You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
(python)
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
first = Node(1)
second = Node(2)
third = Node(3)
first.next = second
second.next = third
first.value = 6
(python)
class LinkedList(object):
def __init__(self):
self.head = None
self.tail = None
def append(self, value):
new_node = Node(value)
if self.head is None:
self.head = new_node
self.tail = new_node
# 맨 뒤의 node가 new_node를 가리켜야 한다.
else:
self.tail.next = new_node
self.tail = self.tail.next
ll = LinkedList()
ll.append(1)
ll.append(2)
ll.append(3)
ll.append(4)
⇒ 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료구조입니다. 삽입과 삭제가 O(1)이 걸리며 탐색에는 O(n)이 걸린다.
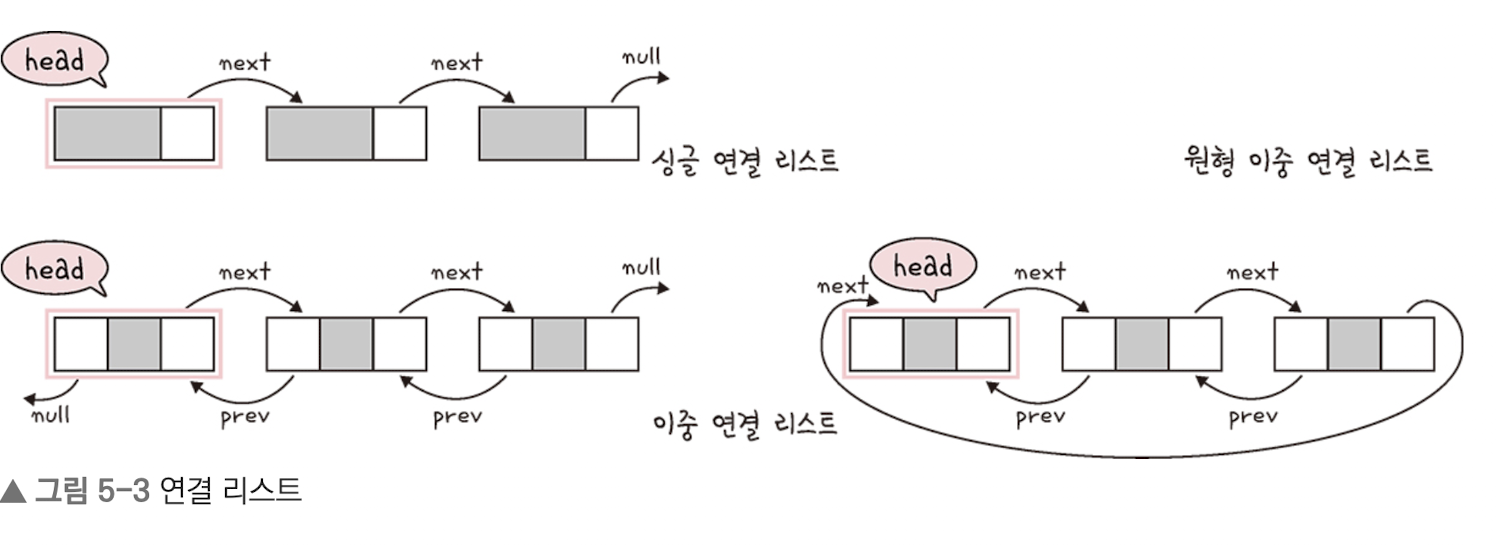
prev 포인터 , next 포인터
⇒ 앞과 뒤의 노드를 연결시킨 것이 연결 리스트
⇒ 맨 앞에 있는 노드를 헤드(head)
싱글 연결 리스트 ⇒ next 포인터만 가진다.
이중 연결 리스트 ⇒ next 포인터와 prev 포인터를 가진다.
이중 연결 리스트 push_front(), push_back, insert()등의 함수가 있다.
원형 이중 연결 리스트 ⇒ 이중 연결 리스트와 같지만 마지막 노드의 next 포인터가 헤드 노드를 가리킨다.
5.2.2 배열(ArrayList)
List ↔ (Set)
Python에서 Arraylist는 이미 List 로 구현이 되어있다.
배열은 선언시에 size를 정하여 해당 size만큼의 연속된 메모리 할당 받아 data를 연속적/순차적으로 저장하는 자료구조
int arr[5] = {3,7,4,2,6}
// size가 5인 int형 배열 선언
배열은 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터 모은 집합
중복을 허용하고 순서가 있다.
정적 배열기반 설명
탐색에 O(1)이 되고
랜덤 접근(random access)이 가능
삽입, 삭제 O(n)이 걸린다.
데이터 추가, 삭제 ⇒ 연결 리스트이 유리
탐색 ⇒ 배열이 유리
배열 ⇒ 인덱스에 해당하는 원소 빠르게 접근 또는 데이터 쌓고 싶을 때 사용
순차적 접근, 랜덤 접근은 아래와 같다.
