|
| 1 | +{ |
| 2 | + "cells": [ |
| 3 | + { |
| 4 | + "cell_type": "markdown", |
| 5 | + "metadata": { |
| 6 | + "slideshow": { |
| 7 | + "slide_type": "slide" |
| 8 | + } |
| 9 | + }, |
| 10 | + "source": [ |
| 11 | + "\n", |
| 12 | + "\n", |
| 13 | + "# Sessions 2 & 3: Project layout and unit tests\n", |
| 14 | + "\n", |
| 15 | + "### Juan Luis Cano Rodríguez <jcano@faculty.ie.edu> - Master in Business Analytics and Big Data (2019-04-03)" |
| 16 | + ] |
| 17 | + }, |
| 18 | + { |
| 19 | + "cell_type": "markdown", |
| 20 | + "metadata": {}, |
| 21 | + "source": [ |
| 22 | + "## Triangular workflows in git\n", |
| 23 | + "\n", |
| 24 | + "When collaborating with a project hosted online on GitHub or GitLab, the most common setup is having a central repository, one remote fork per user, and local clones/checkouts:\n", |
| 25 | + "\n", |
| 26 | + "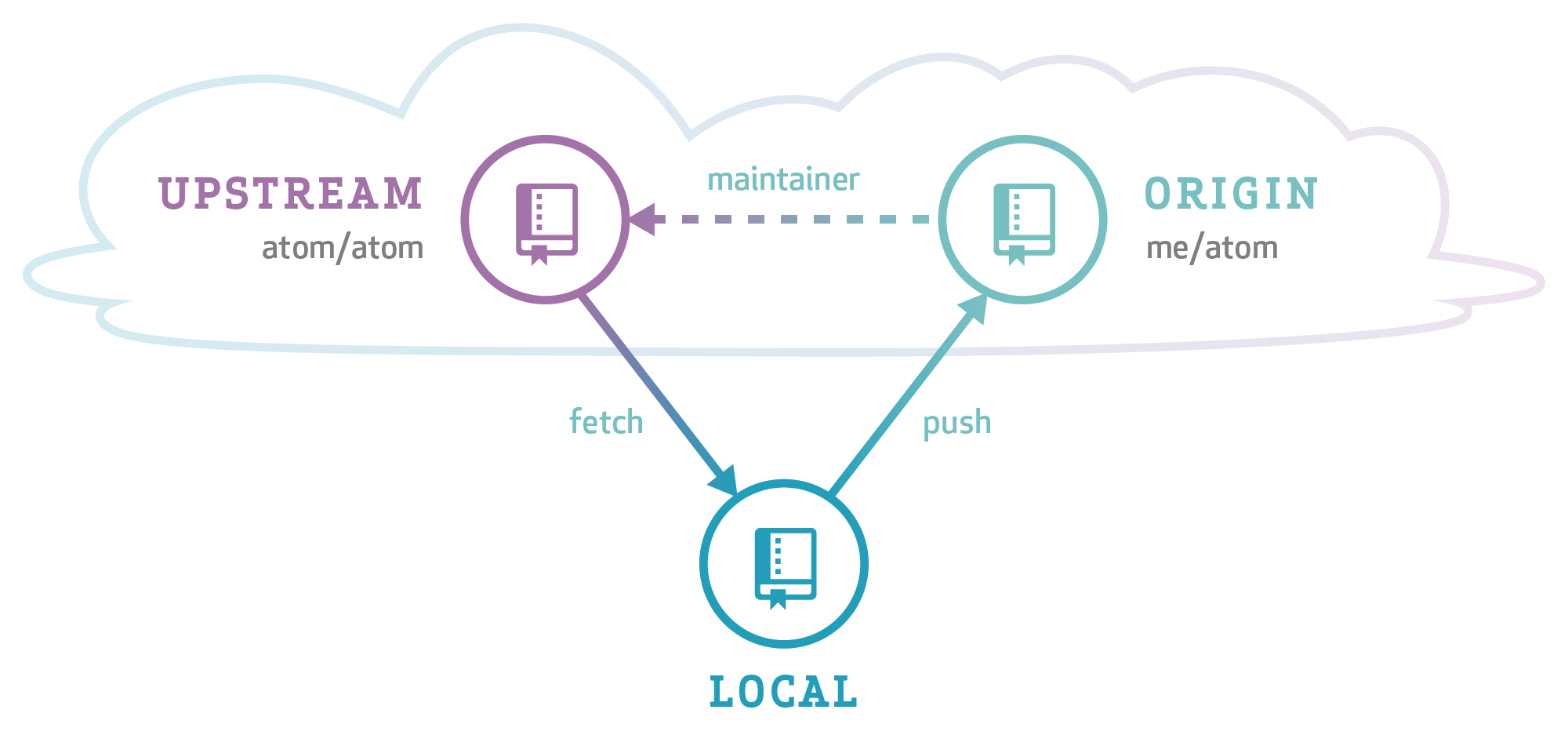\n", |
| 27 | + "\n", |
| 28 | + "(Source: https://github.blog/2015-07-29-git-2-5-including-multiple-worktrees-and-triangular-workflows/)\n", |
| 29 | + "\n", |
| 30 | + "Following this workflow requires discipline and sticking to a subset of actions and git commands to avoid common mistakes. This website contains all you need to know to setup your triangular workflow and we don't need to reproduce it here:\n", |
| 31 | + "\n", |
| 32 | + "https://www.asmeurer.com/git-workflow/\n", |
| 33 | + "\n", |
| 34 | + "*Notice* the different naming conventions between this website and the first image:\n", |
| 35 | + "\n", |
| 36 | + "1. **Convention 1**: upstream/origin/local\n", |
| 37 | + "2. **Convention 2**: origin/<username>/local\n", |
| 38 | + "\n", |
| 39 | + "We will be consistent with the Aaron Meurer guide and therefore use Convention 2 all the time.\n", |
| 40 | + "\n", |
| 41 | + "### ⚠ After creating a pull request ⚠\n", |
| 42 | + "\n", |
| 43 | + "After your pull request has been merged to `master`, your local `master` and `<username>/master` will be outdated with respect to `origin/master`. On the other hand, **you should avoid working on this branch anymore in the future**: remember branches should be ephemeral and short-lived.\n", |
| 44 | + "\n", |
| 45 | + "To put yourself in a clean state again, you have to:\n", |
| 46 | + "\n", |
| 47 | + "1. Click \"remove branch\" in the pull request (don't click \"remove fork\"!)\n", |
| 48 | + "2. `git checkout master` (go back to `master`)\n", |
| 49 | + "3. `git fetch origin` (**never, ever use `git pull` unless you know exactly what you're doing**)\n", |
| 50 | + "4. `git merge --ff-only origin master` (update your local `master` with `origin/master`, and fail if you accidentally made any commit in `master`)\n", |
| 51 | + "5. `git fetch -p <username>` (✨ acknowledge the removal of the remote branch ✨)\n", |
| 52 | + "6. `git branch -d old-branch` (remove the old branch)\n", |
| 53 | + "7. `git push <username> master` (update your fork with respect to `origin`)\n", |
