


[arXiv] [HuggingFace] [X]
This repository is for our paper:
Efficient Reasoning Models: A Survey
Sicheng Feng1,2, Gongfan Fang1, Xinyin Ma1, Xinchao Wang1,*
1National University of Singapore, Singapore
2Nankai University, Tianjin, China
∗Corresponding author: xinchao@nus.edu.sg
🙋 Please let us know if you find out a mistake or have any suggestions!
🌟 If you find this resource helpful, please consider to star this repository and cite our research!

- 2025-05-24: 🚀 We present a fine-grained visual reasoning benchmark - ReasonMap!
- 2025-05-18: 🎉 We open a new section about efficient multimodal reasoning methods!
- 2025-05-16: 🎉 Two-month milestone! Special thanks to VainF, horseee, CHEN1594, ZhenyuSun-Walker, xianzuwu!
- 2025-04-16: 📝 The survey is now available on arXiv!
- 2025-04-11: 📚 The full paper list is now available, and our survey is coming soon!
- 2025-03-16: 🚀 Efficient Reasoning Repo launched!
Contributions
If you want to add your paper or update details like conference info or code URLs, please submit a pull request. You can generate the necessary markdown for each paper by filling out
generate_item.pyand runningpython generate_item.py. We greatly appreciate your contributions. Alternatively, you can email me (Gmail) the links to your paper and code, and I will add your paper to the list as soon as possible.

- Make Long CoT Short
- Build SLM with Strong Reasoning Ability
- Let Decoding More Efficient
- Efficient Multimodal Reasoning
- Evaluation and Benchmarks
- Background Papers
- Competition
























































































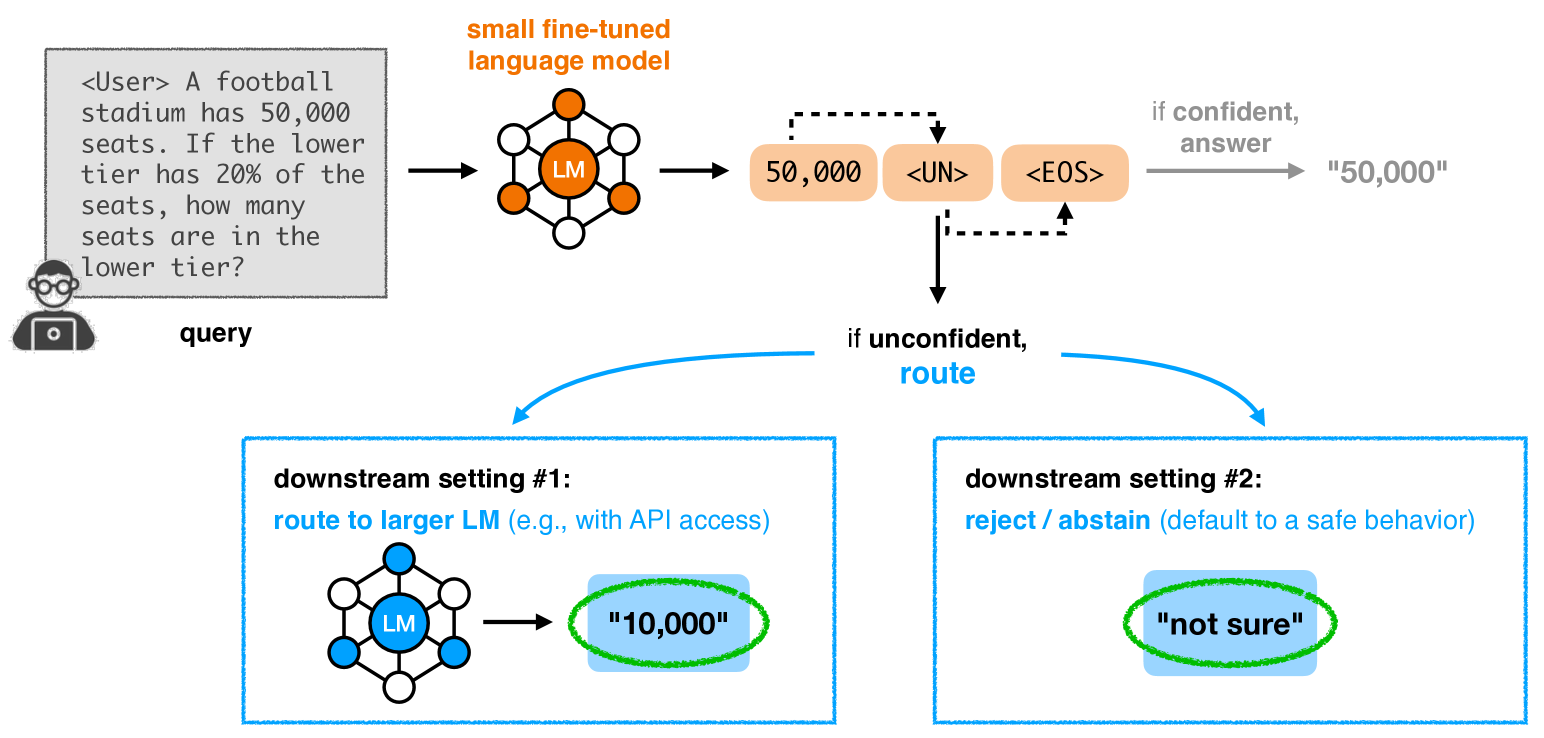

- Claude 3.7 Sonnet. Claude team. [Paper]
| Title & Authors | Introduction | Links |
|---|---|---|
| LLMs are Single-threaded Reasoners: Demystifying the Working Mechanism of Soft Thinking Chünhung Wu, Jinliang Lu, Zixuan Ren, Gangqiang Hu, Zhi Wu, Dai Dai, Hua Wu |
 |
Paper |
| CTRLS: Chain-of-Thought Reasoning via Latent State-Transition Junda Wu, Yuxin Xiong, Xintong Li, Zhengmian Hu, Tong Yu, Rui Wang, Xiang Chen, Jingbo Shang, Julian McAuley |
 |
Paper |
 Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer Wenquan Lu, Yuechuan Yang, Kyle Lee, Yanshu Li, Enqi Liu |
 |
Github Paper |
 Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, Chuang Gan |
 |
Github Paper |
 Parallel Continuous Chain-of-Thought with Jacobi Iteration Haoyi Wu, Zhihao Teng, Kewei Tu |
 |
Github Paper |
| DART: Distilling Autoregressive Reasoning to Silent Thought Nan Jiang, Ziming Wu, De-Chuan Zhan, Fuming Lai, Shaobing Lian |
 |
Paper |
| System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts Xiaoqiang Wang, Suyuchen Wang, Yun Zhu, Bang Liu |
 |
Paper |
| Hybrid Latent Reasoning via Reinforcement Learning Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, Dong Wang |
 |
Paper |
| SCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought Guanghao Li,Wenhao Jiang,Mingfeng Chen,Yan Li,Hao Yu,Shuting Dong,Tao Ren,Ming Tang,Chun Yuan |
 |
Paper |
| Continuous Chain of Thought Enables Parallel Exploration and Reasoning Halil Alperen Gozeten,M. Emrullah Ildiz,Xuechen Zhang,Hrayr Harutyunyan,Ankit Singh Rawat,Samet Oymak |
 |
Paper |
 Efficient Reasoning via Chain of Unconscious Thought Ruihan Gong, Yue Liu, Wenjie Qu, Mingzhe Du, Yufei He, Yingwei Ma, Yulin Chen, Xiang Liu, Yi Wen, Xinfeng Li, Ruidong Wang, Xinzhong Zhu, Bryan Hooi, Jiaheng Zhang |
 |
Github Paper |
 Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Hanlin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, Xiaoyu Shen |
 |
Github Paper |
 Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Jian Luan, Ruihua Song |
 |
Github Paper |
 Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, Shuohang Wang, Yelong Shen, Xin Eric Wang |
 |
Github Paper |
| Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models Zihao Li, Xu Wang, Yuzhe Yang, Ziyu Yao, Haoyi Xiong, Mengnan Du |
 |
Paper |
| Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space Hengli Li, Chenxi Li, Tong Wu, Xuekai Zhu, Yuxuan Wang, Zhaoxin Yu, Eric Hanchen Jiang, Song-Chun Zhu, Zixia Jia, Ying Nian Wu, Zilong Zheng |
 |
Paper |
| Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, Yuandong Tian |
 |
Paper |
 SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning Yige Xu, Xu Guo, Zhiwei Zeng, Chunyan Miao |
 |
Github Paper |
| Beyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in Large Language Models Thilo Hagendorff, Sarah Fabi |
 |
Paper |
| Distilling System 2 into System 1 Ping Yu, Jing Xu, Jason Weston, Ilia Kulikov |
 |
Paper |
 Implicit Chain of Thought Reasoning via Knowledge Distillation Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, Stuart Shieber |
 |
Github Paper |
 Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models Jiacheng Ye, Shansan Gong, Liheng Chen, Lin Zheng, Jiahui Gao, Han Shi, Chuan Wu, Xin Jiang, Zhenguo Li, Wei Bi, Lingpeng Kong |
 |
Github Paper |
 From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step Yuntian Deng, Yejin Choi, Stuart Shieber |
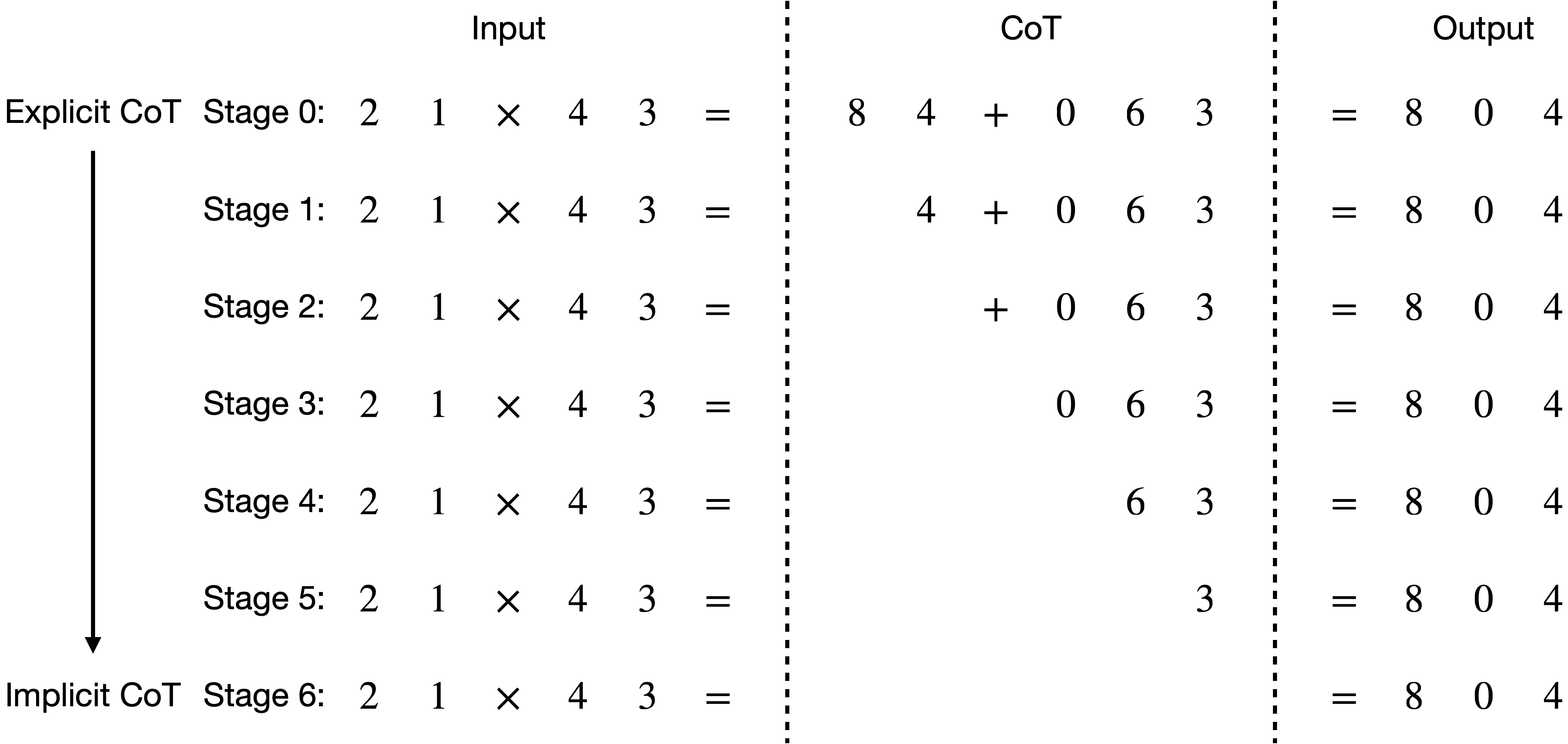 |
Github Paper |
| Compressed Chain of Thought: Efficient Reasoning Through Dense Representations Jeffrey Cheng, Benjamin Van Durme |
