[CLS] la început, dar nu este singurul lucru necesar!"
+ },
+ {
+ text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2 [SEP]",
+ explain: "Corect!",
+ correct: true
+ },
+ {
+ text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2",
+ explain: "Este nevoie atât de un token special [CLS] la început, cât și de un token special [SEP] pentru a separa cele două propoziții, dar mai lipsește ceva!"
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 4. Care sunt avantajele metodei `Dataset.map()`?
+
+DataLoader. Am folosit funcția DataCollatorWithPadding, care împachetează toate elementele dintr-un batch astfel încât să aibă aceeași lungime.",
+ correct: true
+ },
+ {
+ text: "Preprocesează întregul set de date.",
+ explain: "Aceasta ar fi o funcție de preprocessing, nu o funcție de collate."
+ },
+ {
+ text: "Trunchiază secvențele din setul de date.",
+ explain: "O funcție de collate se ocupă de manipularea batch-urilor individuale, nu a întregului set de date. Dacă sunteți interesați de trunchiere, puteți folosi argumentul truncate al tokenizer."
+ }
+ ]}
+/>
+
+### 7. Ce se întâmplă când instanțiați una dintre clasele `AutoModelForXxx` cu un model de limbaj preantrenat (cum ar fi `bert-base-uncased`), care corespunde unei alte sarcini decât cea pentru care a fost antrenat?
+
+bert-base-uncased, am primit avertismente la instanțierea modelului. Head-ul preantrenat nu este folosit pentru sarcina de clasificare secvențială, așa că este eliminat și un nou head este instanțiat cu greutăți inițializate aleator.",
+ correct: true
+ },
+ {
+ text: "Head-ul modelului preantrenat este eliminat.",
+ explain: "Mai trebuie să se întâmple și altceva. Încercați din nou!"
+ },
+ {
+ text: "Nimic, pentru că modelul poate fi ajustat fin (fine-tuned) chiar și pentru o altă sarcină.",
+ explain: "Head-ul preantrenat al modelului nu a fost antrenat pentru această sarcină, deci trebuie eliminat!"
+ }
+ ]}
+/>
+
+### 8. Care este scopul folosirii `TrainingArguments`?
+
+TrainingArguments."
+ },
+ {
+ text: "Conține doar hiperparametrii folosiți pentru evaluare.",
+ explain: "În exemplu, am specificat și unde va fi salvat modelul și checkpoint-urile. Încercați din nou!"
+ },
+ {
+ text: "Conține doar hiperparametrii folosiți pentru antrenare.",
+ explain: "În exemplu, am folosit și un evaluation_strategy, așadar acest lucru afectează evaluarea. Încercați din nou!"
+ }
+ ]}
+/>
+
+### 9. De ce ar trebui să folosiți biblioteca 🤗 Accelerate?
+
+bert-base-uncased, am primit avertismente la instanțierea modelului. Head-ul preantrenat nu este folosit pentru sarcina de clasificare secvențială, așa că este eliminat și un nou head este instanțiat cu greutăți inițializate aleator.",
+ correct: true
+ },
+ {
+ text: "Head-ul modelului preantrenat este eliminat.",
+ explain: "Mai trebuie să se întâmple și altceva. Încercați din nou!"
+ },
+ {
+ text: "Nimic, pentru că modelul poate fi ajustat fin (fine-tuned) chiar și pentru o altă sarcină.",
+ explain: "Head-ul preantrenat al modelului nu a fost antrenat pentru această sarcină, deci trebuie eliminat!"
+ }
+ ]}
+/>
+
+### 5. Modelele TensorFlow din `transformers` sunt deja modele Keras. Ce avantaj oferă acest lucru?
+
+compile(), fit() și predict().",
+ explain: "Corect! Odată ce aveți datele, antrenarea necesită foarte puțin efort.",
+ correct: true
+ },
+ {
+ text: "Învățați atât Keras, cât și transformers.",
+ explain: "Corect, dar căutăm altceva :)",
+ correct: true
+ },
+ {
+ text: "Puteți calcula cu ușurință metrici legate de dataset.",
+ explain: "Keras ne ajută la antrenarea și evaluarea modelului, nu la calcularea metricilor legate de dataset."
