You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: NEWS.md
+6Lines changed: 6 additions & 0 deletions
Original file line number
Diff line number
Diff line change
@@ -1,3 +1,9 @@
1
+
## crunchtabs 1.4.3
2
+
3
+
- categorical_arrays were previously spliced into the first position at every question iteration, leading to questions being presented out of vector order in the resulting pdf output. This update patches the results list back together when splicing the array questions in-place. Now, the order of variables is the same as the order presented in the output pdf. (INNOV-498)
4
+
- When a categorical_array is flattened into categoricals inside of a trackingReport, the names of the subvariables are regenerated. If the user is using latex_flip_specific_grids the question name will not be the original categorical array's name. A warning is now shown that provides the user with instructions on the explicit names to use in latex_flip_specific_grids. (INNOV-498)
5
+
- The vignette for tracking reports has been: reorganized for clarity, updated with more recommendations, and clarifies some finer points related to relabelling, and restructuring data for use with tracking reports. (INNOV-498)
Copy file name to clipboardExpand all lines: vignettes/Tracking.Rmd
+87-82Lines changed: 87 additions & 82 deletions
Original file line number
Diff line number
Diff line change
@@ -15,80 +15,52 @@ Last updated: `r Sys.Date()`
15
15
16
16
## Reporting Over Time
17
17
18
-
`crunchtabs` supports two distinct forms of tracking reports. A recontact report, where the same questions have been asked in the same dataset over time and require individual weighting. An example of this would be a political survey, where voters have been asked about their vote intention before and after a debate. The second, is a tracking report, where the same questions have been asked in different datasets and require independent weighting.
18
+
`crunchtabs` supports two distinct forms of tracking reports. A tracking report where the same questions have been asked in the different datasets over time, and a recontact report where questions have been asked in the same survey requiring individual weighting. An example of this would be a political survey, where voters have been asked about their vote intention before and after a debate. The function to create tracking reports is much more flexible and is the recommended approach for creating reports of this nature where stacking datasets is of interest. It is not only limited to stacking data over time, it can also be used to stack datasets in different geographies from, for example, a global study, or any kind of split dataset.
19
19
20
-
By default, both of these functions will allow you to present variables that you have included in your specification that do not exist across datasets.
20
+
Not all "recontact surveys" are formatted appropriately for use with the `recontact_report` function. It is often easier to get the desired result with `trackingReport`, by following these steps:
21
21
22
-
### Generating a Recontact Report
23
-
24
-
In the code below, the crunch example dataset is used to illustrate the setup required for recontact style reporting. There are a few important assumptions about the naming and setup of your data that are critical to the success of this function:
25
-
26
-
1. Your "pre" and "post" wave's questions should both have the same categories.
27
-
2. Your "pre" and "post" wave's question names should be equal, with different suffixes, such as: question_pre and question_post.
28
-
29
-
```{r, eval = FALSE}
30
-
library(crunchtabs)
31
-
login()
32
-
33
-
# Create an example dataset
34
-
ds <- newExampleDataset()
35
-
ds <- loadDataset("Example dataset")
36
-
37
-
# Generate weights
38
-
ds$weight1 <- makeWeight(ds$q1 ~ c(0.3,0.3,0.4,0), name = 'weight1')
39
-
ds$weight2 <- makeWeight(ds$q1 ~ c(0.4,0.4,0.1,0.1), name = 'weight2')
40
-
41
-
# Oddity of crunch, you can't use a weight in a tabBook that
42
-
# has never been applied to the dataset.
43
-
weight(ds) <- ds$weight1
44
-
weight(ds) <- ds$weight2
45
-
weight(ds) <- ds$weight1
46
-
47
-
# Fake pre and post questions
48
-
ds$q1_pre <- copyVariable(ds$q1, deep = TRUE, name = "Pet name pre")
49
-
ds$q1_post <- copyVariable(ds$q1, deep = TRUE, name = "Pet name post")
50
-
ds$country_pre <- copyVariable(ds$country, deep = TRUE, name = "Country pre")
51
-
ds$country_post <- copyVariable(ds$country, deep = TRUE, name = "Country post")
2. Recalculate weights, ensuring the same variable name is used in all datasets.
24
+
3. Align variable names so that they are the same in both datasets where they exist.
67
25
26
+
Missingness is dealt with gracefully. If there are missing data where a question was asked in one wave but not the other, the proportions are replaced with "-".