 |
Paper |
| SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs Yige Xu, Xu Guo, Zhiwei Zeng, Chunyan Miao |
 |
Paper |
Reasoning with Latent Thoughts: On the Power of Looped Transformers Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, Sashank J. Reddi |
 |
Paper |
 Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning Qifan Yu, Zhenyu He, Sijie Li, Xun Zhou, Jun Zhang, Jingjing Xu, Di He |
 |
Github Paper |
| CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, Yulan He |
 |
Paper |
 LightThinker: Thinking Step-by-Step Compression Jintian Zhang, Yuqi Zhu, Mengshu Sun, Yujie Luo, Shuofei Qiao, Lun Du, Da Zheng, Huajun Chen, Ningyu Zhang |
 |
Github Paper |
 Guiding Language Model Reasoning with Planning Tokens Xinyi Wang, Lucas Caccia, Oleksiy Ostapenko, Xingdi Yuan, William Yang Wang, Alessandro Sordoni |
 |
Github Paper |
 Let's Think Dot by Dot: Hidden Computation in Transformer Language Models Jacob Pfau, William Merrill, Samuel R. Bowman |
 |
Github Paper |
 Disentangling Memory and Reasoning Ability in Large Language Models Mingyu Jin, Weidi Luo, Sitao Cheng, Xinyi Wang, Wenyue Hua, Ruixiang Tang, William Yang Wang, Yongfeng Zhang |
 |
Github Paper |
| Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, Qinqing Zheng |
 |
Paper |
| Training Large Language Models to Reason in a Continuous Latent Space Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian |
 |
Paper |
 Efficient Reasoning with Hidden Thinking Xuan Shen, Yizhou Wang, Xiangxi Shi, Yanzhi Wang, Pu Zhao, Jiuxiang Gu |
 |
Github Paper |
Think before you speak: Training Language Models With Pause Tokens Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan |
 |
Paper |
 Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Tom Goldstein |
 |
Github Paper |
| Weight-of-Thought Reasoning: Exploring Neural Network Weights for Enhanced LLM Reasoning Saif Punjwani, Larry Heck |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi Xu, Wei Chu, Yuan Qi |
 |
Paper |
| Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster Xiao Chen, Sihang Zhou, Ke Liang, Xiaoyu Sun, Xinwang Liu |
 |
Paper |
| Llama-Nemotron: Efficient Reasoning Models NVIDIA |
 |
Paper |
| Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math Haoran Xu, Baolin Peng, Hany Awadalla, Dongdong Chen, Yen-Chun Chen, Mei Gao, Young Jin Kim, Yunsheng Li, Liliang Ren, Yelong Shen, Shuohang Wang, Weijian Xu, Jianfeng Gao, Weizhu Chen |
 |
Paper |
| Phi-4-reasoning Technical Report Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, Piero Kauffmann, Yash Lara, Caio César Teodoro Mendes, Arindam Mitra, Besmira Nushi, Dimitris Papailiopoulos, Olli Saarikivi, Shital Shah, Vaishnavi Shrivastava, Vibhav Vineet, Yue Wu, Safoora Yousefi, Guoqing Zheng |
 |
Paper |
Teaching Small Language Models to Reason Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, Aliaksei Severyn |
 |
Paper |
Mixed Distillation Helps Smaller Language Model Better Reasoning Chenglin Li, Qianglong Chen, Liangyue Li, Caiyu Wang, Yicheng Li, Zulong Chen, Yin Zhang |
 |
Paper |
 Small Models Struggle to Learn from Strong Reasoners Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ramasubramanian, Radha Poovendran |
 |
Github Paper |
 Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Bin Sun, Xinglin Wang, Heda Wang, Kan Li |
 |
Github Paper |
Teaching Small Language Models Reasoning through Counterfactual Distillation Tao Feng, Yicheng Li, Li Chenglin, Hao Chen, Fei Yu, Yin Zhang |
 |
Paper |
| Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation Yijia Luo, Yulin Song, Xingyao Zhang, Jiaheng Liu, Weixun Wang, GengRu Chen, Wenbo Su, Bo Zheng |
 |
Paper |
 Small Language Models Need Strong Verifiers to Self-Correct Reasoning Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang |
 |
Github Paper |
| Improving Mathematical Reasoning Capabilities of Small Language Models via Feedback-Driven Distillation Xunyu Zhu, Jian Li, Can Ma, Weiping Wang |
 |
Paper |
 SKIntern : Internalizing Symbolic Knowledge for Distilling Better CoT Capabilities into Small Language Models Huanxuan Liao, Shizhu He, Yupu Hao, Xiang Li, Yuanzhe Zhang, Jun Zhao, Kang Liu |
 |
Github Paper |
Probe then Retrieve and Reason: Distilling Probing and Reasoning Capabilities into Smaller Language Models Yichun Zhao, Shuheng Zhou, Huijia Zhu |
 |
Paper |
| Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners Daniele Paliotta, Junxiong Wang, Matteo Pagliardini, Kevin Y. Li, Aviv Bick, J. Zico Kolter, Albert Gu, François Fleuret, Tri Dao |
 |
Paper |
| Distilling Reasoning Ability from Large Language Models with Adaptive Thinking Xiaoshu Chen, Sihang Zhou, Ke Liang, Xinwang Liu |
 |
Paper |
 Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning Xinghao Chen, Zhijing Sun, Wenjin Guo, Miaoran Zhang, Yanjun Chen, Yirong Sun, Hui Su, Yijie Pan, Dietrich Klakow, Wenjie Li, Xiaoyu Shen |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Towards Reasoning Ability of Small Language Models Gaurav Srivastava, Shuxiang Cao, Xuan Wang |
 |
Paper |
 Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models Ruikang Liu, Yuxuan Sun, Manyi Zhang, Haoli Bai, Xianzhi Yu, Tiezheng Yu, Chun Yuan, Lu Hou |
 |
Github Paper |
