Project Created By - Ali Quidwai and Nagharjun
Not every organization will have the resources or capability to build a large language model from scratch due to the extensive dataset and computational requirements involved in the process
We believe that Model as a Service will become the standard in the industry, and that the most effective way to improve already trained large language models (LLMs) with over 100 billion parameters will be through fine-tuning
In this context, we propose an optimized method for fine-tuning Large LLM with a high accuracy rate on a limited amount of training data, which is known as few-shot learning
This is a project using transfer learning to fine tune GPT3 Language Model. With low amount of data, we are efficiently fine tuning the model based on a specific task. We also explore a cost effective way for training.
We implement transfer learning strategy for fine tuning a GPT-3 model to work on script generation for a language model.
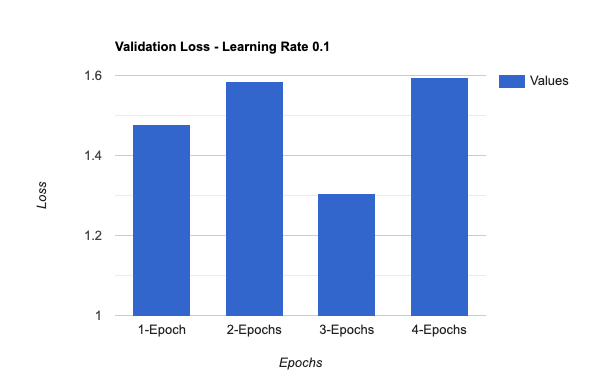
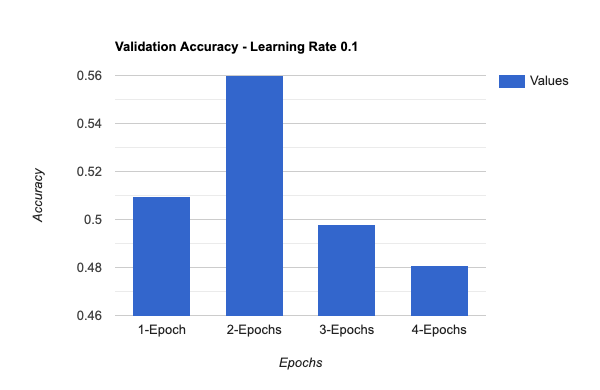
