Replies: 12 comments 9 replies
-
|
their code is here https://github.com/abertsch72/unlimiformer |
Beta Was this translation helpful? Give feedback.
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
It mentions this paper: https://openreview.net/forum?id=TrjbxzRcnf- They put the lookup on only one layer and there are some parameters also that need training. |
Beta Was this translation helpful? Give feedback.
-
|
I see the paper 4.2 EXPERIMENTAL METHOD We used a 12-layer decoder-only transformer (with and without Transformer-XL cache) with an embedding size of 1024, 8 attention heads of dimension 128, and an FFN hidden layer of size 4096. For all of our experiments, we used k = 32. Unless specified otherwise, we use the 9th layer as the kNN augmented attention layer. We used a sentence-piece (Kudo & Richardson, 2018) tokenizer with a vocabulary size of 32K. So that should also work with llama. |
Beta Was this translation helpful? Give feedback.
-
|
Looks interesting - we should probably make a PoC Does anyone understand if the kNN works per-token or per-context or something in-between?
For example, let's assume a LLaMA model with 2048 context size. |
Beta Was this translation helpful? Give feedback.
-
|
It is more like there are 32 KV caches and you select the closest one. This is what Wu describes. Unlimiformer:
Then they say their version is more efficient because they are doing the lookup per attention head
So that means they operate with the attention head vector |
Beta Was this translation helpful? Give feedback.
-
|
The author mentioned in Github issue Question about decoder models #2
transformer blog
also
|
Beta Was this translation helpful? Give feedback.
-
|
Although the model was trained with a sequence length of 2048, ALiBi enables users to increase the maximum sequence length during finetuning and/or inference. For example: I saw mpt-7b mention that AliBi, any clue of it? |
Beta Was this translation helpful? Give feedback.
-
|
It requires the model be trained with it from the beginning. Probably not useful for LLaMa. Unlimiformer uses an external memory, but I have doubts how it would work in LLaMa as well since it stores and retrieves the encoder hidden vector in the datastore, but LLaMa is decoder-only. |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
I see #1348, wondering if that architecture could be hacked? |
Beta Was this translation helpful? Give feedback.
-
|
I think we could integrate an knn index in llama.cpp by modifing the K and V matrices in eval_internal: Q shape To enhance this with an knn index we could insert K,V pairs, as calculated above, in the index. For example when they get pushed out of n_ctx. Note that K is roped.. This makes things a bit ambiguous... for which position in context window (each resulting in different rope) should it be inserted? Maybe for all? Seems wasteful, maybe some regular samples over context length. For example roped at positions Then we modify K and V in one or more layers. Augment K and V by concatinating K_knn and V_knn before K_knn: Then proceed with KQV as in original code. The whole KQV setup as above is in itself some kind of K,V database. Make big K_index tensor of shape Insert new K,V vector pairs by writing into key rows and value columns at current size and increase size by one. For each key row, track some statistics about usage of the entries so we have some data to decide which to replace when the index is full. To query the index: Computing K_indexQ results in a big matrix multiplication when evaluating a lot of new tokens at once, in this case this can will be a bottleneck. But when only generating a single token each time (N = 1) it should be ok. |
Beta Was this translation helpful? Give feedback.
-
|
That is pretty impressive. But do you think if this should come under scope
of this repo ?
You could already use something like Langchain or Vector search engine in
front of Llama.cpp to achieve this.
…On Sat, 20 May 2023 at 9:53 PM, xaedes ***@***.***> wrote:
I think we could integrate an knn index in llama.cpp by modifing the K and
V matrices in eval_internal:
https://github.com/ggerganov/llama.cpp/blob/b8ee340abe4a46143eb8cc4a135b976856c9136c/llama.cpp#L1260-L1305
Q shape [n_embd/n_head, N, n_head] is the roped query for each new token
that we also use to query the knn index.
K shape [n_embd/n_head, n_past + N, n_head] are the roped keys for all
tokens that are also used as keys to insert in the knn index.
KQ shape [n_past + N, N, n_head] measures how strongly each token key
correlates with each query with dot(key_row, query_row).
V shape [n_past + N, n_embd/n_head, n_head] are the values for each
token, each column corresponding to a key row.
KQV shape [n_embd/n_head, N, n_head] is the result for each new token of
the query lookup Q in the K,V 'database', by activating the values based on
KQ.
To enhance this with an knn index we could insert K,V pairs, as calculated
above, in the index. For example when they get pushed out of n_ctx.
Note that K is roped.. This makes things a bit ambiguous... for which
position in context window (each resulting in different rope) should it be
inserted? Maybe for all? Seems wasteful, maybe some regular samples over
context length. For example roped at positions [0, n_ctx*1/4, n_ctx*2/4,
n_ctx*3/4]
Then we modify K and V in one or more layers.
Lookup n_knn items for the queries Q. Note that there are many queries.
This returns K_knn,V_knn from the knn index.
These are tensors of shape K_knn [n_embd/n_head, n_knn] and V_knn [n_knn,
n_embd/n_head].
Augment K and V by concatinating K_knn and V_knn before K_knn:
K := concat(K_knn, K, axis=1) resulting in shape [n_embd/n_head, n_knn +
n_past + N, n_head]
V := concat(V_knn, V, axis=0) resulting in shape [n_knn + n_past + N,
n_embd/n_head, n_head]
Then proceed with KQV as in original code.
------------------------------
The whole KQV setup as above is in itself some kind of K,V database.
So maybe we could use similar for simulating a knn_index in a
proof-of-concept without external dependencies.
Something like this:
Make big K_index tensor of shape [n_embd/n_head, n_index].
