Use MyST in other static site generators #974
Replies: 7 comments 34 replies
-
|
I fought with this and in the end gave up and went back to Jekyll 😹 😭
See this plugin for Pelican:
and also posts here:
grumpy take: The core problem is that most static site generators don't speak Sphinx natively, their goals are orthogonal to what Sphinx tries to do as a docs generator |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @NickleDave! Just a minor remark on the issue you link (the other things have been addressed by @agoose77): I understand that using MyST fancy features requires adjusting the styling on the other end, but I consider this a good problem to have! |
Beta Was this translation helpful? Give feedback.
-
|
I can't speak to the technical feasibility just yet (I'll let the rest of the EB maintainers touch on this). As for our goals, MyST is intended to exist beyond Sphinx, hence https://myst-tools.org/docs/spec. The work on MyST has been happening for some time, and some of the discussions from 2020 will be outdated with respect to where we are now. At a high-level, many Markdown renderers spit-out HTML as the "lingua franca" representation. Most MyST tooling, meanwhile, outputs some form of an AST (e.g. myst-parser speaks docutils nodes, whilst mystjs outputs MDAST), meaning that HTML is not a primary render target. It's the secondary pipeline, e.g. docutils/Sphinx's renderer, or mystjs' MDAST react renderer that produces something visually interesting. I'd therefore be interested to hear the rest of the EB team's thoughts on where other SSGs fit into this landscape. Tagging a few (@choldgraf, @chrisjsewell, @rowanc1) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @agoose77, I've been looking at mystjs for some time but your answer clarifies to me how it relates to its Python counterpart. In light of your answer I also double checked https://myst-parser.readthedocs.io/en/latest/develop/architecture.html and https://myst-parser.readthedocs.io/en/latest/intro.html and I think I now understand the role (no pun intended) of docutils and Sphinx in the process. I guess there are no plans to port MDAST to Python? 😈 |
Beta Was this translation helpful? Give feedback.
-
|
I would suggest AST is just one part of it:
Most document generators then have their own bespoke source syntax (nominally based on Markdown) that is specifically designed to feed in to their engine. All this complexity is wrapped up into the document generator. |
Beta Was this translation helpful? Give feedback.
-
|
Sorry if I made it sound like I think of MyST as just a way to get to restructured text. Not to talk over replies from other maintainers but: @astrojuanlu you said yourself this is a very open-ended question, but are there specific use cases you had in mind? Since you mentioned both mkdocs and docusaurus, and they're both mainly for docs, I think that's why my mind immediately went to "will I still be able to get stuff from Sphinx / Python" |
Beta Was this translation helpful? Give feedback.
-
|
I'm trying to figure out what's missing for us to break free from the current documentation toolchains we have in Python. In my view, Sphinx, MkDocs and the like boil down to this: an underpowered static site generator coupled with a superb docstring parsing mechanism. This allows narrative + API docs to exist together in a coherent way, but forces us to use a specific SSG that might not be as popular, well maintained, or powerful as other SSGs that exist. Hence the question: what if we could use any SSG of our liking while keeping the API documentation capabilities by decoupling these two feature sets? In other words, trying to create documentation sites for Python projects using Hugo + (?), or Docusaurus + (?). Looks like this should already be within reach with MyST for the narrative docs, https://github.com/mkdocstrings/griffe/ for signature + docsting parsing (hence enabling an "autodoc/autosummary/autoapi" of sorts), and some glue code. |
Beta Was this translation helpful? Give feedback.
-
Can you explain a little further what you mean by this: what features do you require that are not currently available, and how do the other tools you mention meet them? |
Beta Was this translation helpful? Give feedback.
-
|
A bit late here to elaborate too deeply but even if I'm not thinking of specific technical features that are missing, sometimes "not well maintained", "slow", "not enough themes", or "logs & error messages are impossible to understand" are good reasons to shop for alternatives. Unfortunately, in Python we cannot go very far - yet. |
Beta Was this translation helpful? Give feedback.