| When Reasoning Meets Compression: Benchmarking Compressed Large Reasoning Models on Complex Reasoning Tasks Nan Zhang, Yusen Zhang, Prasenjit Mitra, Rui Zhang |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Replacing thinking with tool usage enables reasoning in small language models Corrado Rainone, Tim Bakker, Roland Memisevic |
 |
Paper |
| Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi Xu, Wei Chu, Yuan Qi |
|
Paper |
| Llama-Nemotron: Efficient Reasoning Models NVIDIA |
|
Paper |
| Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math Haoran Xu, Baolin Peng, Hany Awadalla, Dongdong Chen, Yen-Chun Chen, Mei Gao, Young Jin Kim, Yunsheng Li, Liliang Ren, Yelong Shen, Shuohang Wang, Weijian Xu, Jianfeng Gao, Weizhu Chen |
|
Paper |
| Phi-4-reasoning Technical Report Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, Piero Kauffmann, Yash Lara, Caio César Teodoro Mendes, Arindam Mitra, Besmira Nushi, Dimitris Papailiopoulos, Olli Saarikivi, Shital Shah, Vaishnavi Shrivastava, Vibhav Vineet, Yue Wu, Safoora Yousefi, Guoqing Zheng |
|
Paper |
 Tina: Tiny Reasoning Models via LoRA Shangshang Wang, Julian Asilis, Ömer Faruk Akgül, Enes Burak Bilgin, Ollie Liu, Willie Neiswanger |
 |
Github Paper |
 Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't Quy-Anh Dang, Chris Ngo |
 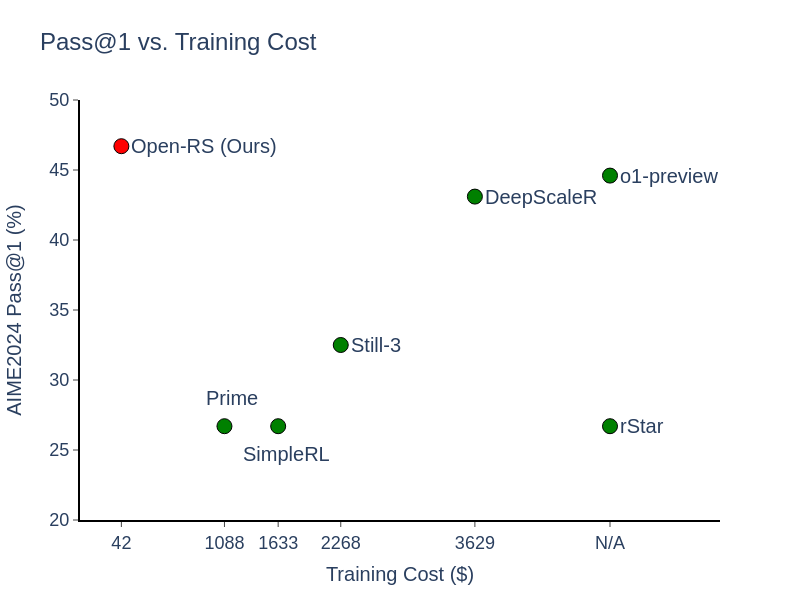 |
Github Paper |
 SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, Junxian He |
 |
Github Paper |
- DeepScaleR. DeepScaleR team. Webpage
| Title & Authors | Introduction | Links |
|---|---|---|
| Inference-Time Hyper-Scaling with KV Cache Compression Adrian Łańcucki, Konrad Staniszewski, Piotr Nawrot, Edoardo M. Ponti |
 |
Paper |
| Control-R: Towards controllable test-time scaling Di Zhang, Weida Wang, Junxian Li, Xunzhi Wang, Jiatong Li, Jianbo Wu, Jingdi Lei, Haonan He, Peng Ye, Shufei Zhang, Wanli Ouyang, Yuqiang Li, Dongzhan Zhou |
 |
Paper |
| Plan and Budget: Effective and Efficient Test-Time Scaling on Large Language Model Reasoning Junhong Lin, Xinyue Zeng, Jie Zhu, Song Wang, Julian Shun, Jun Wu, Dawei Zhou |
 |
Paper |
| First Finish Search: Efficient Test-Time Scaling in Large Language Models Aradhye Agarwal, Ayan Sengupta, Tanmoy Chakraborty |
 |
Paper |
| LIMOPro: Reasoning Refinement for Efficient and Effective Test-time Scaling Yang Xiao, Jiashuo Wang, Ruifeng Yuan, Chunpu Xu, Kaishuai Xu, Wenjie Li, Pengfei Liu |
 |
Paper |
| Guided by Gut: Efficient Test-Time Scaling with Reinforced Intrinsic Confidence Amirhosein Ghasemabadi, Keith G. Mills, Baochun Li, Di Niu |
 |
Paper |
| Let Me Think! A Long Chain-of-Thought Can Be Worth Exponentially Many Short Ones Parsa Mirtaheri, Ezra Edelman, Samy Jelassi, Eran Malach, Enric Boix-Adsera |
 |
Paper |
| Don't Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning Michael Hassid, Gabriel Synnaeve, Yossi Adi, Roy Schwartz |
 |
Paper |
 Value-Guided Search for Efficient Chain-of-Thought Reasoning Kaiwen Wang, Jin Peng Zhou, Jonathan Chang, Zhaolin Gao, Nathan Kallus, Kianté Brantley, Wen Sun |
 |
Github Paper |
| Accelerated Test-Time Scaling with Model-Free Speculative Sampling Woomin Song, Saket Dingliwal, Sai Muralidhar Jayanthi, Bhavana Ganesh, Jinwoo Shin, Aram Galstyan, Sravan Babu Bodapati |
 |
Paper |
| Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision Eric Hanchen Jiang, Haozheng Luo, Shengyuan Pang, Xiaomin Li, Zhenting Qi, Hengli Li, Cheng-Fu Yang, Zongyu Lin, Xinfeng Li, Hao Xu, Kai-Wei Chang, Ying Nian Wu |
 |
Paper |
| Rethinking Optimal Verification Granularity for Compute-Efficient Test-Time Scaling Hao Mark Chen, Guanxi Lu, Yasuyuki Okoshi, Zhiwen Mo, Masato Motomura, Hongxiang Fan |
 |
Paper |
| Reward Reasoning Model Jiaxin Guo, Zewen Chi, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, Furu Wei |
 |
Paper |
| Fractured Chain-of-Thought Reasoning Baohao Liao, Hanze Dong, Yuhui Xu, Doyen Sahoo, Christof Monz, Junnan Li, Caiming Xiong |
 |
Paper |
| Thinking Short and Right Over Thinking Long: Serving LLM Reasoning Efficiently and Accurately Yuhang Wang, Youhe Jiang, Bin Cui, Fangcheng Fu |
 |
Paper |
| Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers Kusha Sareen, Morgane M Moss, Alessandro Sordoni, Rishabh Agarwal, Arian Hosseini |
 |
Paper |
| Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods Junlin Wang, Shang Zhu, Jon Saad-Falcon, Ben Athiwaratkun, Qingyang Wu, Jue Wang, Shuaiwen Leon Song, Ce Zhang, Bhuwan Dhingra, James Zou |
 |
Paper |
 xVerify: Efficient Answer Verifier for Reasoning Model Evaluations Ding Chen, Qingchen Yu, Pengyuan Wang, Wentao Zhang, Bo Tang, Feiyu Xiong, Xinchi Li, Minchuan Yang, Zhiyu Li |
 |
Github Paper |
 Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs Pranjal Aggarwal, Aman Madaan, Yiming Yang, Mausam |
 |
Github Paper |
 Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, Kan Li |
 |
Github Paper |
 Make Every Penny Count: Difficulty-Adaptive Self-Consistency for Cost-Efficient Reasoning Xinglin Wang, Shaoxiong Feng, Yiwei Li, Peiwen Yuan, Yueqi Zhang, Chuyi Tan, Boyuan Pan, Yao Hu, Kan Li |
 |
Github Paper |
| Path-Consistency: Prefix Enhancement for Efficient Inference in LLM Jiace Zhu, Yingtao Shen, Jie Zhao, An Zou |
 |
Paper |
