Releases: MASD-Project/dogen
Dogen v1.0.12, "Estádio do Atlético"
Estádio Joaquim Morais, Moçamedes, Namibe. (C) 2018 Jornal de Angola.

Overview
With Sprint 12 we are hoping to finally return to a regular release cadence. This was a much more predictable two-week sprint, which largely delivered on the sprint's mission statement of cleaning up the mess of refactors and reactivating system testing. As such, it was not a particularly exciting sprint in terms of end user features, but still got us very excited because we are finally paying off years of technical debt in a manner that respects established MDE theory.
Internal Changes
The key internal changes are described in the next sections.
Complete the orchestration refactor
We have now finally got a proper pipeline of tasks, with well-defined roles and terminology:
- injection: responsible for importing external models into MASD. The name "injection" comes from the MDE concept of injecting external technical spaces into a technical space.
- coding: meta-model responsible for modeling software engineering entities.
- generation: meta-model responsible for the expansion into facets, providing a multidimensional extension to the coding model. The role of generation is to get the meta-model as close as possible to the requirements of code-generation.
- extraction: responsible for extracting a model out of MASD into an external technical space. Again, the name "extraction" comes from the MDE notion of extracting content from one technical space into another.
The biggest advantage of this architecture is that we now have a simple pipeline of transformations, taking us from the original external model into the final generated code:

This orchestration pipeline is conceptually similar to the architecture of a compiler, and each of these high-level transforms can be thought of as a "lowering phase" where we move to lower and lower levels of abstraction. However, for a proper technical explanation of the approach you'll have to wait for the PhD thesis to be published.
This work has enabled us to do a number of important clean ups, such as:
- core models now have a uniform structure, with distinct meta-models, transform-sets and transform contexts. We don't have special cases any more.
- all of the mix-and-match processing that occurred inside of the coding model is now gone (e.g. injection work, extraction work, etc).
- the creation of the extraction transform pipeline made things significantly easier to implement features such as diffing and the dry run mode (see user visible changes).
Reactivate all system tests
One of the biggest problems we faced of late has been a lack of adequate testing. Whilst we were experimenting with the architecture, we had to disable all system tests as they became completely out of sync with the (admittedly crazy) experiments we were carrying out. However, before we can enter the last few refactors, we desperately needed to have system tests again.
This sprint saw a lot of infrastructural work to enable a more sensible approach to system testing; one that takes into account both reference models (C++ and C#) as well as using dogen's own models. In order to make this practical, we ended up having to improve the conversion of Dia models into JSON as well. On the plus side, our code coverage has experienced a marked uptick:
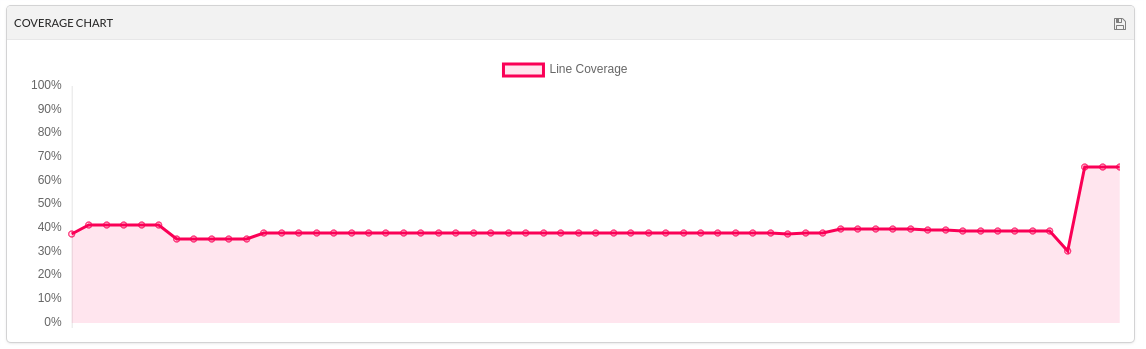
However, analysis reveals that we are still not testing a fair bit of the generated code, so next sprint the objective is to close the gap further in code coverage and testing.
User visible changes
We've finally got round creating a video to demo the user visible features added in this sprint:

Hopefully this will become a habit from now on. The next sections describe in more detail the key user visible changes.
Improvements on handling of references
There were two key changes on how references are processed. First, we no longer automatically include system models. From now on, these are treated just like any other model and must be included manually. As an example, a C++ model using the STL, C++ built-in types and boost would now need to have the following references:
#DOGEN masd.injection.reference=cpp.builtins
#DOGEN masd.injection.reference=cpp.std
#DOGEN masd.injection.reference=cpp.boost
Whilst it is a bit of an inconvenience to have to add these to every other model (specially builtins and std), this does mean that there are now no special cases and no need for "speculative processing" of models. In the past we loaded all system models and there was a lot of extra logic to determine which ones where needed by whom (e.g. do not load C# system models for a C++ model, but maybe load it for a LAM model, etc). We have now placed the onus of determining what should be loaded onto the user, who knows what models to load.
A second related change is that references are now transitive. This means that if model A depends on model B which depends on model C, you no longer need to add a reference to model C in model A as you had to in the past; the reference from model B to model C will be honoured. Sounds like a trivial change, but in reality this was only possible because of the move towards a simplified pipeline (as outlined in the previous section).
Dry-run mode
One of the biggest annoyances we've had is the need to code generate in order to see what would change. The problem with C++ is that, if the generated code is not what you'd expect - a fairly common occurrence when you are developing the code generator, as it turns out - you end up with a large number of rebuilt translation units for no good reason. Thus we copied the idea from vcpkg and others of a "dry-run mode": in effect, do all the transforms and produce all the generated code, but don't actually write it to the filesystem. Of course, the logical conclusion is that some kind of diffing mechanism is required in order to see what would change. For this we relied on the nifty Diff Template Library, which provides a very simple way of producing unified diffs from C++. Sadly it was not on vcpkg, but the most excellent vcpkg developers responded quickly to our PR, so you if you'd like to use it, you can now simply vcpkg install dtl.
As a result, with a fairly simple incantation, you can now see what dogen would like to do to your current state. For example, say we've updated the comment for property attribute of the hello_world.dia test model; to check our changes, we could do:
$ ./masd.dogen.cli generate --target hello_world.dia --dry-run-mode-enabled --diffing-enabled --diffing-destination console
diff -u include/dogen.hello_world/types/one_property.hpp include/dogen.hello_world/types/one_property.hpp
Reason: Changed generated file.
--- include/dogen.hello_world/types/one_property.hpp
+++ include/dogen.hello_world/types/one_property.hpp
@@ -33,7 +33,7 @@
public:
/**
- * @brief This is a sample property.
+ * @brief This is a sample property. Test diff
*/
/**@{*/
const std::string& property() const;
Whilst the arguments required may appear a bit excessive at this point, we decided to roll out the feature as is to gain a better understanding of how we use it. We will then clean up the arguments as required (for example, should dry run mode default to --diffing-enabled --diffing-destination console?).
As an added bonus, if you choose to output to file instead of console, we generate a patch file which can be patched on the command line via patch. We don't have a particular use case for this as of yet, but it just seems nice.
Reporting
A feature that is related to dry-run mode is reporting. We originally merged the two together but then realised that reporting might be useful even when you don't require a diff or a dry run, so we ended up implementing it stand alone. Reporting provides an overview of the operations dogen performed (or would have performed, if you are in dry run mode) to your file system. And, as with tracing, you can visualise it on org mode, making it really easy to navigate if you are a vi or emacs user:
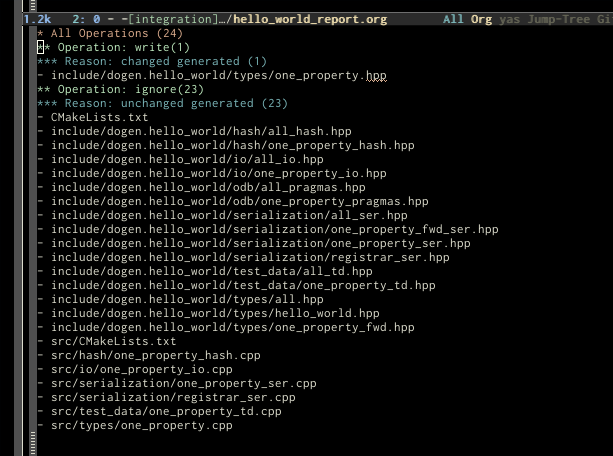
However, if you'd like to grep for specific types of operations, you can use the plain report instead:
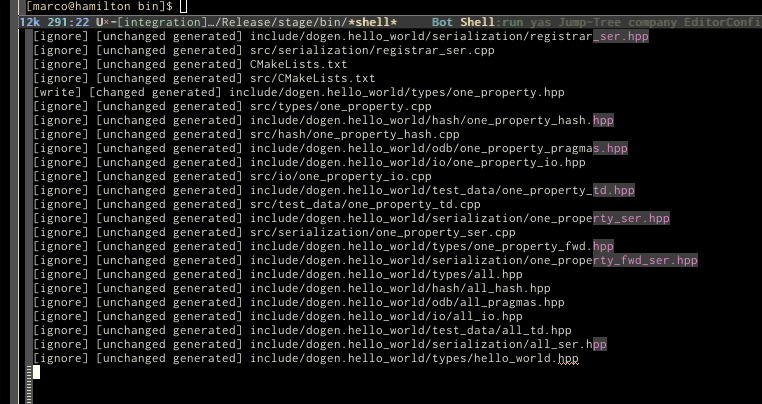
To enable reporting, simply do:
./masd.dogen.cli generate --target hello_world.dia --reporting-enabled --reporting-style org-mode
Replacing org-mode with plain as required. And, as explained, you can always add --dry-run-mode-enabled if you'd like.
Byproducts directory
Even before the advent of diffing and reporting, we were already generating a large number of non-code related files, all of which were fairly randomly placed in the filesystem. With this release, we just couldn't continue with this approach so, instead, all of the non-generated files are now created under a "byproducts" directory. This includes:
- log files;
- trace...
Dogen v1.0.11, "Moçamedes"
Município de Moçamedes, capital da província do Namibe. (C) 2018 Portal de Angola.