+ }
+ ]}
+/>
+
+### 6. Cum vă puteți defini propria metrică personalizată?
+
+metric_fn(y_true, y_pred).",
+ explain: "Corect!",
+ correct: true
+ },
+ {
+ text: "Căutând pe Google.",
+ explain: "Nu este răspunsul pe care îl căutăm, dar probabil v-ar putea ajuta să-l găsiți.",
+ correct: true
+ }
+ ]}
+/>
+
+{/if}
\ No newline at end of file
diff --git a/chapters/rum/chapter4/1.mdx b/chapters/rum/chapter4/1.mdx
new file mode 100644
index 000000000..4ef56abf4
--- /dev/null
+++ b/chapters/rum/chapter4/1.mdx
@@ -0,0 +1,22 @@
+# Platforma Hugging Face Hub[[the-hugging-face-hub]]
+
+
+ +
+
+
+Alegem checkpointul „camembert-base” pentru al încerca. Identificatorul `camembert-base` este tot de ce avem nevoie pentru a începe. În capitolele precedente, am văzut cum putem inițializa modelul folosind funcția `pipeline()`:
+
+```py
+from transformers import pipeline
+
+camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
+results = camembert_fill_mask("Le camembert est
+
+ +
+
+
+Puteți inițializa checkpointul în mod direct folosind arhitectura modelului:
+
+{#if fw === 'pt'}
+```py
+from transformers import CamembertTokenizer, CamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = CamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+Însă, recomandăm utilizarea [claselor `Auto*`](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes), deoarece acestea sunt proiectate să fie architecture-agnostic. În timp ce codul precedent limita utilizatorii la checkpoints loadable în CamemBERT architecture, utilizarea claselor `Auto*` face schimbarea checkpointurilor simplă:
+
+```py
+from transformers import AutoTokenizer, AutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = AutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{:else}
+```py
+from transformers import CamembertTokenizer, TFCamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = TFCamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+Însă, recomandăm utilizarea [claselor `TFAuto*`](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes), deoarece acestea sunt proiectate să fie architecture-agnostic. În timp ce codul precedent limita utilizatorii la checkpoints loadable în CamemBERT architecture, utilizarea claselor `TFAuto*` face schimbarea checkpointurilor simplă:
+
+```py
+from transformers import AutoTokenizer, TFAutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = TFAutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{/if}
+
+
+
+  +
+
+
+{:else}
+
+Dacă utilizați Keras pentru a antrena modelul dumneavoastră, cea mai ușoară modalitate de a încărca-o pe Hub este să transmiteți un `PushToHubCallback` când chemați `model.fit()`:
+
+```py
+from transformers import PushToHubCallback
+
+callback = PushToHubCallback(
+ "bert-finetuned-mrpc", save_strategy="epoch", tokenizer=tokenizer
+)
+```
+
+Apoi, adăugați `callbacks=[callback]` în apelul la `model.fit()`. Callback-ul va încărca apoi modelul pe Hub de fiecare dată când se salvează (aici, la fiecare epocă) într-un repository din namespace-ul tău. Acest repository va fi numit după output directory ales (aici `bert-finetuned-mrpc`), dar puteți alege un alt nume cu `hub_model_id = "un_nume_diferit"`.
+
+Pentru a încărca modelul într-o organizație din care faceți parte, este suficient să introduceți aceasta în `hub_model_id = "organizația_mea/numele_repositoriului"`.
+
+{/if}
+
+La un nivel inferior, accesarea Hub-ului se poate face direct pe modele, tokenizers și configurations objects prin metoda `push_to_hub()`. Această metodă se ocupă atât de crearea repositoriului cât si de încărcarea modelului și tokenizerului direct în el. Nu este nevoie de o interacțiune manuală, precum fața de API-ul pe care îl vom vedea mai jos.