Make big V_index tensor of shape [n_index, n_embd/n_head].
Insert new K,V vector pairs by writing into key rows and value columns at
current size and increase size by one.
For each key row, track some statistics about usage of the entries so we
have some data to decide which to replace when the index is full.
To query the index:
Compute K_indexQ = K_index*Q with shape [n_index, N, n_head]
Sum or max columns of K_indexQ to measure how active each index entry is.
Resulting in shape [n_index, 1, n_head]
Sort by index activity to select top n_knn corresponding rows of K and
columns of V.
Update usage statistics.
Resulting in K_knn of shape [n_embd/n_head, n_knn, n_head] and V_knn of
shape [n_knn, n_embd/n_head, n_head]
Computing K_indexQ results in a big matrix multiplication when evaluating
a lot of new tokens at once, in this case this can will be a bottleneck.
But when only generating a single token each time (N = 1) it should be ok.
—
Reply to this email directly, view it on GitHub
<#1357 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAXGU4AVTLCEVMHJYIUOTPLXHDVZNANCNFSM6AAAAAAXZCFDXI>
.
You are receiving this because you are subscribed to this thread.Message
ID: ***@***.***
com>
|
Beta Was this translation helpful? Give feedback.
-
|
Transformer also can use cpu, and doesn't matter us to choose ggml. |
Beta Was this translation helpful? Give feedback.
-
|
Maybe a small llm can use to locate the tensors in the right place so extend the context length? |
Beta Was this translation helpful? Give feedback.
-
|
I have been developing unconventional transformer platforms using segmentation logic for large contexts and low processing. |
Beta Was this translation helpful? Give feedback.
-
|
I believe that the use of recurrence with a module application manages to propagate the characteristics of the data through simple operations, in the same way that addler32 is not used because it has a vulnerability, this vulnerability, if exploited, can add similar items as I have been researching, especially when used as a sublayer, it can normalize quickly when converted back into an embbed from a token generated from a dimension. This has no lines of research, and I believe it has a lot to use, at least I have used it quite often, and it has replaced with much better results, all types of normalization, not to mention the speed of convergence |
Beta Was this translation helpful? Give feedback.
-
|
in the last months I have been working with the creation of autonomous learning methods. one that is working very well is a different way of structuring the data. |
Beta Was this translation helpful? Give feedback.
-
|
I just noticed this discussion, and wanted to point out that Unlimiformer as of recently supports Llama-2 natively, so if any implementation details were unclear before, there's functional reference now. |
Beta Was this translation helpful? Give feedback.
-
|
https://github.com/abertsch72/unlimiformer They just added support! |
Beta Was this translation helpful? Give feedback.
-
|
(support for llama2) |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
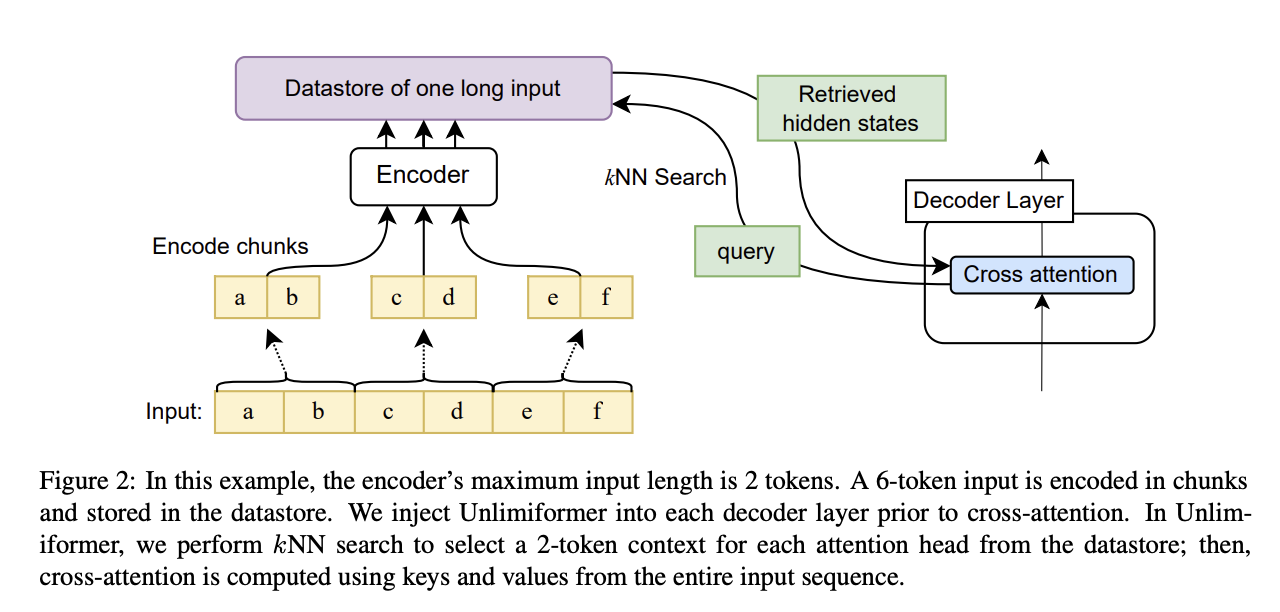
From the paper "Unlimiformer: Long-Range Transformers with Unlimited Length Input"
This probably trades away some quality of the generation, but unlimited length input sounds fantastic. No training required and can work with any pretrained model.
Would be nice to have for llama! Biggest hurdle would probably be the knn index.
Beta Was this translation helpful? Give feedback.
All reactions