Overview
Sprint 11 was yet another "never ending" sprint, lasting several months and is packed full of work. By far, the largest contributor for this oversized sprint was the work on the PhD thesis, which lays the theoretical foundations of MASD. All of the preliminary reviews of the PhD have now been completed, and we have reached the "business end" towards the delivery of the dissertation. This is good news for the Dogen development, because it means that the theoretical model is now close to completion and we can once more focus on coding. The downside is that after many months of theory without giving the code the proper attention, it is now quite far away from the theory. Towards the end of the sprint some coding work did get done though, adding some interesting features.
Infrastructure Cleanup
Continuing from the previous sprint, we worked on a number of small housekeeping tasks that have been outstanding for a while:
- Nightly builds have now returned. We still have a number of false positives in valgrind that need to be suppressed, but we're closing in on those. Hopefully more checkers shall follow such as ASAN and the like.
- Clang-cl build is no longer experimental. Dogen now builds and runs all tests, and the C++ reference implementation has only one test failure. We've also made some inroads in improving CDash's support for clang-cl (Kitware/CDash#733). We are now very close to shipping our Windows binaries from clang-cl.
- Assorted vcpkg updates: Boost is now at v1.69 across all operative systems, ODB is now at v2.5.

Reference Models Cleanup
A number of small fixes were done to the reference models, improving our confidence in the build process:
- Update all models to latest Dogen, including sync'ing the JSON models to the latest Dia models.
- Update the
northwindmodel to latest ODB, and add tests to connect to a postgres database on travis (Linux only). We are now validating our ORM support. - Added a colour palette test model to exercise all stereotypes that have an associated colour to ensure the palette is consistent.

Codebase Cleanup
Continuing with our overall code cleanup, a number of refactors were made:
- the utility model is now a regular model. Together with the "single binary" work (see below), this now means that Dogen is made entirely of Dogen models.
- reduce the number of generated files that are unused. We've removed many forward declarations and other facets that were generated for no good reason. This work resulted in cleaning up some bugs for corner cases in facet enablement.
- clean up temporary profiles, created when we were trying to get rid of unnecessary facets. We now have only one temporary profile, that can only be removed when we fix a bug in Dogen.
- start using Boost.DI for dependency injection instead of rolling our own code. We still need to replace all the registrars and so forth, but we've made a start.
User visible changes
A number of user visible changes were made with this release. These are all breaking changes and require updates in order for existing models to continue working.
Complete MASD namespace rename
All of the profiles and meta-data are now in the MASD namespace. With this release we tidied up missed items such as: masd.decoration.licence_name, masd.decoration.copyright_notice etc that had been missed previously.
Move command line options to metadata
A number of command line options have been moved into the meta-data section of the model. This is because these options were really model properties. With this change we now make it easier to regenerate models in a reproducible manner. Example options:
#DOGEN masd.extraction.ignore_files_matching_regex=.*/CMakeLists.txt
#DOGEN masd.extraction.delete_extra_files=true
#DOGEN masd.extraction.force_write=true
Create a single Dogen binary
When we started Dogen we created a number of tiny binaries that worked as frontends to specific transformations such as knitter, stitcher and so forth. However, as we better understood the problem domain, it became clear that there was lots of duplication between binaries for no real advantage. With this release, we implemented the git approach of having a single binary with a "command" interface. The help screen explains this new approach:
$ ./masd.dogen.cli --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Dogen uses a command-based interface: <command> <options>.
See below for a list of valid commands.
Global options:
General:
-h [ --help ] Display usage and exit.
-v [ --version ] Output version information and exit.
Logging:
-e [ --log-enabled ] Generate a log file.
-g [ --log-directory ] arg Directory to place the log file in. Defaults
to 'log'.
-l [ --log-level ] arg What level to use for logging. Valid values:
trace, debug, info, warn, error. Defaults to
'info'.
Tracing:
--tracing-enabled Generate metrics about executed transforms.
--tracing-level arg Level at which to trace.Valid values: detail,
summary.
--tracing-guids-enabled Use guids in tracing metrics, Not
recommended when making comparisons between
runs.
--tracing-format arg Format to use for tracing metrics. Valid
values: org-mode, text
--tracing-output-directory arg Directory in which to dump probe data. Only
used if transforms tracing is enabled.
Error Handling:
--compatibility-mode-enabled Try to process models even if there are
errors.
Commands:
generate Generates source code from input models.
convert Converts a model from one codec to another.
weave Weaves one or more template files into its final output.
For command specific options, type <command> --help.
And then for say the generate command, we now have:
$ ./masd.dogen.cli generate --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the generate command.
For global options, type --help.
Generation:
-t [ --target ] arg Model to generate code for, in any of the
supported formats.
-o [ --output-directory ] arg Output directory for the generated code.
Defaults to the current working directory.
This approach cleaned significantly the internals, resulting in the deletion of a number of model-lets and coalescing all of their functionality in a much cleaner way in a single model: masd.dogen.cli.
New stereotypes
A small number of stereotypes has been added:
masd::cpp::header_only: handcrafted type that has only a header file.masd::entry_point: handcrafted type that has only an implementation file.masd::interface: handcrafted type that has only a header file.
In the future we will bind different templates to these stereotypes to provide a more suitable starting state.
For more details of the work carried out this sprint, see the sprint log.
Next Sprint
We are now in full refactoring mode in Dogen. The objective of the next sprint is to implement the orchestration model properly, removing all of the (many) experiments that have been attempted over the last few years.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.10, "Lucira"
Lucira fishing village, Namibe province, Angola. (C) 2016 Rede Angola.

