: "Exactly! The __call__ method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
- correct: true
- },
- {
- text: "pad",
- explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
- },
- {
- text: "tokenize",
- explain: "The tokenize method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
- }
- ]}
-/>
-
-### 9. What does the `result` variable contain in this code sample?
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-result = tokenizer.tokenize("Hello!")
-```
-
-convert_tokens_to_ids method is for!"
- },
- {
- text: "A string containing all of the tokens",
- explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 10. Is there something wrong with the following code?
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = AutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Un Trainer",
- explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
- correct: true
- }
- ]}
-/>
-
-{:else}
-push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
- correct: true
- },
- {
- text: "Un model",
- explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
- correct: true
- },
- {
- text: "Toate cele trei cu un callback dedicat",
- explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
- correct: true
- }
- ]}
-/>
-{/if}
-
-### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
-
-huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
- },
- {
- text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
- explain: "Comanda upload-model nu există."
- }
- ]}
-/>
-
-### 8. Carele operații git poți face cu clasa `Repository`?
-
-git_pull()",
- correct: true
- },
- {
- text: "Un push",
- explain: "Metoda git_push() face acest lucru.",
- correct: true
- },
- {
- text: "Un merge",
- explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
- }
- ]}
-/>
\ No newline at end of file
From c1170187ba99e85c2d5ba60c07b44d205116cc2e Mon Sep 17 00:00:00 2001
From: eduard-balamatiuc
+
+
+
+Următorul pas este să instalezi librăriile pe care le vom folosi în acest curs. Vom folosi `pip` pentru instalare, care este managerul de packages pentru Python. În notebook-uri, poți rula comenzi de sistem începând comanda cu caracterul `!`, așa că poți instala librăria 🤗 Transformers astfel:
+
+```
+!pip install transformers
+```
+
+Te poți asigura că pachetul a fost instalat corect importându-l în cadrul mediului tău Python:
+
+```
+import transformers
+```
+
+
+
+
+
+
+Aceasta instalează o versiune foarte ușoară a 🤗 Transformers. În special, nu sunt instalate framework-uri specifice de machine learning (cum ar fi PyTorch sau TensorFlow). Deoarece vom folosi multe caracteristici diferite ale librăriei, îți recomandăm să instalezi versiunea pentru development, care vine cu toate dependențele necesare pentru cam orice caz de utilizare imaginabil:
+
+```
+!pip install transformers[sentencepiece]
+```
+
+Aceasta va dura puțin timp, dar apoi vei fi gata de drum pentru restul cursului!
+
+## Folosirea unui virtual environment Python[[folosirea-unui-virtual-environment-python]]
+
+Dacă preferi să folosești un mediu virtual Python, primul pas este să instalezi Python pe sistemul tău. Îți recomandăm să urmezi [această ghidare](https://realpython.com/installing-python/) pentru a începe.
+
+Odată ce ai Python instalat, ar trebui să poți rula comenzi Python în terminalul tău. Poți începe rulând următoarea comandă pentru a te asigura că este instalat corect înainte de a trece la pașii următori: `python --version`. Aceasta ar trebui să afișeze versiunea Python disponibilă acum pe sistemul tău.
+
+Când rulezi o comandă Python în terminalul tău, cum ar fi `python --version`, ar trebui să te gândești la programul care rulează comanda ta ca la Python-ul "principal" de pe sistemul tău. Îți recomandăm să păstrezi această instalare principală liberă de orice pachete și să o folosești pentru a crea environment-uri separate pentru fiecare aplicație pe care lucrezi — în acest fel, fiecare aplicație poate avea propriile sale dependențe și pachete, și nu va trebui să te preocupi de problemele de compatibilitate potențiale cu alte aplicații.
+
+În Python, acest lucru se face prin [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), care sunt directory trees autonomi ce conțin fiecare o instalare Python cu o anumită versiune Python împreună cu toate pachetele de care are nevoie aplicația. Crearea unui astfel de mediu virtual poate fi realizată cu mai multe instrumente diferite, dar vom folosi pachetul oficial Python pentru acest scop, denumit [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
+
+În primul rând, creează folder în care dorești ca aplicația ta să locuiască — de exemplu, ai putea dori să faci un nou folder numit *transformers-course* în rădăcina folderului tău personal:
+
+```
+mkdir ~/transformers-course
+cd ~/transformers-course
+```
+
+Din interiorul acestui folder, creează un virtual environment folosind modulul Python `venv`:
+
+```
+python -m venv .env
+```
+
+Acum ar trebui să ai un folder numit *.env* în folderul tău altfel gol:
+
+```
+ls -a
+```
+
+```out
+. .. .env
+```
+
+Poți să intri și să ieși din environment folosind comenzile `activate` și `deactivate`:
+
+```
+# Activează mediul virtual
+source .env/bin/activate
+
+# Dezactivează virtual environment-ul
+deactivate
+```
+
+Te poți asigura că environment-ul este activat rulând comanda `which python`: dacă aceasta indică către virtual environment, atunci l-ai activat cu succes!
