Replies: 8 comments
-
|
Sounds useful as a way to know whether there was a regression. Reminds me a bit of http://speed.pypy.org It would be nice as a continous job and published results somewhere. Maybe we can already store build artifacts from Travis runs (benchmark results in JSON) and present them grouped in a webapp in the future? |
Beta Was this translation helpful? Give feedback.
-
|
I acknowledge that CI performance will vary but it should be enough to catch serious performance regression. |
Beta Was this translation helpful? Give feedback.
-
yep that would be great. I imagine that the webapp would be built with RES. That would be quite meta 😃 |
Beta Was this translation helpful? Give feedback.
-
|
So I had a closer look at the alleged issue that reading events in RES 0.12 is 42 times slower than in RES 0.11. It turned out that indeed there is an issue but in my benchmark, not in RES. Correct results below: What was the issue then? The API in RES 0.12 has changed from def publish_event(event, stream_name)to keyword arguments def publish_event(event, stream_name:)The benchmark assumed keyword arguments for all RES versions though. It's a valid assumption for RES >= 0.12 but here's what happens in RES <= 0.11 # it passes a hash as a stream name. Not a string!
es.publish_event(some_event, stream_name: "some_stream")
# INSERT INTO event_store_events (stream_name, ...)
# VALUES ('{"stream_name" => "some_stream"}', ...)
# Now this reads zero events because "some_stream" is empty
es.read_stream_events_formward("some_stream")In other words the benchmark stated that reading zero events is 42x faster than reading 50 events. Thank you captain obvious. Fix: mlomnicki/res-benchmarks@6626483 Lesson learnt: TDD your benchmarks? 🤔 |

Beta Was this translation helpful? Give feedback.
-
|
@mlomnicki I think it would be very beneficial and it makes sense. As to HOW... I believe the mono-repo could have a A separate repo above would know how to checkout to specific versions of the gem and run the benchmark. I believe it might have been a better solution because one would need to continue keep the benchmarks working. The downside is, it would be hard to benchmark historical code with a certain scenario, unless we maintain that scenario on many branches. |
Beta Was this translation helpful? Give feedback.
-
|
What kind of benchmarks would you like to see?
|
Beta Was this translation helpful? Give feedback.
-
|
@pawelpacana all sound nice
These might require multiple producers and contention to see any actual effect. |
Beta Was this translation helpful? Give feedback.
-
|
https://rubybench.org could be a good start |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
The discussion on the implementation of optimistic locking made me think that it would be beneficial to have an automated way to benchmark RES. Reasons are pretty obvious
I came up with the list of the following requirements:
This is an initial attempt to implement such solution https://github.com/mlomnicki/res-benchmarks
For now there are 2 benchmarks
It benchmarks the following RES versions
The benchmarks have already proved to be useful. The "read" benchmark discovered that there was a major regression in RES 0.12.
https://benchmark.fyi/T
As you can see the last version where reading events is efficient is 0.11. In 0.12 reading from stream became 42x slower.
No surprises when it comes to publishing events
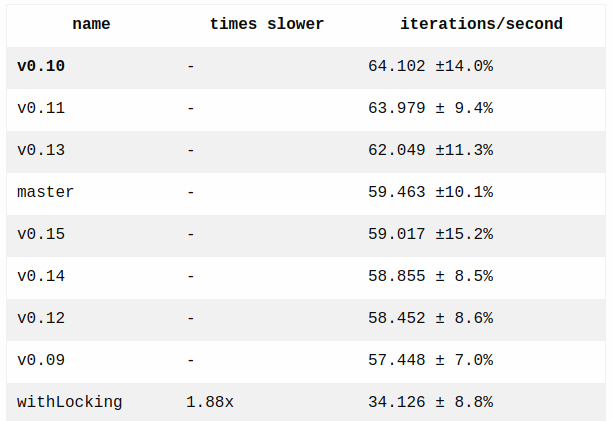
http://benchmark.fyi/U
I'd like to get some feedback from you. In particular:
Obviosuly there's a huge room for improvement
Feedback is more than welcome
Beta Was this translation helpful? Give feedback.
All reactions