Overview
This sprint brought the infrastructural work to a close. Much was achieved, though mainly relevant to the development process. As always, you can get the gory details in the sprint log, but the below has the highlights.
Complete the vcpkg transition
There were still a number of issues to mop-up including proper OSX build support, removing all references to conan (the previous packaging system) and fixing a number of warnings that resulted from the build settings on vcpkg. We have now fully transitioned to vcpkg and we're already experiencing the benefits of the new package management system: adding new packages across all operative systems now takes a couple of hours (the time it takes to rebuild the vcpkg export in three VMs). However, not all packages are available in vcpkg and not all packages that are available build cleanly on all our supported platforms, so we haven't reached nirvana just yet.
Other build improvements
In parallel to the vcpkg transition we also cleaned up most warnings, resulting in very clean builds on CDash. The only warnings we see are real warnings that need to be addressed. We have tried moving to /W4 and even Wall on MSVC but quickly discovered that it isn't feasible at present, so we are using the compiler default settings until the issues we raised are addressed.
Sadly, we've had to ignore all failing tests across all platforms for now (thus taking a further hit on code coverage). This had to be done because at present the tests do not provide enough information for us to understand why they are failing when looking at the Travis/AppVeyor logs. Since reproducing things locally is just too expensive, we need to rewrite these tests to make them easy to troubleshoot from CI logs. This will be done as part of the code generation of model tests.
A final build "improvement" was the removal of facets that were used only to test the code generator, such as hashing, serialisation etc. This has helped immensely in terms of the build time outs but the major downside is we've lost yet another significant source of testing. It seems the only way forward is to create a nightly build that exercises all features of the code generator and runs on our machines - we just do not have enough time on Travis / AppVeyor to compile non-essential code. We still appear to hit occasional timeouts, but these are much less frequent.
Code coverage
We've lacked code coverage for a very long time, and this has been a pressing need because we need to know which parts of the generated code are not being exercised. We finally managed to get it working thanks to the amazing kcov. It is far superior to gcov and previous alternative approaches, requiring very little work to set up. Unfortunately coverage numbers are now very low now due to the commenting out of many unit tests to resolve the build times issues. However, the great news is we can now monitor the coverage as we re-introduce the tests. Sadly, the code coverage story on C# is still weak as we do not seem to be able to generate any information at present (likely due to NUnit shadowing). This will have to be looked at in the future.
We now have support for both Codecov and Coveralls, which appear to give us different results.
C++ 17 support
One of the long time desires has been to migrate from C++ 14 to C++ 17 so that we can use the new features. However, this migration was blocked due to the difficulties of upgrading packages across all platforms. With the completion of the vcpkg story, we finally had all the building blocks in place to move to C++ 17, which was achieved successfully this sprint. This now means we can start to make use of ranges, string_view and all the latest developments. The very first feature we've introduced is nested namespaces, described below.
Project naming clean-up
Now we've settled on the new standard namespaces structure, as defined by the Framework Design Guidelines, we had to update all projects to match. We've also made the build targets match this structure, as well as the folders in the file system, making them all consistent. Since we had to update the CMake files, we started to make them a bit more modern - but we only scratched the surface.
Defining a Dogen API
As part of the work with Framework Design Guidelines, we've created a model to define the product level API and tested it via scenarios. The API is much cleaner and suitable for interoperability (e.g. SWIG) as well as for the code generation of the remotable interfaces.
User visible changes
The main feature added this sprint was the initial support for C++ 17. You can now set your standard to this version:
#DOGEN quilt.cpp.standard=c++-17
At present the only difference is how nested namespaces are handled. Using our annotations class as an example, prior to enabling C++ 17 we had:
namespace masd
namespace dogen
namespace annotations {
<snip>
} } }
Now we generate the following code:
namespace masd::dogen::annotations {
<snip>
}
Next Sprint
We have reached a bit of a fork in Dogen's development: we have got some good ideas on how to address the fundamental architectural problems, but these require very significant surgery into the core of Dogen and its not yet clear if this can be achieved in an incremental manner. On the other hand, there are a number of important stories that need to be implemented in order to get us in a good shape (such as sorting out the testing story). Hard decisions will have to be made in the next sprint.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.09, "Kubata"
Traditional Angolan village house. (C) Rob and Sophie.