| 54 | + "8. `git checkout -b new-branch` (start working in the new feature!)\n", |
| 55 | + "\n", |
| 56 | + "This process **has to be repeated after every pull request**.\n", |
| 57 | + "\n", |
| 58 | + "🌈 " |
| 59 | + ] |
| 60 | + }, |
| 61 | + { |
| 62 | + "cell_type": "markdown", |
| 63 | + "metadata": {}, |
| 64 | + "source": [ |
| 65 | + "## Project layout\n", |
| 66 | + "\n", |
| 67 | + "Most data science projects will start with a bunch of notebooks. However, at some point we will want to reuse code between them, and eventually put our models in production without the need to use the notebooks themselves ([unless you are Netflix](https://medium.com/netflix-techblog/notebook-innovation-591ee3221233)). Choosing a good project layout is extremely important to organize the code, avoid common pitfalls and be predictable (i.e. imitate the rest of the ecosystem to minimize surprise). On the other hand, there is lots (**lots**) of outdated, bad or wrong advice on the Internet about this topic, so here we will present The Truth™.\n", |
| 68 | + "\n", |
| 69 | + "### References\n", |
| 70 | + "\n", |
| 71 | + "* Packaging a Python library https://blog.ionelmc.ro/2014/05/25/python-packaging/\n", |
| 72 | + "* Less known packaging features and tricks https://blog.ionelmc.ro/presentations/packaging/\n", |
| 73 | + "* setuptools documentation https://setuptools.readthedocs.io/en/stable/setuptools.html" |
| 74 | + ] |
| 75 | + }, |
| 76 | + { |
| 77 | + "cell_type": "markdown", |
| 78 | + "metadata": {}, |
| 79 | + "source": [ |
| 80 | + "### The `src` layout\n", |
| 81 | + "\n", |
| 82 | + "```\n", |
| 83 | + "├─ src\n", |
| 84 | + "│ └─ packagename\n", |
| 85 | + "│ ├─ __init__.py\n", |
| 86 | + "│ └─ ...\n", |
| 87 | + "├─ tests\n", |
| 88 | + "│ └─ ...\n", |
| 89 | + "├─ README.txt\n", |
| 90 | + "├─ setup.py\n", |
| 91 | + "└─ setup.cfg\n", |
| 92 | + "```\n", |
| 93 | + "\n", |
| 94 | + "* The `src/packagename` contains the source code of the library.\n", |
| 95 | + " - The `packagename` is what users type after `import` in a Python script, and therefore should not contain special characters.\n", |
| 96 | + " - It should contain a `__init__.py` that can be empty (more on that below).\n", |
| 97 | + " - The `src` segment prevents you from *shooting yourself in the foot*, because it's common to do `import packagename` when you are developing, and this will import the code from the directory, not from your `sys.path`. Always include it.\n", |
| 98 | + "\n", |
| 99 | + "* The `tests` directory contains the tests. It **must not** contain any `__init__.py` because it's not meant to be imported as a package. In very specific cases it's included inside `src/packagename`.\n", |
| 100 | + "\n", |
| 101 | + "* Every project contains a `README.txt` that at least explains what the project is.\n", |
| 102 | + "\n", |
| 103 | + "* `setup.py` can be an extremely simple file containing only this:\n", |
| 104 | + "\n", |
| 105 | + "```\n", |