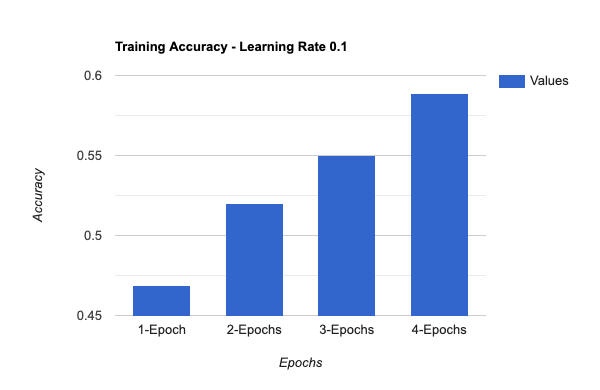
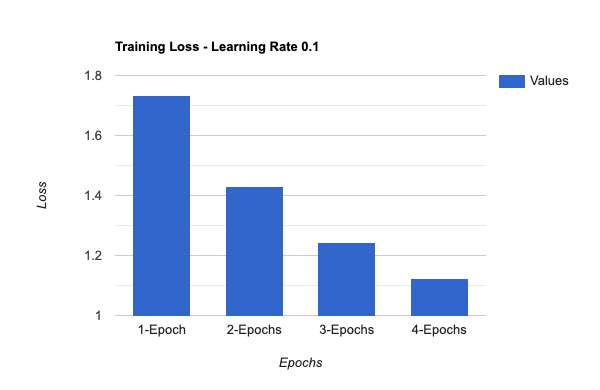
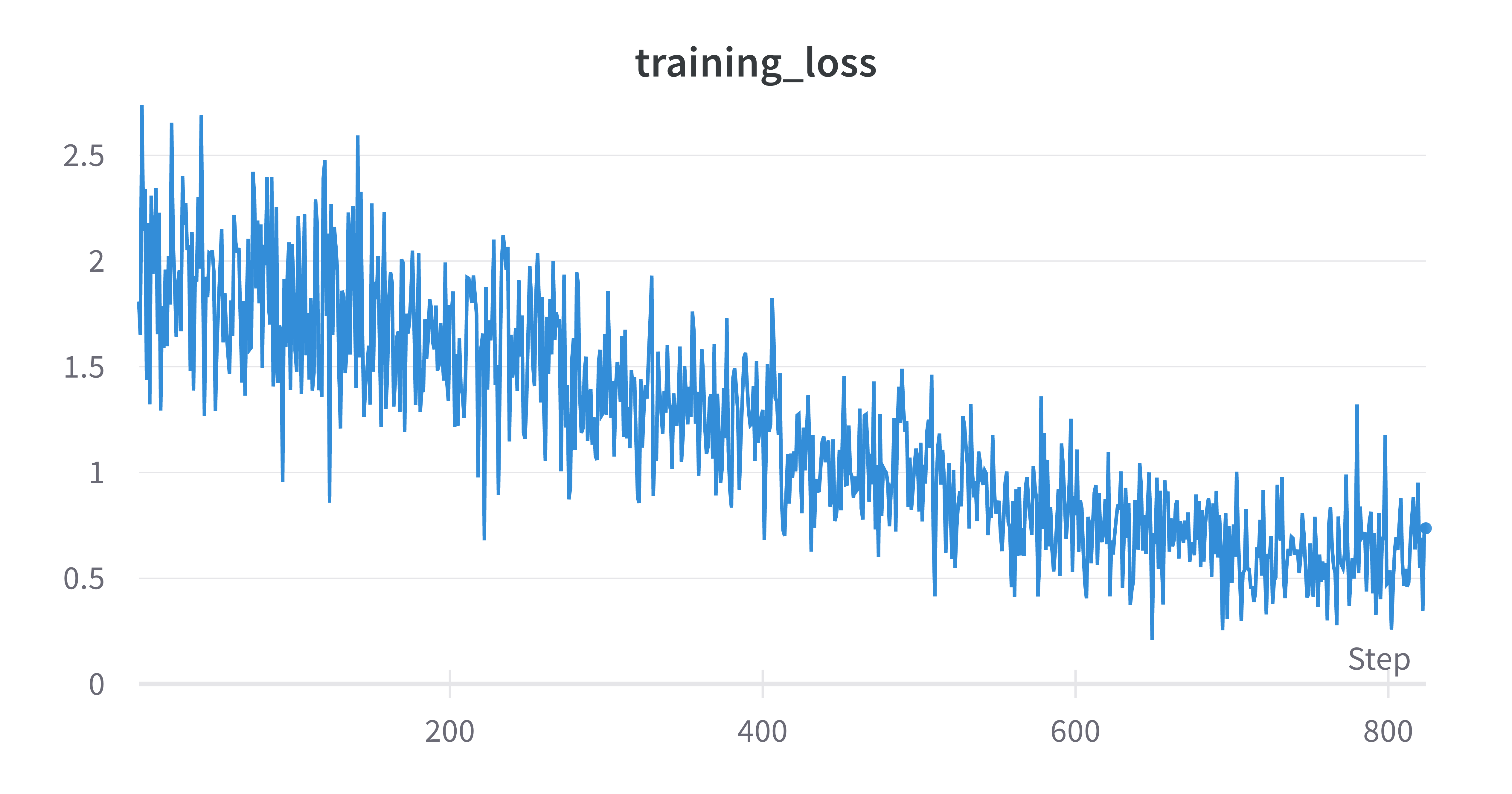
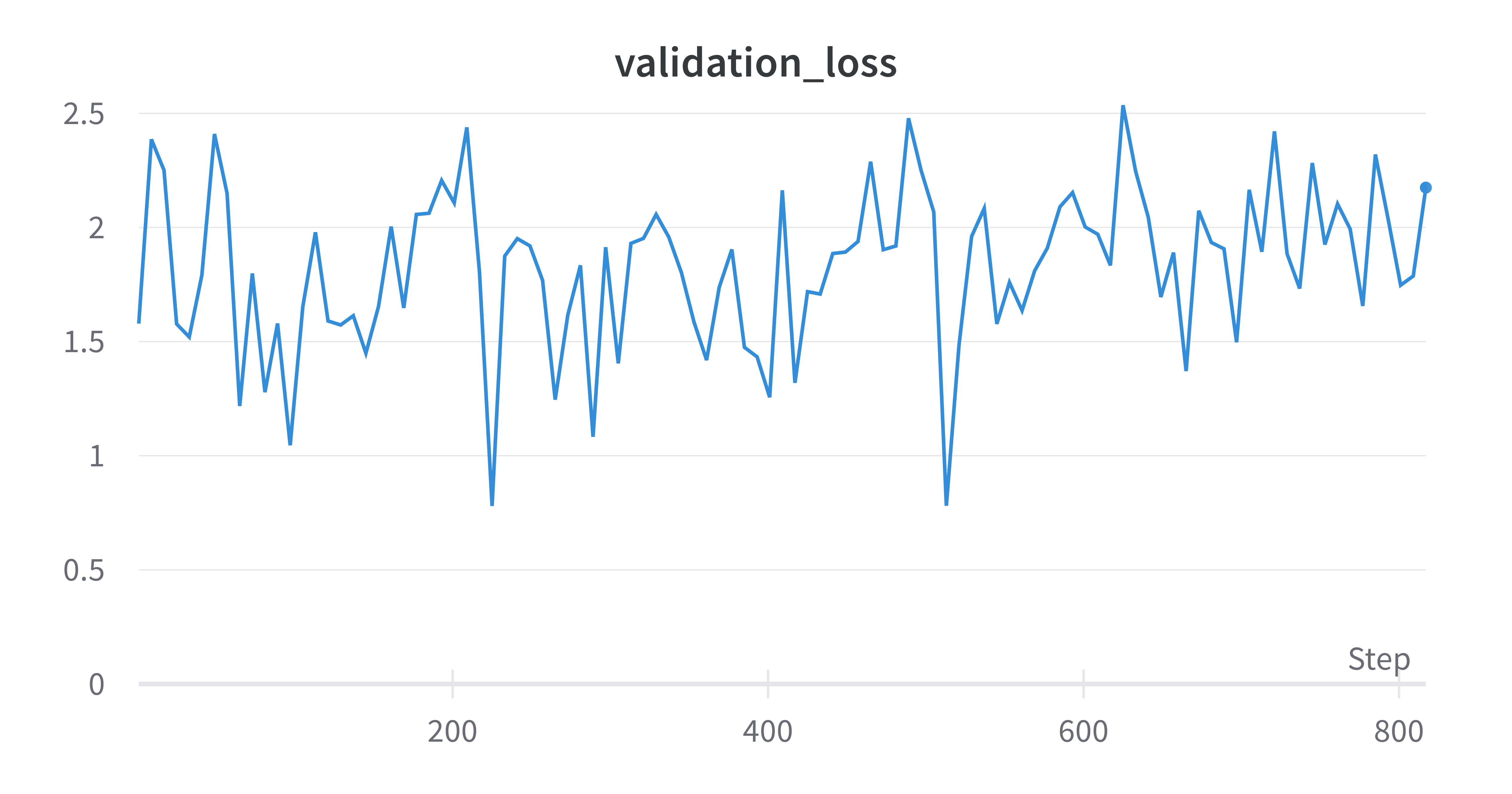
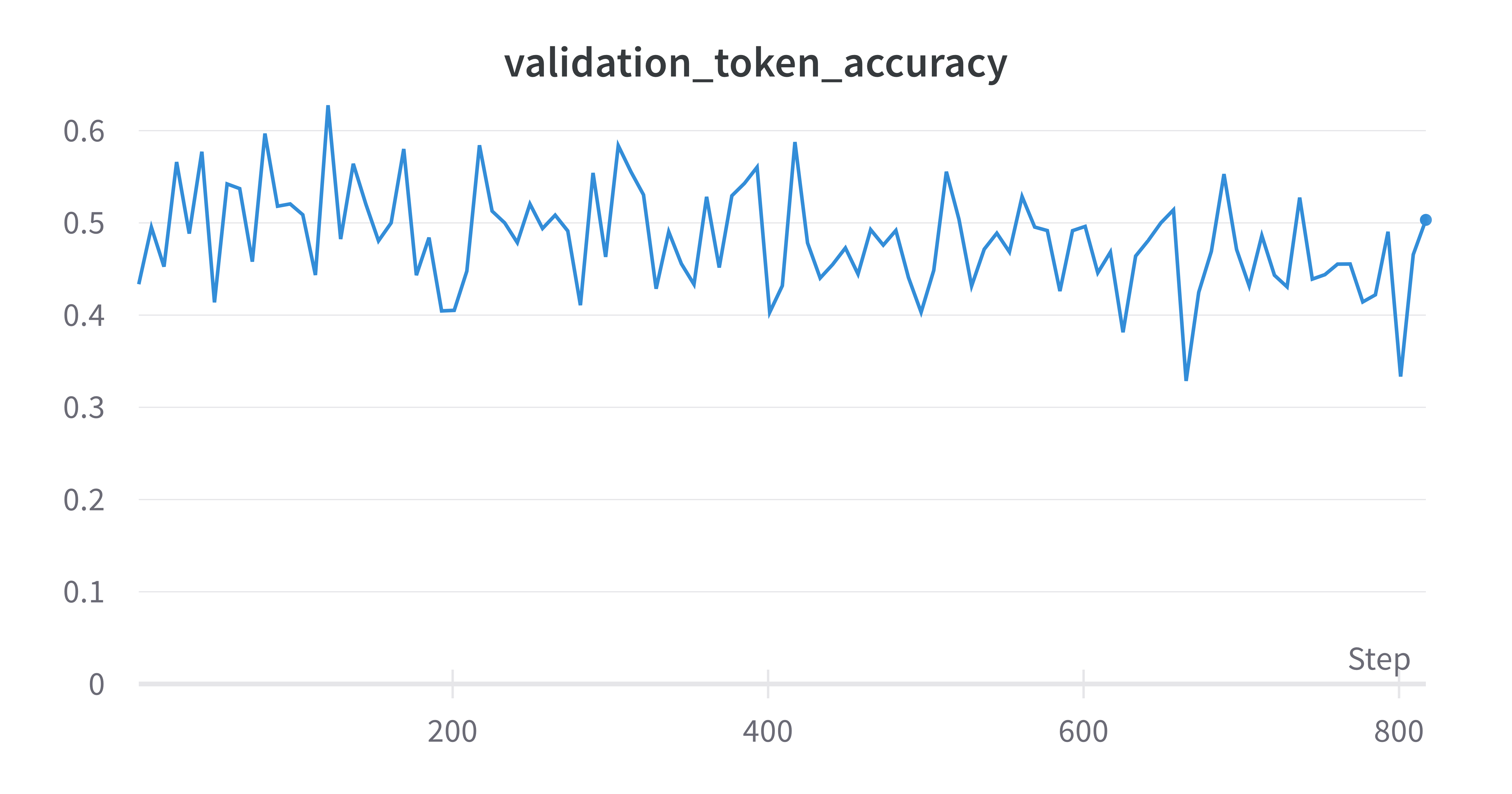
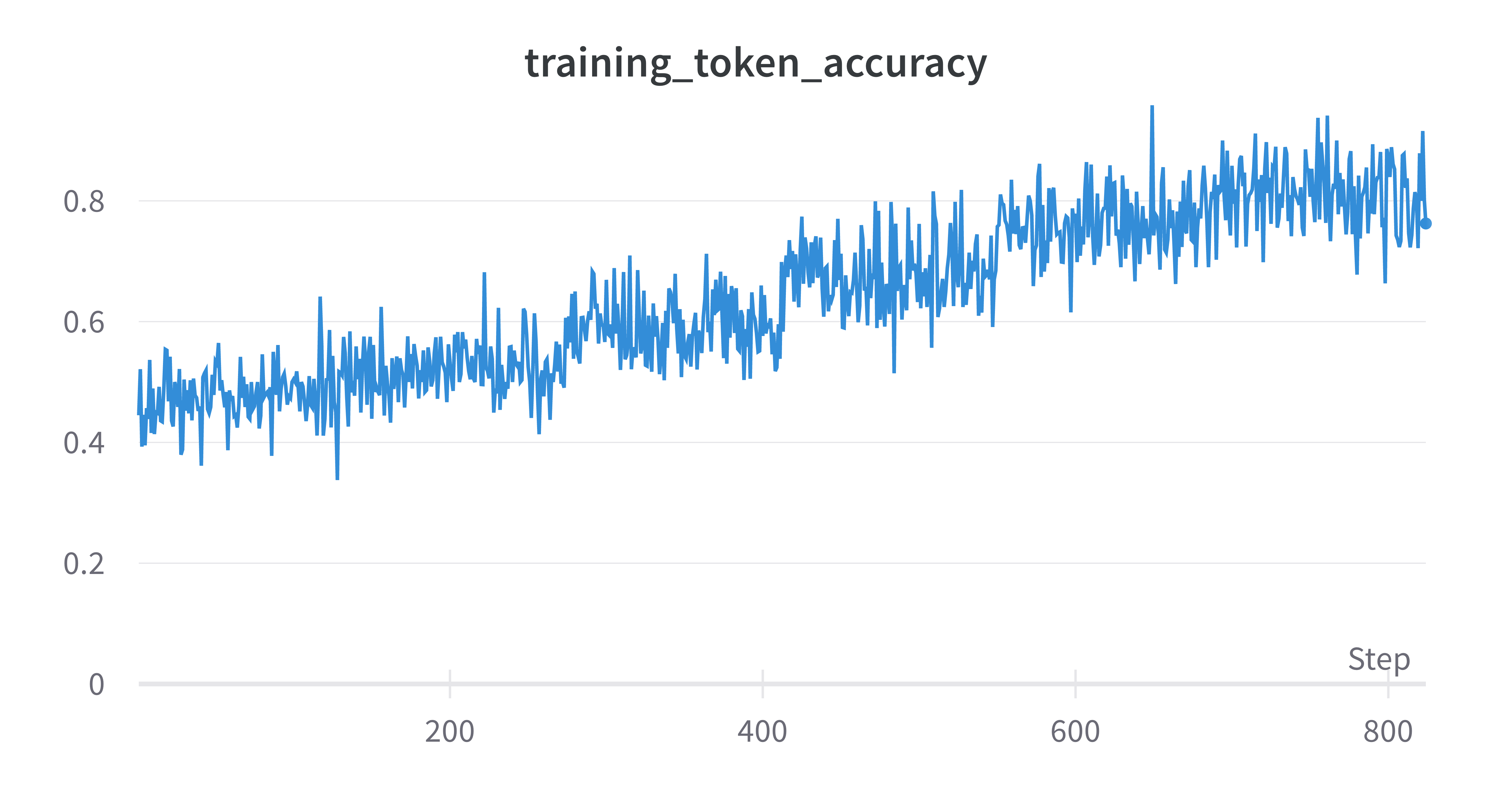
To optimize the performance of the model, we have experimented with different values for epochs, batch size, and learning rate during the fine-tuning process. By altering these parameters, we were able to determine which combination yields the best results.
We were able to successfully train the model with only a small amount of training and validation data.
We propose a strategy to lower the cost of GPT-3 while maintaining its high quality.