+
+```
+which python
+```
+
+```out
+/home/
+
+
+
+
+
+Cu maparea aceasta, suntem gat a să reproducem(aproape în total) rezultat primului pipeline -- noi putem lua scorul și labelul fiecărui token care nu a fost clasificat ca `O`:
+
+```py
+results = []
+tokens = inputs.tokens()
+
+for idx, pred in enumerate(predictions):
+ label = model.config.id2label[pred]
+ if label != "O":
+ results.append(
+ {"entity": label, "score": probabilities[idx][pred], "word": tokens[idx]}
+ )
+
+print(results)
+```
+
+```python out
+[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S'},
+ {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl'},
+ {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va'},
+ {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in'},
+ {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu'},
+ {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging'},
+ {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face'},
+ {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn'}]
+```
+
+Acest lucru este foarte similar cu ce am avut mai devreme, cu o excepție: pipelineul de asemenea ne-a oferit informație despre `start` și `end` al fiecărei entități în propoziția originală. Acum e momentul când offset mappingul nostru ne va ajuta. Pentru a obține offseturile, noi trebuie să setăm `return_offsets_mapping=True` când aplicăm tokenizerul pe inputurile noastre:
+
+```py
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+inputs_with_offsets["offset_mapping"]
+```
+
+```python out
+[(0, 0), (0, 2), (3, 7), (8, 10), (11, 12), (12, 14), (14, 16), (16, 18), (19, 22), (23, 24), (25, 29), (30, 32),
+ (33, 35), (35, 40), (41, 45), (46, 48), (49, 57), (57, 58), (0, 0)]
+```
+
+Fiecare tuple este spanul de text care corespunde fiecărui token, unde `(0, 0)` este rezervat pentru tokenii speciali. Noi am văzut înainte că tokenul la indexul 5 este `##yl`, care are aici `(12, 14)` ca offsets. Dacă luăm sliceul corespunzător în exemplul nostru:
+
+```py
+example[12:14]
+```
+
+noi obținem spanul propriu de text fără `##`:
+
+```python out
+yl
+```
+
+Folosind aceasta, putem acum completa rezultatele anterioare:
+
+
+```py
+results = []
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+tokens = inputs_with_offsets.tokens()
+offsets = inputs_with_offsets["offset_mapping"]
+
+for idx, pred in enumerate(predictions):
+ label = model.config.id2label[pred]
+ if label != "O":
+ start, end = offsets[idx]
+ results.append(
+ {
+ "entity": label,
+ "score": probabilities[idx][pred],
+ "word": tokens[idx],
+ "start": start,
+ "end": end,
+ }
+ )
+
+print(results)
+```
+
+```python out
+[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
+ {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
+ {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
+ {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
+ {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
+ {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
+ {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
+ {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Acest răspuns e același răspuns pe care l-am primit de la primul pipeline:
+
+### Gruparea entităților[[grouping-entities]]
+
+Utilizarea offseturilor pentru a determina cheile de start și de sfârșit pentru fiecare entitate este util, dar această informație nu este strict necesară. Când dorim să grupăm entitățile împreună, totuși, offseturile ne vor salva o mulțime de messy code. De exemplu, dacă am dori să grupăm împreună tokenii `Hu`, `##gging` și `Face`, am putea crea reguli speciale care să spună că primele două ar trebui să fie atașate și să înlăturăm `##`, iar `Face` ar trebui adăugat cu un spațiu, deoarece nu începe cu `##` -- dar acest lucru ar funcționa doar pentru acest tip particular de tokenizer. Ar trebui să scriem un alt set de reguli pentru un tokenizer SentencePiece sau unul Byte-Pair-Encoding (discutat mai târziu în acest capitol).
