Improve efficency of the posthog-event pool #13260
Description
In what situation are you experiencing subpar performance?
The posthog-event pool scales too big during peak hours, increasing costs above what one would expect.
First findings
After adding custom Sentry spans and running a local 50 req/s stress test, here are the typical timings one can observe:
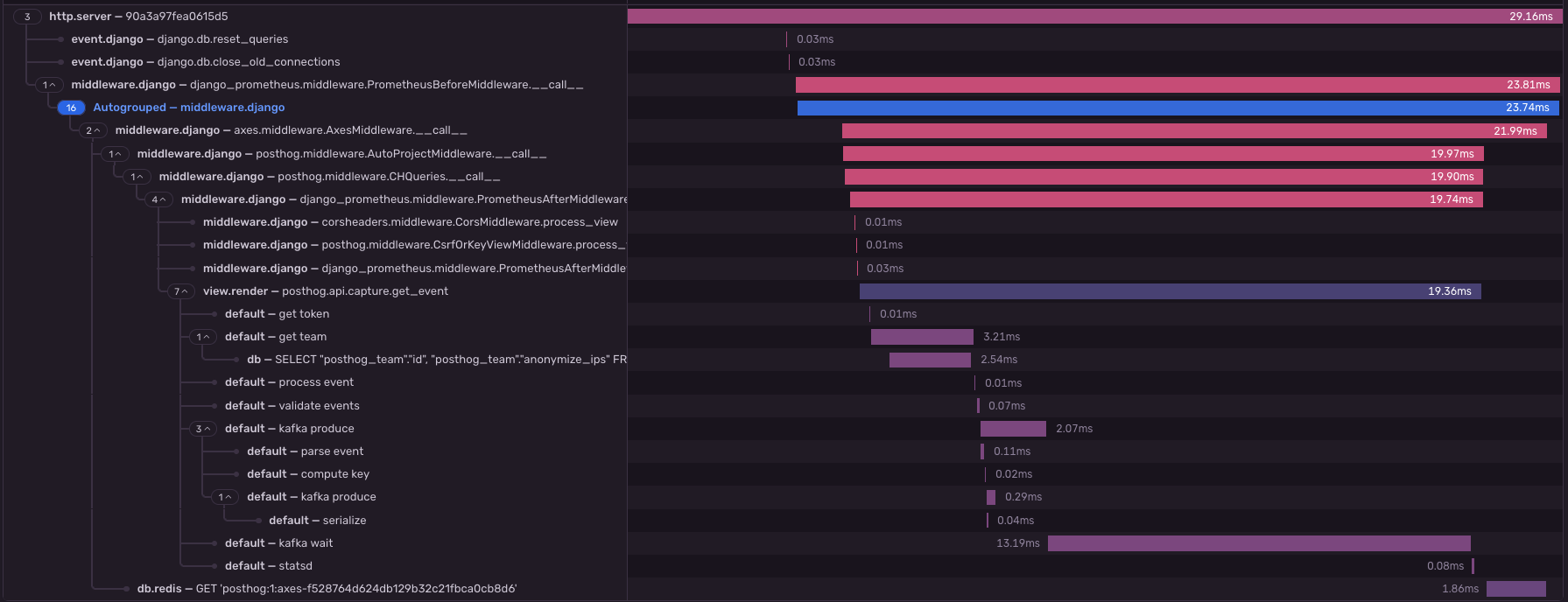
This is tracing on wall time, not profiling on cpu time, we can see in it that cpu-bound operations (event parsing, serialization...) are actually pretty small compared to the rest. The biggest contributors to latency seem to be:
- the middleware chain, especially Axes, which should be disabled on this pool
get_event_ingestion_context(get team span), with one uncached PG request per batch- syncronously waiting on Kafka writes (the untagged end of
kafka produce, pluskafka wait): we might be able to tune the producer latency down, but we might hit diminishing returns fast here
I also run some profiling with pyroscope and results are pretty much aligned with the tracing results above.
Action plan
- cache calls to
get_event_ingestion_contextwith a bounded LRU cache to - skip most middlewares on the posthog-event pool, via a additional envvar in the chart that we'll read in
settings/web.pyto build the middleware chain - investigate what knobs the python kafka library exposes to reduce producer latency
- when ingesting batches, do a single kafka produce call for the whole batch, instead of one per message
- discuss transitionning to an async request handler (stack/language TDB), so that request throughput is not linked to Kafka latency