Setting up RAG model for generative pipeline #4637
Replies: 2 comments 3 replies
-
|
@julian-risch I just noticed that this issue was also discussed before. Do you know any quick fix for being able to use the generative pipeline on a local docstore? |
Beta Was this translation helpful? Give feedback.
-
|
Hello @aghelinejad did you have a look at our tutorial on RAG? https://haystack.deepset.ai/tutorials/07_rag_generator Should work out of the box. 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
Hi @julian-risch , I just replicated exact same tutorial and this is what I get: And this is the returned answers: |



Beta Was this translation helpful? Give feedback.
-
|
This happens with your data or the tutorials data? 👀 |
Beta Was this translation helpful? Give feedback.
-
|
This is with my data, and I'm just reading a text document and doing simple preprocessing on it. Then I pass the processed doc to the docstore: |
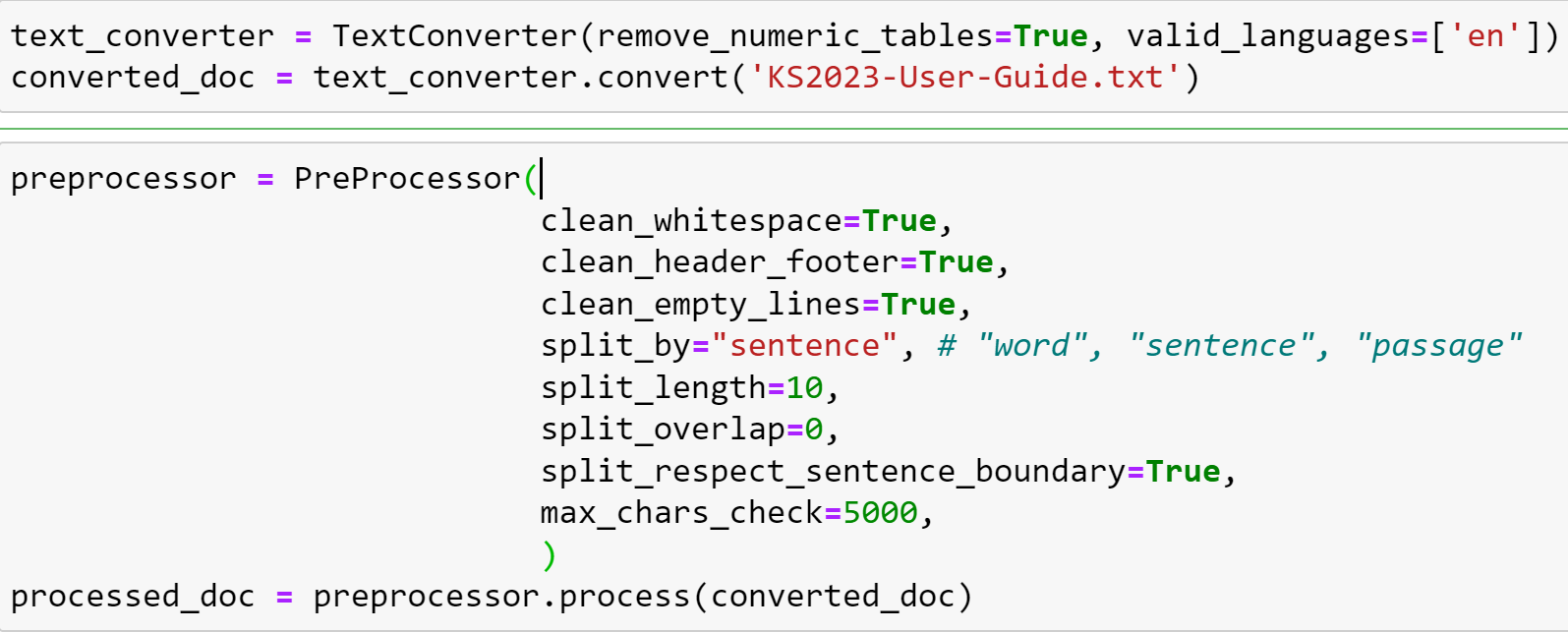
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi All,
I'm new to LLM and HayStack and I'm having problem while trying to configure a generative pipeline using a text document.
I keep getting warnings that show my generator model and the tokenizer does not match, so it generates nonsense results
Here are the warnings:
and here is my script (I have tested both embeding and dense retriever):
text_converter = TextConverter(remove_numeric_tables=False, valid_languages=['en'])
converted_doc = text_converter.convert('file.txt')
preprocessor = PreProcessor(
clean_whitespace=True,
clean_header_footer=False,
clean_empty_lines=True,
split_by="word",
split_length=200,
split_overlap=0,
split_respect_sentence_boundary=True,
)
processed_doc = preprocessor.process(converted_doc)
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat", return_embedding=True)
document_store.delete_documents()
document_store.write_documents(processed_doc)
retriever_emb = EmbeddingRetriever(document_store=document_store,
model_format='sentence_transformers',
embedding_model='distilroberta-base-msmarco-v2',
batch_size=8,
use_gpu=True)
retriever_dpr = DensePassageRetriever(
document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
use_gpu=True,
embed_title=True,
)
document_store.update_embeddings(retriever=retriever)
retriever_emb.retrieve(query='some query', document_store=document_store, top_k=2)
generator = RAGenerator(
model_name_or_path="facebook/rag-token-base",
retriever=None,
generator_type='token',
use_gpu=True,
top_k=3,
max_length=200,
min_length=5,
embed_title=True,
num_beams=2,
)
gen_pipe = GenerativeQAPipeline(generator=generator, retriever=retriever)
pred_gen_pipe = gen_pipe.run(
query="some question?",
params={"Retriever": {"top_k": 5}, "Generator": {"top_k": 5}}
)
Beta Was this translation helpful? Give feedback.
All reactions