-
|
Indeed you should absolutely shop for alternatives, if you're not happy with the current, no worries 😉 My devils advocate would be, if there is another framework you like better, why not just ask them to add such API functionality? |
Beta Was this translation helpful? Give feedback.
-
In the spirit of good open source citizenship, I'm trying to figure out "how hard can it be" before asking for it 😄 |
Beta Was this translation helpful? Give feedback.
-
|
I'm not going to dive into technical details and implementation, as that's probably SSG-specific, and I generally agree w/ @agoose77's take. To your more general point @astrojuanlu: I think it would be excellent to see MyST support in other SSGs. As others have noted, a big question is how much of a "1 to 1" experience you want to have between something like the Python or JS parsers and whatever new SSG you'd want to support. However, my feeling is that just supporting the markdown syntax so that it behaves similarly, and a subset of directives that are particularly common and useful (in particular, admonitions), would go a long way. I think that doing this would be something like:
I would love to see, for example, a parser that Hugo could use so that people can write MyST Markdown in their hugo sites. I'd love to see the same tried for Docusaurus (and maybe mystjs would help there since it's also in the TS/JS world). Even if it didn't support all of the functionality of Sphinx/mystjs/etc, I think it'd be a win just to reduce the friction for moving source content from one to another and standardizing syntax a bit.1 Example of how this works in Sphinx and the Python MyST ParserIn Sphinx, it is relatively easier because many of the core ideas that myst supports (cross references w/ labels, admonitions, directives, etc) already exist in Sphinx. So we don't need to re-invent those ideas there, we just need to translate them. So for example, here's roughly how this works with the Sphinx parser. It might be slightly off but my goal is to give the general idea. Overview: We define a parser for Sphinx that uses markdown-it-py ( Longer version w/ links: We define a markdown-it-py parser with the necessary MyST syntax here: We then define a new It also uses a renderer ( Note that we use the Here's the definition of And we inherit from We then tell Sphinx to register this parser for So at that point, Sphinx will use this parsing chain when it encounters a Note that Sphinx has its own concept of "how to support a new source file and parser/renderer", and it also has its own "document engine" so it might be a bit different for a different SSG. In addition, styling for things like "what an admonition looks like" is done by Sphinx themes (e.g. the sphinx book theme, so the Hopefully this is a helpful high-level overview of the process! Maybe it can provide inspiration for others Footnotes
|
Beta Was this translation helpful? Give feedback.
-
|
@choldgraf @chrisjsewell @rowanc1 , Honest question: doesn't a Javascript MyST-to-HTML parser cover > 90% of all SSG use? Hugo, Jekyll and the non-JS SSGs are a tiny fraction compared to Next, Nuxt, 11ty, SvelteKit, Gatsby, Docusaurus, Astro, SolidStart, QuikCity, etc. I saw somebody started working on an implementation in Unified (https://github.com/executablebooks/unified-myst) which would be SO cool because then you could use it in MDX. |
Beta Was this translation helpful? Give feedback.
-
|
@riziles I think maybe your (broader) question is for another thread 😅
yep that was me 👍; I wanted to look at unified for parsing, as well as post-processing (i.e. AST manipulation), and also look at what an "ideal" extension framework might look like for MyST (akin to sphinx's extension system). |
Beta Was this translation helpful? Give feedback.
-
Yep agree @pawamoy, sphinx-autodoc2 also has essentially a schema for Python based APIs: https://github.com/sphinx-extensions2/sphinx-autodoc2/blob/13933a5b25a780e03f227414d432420706962212/src/autodoc2/utils.py#L20 @astrojuanlu I think that key thing here is that there are two stages:
|
Beta Was this translation helpful? Give feedback.
-
You might find more information or reasoning here: Python-Markdown/markdown#1175 For example, from @facelessuser:
Many more references to MyST in the discussion 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
I've just published a JSON schema for Griffe 😄 https://github.com/mkdocstrings/griffe/blob/master/docs/schema.json |
Beta Was this translation helpful? Give feedback.