| 106 | + "from setuptools import setup\n", |
| 107 | + "\n", |
| 108 | + "setup()\n", |
| 109 | + "```\n", |
| 110 | + "\n", |
| 111 | + "(This requires `setuptools > 30.3.0`, released 8 Dec 2016)\n", |
| 112 | + "\n", |
| 113 | + "* `setup.cfg` contains the metadata of the project. The absolutely required fields are `name`, `version`, and `packages`, therefore you will need something like this:\n", |
| 114 | + "\n", |
| 115 | + "```\n", |
| 116 | + "[metadata]\n", |
| 117 | + "name = my_package\n", |
| 118 | + "version = 0.1.dev0\n", |
| 119 | + "\n", |
| 120 | + "# Magic! Don't touch below this line\n", |
| 121 | + "[options]\n", |
| 122 | + "package_dir=\n", |
| 123 | + " =src\n", |
| 124 | + "packages=find:\n", |
| 125 | + "\n", |
| 126 | + "[options.packages.find]\n", |
| 127 | + "where=src\n", |
| 128 | + "```\n", |
| 129 | + "\n", |
| 130 | + "The `name` is what users will have to type after `pip install` and therefore can contain hyphens. **Do not confuse this** with what users have to type on `import` (see above).\n", |
| 131 | + "\n", |
| 132 | + "With this layout, **you can `pip install` your code** in your Python environment:\n", |
| 133 | + "\n", |
| 134 | + "```\n", |
| 135 | + "$ pip install --editable .\n", |
| 136 | + "$ python\n", |
| 137 | + ">>> import packagename\n", |
| 138 | + ">>>\n", |
| 139 | + "```\n", |
| 140 | + "\n", |
| 141 | + "This is an alternative to modifying the `PYTHONPATH` environment variable (see first session)." |
| 142 | + ] |
| 143 | + }, |
| 144 | + { |
| 145 | + "cell_type": "markdown", |
| 146 | + "metadata": {}, |
| 147 | + "source": [ |
| 148 | + "### Version numbers\n", |
| 149 | + "\n", |
| 150 | + "* Version numbers for Python packages are explained in [PEP 440](https://www.python.org/dev/peps/pep-0440/)\n", |
| 151 | + "* For libraries, the most widely used convention is [semantic versioning](https://semver.org/): `X.Y.Z`\n", |
| 152 | + " - `Z` **must** be incremented if only backwards compatible bug fixes are introduced (a bug fix is defined as an internal change that fixes incorrect behavior)\n", |
| 153 | + " - `Y` **must** be incremented every time there is new, backwards-compatible functionality\n", |
| 154 | + " - `X` **must** be incremented every time there are backwards-incompatible changes\n", |
| 155 | + "* Between releases, the version should have the `.dev0` suffix\n", |
| 156 | + "* Recommendation: start with `0.1.dev0` (development version), then make a `0.1.0` release, then progress to `0.1.1` for quick fixes and `0.2.0` for new functionality, and when you want to make a promise of *relative* stability jump to `1.0.0`\n", |
| 157 | + "* For applications, other conventions are more appropriate, like [calendar versioning](http://calver.org/): `[YY]YY.MM.??" |
| 158 | + ] |
| 159 | + }, |
| 160 | + { |
| 161 | + "cell_type": "markdown", |
| 162 | + "metadata": {}, |
| 163 | + "source": [ |
| 164 | + "### Exercise\n", |
| 165 | + "\n", |
| 166 | + "1. Create a directory called `nlp-utils`\n", |