-
The
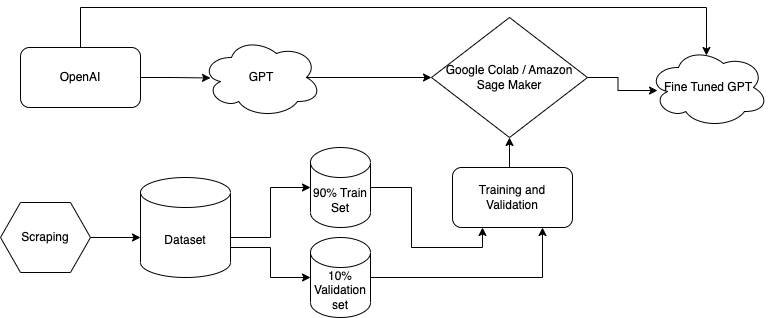
code.ipynbfile can run locally through Jupyter Notebook or Google Colab. -
Requirements:
pip install openaipip install wandb -
A wandb account is required to run this code. Creating a wandb account is free and the API Key of the wandb account is required to publish the graphs and visualizations into it.
-
While running the
Preparing the data to be fed into the GPT-3 model for fine tuning. The CSV file is converted to a JSON file format suitable to fine tune OpenAI's GPT model.cell, passYto all requests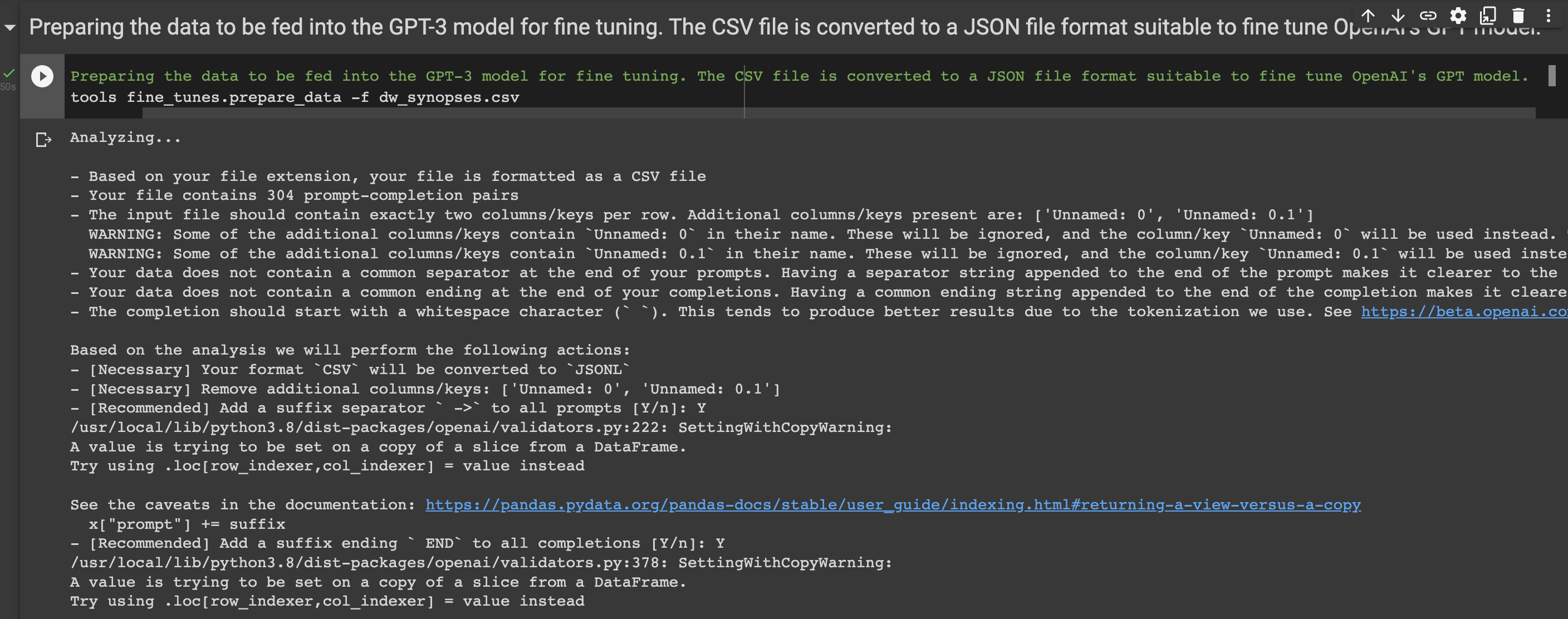
-
While running the
Training the modelcell, pass empty strings to everything.