+
+Pentru a înțelege cum funcționează, luați în considerare inițializarea unui model și a unui tokenizer:
+
+{#if fw === 'pt'}
+```py
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = AutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{:else}
+```py
+from transformers import TFAutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{/if}
+
+Sunteți liberi să faceți orice ați vrea cu acestea - adăugați tokens la tokenizer, antrenați modelul sau faceți fine-tune. Odată ce sunteți mulțumiți de modelul obținut, weighturile și tokenizerul acestuia , puteți folosi metoda `push_to_hub()` disponibilă direct pe obiectul `model`:
+
+```py
+model.push_to_hub("dummy-model")
+```
+Acest lucru va crea un nou repository `dummy-model` în profilul tău și o va popula cu fișierele modelului tău.
+Încercați același lucru cu tokenizerul, astfel încât toate fișierele să fie acum disponibile în acest repository:
+
+```py
+tokenizer.push_to_hub("dummy-model")
+```
+
+Dacă aparțineți unei organizații, specificați doar argumentul `organization` pentru a încărca în namespace-ul acestei organizații:
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface")
+```
+
+Dacă doriți să utilizați un anumit token Hugging Face, sunteți liberi să specificați acest lucru metodei `push_to_hub()`:
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="
+
+ +
+
+{:else}
+
+
+ +
+
+{/if}
+
+
+
+ +
+
+
+În primul rând, specificați deținătorul repositoriului: acesta puteți fi fie dumneavoastră, fie orice organizație cu care sunteți afiliat. Dacă alegeți o organizație, modelul va fi prezent pe pagina organizației și toți membrii acesteia vor avea posibilitatea să contribuie la repositoriu.
+
+În al doilea rând, introduceți numele modelului dumneavoastră. Acest lucru va fi și denumirea repositoriului. În final, puteți specifica dacă doriți ca modelul dumneavoastră să fie public sau privat. Modelele private nu sunt vizibile ceilorlalți.