Overview
As described on the previous sprint, the key objective at present is to get all the infrastructure up-to-date after a hiatus of a year or so of development. This is a requirement so that we can move to C++ 17 and start to make use of all the nice new libraries available. As such, this sprint was entirely taken with infrastructure clean up. Whilst these changes are not user visible, they still provide important benefits to project development so we'll briefly summarise them here.
MASD Project Transition
We have started to sync up the work on the PhD with the work on Dogen. This sprint, the main focus was on creating an organisation solely for Model Assisted Software Development (more details on that in the future), and moving all of the infrastructure to match - Bintray, Travis, Gitter and the like.
Move to vcpkg
Historically, we've always had a problem in keeping dogen's dependencies up-to-date across the three supported platforms. The problem stems from a lack of a cross-platform package manager in C++. Whilst we tried Conan in the past, we never managed to get it working properly for our setup. With this sprint we started the move towards using vcpkg.
Whilst it still has some deficiencies, it addresses our use case particularly well and will allow us to pick up new dependencies fairly easily going forward. This is crucial as we expand the number of facets available, which hopefully will happen over the next couple of months. In this sprint we have completed the transition to vcpkg for Linux and Windows; the next sprint will be OSX's turn. With the introduction of vcpkg we took the opportunity to upgrade to boost 1.68 on Linux and Windows.
Add CDash support
Since we moved away from our own infrastructure we lost the ability to know which tests are passing and how long test execution is taking. With this sprint we resurrected CDash/CTest support, with a new dashboard, available here. There are still a few tweaks required - a lot of tests are still failing due to setup issues - but its clearly a win as we can now see a clearer picture across the testing landscape.
Move reference models out of Dogen's repository
For a long time we've been struggling to build Dogen within the hour given to us by Travis. An easy win was to move the reference models (C++ and C#) away from the main repository. This is also a very logical thing to do as we want these to be examples of stand-alone Dogen products, so that we can point them out to users as an example of how to use the product. Work still remains to be done on the reference implementations (CTest/CDash integration, clean up tests) but the bulk has been done this sprint.
For more details of the work carried out this sprint, see the sprint log.
User visible changes
Two tiny featurelets were added this sprint:
- Development Binaries: We now generate binaries for development releases. These are overwritten with every commit on BinTray.
- Improvements on
--version: The command now outputs build information to link it back to the build agent and build number. Note that these details are used only for information purposes. We will add GPG signatures in the future to validate the binaries.
$ dogen.knitter --version
Dogen Knitter v1.0.09
Copyright (C) 2015-2017 Domain Driven Consulting Plc.
Copyright (C) 2012-2015 Marco Craveiro.
License: GPLv3 - GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>.
Build: Provider = 'travis' Number = '2082' Commit = '53a1a169bd6f15c4388add9da933be2a353c4cbf' Timestamp = '2018/10/14 21:54:46'
IMPORTANT: build details are NOT for security purposes.
Next Sprint
Infrastructural work will hopefully conclude on the next sprint, but the next big task is getting all the tests to run and pass.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.08, "Caminhada"

Overview
After a rather long hiatus of some nine months, Dogen development resumes once more. In truth, the break was only related to the open source aspect of the Dogen project; behind the scenes I have been hard at work on my PhD, which has morphed into an attempt to lay the theoretical foundations for all the software engineering that has been done with Dogen. Sadly, I cannot perform that work out in the open until the thesis or papers are published, so it is expected to remain closed for at least another year or two.
On the bright side, after performing an extensive literature review of the field of Model Driven Engineering - the technical name used in academia for the field Dogen is in - a lot of what we have been trying to do has finally become clear. The down side is that, as a result of all of this theoretical work, very little has changed with regards to the code during this period. As such, this sprint contains only some minor analysis work that was done in parallel, and I am closing it just avoid conflating it with the new work going forward.
The future for Dogen is bright, though. We are now starting the long road towards the very ambitious release that will be Dogen 2.0. The objective is to sync the code to match all of the work done on the theory side. This work as already started; you will not fail to notice that the repository has been moved to the MASD project - Model Assisted Software Development.
For more details of the work carried out this sprint, see the sprint log.
User visible changes
There are no user visible changes this sprint.
Next Sprint
The next few sprints will be extremely active, addressing a number of long standing issues such as moving test models outside of the main repo and concluding ongoing refactorings.
Binaries
Due to the transition of organisations, we did not generate any binaries for this release. As there are no code changes, please use the binaries for the previous release (v1.0.07) or build Dogen from source. Source downloads are available at the top.
Dogen v1.0.07, "Mercado"

