[Proposal] meilisearch 搜索调优 #229
Description
抱歉最近有些鸽,不过终于还是写完了。要看结论的话最末尾有 TL;DR。这里写得比较长主要是为了留一个记录,如果以后有人想继续这部分的工作也有一个上手的入口。
Proposal: meilisearch 搜索调优
背景
bangumi 新后端使用 meilisearch 提供全局关键字搜索能力,预期比现有后端搜索功能更好地支持模糊匹配。但当前使用 meilisearch 的默认索引参数,字段查询顺序也未根据需要进行调整。这导致了部分关键词返回结果与预期相差较大。
本提案目标即为对这些现象进行调优。
字段数据的使用
目前 bangumi 的每个 subject 有如下字段(命名可能与代码或数据库中的不一致):
| 名称 | 类型 | 描述 |
|---|---|---|
| id | int | bgm id |
| name | string | 条目名 |
| name_cn | string | 条目中文名 |
| infobox | string | 信息框中的全部内容,以类 wiki 标记语言格式存储,内容很杂 |
| summary | string | 简介 |
| type | int | 类型,动画、小说、音乐,etc. |
| platform | int | 对应类型下的平台(子类) \n 对动画来说就是 TV,OVA,剧场版这些; \n 游戏就是 PC,Xbox 这些 |
| image | string | 不含 cdn 前缀的图片路径 |
| eps | int | 集数 |
| tags | { name: string; count: int} | 标签,同时包括标签名和该标签的标记数 |
| wish, collect, doing, etc. | int | 收藏夹各分类的数量 |
| rate_{1,10} | int | 1-10评分每种的投票人数 |
| rank | int | 排名 |
| nsfw | bool | 是否为 nsfw |
| ban | bool (int) | 是否被禁止(0 否,1 是,2 被合并) |
| date | datetime (string) | 发布日期 |
meilisearch 中对字段的处理
可搜索字段指的是每个在 meilisearch 中的文档(等同于 mongodb 的 document 或 mysql 的 row)的哪些字段能被用来匹配关键字。可搜索字段在文档中的顺序被视为该字段的优先级。
可显示字段指搜索结果中返回哪些字段,类似于数据库查询的 select。本提案不包含对字段可见性进行约束。
distinct 字段指多个文档如何在搜索结果中被判断为相同的,用于令搜索结果仅包含其中一条。官方的例子是在电商搜索中用于合并SKU,感觉也用不到。
可过滤与可排序字段指文档中的哪些字段是能作为过滤条件或排序条件的,这些字段更像是数据库中“字段”的概念,他们能够被逻辑运算直接处理,而不是分词后进行模糊匹配。常用于精准匹配或固定的分类过滤,以及按某种顺序排序。