+
+După crearea repositoriului, ar trebui să vedeți o pagină ca aceasta:
+
+
+
+ +
+
+
+Acesta este locul unde va fi găzduit modelul. Pentru a începe să populați acesta, puteți adăuga un fișier README direct din interfața web.
+
+
+
+ +
+
+
+Fișierul README este scris în format Markdown - vă rugăm să fiți creativi cu el! A treia parte a acestui capitol se ocupă de crearea unui model card. Acestea sunt foarte importante pentru a aduce valoare modelului dumneavoastră, deoarece este acolo unde spuneți celorlalți ce poate face.
+
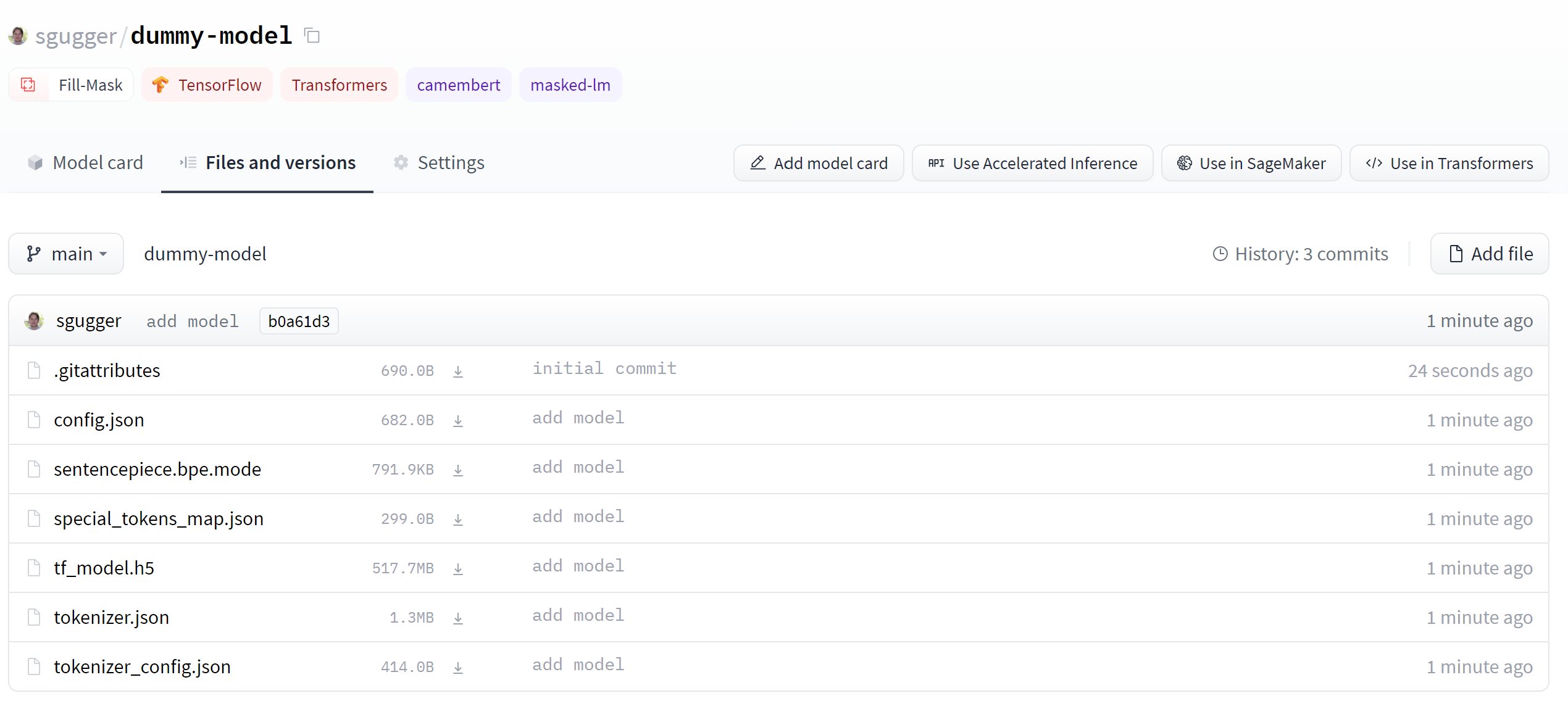
+Dacă vă uitați la secțiunea "Fișiere și versiuni", veți vedea că nu sunt prea multe fișiere acolo încă - doar *README.md* pe care l-ați creat dumneavoastră și *.gitattributes* care urmărește fișierele mari.
+
+
+
+ +
+
+
+Vom vedea mai târziu cum să adăugați câteva fișiere noi.
+
+## Încărcarea fișierelor modelului[[uploading-the-model-files]]
+
+Sistemul pentru a gestiona fișierele în Hugging Face Hub se bazează pe git pentru fișierele obișnuite, și pe git-lfs (care se descrifrează ca [Git Large File Storage](https://git-lfs.github.com/)) pentru fișierele mai mari.
+
+În secțiunea următoare, vom discuta despre trei metode diferite de încărcare a fișierelor în Hub: prin `huggingface_hub` și prin comanda git.
+
+### Metoda `upload_file`[[the-uploadfile-approach]]
+
+Prin `upload_file` nu este necesar să instalați git și git-lfs pe sistemul dumneavoastră. Acest lucru încarcă direct fișierele în 🤗 Hub folosind HTTP POST requests. O limitare a acestei metode este că ea nu se ocupă de fișiere care sunt mai mari de 5GB.
+Dacă fișierele dumneavoastră sunt mai mari decât 5 GB, vă rugăm să urmați celelalte două metode descrise mai jos.