| Bridging Internal Probability and Self-Consistency for Effective and Efficient LLM Reasoning Zhi Zhou, Tan Yuhao, Zenan Li, Yuan Yao, Lan-Zhe Guo, Xiaoxing Ma, Yu-Feng Li |
 |
Paper |
| Confidence Improves Self-Consistency in LLMs Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, Gal Yona |
 |
Paper |
 Efficient Test-Time Scaling via Self-Calibration Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, Jiaxin Huang |
 |
Github Paper |
 Fast Best-of-N Decoding via Speculative Rejection Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter Bartlett, Andrea Zanette |
 |
Github Paper |
| Sampling-Efficient Test-Time Scaling: Self-Estimating the Best-of-N Sampling in Early Decoding Yiming Wang, Pei Zhang, Siyuan Huang, Baosong Yang, Zhuosheng Zhang, Fei Huang, Rui Wang |
 |
Paper |
| FastMCTS: A Simple Sampling Strategy for Data Synthesis Peiji Li, Kai Lv, Yunfan Shao, Yichuan Ma, Linyang Li, Xiaoqing Zheng, Xipeng Qiu, Qipeng Guo |
 |
Paper |
 Non-myopic Generation of Language Models for Reasoning and Planning Chang Ma, Haiteng Zhao, Junlei Zhang, Junxian He, Lingpeng Kong |
 |
Github Paper |
 Language Models can Self-Improve at State-Value Estimation for Better Search Ethan Mendes, Alan Ritter |
 |
Github Paper |
 ϕ-Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation Fangzhi Xu, Hang Yan, Chang Ma, Haiteng Zhao, Jun Liu, Qika Lin, Zhiyong Wu |
 |
Github Paper |
| Dynamic Parallel Tree Search for Efficient LLM Reasoning Yifu Ding, Wentao Jiang, Shunyu Liu, Yongcheng Jing, Jinyang Guo, Yingjie Wang, Jing Zhang, Zengmao Wang, Ziwei Liu, Bo Du, Xianglong Liu, Dacheng Tao |
 |
Paper |
 Don't Get Lost in the Trees: Streamlining LLM Reasoning by Overcoming Tree Search Exploration Pitfalls Ante Wang, Linfeng Song, Ye Tian, Dian Yu, Haitao Mi, Xiangyu Duan, Zhaopeng Tu, Jinsong Su, Dong Yu |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 Activation Steering for Chain-of-Thought Compression Seyedarmin Azizi, Erfan Baghaei Potraghloo, Massoud Pedram |
 |
Github Paper |
| Scaling Speculative Decoding with Lookahead Reasoning Yichao Fu, Rui Ge, Zelei Shao, Zhijie Deng, Hao Zhang |
 |
Paper |
| Wait, We Don't Need to 'Wait'! Removing Thinking Tokens Improves Reasoning Efficiency Chenlong Wang, Yuanning Feng, Dongping Chen, Zhaoyang Chu, Ranjay Krishna, Tianyi Zhou |
 |
Paper |
| Steering LLM Thinking with Budget Guidance Junyan Li, Wenshuo Zhao, Yang Zhang, Chuang Gan |
 |
Paper |
 SeerAttention-R: Sparse Attention Adaptation for Long Reasoning Yizhao Gao, Shuming Guo, Shijie Cao, Yuqing Xia, Yu Cheng, Lei Wang, Lingxiao Ma, Yutao Sun, Tianzhu Ye, Li Dong, Hayden Kwok-Hay So, Yu Hua, Ting Cao, Fan Yang, Mao Yang |
 |
Github Paper |
| Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs Roy Eisenstadt, Itamar Zimerman, Lior Wolf |
 |
Paper |
 Token Signature: Predicting Chain-of-Thought Gains with Token Decoding Feature in Large Language Models Peijie Liu, Fengli Xu, Yong Li |
 |
Github Paper |
 AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time Junyu Zhang, Runpei Dong, Han Wang, Xuying Ning, Haoran Geng, Peihao Li, Xialin He, Yutong Bai, Jitendra Malik, Saurabh Gupta, Huan Zhang |
 |
Github Paper |
| ProxyThinker: Test-Time Guidance through Small Visual Reasoners Zilin Xiao,Jaywon Koo,Siru Ouyang,Jefferson Hernandez,Yu Meng,Vicente Ordonez |
 |
Paper |
| A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings Xiaoang Xu,Shuo Wang,Xu Han,Zhenghao Liu,Huijia Wu,Peipei Li,Zhiyuan Liu,Maosong Sun,Zhaofeng He |
 |
Paper |
| Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models Zekai Zhao, Qi Liu, Kun Zhou, Zihan Liu, Yifei Shao, Zhiting Hu, Biwei Huang |
 |
Paper |
| Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training Mengru Wang, Xingyu Chen, Yue Wang, Zhiwei He, Jiahao Xu, Tian Liang, Qiuzhi Liu, Yunzhi Yao, Wenxuan Wang, Ruotian Ma, Haitao Mi, Ningyu Zhang, Zhaopeng Tu, Xiaolong Li, Dong Yu |
 |
Paper |
 Reasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning Jiwon Song, Dongwon Jo, Yulhwa Kim, Jae-Joon Kim |
 |
Github Paper |
| RL of Thoughts: Navigating LLM Reasoning with Inference-time Reinforcement Learning Qianyue Hao, Sibo Li, Jian Yuan, Yong Li |
 |
Paper |
| Group Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity Chan-Jan Hsu, Davide Buffelli, Jamie McGowan, Feng-Ting Liao, Yi-Chang Chen, Sattar Vakili, Da-shan Shiu |
 |
Paper |
 Rethinking Repetition Problems of LLMs in Code Generation Yihong Dong, Yuchen Liu, Xue Jiang, Zhi Jin, Ge Li |
 |
Github Paper |
| Accelerating Chain-of-Thought Reasoning: When Goal-Gradient Importance Meets Dynamic Skipping Ren Zhuang, Ben Wang, Shuifa Sun |
 |
Paper |
 Learn to Think: Bootstrapping LLM Reasoning Capability Through Graph Learning Hang Gao, Chenhao Zhang, Tie Wang, Junsuo Zhao, Fengge Wu, Changwen Zheng, Huaping Liu |
 |
Github Paper |
 Beyond the Last Answer: Your Reasoning Trace Uncovers More than You Think Hasan Abed Al Kader Hammoud, Hani Itani, Bernard Ghanem |
 |
Github Paper |
| Trace-of-Thought: Enhanced Arithmetic Problem Solving via Reasoning Distillation From Large to Small Language Models Tyler McDonald, Ali Emami |
 |
Paper |
 Efficient Reasoning for LLMs through Speculative Chain-of-Thought Jikai Wang, Juntao Li, Lijun Wu, Min Zhang |
 |
Github Paper |
