-
|
I'm in the process of using the NeMo framework to fine-tune a pretrained english model for swedish.
The train and dev splits are tarred with following config for
The tokenizer used currently is a "SPE" tokenizer made with
The idea is to use the pretrained STT En Conformer-Transducer Large model and fine-tune it for Swedish. The way I've set up the training so far is: I've taken the base config The set-up is further done as: Now to the actual questions: For instance; 1. Should the optimizer config be changed from the baseconfig? I'd highly appreciate any help & pointers. Br |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 8 replies
-
|
I'm tagging you @titu1994 as I've seen you give great answers on a lot of other similar questions, thanks in advance! |
Beta Was this translation helpful? Give feedback.
-
|
Hi, thanks for the incredibly detailed discussion ! So first off let's start of with some important considerations -
Now onto the setup code
It's not a full tutorial but it has most of the important steps.
It is simply too vast for 1 gpu. I would first do short experiments - maybe 5-10 epochs ~ 50,000-100,000 steps. That should be a reasonable baseline for training. As you'll see in the Hindi notebook, even 5000 steps can be the start of training - from 100% we're to 40% !
|
Beta Was this translation helpful? Give feedback.
-
|
Your LR peak seems to be too high, I think best to use 10-15k warmup steps or to reduce LR to 1 or 2 so the peak doesn't go too much above 0.002. Overall your model seems to be learning well. It is a transducer though, so it should do a lot better. Are you using spec augment? You could try disabling it (set both freq_masks and time_maska to 0) and see if you can overfit your dataset. As far as I can tell you will need longer training run but that should reduce your wer to around 10-15% at the end of training. How noisy is your test set ? We have a lot of compute so we usually train for 100-200 epochs and process the dev / test set to be cleaned up before we do eval on it. Might be why you're seeing 25% wer. You could use the speech data explorer in Nemo to make out what mistakes are being made or if it's ground truth itself that is noisy. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot again for your quick replys! I see, so far I've indeed used spec augment. Will try to turn it off. Btw would there be any reason to also turn off dropout in encoder/decoder or will this just likely result in overfitting to fast? Further, would you recommend to re-train it from "scratch" (I.e not from the 10th epoch with the new LR) or to continue from the 10th epoch? As another sanity check just so I understand things correctly; Below is the order in which I setup the model before training. Is it correct in terms of preserving the weights from the enc/dec/joint from the pre-trained en model? I would say that the dataset in general is fairly clean but will try out the data explorer, thanks for the tip! Best |