-
|
By the way I've been spending some days in this rabbit hole and today I started to write a GitHub comment that was so long that eventually I decided to go back to blogging. See https://dev.to/astrojuanlu/futuristic-documentation-systems-in-python-part-1-aiming-for-more-1a17 for the first part of those reflections, summarizing some things that have been mentioned in this thread. I commit to writing parts 2 and 3 soon (but now I'd better get back to what I was doing). |
Beta Was this translation helpful? Give feedback.
-
|
Indeed, I have a lot of thoughts on this, a few hundred hours of work. I'm likely an outlier on my thinking. 😀 |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @astrojuanlu
I certainly understand why you didn't, but I definitely think it would be very helpful to have a list of features that would be desirable for documentation generators (and indeed what a "modern" feature is), in order to provide some assessment/comparison of the different products. In terms of API documentation, as I mention in #974 (reply in thread), I feel there is a framework agnostic step, but then a step that is very dependent on the framework and its capabilities In terms of Python documentation/docstings in particular, I feel that it would be ideal if there was a very clear specification coming directly from the Python steering council themselves. |
Beta Was this translation helpful? Give feedback.
-
|
Spot on @chrisjsewell. I kind of take those features for granted because honestly we're so spoiled by how good MyST is, but I know that as soon as I start poking around with Hugo or even MkDocs, the gaps are going to become very evident. Rant about CPython docs cultureLoved this sentence from Rust:
Most of CPython docstrings aren't actually that good - in fact, CPython famously doesn't even use autodoc, so devs have to write https://github.com/python/cpython/blob/1f7eb8fe6c1a566caf934a96c6fe2877b2447d5b/Doc/library/pathlib.rst?plain=1#L99 and also https://github.com/python/cpython/blob/1f7eb8fe6c1a566caf934a96c6fe2877b2447d5b/Lib/pathlib.py#L455-L463 . There's obvious historical reasons for this, and I know there is an active group trying to modernize Python docs infrastructure, but I'm out of the loop of how conversations are going. Long story short, I don't expect a spec coming directly from the CPython steering council - we'd probably get in yet another flame war between "the data people" (largely using NumPy style) and "the web people". |
Beta Was this translation helpful? Give feedback.
-
|
Anybody up for an open space at PyCon? Around 4 years ago I did a VERY long effort to turn Sphinx into a knowledge base, inspired by CMS ideas. It went well but I went too far. I had a view layer, a non-Jinja component templating approach with DI, a highly-pluggable registry inspired by Pyramid, frontmatter validation. Even got into a theming infrastructure and a "dev server" mode. Wound up getting pretty far into Sphinx internals and learning what I really like about Sphinx's content model. It was really cool developing Sphinx sites for that. I then switched to Gatsby because I couldn't finish the project. Gatsby was PITIFUL. But I learned a LOT about what I want. Also: how far behind Python is compared to modern frontends, on nearly every front. Over the last 3 years, I gradually re-built the Python/Sphinx pieces: a registry injector, a templating approach, etc. All in repos with a lot of tests. I had a detour trying to switch to Antidote, but that project is now unmaintained, so I ultimately have to backtrack. Last week I put into production a Gatsby replacement, based on Eleventy 2.0 and: Vite, Vitest, TypeScript, JSX, and TypeBox validation. It's still the same idea: a tree of Markdown with frontmatter is actually a hierarchical database on disk. I suspect anybody reading the above will be like: WTF? I don't know if anybody wants what I want. The speeed of Hugo, the content model of Sphinx, the "modern web" of Gatsby, the ease of 11ty....in Python. I have two parts relevant to a MyST-like thing that I could discuss. But I fully realize: I'm on island with a population of one. 😇 |
Beta Was this translation helpful? Give feedback.
-
Make space for another human in that island :) |
Beta Was this translation helpful? Give feedback.