+
+API-ul poate fi folosit astfel:
+
+```py
+from huggingface_hub import upload_file
+
+upload_file(
+ "
+
+ +
+
+
+Interfața permite explorarea fișierelor modelului și a commiturilor și vizualizarea diferenței introduse de fiecare commit:
+
+
+
+ +
+
+{:else}
+Dacă ne uităm la repositoriul modelului când acest lucru este finalizat, putem vedea toate fișierele recent adăugate:
+
+
+
+ +
+
+
+Interfața permite explorarea fișierelor modelului și a commiturilor și vizualizarea diferenței introduse de fiecare commit:
+
+
+
+ +
+
+{/if}
diff --git a/chapters/rum/chapter4/4.mdx b/chapters/rum/chapter4/4.mdx
new file mode 100644
index 000000000..5615a1651
--- /dev/null
+++ b/chapters/rum/chapter4/4.mdx
@@ -0,0 +1,88 @@
+# Crearea unui card de model[[building-a-model-card]]
+
+
+
+push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Un Trainer",
+ explain: "Corect — Trainer implementează metoda push_to_hub, și utilizând-o, vor încărca modelul, configurarea sa, tokenizerul, precum și un draft a unui model card către un repo. Încearcă și altă opțiune!",
+ correct: true
+ }
+ ]}
+/>
+
+{:else}
+push_to_hub, și utilizând-o, vor împărtăși configurația către un repo. Și ce altceva poți oferi?",
+ correct: true
+ },
+ {
+ text: "Un model",
+ explain: "Corect! Toate modelele au metoda push_to_hub, și utilizând-o, vor împărtăși ei, precum și fișierele de configurare către un repo. Și nu numai asta!",
+ correct: true
+ },
+ {
+ text: "Toate cele trei cu un callback dedicat",
+ explain: "Corect — PushToHubCallback va trimite regular toate aceste obiecte către un repo în timpul antrenării.",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. Care este primul pas atunci când utilizați metoda `push_to_hub()` sau instrumentele CLI?
+
+huggingface_hub: nu vă trebuie nici un wrapping suplimentar!"
+ },
+ {
+ text: "Prin salvarea lor pe disc și apelarea transformers-cli upload-model",
+ explain: "Comanda upload-model nu există."
+ }
+ ]}
+/>
+
+### 8. Ce operații git poți face cu clasa `Repository`?
+
+git_pull()",
+ correct: true
+ },
+ {
+ text: "Un push",
+ explain: "Metoda git_push() face acest lucru.",
+ correct: true
+ },
+ {
+ text: "Un merge",
+ explain: "Nu, această operație nu va fi niciodată posibilă cu acest API."
+ }
+ ]}
+/>
\ No newline at end of file
diff --git a/chapters/rum/chapter5/1.mdx b/chapters/rum/chapter5/1.mdx
new file mode 100644
index 000000000..99ac985b9
--- /dev/null
+++ b/chapters/rum/chapter5/1.mdx
@@ -0,0 +1,22 @@
+# Introducere[[introduction]]
+
+| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
+ +
+
+
+Dacă ați da clic pe una dintre aceste issue-uri veți găsi că aceasta conține un titlu, o descriere și un set de labeluri care caracterizează issue-ul. Un exemplu este prezentat în screenshotul următor.
+
+
+
+ +
+
+
+Pentru a descărca toate issue-urile din repositoriu, vom folosi [GitHub REST API](https://docs.github.com/en/rest) pentru a enumera [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues). Aceast endpoint returnează o listă de obiecte JSON, cu fiecare obiect conținând un număr mare de câmpuri care includ titlul și descrierea precum și metadata despre starea issue-ului și așa mai departe.