Beta Was this translation helpful? Give feedback.
-
|
Dropout in encoder is important, conformer will overfit too rapidly without it. You could retrain from scratch if preferred, since 10 epochs one has not reached best possible wer. When we train for 100-200 epochs, we use that checkpoint for the next generation as initialization. Order of operations looks good |
Beta Was this translation helpful? Give feedback.
-
|
Thanks again! I've now retrained it without augmentation and with more (15 000) warm-up steps. The training results are as follows; Best |
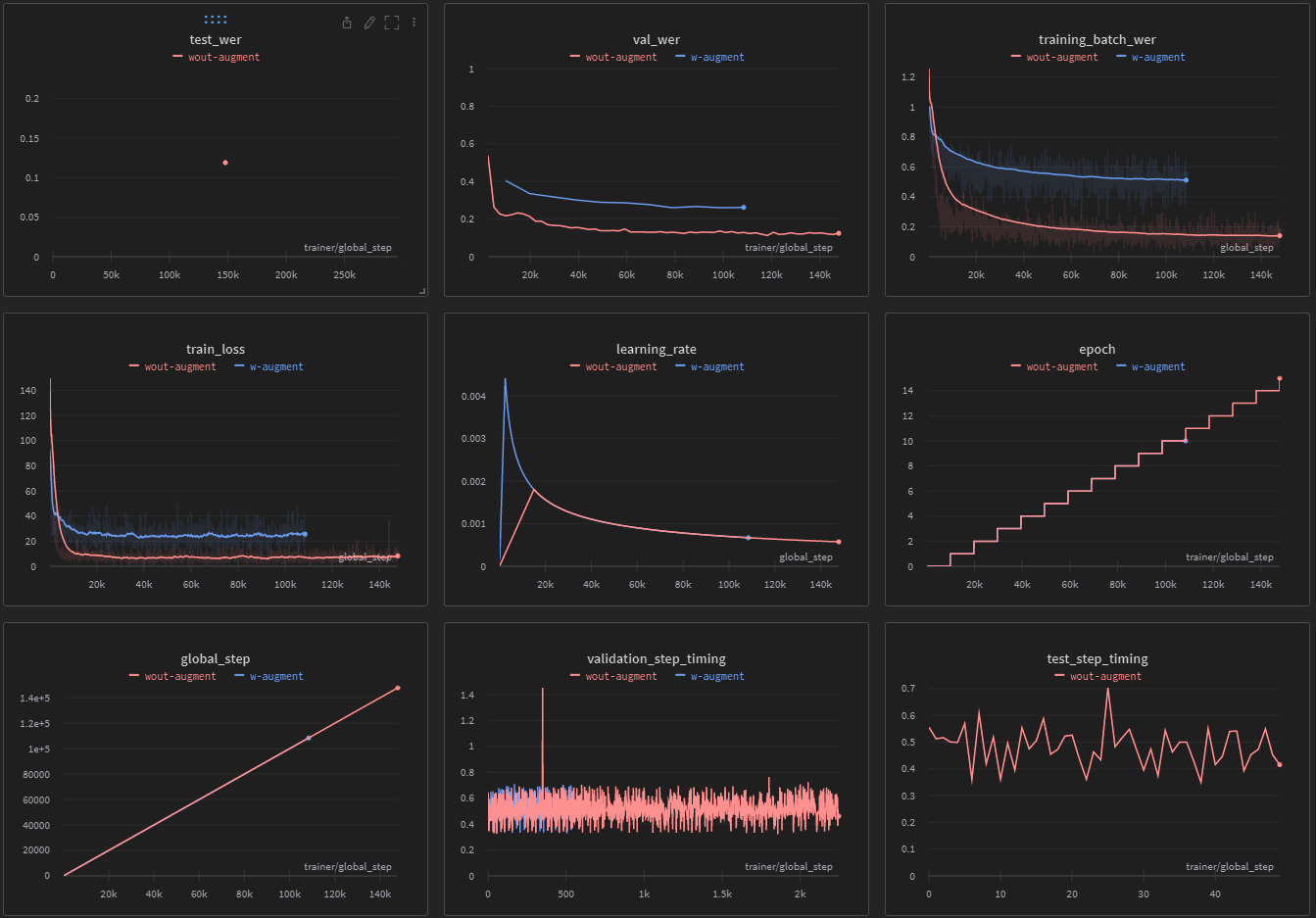
Beta Was this translation helpful? Give feedback.
-
|
Possibly noise in the data + insufficient data to train a model to full convergence. Note your train loss has reached near saturation and almost flatlined. You can do some tricks such as train it for more steps with this model as initialization and reduce peak lr to 0.0005 (you'll need to figure out the LR scaler for Noam). Another option is to finetuned this model with light augmentation - maybe 2x freq and 2/5x time masks. Though given how low your model has reached yet train loss is not at 0 (its slope has flatlined well above 0.xx value, close to 10s mark) probably means there is some irreducible labeling error. So augmentation might help a little bit it won't fix the full issue. Note that RNNT is very prone to overfit with perfect data for large models, and often reaches train loss close to 0 without specaug. So if your train loss were approaching 0 I'd strongly suggest augmentation, but in this case it might not help that much |
Beta Was this translation helpful? Give feedback.
Hi, thanks for the incredibly detailed discussion ! So first off let's start of with some important considerations -
You have Tokenizer, are referring to bpe config, but are manually inserting parts of config from character based models config. Please refer to the bpe / subword config only when using Tokenizers. Mixing the two will not work and may silently cause major issues.
validation set cannot be used with tarred dataset. It is also quite wasteful to have over 10 hours of validation data, cause you'll mostly cover the whole vocabulary with that much. Also, NeMo does not support Val and test data loaders being tarred datasets cause they drop samples which would make results incomp…