-
@pauleveritt +1 for this, I'll be there
@astrojuanlu I feel like there's a lot of parallels to what's happening with packaging: it's hard enough for the core devs to work on CPython already, so they are happy to let someone else worry about packaging. I know the steering council =/= core devs but still, they have enough on their plate already. It's also clear that some non-negligible subset of people are frustrated by the status quo (This isn't news to anyone reading this issue, I realize.) I wonder if some sort of Python Docs Collective could get together (I have an allergy to "Authority"). I don't know what the goal would be: more standards? yet another tool? (shudders) This is definitely veering off topic from "use MyST in other static site generators" and to be clear I am all in on MyST wherever I can use it. But just wanted to reply to both those points. |
Beta Was this translation helpful? Give feedback.
-
|
Yep, that's another conversation - namely that lots of people are unhappy about how docutils is managed but nobody has the energy to fork, and it's also unclear whether such a fork would be useful at all because Sphinx would need to adopt it. There are some people that are not yet burned out by past interactions that are trying to build bridges, but looks like the core issues remain. I still want to use MyST everywhere regardless of whether the Python implementation uses docutils under the hood or not, I assume it's largely unavoidable for now. On the other hand, it's exciting to see that on JS land the pastures look greener and that mystjs can use mdast for document representation. |
Beta Was this translation helpful? Give feedback.
-
|
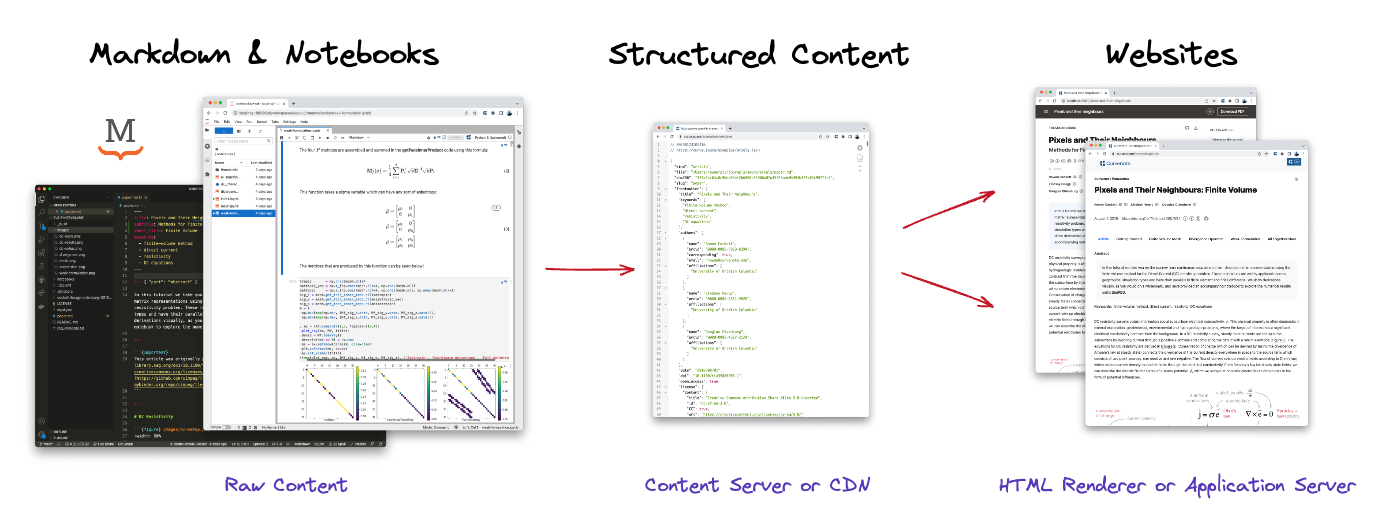
Thanks for sparking a really interesting discussion @astrojuanlu, it has been fun to read, and enjoyed your blog. :) I will try to keep up to @choldgraf and give an overview of how this currently works in Technically this forces an architecture which has a strong focus on structured data (e.g. an AST -- in scholarly publishing the standard is JATS) which separates the content from the way you are viewing that content (@lheagy's 2016 scipy talk is one of my favourites on this topic; using sphinx pre-myst). In web speak, this is something closer to a content-management system, and with (MyST) Markdown at the center it is a JAM stack. The architecture that we are working on has three parts: (1) parse the documents; (2) a content server; and (3) an html renderer or application that actually renders the page.