+
+Cu offseturile, tot acel cod custom dispare: pur și simplu putem lua spanul din textul original care începe cu primul token și se termină cu ultimul token. Deci, în cazul tokenurilor `Hu`, `##gging` și `Face`, ar trebui să începem la caracterul 33 (începutul lui `Hu`) și să ne oprim înainte de caracterul 45 (sfârșitul lui `Face`):
+
+```py
+example[33:45]
+```
+
+```python out
+Hugging Face
+```
+
+Pentru a scrie codul care post-procesează predicțiile în timp ce grupăm entitățile, vom grupa entitățile care sunt consecutive și labeled cu `I-XXX`, cu excepția primeia, care poate fi labeled ca `B-XXX` sau `I-XXX` (decidem să oprim gruparea unei entități atunci când întâlnim un `O`, un nou tip de entitate, sau un `B-XXX` care ne spune că o entitate de același tip începe):
+
+```py
+import numpy as np
+
+results = []
+inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
+tokens = inputs_with_offsets.tokens()
+offsets = inputs_with_offsets["offset_mapping"]
+
+idx = 0
+while idx < len(predictions):
+ pred = predictions[idx]
+ label = model.config.id2label[pred]
+ if label != "O":
+ # Remove the B- or I-
+ label = label[2:]
+ start, _ = offsets[idx]
+
+ # Grab all the tokens labeled with I-label
+ all_scores = []
+ while (
+ idx < len(predictions)
+ and model.config.id2label[predictions[idx]] == f"I-{label}"
+ ):
+ all_scores.append(probabilities[idx][pred])
+ _, end = offsets[idx]
+ idx += 1
+
+ # The score is the mean of all the scores of the tokens in that grouped entity
+ score = np.mean(all_scores).item()
+ word = example[start:end]
+ results.append(
+ {
+ "entity_group": label,
+ "score": score,
+ "word": word,
+ "start": start,
+ "end": end,
+ }
+ )
+ idx += 1
+
+print(results)
+```
+
+Și obținem aceleași răspuns ca de la pipelineul secundar!
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Alt exemplu de sarcină unde offseturile sunt extrem de useful pentru răspunderea la întrebări. Scufundându-ne în pipelineuri, un lucru pe care îl vom face în următoarea secțiune, ne vom premite să ne uităm peste o caracteristică a tokenizerului în librăria 🤗 Transformers: vom avea de-a face cu overflowing tokens când truncăm un input de o anumită lungime.
+
diff --git a/chapters/rum/chapter6/3b.mdx b/chapters/rum/chapter6/3b.mdx
new file mode 100644
index 000000000..0a7997708
--- /dev/null
+++ b/chapters/rum/chapter6/3b.mdx
@@ -0,0 +1,643 @@
+
+
+
+
+
+
+
+Modelele create pentru răspunderea la întrebări funcționează puțin diferit de modelele pe care le-am văzut până acum. Folosind imaginea de mai sus ca exemplu, modelul a fost antrenat pentru a prezice indicele tokenului cu care începe răspunsului (aici 21) și indicele simbolului la care se termină răspunsul (aici 24). Acesta este motivul pentru care modelele respective nu returnează un singur tensor de logits, ci două: unul pentru logits-ul corespunzători tokenului cu care începe răspunsului și unul pentru logits-ul corespunzător tokenului de sfârșit al răspunsului. Deoarece în acest caz avem un singur input care conține 66 de token-uri, obținem:
+
+```py
+start_logits = outputs.start_logits
+end_logits = outputs.end_logits
+print(start_logits.shape, end_logits.shape)
+```
+
+{#if fw === 'pt'}
+
+```python out
+torch.Size([1, 66]) torch.Size([1, 66])
+```
+
+{:else}
+
+```python out
+(1, 66) (1, 66)
+```
+
+{/if}
+
+Pentru a converti acești logits în probabilități, vom aplica o funcție softmax - dar înainte de aceasta, trebuie să ne asigurăm că mascăm indicii care nu fac parte din context. Inputul nostru este `[CLS] întrebare [SEP] context [SEP]`, deci trebuie să mascăm token-urile întrebării, precum și tokenul `[SEP]`. Cu toate acestea, vom păstra simbolul `[CLS]`, deoarece unele modele îl folosesc pentru a indica faptul că răspunsul nu se află în context.