| Dynamic Early Exit in Reasoning Models Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, Weiping Wang |
 |
Paper |
 Learning Adaptive Parallel Reasoning with Language Models Jiayi Pan, Xiuyu Li, Long Lian, Charlie Snell, Yifei Zhou, Adam Yala, Trevor Darrell, Kurt Keutzer, Alane Suhr |
 |
Github Paper |
| THOUGHTTERMINATOR: Benchmarking, Calibrating, and Mitigating Overthinking in Reasoning Models Xiao Pu, Michael Saxon, Wenyue Hua, William Yang Wang |
 |
Paper |
 Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation Xuefei Ning, Zinan Lin, Zixuan Zhou, Zifu Wang, Huazhong Yang, Yu Wang |
 |
Github Paper |
| Adaptive Skeleton Graph Decoding Shuowei Jin, Yongji Wu, Haizhong Zheng, Qingzhao Zhang, Matthew Lentz, Z. Morley Mao, Atul Prakash, Feng Qian, Danyang Zhuo |
 |
Paper |
 Reward-Guided Speculative Decoding for Efficient LLM Reasoning Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, Caiming Xiong |
 |
Github Paper |
| Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models Yuan Sui, Yufei He, Tri Cao, Simeng Han, Bryan Hooi |
 |
Paper |
 Atom of Thoughts for Markov LLM Test-Time Scaling Fengwei Teng, Zhaoyang Yu, Quan Shi, Jiayi Zhang, Chenglin Wu, Yuyu Luo |
 |
Github Paper |
| DISC: Dynamic Decomposition Improves LLM Inference Scaling Jonathan Light, Wei Cheng, Wu Yue, Masafumi Oyamada, Mengdi Wang, Santiago Paternain, Haifeng Chen |
 |
Paper |
| From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models Jinyi Liu, Yan Zheng, Rong Cheng, Qiyu Wu, Wei Guo, Fei Ni, Hebin Liang, Yifu Yuan, Hangyu Mao, Fuzheng Zhang, Jianye Hao |
 |
Paper |
 Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models? Kun Xiang, Zhili Liu, Zihao Jiang, Yunshuang Nie, Kaixin Cai, Yiyang Yin, Runhui Huang, Haoxiang Fan, Hanhui Li, Weiran Huang, Yihan Zeng, Yu-Jie Yuan, Jianhua Han, Lanqing Hong, Hang Xu, Xiaodan Liang |
 |
Github Paper |
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters Charlie Snell, Jaehoon Lee, Kelvin Xu, Aviral Kumar |
 |
Paper |
 Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, Yiming Yang |
 |
Github Paper |
 Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning Yuxiao Qu, Matthew Y. R. Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, Aviral Kumar |
 |
Github Paper |
 SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning Rui Pan, Yinwei Dai, Zhihao Zhang, Gabriele Oliaro, Zhihao Jia, Ravi Netravali |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning Shenshen Li, Kaiyuan Deng, Lei Wang, Hao Yang, Chong Peng, Peng Yan, Fumin Shen, Heng Tao Shen, Xing Xu |
 |
Github Paper |
PixelThink: Towards Efficient Chain-of-Pixel Reasoning Song Wang, Gongfan Fang, Lingdong Kong, Xiangtai Li, Jianyun Xu, Sheng Yang, Qiang Li, Jianke Zhu, Xinchao Wang |
 |
Github Paper |
 Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models Jiaqi Wang, Kevin Qinghong Lin, James Cheng, Mike Zheng Shou |
 |
Github Paper |
| MilChat: Introducing Chain of Thought Reasoning and GRPO to a Multimodal Small Language Model for Remote Sensing Aybora Koksal, A. Aydin Alatan |
 |
Paper |
 Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, Jiaqi Wang |
 |
Github Paper |
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models? Kun Xiang, Zhili Liu, Zihao Jiang, Yunshuang Nie, Kaixin Cai, Yiyang Yin, Runhui Huang, Haoxiang Fan, Hanhui Li, Weiran Huang, Yihan Zeng, Yu-Jie Yuan, Jianhua Han, Lanqing Hong, Hang Xu, Xiaodan Liang |
|
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, Hao Li |
 |
Paper |
 Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, Yu Qiao |
 |
Github Paper |
| VGR: Visual Grounded Reasoning Jiacong Wang, Zijian Kang, Haochen Wang, Haiyong Jiang, Jiawen Li, Bohong Wu, Ya Wang, Jiao Ran, Xiao Liang, Chao Feng, Jun Xiao |
 |
Paper |
 Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, Tieniu Tan |
 |
Github Paper |
| Multi-Step Visual Reasoning with Visual Tokens Scaling and Verification Tianyi Bai, Zengjie Hu, Fupeng Sun, Jiantao Qiu, Yizhen Jiang, Guangxin He, Bohan Zeng, Conghui He, Binhang Yuan, Wentao Zhang |
 |
Paper |
| Active-O3: Empowering Multimodal Large Language Models with Active Perception via GRPO Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, Chunhua Shen |
 |
Paper |
| One RL to See Them All: Visual Triple Unified Reinforcement Learning Yan Ma, Linge Du, Xuyang Shen, Shaoxiang Chen, Pengfei Li, Qibing Ren, Lizhuang Ma, Yuchao Dai, Pengfei Liu, Junjie Yan |
 |
Paper |
| MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, Hongsheng Li |
 |
Paper |
| GThinker: Towards General Multimodal Reasoning via Cue-Guided Rethinking Yufei Zhan, Ziheng Wu, Yousong Zhu, Rongkun Xue, Ruipu Luo, Zhenghao Chen, Can Zhang, Yifan Li, Zhentao He, Zheming Yang, Ming Tang, Minghui Qiu, Jinqiao Wang |
 |
Paper |
| Fast or Slow? Integrating Fast Intuition and Deliberate Thinking for Enhancing Visual Question Answering Songtao Jiang, Chenyi Zhou, Yan Zhang, Yeying Jin, Zuozhu Liu |
 |
Paper |
| Grounded Reinforcement Learning for Visual Reasoning Gabriel Sarch,Snigdha Saha,Naitik Khandelwal,Ayush Jain,Michael J. Tarr,Aviral Kumar,Katerina Fragkiadaki |
 |
Paper |
| Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models Zeyu Liu,Yuhang Liu,Guanghao Zhu,Congkai Xie,Zhen Li,Jianbo Yuan,Xinyao Wang,Qing Li,Shing-Chi Cheung,Shengyu Zhang,Fei Wu,Hongxia Yang |