68
27
69
28
### Flipping Grids
70
29
71
30
Often the case may be that your category labels are long, and your wave descriptors are very short. In this case, crunchtabs provides options for "flipping grids". You can transpose the presentation so that the wave labels are columns, and the category labels are rows.
72
31
73
-
To do so globally, we set the `latex_flip_gris` theme option to `TRUE`:
32
+
> NOTE: Many references are made to "wave" here, but it could be any kind of split. Geography, gender, and so on.
33
+
34
+
To do so globally, we set the `latex_flip_grids` theme option to `TRUE`:
35
+
36
+
> NOTE: If your dataset contains categorical_arrays that are present in only one wave, it is better to use `latex_flip_specific_grids`. An example is provided further below.
74
37
75
38
```{r, eval = FALSE}
76
39
theme <- themeNew(..., latex_flip_grids = TRUE)
77
40
```
78
41
79
42
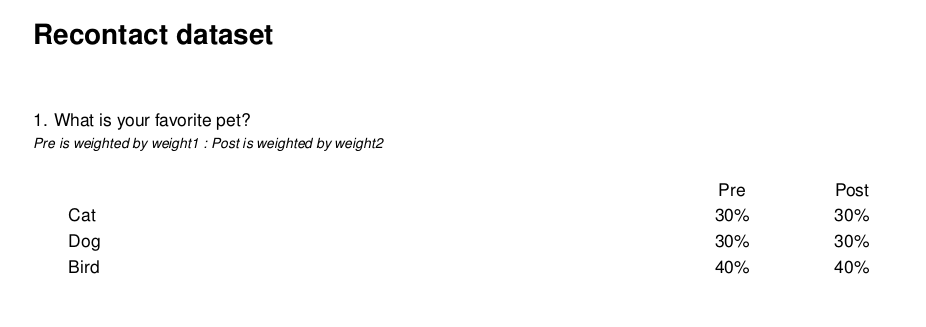
80
43
81
-
82
-
83
-
In addition to global transposition of grids, you can also do so conditionally:
44
+
In addition to global transposition of grids, you can also do so conditionally using the `latex_flip_specific_grids` theme option:
The above will only flip `q1`. When you have many variables and only a few that you do not want to be flipped, it can be useful to use `setdiff()` to opt out specific variables. This is especially desirable if your data include categorical arrays that were only asked in one wave, as these are often much wider than
51
+
52
+
```{r, eval=FALSE}
53
+
vars <- c("cat1_all", "cat2_wave1", "catarray1_all", "catarray1_wave1")
While recontact reports are designed for questions asked in the same dataset, there is also the ability to present questions asked in multiple datasets in a similar fashion.
63
+
While recontact reports are designed for questions asked in the same dataset, there is also the ability to present questions asked in multiple datasets in a similar fashion. Even if you have a single dataset it can often be useful to split, align the variable names and recalculate the weights to take advantage of `trackingReport`'s flexibility.
92
64
93
65
In the code block below, we illustrate data setup and an example call to `trackingReports`. While our example is not representative of a real-life situation, the manner in which you would need to manage data are the same.
94
66
@@ -123,7 +95,7 @@ theme <- themeNew(
123
95
ct <- trackingReport(
124
96
dataset_list = list(ds1, ds2, ds3),
125
97
vars = c("allpets", "q1", "petloc"),
126
-
wave_labels = NULL
98
+
wave_labels = NULL # automatically Wave 1, 2, 3
127
99
)
128
100
129
101
# Write to latex and convert to pdf
@@ -176,49 +148,82 @@ ct <- trackingReport(
176
148
writeLatex(ct, pdf = TRUE)
177
149
```
178
150
179
-
### Including One-off Questions
180
151
181
-
While the default behavior of `trackingReport` and `recontact_report` is to only include those questions that have been asked more than once, it is often desirable to show questions that have only been asked in a certain wave of your survey or during one phase of your recontact. In both cases, we provide a `vars` argument, that when provided will identify all of the questions to be presented in the output. Importantly, the order of this `vars` argument will also match that of the output PDF.