+
+Un mod convenabil de descărcare a issue-urilor este prin utilizarea librăriei `requests`, care este modalitatea standard pentru a face cereri HTTP în Python. Puteți instala libraria rulând comanda:
+
+```python
+!pip install requests
+```
+
+Odată cu instalarea librariei, puteți face cereri GET la `Issues` endpoint prin invocarea funcției `requests.get()`. De exemplu, puteți rula următorul cod pentru a obține primul issue din prima pagină:
+
+```py
+import requests
+
+url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
+response = requests.get(url)
+```
+
+Obiectul `response` conține o cantitate mare de informații utile despre requestul efectuat, inclusiv HTTP status code:
+
+```py
+response.status_code
+```
+
+```python out
+200
+```
+
+unde statusul `200` înseamnă că cererea a fost reușită (puteți găsi o listă completă de status coduri [aici](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)). De ceea ce suntem însă interesați este _payload_, care poate fi accesat în diverse formaturi precum bytes, string sau JSON. Deoarece știm că issue-urile noastre sunt în format JSON, să inspectăm payload-ul astfel:
+
+```py
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
+ 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
+ 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
+ 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'id': 968650274,
+ 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
+ 'number': 2792,
+ 'title': 'Update GooAQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'labels': [],
+ 'state': 'open',
+ 'locked': False,
+ 'assignee': None,
+ 'assignees': [],
+ 'milestone': None,
+ 'comments': 1,
+ 'created_at': '2021-08-12T11:40:18Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'closed_at': None,
+ 'author_association': 'CONTRIBUTOR',
+ 'active_lock_reason': None,
+ 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
+ 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
+ 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
+ 'performed_via_github_app': None}]
+```
+
+Uau, aceasta e o cantitate mare de informație! Putem vedea câmpuri utile cum ar fi `title`, `body` și `number` care descriu problema, precum și informații despre utilizatorul GitHub care a deschis issue-ul.
+
+
+
+ +
+
+
+GitHub REST API oferă un endpoint [`Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) care returnează toate comentariile asociate numărului problemei. Să testăm endpointul pentru a vedea ce returnează:
+
+```py
+issue_number = 2792
+url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+response = requests.get(url, headers=headers)
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
+ 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'id': 897594128,
+ 'node_id': 'IC_kwDODunzps41gDMQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'created_at': '2021-08-12T12:21:52Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'author_association': 'CONTRIBUTOR',
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'performed_via_github_app': None}]
+```
+
+Putem vedea că comentariul este stocat în câmpul `body`, așa că putem scrie o funcție simplă care returnează toate comentariile asociate unei probleme prin extragerea conținutului `body` pentru fiecare element în `response.json()`:
+
+```py
+def get_comments(issue_number):
+ url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+ response = requests.get(url, headers=headers)
+ return [r["body"] for r in response.json()]
+
+
+# Testăm dacă funcția lucrează cum ne dorim
+get_comments(2792)
+```
+
+```python out
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+```
+
+Arată bine. Acum hai să folosim `Dataset.map()` pentru a adăuga noi coloane `comments` fiecărui issue în datasetul nostru:
+
+```py
+# Depending on your internet connection, this can take a few minutes...
+issues_with_comments_dataset = issues_dataset.map(
+ lambda x: {"comments": get_comments(x["number"])}
+)
+```
+
+Ultimul pas este să facem push datasetului nostru pe Hub. Să vedem cum putem face asta.
+
+## Încărcarea datasetului pe Hugging Face Hub[[uploading-the-dataset-to-the-hugging-face-hub]]
+
+
+
+ +
+
+
+2. Citiți [ghidul 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) despre crearea de dataset cards informative și utilizați-l ca șablon.
+
+Puteți crea fișierul *README.md* direct pe Hub și puteți găsi un template pentru dataset card în repositoriul `lewtun/github-issues`. Un screenshot a dataset card completată este afișată mai jos.