| 167 | + "2. `git init` inside it\n", |
| 168 | + "3. Create a basic `src` layout in it, with `name = nlp-utils` and the source in `src/nlp_utils`\n", |
| 169 | + "4. Create a `src/test_package/__init__.py` with a `print(\"Hello, world!\")`\n", |
| 170 | + "5. Install it in editable mode using `pip` and test that `>>> import nlp_utils` prints `Hello, world!`\n", |
| 171 | + "6. Include a `README.txt` and an appropriate `.gitignore` from http://gitignore.io/\n", |
| 172 | + "7. Commit the changes\n", |
| 173 | + "8. Create a new GitHub project and push the repository there\n", |
| 174 | + "\n", |
| 175 | + "🎉" |
| 176 | + ] |
| 177 | + }, |
| 178 | + { |
| 179 | + "cell_type": "markdown", |
| 180 | + "metadata": {}, |
| 181 | + "source": [ |
| 182 | + "## Testing\n", |
| 183 | + "\n", |
| 184 | + "Testing is **essential**. Many developers get along without testing their software, but as common wisdom says:\n", |
| 185 | + "\n", |
| 186 | + "<blockquote class=\"twitter-tweet\"><p lang=\"en\" dir=\"ltr\">If you use software that lacks automated tests, you are the tests.</p>— Jenny Bryan (@JennyBryan) <a href=\"https://twitter.com/JennyBryan/status/1043307291909316609?ref_src=twsrc%5Etfw\">September 22, 2018</a></blockquote> <script async src=\"https://platform.twitter.com/widgets.js\" charset=\"utf-8\"></script>\n", |
| 187 | + "\n", |
| 188 | + "Computers excel at doing repetitive tasks: they basically never make mistakes (the mistake might be in what we told the computer to do). Humans, on the other hand, fail more often, especially under pressure, or on Friday afternoons and Monday mornings. Therefore, instead of letting the humans be the tests, we will use the computer to **frequently verify that our software works as specified**.\n", |
| 189 | + "\n", |
| 190 | + "### References\n", |
| 191 | + "\n", |
| 192 | + "* pytest documentation https://docs.pytest.org\n", |
| 193 | + "\n", |
| 194 | + "### Further reading\n", |
| 195 | + "\n", |
| 196 | + "* Extreme Programming https://www.wikiwand.com/en/Extreme_programming\n", |
| 197 | + "* Obey the Testing Goat! http://www.obeythetestinggoat.com/pages/book.html#toc\n", |
| 198 | + "* (Shameless self-plug) Testing and validation approaches for scientific software https://nbviewer.jupyter.org/format/slides/github/poliastro/oscw2018-talk/blob/master/Talk.ipynb" |
| 199 | + ] |
| 200 | + }, |
| 201 | + { |
| 202 | + "cell_type": "markdown", |
| 203 | + "metadata": {}, |
| 204 | + "source": [ |
| 205 | + "### Test-Driven Development\n", |
| 206 | + "\n", |
| 207 | + "> Make it work. Make it right. Make it fast.\n", |
| 208 | + "\n", |
| 209 | + "Test-Driven Development shifts the focus of software development to writing tests. The \"practice of test-first development, planning and writing tests before each micro-increment\" is not new: it was in use at NASA in the early 1960s ([source](https://www.wikiwand.com/en/Extreme_programming)). In the 1990s, Extreme Programming took this concept to the extreme by the use of **small, automated** tests.\n", |