Mercado Municipal, Namibe, Angola. Found in mapio.
Overview
The bulk of the work this sprint was yet again spent on refactoring, but at least it now seems there is a light at the end of the tunnel. The adventures were narrated on a blog post: Nerd Food: The Refactoring Quagmire. The TL; DR of it is that - at long last - we now have a way to contain the refactoring work, which was somewhat spiraling out of control.
The remainder of the sprint was spent on infrastructural tasks such as fixing travis, tests, rtags and so forth.
As always, for gory details on the work carried out this sprint, see the sprint log.
User visible changes
There are no user visible changes this sprint.
Next Sprint
Next sprint will be focused on continuing the clean up as described in the blog post above, which hopefully will take us to the final iteration of the architecture - at least for the near future.
Binaries
You can download the remaining binaries from Bintray for OSX, Linux and Windows (all 64-bit):
Note: due to issues with Conan, we were not able to generate Windows binaries for this sprint.
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.06, "Praia da Mariquita"
Praia da Mariquita, Namibe, Angola. (C) Praia da Mariquita Lodge, 2014.

Overview
Our long road towards the clean up of the backends continued with another long and arduous sprint. The bulk of the work in this sprint was focused on two activities:
- File locators work: clean up the backend-specific file locators and move them into yarn. In order to do this we needed to generalise a large number of data structures that were originally designed to be language-specific. This has proven to be quite a challenge, and we probably still have another full sprint ahead of us on this work.
- Additional exomodel work: in the previous sprint we introduced the concept of exomodels; these originally used the regular meta-model elements such as
yarn::objectand so forth. This sprint it became obvious that a further round of simplification is still required, moving away from the core meta-model elements within the frontends. This work has only started but we can already see two obvious benefits: a) creating a frontend will be much easier, with very little code required b) the final JSON format will be quite trivial, making it easy for users to generate it or to map it from other tooling.
In addition to this, a number of "fun" activities where also undertaken to break away from the monotony of refactoring. These also provided tangible benefits in terms of Dogen development:
- Consolidation of responsibilities in Yarn: A number of classes were tidied up and moved into Yarn, making the meta-model more cohesive (file housekeeping, artefact writing, etc). Other classes already in Yarn were improved (better naming, remove classes that did not add any value, etc).
- Integration of CCache in Travis: most of our builds are now much quicker (in the order of tens of minutes or less) due to caching of translation units. Unfortunately, this work does not extend to GCC's Debug build (for some not yet understood reason) nor to OSX (given the peculiarities of its many packaging systems, we still haven't quite figure out how to install CCache) nor to Windows (its not clear that AppVeyor and/or MSVC support CCache or a CCache like tool).
- Use of colour in Dia's UML diagrams: as described below, we started colour-coding UML classes in Dia.
- Revamp of project logo: Dogen now sports a slightly more professional project logo in Github.
User visible changes
The only user visible change this sprint is the introduction of a simple colour scheme for Dia UML Diagrams. This idea was largely copied from this paper: Instinct: A Biologically Inspired Reactive Planner for Embedded Environments. Note that the colours have no meaning to Dogen itself, but they do make interpreting diagrams a lot easier.

Colouring is performed via a simple python script available here, which can be executed in Dia's interactive python console.
As always, for gory details on the work carried out this sprint, see the sprint log.
Next Sprint
Next sprint we'll continue working on the new exomodel classes and resume the work on the backend-agnostic file locator.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.05, "Tribunal"
Tribunal, Namibe, Angola. (C) SkyScrapperCity, 2011.