 |
Paper |
 Qwen Look Again: Guiding Vision-Language Reasoning Models to Re-attention Visual Information Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, Weiping Li |
 |
Github Paper |
| Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought Yunze Man,De-An Huang,Guilin Liu,Shiwei Sheng,Shilong Liu,Liang-Yan Gui,Jan Kautz,Yu-Xiong Wang,Zhiding Yu |
 |
Paper |
| Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models Yufei Zhan, Hongyin Zhao, Yousong Zhu, Shurong Zheng, Fan Yang, Ming Tang, Jinqiao Wang |
 |
Paper |
| Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning Minheng Ni, Zhengyuan Yang, Linjie Li, Chung-Ching Lin, Kevin Lin, Wangmeng Zuo, Lijuan Wang |
 |
Paper |
| Ground-R1: Incentivizing Grounded Visual Reasoning via Reinforcement Learning Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, Xiaodan Liang |
 |
Paper |
| SATORI-R1: Incentivizing Multimodal Reasoning with Spatial Grounding and Verifiable Rewards Chuming Shen, Wei Wei, Xiaoye Qu, Yu Cheng |
 |
Paper |
| Don't Look Only Once: Towards Multimodal Interactive Reasoning with Selective Visual Revisitation Jiwan Chung, Junhyeok Kim, Siyeol Kim, Jaeyoung Lee, Min Soo Kim, Youngjae Yu |
 |
Paper |
| Visual Abstract Thinking Empowers Multimodal Reasoning Dairu Liu, Ziyue Wang, Minyuan Ruan, Fuwen Luo, Chi Chen, Peng Li, Yang Liu |
 |
Paper |
| VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, Klara Nahrstedt |
 |
Paper |
| DreamPRM: Domain-Reweighted Process Reward Model for Multimodal Reasoning Qi Cao, Ruiyi Wang, Ruiyi Zhang, Sai Ashish Somayajula, Pengtao Xie |
 |
Paper |
| FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, Xing Wei |
 |
Paper |
 Decoupled Visual Interpretation and Linguistic Reasoning for Math Problem Solving Zixian Guo, Ming Liu, Zhilong Ji, Jinfeng Bai, Lei Zhang, Wangmeng Zuo |
 |
Github Paper |
| Let Androids Dream of Electric Sheep: A Human-like Image Implication Understanding and Reasoning Framework Chenhao Zhang, Yazhe Niu |
 |
Paper |
| Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning Alex Su, Haozhe Wang, Weimin Ren, Fangzhen Lin, Wenhu Chen |
 |
Paper |
 Training-Free Reasoning and Reflection in MLLMs Hongchen Wei, Zhenzhong Chen |
 |
Github Paper |
 R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO Huanjin Yao, Qixiang Yin, Jingyi Zhang, Min Yang, Yibo Wang, Wenhao Wu, Fei Su, Li Shen, Minghui Qiu, Dacheng Tao, Jiaxing Huang |
 |
Github Paper |
 SophiaVL-R1: Reinforcing MLLMs Reasoning with Thinking Reward Kaixuan Fan, Kaituo Feng, Haoming Lyu, Dongzhan Zhou, Xiangyu Yue |
 |
Github Paper |
| VLM-R3: Region Recognition, Reasoning, and Refinement for Enhanced Multimodal Chain-of-Thought Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang |
 |
Paper |
 Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning Siqu Ou, Hongcheng Liu, Pingjie Wang, Yusheng Liao, Chuan Xuan, Yanfeng Wang, Yu Wang |
 |
Github Paper |
| GRIT: Teaching MLLMs to Think with Images Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, Xin Eric Wang |
 |
Paper |
| UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, Yansong Tang |
 |
Paper |
 MMaDA: Multimodal Large Diffusion Language Models Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, Mengdi Wang |
 |
Github Paper |
| Visual Thoughts: A Unified Perspective of Understanding Multimodal Chain-of-Thought Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, Libo Qin |
 |
Paper |
 Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning Jiaer Xia, Yuhang Zang, Peng Gao, Yixuan Li, Kaiyang Zhou |
 |
Github Paper |
 VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning Yuqi Liu, Tianyuan Qu, Zhisheng Zhong, Bohao Peng, Shu Liu, Bei Yu, Jiaya Jia |
 |
Github Paper |
 MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision Lingxiao Du, Fanqing Meng, Zongkai Liu, Zhixiang Zhou, Ping Luo, Qiaosheng Zhang, Wenqi Shao |
 |
Github Paper |
| CoT-Vid: Dynamic Chain-of-Thought Routing with Self Verification for Training-Free Video Reasoning Hongbo Jin, Ruyang Liu, Wenhao Zhang, Guibo Luo, Ge Li |
 |
Paper |
| Visual Planning: Let's Think Only with Images Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, Ivan Vulić |
 |
Paper |
 X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains Qianchu Liu, Sheng Zhang, Guanghui Qin, Timothy Ossowski, Yu Gu, Ying Jin, Sid Kiblawi, Sam Preston, Mu Wei, Paul Vozila, Tristan Naumann, Hoifung Poon |
 |
Github Paper |
| Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning Xiaokun Wang, Chris, Jiangbo Pei, Wei Shen, Yi Peng, Yunzhuo Hao, Weijie Qiu, Ai Jian, Tianyidan Xie, Xuchen Song, Yang Liu, Yahui Zhou |
 |
Paper |
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning Ke Wang, Junting Pan, Linda Wei, Aojun Zhou, Weikang Shi, Zimu Lu, Han Xiao, Yunqiao Yang, Houxing Ren, Mingjie Zhan, Hongsheng Li |
 |
Paper |
 Visually Interpretable Subtask Reasoning for Visual Question Answering Yu Cheng, Arushi Goel, Hakan Bilen |
 |
Github Paper |
 Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging Shiqi Chen, Jinghan Zhang, Tongyao Zhu, Wei Liu, Siyang Gao, Miao Xiong, Manling Li, Junxian He |
 |
Github Paper |
 Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning Chris, Yichen Wei, Yi Peng, Xiaokun Wang, Weijie Qiu, Wei Shen, Tianyidan Xie, Jiangbo Pei, Jianhao Zhang, Yunzhuo Hao, Xuchen Song, Yang Liu, Yahui Zhou |
 |
Github Paper |
- Seed1.5-VL Technical Report. seed team. [Paper]
| Title & Authors | Introduction | Links |
|---|---|---|
| Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu |
 |
Paper |
 CoT-Valve: Length-Compressible Chain-of-Thought Tuning Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, Xinchao Wang |
 |
Github Paper |
 Non-Determinism of "Deterministic" LLM Settings Berk Atil, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, Zhe Wu, Lixinyu Xu, Breck Baldwin |
 |
Github Paper |
| The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, Nicholas Thumiger, Aditya Desai, Ion Stoica, Ana Klimovic, Graham Neubig, Joseph E. Gonzalez |
 |
Paper |
| Evaluating Large Language Models Trained on Code Mark Chen, Jerry Tworek, et al. |
 |
Paper |
| τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains Shunyu Yao, Noah Shinn, Pedram Razavi, Karthik Narasimhan |
 |
Paper |
 Are Your LLMs Capable of Stable Reasoning? Junnan Liu, Hongwei Liu, Linchen Xiao, Ziyi Wang, Kuikun Liu, Songyang Gao, Wenwei Zhang, Songyang Zhang, Kai Chen |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps Sicheng Feng, Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song, Jianke Zhu, Huan Wang, Xinchao Wang |
 |
Github Paper |
| ViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations Xuecheng Wu, Jiaxing Liu, Danlei Huang, Xiaoyu Li, Yifan Wang, Chen Chen, Liya Ma, Xuezhi Cao, Junxiao Xue |
 |
Paper |
 ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models Liyan Tang, Grace Kim, Xinyu Zhao, Thom Lake, Wenxuan Ding, Fangcong Yin, Prasann Singhal, Manya Wadhwa, Zeyu Leo Liu, Zayne Sprague, Ramya Namuduri, Bodun Hu, Juan Diego Rodriguez, Puyuan Peng, Greg Durrett |
 |
Github Paper |
| Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang |
 |
Paper |
| StoryReasoning Dataset: Using Chain-of-Thought for Scene Understanding and Grounded Story Generation Daniel A. P. Oliveira, David Martins de Matos |
 |
Paper |
 Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency Zhikai Wang, Jiashuo Sun, Wenqi Zhang, Zhiqiang Hu, Xin Li, Fan Wang, Deli Zhao |
 |
Github Paper |
 CipherBank: Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges Yu Li, Qizhi Pei, Mengyuan Sun, Honglin Lin, Chenlin Ming, Xin Gao, Jiang Wu, Conghui He, Lijun Wu |
 |
Github Paper |
 VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wengang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zhu, Wenhai Wang, Jifeng Dai, Jinguo Zhu |
 |
Github Paper |
| LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception Yuan-Hong Liao, Sven Elflein, Liu He, Laura Leal-Taixé, Yejin Choi, Sanja Fidler, David Acuna |
 |
Paper |
| THOUGHTTERMINATOR: Benchmarking, Calibrating, and Mitigating Overthinking in Reasoning Models Xiao Pu, Michael Saxon, Wenyue Hua, William Yang Wang |
|
Paper |
| Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu |
|
Paper |
| The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, Nicholas Thumiger, Aditya Desai, Ion Stoica, Ana Klimovic, Graham Neubig, Joseph E. Gonzalez |
|
Paper |
 Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights Shubham Parashar, Blake Olson, Sambhav Khurana, Eric Li, Hongyi Ling, James Caverlee, Shuiwang Ji |
 |
Github Paper |
 Bag of Tricks for Inference-time Computation of LLM Reasoning Fan Liu, Wenshuo Chao, Naiqiang Tan, Hao Liu |
 |
Github Paper |
 Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, Bowen Zhou |
 |
Github Paper |
| DNA Bench: When Silence is Smarter -- Benchmarking Over-Reasoning in Reasoning LLMs Masoud Hashemi, Oluwanifemi Bamgbose, Sathwik Tejaswi Madhusudhan, Jishnu Sethumadhavan Nair, Aman Tiwari, Vikas Yadav |
 |
Paper |
| S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models Wenyuan Zhang, Shuaiyi Nie, Xinghua Zhang, Zefeng Zhang, Tingwen Liu |
 |
Paper |
 VCR-Bench: A Comprehensive Evaluation Framework for Video Chain-of-Thought Reasoning Yukun Qi, Yiming Zhao, Yu Zeng, Xikun Bao, Wenxuan Huang, Lin Chen, Zehui Chen, Jie Zhao, Zhongang Qi, Feng Zhao |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention MiniMax Team |
 |
Github Paper |
| Resa: Transparent Reasoning Models via SAEs Shangshang Wang, Julian Asilis, Ömer Faruk Akgül, Enes Burak Bilgin, Ollie Liu, Deqing Fu, Willie Neiswanger |
 |
Paper |
| AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping |
 |
Paper |
 BARREL: Boundary-Aware Reasoning for Factual and Reliable LRMs Junxiao Yang, Jinzhe Tu, Haoran Liu, Xiaoce Wang, Chujie Zheng, Zhexin Zhang, Shiyao Cui, Caishun Chen, Tiantian He, Hongning Wang, Yew-Soon Ong, Minlie Huang |
 |
Github Paper |
 RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning Kaiwen Zha, Zhengqi Gao, Maohao Shen, Zhang-Wei Hong, Duane S. Boning, Dina Katabi |
 |
Github Paper |
| Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision Eric Hanchen Jiang, Haozheng Luo, Shengyuan Pang, Xiaomin Li, Zhenting Qi, Hengli Li, Cheng-Fu Yang, Zongyu Lin, Xinfeng Li, Hao Xu, Kai-Wei Chang, Ying Nian Wu |
|
Paper |
| Warm Up Before You Train: Unlocking General Reasoning in Resource-Constrained Settings Safal Shrestha, Minwu Kim, Aadim Nepal, Anubhav Shrestha, Keith Ross |