| 210 | + "\n", |
| 211 | + "The \"test-driven development mantra\" is <span style=\"color: red\">**Red**</span> - <span style=\"color: green\">**Green**</span> - **Refactor**:\n", |
| 212 | + "\n", |
| 213 | + "\n", |
| 214 | + "\n", |
| 215 | + "1. Write a test. <span style=\"color: red\">**Watch it fail**</span>.\n", |
| 216 | + "2. Write just enough code to <span style=\"color: green\">**pass the test**</span>.\n", |
| 217 | + "3. Improve the code without breaking the test.\n", |
| 218 | + "4. Repeat." |
| 219 | + ] |
| 220 | + }, |
| 221 | + { |
| 222 | + "cell_type": "markdown", |
| 223 | + "metadata": {}, |
| 224 | + "source": [ |
| 225 | + "### Testing in Python\n", |
| 226 | + "\n", |
| 227 | + "Summary: **use pytest**. Everybody does. It rocks.\n", |
| 228 | + "\n", |
| 229 | + "[pytest](https://docs.pytest.org/) is a testing framework for Python that makes writing tests extremely easy. It is much more powerful than the standard library equivalent, `unittest`. To use it, you need to install it first:\n", |
| 230 | + "\n", |
| 231 | + "```\n", |
| 232 | + "$ pip install pytest\n", |
| 233 | + "```\n", |
| 234 | + "\n", |
| 235 | + "The simplest test is **a function with an `assert`**. The `assert` statement just fails if the contents are not `True`, and else it does nothing. *It should only be used for testing*." |
| 236 | + ] |
| 237 | + }, |
| 238 | + { |
| 239 | + "cell_type": "code", |
| 240 | + "execution_count": 1, |
| 241 | + "metadata": {}, |
| 242 | + "outputs": [], |
| 243 | + "source": [ |
| 244 | + "assert True # Does nothing" |
| 245 | + ] |
| 246 | + }, |
| 247 | + { |
| 248 | + "cell_type": "code", |
| 249 | + "execution_count": 2, |
| 250 | + "metadata": {}, |
| 251 | + "outputs": [ |
| 252 | + { |
| 253 | + "ename": "AssertionError", |
| 254 | + "evalue": "", |
| 255 | + "output_type": "error", |
| 256 | + "traceback": [ |
| 257 | + "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", |
| 258 | + "\u001b[0;31mAssertionError\u001b[0m Traceback (most recent call last)", |
| 259 | + "\u001b[0;32m<ipython-input-2-40f67ddecc26>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0;32massert\u001b[0m \u001b[0;32mFalse\u001b[0m \u001b[0;31m# Fails!\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m", |
| 260 | + "\u001b[0;31mAssertionError\u001b[0m: " |
| 261 | + ] |
| 262 | + } |
| 263 | + ], |
| 264 | + "source": [ |
| 265 | + "assert False # Fails!" |
| 266 | + ] |
| 267 | + }, |
| 268 | + { |
| 269 | + "cell_type": "code", |
| 270 | + "execution_count": 3, |
| 271 | + "metadata": {}, |
| 272 | + "outputs": [ |
| 273 | + { |
| 274 | + "ename": "AssertionError", |
| 275 | + "evalue": "Math is wrong", |
| 276 | + "output_type": "error", |
| 277 | + "traceback": [ |
| 278 | + "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", |
| 279 | + "\u001b[0;31mAssertionError\u001b[0m Traceback (most recent call last)", |