152
+
### Relabeling Categories or Responses
182
153
183
-
```{r, eval = FALSE}
184
-
# For recontact_toplines
154
+
There are a number of situations where your category names in a multiple response or categorical array question may be too long for reasonable presentation. Flipping grids is a good option, however, this may not be desirable or possible due to the number of waves or datasets that you are working with. For these cases, crunchtabs offers the ability to relabel your responses or to reposition them.
185
155
186
-
# The resulting report would show q1 recontact, other alias single, and country recontact
187
-
ct <- recontact_toplines(
188
-
ds,
189
-
questions = c("q1", "country"),
190
-
suffixes = c("_pre", "_post"),
191
-
labels = c("Pre", "Post"),
192
-
weights = c("weight1", "weight2"),
193
-
vars = c("q1", "other_alias","country")
194
-
)
156
+
#### Relabeling
195
157
196
-
# For trackingReport
158
+
Renaming happens just before printing to latex, that means you can create customizations for other defaults using this command. It's important to recognize that this will overwrite both labels and subvariable names. If you define it appropriately, it will rename it. This includes wave names, category labels or multiple response statements.
197
159
198
-
# The resulting report would show allpets tracking, q1 tracking, petloc tracking and alias_available_in_ds3_only
199
-
ct <- trackingReport(
200
-
dataset_list = list(ds1, ds2, ds3),
201
-
vars = c("allpets", "q1", "petloc", "alias_available_in_ds3_only"),
202
-
wave_labels = NULL
203
-
)
160
+
You can generally relabel any element of the specified alias. The question options (categories), items (statements in an array), the notes (typically the subtext of a question), or the description (question text).
161
+
162
+
```{r, eval = FALSE}
163
+
164
+
# `ct` is an object created by crosstabs or trackingReport
There are a number of situations where your category names in a multiple response or categorical array question may be too long for reasonable presentation. Flipping grids is a good option, however, this may not be desirable or possible due to the number of waves or datasets that you are working with. For these cases, crunchtabs offers the ability to relabel your responses or to reposition them.
209
178
210
-
#### Relabeling
211
179
212
-
Renaming happens just before printing to latex, that means you can create customizations for other defaults using this command. It's important to recognize that this will overwrite both labels and subvariable names. If you define it appropriately, it will rename it. This includes wave names, category labels or multiple response statements.
180
+
### Generating a Recontact Report
181
+
182
+
A recontact report is a special case and has limited flexibility.
183
+
184
+
1. Variables must have a suffix identifying the pre and post waves.
185
+
2. Two separate weighting variables
186
+
187
+
In the code below, the crunch example dataset is used to illustrate the setup required for recontact style reporting. There are a few important assumptions about the naming and setup of your data that are critical to the success of this function:
213
188
214
-
In the example below, "x" and "a" are the labels you wish to rename and "y" and "b" are the resulting labels.
189
+
1. Your "pre" and "post" wave's questions should both have the same categories.
190
+
2. Your "pre" and "post" wave's question names should be equal, with different suffixes, such as: question_pre and question_post.
215
191
216
192
```{r, eval = FALSE}
193
+
library(crunchtabs)
194
+
login()
195
+
196
+
# Create an example dataset
197
+
ds <- newExampleDataset()
198
+
ds <- loadDataset("Example dataset")
199
+
200
+
# Generate weights
201
+
ds$weight1 <- makeWeight(ds$q1 ~ c(0.3,0.3,0.4,0), name = 'weight1')
202
+
ds$weight2 <- makeWeight(ds$q1 ~ c(0.4,0.4,0.1,0.1), name = 'weight2')
203
+
204
+
# Oddity of crunch, you can't use a weight in a tabBook that
205
+
# has never been applied to the dataset.
206
+
weight(ds) <- ds$weight1
207
+
weight(ds) <- ds$weight2
208
+
weight(ds) <- ds$weight1
209
+
210
+
# Fake pre and post questions
211
+
ds$q1_pre <- copyVariable(ds$q1, deep = TRUE, name = "Pet name pre")
212
+
ds$q1_post <- copyVariable(ds$q1, deep = TRUE, name = "Pet name post")
213
+
ds$country_pre <- copyVariable(ds$country, deep = TRUE, name = "Country pre")
214
+
ds$country_post <- copyVariable(ds$country, deep = TRUE, name = "Country post")
0 commit comments