 |
Paper |
| Reasoning Models Better Express Their Confidence Dongkeun Yoon, Seungone Kim, Sohee Yang, Sunkyoung Kim, Soyeon Kim, Yongil Kim, Eunbi Choi, Yireun Kim, Minjoon Seo |
 |
Paper |
| Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning Haolei Xu, Yuchen Yan, Yongliang Shen, Wenqi Zhang, Guiyang Hou, Shengpei Jiang, Kaitao Song, Weiming Lu, Jun Xiao, Yueting Zhuang |
 |
Paper |
 ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning Jiaan Wang, Fandong Meng, Jie Zhou |
 |
Github Paper |
 RBF++: Quantifying and Optimizing Reasoning Boundaries across Measurable and Unmeasurable Capabilities for Chain-of-Thought Reasoning Qiguang Chen, Libo Qin, Jinhao Liu, Yue Liao, Jiaqi Wang, Jingxuan Zhou, Wanxiang Che |
 |
Github Paper |
| Absolute Zero: Reinforced Self-play Reasoning with Zero Data Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang |
 |
Paper |
 Learning from Peers in Reasoning Models Tongxu Luo, Wenyu Du, Jiaxi Bi, Stephen Chung, Zhengyang Tang, Hao Yang, Min Zhang, Benyou Wang |
 |
Github Paper |
 Beyond Aha!: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models Zhiyuan Hu, Yibo Wang, Hanze Dong, Yuhui Xu, Amrita Saha, Caiming Xiong, Bryan Hooi, Junnan Li |
 |
Github Paper |
 OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, Yu Cheng |
 |
Github Paper |
| The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think Seongyun Lee, Seungone Kim, Minju Seo, Yongrae Jo, Dongyoung Go, Hyeonbin Hwang, Jinho Park, Xiang Yue, Sean Welleck, Graham Neubig, Moontae Lee, Minjoon Seo |
 |
Paper |
| Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, Guo-Jun Qi |
 |
Paper |
| J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason Weston, Ilia Kulikov, Swarnadeep Saha |
 |
Paper |
| INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning Prime Intellect Team, Sami Jaghouar, Justus Mattern, Jack Min Ong, Jannik Straube, Manveer Basra, Aaron Pazdera, Kushal Thaman, Matthew Di Ferrante, Felix Gabriel, Fares Obeid, Kemal Erdem, Michael Keiblinger, Johannes Hagemann |
 |
Paper |
| AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale Yunjie Ji, Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, Xiangang Li |
 |
Paper |
 Chain-of-Thought Tokens are Computer Program Variables Fangwei Zhu, Peiyi Wang, Zhifang Sui |
 |
Github Paper |
 MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining Xiaomi LLM-Core Team |
 |
Github Paper |
| Thoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines Ramesh Manuvinakurike, Emanuel Moss, Elizabeth Anne Watkins, Saurav Sahay, Giuseppe Raffa, Lama Nachman |
 |
Paper |
| Between Underthinking and Overthinking: An Empirical Study of Reasoning Length and correctness in LLMs Jinyan Su, Jennifer Healey, Preslav Nakov, Claire Cardie |
 |
Paper |
 WebThinker: Empowering Large Reasoning Models with Deep Research Capability Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, Zhicheng Dou |
 |
Github Paper |
Beyond the Last Answer: Your Reasoning Trace Uncovers More than You Think Hasan Abed Al Kader Hammoud, Hani Itani, Bernard Ghanem |
|
Github Paper |
 Reinforcement Learning for Reasoning in Large Language Models with One Training Example Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Lucas Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, Yelong Shen |
 |
Github Paper |
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning Chris, Yichen Wei, Yi Peng, Xiaokun Wang, Weijie Qiu, Wei Shen, Tianyidan Xie, Jiangbo Pei, Jianhao Zhang, Yunzhuo Hao, Xuchen Song, Yang Liu, Yahui Zhou |
|
Github Paper |
 Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang |
 |
Github Paper |
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou |
 |
Paper |
 Tree of Thoughts: Deliberate Problem Solving with Large Language Models Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan |
 |
Github Paper |
 Graph of Thoughts: Solving Elaborate Problems with Large Language Models Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, Torsten Hoefler |
 |
Github Paper |
Self-Consistency Improves Chain of Thought Reasoning in Language Models Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou |
 |
Paper |
 Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks Wenhu Chen, Xueguang Ma, Xinyi Wang, William W. Cohen |
 |
Github Paper |
 Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models Hanxu Hu, Hongyuan Lu, Huajian Zhang, Yun-Ze Song, Wai Lam, Yue Zhang |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Thinking Machines: A Survey of LLM based Reasoning Strategies Dibyanayan Bandyopadhyay, Soham Bhattacharjee, Asif Ekbal |
 |
Paper |
 From System 1 to System 2: A Survey of Reasoning Large Language Models Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, Cheng-Lin Liu |
 |
Github Paper |
AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset. Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, Igor Gitman. [Paper][Github]

This repository is inspired by Awesome-Efficient-LLM
@article{feng2025efficient,
title={Efficient Reasoning Models: A Survey},
author={Feng, Sicheng and Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},
journal={arXiv preprint arXiv:2504.10903},
year={2025},
}