For the renderer at the moment we use React and Remix (similar to nextjs), both are pretty different (and more complex) than the traditional pre-built HTML approach that, for example, Sphinx takes -- which can have advantages for performance/accessibility etc. (e.g. see some comparisons) mostly because that is where a lot of web-developers spend there time. It also allows for a mix between a single-page app approach where browsing between pages is super fast, and a server-side rendered or generated approach, where you get the full HTML on first load (pictures!). This is similar/the same as documentation tools like docusaurus, and I think/hope there will be compatibility in the react ecosystem of mystjs and docusaurus in the future. For the whole document pipeline in import { mystParser } from 'myst-parser';
import { State, transform, mystToHast, formatHtml } from 'myst-to-html';
import rehypeStringify from 'rehype-stringify';
import { unified } from 'unified';
const pipe = unified()
.use(mystParser)
.use(transform, new State())
.use(mystToHast)
.use(formatHtml)
.use(rehypeStringify);
const file = pipe.processSync(':::{important}\nHello to the world!\n:::');
console.log(file.value);
// <aside class="admonition important"><p class="admonition-title">Important</p><p>Hello to the world!</p></aside>This can include adding custom roles/directives as options to the parser (e.g. a test is here), but some of the APIs are still a bit in flux, and it is severely lacking in developer docs (we have been mostly focused on user facing docs!). This can also be completed for other document processing pipelines, like docx which takes an AST (e.g. see here to create the tree): import { mystToDocx } from 'myst-to-docx';
const docxBlob = unified()
.use(mystToDocx, opts)
.stringify(tree).result;There is a similar story for I will note that although we are using unified for the majority of things, we are actually still using markdown-it for the tokenization, so it probably won't work as-is in mdx workflows quite yet, which are based around remark/rehype plugins, (we are getting closer @riziles!). We are using a full-unified workflow for the LaTeX parsing (e.g. a blog here) and there are some really nice things that come with that (e.g. column numbers) that make error messages really nice. Another thing that I have experimented with is running the Curvenote blog using a myst site. The blog is here and a pre-mystjs explanation of how it hangs together is here. Hopefully some of those pointers and code snippets help explain how things currently work in mystjs! |
Beta Was this translation helpful? Give feedback.
-
|
Blog looks amazing @rowanc1, thank you -- this is why I was looking at SSGs + MyST in the first place |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @NickleDave! Appreciate it. :) One of the templates I have had my eye on integrating with is this tailwind/nextjs blog. It is very close to what we can do with mystjs today, and also has a bit of a community around the template. That is aimed at a replacement for Jekyll/Hugo, and with MyST could also be a really good complement for showing notebooks, scientific articles, etc. |
Beta Was this translation helpful? Give feedback.
-
|
You read my mind 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
Well it's time to learn Node.js for real it seems :) Trying to get a basic example to work before hopefully achieving MyST to Markdown conversion (and beyond) #981 |
Beta Was this translation helpful? Give feedback.
-
|
Put together a small playground here with a video: https://github.com/rowanc1/myst-playground Please continue to ask questions!! :) |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
What would be the best way to integrate MyST into other static site generators? I'm looking for a generic answer from the MyST perspective, rather than a case by case specific answer. I'm thinking of MkDocs (mkdocs/mkdocs#2898), Hugo, and Docusaurus.
Should I attempt to create some middleware that translates from MyST to tool-specific markdown on the fly as a separate step? Or maybe you have other approaches in mind?
I know this is quite open ended and maybe difficult to answer, but I'm trying to solve any unknown unknowns before getting too deep into the rabbit hole.
Beta Was this translation helpful? Give feedback.
All reactions