| 280 | + "\u001b[0;32m<ipython-input-3-c2bde6a3219c>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0;32massert\u001b[0m \u001b[0;36m2\u001b[0m \u001b[0;34m+\u001b[0m \u001b[0;36m2\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0;36m5\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m\"Math is wrong\"\u001b[0m \u001b[0;31m# Fails with a message\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m", |
| 281 | + "\u001b[0;31mAssertionError\u001b[0m: Math is wrong" |
| 282 | + ] |
| 283 | + } |
| 284 | + ], |
| 285 | + "source": [ |
| 286 | + "assert 2 + 2 == 5, \"Math is wrong\" # Fails with a message" |
| 287 | + ] |
| 288 | + }, |
| 289 | + { |
| 290 | + "cell_type": "markdown", |
| 291 | + "metadata": {}, |
| 292 | + "source": [ |
| 293 | + "### Example\n", |
| 294 | + "\n", |
| 295 | + "> Write a function that **tokenizes a sentence** (i.e. splits it into a list of words)\n", |
| 296 | + "\n", |
| 297 | + "First, we write a (failing) test:\n", |
| 298 | + "\n", |
| 299 | + "```python\n", |
| 300 | + "# tests/test_tokenize.py\n", |
| 301 | + "from nlp_utils import tokenize # This will fail right away!\n", |
| 302 | + "\n", |
| 303 | + "def test_tokenize_returns_expected_list():\n", |
| 304 | + " sentence = \"This is a sentence\"\n", |
| 305 | + " expected_tokens = [\"This\", \"is\", \"a\", \"sentence\"]\n", |
| 306 | + "\n", |
| 307 | + " tokens = tokenize(sentence)\n", |
| 308 | + "\n", |
| 309 | + " assert tokens == expected_tokens\n", |
| 310 | + "```\n", |
| 311 | + "\n", |
| 312 | + "and we run it from the command line:\n", |
| 313 | + "\n", |
| 314 | + "```\n", |
| 315 | + "$ pytest\n", |
| 316 | + "...\n", |
| 317 | + "```\n", |
| 318 | + "\n", |
| 319 | + "Then we fix the test in the simplest way:\n", |
| 320 | + "\n", |
| 321 | + "```python\n", |
| 322 | + "# src/nlp_utils/__init__.py\n", |
| 323 | + "def tokenize(sentence):\n", |
| 324 | + " return sentence.split()\n", |
| 325 | + "```\n", |
| 326 | + "\n", |
| 327 | + "And we watch it pass!\n", |
| 328 | + "\n", |
| 329 | + "```\n", |
| 330 | + "$ pytest\n", |
| 331 | + "...\n", |
| 332 | + "```" |
| 333 | + ] |
| 334 | + }, |
| 335 | + { |
| 336 | + "cell_type": "markdown", |
| 337 | + "metadata": {}, |
| 338 | + "source": [ |
| 339 | + "### Exercise\n", |
| 340 | + "\n", |
| 341 | + "1. Add a new test that checks that `tokenize(sentence, lower=True)` returns a list of *lowercase* tokens.\n", |
| 342 | + "2. Fix the test *in a way the first one doesn't break*.\n", |
| 343 | + "3. *Extra*: Use `@pytest.mark.parametrize` to pass two different sentences to the new test https://docs.pytest.org/en/latest/example/parametrize.html" |
| 344 | + ] |
| 345 | + } |
| 346 | + ], |
| 347 | + "metadata": { |
| 348 | + "kernelspec": { |
| 349 | + "display_name": "Python 3", |
| 350 | + "language": "python", |
| 351 | + "name": "python3" |
| 352 | + } |
| 353 | + }, |
| 354 | + "nbformat": 4, |
| 355 | + "nbformat_minor": 2 |
| 356 | +} |
0 commit comments