字段的选取
根据上述概念,我将 bangumi subject 的字段分为三类,他们之间可能有重叠。
- 可搜索字段,用于分词后模糊匹配关键字
- id
- name
- name_cn
- summary
- tags
- 可过滤/排序字段,用于各种高级搜索的筛选(或排序)条件
- id
- type
- platform
- rank
- rate (由rate_{1,10}计算而来)
- date
- eps
- nsfw
- 其他,其余都是不会在搜索中使用的字段
meilisearch 的搜索规则
Ranking rules 是 meilisearch 对搜索规则的称呼。其内置了6种搜索规则,具体含义比较复杂,可在这里查看,优先级按数组成员顺序排列:
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness"
]同时还支持对可过滤参数(filterable attributes)添加排序规则,以影响搜索结果的顺序。类似于若需要在搜索结果中将榜单排名靠前的条目尽量优先展示,可以配置为:
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness",
"rank:asc"
]本提案的具体目标
因而,本提案将从两方面对搜索结果进行调优
- 选取合适的可搜索字段,并确定他们的最佳顺序(优先级)
- 确定合适的 ranking rules
检验集的建立
目前开发团队并未针对搜索设置测试样例,而我对此也无法称得上专业,同时我仅对动画条目的数据比较熟悉(因此本提案可能会存在对其他类型的 subject 不够适用的情况,请注意)。
故仅凭经验(aka 拍脑袋)选取常用的几种 case,如下:
| 关键词 | 说明 |
|---|---|
| 哥布林 | 经常出现在各种作品中的关键词 |
| 林明美 | 人物关键词,出现在简介和tag中 |
| Marcross delta | vs 超时空要塞Δ,替代性写法 |
| fate 伊莉雅 2 | 描述性的关键词 |
| 妖精的2 | 不完整但带有季号的关键词,且存在名称相似的条目 |
| loli | 非常宽泛的关键词 |
| 国产 | 通常只在简介和tags中出现的词 |
| 巨侠 | 只在 tags 中出现的词 |
| 大河内一楼 | 知名作者 |
| 测试 笨蛋 | 非标准译名(==笨蛋==,测验,召唤兽) |
| LYCORIS | 不在 name 和 nameCN 中的别名 |
| ルルーシュ | 系列作品排序问题 |
| 百合 神作 / 轻百合 神作 | 在关键词中直接搜索 tags |
现状分析
-
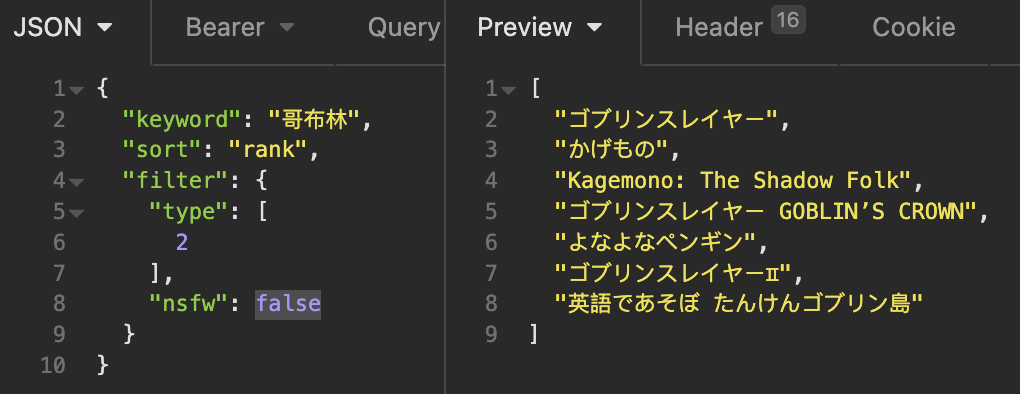
描述的权重非常高,经常导致非常不相关的条目出现在结果前排,仅仅因为这个关键词在 summary 中出现过。