배열 / 연결 리스트
배열은 상자를 순서대로 나열한 데이터 구조
몇 번째 상자인지만 알면 상자의 요소를 끄집어낼 수 있다.
연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조, 상자 안의 요소 알기 위해 하나씩 상자 내부 확인해봐야 함
탐색은 배열이 빠르고 연결 리스트는 느림
배열의 경우 상자 위에 있는 요소 탐색하면 됨
연결 리스트는 상자를 열어야 하고
선을 기반으로 순차적으로 열어야 한다.
데이터 추가 및 삭제는 연결리스트가 더 빠르고 배열이 느림
배열은 모든 상자를 앞으로 옮겨야 추가 가능
연결 리스트는 선을 바꿔서 연결해주기만 하면 됨
5.2.3 벡터
벡터는 동적으로 요소를 할당할 수 있는 동적 배열
컴파일 시점에 개수 모르면 벡터 써야한다.
중복을 허용하고 순서가 있고 랜덤 접근이 가능
탐색과 맨 뒤의 요소를 삭제, 삽입하는 데 O(1)이 걸림, 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)의 시간 걸림
뒤에서부터 삽입하는 push_back() / O(1)의 시간 걸림
벡터의 크기가 증가되는 시간 복잡도가 amortized 복잡도, 상수 시간 복잡도 O(1)과 유사한 시간 복잡도를 가지기 때문
push_back()을 한다 해서 매번 크기가 증가하는 것이 아니라 2의 제곱승 + 1마다 크기를 2배로 늘림
ci를 i번째 push_back()을 할 때 드는 비용(cost)이라 하면 ci는 1 또는 1 + 2**k라는 것을 알 수 있다. n번 push_back()을 한다 했을 때 드는 비용 T(n)은 아래와 같다.
뒤부터 요소를 더하는 push_back(), 맨 뒤부터 지우는 pop_back(), 지우는 erase(), 요소를 찾는 find(), 배열을 초기화하는 clear() 함수가 있다.
- 두개의 코드는 같은 코드
- 벡터의 요소를 순차적으로 탐색
- v에 pair라는 값이 들어가면 for (pair a : v) 방식으로 순회
5.2.4 스택
LIFO(Last In First Out) : 스택은 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는 성질을 가진 자료 구조
재귀적인 함수, 알고리즘에 사용
웹 브라우저 방문 기록 등에 쓰임
삽입 및 삭제 O(1), 탐색 O(n)
5.2.5 큐
FIFO(First In First Out) : 큐는 먼저 집어넣은 데이터가 먼저 나오는 성질을 지닌 자료 구조
삽입 및 삭제 O(1), 탐색 O(n)
CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비 우선 탐색, 캐시 등에 사용
reacted with thumbs up emoji reacted with thumbs down emoji reacted with laugh emoji reacted with hooray emoji reacted with confused emoji reacted with heart emoji reacted with rocket emoji reacted with eyes emoji
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
연결 리스트, 배열, 벡터
선형 자료 구조
5.2.1 연결리스트
Node를 활용해서 링크드리스트 트리 등 다양하게 구현이 가능하다.
LinkedList 틀
Linked List 구현
get
remove
insert_back()
⇒ 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료구조입니다. 삽입과 삭제가 O(1)이 걸리며 탐색에는 O(n)이 걸린다.
prev 포인터 , next 포인터
⇒ 앞과 뒤의 노드를 연결시킨 것이 연결 리스트
⇒ 맨 앞에 있는 노드를 헤드(head)
5.2.2 배열(ArrayList)
List ↔ (Set)
Python에서 Arraylist는 이미 List 로 구현이 되어있다.
배열은 선언시에 size를 정하여 해당 size만큼의 연속된 메모리 할당 받아 data를 연속적/순차적으로 저장하는 자료구조
배열 / 연결 리스트
5.2.3 벡터
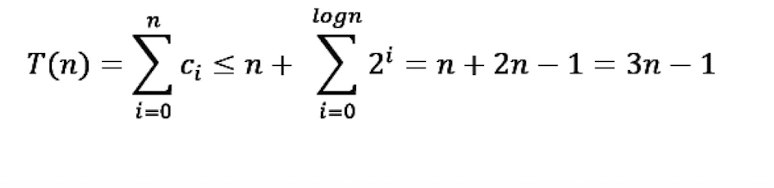
뒤부터 요소를 더하는 push_back(), 맨 뒤부터 지우는 pop_back(), 지우는 erase(), 요소를 찾는 find(), 배열을 초기화하는 clear() 함수가 있다. - 두개의 코드는 같은 코드 - 벡터의 요소를 순차적으로 탐색 - v에 pair라는 값이 들어가면 for (pair a : v) 방식으로 순회5.2.4 스택
5.2.5 큐
<출처 및 참고 : 면접을 위한 CS 전공지식 노트 - 주홍철 >
Beta Was this translation helpful? Give feedback.
All reactions