[GRNN] Learning Spatial Common Sense with Geometry-Aware Recurrent Networks (April 2019 CVPR) #24
Description
0. Article Information and Links
- Paper's project website: https://ricsonc.github.io/grnn/
- Semantic Scholar: https://www.semanticscholar.org/paper/Learning-Spatial-Common-Sense-With-Geometry-Aware-Tung-Cheng/524cb4afc83a36a4f126de541ceadda26797ff54
- Release date: 2019/04/09
- Number of citations (as of 2020/08/17): 19
- Talk that discusses this paper from CVPR 2020 3D Scene Understanding Workshop: https://www.youtube.com/watch?v=1d-KsKjWUbo&t=38m26s
1. What do the authors try to accomplish?
- learn 3D understanding of a scene. "Create geometrically consistent mapping between world scenes and 3D latent features"
- Predict novel camera views given short frame sequences
- 3D object detection based only on 3D latent features, no 2D; persist even when occluded
- provide architecture for spatial common sense
Seek to answer:
- Do the proposed Geometric RNNs learn spatial common sense?
- Are geometric structural biases necessary for spatial common sense to emerge?
- How well do GRNNs perform on egomotion estimation and 3D object detection?
2. What's great compared to previous research?
- SOTA computer vision relies on internet images with static viewpoints. Pictures are the output of human experts
- But real agents that move around see things from many angles. Images might not even be labelable because what is seen is half out of view or occluded.
- Propose an architecture, GRNN, that inherently has 3D structural bias. Similar to how convolutions have spatial bias, GRNNs have 3D spatial bias.
- GRNN latent space supports scene arithmetic, e.g. add or subtract 3D objects.

- suggests that 3D latent space and egomotion-stabilization are necessary architectural choices for spatial reasoning to emerge.
3. Where are the key elements of the technology and method?
Methods
Geometric Recurrent Neural Networks
Outperform geometry unaware nets.
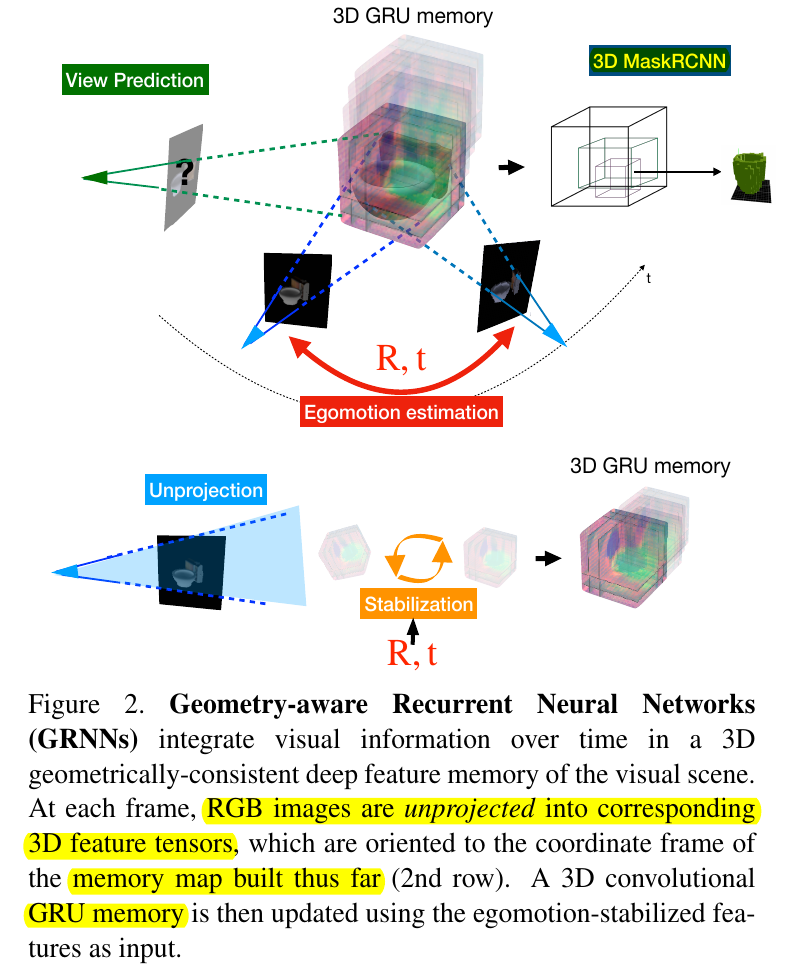
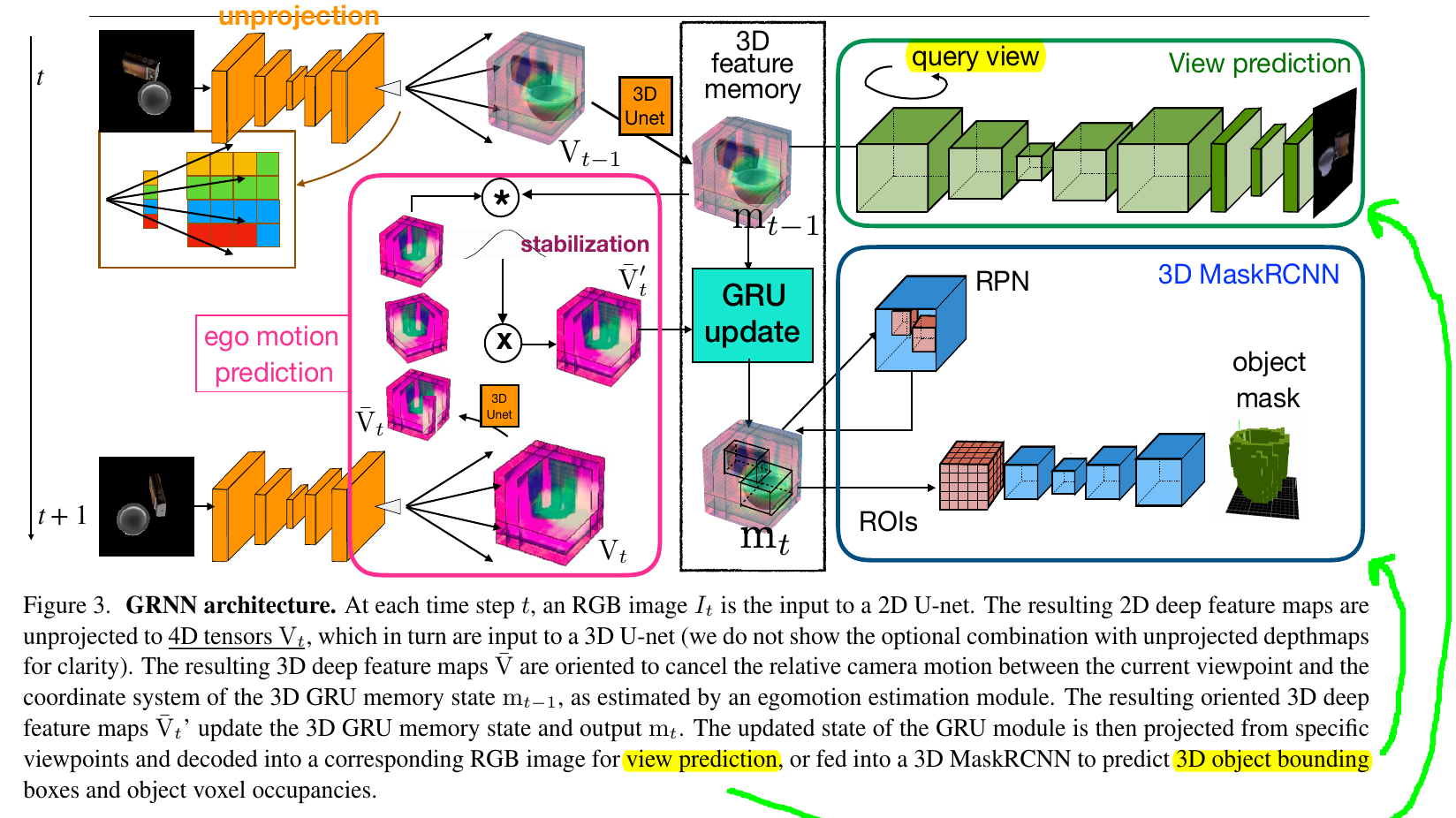
Egomotion-Stabilized Convolutions
Proposed by Cheng et al., but also used here.