+
+
+
+ +
+
+
+
+
+ +
+ +
+
+
+## Încărcarea și pregătirea datasetului[[loading-and-preparing-the-dataset]]
+
+Prima lucru pe care trebuie să îl facem este să descărcăm datasetul nostru cu GitHub issues, așa că folosim funcția `load_dataset()` ca de obicei:
+
+```py
+from datasets import load_dataset
+
+issues_dataset = load_dataset("lewtun/github-issues", split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
+Aici am specificat splitul default `train` în `load_dataset()`, astfel încât returnează un `Dataset` în loc de `DatasetDict`. Primul lucru care treubuie făcut este să filtrăm pull requesturile, deoarece acestea rareori tind să fie utilizate pentru a răspunde la întrebările utilizatorilor și vor introduce noise în motorul nostru de căutare. Așa cum ar trebuie deja să știți, putem utiliza funcția `Dataset.filter()` pentru a exclude aceste rânduri din datasetul nostru. În timp ce suntem aici, putem să filtrăm și rândurile fără comentari, deoarece acestea nu oferă niciun răspuns la întrebările utilizatorilor:
+
+```py
+issues_dataset = issues_dataset.filter(
+ lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
+)
+issues_dataset
+```
+
+```python out
+Dataset({
+ caracteristici: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 771
+})
+```
+
+Putem vedea că există multe coloane în datasetul nostru, majoritatea dintre care nu sunt necesare pentru a construi motorul nostru de căutare. Din perspectiva căutării, cele mai informative coloane sunt `title`, `body` și `comments`, în timp ce `html_url` ne oferă un link înapoi la problema sursă. Hai să utilizăm funcția `Dataset.remove_columns()` pentru a elimina restul:
+
+```py
+columns = issues_dataset.column_names
+columns_to_keep = ["title", "body", "html_url", "comments"]
+columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
+issues_dataset = issues_dataset.remove_columns(columns_to_remove)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 771
+})
+```
+
+Pentru a crea embeddedurile noastre, vom completa fiecare comentariu cu titlul și body-ul problemei, deoarece aceste câmpuri adesea includ informații contextuale utile. Deoarece coloana noastră `comments` este în prezent o listă de comentarii pentru fiecare issue, trebuie să "explodăm" coloana, astfel încât fiecare rând să fie format dintr-un tuple `(html_url, title, body, comment)`. În Pandas, putem face acest lucru cu funcția [`DataFrame.explode()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), care creează un rând nou pentru fiecare element dintr-o coloană asemănătoare cu o listă, în timp ce copiază toate celelalte valori ale coloanelor. Pentru a vedea acest lucru în acțiune, să trecem la formatul pandas `DataFrame` mai întâi:
+
+```py
+issues_dataset.set_format("pandas")
+df = issues_dataset[:]
+```
+
+Dacă inspectăm primul rând din acest `DataFrame`, putem vedea că există patru comentarii asociate acestei probleme:
+
+```py
+df["comments"][0].tolist()
+```
+
+```python out
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+ 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
+```
+
+Când facem explode `df`, ne așteptăm să obținem un rând pentru fiecare dintre aceste comentarii. Haideți să verificăm dacă ăsta e cazul:
+
+```py
+comments_df = df.explode("comments", ignore_index=True)
+comments_df.head(4)
+```
+
+
+
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
dataset.shuffle().select(range(50))",
+ explain: "Corect! Așa cum ați văzut în acest capitol, mai întâi faceți shuffle datasetului și apoi selectați exemplele din el.",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "Acest lucru este incorect -- deși codul va rula, va amesteca doar primele 50 de elemente din setul de date."
+ }
+ ]}
+/>
+
+### 3. Presupunem că aveți un set de date despre animale de companie numit `pets_dataset`, care are o coloană `name` care denotă numele fiecărui animal de companie. Care dintre următoarele abordări v-ar permite să filtrați setul de date pentru toate animalele de companie ale căror nume încep cu litera "L"?
+
+pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "Acest lucru este incorect -- o funcție lambda are forma generală lambda *arguments* : *expression*, deci trebuie să furnizați argumente în acest caz."
+ },
+ {
+ text: "Creați o funcție ca def filter_names(x): return x['name'].startswith('L') și rulați pets_dataset.filter(filter_names).",
+ explain: "Corect! La fel ca și cu Dataset.map(), puteți trece funcții explicite la Dataset.filter(). Acest lucru este util atunci când aveți o logică complexă care nu este potrivită pentru o funcție lambda. Care dintre celelalte soluții ar mai funcționa?",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Ce este memory mapping?
+
+IterableDataset este un generator, nu un container, deci ar trebui să accesați elementele sale utilizând next(iter(dataset)).",
+ correct: true
+ },
+ {
+ text: "Datasetul allocine nu are o un split train.",
+ explain: "Acest lucru este incorect -- consultați cardul datasetului allocine de pe Hub pentru a vedea ce splituri conține."
+ }
+ ]}
+/>
+
+### 7. Care sunt principalele beneficii ale creării unui dataset card?
+
+