Replies: 3 comments 9 replies
-
|
Dear Anurag, Thank you very much for the interest in the DeePMD-kit project. Current we are working on integrating the attention structure, which greatly improves the accuracy and data efficiency of the DP model. We find that the attention is very expansive and becomes the hot spot of the code. You are welcome to benchmark and let us know how to improve the efficiency of the model, especially on GPUs. The attention code has not yet been PRed, but you may check it via the link: Best regards, |
Beta Was this translation helpful? Give feedback.
-
|
@denghuilu If you could just share resources that would also work. |
Beta Was this translation helpful? Give feedback.
-
|
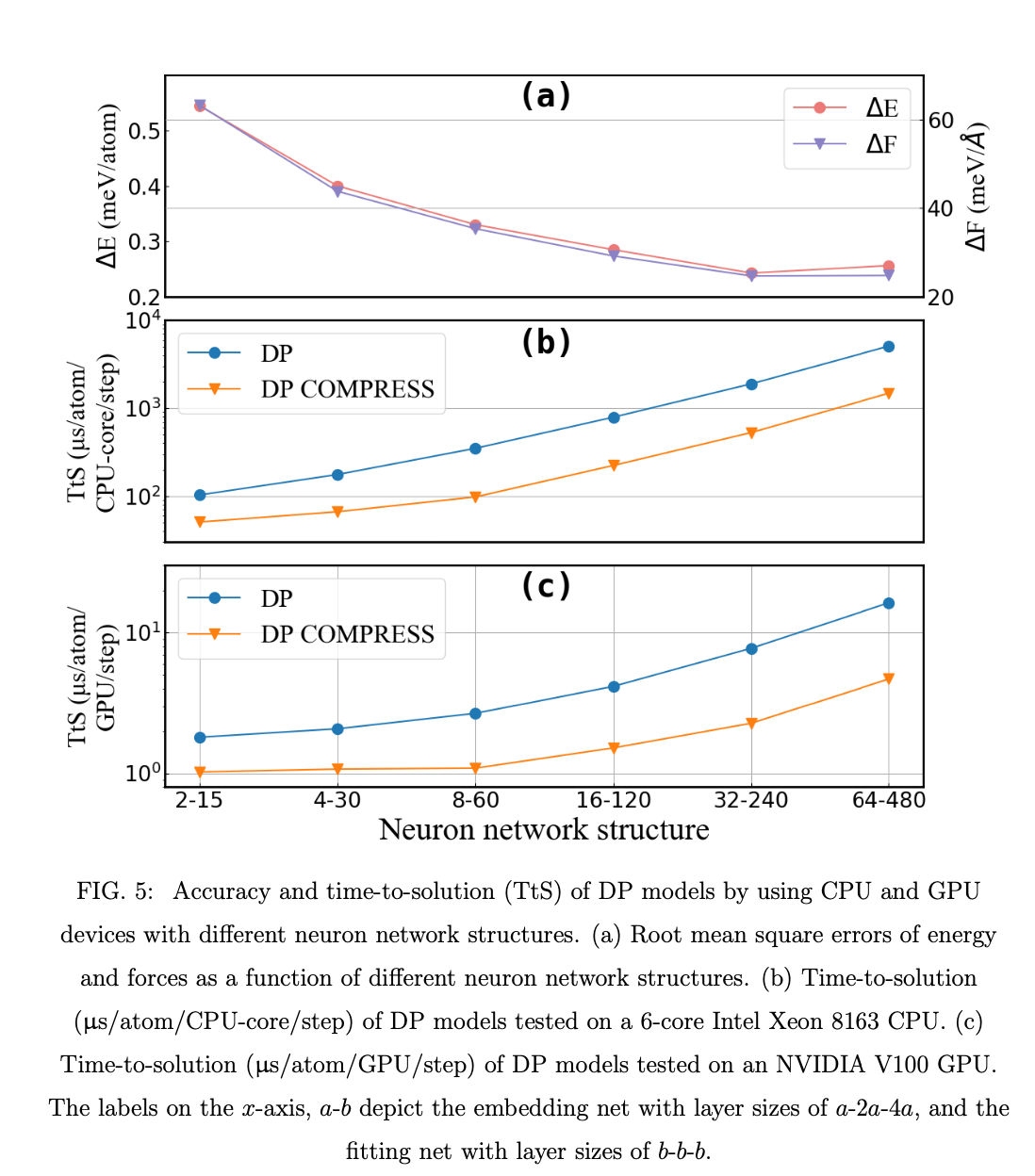
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the answer. I will try to do it myself in case I face difficulty I will get back. |
Beta Was this translation helpful? Give feedback.
-
Can the graph neural network improve the fitting accuracy of the DP model ? |
Beta Was this translation helpful? Give feedback.
-
|
"graph neural network" is a general concept. We cannot say whether it improves or not the accuracy of the DP. |
Beta Was this translation helpful? Give feedback.
-
|
Hello @wanghan-iapcm, |
Beta Was this translation helpful? Give feedback.
-
|
Hello @AnuragKr The gemm is the bottleneck of the standard DP model (not compressed), but we find that that the performance is memory bound, not computational bound, at least on the V100 GPU. This means that faster (in the sense of floating point operations) gemm would not help improve the over-all performance. For example using the tensorcores of V100 does not significantly improves the speed of DP. (unless far-beyond-necessarily-large embedding nets are used). By the model compression technique we have removed the gemm in the embedding net, thus the hot-spot becomes tabulated energy and force evaluation and the gemms in the fitting net. it is definitely welcome to raise new ideas of improving the performance of these parts. |
Beta Was this translation helpful? Give feedback.
-
|
Hello, @wanghan-iapcm I came across one CNN-based model Schnet. Is it a good idea to extend the DeePMD-kit fitting net architecture option apart from the feed-forward neural network, keeping the input data format and loss function the same? |
Beta Was this translation helpful? Give feedback.
-
|
New architectures are welcomed. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
I am from Computer Science And Data Science Background. I want to contribute to this project. I need ideas on what new feature or improvement regarding Model Training or Improvement enhancement on GPU I can do.
Beta Was this translation helpful? Give feedback.
All reactions