After 2D is unprojected into 3D, it's probably in a different 3D orientation. Therefore, account for egomotion (camera motion) differences by "normalizing" (aka stabilizing) the 3D into the same orientation for GRU memory.
Self-supervised Approach
One of the central contributions of this work. 2D --> 3D --> 2D. Can use a separate 2D view as the ground truth, and compare with what's extracted from the 3D representation.
Experiments
Novel View Synthesis
New views given the 3D latent representation.

Object Permanence
Object detection that persists for heavily occluded objects
Scene Arithmetic
Add and subtract within the 3D latent representation accurately reflected in the projected result.
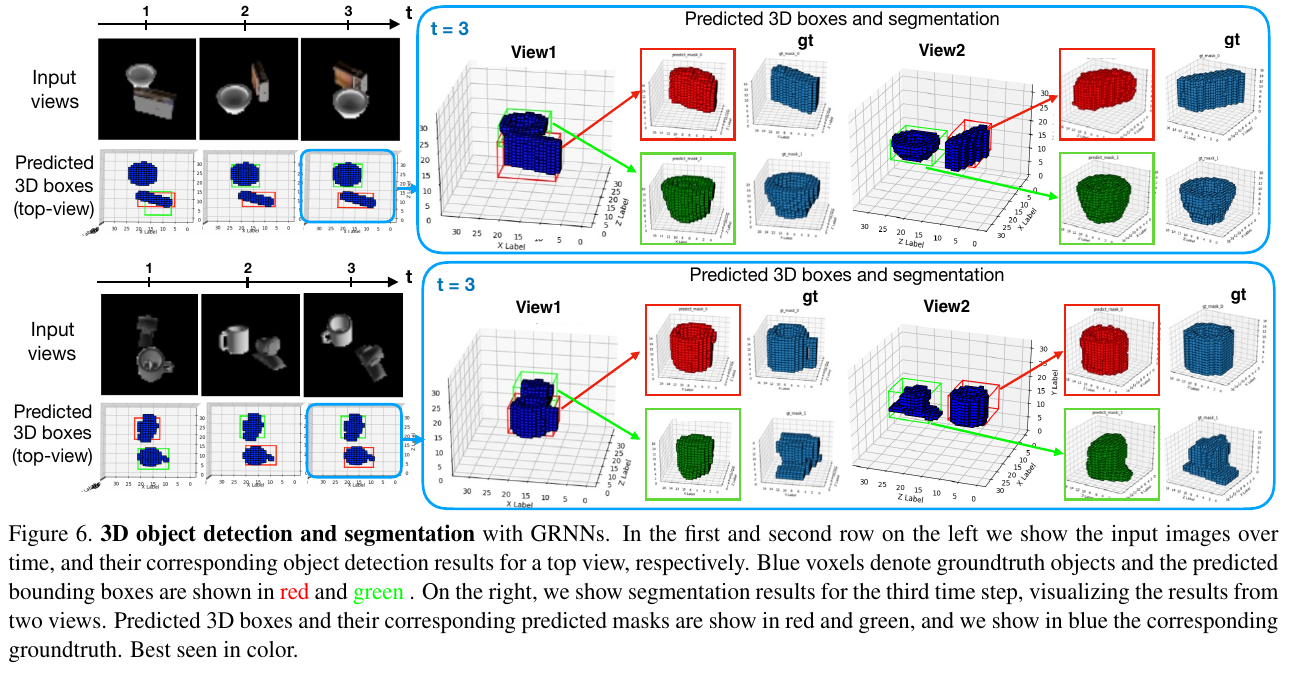
3D Segmentation
Attaches a 3D version of MaskRCNN to predict 3D meshes; then compute loss of generated 3D mesh against true 3D mesh.
4. How do the authors measure success?
Qualitative
Compare to Tower baseline, visually looks better.
Quantitiatve
3D object detection and segmentation using Intersection over Union (IoU).
5. How did you verify that it works?
6. Things to discuss? (e.g. weaknesses, potential for future work, relation to other work)
Limitations are: restricted to static scenes. Restricted to camera orbiting a fixed location; no camera translation used.
7. Are there any papers to read next?
- Followup paper that works on camera translations over video: http://www.cs.cmu.edu/~aharley/viewcontrast/
- Reminds me of recent Free View Synthesis paper https://www.youtube.com/watch?v=JDJPn3ZtfZs