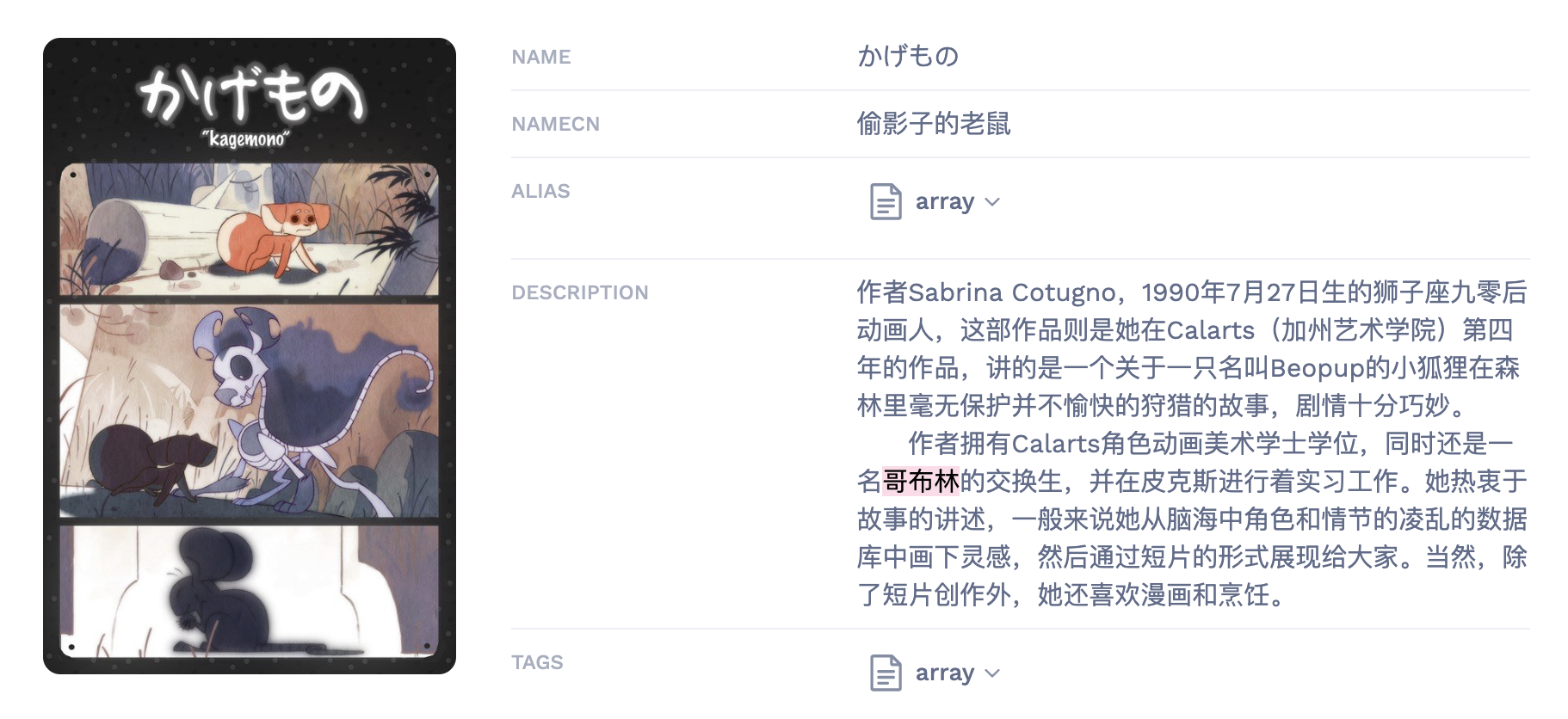
如搜索“哥布林”,毫不相干的两个「偷影子的老鼠」条目横割开了更合理的两个「哥布林杀手」条目。这一问题在使用模糊且通用的搜索词,如「loli」时更为严重。
-
tags 也对搜索结果影响巨大,如搜索「林明美」,第一个条目竟然是「天元突破 Parallel Works 2」……因为 tag 里有人打了 「林明美」(同名动画师)的标签……
-
匹配规则的权重不合理,仍然是搜索「林明美」,排在结果第四位的「アニ*クリ15」让事情更加离谱。其仅仅是因为 summary 非常长,里面出现了很多「美」字(美术、美少女、美国……),就出现在了搜索结果中。
-
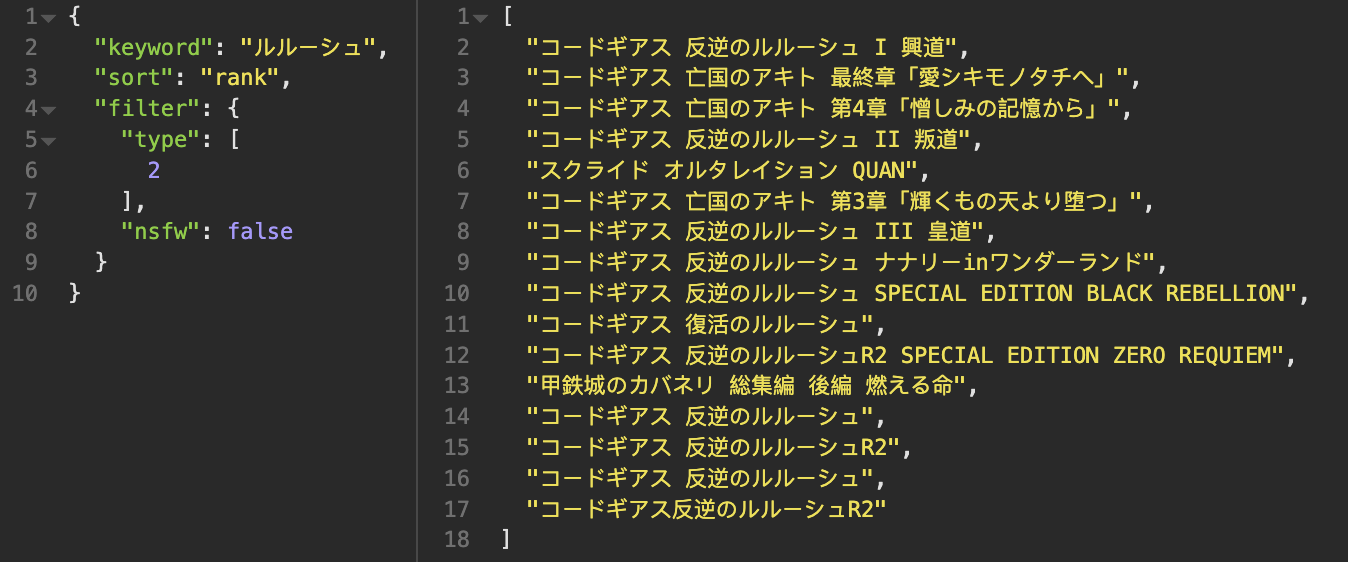
系列作品的排序顺序不合理

调优
字段的优化
当前设置的 searchable 列表为:Summary, Tag, Name (这里的Name同时包括了 name、nameCN和infobox中的“别名”),这是导致上述多个问题的主要原因。我将其修改为:
[
"name",
"name_cn",
"summary",
// tag 名字符串数组,按照标记数倒序
"tags",
// 这里的 type 是 type + platform 转换成对应文本的形式,如“OVA”“剧场版”等关键字
"type",
// bgm id,这里可以酌情考虑加或不加
// 区别在于是否想让搜索框直接搜索 id 出现内容
// 但这种做法偶尔会带来一些干扰,如较小的 id 号会匹配到标题或描述中的数字
// 所以这里仅放置在优先级最低的位置
"id",
]优化后前述 summary 占用过高权重的问题消失。
优化 ranking rules
默认的 ranking rules 以关键词匹配到的数量为最优先事项,这在 searchable attributes 较多,且包含 tags 这种字段的情况下明显不适合。
甚至官方的示例(电影条目搜索,与 bangumi 的场景非常相似)都是以此为反例说明如何调整 ranking rules……那么我们不妨先采用官方在这个场景下推荐的优先级:
[
// 相似度最优先
"exactness",
"words",
"typo",
"proximity",
"attribute",
"sort",
// id 在前的优先展示,主要是为了系列作品能有个很好的顺序
"id:asc",
// 以下酌情,我选择优先展示排行榜排名更高、评分更高的条目,且尽量优先展示 sfw 内容
"rank:asc",
"rate:desc",
"nsfw:asc",
]这优化了前述4的问题。
将 summary 移出可搜索字段
以上优化之后,问题3仍然不能得到很好的解决。同时,在设置关键词 cases 的过程中,也同样见到了许多相似的情况。