+
+Deoarece vom aplica ulterior un softmax, trebuie doar să înlocuim logiturile pe care dorim să le mascăm cu un număr negativ mare. Aici, folosim `-10000`:
+
+{#if fw === 'pt'}
+
+```py
+import torch
+
+sequence_ids = inputs.sequence_ids()
+# Mask everything apart from the tokens of the context
+mask = [i != 1 for i in sequence_ids]
+# Unmask the [CLS] token
+mask[0] = False
+mask = torch.tensor(mask)[None]
+
+start_logits[mask] = -10000
+end_logits[mask] = -10000
+```
+
+{:else}
+
+```py
+import tensorflow as tf
+
+sequence_ids = inputs.sequence_ids()
+# Mask everything apart from the tokens of the context
+mask = [i != 1 for i in sequence_ids]
+# Unmask the [CLS] token
+mask[0] = False
+mask = tf.constant(mask)[None]
+
+start_logits = tf.where(mask, -10000, start_logits)
+end_logits = tf.where(mask, -10000, end_logits)
+```
+
+{/if}
+
+Acum că am mascat în mod corespunzător logiturile corespunzătoare pozițiilor pe care nu dorim să le prezicem, putem aplica softmax:
+
+{#if fw === 'pt'}
+
+```py
+start_probabilities = torch.nn.functional.softmax(start_logits, dim=-1)[0]
+end_probabilities = torch.nn.functional.softmax(end_logits, dim=-1)[0]
+```
+
+{:else}
+
+```py
+start_probabilities = tf.math.softmax(start_logits, axis=-1)[0].numpy()
+end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
+```
+
+{/if}
+
+La acest stadiu, am putea lua argmax al probabilităților de început și de sfârșit - dar am putea ajunge la un indice de început care este mai mare decât indicele de sfârșit, deci trebuie să luăm câteva precauții suplimentare. Vom calcula probabilitățile fiecărui `start_index` și `end_index` posibil în cazul în care `start_index <= end_index`, apoi vom lua un tuple `(start_index, end_index)` cu cea mai mare probabilitate.
+
+Presupunând că evenimentele "The answer starts at `start_index`" și "The answer ends at `end_index`" sunt independente, probabilitatea ca răspunsul să înceapă la `start_index` și să se termine la `end_index` este:
+
+$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
+
+Deci, pentru a calcula toate scorurile, trebuie doar să calculăm toate produsele \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) unde `start_index <= end_index`.
+
+Mai întâi hai să calculăm toate produsele posibile:
+
+```py
+scores = start_probabilities[:, None] * end_probabilities[None, :]
+```
+
+{#if fw === 'pt'}
+
+Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `torch.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
+
+```py
+scores = torch.triu(score)
+```
+
+{:else}
+
+Apoi vom masca valorile în care `start_index > end_index` prin stabilirea lor la `0` (celelalte probabilități sunt toate numere pozitive). Funcția `np.triu()` returnează partea triunghiulară superioară a tensorului 2D trecut ca argument, deci va face această mascare pentru noi:
+
+```py
+import numpy as np
+
+scores = np.triu(scores)
+```
+
+{/if}
+
+Acum trebuie doar să obținem indicele maximului. Deoarece PyTorch va returna indicele în tensorul aplatizat, trebuie să folosim operațiile floor division `//` și modulusul `%` pentru a obține `start_index` și `end_index`:
+
+```py
+max_index = scores.argmax().item()
+start_index = max_index // scores.shape[1]
+end_index = max_index % scores.shape[1]
+print(scores[start_index, end_index])
+```
+
+Nu am terminat încă, dar cel puțin avem deja scorul corect pentru răspuns (puteți verifica acest lucru comparându-l cu primul rezultat din secțiunea anterioară):
+
+```python out
+0.97773
+```
+
+
+
+
+
+
+
+
+Înainte de a împărți un text în subtokens (în conformitate cu modelul său), tokenizerul efectuează doi pași: _normalization__ și _pre-tokenization_.
+
+## Normalization[[normalization]]
+
+
+
+
+
+
+
+
+Biblioteca 🤗 Tokenizers a fost construită pentru a oferi mai multe opțiuni pentru fiecare dintre acești pași, pe care le puteți amesteca și combina împreună. În această secțiune vom vedea cum putem construi un tokenizer de la zero, spre deosebire de antrenarea unui tokenizer nou dintr-unul vechi, așa cum am făcut în [secțiunea 2](/course/chapter6/2). Veți putea apoi să construiți orice fel de tokenizer la care vă puteți gândi!
+
+
+
+`` și '' cu " și orice secvență de două sau mai multe spații cu un singur spațiu, precum și ștergerea accentelor în textele ce trebuie tokenizate.
+
+Pre-tokenizerul care trebuie utilizat pentru orice tokenizer SentencePiece este `Metaspace`:
+
+```python
+tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
+```
+
+Putem arunca o privire la pre-tokenizarea unui exemplu de text ca mai înainte:
+
+```python
+tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
+```
+
+```python out
+[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
+```
+
+Urmează modelul, care are nevoie de antrenare. XLNet are destul de mulți tokeni speciali:
+
+```python
+special_tokens = ["