Overview
The bulk of this sprint was focused on three refactoring tasks:
- Renaming Concepts to Object Templates: This is a long-standing clean-up that needed doing. One of the key principles in Yarn is to avoid binding to language specific terms when those terms don't cleanly map across to several programming languages. Since its inception, "Concepts" has been in flagrant violation of this principle, as it alludes to a C++ feature of which it isn't even a proper implementation of, nor does it map to generics. With the work on profiles looming, this clean-up became ever more pressing. Granted, "object templates" is rather more verbose - but we decided to make the change in the interest of cleaning up Yarn vocabulary. It is, at least, a more accurate reflection of this meta-model element's responsibilities.
- Probing support: Historically, Dogen has always had good logging, allowing us to troubleshoot most issues quickly. However, with Yarn's transition towards a transformation-based architecture, it has become increasingly difficult to figure out what each transformation is doing. The linear nature of the log does not help, given that one is trying to visualise a graph. Thus, troubleshooting of issues has slowed down noticeably, so something had to be done. Probing is the proposed solution for this problem, and it has already made troubleshooting orders of magnitude faster. This feature is described in depth below.
- Work on moving kernel specific transforms: we continued our long road on moving all of the "kernel-specific" transforms which aren't actually kernel-specific into Yarn. Enablement is almost done, but it remains elusive.
In addition to this, there were other minor (but still significant) strands of work:
- we continued work on the theme "everything is a transform", adding more transform chains and cleaning up more terminology as we went along. This work is now more or less complete, with the core of Yarn providing a set of primitives that are in keeping with the literature on code generation - in particular Model-Driven Software Engineering in Practice. This has greatly simplified Yarn's conceptual model and vocabulary since we can now rely on "standard" terms.
- in a similar vein, we continued to merge more functionality into Yarn, deprecating the Knit model and moving its contents as transforms into Yarn.
User visible changes
The most important user visible changes introduced with this sprint are related to stereotypes:
- all meta-model types must now be prefixed: where you had
objectyou must now putyarn::object. This change was done in preparation for both the generalisation of profiles, and for adding the ability to refer to object templates (née concepts) across models. - as explained in the previous section,
concepthas been renamed toobject_template, so where you hadconceptyou must now putyarn::object_template.
In addition, there was also a ORM related change that brings it in line with all other tagged values: the low-level ODB parameter was renamed from odb_pragma to quilt.cpp.odb.pragma. So, in your models, where you had:
#DOGEN odb_pragma=no_id
You must replace it with:
#DOGEN quilt.cpp.odb.pragma=no_id
The final user visible change is the most significant in terms of time spent: transform probing. As it happens, it is not really aimed at end-users, but its worth describing the feature as it may still prove to be useful.
A new set of command line options have been added to dogen.knitter:
--probe-stats Generate stats about executed
transforms.
--probe-stats-disable-guids Disable guids in probe stats, to make
comparisons easier.
--probe-stats-org-mode Use org-mode format for stats. Requires
enabling stats.
--probe-all Dump all available probing information
about transforms.
--probe-directory Directory in which to dump probe data.
Only used if transforms probing is
enabled.
--probe-use-short-names Use short names for directories and
files. Useful for Windows where long
paths are not supported.
We'll start with --probe-stats and related options, since it is the most likely to be of use to end users. It is now possible to dump statistics about the transform graph, allowing simple benchmarkings. When a user selects this option, a file is generated under the probing directory (configurable via --probe-directory), with the name transform_stats.txt. As an example, here is the head of the generation of the yarn model:
root (1574 ms) [version: v1.0.06, log: debug, probing: off] [4423093f-eb3e-40af-a370-b879684f7950]
dogen.yarn.code_generation_chain (1527 ms) [yarn.dia] [c6d812e9-9e97-4084-a1e1-afd804929dc0]
yarn.transforms.model_generation_chain (1075 ms) [] [9778eeab-107a-4c0f-a633-87ffd06fcd5c]
yarn.transforms.endomodel_generation_chain (890 ms) [yarn.dia] [3425b8d7-7ab2-4f95-a53a-b8c4bf7e0485]
yarn.transforms.initial_target_chain (398 ms) [yarn.dia] [229a572e-70c1-4934-be79-db7e481de5bc]
yarn.transforms.exomodel_generation_chain (333 ms) [yarn.dia] [240ea71b-778a-4601-8682-153ad8b78d51]
yarn.dia.exomodel_transform (58 ms) [yarn.dia] [5e599d88-9676-41e9-aa9a-aaf4ebb134f8]
yarn.transforms.annotations_transform (12 ms) [] [7d95b799-72d0-471f-a50c-bb29a0d70709]
yarn.transforms.naming_transform (10 ms) [] [5c768d15-7964-4d54-a9c1-f32acc452161]
yarn.transforms.exomodel_to_endomodel_transform (0 ms) [<dogen><yarn>] [e8ec0c9f-92f1-4b03-a755-a335beda1c44]
As you can see, each node has the total elapsed time it took the transform to execute. In addition, the root node of the graph contains information about the configuration, so that we can compare like with like. This includes the Dogen version, the type of logging and whether detailed probing was enabled or not. You will also not fail to notice the GUIDs next to each node in the graph. These are correlation IDs, enabling one to find the logging for each of the transforms in the log file:
2017-09-18 11:22:11.618837 [DEBUG] [yarn.helpers.transform_prober] Starting: yarn.transforms.endomodel_pre_processing_chain (229a572e-70c1-4934-be79-db7e481de5bc)
If instead one just wants to diff two transformation graphs - perhaps looking for performance changes, or changes in the composition of the grap - one can disable the GUIDs via --probe-stats-disable-guids.
root (1530 ms) [version: v1.0.06, log: debug, probing: off]
dogen.yarn.code_generation_chain (1522 ms) [yarn.dia]
yarn.transforms.model_generation_chain (1066 ms) []
yarn.transforms.endomodel_generation_chain (880 ms) [yarn.dia]
yarn.transforms.initial_target_chain (393 ms) [yarn.dia]
yarn.transforms.exomodel_generation_chain (328 ms) [yarn.dia]
yarn.dia.exomodel_transform (58 ms) [yarn.dia]
yarn.transforms.annotations_transform (12 ms) []
yarn.transforms.naming_transform (9 ms) []
yarn.transforms.exomodel_to_endomodel_transform (1 ms) [<dogen><yarn>]
For Vi and Emacs users, there is an additional way of interacting with the transform graph: we've added an org-mode compatible dump of the graph via --probe-stats-org-mode. This feature is extremely useful because it allows collapsing and expanding the graph interactively from within the editor:

The second aspect of probing is the ability to dig deep into each transform, in order to understand what it was doing. For this we can use --probe-all. Once enabled, a dump is generated for each transform in the transform graph of its inputs and outputs - where applicable. These are also stored in the probe directory. The directory structure follows the graph:
000-archetype_location_repository.json
001-type_repository.json
002-mapping_set_repository.json
003-dogen.yarn.code_generation_chain
transform_stats.txt
Each transform chain becomes a directory, and each transform has files with inputs and outputs, in JSON. It is trivial to indent the JSON files and diff input with output to figure out what the transform did - or, more likely, didn't do.
As always, there were complications with Windows. Since this operative system does not support long paths, we found that probing often failed with errors because our transform graph is deeply nested and the transforms have very long names. To allow one to use this feature under Windows, we've added --probe-use-short-names. This makes the files and directories a lot less meaningful, but at least it still works:
000.json
001.json
002.json
003
transform_stats.txt
It is difficult to overstate the importance of probing in Dogen development. It was already used during this sprint to quickly get to the bottom of issues in enablement, and it was found to greatly simply this task....
Dogen v1.0.04, "Zona dos Riscos"
Zona dos Riscos, Namibe, Angola. (C) Alma de Viajante, 2017.

Overview
As usual, yarn internal refactoring is the bulk of the work in this sprint. The refactoring work had three major themes:
- Use shared pointers across the board for yarn elements, from frontend to the backend. This was done as a requirement for the exogenous models changes described below; as it happens, it has the nice side-effect of reducing the number of copies of model elements.
- Finish exogenous models support: frontends now have a special purpose model type, designed only for the kind of operations supported at the frontend level. This cleaned up transformations quite a bit, making it obvious which ones apply at which stage. The conceptual model is now somewhat cleaner, with the introduction of exomodels (previously "exogenous models") and endomodels (previously "intermediate models"), which specific purposes.
- Name processing now done in core: as part of the exogenous models change, we also moved the external and model module processing away from the frontends and into the core. This means less code duplication across frontends.
In addition to these, there were a couple of additional stories that had user facing impact, described in the next section.
User visible changes
This sprint introduced a number of user visible changes, all related to the internal clean-up work:
- Upsilon support was considered deprecated, since the customer for which we developed it no longer requires it. As it was a custom-made frontend, with no real application outside of this specific use case, all code related to upsilon has been removed.
- Continuing the meta-name work, JSON now represents these as regular yarn names. Sadly, this makes the JSON more verbose - but at least all names have a consistent representation now. This change breaks backwards compatibility, so users with JSON models need to update them. Sample change:
- "meta_type": "module",
+ "meta_name": {
+ "simple": "module",
+ "external_modules": "dogen",
+ "model_modules": "yarn",
+ "internal_modules": "meta_model"
+ }
- A new command line flag was introduced:
--compatibility-mode. The objective of this flag is to disable some of the model validation code, where the errors are known to be caused by a forwards or backwards incompatible change. However: a) this is an experimental flag, very incomplete at present; and b) even when finished, the generated code may just be invalid.
For more details of the work carried out this sprint, see the sprint log.
Next Sprint
Next sprint we'll resume the work on moving kernel-agnostic transformations from the kernels into yarn, and start looking at the meta-data/concepts clean-up.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Dogen v1.0.03, "Pavilhão"
Pavilhão Welvitchia Mirabilis, Moçâmedes, Namibe. (C) Angola Press 2016.

Overview
We continue with yet another sprint refactoring the core in yarn. Initially, the focus was on moving more code from the C++ and C# kernels into yarn, but a series of deficiencies were found on the way we are processing exogenous models and so we switched focus to fixing those. This work will continue into the next sprint.
As part of this sprint we did manage to move away from using std::type_index and using instead our own meta-meta-model, which is consistent with our conceptual model and notions of modeling spaces. In addition, we cleaned up usages of the type repository, which greatly simplified the code.
User visible changes
There are no user visible changes in this sprint.
For more details of the work carried out this sprint, see the sprint log.
Next Sprint
In the next sprint we'll finish the work on exogenous models and resume the work on moving kernel-agnostic transformations from the kernels into yarn.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
Note: They are produced by CI so they may not yet be ready.
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.