究其原因,summary 虽然是该条目的「简介」,但实际上其内容往往不局限于条目故事内容本身,经常包含对动画创作背景、制作人员、获得奖项等的介绍,这引入了大量毫不相干的关键词。
尝试将其去除,获得了很好的效果。
关于移除 summary 对搜索结果影响的进一步探讨
可能你会担心将 summary 移除出可搜索字段会导致一部分条目更难以被搜索到,我也曾有这个担心。但就像上一节所说,将其保留会导致远远更广泛的问题。更何况包含 summary 真的能提供更多的信息以供人检索吗?
Bangumi 条目的标签功能对搜索结果的优化意义重大,这一“由用户产生的标签”无疑是与“用户使用标签搜索”背后对于“标签”的理解是一致的,换句话说可以这么认为,标签功能为搜索提供了非常精准的人工优化。可能被用于搜索的关键词通常都能在这里找到,它比由机器胡乱分词(jieba 的分词效果也就那么回事……)的 summary(多数情况下)更精准和覆盖面更广。
所以至少在我的测试中,去除 summary 效果更好一些。
遗留问题
infobox 数据的标准化
由于我暂时没找到合适的方案解析 infobox 的数据,所以我提出的方案相比于现有方案,反而还少了 infobox 中的“别名”,但这部分是应该包含的,建议排在 nameCN 后面。
infobox 中其他的数据可能也有可以拿来用的,特别是用于精确匹配的高级搜索中的某个项目(如提供精准匹配某个制作公司、监督或出版社的功能)。但是因为 infobox 中的数据没有很好地标准化(至少在我看来是这样),所以这部分不在本次的考虑范围内,也许后续能有其他人继续研究这方面的内容吧。
一些边缘 case
这里列举一些早期想要优化掉,但实际上并没有找到方案的 case。
- 通过“Marcross delta”并不能找到“超时空要塞Δ”,虽然因为别名和 tags 的存在类似的场景大多不会有问题,但这个条目刚好无论是别名还是 tags 中都没有“delta”的出现。理论上,这里应该通过 meilisearch 的同义词功能解决,但是众多的场景如何确定同义词呢?过多的同义词是不是也会对搜索结果造成可见的干扰?我没有想到很好的办法。
TL;DR
- 将 searchable fields 设置为:
[ "name", "name_cn", // infobox 中的 “别名” "alias" "summary", "tags", "type", "id", ]
- 调整 ranking rules 为:
[ "exactness", "words", "typo", "proximity", "attribute", "sort", "id:asc", // 以下酌情 "rank:asc", "rate:desc", "nsfw:asc", ]
- filterable fields 可以选择这些
- id
- type
- platform
- rank
- rate (由rate_{1,10}计算而来)
- date
- eps
- nsfw
- infobox 中其他可精确匹配的字段(如制作公司、监督等)